Vandaag zijn we verheugd om aan te kondigen dat de Lama bewaker model is nu beschikbaar voor klanten die het gebruiken Amazon SageMaker JumpStart. Llama Guard biedt invoer- en uitvoerbeveiligingen bij de implementatie van grote taalmodellen (LLM). Het is een van de componenten onder Purple Llama, het initiatief van Meta met open vertrouwens- en veiligheidstools en evaluaties om ontwikkelaars te helpen verantwoord te bouwen met AI-modellen. Purple Llama brengt tools en evaluaties samen om de gemeenschap te helpen verantwoord te bouwen met generatieve AI-modellen. De eerste release omvat een focus op cyberbeveiliging en LLM-invoer- en outputwaarborgen. Voor componenten binnen het Purple Llama-project, waaronder het Llama Guard-model, is een licentie verleend, waardoor zowel onderzoek als commercieel gebruik mogelijk is.
Nu kunt u het Llama Guard-model gebruiken binnen SageMaker JumpStart. SageMaker JumpStart is de machine learning (ML)-hub van Amazon Sage Maker die toegang biedt tot basismodellen naast ingebouwde algoritmen en end-to-end-oplossingssjablonen om u te helpen snel aan de slag te gaan met ML.
In dit bericht laten we zien hoe we het Llama Guard-model kunnen inzetten en verantwoorde generatieve AI-oplossingen kunnen bouwen.
Llama Guard-model
Llama Guard is een nieuw model van Meta dat input- en outputvangrails biedt voor LLM-implementaties. Llama Guard is een openlijk beschikbaar model dat concurrerend presteert op algemene open benchmarks en ontwikkelaars een vooraf getraind model biedt om zich te beschermen tegen het genereren van potentieel risicovolle resultaten. Dit model is getraind op een mix van openbaar beschikbare datasets om detectie mogelijk te maken van veelvoorkomende typen potentieel risicovolle of inbreukmakende inhoud die relevant kan zijn voor een aantal gebruiksscenario's voor ontwikkelaars. Uiteindelijk is de visie van het model om ontwikkelaars in staat te stellen dit model aan te passen om relevante gebruiksscenario's te ondersteunen en om het moeiteloos te maken om best practices over te nemen en het open ecosysteem te verbeteren.
Llama Guard kan worden gebruikt als een aanvullend hulpmiddel voor ontwikkelaars om te integreren in hun eigen mitigatiestrategieën, zoals voor chatbots, contentmoderatie, klantenservice, monitoring van sociale media en onderwijs. Door door gebruikers gegenereerde inhoud door te geven aan Llama Guard voordat deze wordt gepubliceerd of erop wordt gereageerd, kunnen ontwikkelaars onveilig of ongepast taalgebruik markeren en actie ondernemen om een veilige en respectvolle omgeving te behouden.
Laten we eens kijken hoe we het Llama Guard-model kunnen gebruiken in SageMaker JumpStart.
Funderingsmodellen in SageMaker
SageMaker JumpStart biedt toegang tot een reeks modellen van populaire modelhubs, waaronder Hugging Face, PyTorch Hub en TensorFlow Hub, die u kunt gebruiken binnen uw ML-ontwikkelingsworkflow in SageMaker. Recente ontwikkelingen op het gebied van ML hebben aanleiding gegeven tot een nieuwe klasse modellen, bekend als funderingsmodellen, die doorgaans zijn getraind op miljarden parameters en kunnen worden aangepast aan een brede categorie gebruiksscenario's, zoals het samenvatten van teksten, het genereren van digitale kunst en het vertalen van talen. Omdat het trainen van deze modellen duur is, willen klanten bestaande, vooraf getrainde basismodellen gebruiken en deze indien nodig verfijnen, in plaats van deze modellen zelf te trainen. SageMaker biedt een samengestelde lijst met modellen waaruit u kunt kiezen op de SageMaker-console.
