Introductie
Als we datawetenschap horen, is het eerste dat in ons opkomt het bouwen van een model op notebooks en het trainen van de gegevens. Maar dit is niet de situatie in de echte datawetenschap. In de echte wereld bouwen datawetenschappers modellen en brengen deze in productie. In de productieomgeving is er een kloof tussen de ontwikkeling, implementatie en betrouwbaarheid van het model en het faciliteren van efficiënte en schaalbare operaties. Dit is waar datawetenschappers gebruik van maken MLops (Machine Learning Operations) om ML-applicaties te bouwen en te implementeren in een productieomgeving. In dit artikel zullen we een voorspellingsproject voor klantverloop bouwen en implementeren met behulp van MLOps.

leerdoelen
In dit artikel leer je:
- Overzicht van het project
- We introduceren de basisprincipes van ZenML en MLOPS.
- Leer hoe u het model lokaal implementeert voor voorspelling
- Verdiep u in de voorverwerking en engineering van gegevens, training en evaluatie van het model
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Overzicht van het project
Allereerst moeten we begrijpen wat ons project is. Voor dit project beschikken we over een dataset van een telecombedrijf. Nu moeten we een model bouwen om te voorspellen of het waarschijnlijk is dat de gebruiker de service van het bedrijf zal voortzetten of niet. We zullen deze ML-applicatie bouwen met behulp van ZenmML en MLlow. Dit is de workflow van ons project.
De workflow van ons project
- Data Collection
- Data voorverwerking
- Trainingsmodel
- Evalueer model
- Deployment
Wat is MLOps?
MLOps is een end-to-end machine learning-levenscyclus, van ontwikkeling tot implementatie en doorlopend onderhoud. MLOps is de praktijk van het stroomlijnen en automatiseren van de gehele levenscyclus van machine learning-modellen, terwijl schaalbaarheid, betrouwbaarheid en efficiëntie worden gegarandeerd.
Laten we het uitleggen met een eenvoudig voorbeeld:
Stel je voor dat je een wolkenkrabber in je stad bouwt. De constructie van het gebouw is voltooid. Maar het ontbreekt aan elektriciteit, water, afvoersysteem, enz. De wolkenkrabber zal niet-functioneel en onpraktisch zijn.
Hetzelfde geldt voor machine learning-modellen. Als deze modellen worden ontworpen zonder rekening te houden met de implementatie van het model, de schaalbaarheid en het onderhoud op de lange termijn, kunnen ze ineffectief en onpraktisch worden. Dit vormt een grote hindernis voor datawetenschappers bij het construeren van machine learning-modellen voor gebruik in productieomgevingen.
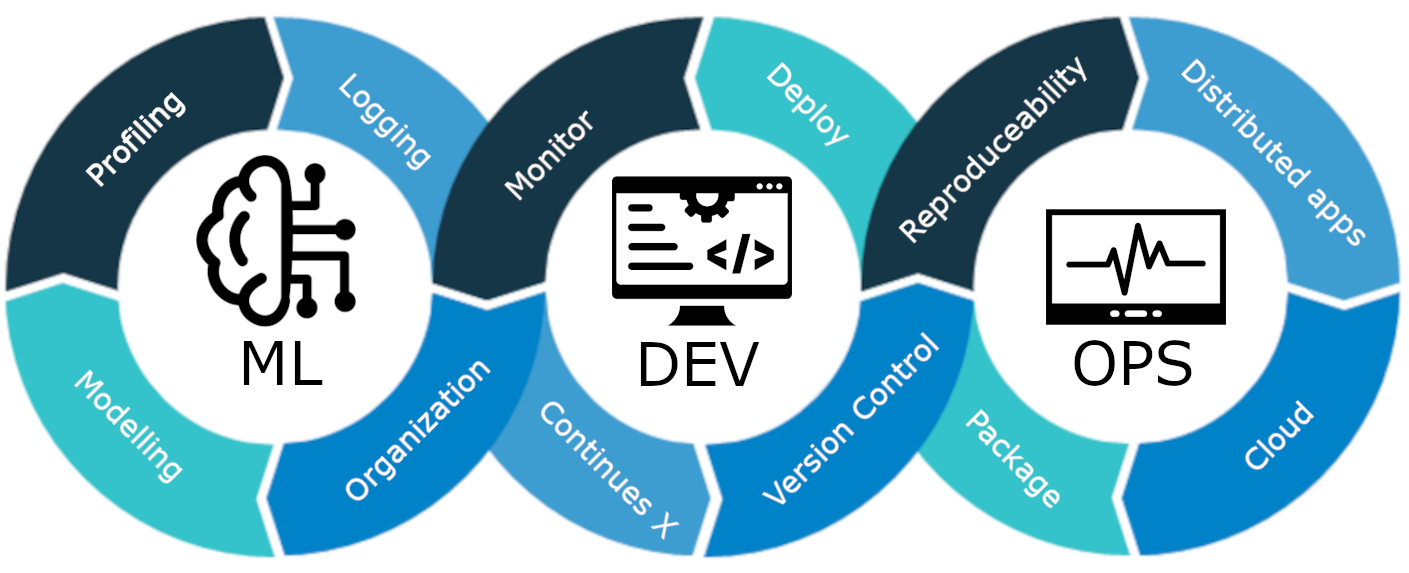
MLOps is een reeks best practices en strategieën die de productie, implementatie en langetermijnonderhoud van machine learning-modellen begeleiden. Het zorgt ervoor dat deze modellen niet alleen nauwkeurige voorspellingen opleveren, maar ook robuust, schaalbaar en waardevol blijven voor bedrijven. Zonder MLOps zal het dus een nachtmerrie zijn om al deze taken efficiënt uit te voeren, wat een uitdaging is. In dit project leggen we uit hoe MLOps werkt, verschillende fasen en een end-to-end project over het opbouwen van een klantomgeving. churn voorspelling model.
Maak kennis met ZenML
ZenML is een open-source MLOPS Framework dat helpt bij het bouwen van draagbare en productieklare pijplijnen. Het ZenML Framework zal ons helpen dit project uit te voeren met behulp van MLOPS.
⚠️ Bent u een Windows-gebruiker, probeer dan wsl op een pc te installeren. Zenml wordt niet ondersteund in Windows.
Voordat we verder gaan met de projecten.
Fundamentele concepten van MLOPS
- Stappen: Stappen zijn afzonderlijke takeneenheden in een pijplijn of workflow. Elke stap vertegenwoordigt een specifieke actie of bewerking die moet worden uitgevoerd om een machine learning-workflow te ontwikkelen. Het opschonen van gegevens, het voorbewerken van gegevens, trainingsmodellen, enz. zijn bijvoorbeeld bepaalde stappen bij het ontwikkelen van een machine learning-model.
