Het ontsluiten van nauwkeurige en inzichtelijke antwoorden uit grote hoeveelheden tekst is een opwindende mogelijkheid die mogelijk wordt gemaakt door grote taalmodellen (LLM's). Bij het bouwen van LLM-applicaties is het vaak nodig om externe gegevensbronnen te verbinden en te bevragen om relevante context aan het model te bieden. Een populaire aanpak is het gebruik van Retrieval Augmented Generation (RAG) om vraag- en antwoordsystemen te creëren die complexe informatie begrijpen en natuurlijke antwoorden op vragen bieden. Met RAG kunnen modellen gebruikmaken van enorme kennisbanken en mensachtige dialogen leveren voor toepassingen zoals chatbots en zoekassistenten voor bedrijven.
In dit bericht onderzoeken we hoe we de kracht van kunnen benutten LamaIndex, Lama 2-70B-Chat en LangChain om krachtige vraag- en antwoordapplicaties te bouwen. Met deze geavanceerde technologieën kunt u tekstcorpora opnemen, kritische kennis indexeren en tekst genereren die de vragen van gebruikers nauwkeurig en duidelijk beantwoordt.
Lama 2-70B-Chat
Llama 2-70B-Chat is een krachtige LLM die concurreert met toonaangevende modellen. Het is vooraf getraind op twee biljoen teksttokens en is door Meta bedoeld om te worden gebruikt voor chathulp aan gebruikers. Gegevens vóór de training zijn afkomstig van openbaar beschikbare gegevens en zijn afgesloten vanaf september 2022, en de gegevens voor het verfijnen van de training zijn afkomstig uit juli 2023. Voor meer details over het trainingsproces van het model, veiligheidsoverwegingen, lessen en beoogde toepassingen, raadpleegt u het artikel Llama 2: Open Foundation en verfijnde chatmodellen. Llama 2-modellen zijn beschikbaar op Amazon SageMaker JumpStart voor een snelle en eenvoudige implementatie.
LamaIndex
LamaIndex is een dataframework waarmee LLM-applicaties kunnen worden gebouwd. Het biedt tools die dataconnectoren bieden om uw bestaande gegevens op te nemen met verschillende bronnen en formaten (PDF's, documenten, API's, SQL en meer). Of u nu gegevens hebt opgeslagen in databases of in PDF's, LlamaIndex maakt het eenvoudig om die gegevens in gebruik te nemen voor LLM's. Zoals we in dit bericht laten zien, maken LlamaIndex API's gegevenstoegang moeiteloos en kunt u krachtige aangepaste LLM-applicaties en workflows creëren.
Als u experimenteert en bouwt met LLM's, bent u waarschijnlijk bekend met LangChain, dat een robuust raamwerk biedt dat de ontwikkeling en implementatie van door LLM aangedreven applicaties vereenvoudigt. Net als LangChain biedt LlamaIndex een aantal tools, waaronder dataconnectors, data-indexen, motoren en data-agents, evenals applicatie-integraties zoals tools en waarneembaarheid, tracering en evaluatie. LlamaIndex richt zich op het overbruggen van de kloof tussen de gegevens en krachtige LLM's, door gegevenstaken te stroomlijnen met gebruiksvriendelijke functies. LlamaIndex is specifiek ontworpen en geoptimaliseerd voor het bouwen van zoek- en ophaaltoepassingen, zoals RAG, omdat het een eenvoudige interface biedt voor het opvragen van LLM's en het ophalen van relevante documenten.
Overzicht oplossingen
In dit bericht laten we zien hoe u een op RAG gebaseerde applicatie kunt maken met behulp van LlamaIndex en een LLM. Het volgende diagram toont de stapsgewijze architectuur van deze oplossing, zoals beschreven in de volgende secties.
