Klanten van elke omvang en branche innoveren op AWS door machine learning (ML) in hun producten en diensten te integreren. Recente ontwikkelingen in generatieve AI-modellen hebben de noodzaak van ML-adoptie in alle sectoren verder versneld. Het implementeren van beveiligings-, gegevensprivacy- en governancecontroles zijn echter nog steeds belangrijke uitdagingen waarmee klanten worden geconfronteerd bij het op grote schaal implementeren van ML-workloads. Door deze uitdagingen aan te pakken, wordt het raamwerk en de basis gelegd voor het beperken van risico's en een verantwoord gebruik van ML-gestuurde producten. Hoewel generatieve AI mogelijk extra controles nodig heeft, zoals het verwijderen van toxiciteit en het voorkomen van jailbreaks en hallucinaties, deelt het dezelfde fundamentele componenten voor beveiliging en bestuur als traditionele ML.
Wij horen van klanten dat zij specialistische kennis en investeringen van maximaal 12 maanden nodig hebben voor het uitbouwen van hun maatwerk Amazon Sage Maker ML-platformimplementatie om schaalbare, betrouwbare, veilige en beheerde ML-omgevingen voor hun bedrijfsactiviteiten (LOB's) of ML-teams te garanderen. Als u geen raamwerk heeft om de ML-levenscyclus op schaal te beheren, kunt u tegen uitdagingen aanlopen zoals het isoleren van bronnen op teamniveau, het schalen van experimenteerbronnen, het operationeel maken van ML-workflows, het schalen van modelbeheer en het beheren van de beveiliging en compliance van ML-workloads.
Het op schaal beheren van de ML-levenscyclus is een raamwerk waarmee u een ML-platform kunt bouwen met ingebouwde beveiligings- en beheercontroles op basis van best practices uit de sector en bedrijfsstandaarden. Dit raamwerk pakt uitdagingen aan door prescriptieve begeleiding te bieden via een modulaire raamwerkbenadering die een uitbreiding van een AWS-verkeerstoren multi-account AWS-omgeving en de aanpak die in de post wordt besproken Het opzetten van veilige, goed beheerde machine learning-omgevingen op AWS.
Het biedt voorgeschreven richtlijnen voor de volgende ML-platformfuncties:
- Basis voor meerdere accounts, beveiliging en netwerken – Deze functie maakt gebruik van AWS Control Tower en goed ontworpen principes voor het opzetten en exploiteren van omgevingen, beveiliging en netwerkdiensten met meerdere accounts.
- Basis voor data en governance – Deze functie maakt gebruik van a data mesh-architectuur voor het opzetten en exploiteren van het datameer, de centrale functieopslag en de fundamenten voor databeheer om fijnmazige gegevenstoegang mogelijk te maken.
- Gedeelde en governance-services op ML-platform – Met deze functie kunt u algemene diensten instellen en bedienen, zoals CI/CD, AWS-servicecatalogus voor inrichtingsomgevingen, en een centraal modelregister voor modelpromotie en afstamming.
- ML-teamomgevingen – Met deze functie worden omgevingen voor ML-teams opgezet en beheerd voor het ontwikkelen, testen en implementeren van hun gebruiksscenario's voor het inbedden van beveiligings- en governance-controles.
- Waarneembaarheid van het ML-platform – Deze functie helpt bij het oplossen van problemen en het identificeren van de hoofdoorzaak van problemen in ML-modellen door middel van centralisatie van logs en het bieden van tools voor visualisatie van loganalyse. Het biedt ook richtlijnen voor het genereren van kosten- en gebruiksrapporten voor ML-gebruiksscenario's.
Hoewel dit raamwerk alle klanten voordelen kan bieden, is het het meest voordelig voor klanten van grote, volwassen, gereguleerde of mondiale ondernemingen die hun ML-strategieën willen opschalen in een gecontroleerde, conforme en gecoördineerde aanpak binnen de hele organisatie. Het helpt de adoptie van ML mogelijk te maken en tegelijkertijd de risico's te beperken. Dit raamwerk is nuttig voor de volgende klanten:
- Grote zakelijke klanten met veel LOB's of afdelingen die geïnteresseerd zijn in het gebruik van ML. Met dit raamwerk kunnen verschillende teams onafhankelijk ML-modellen bouwen en implementeren, terwijl centraal beheer wordt geboden.
- Enterprise-klanten met een gemiddelde tot hoge volwassenheid in ML. Ze hebben al een aantal initiële ML-modellen geïmplementeerd en willen hun ML-inspanningen opschalen. Dit raamwerk kan de adoptie van ML binnen de hele organisatie helpen versnellen. Deze bedrijven erkennen ook de noodzaak van governance om zaken als toegangscontrole, datagebruik, modelprestaties en oneerlijke vooroordelen te beheren.
- Bedrijven in gereguleerde sectoren zoals de financiële dienstverlening, de gezondheidszorg, de chemie en de particuliere sector. Deze bedrijven hebben een sterke governance en hoorbaarheid nodig voor alle ML-modellen die in hun bedrijfsprocessen worden gebruikt. Het aannemen van dit raamwerk kan de naleving helpen vergemakkelijken en tegelijkertijd de ontwikkeling van lokale modellen mogelijk maken.
- Mondiale organisaties die een evenwicht moeten vinden tussen gecentraliseerde en lokale controle. De gefedereerde aanpak van dit raamwerk stelt het centrale platform-engineeringteam in staat een aantal beleidslijnen en standaarden op hoog niveau vast te stellen, maar geeft LOB-teams ook de flexibiliteit om zich aan te passen op basis van lokale behoeften.