- Pijpleidingen: Ze verbinden meerdere stappen met elkaar om een gestructureerd en geautomatiseerd proces voor machine learning-taken te creëren. voor bijvoorbeeld de gegevensverwerkingspijplijn, de modelevaluatiepijplijn en de modeltrainingspijplijn.
Ermee beginnen
Creëer een virtuele omgeving voor het project:
conda create -n churn_prediction python=3.9Installeer vervolgens deze bibliotheken:
pip install numpy pandas matplotlib scikit-learnNadat je dit hebt geïnstalleerd, installeer je ZenML:
pip install zenml["server"]Initialiseer vervolgens de ZenML-repository.
zenml init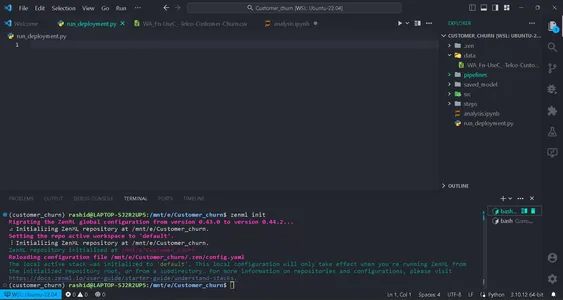
U krijgt een groene vlag om verder te gaan als uw scherm dit laat zien. Na het initialiseren van een map wordt .zenml in uw directory aangemaakt.
Maak een map voor gegevens in de map. Haal hier de gegevens op link:
Maak mappen volgens deze structuur.
Data Collection
In deze stap gaan we gegevens uit ons csv-bestand importeren. Deze gegevens worden gebruikt voor het trainen van het model na het opschonen en coderen.
Maak een bestand ingest_data.py in de map stappen.
import pandas as pd
import numpy as np
import logging
from zenml import step class IngestData: """ Ingesting data to the workflow. """ def __init__(self, path:str) -> None: """ Args: data_path(str): path of the datafile """ self.path = path def get_data(self): df = pd.read_csv(self.path) logging.info("Reading csv file successfully completed.") return df @step(enable_cache = False)
def ingest_df(data_path:str) -> pd.DataFrame: """ ZenML step for ingesting data from a CSV file. """ try: #Creating an instance of IngestData class and ingest the data ingest_data = IngestData(data_path) df = ingest_data.get_data() logging.info("Ingesting data completed") return df except Exception as e: #Log an error message if data ingestion fails and raise the exception logging.error("Error while ingesting data") raise eHier is het project link.
In deze code hebben we eerst de klasse IngestData gemaakt om de logica voor gegevensopname in te kapselen. Vervolgens hebben we een ZenML stap, ingest_df, wat een individuele eenheid is van de pijplijn voor gegevensverzameling.
Een bestand training_pipeline.py maken in de mappijplijn.
Schrijf de code
from zenml import pipeline from steps.ingest_data import ingest_df #Define a ZenML pipeline called training_pipeline. @pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' df = ingest_df(data_path=data_path)Hier creëren we een trainingspijplijn voor het trainen van een machine learning-model met behulp van een reeks stappen.
Maak vervolgens een bestand met de naam run_pipeline.py in de basismap om het pijpleiding.
from pipelines.training_pipeline import train_pipeline if __name__ == '__main__': #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Deze code wordt gebruikt voor het uitvoeren van de pijplijn.
Nu zijn we dus klaar met de pijplijn voor gegevensopname. Laten we het uitvoeren.
Voer de opdracht uit in uw terminal:
python run_pipeline.py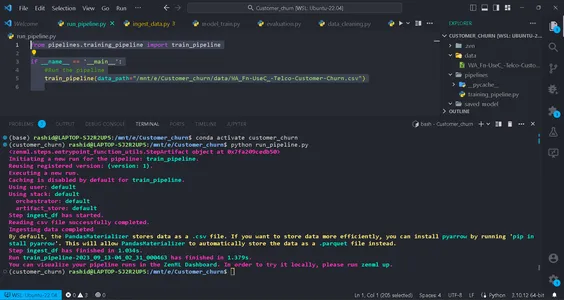
Vervolgens kunt u de opdrachten zien die aangeven dat training_pipeline met succes is voltooid.
Data Preprocessing
In deze stap zullen we verschillende strategieën creëren voor het opschonen van gegevens. De ongewenste kolommen worden verwijderd en categorische kolommen worden gecodeerd met behulp van Label-codering. Ten slotte worden de gegevens opgesplitst in trainings- en testgegevens.
Maak een bestand met de naam clean_data.py in de src-map.
In dit bestand gaan we klassen van strategieën maken voor het opschonen van de gegevens.
import pandas as pd
import numpy as np
import logging
from sklearn.model_selection import train_test_split
from abc import abstractmethod, ABC
from typing import Union
from sklearn.preprocessing import LabelEncoder class DataStrategy(ABC): @abstractmethod def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame,pd.Series]: pass # Data Preprocessing strategy
class DataPreprocessing(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df['TotalCharges'] = df['TotalCharges'].replace(' ', 0).astype(float) df.drop('customerID', axis=1, inplace=True) df['Churn'] = df['Churn'].replace({'Yes': 1, 'No': 0}).astype(int) service = ['PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] for col in service: df[col] = df[col].replace({'No phone service': 'No', 'No internet service': 'No'}) logging.info("Length of df: ", len(df.columns)) return df except Exception as e: logging.error("Error in Preprocessing", e) raise e # Feature Encoding Strategy
class LabelEncoding(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df_cat = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] lencod = LabelEncoder() for col in df_cat: df[col] = lencod.fit_transform(df[col]) logging.info(df.head()) return df except Exception as e: logging.error(e) raise e # Data splitting Strategy
class DataDivideStrategy(DataStrategy): def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: X = df.drop('Churn', axis=1) y = df['Churn'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) return X_train, X_test, y_train, y_test except Exception as e: logging.error("Error in DataDividing", e) raise e
Deze code implementeert een modulaire datavoorverwerkingspijplijn voor machinaal leren. Het omvat strategieën voor de voorverwerking van gegevens, het coderen van functies en de stappen voor gegevenscodering voor het opschonen van gegevens voor voorspellende modellering.
1. Gegevensvoorverwerking: Deze klasse is verantwoordelijk voor het verwijderen van ongewenste kolommen en het verwerken van ontbrekende waarden (NA-waarden) in de gegevensset.