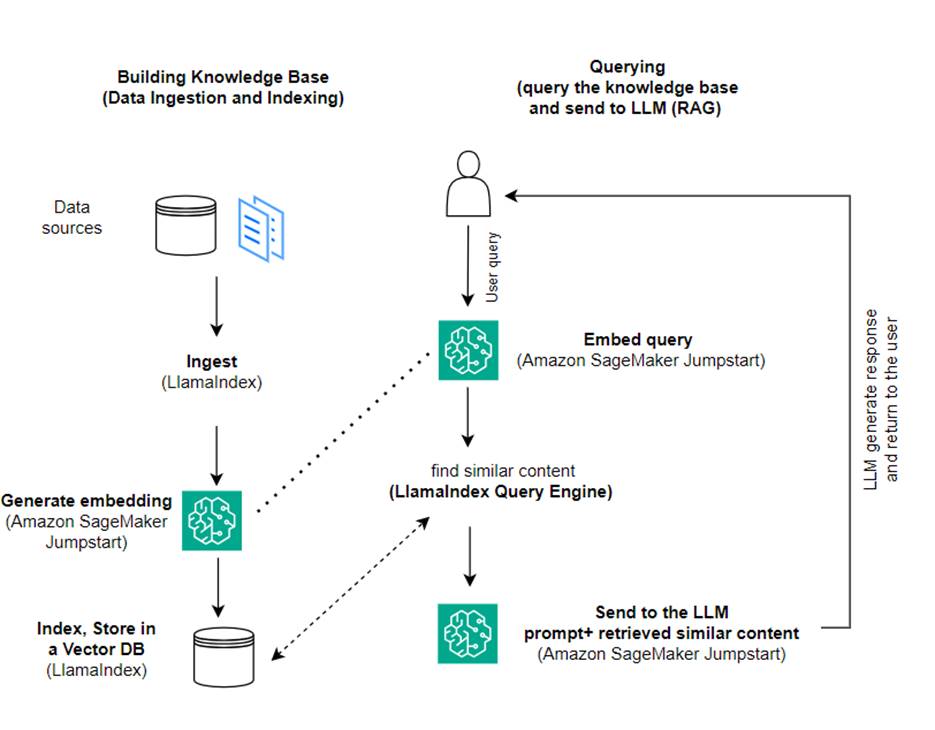
RAG combineert het ophalen van informatie met het genereren van natuurlijke taal om meer inzichtelijke reacties te produceren. Wanneer daarom wordt gevraagd, doorzoekt RAG eerst tekstcorpora om de meest relevante voorbeelden voor de invoer op te halen. Tijdens het genereren van antwoorden houdt het model rekening met deze voorbeelden om zijn mogelijkheden te vergroten. Door relevante gevonden passages op te nemen, zijn RAG-reacties feitelijker, coherenter en consistenter met de context vergeleken met generatieve basismodellen. Dit raamwerk voor ophalen en genereren maakt gebruik van de sterke punten van zowel ophalen als genereren, en helpt problemen als herhaling en gebrek aan context aan te pakken die kunnen voortkomen uit pure autoregressieve gespreksmodellen. RAG introduceert een effectieve aanpak voor het bouwen van gespreksagenten en AI-assistenten met gecontextualiseerde, hoogwaardige antwoorden.
Het bouwen van de oplossing bestaat uit de volgende stappen:
- Instellen Amazon SageMaker Studio als de ontwikkelomgeving en installeer de vereiste afhankelijkheden.
- Implementeer een insluitingsmodel vanuit de Amazon SageMaker JumpStart-hub.
- Download persberichten om te gebruiken als onze externe kennisbank.
- Bouw een index op van de persberichten om deze te kunnen opvragen en als extra context aan de prompt toe te voegen.
- Query's uitvoeren in de kennisbank.
- Bouw een vraag- en antwoordtoepassing met behulp van LlamaIndex- en LangChain-agents.
Alle code in dit bericht is beschikbaar in de GitHub repo.