In het eerste deel van deze serie lopen we door de referentiearchitectuur voor het opzetten van het ML-platform. In een later bericht zullen we beschrijvende richtlijnen geven voor het implementeren van de verschillende modules in de referentiearchitectuur in uw organisatie.
De mogelijkheden van het ML-platform zijn gegroepeerd in vier categorieën, zoals weergegeven in de volgende afbeelding. Deze mogelijkheden vormen de basis van de referentiearchitectuur die later in dit bericht wordt besproken:
- Bouw een ML-fundament
- Schaal ML-bewerkingen
- Waarneembare ML
- Veilige ML
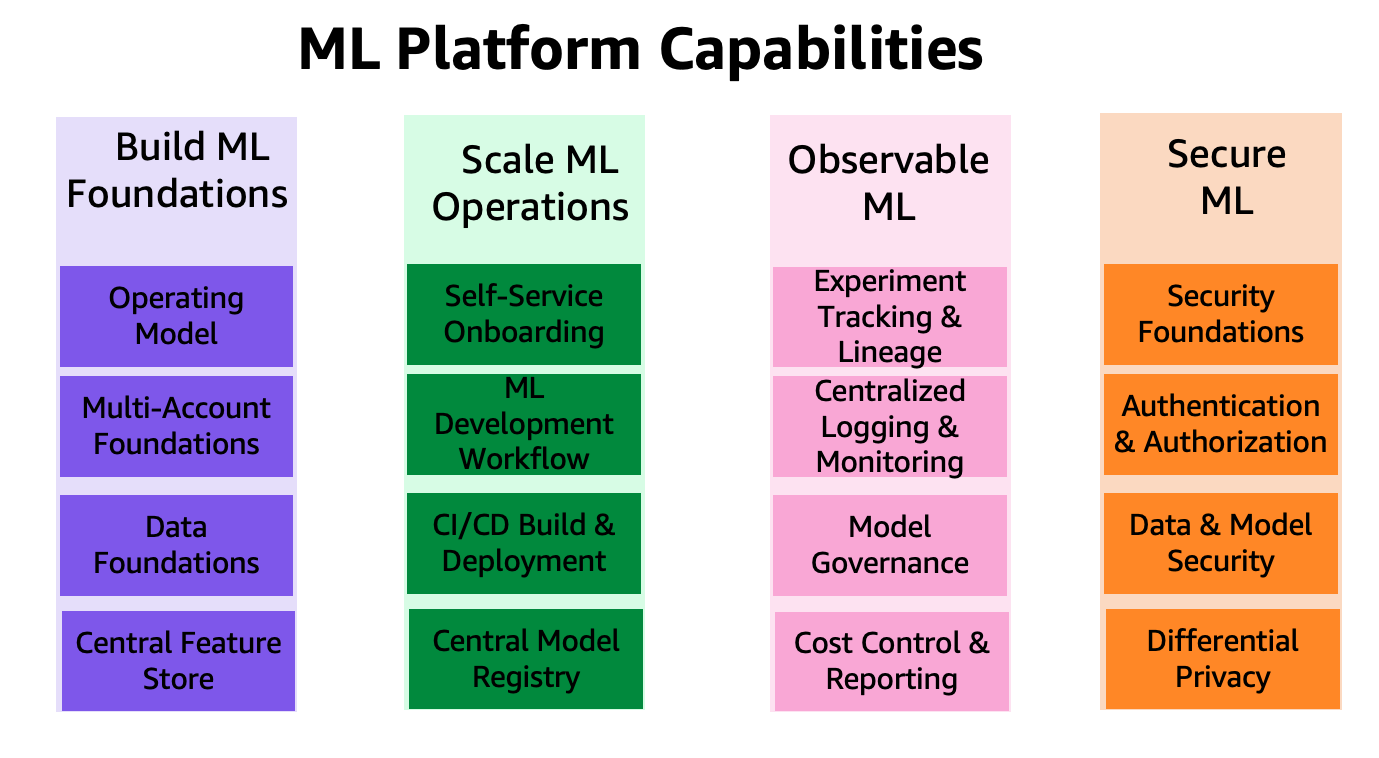
Overzicht oplossingen
Het raamwerk voor het op grote schaal beheren van de ML-levenscyclus stelt organisaties in staat om beveiligings- en governance-controles in te bedden gedurende de ML-levenscyclus, waardoor organisaties op hun beurt de risico's kunnen verminderen en de inbreng van ML in hun producten en diensten kunnen versnellen. Het raamwerk helpt bij het optimaliseren van de opzet en het beheer van veilige, schaalbare en betrouwbare ML-omgevingen die kunnen worden geschaald om een toenemend aantal modellen en projecten te ondersteunen. Het raamwerk maakt de volgende functies mogelijk:
- Account- en infrastructuurinrichting met infrastructuurbronnen die voldoen aan het organisatiebeleid
- Selfservice-implementatie van data science-omgevingen en end-to-end ML-bewerkingen (MLOps)-sjablonen voor ML-gebruiksscenario's
- Isolatie van bronnen op LOB- of teamniveau voor naleving van beveiliging en privacy
- Beheerde toegang tot productiegegevens voor experimenten en productieklare workflows
- Beheer en beheer van codeopslagplaatsen, codepijplijnen, geïmplementeerde modellen en gegevensfuncties
- Een modelregister en functiearchief (lokale en centrale componenten) voor het verbeteren van het bestuur
- Beveiligings- en beheercontroles voor het end-to-end modelontwikkelings- en implementatieproces
In deze sectie bieden we een overzicht van voorgeschreven richtlijnen om u te helpen dit ML-platform op AWS te bouwen met ingebouwde beveiligings- en governance-controles.
