Introductie
De One-Class Support Vector Machine (SVM) is een variant van de traditionele SVM. Het is specifiek afgestemd op het detecteren van afwijkingen. Het primaire doel is om gevallen te lokaliseren die met name afwijken van de standaard. In tegenstelling tot conventioneel Machine leren modellen gericht op binaire classificatie of classificatie met meerdere klassen, is de SVM met één klasse gespecialiseerd in de detectie van uitschieters of nieuwigheden binnen datasets. In dit artikel leert u hoe One-Class Support Vector Machine (SVM) verschilt van traditionele SVM. Ook leer je hoe OC-SVM werkt en hoe je het implementeert. Je leert ook over de hyperparameters ervan.
leerdoelen
- Om afwijkingen te begrijpen
- Meer informatie over SVM met één klasse
- Begrijp hoe het verschilt van de traditionele Support Vector Machine (SVM)
- Hyperparameters van OC-SVM in Sklearn
- Hoe afwijkingen te detecteren met OC-SVM
- Gebruiksscenario's van één-klasse SVM
Inhoudsopgave
Anomalieën begrijpen
Afwijkingen zijn waarnemingen of gevallen die aanzienlijk afwijken van het normale gedrag van een dataset. Deze afwijkingen kunnen zich in verschillende vormen manifesteren, zoals uitschieters, ruis, fouten of onverwachte patronen. Anomalieën zijn vaak fascinerend omdat ze waardevolle inzichten kunnen vertegenwoordigen. Ze kunnen inzichten opleveren zoals het identificeren van frauduleuze transacties, het opsporen van defecten aan apparatuur of het blootleggen van nieuwe fenomenen. Uitbijter- en nieuwigheidsdetectie identificeren afwijkingen en abnormale of ongebruikelijke waarnemingen.
Lees ook: Een end-to-end gids over anomaliedetectie
Eén klasse SVM
Inleiding tot ondersteuning van vectormachines (SVM's)
Ondersteuning van vectormachines (SVM's) zijn populair algoritme voor leren onder supervisie voor classificatie- en regressietaken. SVM's werken door het optimale hypervlak te vinden dat verschillende klassen in functieruimte scheidt, terwijl de marge daartussen wordt gemaximaliseerd. Dit hypervlak is gebaseerd op een subset van trainingsgegevenspunten die ondersteuningsvectoren worden genoemd.
Eén-klasse SVM versus traditionele SVM
- SVM's van één klasse vertegenwoordigen een variant van het traditionele SVM-algoritme dat voornamelijk wordt gebruikt voor taken voor het detecteren van uitschieters en nieuwigheden. In tegenstelling tot traditionele SVM's, die binaire classificatietaken afhandelen, traint One-Class SVM uitsluitend op datapunten uit één enkele klasse, ook wel de doelklasse genoemd. SVM met één klasse heeft tot doel een grens- of beslissingsfunctie te leren die de doelklasse in de kenmerkruimte inkapselt, waardoor het normale gedrag van de gegevens effectief wordt gemodelleerd.
- Traditionele SVM's streven ernaar een beslissingsgrens te vinden die de marge tussen verschillende klassen maximaliseert, waardoor een optimale classificatie van nieuwe datapunten mogelijk is. Aan de andere kant probeert One-Class SVM een grens te vinden die de doelklasse inkapselt, terwijl het risico wordt geminimaliseerd dat er uitschieters of nieuwe gevallen buiten deze grens worden opgenomen.
- Traditionele SVM's vereisen gelabelde gegevens met instanties uit meerdere klassen, waardoor ze geschikt zijn voor gecontroleerde classificatietaken. Een One-Class SVM maakt daarentegen toepassing mogelijk in scenario's waarin alleen gegevens uit de doelklasse beschikbaar zijn, waardoor deze zeer geschikt is voor niet-gecontroleerde afwijkingendetectie en nieuwigheidsdetectietaken.