2. Labelcodering: De klasse LabelEncoding is ontworpen om categorische variabelen te coderen in een numeriek formaat waarmee machine learning-algoritmen effectief kunnen werken. Het transformeert op tekst gebaseerde categorieën in numerieke waarden.
3. DataDivideStrategie: Deze klasse verdeelt de dataset in onafhankelijke variabelen (X) en afhankelijke variabelen (y). Vervolgens worden de gegevens opgesplitst in trainings- en testsets.
We zullen ze stap voor stap implementeren om onze gegevens voor te bereiden op machine learning-taken.
Deze strategieën zorgen ervoor dat de gegevens correct worden gestructureerd en geformatteerd voor modeltraining en evaluatie.
creëren data_cleaning.py in de stappen map.
import pandas as pd
import numpy as np
from src.clean_data import DataPreprocessing, DataDivideStrategy, LabelEncoding
import logging
from typing_extensions import Annotated
from typing import Tuple
from zenml import step # Define a ZenML step for cleaning and preprocessing data
@step(enable_cache=False)
def cleaning_data(df: pd.DataFrame) -> Tuple[ Annotated[pd.DataFrame, "X_train"], Annotated[pd.DataFrame, "X_test"], Annotated[pd.Series, "y_train"], Annotated[pd.Series, "y_test"],
]: try: # Instantiate the DataPreprocessing strategy data_preprocessing = DataPreprocessing() # Apply data preprocessing to the input DataFrame data = data_preprocessing.handle_data(df) # Instantiate the LabelEncoding strategy feature_encode = LabelEncoding() # Apply label encoding to the preprocessed data df_encoded = feature_encode.handle_data(data) # Log information about the DataFrame columns logging.info(df_encoded.columns) logging.info("Columns:", len(df_encoded)) # Instantiate the DataDivideStrategy strategy split_data = DataDivideStrategy() # Split the encoded data into training and testing sets X_train, X_test, y_train, y_test = split_data.handle_data(df_encoded) # Return the split data as a tuple return X_train, X_test, y_train, y_test except Exception as e: # Handle and log any errors that occur during data cleaning logging.error("Error in step cleaning data", e) raise eIn deze stap hebben we de strategieën geïmplementeerd die we hebben ontwikkeld clean_data.py
Laten we dit implementeren stap in training_pipeline.py
from zenml import pipeline #importing steps from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df)Dat is het; we hebben onze gegevensvoorverwerkingsstap in de trainingspijplijn voltooid.
Model opleiding
Nu gaan we het model voor dit project bouwen. Hier voorspellen we een binair classificatieprobleem. We kunnen gebruiken logistische regressie. Onze focus zal niet liggen op de nauwkeurigheid van het model. Het zal gebaseerd zijn op het MLOps-gedeelte.
Voor degenen die niets weten over logistische regressie, je kunt er hier over lezen. We zullen dezelfde stappen implementeren als bij de voorverwerkingsstap van de gegevens. Eerst gaan we een bestand aanmaken training_model.py in de src map.
import pandas as pd
from sklearn.linear_model import LogisticRegression
from abc import ABC, abstractmethod
import logging #Abstract model
class Model(ABC): @abstractmethod def train(self,X_train:pd.DataFrame,y_train:pd.Series): """ Trains the model on given data """ pass class LogisticReg(Model): """ Implementing the Logistic Regression model. """ def train(self, X_train: pd.DataFrame, y_train: pd.Series): """ Training the model Args: X_train: pd.DataFrame, y_train: pd.Series """ logistic_reg = LogisticRegression() logistic_reg.fit(X_train,y_train) return logistic_regWe definiëren een abstracte Modelklasse met een 'train'-methode die alle modellen moeten implementeren. De LogisticReg-klasse is een specifieke implementatie die gebruikmaakt van logistieke regressie. De volgende stap omvat het configureren van een bestand met de naam config.py in de stappenmap. Maak een bestand met de naam config.py in de map steps.
Modelparameters configureren
from zenml.steps import BaseParameters """
This file is used for used for configuring
and specifying various parameters related to your machine learning models and training process """ class ModelName(BaseParameters): """ Model configurations """ model_name: str = "logistic regression"In het bestand genaamd config.py, in de stappen map, configureert u parameters die betrekking hebben op uw machine-learning-model. U maakt een ModelName-klasse die overerft van Basisparameters om de modelnaam op te geven. Dit maakt het eenvoudig om het modeltype te wijzigen.
import logging import pandas as pd
from src.training_model import LogisticReg
from zenml import step
from .config import ModelName #Define a step called train_model
@step(enable_cache=False)
def train_model(X_train:pd.DataFrame,y_train:pd.Series,config:ModelName): """ Trains the data based on the configured model """ try: model = None if config == "logistic regression": model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) return trained_model except Exception as e: logging.error("Error in step training model",e) raise eDefinieer in het bestand met de naam model_train.py in de stappenmap een stap met de naam train_model met behulp van ZenML. Het doel van deze stap is het trainen van een machine learning-model op basis van de naam van het model in Modelnaam.
In het programma
Controleer de geconfigureerde modelnaam. Als het om 'logistische regressie' gaat, hebben we een exemplaar van het LogisticReg-model gemaakt en dit getraind met de opgegeven trainingsgegevens (X_train en y_train). Als de modelnaam niet wordt ondersteund, treedt er een fout op. Eventuele fouten tijdens dit proces worden geregistreerd en de fout treedt op.
Hierna gaan we deze stap implementeren training_pipeline.py
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train)Nu hebben we de stap train_model in de pijplijn geïmplementeerd. De stap model_train.py is dus voltooid.
Evaluatiemodel
In deze stap zullen we evalueren hoe efficiënt ons model is. Daarvoor zullen we de nauwkeurigheidsscore controleren bij het voorspellen van de testgegevens. Dus eerst gaan we de strategieën creëren die we in de pijplijn gaan gebruiken.