De functionele architectuur die bij het ML-platform hoort, wordt weergegeven in het volgende diagram. De architectuur brengt de verschillende mogelijkheden van het ML-platform in kaart voor AWS-accounts.
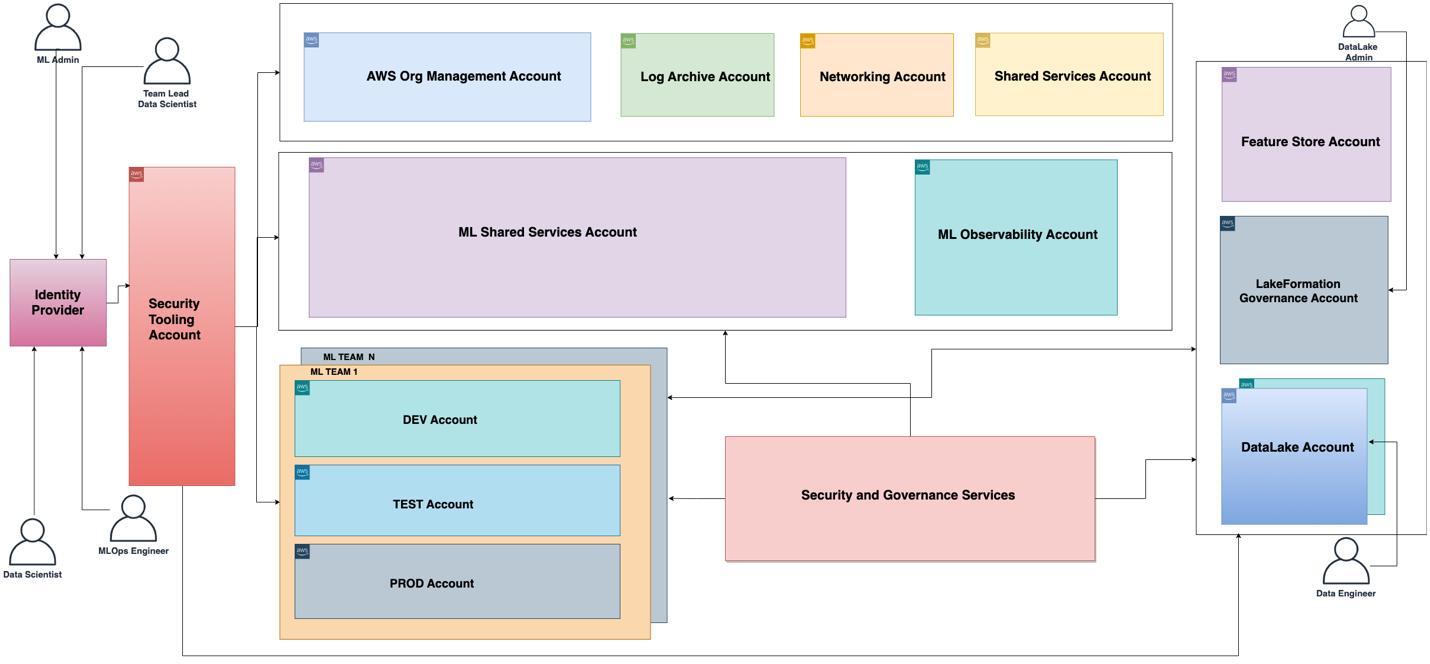
De functionele architectuur met verschillende mogelijkheden wordt geïmplementeerd met behulp van een aantal AWS-services, waaronder AWS-organisaties, SageMaker, AWS DevOps-services en een datameer. De referentiearchitectuur voor het ML-platform met verschillende AWS-services wordt weergegeven in het volgende diagram.
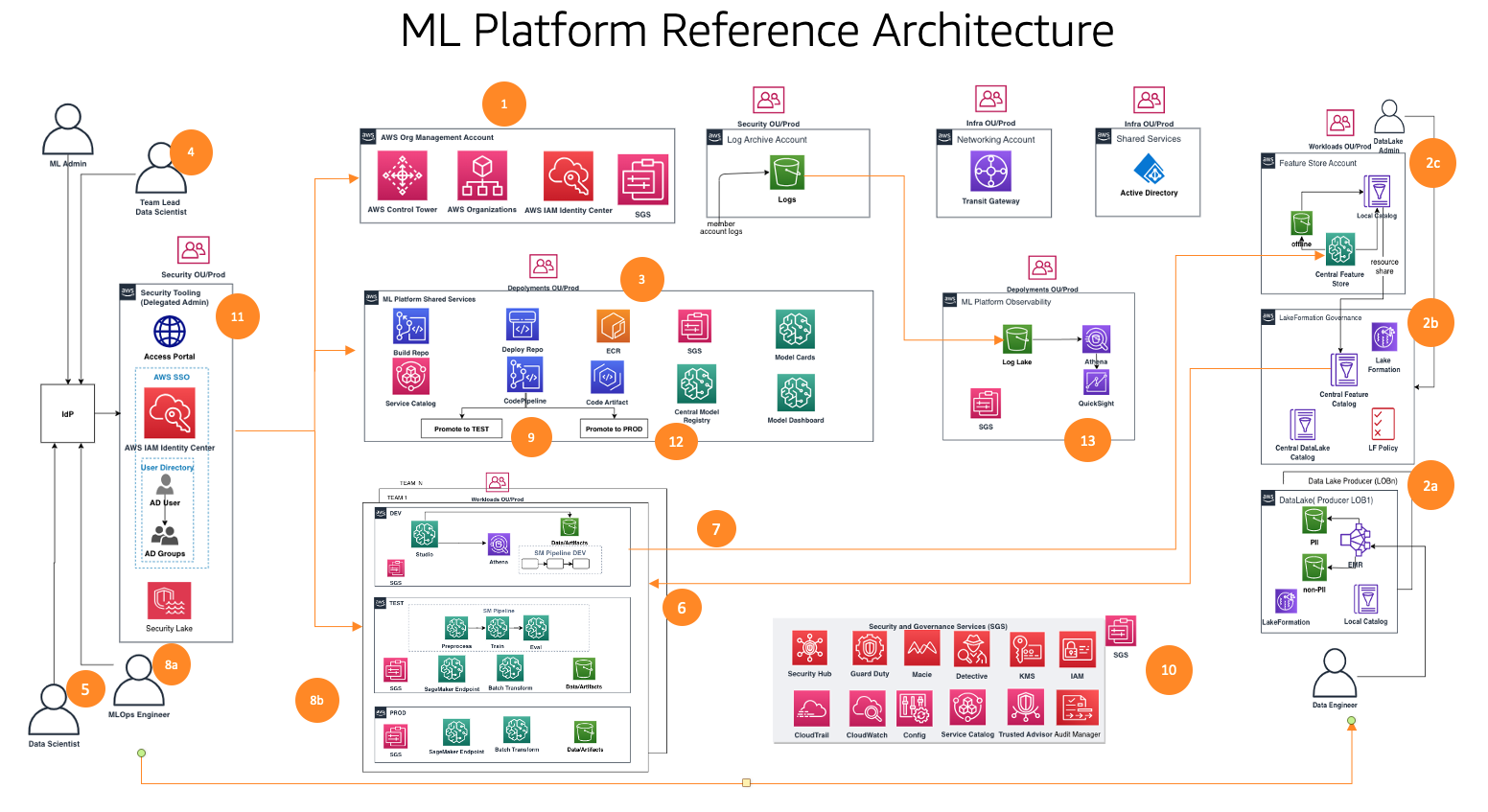
Dit raamwerk houdt rekening met meerdere persona's en services om de ML-levenscyclus op schaal te besturen. We raden de volgende stappen aan om uw teams en services te organiseren:
- Met behulp van AWS Control Tower en automatiseringstools zet uw cloudbeheerder de basis voor meerdere accounts op, zoals Organisaties en AWS IAM Identiteitscentrum (opvolger van AWS Single Sign-On) en beveiligings- en governancediensten zoals AWS Sleutelbeheerservice (AWS KMS) en servicecatalogus. Daarnaast stelt de beheerder diverse organisatie-eenheden (OE's) en initiële accounts in ter ondersteuning van uw ML- en analyseworkflows.
- Data Lake-beheerders stellen uw data lake en datacatalogus in, en zetten de centrale feature store op in samenwerking met de ML-platformbeheerder.
- De beheerder van het ML-platform levert gedeelde ML-services zoals AWS Codecommit, AWS CodePipeline, Amazon Elastic Container-register (Amazon ECR), een centraal modelregister, SageMaker-modelkaarten, SageMaker-modeldashboarden Service Catalog-producten voor ML-teams.
- De leider van het ML-team werkt samen via IAM Identity Center, gebruikt Service Catalog-producten en richt bronnen in de ontwikkelomgeving van het ML-team in.
- Datawetenschappers van ML-teams uit verschillende bedrijfseenheden werken samen in de ontwikkelomgeving van hun team om de modelpijplijn op te bouwen.
- Datawetenschappers zoeken en halen functies uit de centrale feature store-catalogus, bouwen modellen door middel van experimenten en selecteren het beste model voor promotie.