Meer informatie: Classificatie in één klasse met behulp van ondersteunende vectormachines
Ze verschillen allebei in hun zachte margeformuleringen en de manier waarop ze deze gebruiken:
(Zachte marge in SVM wordt gebruikt om een zekere mate van misclassificatie mogelijk te maken)
SVM met één klasse heeft tot doel een hypervlak met maximale marge binnen de featureruimte te ontdekken door de in kaart gebrachte gegevens te scheiden van de oorsprong. Op een gegevensset Dn = {x1, . . . , xn} met xi ∈ X (xi is een kenmerk) en n dimensies:
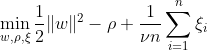
Deze vergelijking vertegenwoordigt de primaire probleemformulering voor OC-SVM, waarbij w het scheidende hypervlak is, ρ de offset vanaf de oorsprong is en ξi slappe variabelen zijn. Ze laten een zachte marge toe, maar bestraffen overtredingen ξi. Een hyperparameter ν ∈ (0, 1] regelt het effect van de spelingsvariabele en moet naar behoefte worden aangepast. Het doel is om de norm van w te minimaliseren en afwijkingen van de marge te bestraffen. Bovendien maakt dit het mogelijk dat een fractie van de gegevens binnen de marge of aan de verkeerde kant van het hypervlak vallen.
WX + b = 0 is de beslissingsgrens, en de slappe variabelen bestraffen afwijkingen.
Traditioneel ondersteunde vectormachines (SVM)
Traditionele Support Vector Machines (SVM) gebruiken de zachte margeformulering voor misclassificatiefouten. Of ze gebruiken datapunten die binnen de marge of aan de verkeerde kant van de beslissingsgrens vallen.
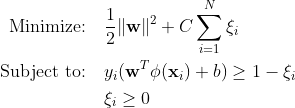
Waar:
w is de gewichtsvector.
b is de bias-term.
ξi zijn slappe variabelen die zachte marge-optimalisatie mogelijk maken.
C is de regularisatieparameter die de afweging regelt tussen het maximaliseren van de marge en het minimaliseren van de classificatiefout.
ϕ(xi) vertegenwoordigt de feature mapping-functie.
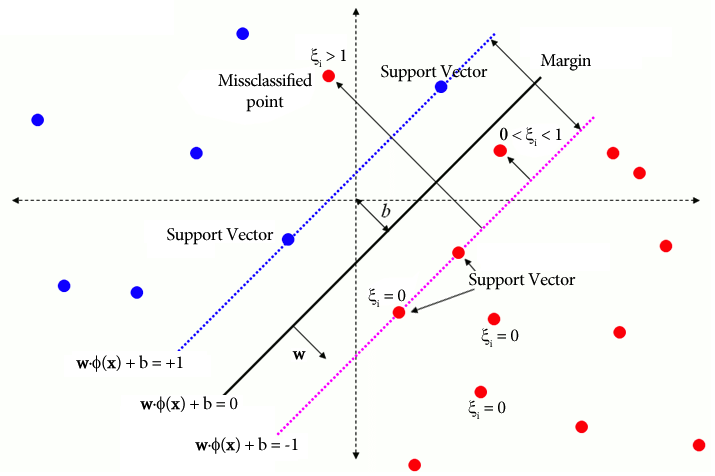
In traditionele SVM omvat een begeleide leermethode die voor scheiding afhankelijk is van klassenlabels slack-variabelen om een bepaald niveau van misclassificatie mogelijk te maken. Het primaire doel van SVM is om datapunten van verschillende klassen te scheiden met behulp van de beslissingsgrens WX + b = 0. De waarde van slappe variabelen varieert afhankelijk van de locatie van datapunten: ze worden op 0 gezet als de datapunten zich buiten de marges bevinden. Als het datapunt zich binnen de marge bevindt, liggen de slappe variabelen tussen 0 en 1, en reiken ze verder dan de tegenovergestelde marge als ze groter zijn dan 1.