Maak een bestand met de naam evalueren_model.py in map src.
import logging
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from abc import ABC, abstractmethod
import numpy as np # Abstract class for model evaluation
class Evaluate(ABC): @abstractmethod def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Abstract method to evaluate a machine learning model's performance. Args: y_true (np.ndarray): True labels. y_pred (np.ndarray): Predicted labels. Returns: float: Evaluation result. """ pass #Class to calculate accuracy score
class Accuracy_score(Evaluate): """ Calculates and returns the accuracy score for a model's predictions. """ def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: try: accuracy_scr = accuracy_score(y_true=y_true, y_pred=y_pred) * 100 logging.info("Accuracy_score:", accuracy_scr) return accuracy_scr except Exception as e: logging.error("Error in evaluating the accuracy of the model",e) raise e
#Class to calculate Precision score
class Precision_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Generates and returns a precision score for a model's predictions. """ try: precision = precision_score(y_true=y_true,y_pred=y_pred) logging.info("Precision score: ",precision) return float(precision) except Exception as e: logging.error("Error in calculation of precision_score",e) raise e class F1_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray): """ Generates and returns an F1 score for a model's predictions. """ try: f1_scr = f1_score(y_pred=y_pred, y_true=y_true) logging.info("F1 score: ", f1_scr) return f1_scr except Exception as e: logging.error("Error in calculating F1 score", e) raise e Nu we de evaluatiestrategieën hebben ontwikkeld, zullen we deze gebruiken om het model te evalueren. Laten we de code erin implementeren stap evalueren_model.py in de stappenmap. Hier zijn de herinneringsscore, de nauwkeurigheidsscore en de precisiescore de strategieën die we gebruiken als maatstaven voor het evalueren van het model.
Laten we deze in stappen implementeren. Maak een bestand met de naam evaluatie.py in stappen:
import logging
import pandas as pd
import numpy as np
from zenml import step
from src.evaluate_model import ClassificationReport, ConfusionMatrix, Accuracy_score
from typing import Tuple
from typing_extensions import Annotated
from sklearn.base import ClassifierMixin @step(enable_cache=False)
def evaluate_model( model: ClassifierMixin, X_test: pd.DataFrame, y_test: pd.Series
) -> Tuple[ Annotated[np.ndarray,"confusion_matix"], Annotated[str,"classification_report"], Annotated[float,"accuracy_score"], Annotated[float,"precision_score"], Annotated[float,"recall_score"] ]: """ Evaluate a machine learning model's performance using common metrics. """ try: y_pred = model.predict(X_test) precision_score_class = Precision_Score() precision_score = precision_score_class.evaluate_model(y_pred=y_pred,y_true=y_test) mlflow.log_metric("Precision_score ",precision_score) accuracy_score_class = Accuracy_score() accuracy_score = accuracy_score_class.evaluate_model(y_true=y_test, y_pred=y_pred) logging.info("accuracy_score:",accuracy_score) return accuracy_score, precision_score except Exception as e: logging.error("Error in evaluating model",e) raise eLaten we deze stap nu in de pijplijn implementeren. Update training_pipeline.py:
Deze code definieert een evalueren_model stap in een machine-learning pijplijn. Er is een getraind classificatiemodel (model), onafhankelijke testgegevens (X_test), en echte labels voor de testgegevens (y_test) als invoer. Vervolgens evalueert het de prestaties van het model met behulp van algemene classificatiestatistieken en retourneert de resultaten, zoals de precisie_score en nauwkeurigheidsscore.
Laten we deze stap nu in de pijplijn implementeren. Update de training_pipeline.py:
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
from steps.evaluation import evaluate_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train) #Evaluation metrics of data accuracy_score, precision_score = evaluate_model(model=model,X_test=X_test, y_test=y_test)Dat is het. Nu hebben we de trainingspijplijn voltooid. Loop
python run_pipeline.py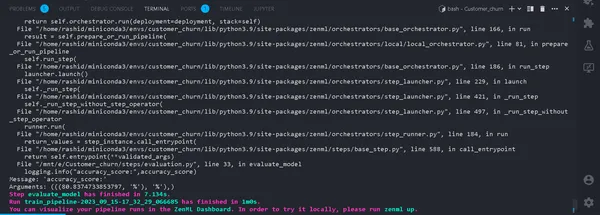
In de Terminal. Als het succesvol verloopt. Nu we lokaal een trainingspijplijn hebben uitgevoerd, ziet het er als volgt uit:
Wat is een experimenttracker?
Een experimenttracker is een tool in machine learning die wordt gebruikt om verschillende experimenten in het ontwikkelingsproces van machine learning op te nemen, te monitoren en te beheren.
Datawetenschappers experimenteren met verschillende modellen om de beste resultaten te krijgen. Ze moeten dus gegevens blijven volgen en verschillende modellen blijven gebruiken. Het zal heel moeilijk voor hen zijn als ze het handmatig registreren met behulp van een Excel-blad.
MLstroom
MLflow is een waardevol hulpmiddel voor het efficiënt volgen en beheren van experimenten op het gebied van machine learning. Het automatiseert het volgen van experimenten, het monitoren van modeliteraties en bijbehorende gegevens. Dit stroomlijnt het modelontwikkelingsproces en biedt een gebruiksvriendelijke interface voor het visualiseren van resultaten.
De integratie van MLflow met ZenML verbetert de robuustheid en het beheer van experimenten binnen het machine learning operations-framework.
Volg deze stappen om MLflow met ZenML in te stellen:
- MLflow-integratie installeren:
- Gebruik de volgende opdracht om de MLflow-integratie te installeren:
zenml integration install mlflow -y2. Registreer de MLflow-experimenttracker:
Registreer een experimenttracker in MLflow met behulp van deze opdracht:
zenml experiment-tracker register mlflow_tracker --flavor=mlflow3. Registreer een stapel:
In ZenML is een Stack een verzameling componenten die taken binnen uw ML-workflow definiëren. Het helpt bij het efficiënt organiseren en beheren van ML-pijplijnstappen. Registreer een stapel met:
Meer details vindt u in de documentatie.
zenml model-deployer register mlflow --flavor=mlflow
zenml stack register mlflow_stack -a default -o default -d mlflow -e mlflow_tracker --setHierdoor wordt uw Stack gekoppeld aan specifieke instellingen voor artefactopslag, orkestrators, implementatiedoelen en het bijhouden van experimenten.
4. Bekijk stapeldetails:
U kunt de componenten van uw Stack bekijken met behulp van:
zenml stack describeHier worden de componenten weergegeven die zijn gekoppeld aan de stapel "mlflow_tracker".
Laten we nu een experimenttracker in het trainingsmodel implementeren en het model evalueren:
U kunt de naam van de componenten zien als mlflow_tracker.