- Datawetenschappers creëren en delen nieuwe functies in de centrale feature store-catalogus voor hergebruik.
- Een ML-ingenieur implementeert de modelpijplijn in de testomgeving van het ML-team met behulp van een CI/CD-proces met gedeelde services.
- Na validatie door belanghebbenden wordt het ML-model geïmplementeerd in de productieomgeving van het team.
- Beveiligings- en beheercontroles zijn ingebed in elke laag van deze architectuur met behulp van services zoals AWS-beveiligingshub, Amazone-wachtdienst, Amazone MacieEn nog veel meer.
- Beveiligingscontroles worden centraal beheerd vanuit het beveiligingstoolaccount met behulp van Security Hub.
- Beheermogelijkheden van ML-platforms, zoals SageMaker Model Cards en SageMaker Model Dashboard, worden centraal beheerd vanuit het governance services-account.
- Amazon Cloud Watch en AWS CloudTrail Logboeken van elk ledenaccount worden centraal toegankelijk gemaakt vanuit een observatieaccount met behulp van native AWS-services.
Vervolgens duiken we diep in de modules van de referentiearchitectuur voor dit raamwerk.
Referentiearchitectuurmodules
De referentiearchitectuur bestaat uit acht modules, elk ontworpen om een specifieke reeks problemen op te lossen. Gezamenlijk richten deze modules zich op het beheer van verschillende dimensies, zoals infrastructuur, data, model en kosten. Elke module biedt een afzonderlijke reeks functies en werkt samen met andere modules om een geïntegreerd end-to-end ML-platform te bieden met ingebouwde beveiligings- en governance-controles. In deze sectie presenteren we een korte samenvatting van de mogelijkheden van elke module.
Stichtingen met meerdere accounts
Deze module helpt cloudbeheerders bij het bouwen van een AWS Control Tower-landingszone als fundamenteel raamwerk. Dit omvat het bouwen van een structuur met meerdere accounts, authenticatie en autorisatie via IAM Identity Center, een netwerk hub-and-spoke-ontwerp, gecentraliseerde logdiensten en nieuwe AWS-lidaccounts met gestandaardiseerde basislijnen voor beveiliging en beheer.