Binnen SageMaker JumpStart kunt u nu funderingsmodellen van verschillende modelaanbieders vinden, zodat u snel aan de slag kunt met funderingsmodellen. U kunt funderingsmodellen vinden op basis van verschillende taken of modelaanbieders, en eenvoudig modelkenmerken en gebruiksvoorwaarden bekijken. U kunt deze modellen ook uitproberen met behulp van een test-UI-widget. Als u een basismodel op schaal wilt gebruiken, kunt u dit eenvoudig doen zonder SageMaker te verlaten door kant-en-klare notebooks van modelaanbieders te gebruiken. Omdat de modellen worden gehost en geïmplementeerd op AWS, kunt u er zeker van zijn dat uw gegevens, ongeacht of deze worden gebruikt voor de evaluatie of het gebruik van het model op schaal, nooit met derden worden gedeeld.
Laten we eens kijken hoe we het Llama Guard-model kunnen gebruiken in SageMaker JumpStart.
Ontdek het Llama Guard-model in SageMaker JumpStart
U hebt toegang tot Code Llama-basismodellen via SageMaker JumpStart in de gebruikersinterface van SageMaker Studio en de SageMaker Python SDK. In dit gedeelte bespreken we hoe u de modellen in kunt ontdekken Amazon SageMaker Studio.
SageMaker Studio is een geïntegreerde ontwikkelomgeving (IDE) die een enkele webgebaseerde visuele interface biedt waar u toegang hebt tot speciaal gebouwde tools om alle ML-ontwikkelingsstappen uit te voeren, van het voorbereiden van gegevens tot het bouwen, trainen en implementeren van uw ML-modellen. Raadpleeg voor meer informatie over hoe u aan de slag kunt gaan en SageMaker Studio kunt instellen Amazon SageMaker Studio.
In SageMaker Studio heeft u toegang tot SageMaker JumpStart, dat vooraf getrainde modellen, notebooks en vooraf gebouwde oplossingen bevat onder Kant-en-klare en geautomatiseerde oplossingen.
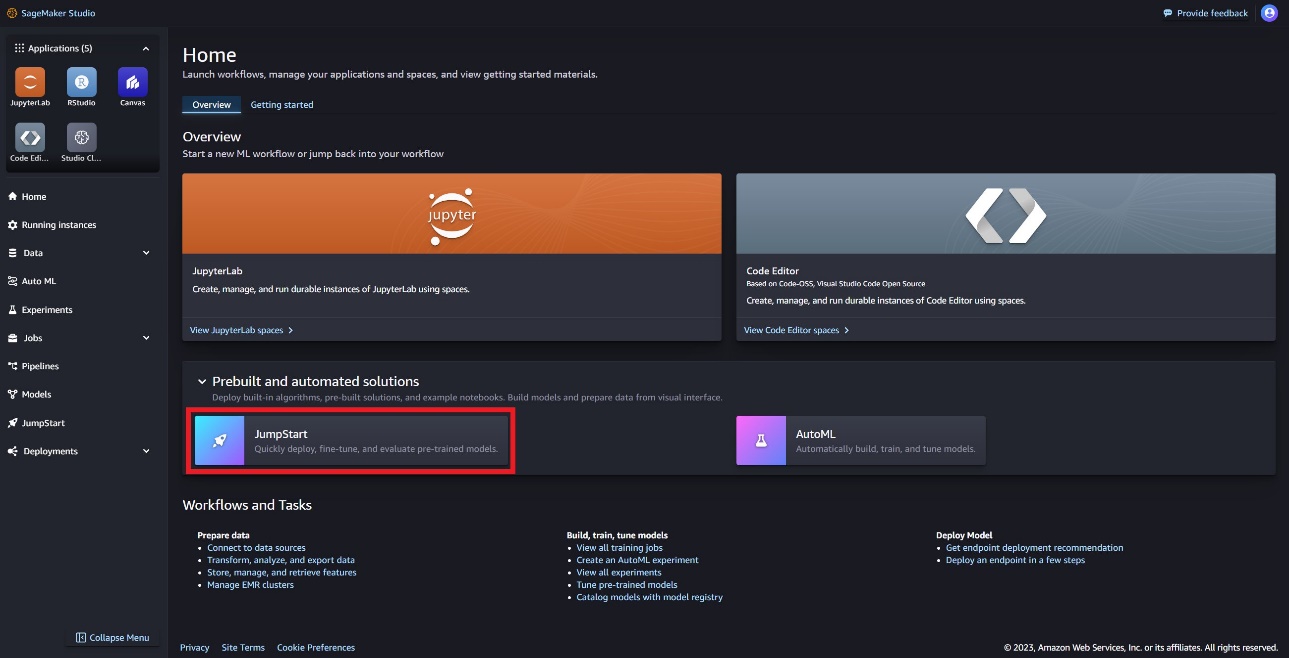
Op de startpagina van SageMaker JumpStart kunt u het Llama Guard-model vinden door de Meta-hub te kiezen of te zoeken naar Llama Guard.

