Vandaag zijn we verheugd om aan te kondigen dat Code Llama-basismodellen, ontwikkeld door Meta, beschikbaar zijn voor klanten via Amazon SageMaker JumpStart te implementeren met één klik voor het uitvoeren van gevolgtrekkingen. Code Llama is een geavanceerd groottaalmodel (LLM) dat code en natuurlijke taal over code kan genereren op basis van zowel code- als natuurlijke taalprompts. Code Llama is gratis voor onderzoek en commercieel gebruik. U kunt dit model uitproberen met SageMaker JumpStart, een machine learning (ML)-hub die toegang biedt tot algoritmen, modellen en ML-oplossingen, zodat u snel aan de slag kunt met ML. In dit bericht bekijken we hoe u het Code Llama-model kunt ontdekken en implementeren via SageMaker JumpStart.
Wat is Code Lama
Code Llama is een model uitgebracht door meta dat bovenop Llama 2 is gebouwd en een geavanceerd model is dat is ontworpen om de productiviteit van programmeertaken voor ontwikkelaars te verbeteren door hen te helpen hoogwaardige, goed gedocumenteerde code te creëren. De modellen tonen state-of-the-art prestaties in Python, C++, Java, PHP, C#, TypeScript en Bash, en hebben het potentieel om ontwikkelaars tijd te besparen en softwareworkflows efficiënter te maken. Het wordt geleverd in drie varianten, ontworpen om een breed scala aan toepassingen te dekken: het basismodel (Code Llama), een gespecialiseerd Python-model (Code Llama-Python) en een instructievolgend model voor het begrijpen van instructies in natuurlijke taal (Code Llama-Instruct ). Alle Code Llama-varianten zijn verkrijgbaar in drie maten: 7B-, 13B- en 34B-parameters. De basis- en instructievarianten 7B en 13B ondersteunen het invullen op basis van omringende inhoud, waardoor ze ideaal zijn voor code-assistenttoepassingen.
De modellen zijn ontworpen met Llama 2 als basis en vervolgens getraind op 500 miljard tokens aan codegegevens, waarbij de gespecialiseerde Python-versie is getraind op incrementeel 100 miljard tokens. De Code Llama-modellen bieden stabiele generaties met maximaal 100,000 tokens aan context. Alle modellen zijn getraind op reeksen van 16,000 tokens en tonen verbeteringen bij invoer met maximaal 100,000 tokens.
Het model wordt onder dezelfde versie beschikbaar gesteld gemeenschapslicentie als Llama 2.
Wat is SageMaker JumpStart
Met SageMaker JumpStart kunnen ML-beoefenaars kiezen uit een groeiende lijst met best presterende basismodellen. ML-beoefenaars kunnen basismodellen inzetten voor specifieke toepassingen Amazon Sage Maker instances binnen een netwerkgeïsoleerde omgeving en pas modellen aan met SageMaker voor modeltraining en implementatie.
U kunt Code Llama-modellen nu met een paar klikken ontdekken en implementeren Amazon SageMaker Studio of programmatisch via de SageMaker Python SDK, zodat u modelprestaties en MLOps-besturingselementen kunt afleiden met SageMaker-functies zoals Amazon SageMaker-pijpleidingen, Amazon SageMaker-foutopsporingof containerlogboeken. Het model wordt geïmplementeerd in een AWS-beveiligde omgeving en onder uw VPC-controle, waardoor de gegevensbeveiliging wordt gewaarborgd. Code Llama-modellen zijn vindbaar en kunnen worden ingezet in de regio's VS-Oost (N. Virginia), VS-West (Oregon) en Europa (Ierland).
Klanten moeten de EULA accepteren om modelvisum SageMaker SDK te implementeren.
Ontdek modellen
U hebt toegang tot Code Llama-basismodellen via SageMaker JumpStart in de gebruikersinterface van SageMaker Studio en de SageMaker Python SDK. In deze sectie bespreken we hoe u de modellen in SageMaker Studio kunt ontdekken.