Daarnaast geeft deze module best practice-richtlijnen over OE- en accountstructuren die geschikt zijn voor het ondersteunen van uw ML- en analyseworkflows. Cloudbeheerders zullen het doel van de vereiste accounts en OU’s begrijpen, hoe ze deze moeten implementeren, en de belangrijkste beveiligings- en compliancediensten die ze moeten gebruiken om hun ML- en analyseworkloads centraal te beheren.
Er wordt ook een raamwerk behandeld voor het verkopen van nieuwe accounts, waarbij gebruik wordt gemaakt van automatisering voor het baseren van nieuwe accounts wanneer deze worden ingericht. Door een geautomatiseerd proces voor het inrichten van accounts te hebben opgezet, kunnen cloudbeheerders ML- en analyseteams de accounts bieden die ze nodig hebben om hun werk sneller uit te voeren, zonder dat dit ten koste gaat van een sterke basis voor governance.
Data lake-stichtingen
Deze module helpt data lake-beheerders bij het opzetten van een data lake om gegevens op te nemen, datasets te beheren en te gebruiken AWS Lake-formatie governancemodel voor het beheren van fijnmazige gegevenstoegang tussen accounts en gebruikers met behulp van een gecentraliseerde gegevenscatalogus, gegevenstoegangsbeleid en op tags gebaseerde toegangscontroles. U kunt klein beginnen met één account voor de basis van uw dataplatform voor een proof of concept of een paar kleine workloads. Voor de implementatie van productiewerklasten op middelgrote tot grote schaal raden we aan een strategie met meerdere accounts te hanteren. In een dergelijke omgeving kunnen LOB's de rol op zich nemen van dataproducenten en dataconsumenten die verschillende AWS-accounts gebruiken, en wordt het data lake-beheer beheerd vanuit een centraal gedeeld AWS-account. De dataproducent verzamelt, verwerkt en bewaart data uit zijn datadomein, naast het monitoren en waarborgen van de kwaliteit van zijn data-assets. Dataconsumenten gebruiken de data van de dataproducent nadat de gecentraliseerde catalogus deze deelt met behulp van Lake Formation. De gecentraliseerde catalogus bewaart en beheert de gedeelde gegevenscatalogus voor de gegevensproducentaccounts.
ML-platformdiensten
Deze module helpt het ML-platform-engineeringteam bij het opzetten van gedeelde services die door de datawetenschapsteams worden gebruikt op hun teamaccounts. De diensten omvatten een servicecatalogusportfolio met producten voor SageMaker-domein inzet, SageMaker-domeingebruikersprofiel implementatie, data science-modelsjablonen voor het bouwen en implementeren van modellen. Deze module bevat functionaliteiten voor een gecentraliseerd modelregister, modelkaarten, modeldashboard en de CI/CD-pijplijnen die worden gebruikt om de modelontwikkeling en implementatieworkflows te orkestreren en automatiseren.
Daarnaast wordt in deze module gedetailleerd beschreven hoe u de controles en het beheer kunt implementeren die nodig zijn om op persona gebaseerde selfservice-mogelijkheden mogelijk te maken, waardoor datawetenschapsteams onafhankelijk hun vereiste cloudinfrastructuur en ML-sjablonen kunnen implementeren.
Ontwikkeling van ML-gebruiksscenario's
Deze module helpt LOB's en datawetenschappers toegang te krijgen tot het SageMaker-domein van hun team in een ontwikkelomgeving en een modelbouwsjabloon te instantiëren om hun modellen te ontwikkelen. In deze module werken datawetenschappers aan een ontwikkelaarsaccountinstantie van de sjabloon om te communiceren met de gegevens die beschikbaar zijn op het gecentraliseerde datameer, functies uit een centrale functieopslag te hergebruiken en te delen, ML-experimenten te maken en uit te voeren, hun ML-workflows te bouwen en te testen, en hun modellen registreren in een register voor ontwikkelaarsaccountmodellen in hun ontwikkelomgevingen.
Mogelijkheden zoals het volgen van experimenten, rapporten over de uitlegbaarheid van modellen, monitoring van gegevens en modelbias en modelregistratie zijn ook geïmplementeerd in de sjablonen, waardoor snelle aanpassing van de oplossingen aan de door datawetenschappers ontwikkelde modellen mogelijk is.
ML-bewerkingen
Met deze module kunnen LOB's en ML-ingenieurs werken aan hun ontwikkelinstanties van de modelimplementatiesjabloon. Nadat het kandidaatmodel is geregistreerd en goedgekeurd, zetten ze CI/CD-pijplijnen op en voeren ze ML-workflows uit in de testomgeving van het team, die het model registreert in het centrale modelregister dat wordt uitgevoerd in een account voor gedeelde platformservices. Wanneer een model wordt goedgekeurd in het centrale modelregister, wordt een CI/CD-pijplijn geactiveerd om het model in de productieomgeving van het team te implementeren.
Gecentraliseerde feature store
Nadat de eerste modellen in productie zijn genomen en meerdere gebruiksscenario's functies beginnen te delen die op basis van dezelfde gegevens zijn gemaakt, wordt een functiearchief essentieel om samenwerking tussen gebruiksscenario's te garanderen en dubbel werk te verminderen. Deze module helpt het engineeringteam van het ML-platform bij het opzetten van een gecentraliseerde functieopslag om opslag en beheer te bieden voor ML-functies die zijn gemaakt door de ML-gebruiksscenario's, waardoor hergebruik van functies in projecten mogelijk wordt gemaakt.
Logging en waarneembaarheid
Deze module helpt LOB's en ML-professionals inzicht te krijgen in de status van ML-workloads in ML-omgevingen door centralisatie van logactiviteiten zoals CloudTrail, CloudWatch, VPC-stroomlogboeken en ML-workloadlogboeken. Teams kunnen logboeken filteren, opvragen en visualiseren voor analyse, wat ook kan helpen de beveiligingspositie te verbeteren.