Voorwaarden
Voor dit voorbeeld heeft u een AWS-account nodig met een SageMaker-domein en passend AWS Identiteits- en toegangsbeheer (IAM)-machtigingen. Voor instructies voor het instellen van een account, zie Maak een AWS-account aan. Als u nog geen SageMaker-domein heeft, raadpleegt u Amazon SageMaker-domein overzicht om er een te maken. In dit bericht gebruiken we de AmazonSageMakerFullAccess rol. Het wordt niet aanbevolen om deze referentie in een productieomgeving te gebruiken. In plaats daarvan moet u een rol maken en gebruiken met machtigingen met de minste bevoegdheden. Je kunt ook onderzoeken hoe je het kunt gebruiken Amazon SageMaker-rolmanager om op persona gebaseerde IAM-rollen voor algemene machine learning-behoeften rechtstreeks via de SageMaker-console te bouwen en te beheren.
Bovendien hebt u toegang nodig tot minimaal de volgende exemplaargroottes:
- ml.g5.2xgroot voor eindpuntgebruik bij het implementeren van de Knuffelend gezicht GPT-J tekstinsluitingsmodel
- ml.g5.48xgroot voor eindpuntgebruik bij de implementatie van het Llama 2-Chat-modeleindpunt
Om uw quotum te verhogen, raadpleegt u Verzoek om een verhoging van het quotum.
Implementeer een GPT-J-inbeddingsmodel met SageMaker JumpStart
In deze sectie vindt u twee opties bij het implementeren van SageMaker JumpStart-modellen. U kunt een op code gebaseerde implementatie gebruiken met behulp van de meegeleverde code, of de SageMaker JumpStart-gebruikersinterface (UI) gebruiken.
Implementeer met de SageMaker Python SDK
U kunt de SageMaker Python SDK gebruiken om de LLM's te implementeren, zoals weergegeven in de code beschikbaar in de repository. Voer de volgende stappen uit:
- Stel de instantiegrootte in die moet worden gebruikt voor de implementatie van het embeddingsmodel met behulp van
instance_type = "ml.g5.2xlarge" - Zoek de ID die het model moet gebruiken voor insluitingen. In SageMaker JumpStart wordt dit geïdentificeerd als
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Haal de vooraf getrainde modelcontainer op en implementeer deze voor gevolgtrekking.
SageMaker retourneert de naam van het modeleindpunt en het volgende bericht wanneer het insluitingsmodel met succes is geïmplementeerd:
Implementeer met SageMaker JumpStart in SageMaker Studio
Voer de volgende stappen uit om het model te implementeren met SageMaker JumpStart in Studio:
- Kies op de SageMaker Studio-console JumpStart in het navigatievenster.

- Zoek en kies het GPT-J 6B Embedding FP16-model.
- Kies Implementeren en pas de implementatieconfiguratie aan.

- Voor dit voorbeeld hebben we een ml.g5.2xlarge-instantie nodig, de standaardinstantie die wordt voorgesteld door SageMaker JumpStart.
- Kies nogmaals Implementeren om het eindpunt te maken.
Het duurt ongeveer 5 tot 10 minuten voordat het eindpunt in gebruik is.

Nadat u het insluitingsmodel hebt geïmplementeerd, moet u, om de LangChain-integratie met SageMaker API's te gebruiken, een functie maken om invoer (onbewerkte tekst) te verwerken en deze met behulp van het model om te zetten in insluitingen. Dit doe je door een klasse aan te maken met de naam ContentHandler, dat een JSON aan invoergegevens nodig heeft en een JSON aan tekstinsluitingen retourneert: class ContentHandler(EmbeddingsContentHandler).
Geef de naam van het modeleindpunt door aan de ContentHandler functie om de tekst te converteren en insluitingen te retourneren:
U kunt de naam van het eindpunt vinden in de uitvoer van de SDK of in de implementatiedetails in de gebruikersinterface van SageMaker JumpStart.
Je kunt testen of de ContentHandler functie en eindpunt werken zoals verwacht door wat onbewerkte tekst in te voeren en de embeddings.embed_query(text) functie. U kunt het gegeven voorbeeld gebruiken text = "Hi! It's time for the beach" of probeer je eigen tekst.
Implementeer en test Llama 2-Chat met SageMaker JumpStart
Nu kunt u het model implementeren dat interactieve gesprekken met uw gebruikers kan voeren. In dit geval kiezen we voor een van de Llama 2-chat-modellen, die wordt geïdentificeerd via
Het model moet worden geïmplementeerd op een realtime eindpunt met behulp van predictor = my_model.deploy(). SageMaker retourneert de eindpuntnaam van het model, die u kunt gebruiken voor de endpoint_name variabele om later naar te verwijzen.