SageMaker Studio is een geïntegreerde ontwikkelomgeving (IDE) die een enkele webgebaseerde visuele interface biedt waar u toegang hebt tot speciaal gebouwde tools om alle ML-ontwikkelingsstappen uit te voeren, van het voorbereiden van gegevens tot het bouwen, trainen en implementeren van uw ML-modellen. Raadpleeg voor meer informatie over hoe u aan de slag kunt gaan en SageMaker Studio kunt instellen Amazon SageMaker Studio.
In SageMaker Studio heeft u toegang tot SageMaker JumpStart, dat vooraf getrainde modellen, notebooks en vooraf gebouwde oplossingen bevat onder Kant-en-klare en geautomatiseerde oplossingen.
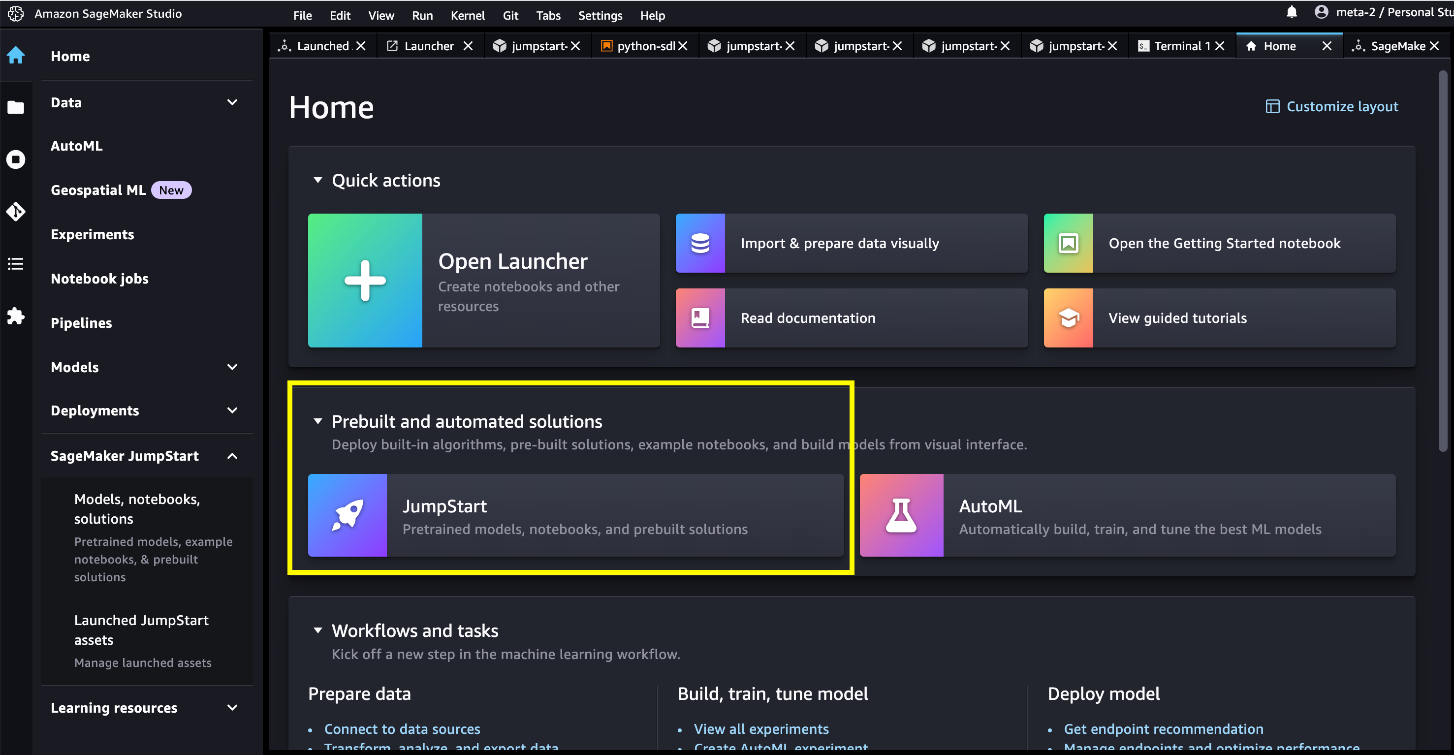
Op de startpagina van SageMaker JumpStart kunt u zoeken naar oplossingen, modellen, notebooks en andere bronnen. Je kunt Code Llama-modellen vinden in de Basismodellen: tekstgeneratie carrousel

Door te kiezen, kunt u ook andere modelvarianten vinden Ontdek alle modellen voor tekstgeneratie of zoeken naar Code Llama.