Je kunt kiezen uit verschillende Llama-modelvarianten, waaronder Llama Guard, Llama-2 en Code Llama.
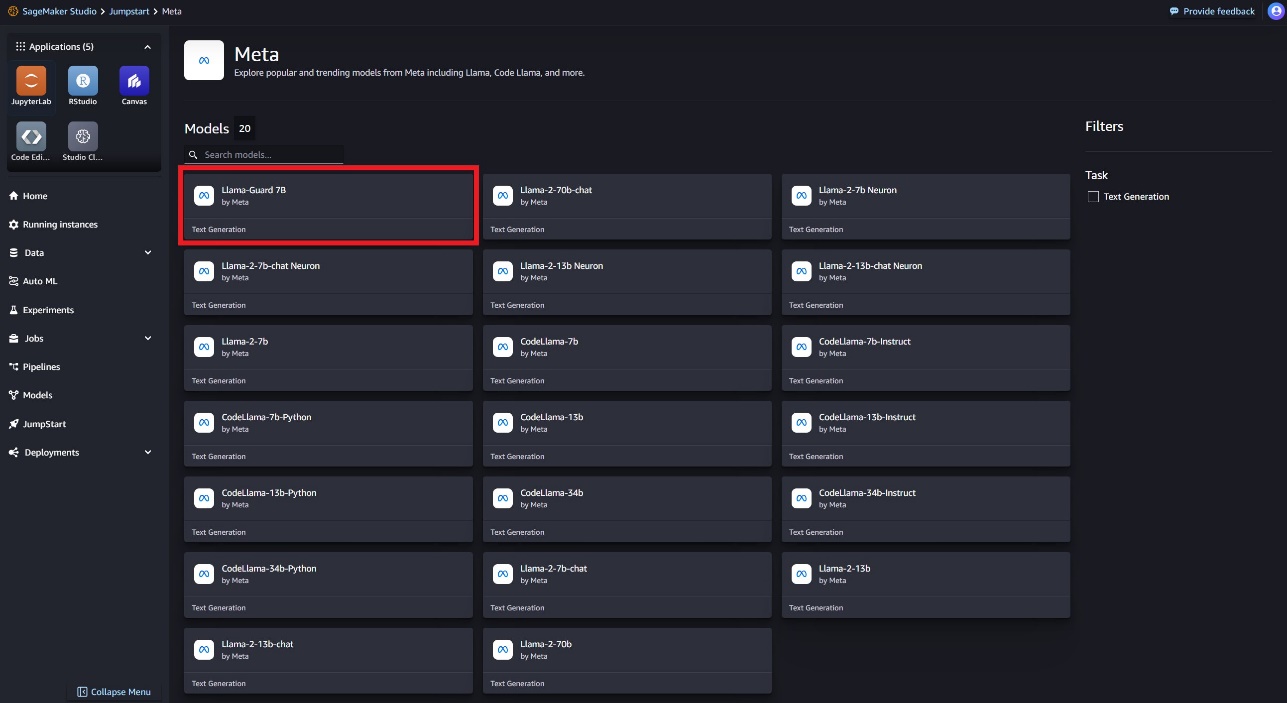
U kunt de modelkaart kiezen om details over het model te bekijken, zoals licentie, gegevens die zijn gebruikt om te trainen en hoe u deze moet gebruiken. Ook vindt u een Implementeren optie, die u naar een landingspagina brengt waar u de gevolgtrekking kunt testen met een voorbeeldpayload.