Je definieert een print_dialogue functie om invoer naar het chatmodel te verzenden en het uitvoerantwoord te ontvangen. De payload bevat hyperparameters voor het model, waaronder het volgende:
- max_nieuwe_tokens – Verwijst naar het maximale aantal tokens dat het model in zijn uitvoer kan genereren.
- top_p – Verwijst naar de cumulatieve waarschijnlijkheid van de tokens die door het model kunnen worden behouden bij het genereren van de outputs
- temperatuur- – Verwijst naar de willekeur van de outputs die door het model worden gegenereerd. Een temperatuur groter dan 0 of gelijk aan 1 verhoogt het niveau van willekeur, terwijl een temperatuur van 0 de meest waarschijnlijke tokens zal genereren.
U moet uw hyperparameters selecteren op basis van uw gebruiksscenario en deze op de juiste manier testen. Bij modellen zoals de Llama-familie moet u een extra parameter opnemen die aangeeft dat u de licentieovereenkomst voor eindgebruikers (EULA) hebt gelezen en geaccepteerd:
Om het model te testen, vervangt u de inhoudssectie van de invoerpayload: "content": "what is the recipe of mayonnaise?". U kunt uw eigen tekstwaarden gebruiken en de hyperparameters bijwerken om ze beter te begrijpen.
Vergelijkbaar met de implementatie van het inbeddingsmodel, kunt u Llama-70B-Chat implementeren met behulp van de SageMaker JumpStart UI:
- Kies op de SageMaker Studio-console snelle start in het navigatievenster
- Zoek en kies de
Llama-2-70b-Chat model - Accepteer de EULA en kies Implementeren, waarbij opnieuw de standaardinstantie wordt gebruikt
Net als bij het inbeddingsmodel kunt u LangChain-integratie gebruiken door een contenthandler-sjabloon te maken voor de invoer en uitvoer van uw chatmodel. In dit geval definieert u de invoer als afkomstig van een gebruiker, en geeft u aan dat deze wordt beheerd door de system prompt. De system prompt informeert het model over zijn rol bij het assisteren van de gebruiker voor een bepaalde gebruikssituatie.
Deze inhoudshandler wordt vervolgens doorgegeven bij het aanroepen van het model, naast de bovengenoemde hyperparameters en aangepaste attributen (EULA-acceptatie). U parseert al deze kenmerken met behulp van de volgende code:
Wanneer het eindpunt beschikbaar is, kunt u testen of het werkt zoals verwacht. Je kunt updaten llm("what is amazon sagemaker?") met uw eigen tekst. Je moet ook het specifieke definiëren ContentHandler om de LLM aan te roepen met LangChain, zoals weergegeven in de code en het volgende codefragment:
Gebruik LlamaIndex om de RAG te bouwen
Om door te gaan, installeert u LlamaIndex om de RAG-applicatie te maken. Je kunt LlamaIndex installeren met behulp van de pip: pip install llama_index
U moet eerst uw gegevens (kennisbank) in LlamaIndex laden voor indexering. Dit omvat een aantal stappen:
- Kies een datalader:
LlamaIndex biedt een aantal dataconnectoren beschikbaar op LamaHub voor algemene gegevenstypen zoals JSON, CSV en tekstbestanden, maar ook voor andere gegevensbronnen, zodat u een verscheidenheid aan gegevenssets kunt opnemen. In dit bericht gebruiken we SimpleDirectoryReader om een paar PDF-bestanden op te nemen, zoals weergegeven in de code. Ons gegevensvoorbeeld bestaat uit twee Amazon-persberichten in PDF-versie in de persberichten map in onze coderepository. Nadat u de PDF's heeft geladen, kunt u zien dat ze zijn geconverteerd naar een lijst met 11 elementen.