U kunt de modelkaart kiezen om details over het model te bekijken, zoals licentie, gegevens die zijn gebruikt om te trainen en hoe u deze moet gebruiken. U vindt ook twee knoppen, Implementeren en Notitieblok openen, waarmee u het model kunt gebruiken.
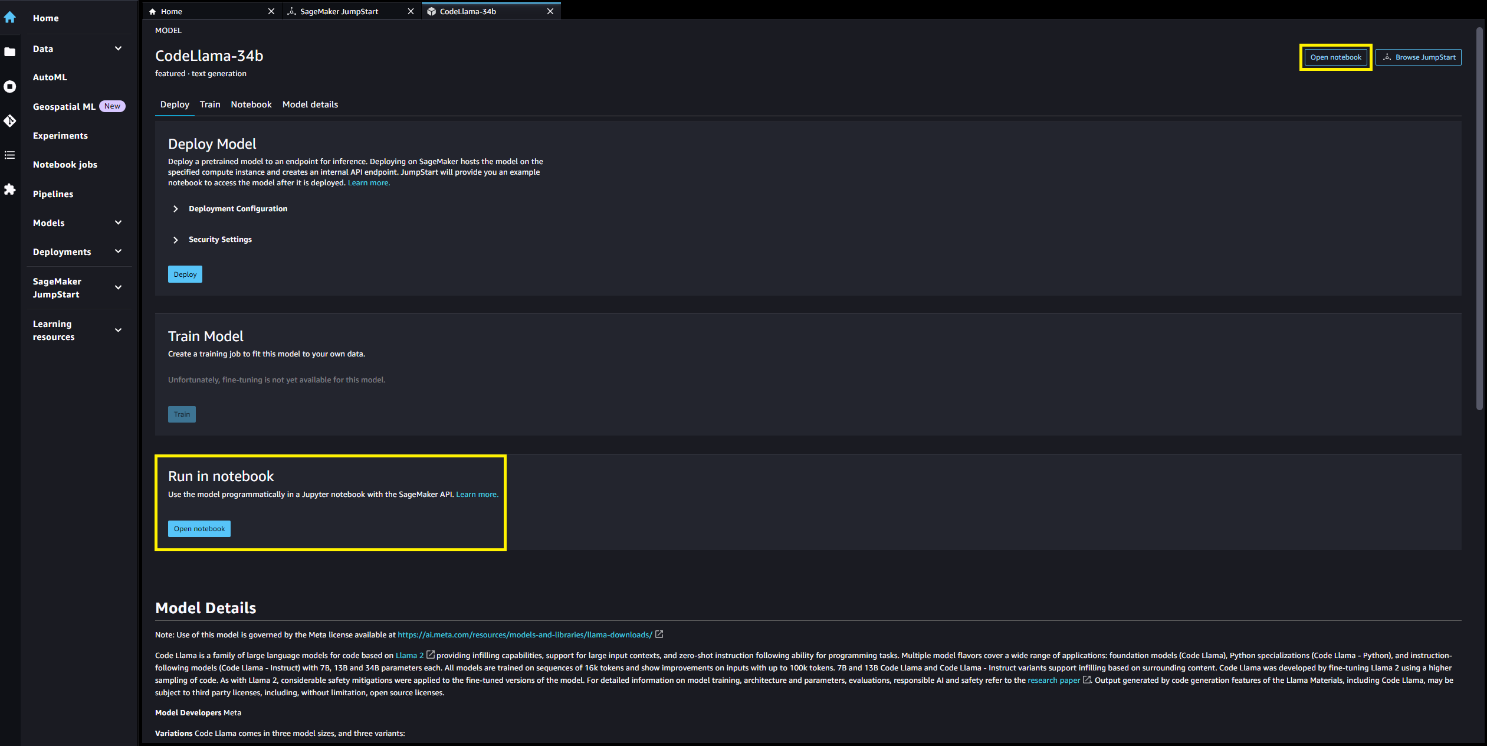
Implementeren
Wanneer je kiest Implementeren en accepteer de voorwaarden, de implementatie zal starten. U kunt ook via het voorbeeldnotebook implementeren door te kiezen Notitieblok openen. Het voorbeeldnotebook dat end-to-end richtlijnen biedt voor het implementeren van het model voor gevolgtrekking en het opschonen van bronnen.