Kosten en rapportage
Deze module helpt verschillende belanghebbenden (cloudbeheerder, platformbeheerder, cloudbedrijfskantoor) bij het genereren van rapporten en dashboards om de kosten op ML-gebruikers-, ML-team- en ML-productniveaus uit te splitsen, en het gebruik bij te houden, zoals het aantal gebruikers, exemplaartypen en eindpunten.
Klanten hebben ons gevraagd om advies te geven over hoeveel accounts ze moeten aanmaken en hoe ze die accounts kunnen structureren. In de volgende sectie bieden we richtlijnen voor die rekeningstructuur als referentie, die u kunt aanpassen aan uw behoeften op basis van de vereisten van uw ondernemingsbestuur.
In deze sectie bespreken we onze aanbeveling voor het organiseren van uw accountstructuur. We delen een basisreferentierekeningstructuur; We raden echter aan dat ML- en gegevensbeheerders nauw samenwerken met hun cloudbeheerder om deze accountstructuur aan te passen op basis van de controles van hun organisatie.

We raden u aan accounts te ordenen op OE voor beveiliging, infrastructuur, workloads en implementaties. Bovendien kunt u binnen elke organisatie-eenheid de organisatie organiseren op niet-productie- en productie-OE, omdat de accounts en werklasten die daaronder worden ingezet, verschillende controles hebben. Vervolgens bespreken we deze OU’s kort.
Beveiliging OU
De accounts in deze OE worden beheerd door de cloudbeheerder of het beveiligingsteam van de organisatie voor het bewaken, identificeren, beschermen, detecteren en reageren op beveiligingsgebeurtenissen.
Infrastructuur OU
De accounts in deze OE worden beheerd door de cloudbeheerder of het netwerkteam van de organisatie voor het beheren van gedeelde infrastructuurbronnen en netwerken op bedrijfsniveau.
We raden u aan de volgende accounts te hebben onder de infrastructuur-OE:
- Netwerk – Zet een gecentraliseerde netwerkinfrastructuur op, zoals AWS-transitgateway
- Gedeelde diensten – Zet gecentraliseerde AD-services en VPC-eindpunten op
Werklasten OE
De accounts in deze OE worden beheerd door de platformteambeheerders van de organisatie. Als u voor elk platformteam verschillende besturingselementen wilt implementeren, kunt u voor dat doel andere OE-niveaus nesten, zoals een OE voor ML-werkbelastingen, OE voor gegevenswerkbelastingen, enzovoort.
We raden de volgende accounts aan onder de werklast-OE:
- ML-ontwikkelaars-, test- en productaccounts op teamniveau – Stel dit in op basis van uw vereisten voor werkbelastingisolatie
- Data Lake-accounts – Verdeel accounts op basis van uw gegevensdomein
- Centraal gegevensbeheeraccount – Centraliseer uw beleid voor gegevenstoegang
- Centraal functiewinkelaccount – Centraliseer functies voor het delen tussen teams
Implementaties OU
De accounts in deze OE worden beheerd door de platformteambeheerders van de organisatie voor het implementeren van werklasten en zichtbaarheid.
We raden de volgende accounts aan onder de implementatie-OE, omdat het ML-platformteam op dit OE-niveau verschillende sets controles kan instellen om implementaties te beheren en te besturen:
- ML gedeelde services-accounts voor test- en prod – Host platform gedeelde services CI/CD en modelregistratie
- ML-waarneembaarheid houdt rekening met test- en prod – Host CloudWatch-logboeken, CloudTrail-logboeken en andere logboeken indien nodig
Vervolgens bespreken we kort organisatiecontroles waarmee rekening moet worden gehouden bij het inbedden in ledenaccounts voor het monitoren van de infrastructuurbronnen.
AWS-omgevingscontroles
Een controle is een regel op hoog niveau die zorgt voor doorlopend beheer van uw algehele AWS-omgeving. Het wordt uitgedrukt in duidelijke taal. In dit raamwerk gebruiken we AWS Control Tower om de volgende controles te implementeren die u helpen uw bronnen te beheren en de naleving van groepen AWS-accounts te controleren:
- Preventieve controles – Een preventieve controle zorgt ervoor dat uw accounts aan de regels blijven voldoen, omdat acties die tot beleidsschendingen leiden, niet worden toegestaan en worden geïmplementeerd met behulp van een Service Control Policy (SCP). U kunt bijvoorbeeld een preventieve controle instellen die ervoor zorgt dat CloudTrail niet wordt verwijderd of gestopt in AWS-accounts of Regio's.
- Detectivecontroles – Een detectiecontrole detecteert niet-naleving van bronnen binnen uw accounts, zoals beleidsschendingen, geeft waarschuwingen via het dashboard en wordt geïmplementeerd met behulp van AWS-configuratie reglement. U kunt bijvoorbeeld een detectivecontrole maken om te detecteren of openbare leestoegang is ingeschakeld voor de Amazon eenvoudige opslagservice (Amazon S3)-buckets in het gedeelde account van het logboekarchief.
- Proactieve controles – Een proactieve controle scant uw bronnen voordat ze worden ingericht en zorgt ervoor dat de bronnen voldoen aan die controle en worden geïmplementeerd met behulp van AWS CloudFormatie haken. Resources die niet aan het beleid voldoen, worden niet ingericht. U kunt bijvoorbeeld een proactieve controle instellen die controleert of directe internettoegang niet is toegestaan voor een SageMaker-notebookinstantie.