In plaats van de documenten direct te laden, kunt u de Document bezwaar in Node objecten voordat u ze naar de index verzendt. De keuze tussen het versturen van het geheel Document bezwaar maken tegen de index of het document converteren naar Node objecten vóór indexering hangt af van uw specifieke gebruiksscenario en de structuur van uw gegevens. De knooppuntenbenadering is over het algemeen een goede keuze voor lange documenten, waarbij u specifieke delen van een document wilt opsplitsen en ophalen in plaats van het hele document. Voor meer informatie, zie Documenten / Knooppunten.
- Start de lader en laad de documenten:
Met deze stap initialiseert u de loader-klasse en eventuele benodigde configuraties, bijvoorbeeld of verborgen bestanden moeten worden genegeerd. Voor meer details, zie SimpleDirectoryReader.
- Bel de lader
load_datamethode om uw bronbestanden en gegevens te parseren en deze om te zetten in LlamaIndex Document-objecten, klaar voor indexering en bevraging. U kunt de volgende code gebruiken om de gegevensopname en voorbereiding voor zoeken in de volledige tekst te voltooien met behulp van de indexerings- en ophaalmogelijkheden van LlamaIndex:
- Bouw de index:
Het belangrijkste kenmerk van LlamaIndex is het vermogen om georganiseerde indexen te construeren over gegevens, die worden weergegeven als documenten of knooppunten. De indexering maakt een efficiënte bevraging van de gegevens mogelijk. We maken onze index met de standaard vectoropslag in het geheugen en met onze gedefinieerde instellingsconfiguratie. De LamaIndex Instellingen is een configuratieobject dat veelgebruikte bronnen en instellingen biedt voor indexerings- en querybewerkingen in een LlamaIndex-toepassing. Het fungeert als een singleton-object, zodat u globale configuraties kunt instellen, terwijl u ook specifieke componenten lokaal kunt overschrijven door ze rechtstreeks door te geven aan de interfaces (zoals LLM's, inbeddingsmodellen) die ze gebruiken. Wanneer een bepaald onderdeel niet expliciet wordt aangeboden, valt het LlamaIndex-framework terug naar de instellingen die zijn gedefinieerd in het Settings object als globale standaard. Om onze inbeddings- en LLM-modellen met LangChain te gebruiken en de Settings we moeten installeren llama_index.embeddings.langchain en llama_index.llms.langchain. Wij kunnen de Settings object zoals in de volgende code:
Standaard VectorStoreIndex maakt gebruik van een in-memory SimpleVectorStore die wordt geïnitialiseerd als onderdeel van de standaardopslagcontext. In praktijksituaties moet u vaak verbinding maken met externe vectorwinkels, zoals Amazon OpenSearch-service. Voor meer details, zie: Vector-engine voor Amazon OpenSearch serverloos.
Nu kunt u vragen en antwoorden over uw documenten uitvoeren met behulp van de query_engine van LamaIndex. Geef hiervoor de index door die u eerder voor zoekopdrachten hebt gemaakt en stel uw vraag. De query-engine is een generieke interface voor het opvragen van gegevens. Het neemt een zoekopdracht in natuurlijke taal als invoer en retourneert een rijk antwoord. De query-engine is doorgaans bovenop een of meer gebouwd indexen gebruik retriever.
U kunt zien dat de RAG-oplossing het juiste antwoord kan achterhalen uit de aangeleverde documenten:
Gebruik LangChain-tools en -agents
Loader klas. De lader is ontworpen om gegevens in LlamaIndex te laden of vervolgens als hulpmiddel in een LangChain-agent. Dit geeft u meer kracht en flexibiliteit om dit te gebruiken als onderdeel van uw toepassing. Je begint met het definiëren van jouw tools uit de LangChain-agentklasse. De functie die u aan uw tool doorgeeft, vraagt de index op die u over uw documenten hebt opgebouwd met behulp van LlamaIndex.