Om te implementeren met behulp van een notebook, beginnen we met het selecteren van een geschikt model, gespecificeerd door de model_id. U kunt elk van de geselecteerde modellen op SageMaker implementeren met de volgende code:
Dit implementeert het model op SageMaker met standaardconfiguraties, inclusief standaard instantietype en standaard VPC-configuraties. U kunt deze configuraties wijzigen door niet-standaardwaarden op te geven in JumpStart-model. Nadat het is geïmplementeerd, kunt u deductie uitvoeren tegen het geïmplementeerde eindpunt via de SageMaker-voorspeller:
Merk op dat standaard accept_eula is ingesteld op false. Je moet instellen accept_eula=true om het eindpunt met succes aan te roepen. Door dit te doen, accepteert u de gebruikerslicentieovereenkomst en het beleid voor acceptabel gebruik zoals eerder vermeld. Je kan ook Download de licentieovereenkomst.
Custom_attributes gebruikt om de EULA door te geven zijn sleutel/waarde-paren. De sleutel en waarde worden gescheiden door = en paren worden gescheiden door ;. Als de gebruiker dezelfde sleutel meerdere keren doorgeeft, wordt de laatste waarde bewaard en doorgegeven aan de scripthandler (in dit geval gebruikt voor voorwaardelijke logica). Bijvoorbeeld als accept_eula=false; accept_eula=true wordt vervolgens doorgegeven aan de server accept_eula=true wordt bewaard en doorgegeven aan de scripthandler.
Inferentieparameters regelen het proces voor het genereren van tekst op het eindpunt. De maximale controle over nieuwe tokens verwijst naar de grootte van de uitvoer die door het model wordt gegenereerd. Merk op dat dit niet hetzelfde is als het aantal woorden, omdat het vocabulaire van het model niet hetzelfde is als het Engelse vocabulaire en elk token mogelijk geen Engelstalig woord is. Temperatuur regelt de willekeur in de uitvoer. Hogere temperaturen resulteren in meer creatieve en hallucinerende resultaten. Alle inferentieparameters zijn optioneel.
De volgende tabel bevat alle Code Llama-modellen die beschikbaar zijn in SageMaker JumpStart, samen met de model-ID's, standaardinstantietypen en de maximaal ondersteunde tokens (som van het aantal invoertokens en het aantal gegenereerde tokens voor alle gelijktijdige verzoeken) die worden ondersteund voor elk van deze modellen.