Zowel traditionele SVM's als One-Class SVM's met formuleringen met zachte marges zijn bedoeld om de norm van de gewichtsvector te minimaliseren. Toch verschillen ze in hun doelstellingen en in de manier waarop ze omgaan met misclassificatiefouten of afwijkingen van de beslissingsgrens. Traditionele SVM's optimaliseren de nauwkeurigheid van de classificatie om overfitting te voorkomen, terwijl One-Class SVM's zich richten op het modelleren van de doelklasse en het beheersen van het aandeel uitschieters of nieuwe gevallen.
Lees ook: De AZ-gids ter ondersteuning van vectormachines
Belangrijke hyperparameters in SVM van één klasse
- nu: Dit is een cruciale hyperparameter in One-Class SVM, die het toegestane percentage uitschieters regelt. Er wordt een bovengrens gesteld aan de fractie trainingsfouten en een ondergrens aan de fractie steunvectoren. Het varieert doorgaans tussen 0 en 1, waarbij lagere waarden een striktere marge impliceren en minder uitschieters kunnen opvangen, terwijl hogere waarden toleranter zijn. De standaardwaarde is 0.5.
- pit: De kernelfunctie bepaalt het type beslissingsgrens dat de SVM gebruikt. Veel voorkomende keuzes zijn onder meer 'lineair', 'rbf' (Gaussiaanse radiale basisfunctie), 'poly' (polynoom) en 'sigmoïde'. De 'rbf'-kernel wordt vaak gebruikt omdat deze op effectieve wijze complexe niet-lineaire relaties kan vastleggen.
- gamma: Dit is een parameter voor niet-lineaire hypervlakken. Het definieert hoeveel invloed een enkel trainingsvoorbeeld heeft. Hoe groter de gammawaarde, hoe dichter andere voorbeelden moeten worden beïnvloed. Deze parameter is specifiek voor de RBF-kernel en is doorgaans ingesteld op 'auto', wat standaard is ingesteld op 1 / n_features.
- kernelparameters (graad, coef0): Deze parameters gelden voor polynomiale en sigmoïde kernels. 'graad' is de graad van de polynomiale kernfunctie, en 'coef0' is de onafhankelijke term in de kernelfunctie. Het afstemmen van deze parameters kan nodig zijn om optimale prestaties te bereiken.
- tol: Dit is het stopcriterium. Het algoritme stopt wanneer de dualiteitskloof kleiner is dan de tolerantie. Het is een parameter die de tolerantie voor het stopcriterium regelt.
Werkingsprincipe van één-klasse SVM
Kernelfuncties in SVM van één klasse
Kernelfuncties spelen een cruciale rol in One-Class SVM door het algoritme te laten werken in hoger-dimensionale featureruimtes zonder expliciet de transformaties te berekenen. In One-Class SVM worden, net als bij traditionele SVM's, kernelfuncties gebruikt om de gelijkenis tussen paren datapunten in de invoerruimte te meten. Veel voorkomende kernelfuncties die worden gebruikt in One-Class SVM zijn onder meer Gaussiaanse (RBF), polynomiale en sigmoïde kernels. Deze kernels brengen de oorspronkelijke invoerruimte in kaart in een hoger-dimensionale ruimte, waar gegevenspunten lineair scheidbaar worden of duidelijkere patronen vertonen, wat het leren vergemakkelijkt. Door een geschikte kernelfunctie te kiezen en de parameters ervan af te stemmen, kan One-Class SVM op effectieve wijze complexe relaties en niet-lineaire structuren in de gegevens vastleggen, waardoor het vermogen om afwijkingen of uitschieters te detecteren wordt verbeterd.