Interacties tussen ML-platformservices, ML-gebruiksscenario's en ML-bewerkingen
Verschillende persona's, zoals het hoofd datawetenschap (hoofddatawetenschapper), datawetenschapper en ML-ingenieur, bedienen modules 2 tot en met 6, zoals weergegeven in het volgende diagram, voor verschillende stadia van ML-platformservices, ML-use-case-ontwikkeling en ML-bewerkingen samen met data lake foundations en de centrale feature store.

De volgende tabel geeft een overzicht van de operationele stroomactiviteiten en de installatiestroomstappen voor verschillende persona's. Zodra een persona een ML-activiteit initieert als onderdeel van de operationele stroom, worden de services uitgevoerd zoals vermeld in de installatiestroomstappen.
| Persona | Ops Flow-activiteit – Aantal | Ops Flow-activiteit – Beschrijving | Installatiestroomstap – Nummer | Installatiestroomstap – Beschrijving |
| Lead Data Science of ML-teamleider |
1 |
Maakt gebruik van Service Catalog in het ML-platformservicesaccount en implementeert het volgende:
|
1-A |
|
|
1-B |
|
|||
| Gegevens Scientist |
2 |
Voert en volgt ML-experimenten uit in SageMaker-notebooks |
2-A |
|
|
3 |
Automatiseert succesvolle ML-experimenten met SageMaker-projecten en -pijplijnen |
3-A |
|
|
|
3-B |
Nadat de SageMaker-pijplijnen zijn uitgevoerd, wordt het model opgeslagen in het lokale (dev) modelregister | |||
| Lead Data Scientist of ML-teamleider |
4 |
Keurt het model goed in het lokale (ontwikkelaar)modelregister |
4-A |
Metagegevens van modellen en modelpakketten worden geschreven van het lokale (dev) modelregister naar het centrale modelregister |
|
5 |
Keurt het model goed in het centrale modellenregister |
5-A |
Start het implementatie-CI/CD-proces om SageMaker-eindpunten in de testomgeving te creëren | |
|
5-B |
Schrijft de modelinformatie en metagegevens naar de ML-governancemodule (modelkaart, modeldashboard) in het ML-platformservicesaccount vanuit het lokale (ontwikkelaars)account | |||
| ML-ingenieur |
6 |
Test en bewaakt het SageMaker-eindpunt in de testomgeving na CI/CD | . | |
|
7 |
Keurt de implementatie voor SageMaker-eindpunten in de productieomgeving goed |
7-A |
Start het CI/CD-implementatieproces om SageMaker-eindpunten in de productomgeving te creëren | |
|
8 |
Test en bewaakt het SageMaker-eindpunt in de testomgeving na CI/CD | . | ||
Persona's en interacties met verschillende modules van het ML-platform
Elke module richt zich op specifieke doelgroepen binnen specifieke divisies die de module het vaakst gebruiken, waardoor ze primaire toegang krijgen. Secundaire toegang is dan toegestaan tot andere divisies die incidenteel gebruik van de modules vereisen. De modules zijn afgestemd op de behoeften van specifieke functies of persona's om de functionaliteit te optimaliseren.
We bespreken de volgende teams:
- Centrale cloud-engineering – Dit team opereert op enterprise-cloudniveau voor alle workloads voor het opzetten van gemeenschappelijke cloudinfrastructuurdiensten, zoals het opzetten van netwerken, identiteiten, machtigingen en accountbeheer op ondernemingsniveau
- Dataplatform-engineering – Dit team beheert bedrijfsdatameren, dataverzameling, datacuratie en databeheer
- ML-platformtechniek – Dit team opereert op ML-platformniveau in alle LOB's om gedeelde ML-infrastructuurdiensten te leveren, zoals het aanbieden van ML-infrastructuur, het volgen van experimenten, modelbeheer, implementatie en observatie
De volgende tabel geeft aan welke divisies primaire en secundaire toegang hebben voor elke module, afhankelijk van de beoogde persona's van de module.
| Module nummer | Modules | Primaire toegang | Secundaire toegang | Doelpersona's | Aantal rekeningen |
|
1 |
Stichtingen met meerdere accounts | Centrale cloud-engineering | Individuele LOB's |
|
Weinig |
|
2 |
Data lake-stichtingen | Centrale cloud- of dataplatform-engineering | Individuele LOB's |
|
meervoudig |
|
3 |
ML-platformdiensten | Centrale cloud- of ML-platformengineering | Individuele LOB's |
|
One |
|
4 |
Ontwikkeling van ML-gebruiksscenario's | Individuele LOB's | Centrale cloud- of ML-platformengineering |
|
meervoudig |
|
5 |
ML-bewerkingen | Centrale cloud- of ML-engineering | Individuele LOB's |
|
meervoudig |
|
6 |
Gecentraliseerde feature store | Centrale cloud- of data-engineering | Individuele LOB's |
|
One |
|
7 |
Logging en waarneembaarheid | Centrale cloud-engineering | Individuele LOB's |
|
One |
|
8 |
Kosten en rapportage | Individuele LOB's | Centrale platformtechniek |
|
One |
Conclusie
In dit bericht hebben we een raamwerk geïntroduceerd voor het op grote schaal beheren van de ML-levenscyclus, waarmee u goed ontworpen ML-workloads kunt implementeren waarin beveiligings- en governance-controles zijn geïntegreerd. We hebben besproken hoe dit raamwerk een holistische benadering hanteert voor het bouwen van een ML-platform, waarbij rekening wordt gehouden met gegevensbeheer, modelbeheer en controles op bedrijfsniveau. We moedigen je aan om te experimenteren met het raamwerk en de concepten die in dit bericht worden geïntroduceerd en je feedback te delen.