| Modelnaam | Model ID | Standaard instantietype | Maximaal ondersteunde tokens |
| CodeLlama-7b | meta-textgeneration-llama-codellama-7b | ml.g5.2xgroot | 10000 |
| CodeLlama-7b-Instrueer | meta-textgeneration-llama-codellama-7b-instruct | ml.g5.2xgroot | 10000 |
| CodeLlama-7b-Python | meta-textgeneration-llama-codellama-7b-python | ml.g5.2xgroot | 10000 |
| CodeLlama-13b | meta-textgeneration-llama-codellama-13b | ml.g5.12xgroot | 32000 |
| CodeLlama-13b-Instrueer | meta-textgeneration-llama-codellama-13b-instruct | ml.g5.12xgroot | 32000 |
| CodeLlama-13b-Python | meta-textgeneration-llama-codellama-13b-python | ml.g5.12xgroot | 32000 |
| CodeLlama-34b | meta-textgeneration-llama-codellama-34b | ml.g5.48xgroot | 48000 |
| CodeLlama-34b-Instrueer | meta-textgeneration-llama-codellama-34b-instruct | ml.g5.48xgroot | 48000 |
| CodeLlama-34b-Python | meta-textgeneration-llama-codellama-34b-python | ml.g5.48xgroot | 48000 |
Terwijl de Code Llama-modellen werden getraind op een contextlengte van 16,000 tokens, rapporteerden de modellen goede prestaties op nog grotere contextvensters. De kolom met maximaal ondersteunde tokens in de voorgaande tabel is de bovengrens van het ondersteunde contextvenster op het standaardinstantietype. Omdat het Code Llama 7B-model slechts 10,000 tokens op een ml.g5.2xlarge-instantie kan ondersteunen, raden we u aan een 13B- of 34B-modelversie te implementeren als grotere contexten vereist zijn voor uw toepassing.
Standaard werken alle modellen voor taken voor het genereren van code. Het basis- en instructiemodel reageren beide op invultaken, hoewel het basismodel voor de meeste voorbeeldquery's een betere uitvoerkwaliteit had. Ten slotte werken alleen instructiemodellen aan instructietaken. In de volgende tabel ziet u welke modellen goede prestaties (goed) en matige prestaties (matig) hadden bij voorbeeldquery's in de demonotebooks.
| . | Code genereren | Code-invulling | Codeer instructies |
| CodeLlama-7b | Goed | Goed | NB |
| CodeLlama-7b-Instrueer | Goed | Matig | Goed |
| CodeLlama-7b-Python | Goed | NB | NB |
| CodeLlama-13b | Goed | Goed | NB |
| CodeLlama-13b-Instrueer | Goed | Matig | Goed |
| CodeLlama-13b-Python | Goed | NB | NB |
| CodeLlama-34b | Goed | NB | NB |
| CodeLlama-34b-Instrueer | Goed | NB | Goed |
| CodeLlama-34b-Python | Goed | NB | NB |
Codegeneratie
De volgende voorbeelden zijn uitgevoerd op het CodeLlama-34b-Instruct-model met payload-parameters "parameters": {"max_new_tokens": 256, "temperature": 0.2, "top_p": 0.9}:
Code-invulling
Code-invulling houdt in dat de gegenereerde code wordt geretourneerd, gegeven de omringende context. Dit verschilt van de codegeneratietaak omdat het model naast een prefix-codesegment ook wordt voorzien van een codesegment-suffix. Tijdens het afstemmen werden speciale tokens gebruikt om het begin van het voorvoegsel te markeren (<PRE>), het begin van het achtervoegsel (<SUF>), en het begin van het midden (<MID>). Invoerreeksen voor het model moeten een van de volgende formaten hebben:
- voorvoegsel-achtervoegsel-midden -
<PRE> {prefix} <SUF>{suffix} <MID> - achtervoegsel-voorvoegsel-midden -
<PRE> <SUF>{suffix} <MID> {prefix}
De volgende voorbeelden gebruiken de indeling voorvoegsel-achtervoegsel-midden op het CodeLlama-7b-model met payload parameters {"max_new_tokens": 256, "temperature": 0.05, "top_p": 0.9}:
Codeer instructies