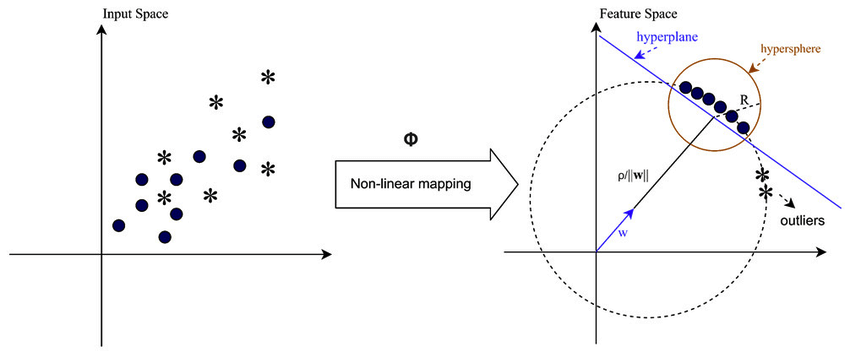
In gevallen waarin de gegevens niet lineair scheidbaar zijn, zoals bij complexe of overlappende patronen, kunnen Support Vector Machines (SVM's) een Radial Basis Function (RBF)-kernel gebruiken om uitschieters effectief van de rest van de gegevens te scheiden. De RBF-kernel transformeert de invoergegevens in een hoger-dimensionale kenmerkruimte die beter kan worden gescheiden.
Marge- en ondersteuningsvectoren
Het concept van marge- en ondersteuningsvectoren in One-Class SVM is vergelijkbaar met dat in traditionele SVM's. De marge verwijst naar het gebied tussen de beslissingsgrens (hypervlak) en de dichtstbijzijnde gegevenspunten van elke klasse. In One-Class SVM vertegenwoordigt de marge het gebied waar de meeste datapunten die tot de doelklasse behoren, liggen. Het maximaliseren van de marge is cruciaal voor One-Class SVM, omdat het nieuwe datapunten goed kan generaliseren en de robuustheid van het model verbetert. Steunvectoren zijn de gegevenspunten die op of binnen de marge liggen en bijdragen aan het definiëren van de beslissingsgrens.
In One-Class SVM zijn ondersteuningsvectoren de datapunten van de doelklasse die zich het dichtst bij de beslissingsgrens bevinden. Deze ondersteuningsvectoren spelen een belangrijke rol bij het bepalen van de vorm en oriëntatie van de beslissingsgrens en dus bij de algehele prestaties van het One-Class SVM-model. Door de ondersteuningsvectoren te identificeren, leert One-Class SVM effectief de representatie van de doelklasse in de featureruimte en construeert een beslissingsgrens die de meeste datapunten inkapselt, terwijl het risico op het opnemen van uitschieters of nieuwe instanties wordt geminimaliseerd.