Over de auteurs
 Ram Vital is een Principal ML Solutions Architect bij AWS. Hij heeft meer dan dertig jaar ervaring met het ontwerpen en bouwen van gedistribueerde, hybride en cloudapplicaties. Hij heeft een passie voor het bouwen van veilige, schaalbare, betrouwbare AI/ML- en big data-oplossingen om zakelijke klanten te helpen met hun cloudadoptie en -optimalisatietraject om hun bedrijfsresultaten te verbeteren. In zijn vrije tijd rijdt hij motor en wandelt hij met zijn driejarige schapen-a-doodle!
Ram Vital is een Principal ML Solutions Architect bij AWS. Hij heeft meer dan dertig jaar ervaring met het ontwerpen en bouwen van gedistribueerde, hybride en cloudapplicaties. Hij heeft een passie voor het bouwen van veilige, schaalbare, betrouwbare AI/ML- en big data-oplossingen om zakelijke klanten te helpen met hun cloudadoptie en -optimalisatietraject om hun bedrijfsresultaten te verbeteren. In zijn vrije tijd rijdt hij motor en wandelt hij met zijn driejarige schapen-a-doodle!
 Sovik Kumar Nath is een AI/ML-oplossingsarchitect met AWS. Hij heeft uitgebreide ervaring met het ontwerpen van end-to-end oplossingen voor machine learning en bedrijfsanalyse op het gebied van financiën, bedrijfsvoering, marketing, gezondheidszorg, supply chain management en IoT. Sovik heeft artikelen gepubliceerd en heeft een patent op ML-modelbewaking. Hij heeft dubbele masters van de University of South Florida, University of Fribourg, Zwitserland, en een bachelors degree van het Indian Institute of Technology, Kharagpur. Buiten zijn werk houdt Sovik van reizen, veerboottochten maken en films kijken.
Sovik Kumar Nath is een AI/ML-oplossingsarchitect met AWS. Hij heeft uitgebreide ervaring met het ontwerpen van end-to-end oplossingen voor machine learning en bedrijfsanalyse op het gebied van financiën, bedrijfsvoering, marketing, gezondheidszorg, supply chain management en IoT. Sovik heeft artikelen gepubliceerd en heeft een patent op ML-modelbewaking. Hij heeft dubbele masters van de University of South Florida, University of Fribourg, Zwitserland, en een bachelors degree van het Indian Institute of Technology, Kharagpur. Buiten zijn werk houdt Sovik van reizen, veerboottochten maken en films kijken.
 Maira Ladeira Tanke is een Senior Data Specialist bij AWS. Als technisch leider helpt ze klanten hun bedrijfswaarde te versnellen door middel van opkomende technologie en innovatieve oplossingen. Maira werkt sinds januari 2020 bij AWS. Daarvoor werkte ze als datawetenschapper in meerdere sectoren, waarbij ze zich richtte op het behalen van bedrijfswaarde uit data. In haar vrije tijd houdt Maira ervan om te reizen en tijd door te brengen met haar familie op een warme plek.
Maira Ladeira Tanke is een Senior Data Specialist bij AWS. Als technisch leider helpt ze klanten hun bedrijfswaarde te versnellen door middel van opkomende technologie en innovatieve oplossingen. Maira werkt sinds januari 2020 bij AWS. Daarvoor werkte ze als datawetenschapper in meerdere sectoren, waarbij ze zich richtte op het behalen van bedrijfswaarde uit data. In haar vrije tijd houdt Maira ervan om te reizen en tijd door te brengen met haar familie op een warme plek.
 Ryan Lempka is Senior Solutions Architect bij Amazon Web Services, waar hij zijn klanten helpt achteruit te werken vanuit zakelijke doelstellingen om oplossingen op AWS te ontwikkelen. Hij heeft diepgaande ervaring in bedrijfsstrategie, IT-systeembeheer en datawetenschap. Ryan streeft ernaar een leven lang te leren en vindt het leuk om zichzelf elke dag uit te dagen om iets nieuws te leren.
Ryan Lempka is Senior Solutions Architect bij Amazon Web Services, waar hij zijn klanten helpt achteruit te werken vanuit zakelijke doelstellingen om oplossingen op AWS te ontwikkelen. Hij heeft diepgaande ervaring in bedrijfsstrategie, IT-systeembeheer en datawetenschap. Ryan streeft ernaar een leven lang te leren en vindt het leuk om zichzelf elke dag uit te dagen om iets nieuws te leren.
 Sriharsh Adari is Senior Solutions Architect bij Amazon Web Services (AWS), waar hij klanten helpt terug te werken vanuit bedrijfsresultaten om innovatieve oplossingen op AWS te ontwikkelen. In de loop der jaren heeft hij meerdere klanten geholpen bij transformaties van dataplatforms in verschillende branches. Zijn belangrijkste expertisegebieden zijn technologiestrategie, data-analyse en datawetenschap. In zijn vrije tijd sport hij graag, kijkt hij tv-programma's en speelt hij Tabla.
Sriharsh Adari is Senior Solutions Architect bij Amazon Web Services (AWS), waar hij klanten helpt terug te werken vanuit bedrijfsresultaten om innovatieve oplossingen op AWS te ontwikkelen. In de loop der jaren heeft hij meerdere klanten geholpen bij transformaties van dataplatforms in verschillende branches. Zijn belangrijkste expertisegebieden zijn technologiestrategie, data-analyse en datawetenschap. In zijn vrije tijd sport hij graag, kijkt hij tv-programma's en speelt hij Tabla.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/governing-the-ml-lifecycle-at-scale-part-1-a-framework-for-architecting-ml-workloads-using-amazon-sagemaker/