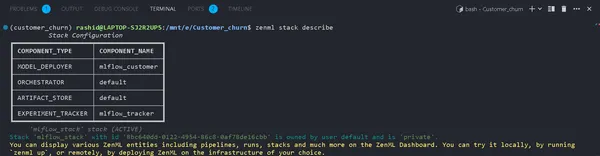
ZenML Experiment Tracker instellen
Begin eerst met het bijwerken van het train_model.py:
import logging
import mlflow
import pandas as pd
from src.training_model import LogisticReg
from sklearn.base import ClassifierMixin
from zenml import step
from .config import ModelName
#import from zenml.client import Client # Obtain the active stack's experiment tracker
experiment_tracker = Client().active_stack.experiment_tracker #Define a step called train_model
@step(experiment_tracker = experiment_tracker.name,enable_cache=False)
def train_model( X_train:pd.DataFrame, y_train:pd.Series, config:ModelName ) -> ClassifierMixin: """ Trains the data based on the configured model Args: X_train: pd.DataFrame = Independent training data, y_train: pd.Series = Dependent training data. """ try: model = None if config.model_name == "logistic regression": #Automatically logging scores, model etc.. mlflow.sklearn.autolog() model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) logging.info("Training model completed.") return trained_model except Exception as e: logging.error("Error in step training model",e) raise eIn deze code hebben we de experimenttracker ingesteld met behulp van mlflow.sklearn.autolog(), waarmee automatisch alle details over het model worden vastgelegd, waardoor het eenvoudiger wordt experimenten bij te houden en te analyseren.
In het evaluatie.py
from zenml.client import Client experiment_tracker = Client().active_stack.experiment_tracker @step(experiment_tracker=experiment_tracker.name, enable_cache = False)Het runnen van de pijplijn
Update uw run_pipeline.py script als volgt:
from pipelines.training_pipeline import train_pipeline
from zenml.client import Client
if __name__ == '__main__': #printimg the experiment tracking uri print(Client().active_stack.experiment_tracker.get_tracking_uri()) #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Kopieer het en plak deze opdracht.
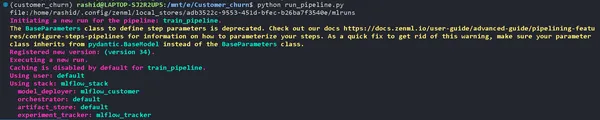
mlflow ui --backend-store-uri "--uri on the top of "file:/home/ "Ontdek uw experimenten
Klik op de link die door de bovenstaande opdracht is gegenereerd om de MLflow-gebruikersinterface te openen. Hier vindt u een schat aan inzichten:
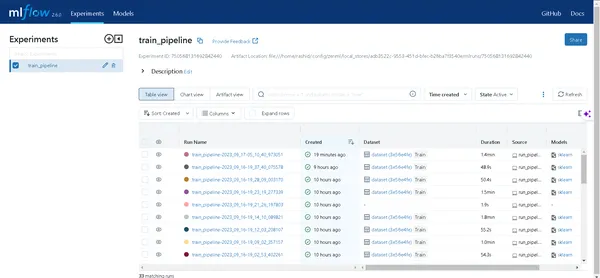
- Pijpleidingen: Gemakkelijk toegang tot alle pijpleidingen die u hebt uitgevoerd.
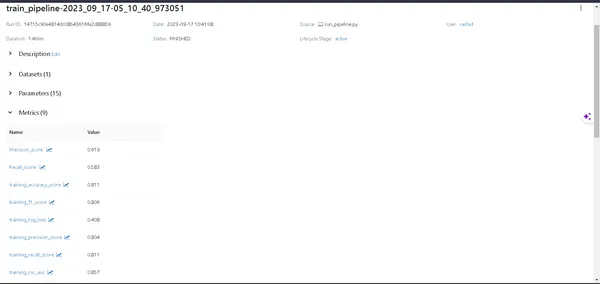
- Modeldetails: Klik op een pijplijn om elk detail van uw model te ontdekken.
- Metriek: duik in het gedeelte met statistieken om de prestaties van uw model te visualiseren.
Nu kunt u het volgen van uw machine learning-experimenten overwinnen met ZenML en MLflow!
Deployment
In de volgende sectie gaan we dit model implementeren. Je moet deze concepten kennen:
a). Pijplijn voor continue implementatie
Deze pijplijn automatiseert het modelimplementatieproces. Zodra een model aan de evaluatiecriteria voldoet, wordt het automatisch in een productieomgeving geïmplementeerd. Het begint bijvoorbeeld met het voorbewerken van gegevens, het opschonen van gegevens, het trainen van de gegevens, het evalueren van modellen, enz.
b). Implementatiepijplijn voor gevolgtrekkingen
De Inference Deployment Pipeline richt zich op het inzetten van machine learning-modellen voor realtime of batch-inferentie. De Inference Deployment Pipeline is gespecialiseerd in het inzetten van modellen voor het maken van voorspellingen in een productieomgeving. Het stelt bijvoorbeeld een API-eindpunt in waar gebruikers tekst kunnen verzenden. Het garandeert de beschikbaarheid en schaalbaarheid van het model en bewaakt de realtime prestaties ervan. Deze pijplijnen zijn belangrijk voor het behoud van de efficiëntie en effectiviteit van machine learning-systemen. Nu gaan we de continue pijplijn implementeren.
Maak een bestand met de naam deployment_pipeline.py in de map pijpleidingen.
import numpy as np
import json
import logging
import pandas as pd
from zenml import pipeline, step
from zenml.config import DockerSettings
from zenml.constants import DEFAULT_SERVICE_START_STOP_TIMEOUT
from zenml.integrations.constants import MLFLOW
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer,
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
from zenml.steps import BaseParameters, Output
from src.clean_data import FeatureEncoding
from .utils import get_data_for_test
from steps.data_cleaning import cleaning_data
from steps.evaluation import evaluate_model
from steps.ingest_data import ingest_df # Define Docker settings with MLflow integration
docker_settings = DockerSettings(required_integrations = {MLFLOW}) #Define class for deployment pipeline configuration
class DeploymentTriggerConfig(BaseParameters): min_accuracy:float = 0.92 @step def deployment_trigger( accuracy: float, config: DeploymentTriggerConfig,
): """ It trigger the deployment only if accuracy is greater than min accuracy. Args: accuracy: accuracy of the model. config: Minimum accuracy thereshold. """ try: return accuracy >= config.min_accuracy except Exception as e: logging.error("Error in deployment trigger",e) raise e # Define a continuous pipeline
@pipeline(enable_cache=False,settings={"docker":docker_settings})
def continuous_deployment_pipeline( data_path:str, min_accuracy:float = 0.92, workers: int = 1, timeout: int = DEFAULT_SERVICE_START_STOP_TIMEOUT
): df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df) model = train_model(X_train=X_train, y_train=y_train) accuracy_score, precision_score = evaluate_model(model=model, X_test=X_test, y_test=y_test) deployment_decision = deployment_trigger(accuracy=accuracy_score) mlflow_model_deployer_step( model=model, deploy_decision = deployment_decision, workers = workers, timeout = timeout )ZenML Framework voor Machine Learning-project
Deze code definieert een continue implementatie voor een machine learning-project met behulp van het ZenML Framework.