Implementeer het model met de SageMaker Python SDK
Je kunt de code vinden die de implementatie van Llama Guard laat zien op Amazon JumpStart en een voorbeeld van hoe je het geïmplementeerde model kunt gebruiken in dit GitHub-notebook.
In de volgende code specificeren we de model-ID en modelversie van het SageMaker-model die moeten worden gebruikt bij het implementeren van Llama Guard:
U kunt het model nu implementeren met SageMaker JumpStart. De volgende code gebruikt de standaardinstantie ml.g5.2xlarge voor het inferentie-eindpunt. U kunt het model op andere instantietypen implementeren door het door te geven instance_type in de JumpStartModel klas. De implementatie kan enkele minuten duren. Voor een succesvolle implementatie moet u handmatig de accept_eula argument in de implementatiemethode van het model True.
Dit model wordt geïmplementeerd met behulp van de deep learning-container Text Generation Inference (TGI). Inferentieverzoeken ondersteunen veel parameters, waaronder de volgende:
- maximale lengte – Het model genereert tekst totdat de uitvoerlengte (inclusief de invoercontextlengte) bereikt is
max_length. Indien gespecificeerd, moet het een positief geheel getal zijn. - max_nieuwe_tokens – Het model genereert tekst totdat de uitvoerlengte (exclusief de lengte van de invoercontext) is bereikt
max_new_tokens. Indien gespecificeerd, moet het een positief geheel getal zijn. - aantal_beams – Dit geeft het aantal balken aan dat is gebruikt bij de hebzuchtige zoektocht. Indien opgegeven, moet het een geheel getal groter dan of gelijk aan zijn
num_return_sequences. - no_repeat_ngram_size – Het model zorgt ervoor dat een reeks woorden van
no_repeat_ngram_sizewordt niet herhaald in de uitgangsvolgorde. Indien gespecificeerd, moet het een positief geheel getal groter dan 1 zijn. - temperatuur- – Deze parameter regelt de willekeur in de uitvoer. Een hogere
temperatureresulteert in een uitvoerreeks met woorden met een lage waarschijnlijkheid, en een lageretemperatureresulteert in een uitvoerreeks met woorden met een hoge waarschijnlijkheid. Alstemperature0 is, resulteert dit in hebzuchtige decodering. Indien gespecificeerd, moet het een positieve float zijn. - vroeg_stoppen - Indien
True, is het genereren van tekst voltooid wanneer alle bundelhypothesen het einde van het zinstoken bereiken. Indien gespecificeerd, moet het Booleaans zijn. - doen_voorbeeld - Indien
True, bemonstert het model het volgende woord op basis van de waarschijnlijkheid. Indien gespecificeerd, moet het Booleaans zijn. - top_k – Bij elke stap van het genereren van tekst neemt het model alleen monsters van de
top_kmeest waarschijnlijke woorden. Indien gespecificeerd, moet het een positief geheel getal zijn. - top_p – In elke stap van het genereren van tekst neemt het model een steekproef uit de kleinst mogelijke reeks woorden met cumulatieve waarschijnlijkheid
top_p. Indien gespecificeerd, moet het een float zijn tussen 0–1. - return_full_text - Indien
True, zal de invoertekst deel uitmaken van de door de uitvoer gegenereerde tekst. Indien gespecificeerd, moet het Booleaans zijn. De standaardwaarde isFalse. - stoppen – Indien opgegeven, moet het een lijst met tekenreeksen zijn. Het genereren van tekst stopt als een van de opgegeven tekenreeksen wordt gegenereerd.