Hoe kunnen afwijkingen worden gedetecteerd met behulp van One-Class SVM?
Afwijkingen detecteren met behulp van One-class SVM (Support Vector Machine) via zowel nieuwheidsdetectie als uitbijterdetectietechnieken:
Detectie van uitbijter
Het gaat om het identificeren van observaties in de trainingsgegevens die aanzienlijk afwijken van de rest, vaak uitschieters genoemd. Schattingen voor uitbijter detectie streven ernaar om te passen in de gebieden waar de trainingsgegevens het meest geconcentreerd zijn, waarbij deze afwijkende observaties buiten beschouwing worden gelaten.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()
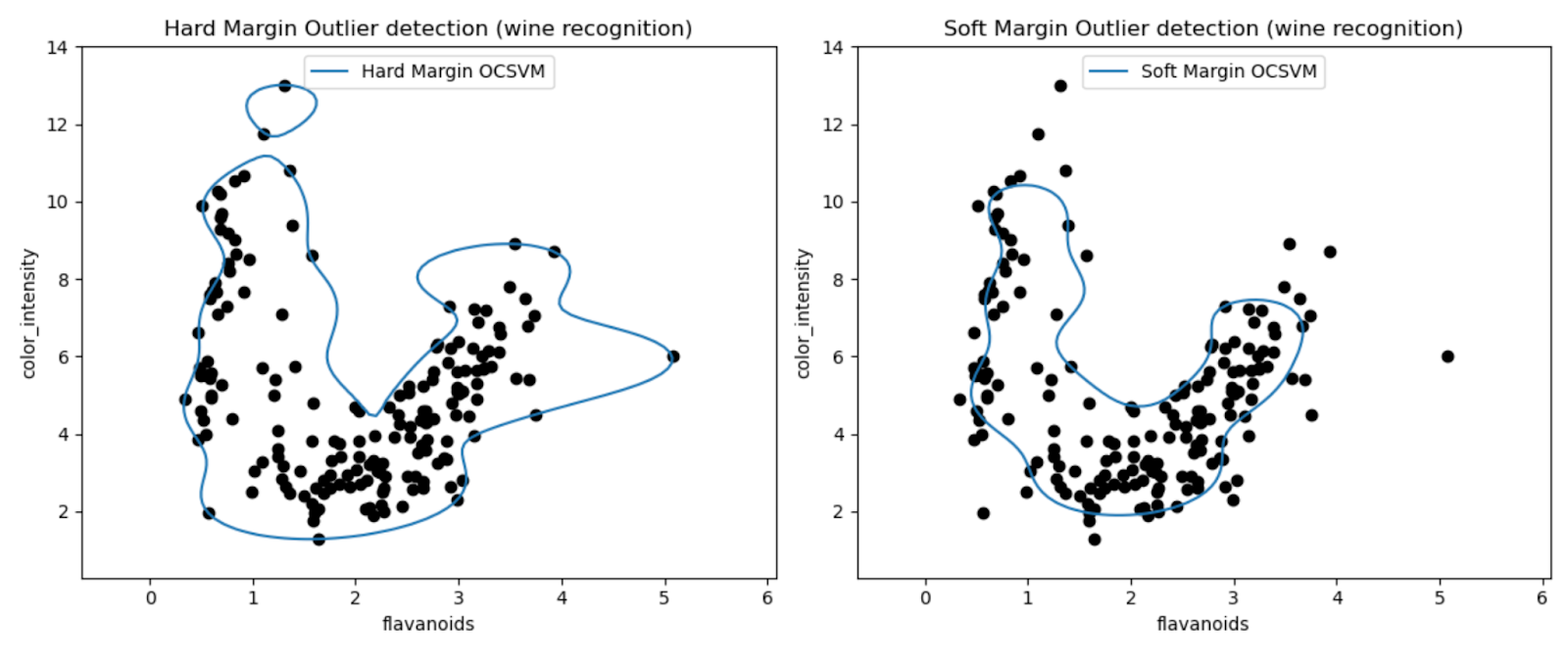
Met de grafieken kunnen we de prestaties van de One-Class SVM-modellen visueel inspecteren bij het detecteren van uitschieters in de Wine-dataset.
Door de resultaten van One-Class SVM-modellen met harde en zachte marges te vergelijken, kunnen we waarnemen hoe de keuze van de marge-instelling (nu-parameter) de detectie van uitschieters beïnvloedt.
Het hardemargemodel met een zeer kleine nu-waarde (0.01) resulteert waarschijnlijk in een conservatievere beslissingsgrens. Het omsluit het merendeel van de gegevenspunten strak en classificeert mogelijk minder punten als uitschieters.
Omgekeerd resulteert het zachtemargemodel met een grotere nu-waarde (0.35) waarschijnlijk in een flexibelere beslissingsgrens. Hierdoor is een grotere marge mogelijk en kunnen mogelijk meer uitschieters worden opgevangen.