Meta leverde ook een instructie-afgestemde variant van Code Llama. Voorbeeldquery's in deze sectie kunnen alleen worden toegepast op deze op instructies afgestemde Code Llama-modellen. Dit zijn de modellen met een model-ID-instructieachtervoegsel. Het Code Llama-formaat voor instructies is hetzelfde als het Llama-2-chat-promptformaat, dat we gedetailleerd beschrijven in Llama 2-basismodellen zijn nu beschikbaar in SageMaker JumpStart
Een eenvoudige gebruikersprompt kan er als volgt uitzien:
U kunt ook een systeemprompt toevoegen met de volgende syntaxis:
Ten slotte kunt u een conversatie-interactie met het model voeren door alle eerdere gebruikersprompts en assistent-reacties in de invoer op te nemen:
Deze voorbeelden zijn uitgevoerd op het CodeLlama-13b-Instruct-model met payload-parameters “parameters”: {"max_new_tokens": 512, "temperature": 0.2, "top_p": 0.9}:
Opruimen
Nadat u klaar bent met het uitvoeren van de notebook, moet u ervoor zorgen dat u alle bronnen verwijdert die u tijdens het proces hebt gemaakt, zodat de facturering wordt stopgezet. Gebruik de volgende code:
Conclusie
In dit bericht hebben we u laten zien hoe u aan de slag kunt gaan met Code Llama-modellen in SageMaker Studio en hoe u het model kunt implementeren voor het genereren van code en natuurlijke taal over code op basis van zowel code- als natuurlijke taalprompts. Omdat basismodellen vooraf zijn getraind, kunnen ze de training- en infrastructuurkosten helpen verlagen en maatwerk voor uw gebruiksscenario mogelijk maken. Bezoek nu SageMaker JumpStart in SageMaker Studio om aan de slag te gaan.
Resources
Over de auteurs
 Gabriël Synnaeve is onderzoeksdirecteur bij het Facebook AI Research (FAIR)-team van Meta. Voordat hij bij Meta kwam, was Gabriel een postdoctoraal onderzoeker in het team van Emmanuel Dupoux aan de École Normale Supérieure in Parijs, waar hij werkte aan reverse-engineering van de taalverwerving bij baby's. Gabriel behaalde zijn doctoraat in Bayesiaanse modellering toegepast op real-time strategiespellen AI aan de Universiteit van Grenoble.
Gabriël Synnaeve is onderzoeksdirecteur bij het Facebook AI Research (FAIR)-team van Meta. Voordat hij bij Meta kwam, was Gabriel een postdoctoraal onderzoeker in het team van Emmanuel Dupoux aan de École Normale Supérieure in Parijs, waar hij werkte aan reverse-engineering van de taalverwerving bij baby's. Gabriel behaalde zijn doctoraat in Bayesiaanse modellering toegepast op real-time strategiespellen AI aan de Universiteit van Grenoble.
 Eissa Jamil is een Partner Engineer RL, Generatieve AI bij Meta.
Eissa Jamil is een Partner Engineer RL, Generatieve AI bij Meta.
 Dr Kyle Ulrich is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
Dr Kyle Ulrich is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
 Dr Ashish Khetan is een Senior Applied Scientist bij Amazon SageMaker JumpStart en helpt bij het ontwikkelen van machine learning-algoritmen. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
Dr Ashish Khetan is een Senior Applied Scientist bij Amazon SageMaker JumpStart en helpt bij het ontwikkelen van machine learning-algoritmen. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
 Vivek Singh is productmanager bij SageMaker JumpStart. Hij richt zich erop klanten in staat te stellen SageMaker JumpStart te gebruiken om hun ML-traject te vereenvoudigen en te versnellen om generatieve AI-applicaties te bouwen.
Vivek Singh is productmanager bij SageMaker JumpStart. Hij richt zich erop klanten in staat te stellen SageMaker JumpStart te gebruiken om hun ML-traject te vereenvoudigen en te versnellen om generatieve AI-applicaties te bouwen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/code-llama-code-generation-models-from-meta-are-now-available-via-amazon-sagemaker-jumpstart/