Roep een SageMaker-eindpunt aan
U kunt voorbeeldpayloads programmatisch ophalen uit de JumpStartModel voorwerp. Dit zal u helpen snel aan de slag te gaan door vooraf opgemaakte instructieprompts te observeren die Llama Guard kan opnemen. Zie de volgende code:
Nadat u het voorgaande voorbeeld hebt uitgevoerd, kunt u zien hoe uw invoer en uitvoer door Llama Guard worden opgemaakt:
Net als Llama-2 gebruikt Llama Guard speciale tokens om veiligheidsinstructies aan het model aan te geven. Over het algemeen moet de payload het onderstaande formaat volgen:
Gebruikersprompt weergegeven als {user_prompt} hierboven, kan verder secties bevatten voor definities van inhoudscategorieën en gesprekken, die er als volgt uitzien:
In de volgende sectie bespreken we de aanbevolen standaardwaarden voor de taak, inhoudscategorie en instructiedefinities. Het gesprek moet afwisselend zijn User en Agent tekst als volgt:
Modereer een gesprek met Llama-2 Chat
U kunt nu een Llama-2 7B Chat-modeleindpunt implementeren voor conversatiechat en vervolgens Llama Guard gebruiken om invoer- en uitvoertekst afkomstig van Llama-2 7B Chat te modereren.
We laten u het voorbeeld zien van de invoer en uitvoer van het Llama-2 7B-chatmodel, gemodereerd via Llama Guard, maar u kunt Llama Guard gebruiken voor moderatie met elke LLM van uw keuze.
Implementeer het model met de volgende code:
U kunt nu de Llama Guard-taaksjabloon definiëren. De categorieën onveilige inhoud kunnen naar wens worden aangepast voor uw specifieke gebruikssituatie. U kunt in platte tekst de betekenis van elke inhoudscategorie definiëren, inclusief welke inhoud als onveilig moet worden gemarkeerd en welke inhoud als veilig moet worden toegestaan. Zie de volgende code:
Vervolgens definiëren we helperfuncties format_chat_messages en format_guard_messages om de prompt op te maken voor het chatmodel en voor het Llama Guard-model waarvoor speciale tokens nodig zijn:
U kunt vervolgens deze hulpfuncties gebruiken op een voorbeeldinvoerprompt voor een bericht om de voorbeeldinvoer via Llama Guard uit te voeren om te bepalen of de berichtinhoud veilig is:
De volgende uitvoer geeft aan dat het bericht veilig is. Het zal u wellicht opvallen dat de prompt woorden bevat die mogelijk verband houden met geweld, maar in dit geval kan Llama Guard de context begrijpen met betrekking tot de instructies en onveilige categoriedefinities die we eerder hebben gegeven en vaststellen dat het een veilige prompt is en niet gerelateerd aan geweld.
Nu u heeft bevestigd dat de invoertekst veilig is met betrekking tot uw Llama Guard-inhoudscategorieën, kunt u deze payload doorgeven aan het geïmplementeerde Llama-2 7B-model om tekst te genereren:
Hieronder volgt de reactie van het model:
Ten slotte wilt u wellicht bevestigen dat de antwoordtekst van het model veilige inhoud bevat. Hier breidt u de LLM-uitvoerreactie uit op de invoerberichten en voert u dit hele gesprek via Llama Guard uit om ervoor te zorgen dat het gesprek veilig is voor uw toepassing:
Mogelijk ziet u de volgende uitvoer, die aangeeft dat de reactie van het chatmodel veilig is:
Opruimen
Nadat u de eindpunten hebt getest, moet u ervoor zorgen dat u de SageMaker-inferentie-eindpunten en het model verwijdert om te voorkomen dat er kosten in rekening worden gebracht.