Nieuwigheidsdetectie
Aan de andere kant passen we het toe als de trainingsgegevens vrij zijn van uitschieters, en het doel is om te bepalen of een nieuwe waarneming zeldzaam is, dat wil zeggen heel anders dan bekende waarnemingen. Deze laatste observatie hier wordt een nieuwigheid genoemd.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()

- Genereer een synthetische dataset met twee clusters van datapunten. Doe dit door ze te genereren met een normale verdeling rond twee verschillende centra: (2, 2) en (-2, -2) voor trein- en testgegevens. Genereer willekeurig twintig gegevenspunten uniform binnen een vierkant gebied variërend van -4 tot 4 langs beide dimensies. Deze gegevenspunten vertegenwoordigen abnormale waarnemingen of uitschieters die aanzienlijk afwijken van het normale gedrag dat wordt waargenomen in de trein- en testgegevens.
- De geleerde grens verwijst naar de beslissingsgrens die is geleerd door het One-class SVM-model. Deze grens scheidt de gebieden van de kenmerkruimte waar het model gegevenspunten als normaal beschouwt, van de uitschieters.
- Het kleurverloop van blauw naar wit in de contouren vertegenwoordigt de variërende mate van vertrouwen of zekerheid die het One-Class SVM-model toewijst aan verschillende regio's in de kenmerkruimte, waarbij donkerdere tinten een groter vertrouwen aangeven in het classificeren van datapunten als 'normaal'. Donkerblauw geeft regio's aan met een sterke indicatie dat ze 'normaal' zijn volgens de beslissingsfunctie van het model. Naarmate de kleur lichter wordt in de contour, is het model minder zeker over het classificeren van gegevenspunten als 'normaal'.