1. Importeer noodzakelijke bibliotheken: Importeren van de benodigde bibliotheken voor implementatie van het model.
2. Docker-instellingen: Door Docker-instellingen te configureren voor gebruik met MLflow, helpt Docker deze modellen consistent te verpakken en uit te voeren.
3. DeploymentTriggerConfig: Het is de klasse waarin de minimale nauwkeurigheidsdrempel wordt geconfigureerd voor de implementatie van een model.
4. implementatie_trigger: Deze stap keert terug als de modelnauwkeurigheid de minimale nauwkeurigheid overschrijdt.
5. continue_deployment_pipeline: Deze pijplijn bestaat uit verschillende stappen: gegevens opnemen, gegevens opschonen, het model trainen en het model evalueren. En het model zal alleen worden ingezet als het aan de minimale nauwkeurigheidsdrempel voldoet.
Vervolgens gaan we de inferentiepijplijn implementeren in deployment_pipeline.py
import logging
import pandas as pd
from zenml.steps import BaseParameters, Output
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import MLFlowModelDeployer
from zenml.integrations.mlflow.services import MLFlowDeploymentService class MLFlowDeploymentLoaderStepParameters(BaseParameters): pipeline_name: str step_name: str running: bool = True @step(enable_cache=False)
def dynamic_importer() -> str: data = get_data_for_test() return data @step(enable_cache=False)
def prediction_service_loader( pipeline_name: str, pipeline_step_name: str, running: bool = True, model_name: str = "model",
) -> MLFlowDeploymentService: model_deployer = MLFlowModelDeployer.get_active_model_deployer() existing_services = model_deployer.find_model_server( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, model_name=model_name, running=running, ) if not existing_services: raise RuntimeError( f"No MLflow prediction service deployed by the " f"{pipeline_step_name} step in the {pipeline_name} " f"pipeline for the '{model_name}' model is currently " f"running." ) return existing_services[0] @step
def predictor(service: MLFlowDeploymentService, data: str) -> np.ndarray: service.start(timeout=10) data = json.loads(data) prediction = service.predict(data) return prediction @pipeline(enable_cache=False, settings={"docker": docker_settings})
def inference_pipeline(pipeline_name: str, pipeline_step_name: str): batch_data = dynamic_importer() model_deployment_service = prediction_service_loader( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, running=False, ) prediction = predictor(service=model_deployment_service, data=batch_data) return prediction
Met deze code wordt een pijplijn opgezet voor het maken van voorspellingen met behulp van een geïmplementeerd machine learning-model via MLflow. Het importeert gegevens, laadt het geïmplementeerde model en gebruikt het om voorspellingen te doen.
We moeten de functie creëren get_data_for_test() in utils.py in de map pijpleidingen. Zo kunnen we onze code efficiënter beheren.
import logging import pandas as pd from src.clean_data import DataPreprocessing, LabelEncoding # Function to get data for testing purposes
def get_data_for_test(): try: df = pd.read_csv('./data/WA_Fn-UseC_-Telco-Customer-Churn.csv') df = df.sample(n=100) data_preprocessing = DataPreprocessing() data = data_preprocessing.handle_data(df) # Instantiate the FeatureEncoding strategy label_encode = LabelEncoding() df_encoded = label_encode.handle_data(data) df_encoded.drop(['Churn'],axis=1,inplace=True) logging.info(df_encoded.columns) result = df_encoded.to_json(orient="split") return result except Exception as e: logging.error("e") raise eLaten we nu de pijplijn implementeren die we hebben gemaakt om het model te implementeren en te voorspellen op basis van het geïmplementeerde model.
Maak de run_deployment.py bestand in projectmap:
import click # For handling command-line arguments
import logging from typing import cast
from rich import print # For console output formatting # Import pipelines for deployment and inference
from pipelines.deployment_pipeline import (
continuous_deployment_pipeline, inference_pipeline
)
# Import MLflow utilities and components
from zenml.integrations.mlflow.mlflow_utils import get_tracking_uri
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService # Define constants for different configurations: DEPLOY, PREDICT, DEPLOY_AND_PREDICT
DEPLOY = "deploy"
PREDICT = "predict"
DEPLOY_AND_PREDICT = "deploy_and_predict" # Define a main function that uses Click to handle command-line arguments
@click.command()
@click.option( "--config", "-c", type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]), default=DEPLOY_AND_PREDICT, help="Optionally you can choose to only run the deployment " "pipeline to train and deploy a model (`deploy`), or to " "only run a prediction against the deployed model " "(`predict`). By default both will be run " "(`deploy_and_predict`).",
)
@click.option( "--min-accuracy", default=0.92, help="Minimum accuracy required to deploy the model",
)
def run_main(config:str, min_accuracy:float ): # Get the active MLFlow model deployer component mlflow_model_deployer_component = MLFlowModelDeployer.get_active_model_deployer() # Determine if the user wants to deploy a model (deploy), make predictions (predict), or both (deploy_and_predict) deploy = config == DEPLOY or config == DEPLOY_AND_PREDICT predict = config == PREDICT or config == DEPLOY_AND_PREDICT # If deploying a model is requested: if deploy: continuous_deployment_pipeline( data_path='/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv', min_accuracy=min_accuracy, workers=3, timeout=60 ) # If making predictions is requested: if predict: # Initialize an inference pipeline run inference_pipeline( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", ) # Print instructions for viewing experiment runs in the MLflow UI print( "You can run:n " f"[italic green] mlflow ui --backend-store-uri '{get_tracking_uri()}" "[/italic green]n ...to inspect your experiment runs within the MLflow" " UI.nYou can find your runs tracked within the " "`mlflow_example_pipeline` experiment. There you'll also be able to " "compare two or more runs.nn" ) # Fetch existing services with the same pipeline name, step name, and model name existing_services = mlflow_model_deployer_component.find_model_server( pipeline_name = "continuous_deployment_pipeline", pipeline_step_name = "mlflow_model_deployer_step", ) # Check the status of the prediction server: if existing_services: service = cast(MLFlowDeploymentService, existing_services[0]) if service.is_running: print( f"The MLflow prediciton server is running locally as a daemon" f"process service and accepts inference requests at: n" f" {service.prediction_url}n" f"To stop the service, run" f"[italic green] zenml model-deployer models delete" f"{str(service.uuid)}'[/italic green]." ) elif service.is_failed: print( f"The MLflow prediciton server is in a failed state: n" f" Last state: '{service.status.state.value}'n" f" Last error: '{service.status.last_error}'" ) else: print( "No MLflow prediction server is currently running. The deployment" "pipeline must run first to train a model and deploy it. Execute" "the same command with the '--deploy' argument to deploy a model." ) # Entry point: If this script is executed directly, run the main function
if __name__ == "__main__": run_main()Deze code is een opdrachtregelscript voor het beheren en implementeren van het machine learning-model met behulp van MLFlow en ZenMl.