Vervolgens selecteert u het juiste type agent dat u wilt gebruiken voor uw RAG-implementatie. In dit geval gebruik je de chat-zero-shot-react-description tussenpersoon. Met deze agent zal de LLM de beschikbare tool gebruiken (in dit scenario de RAG via de kennisbank) om het antwoord te bieden. Vervolgens initialiseert u de agent door uw tool, LLM en agenttype door te geven:
Je ziet de agent doorlopen thoughts, actions en observation , gebruik de tool (in dit scenario vraagt u uw geïndexeerde documenten op); en retourneer een resultaat:
De end-to-end implementatiecode vindt u in het bijgevoegde document GitHub repo.
Opruimen
Om onnodige kosten te voorkomen, kunt u uw bronnen opschonen via de volgende codefragmenten of via de Amazon JumpStart-gebruikersinterface.
Als u de Boto3 SDK wilt gebruiken, gebruikt u de volgende code om het eindpunt van het tekstinsluitingsmodel en het eindpunt van het tekstgeneratiemodel, evenals de eindpuntconfiguraties, te verwijderen:
Voer de volgende stappen uit om de SageMaker-console te gebruiken:
- Kies op de SageMaker-console onder Inferentie in het navigatievenster Eindpunten
- Zoek naar de eindpunten voor het insluiten en genereren van tekst.
- Kies Verwijderen op de pagina met eindpuntdetails.
- Kies nogmaals Verwijderen om te bevestigen.
Conclusie
Voor gebruiksscenario's gericht op zoeken en ophalen biedt LlamaIndex flexibele mogelijkheden. Het blinkt uit in het indexeren en ophalen van LLM's, waardoor het een krachtig hulpmiddel is voor diepgaande verkenning van gegevens. Met LlamaIndex kunt u georganiseerde gegevensindexen maken, diverse LLM's gebruiken, gegevens uitbreiden voor betere LLM-prestaties en gegevens opvragen met natuurlijke taal.
Dit bericht demonstreerde enkele belangrijke LlamaIndex-concepten en -mogelijkheden. We gebruikten GPT-J voor het insluiten en Llama 2-Chat als LLM om een RAG-applicatie te bouwen, maar je zou in plaats daarvan elk geschikt model kunnen gebruiken. U kunt het uitgebreide assortiment modellen verkennen dat beschikbaar is op SageMaker JumpStart.
We hebben ook laten zien hoe LlamaIndex krachtige, flexibele tools kan bieden voor het verbinden, indexeren, ophalen en integreren van gegevens met andere raamwerken zoals LangChain. Met LlamaIndex-integraties en LangChain kunt u krachtigere, veelzijdige en inzichtelijke LLM-applicaties bouwen.
Over de auteurs
 Dr. Romina Sharifpour is een Senior Machine Learning en Artificial Intelligence Solutions Architect bij Amazon Web Services (AWS). Ze heeft ruim tien jaar leiding gegeven aan het ontwerp en de implementatie van innovatieve end-to-end-oplossingen, mogelijk gemaakt door de vooruitgang op het gebied van ML en AI. Romina's interessegebieden zijn natuurlijke taalverwerking, grote taalmodellen en MLOps.
Dr. Romina Sharifpour is een Senior Machine Learning en Artificial Intelligence Solutions Architect bij Amazon Web Services (AWS). Ze heeft ruim tien jaar leiding gegeven aan het ontwerp en de implementatie van innovatieve end-to-end-oplossingen, mogelijk gemaakt door de vooruitgang op het gebied van ML en AI. Romina's interessegebieden zijn natuurlijke taalverwerking, grote taalmodellen en MLOps.
 Nicole Pinto is een AI/ML Specialist Solutions Architect gevestigd in Sydney, Australië. Haar achtergrond in de gezondheidszorg en financiële dienstverlening geeft haar een uniek perspectief bij het oplossen van klantproblemen. Ze heeft een passie voor het faciliteren van klanten door middel van machinaal leren en het empoweren van de volgende generatie vrouwen in STEM.
Nicole Pinto is een AI/ML Specialist Solutions Architect gevestigd in Sydney, Australië. Haar achtergrond in de gezondheidszorg en financiële dienstverlening geeft haar een uniek perspectief bij het oplossen van klantproblemen. Ze heeft een passie voor het faciliteren van klanten door middel van machinaal leren en het empoweren van de volgende generatie vrouwen in STEM.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