- De plot geeft visueel weer hoe het One-class SVM-model onderscheid kan maken tussen reguliere en abnormale waarnemingen. De geleerde beslissingsgrens scheidt de gebieden van normale en abnormale waarnemingen. Eén-klasse SVM voor nieuwigheidsdetectie bewijst zijn doeltreffendheid bij het identificeren van abnormale waarnemingen in een bepaalde dataset.
Voor nu=0.5:
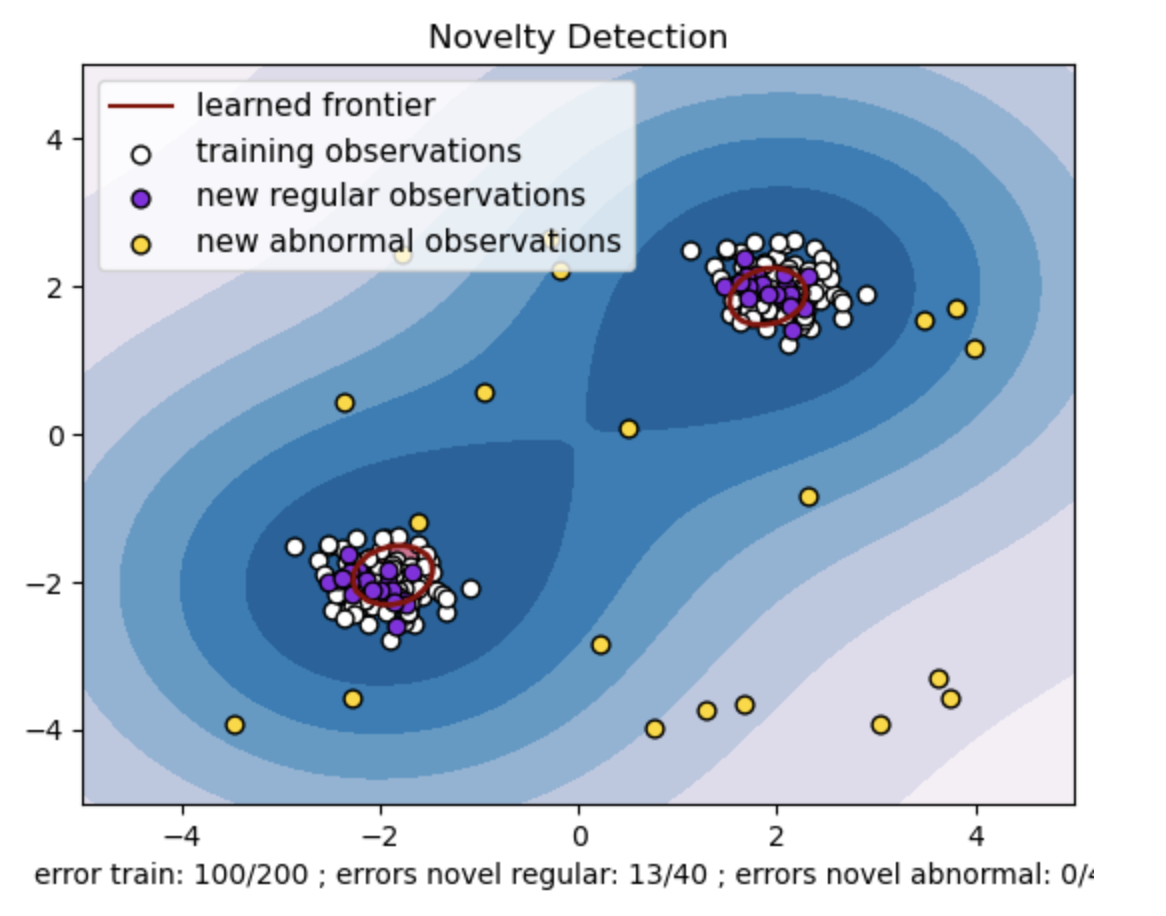
De “nu”-waarde in One-class SVM speelt een cruciale rol bij het beheersen van de fractie uitschieters die door het model wordt getolereerd. Het heeft rechtstreeks invloed op het vermogen van het model om afwijkingen te identificeren en beïnvloedt zo de voorspelling. We kunnen zien dat het model toestaat dat 100 trainingspunten verkeerd worden geclassificeerd. Een lagere waarde van nu impliceert een strengere beperking van het toegestane percentage uitschieters. De keuze voor nu beïnvloedt de prestaties van het model bij het detecteren van afwijkingen. Het vereist ook een zorgvuldige afstemming op basis van de specifieke vereisten van de applicatie en de kenmerken van de dataset.
Voor gamma=0.5 en nu=0.5
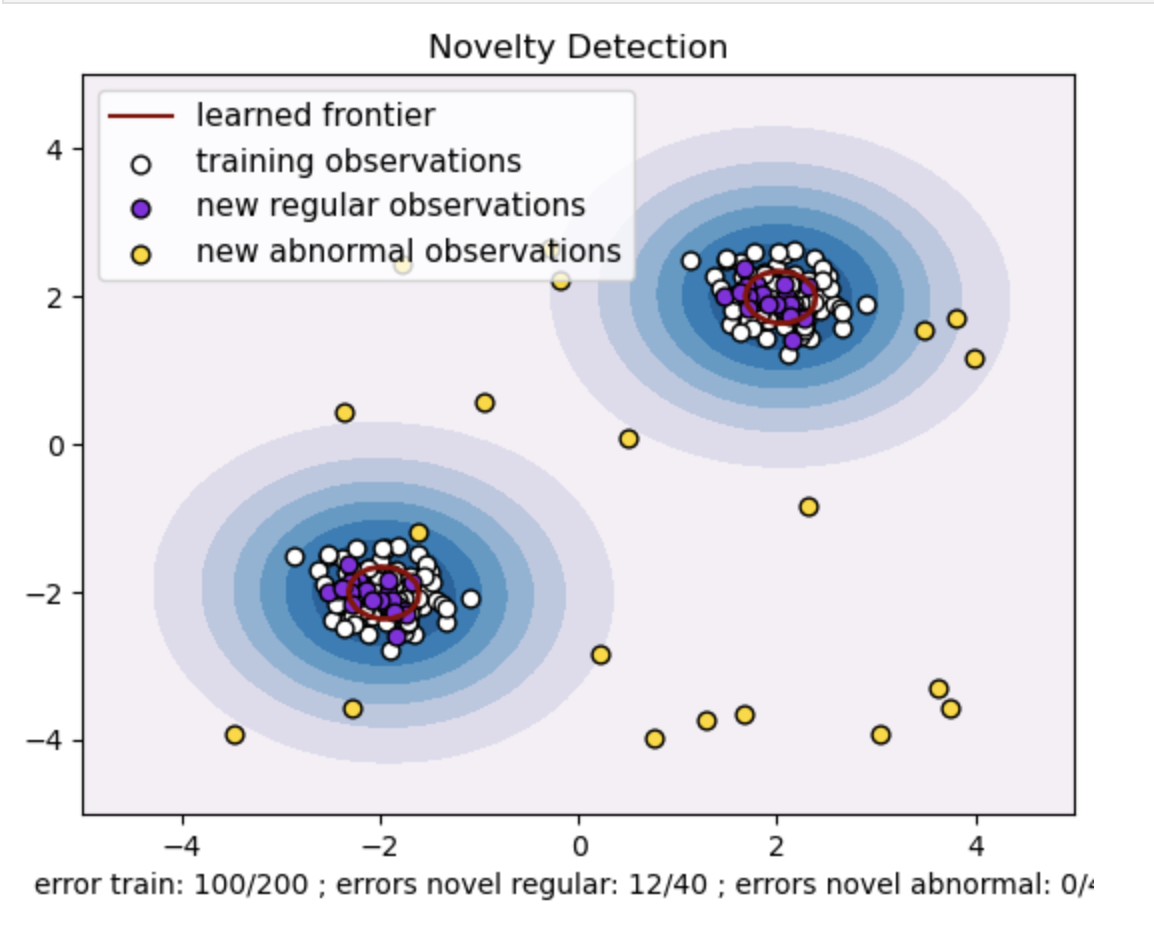
In One-class SVM vertegenwoordigt de gamma-hyperparameter de kernelcoëfficiënt voor de 'rbf'-kernel. Deze hyperparameter beïnvloedt de vorm van de beslissingsgrens en beïnvloedt bijgevolg de voorspellende prestaties van het model.
Wanneer gamma hoog is, beperkt een enkel trainingsvoorbeeld de invloed ervan tot de directe omgeving. Hierdoor ontstaat een meer gelokaliseerde beslissingsgrens. Daarom moeten gegevenspunten dichter bij de steunvectoren liggen om tot dezelfde klasse te behoren.