Laten we nu het model implementeren.
Voer deze opdracht uit op uw terminal.
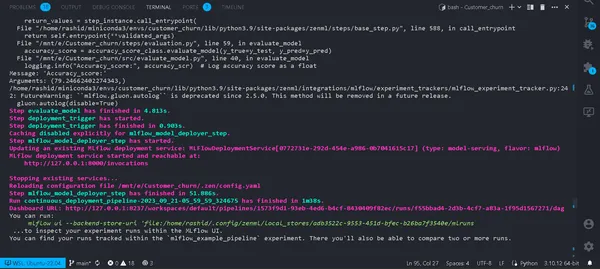
python run_deployment.py --config deploy
Nu hebben we ons model geïmplementeerd. Uw pijplijn wordt met succes uitgevoerd en u kunt deze bekijken in het zenml-dashboard.
python run_deployment.py --config predictHet initiëren van het voorspellingsproces
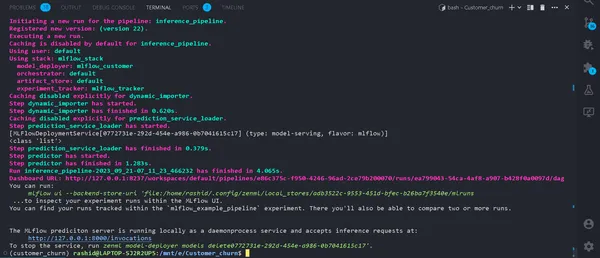
Nu draait onze MLFlow-voorspellingsserver.
We hebben een webapp nodig om de gegevens in te voeren en de resultaten te bekijken. Je vraagt je vast af waarom we een webapp helemaal opnieuw moeten maken.
Niet echt. We gaan Streamlit gebruiken, een open-source frontend-framework dat helpt bij het bouwen van snelle en gemakkelijke frontend-webapps voor ons machine learning-model.
Installeer de bibliotheek
pip install streamlitMaak een bestand met de naam streamlit_app.py in uw projectmap.
import json
import logging
import numpy as np
import pandas as pd
import streamlit as st
from PIL import Image
from pipelines.deployment_pipeline import prediction_service_loader
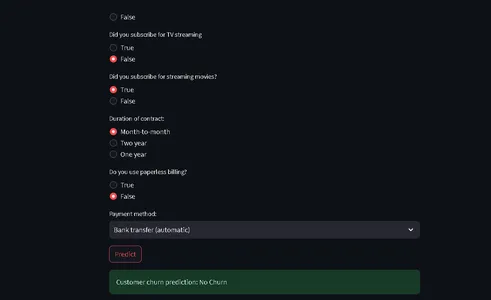
from run_deployment import main def main(): st.title("End to End Customer Satisfaction Pipeline with ZenML") st.markdown( """ #### Problem Statement The objective here is to predict the customer satisfaction score for a given order based on features like order status, price, payment, etc. I will be using [ZenML](https://zenml.io/) to build a production-ready pipeline to predict the customer satisfaction score for the next order or purchase. """ ) st.markdown( """ Above is a figure of the whole pipeline, we first ingest the data, clean it, train the model, and evaluate the model, and if data source changes or any hyperparameter values changes, deployment will be triggered, and (re) trains the model and if the model meets minimum accuracy requirement, the model will be deployed. """ ) st.markdown( """ #### Description of Features This app is designed to predict the customer satisfaction score for a given customer. You can input the features of the product listed below and get the customer satisfaction score. | Models | Description | | ------------- | - | | SeniorCitizen | Indicates whether the customer is a senior citizen. | | tenure | Number of months the customer has been with the company. | | MonthlyCharges | Monthly charges incurred by the customer. | | TotalCharges | Total charges incurred by the customer. | | gender | Gender of the customer (Male: 1, Female: 0). | | Partner | Whether the customer has a partner (Yes: 1, No: 0). | | Dependents | Whether the customer has dependents (Yes: 1, No: 0). | | PhoneService | Whether the customer has dependents (Yes: 1, No: 0). | | MultipleLines | Whether the customer has multiple lines (Yes: 1, No: 0). | | InternetService | Type of internet service (No: 1, Other: 0). | | OnlineSecurity | Whether the customer has online security service (Yes: 1, No: 0). | | OnlineBackup | Whether the customer has online backup service (Yes: 1, No: 0). | | DeviceProtection | Whether the customer has device protection service (Yes: 1, No: 0). | | TechSupport | Whether the customer has tech support service (Yes: 1, No: 0). | | StreamingTV | Whether the customer has streaming TV service (Yes: 1, No: 0). | | StreamingMovies | Whether the customer has streaming movies service (Yes: 1, No: 0). | | Contract | Type of contract (One year: 1, Other: 0). | | PaperlessBilling | Whether the customer has paperless billing (Yes: 1, No: 0). | | PaymentMethod | Payment method (Credit card: 1, Other: 0). | | Churn | Whether the customer has churned (Yes: 1, No: 0). | """ ) payment_options = { 2: "Electronic check", 3: "Mailed check", 1: "Bank transfer (automatic)", 0: "Credit card (automatic)" } contract = { 0: "Month-to-month", 2: "Two year", 1: "One year" } def format_func(PaymentMethod): return payment_options[PaymentMethod] def format_func_contract(Contract): return contract[Contract] display = ("male", "female") options = list(range(len(display))) # Define the data columns with their respective values SeniorCitizen = st.selectbox("Are you senior citizen?", options=[True, False],) tenure = st.number_input("Tenure") MonthlyCharges = st.number_input("Monthly Charges: ") TotalCharges = st.number_input("Total Charges: ") gender = st.radio("gender:", options, format_func=lambda x: display[x]) Partner = st.radio("Do you have a partner? ", options=[True, False]) Dependents = st.radio("Dependents: ", options=[True, False]) PhoneService = st.radio("Do you have phone service? : ", options=[True, False]) MultipleLines = st.radio("Do you Multiplines? ", options=[True, False]) InternetService = st.radio("Did you subscribe for Internet service? ", options=[True, False]) OnlineSecurity = st.radio("Did you subscribe for OnlineSecurity? ", options=[True, False]) OnlineBackup = st.radio("Did you subscribe for Online Backup service? ", options=[True, False]) DeviceProtection = st.radio("Did you subscribe for device protection only?", options=[True, False]) TechSupport =st.radio("Did you subscribe for tech support? ", options=[True, False]) StreamingTV = st.radio("Did you subscribe for TV streaming", options=[True, False]) StreamingMovies = st.radio("Did you subscribe for streaming movies? ", options=[True, False]) Contract = st.radio("Duration of contract: ", options=list(contract.keys()), format_func=format_func_contract) PaperlessBilling = st.radio("Do you use paperless billing? ", options=[True, False]) PaymentMethod = st.selectbox("Payment