Conclusie
Het gebruik van One-Class SVM voor anomaliedetectie, het gebruik van uitbijter- en nieuwigheidsdetectie biedt een robuuste oplossing voor verschillende domeinen. Dit helpt in scenario's waarin gelabelde afwijkende gegevens schaars of niet beschikbaar zijn. Dit maakt het bijzonder waardevol in toepassingen in de echte wereld waar afwijkingen zeldzaam zijn en moeilijk expliciet te definiëren zijn. De gebruiksscenario's strekken zich uit tot diverse domeinen, zoals cyberbeveiliging en foutdiagnose, waar afwijkingen gevolgen hebben. Hoewel One-Class SVM tal van voordelen biedt, is het echter noodzakelijk om de hyperparameters in te stellen op basis van de gegevens om betere resultaten te krijgen, wat soms vervelend kan zijn.
Veelgestelde Vragen / FAQ
A. One-Class SVM construeert een hypervlak (of een hypersfeer in hogere dimensies) dat de normale datapunten inkapselt. Dit hypervlak is gepositioneerd om de marge tussen de normale gegevens en de beslissingsgrens te maximaliseren. Gegevenspunten worden tijdens testen of inferentie geclassificeerd als normaal (binnen de grens) of afwijkingen (buiten de grens).
A. SVM met één klasse is voordelig omdat er geen gelabelde gegevens nodig zijn voor afwijkingen tijdens de training. Het kan leren van een dataset die alleen reguliere exemplaren bevat, waardoor het geschikt is voor scenario's waarin afwijkingen zeldzaam zijn en het lastig is om gelabelde voorbeelden voor training te verkrijgen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/