method:", options=list(payment_options.keys()), format_func=format_func) # You can use PaymentMethod to get the selected payment method's numeric value if st.button("Predict"): service = prediction_service_loader( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", running=False, ) if service is None: st.write( "No service could be found. The pipeline will be run first to create a service." ) run_main() try: data_point = { 'SeniorCitizen': int(SeniorCitizen), 'tenure': tenure, 'MonthlyCharges': MonthlyCharges, 'TotalCharges': TotalCharges, 'gender': int(gender), 'Partner': int(Partner), 'Dependents': int(Dependents), 'PhoneService': int(PhoneService), 'MultipleLines': int(MultipleLines), 'InternetService': int(InternetService), 'OnlineSecurity': int(OnlineSecurity), 'OnlineBackup': int(OnlineBackup), 'DeviceProtection': int(DeviceProtection), 'TechSupport': int(TechSupport), 'StreamingTV': int(StreamingTV), 'StreamingMovies': int(StreamingMovies), 'Contract': int(Contract), 'PaperlessBilling': int(PaperlessBilling), 'PaymentMethod': int(PaymentMethod) } # Convert the data point to a Series and then to a DataFrame data_point_series = pd.Series(data_point) data_point_df = pd.DataFrame(data_point_series).T # Convert the DataFrame to a JSON list json_list = json.loads(data_point_df.to_json(orient="records")) data = np.array(json_list) for i in range(len(data)): logging.info(data[i]) pred = service.predict(data) logging.info(pred) st.success(f"Customer churn prediction: {'Churn' if pred == 1 else 'No Churn'}") except Exception as e: logging.error(e) raise e if __name__ == "__main__": main()Deze code definieert een StreamLit die een frontend biedt voor het voorspellen van het klantverloop bij een telecombedrijf op basis van klantgegevens en demografische details.
Gebruikers kunnen hun informatie invoeren via een gebruiksvriendelijke interface, en de code maakt gebruik van een getraind machine learning-model (geïmplementeerd met ZenML en MLflow) om voorspellingen te doen.
Het voorspelde resultaat wordt vervolgens aan de gebruiker weergegeven.
Voer nu deze opdracht uit:
⚠️ zorg ervoor dat je voorspellingsmodel draait
streamlit run streamlit_app.pyKlik op de link.
Dat is het; we hebben ons project voltooid.

Dat is het; we hebben ons end-to-end machine learning-project, hoe professionals het hele proces benaderen, met succes afgerond.
Conclusie
In deze uitgebreide verkenning van machine learning-operaties (MLOps) door de ontwikkeling en implementatie van een voorspellingsmodel voor klantverloop, zijn we getuige geweest van de transformerende kracht van MLOps bij het stroomlijnen van de levenscyclus van machine learning. Van gegevensverzameling en voorverwerking tot modeltraining, evaluatie en implementatie: ons project toont de essentiële rol van MLOps bij het overbruggen van de kloof tussen ontwikkeling en productie. Nu organisaties steeds meer vertrouwen op datagestuurde besluitvorming, benadrukken de hier gedemonstreerde efficiënte en schaalbare praktijken het cruciale belang van MLOps bij het garanderen van het succes van machine learning-toepassingen.
Key Takeaways
- MLOps (Machine Learning Operations) is cruciaal voor het stroomlijnen van de end-to-end levenscyclus van machine learning, waardoor efficiënte, betrouwbare en schaalbare activiteiten worden gegarandeerd.
- ZenML en MLflow zijn krachtige raamwerken die de ontwikkeling, tracking en implementatie van machine learning-modellen in echte toepassingen vergemakkelijken.
- Een goede voorverwerking van gegevens, inclusief opschonen, coderen en splitsen, is van fundamenteel belang voor het bouwen van robuuste machine-learning-modellen.
- Evaluatiestatistieken zoals nauwkeurigheid, precisie, terugroepactie en F1-score bieden een uitgebreid inzicht in de modelprestaties.
- Tools voor het volgen van experimenten, zoals MLflow, verbeteren het samenwerkings- en experimentbeheer in datawetenschapsprojecten.
- Pijplijnen voor continue implementatie en gevolgtrekking zijn van cruciaal belang voor het behoud van de modelefficiëntie en beschikbaarheid in productieomgevingen.
Veelgestelde Vragen / FAQ
MLOPS betekent dat Machine Learning Operations een end-to-end levenscyclus van machine learning is, van ontwikkeling tot gegevensverzameling. Het is een reeks praktijken voor het ontwerpen en automatiseren van de gehele machine-leercyclus. Het omvat elke fase, van de ontwikkeling en training van machine learning-modellen tot de implementatie, monitoring en doorlopend onderhoud ervan. MLOps is van cruciaal belang omdat het de schaalbaarheid, betrouwbaarheid en efficiëntie van machine learning-toepassingen garandeert. Het helpt datawetenschappers robuuste machine-learning-applicaties te creëren die nauwkeurige voorspellingen opleveren.
MLOps en DevOps hebben vergelijkbare doelen: het stroomlijnen en automatiseren van processen binnen hun respectievelijke domeinen. DevOps richt zich primair op softwareontwikkeling, de softwareleveringspijplijn. Het heeft tot doel de softwareontwikkeling te versnellen, de codekwaliteit te verbeteren en de betrouwbaarheid van de implementatie te verbeteren. MLOps komt tegemoet aan de gespecialiseerde behoeften van machine learning-projecten, waardoor het een cruciale praktijk is om AI en datawetenschap te benutten.
Dit is een veel voorkomende fout waarmee u in het project te maken krijgt. Ren gewoon
'zenml naar beneden'
harte
'zenml ontkoppelen'
voer de pijpleiding opnieuw uit. Het zal worden opgelost.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/10/a-mlops-enhanced-customer-churn-prediction-project/