Conclusie
In dit bericht hebben we je laten zien hoe je input en output kunt modereren met Llama Guard en hoe je vangrails kunt plaatsen voor input en output van LLM's in SageMaker JumpStart.
Naarmate AI zich blijft ontwikkelen, is het van cruciaal belang om prioriteit te geven aan verantwoorde ontwikkeling en implementatie. Tools als CyberSecEval en Llama Guard van Purple Llama spelen een belangrijke rol bij het bevorderen van veilige innovatie en bieden vroegtijdige risico-identificatie en begeleiding voor taalmodellen. Deze moeten worden ingebakken in het AI-ontwerpproces om vanaf dag 1 het volledige potentieel van LLM’s ethisch te benutten.
Probeer Llama Guard en andere funderingsmodellen vandaag nog in SageMaker JumpStart en laat ons uw feedback weten!
Deze richtlijnen zijn uitsluitend bedoeld ter informatie. U dient nog steeds uw eigen onafhankelijke beoordeling uit te voeren en maatregelen te nemen om ervoor te zorgen dat u voldoet aan uw eigen specifieke kwaliteitscontrolepraktijken en -normen, en aan de lokale regels, wetten, voorschriften, licenties en gebruiksvoorwaarden die op u, uw inhoud, en het model van derden waarnaar in deze handleiding wordt verwezen. AWS heeft geen controle of autoriteit over het model van derden waarnaar in deze richtlijnen wordt verwezen, en geeft geen enkele verklaring of garantie dat het model van derden veilig, virusvrij, operationeel of compatibel is met uw productieomgeving en standaarden. AWS geeft geen verklaringen, garanties of garanties dat de informatie in deze handleiding tot een bepaalde uitkomst of resultaat zal leiden.
Over de auteurs
 Dr Kyle Ulrich is een Applied Scientist met de Ingebouwde algoritmen van Amazon SageMaker team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
Dr Kyle Ulrich is een Applied Scientist met de Ingebouwde algoritmen van Amazon SageMaker team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
 Evan Kravitz is een software-ingenieur bij Amazon Web Services en werkt aan SageMaker JumpStart. Hij is geïnteresseerd in de samenloop van machine learning met cloud computing. Evan behaalde zijn bachelordiploma aan de Cornell University en zijn masterdiploma aan de University of California, Berkeley. In 2021 presenteerde hij op de ICLR-conferentie een paper over vijandige neurale netwerken. In zijn vrije tijd houdt Evan van koken, reizen en hardlopen in New York City.
Evan Kravitz is een software-ingenieur bij Amazon Web Services en werkt aan SageMaker JumpStart. Hij is geïnteresseerd in de samenloop van machine learning met cloud computing. Evan behaalde zijn bachelordiploma aan de Cornell University en zijn masterdiploma aan de University of California, Berkeley. In 2021 presenteerde hij op de ICLR-conferentie een paper over vijandige neurale netwerken. In zijn vrije tijd houdt Evan van koken, reizen en hardlopen in New York City.
 Rachna Chadha is Principal Solution Architect AI/ML in Strategic Accounts bij AWS. Rachna is een optimist die gelooft dat ethisch en verantwoord gebruik van AI de samenleving in de toekomst kan verbeteren en economische en sociale welvaart kan brengen. In haar vrije tijd brengt Rachna graag tijd door met haar gezin, wandelen en naar muziek luisteren.
Rachna Chadha is Principal Solution Architect AI/ML in Strategic Accounts bij AWS. Rachna is een optimist die gelooft dat ethisch en verantwoord gebruik van AI de samenleving in de toekomst kan verbeteren en economische en sociale welvaart kan brengen. In haar vrije tijd brengt Rachna graag tijd door met haar gezin, wandelen en naar muziek luisteren.
 Dr Ashish Khetan is een Senior Applied Scientist met ingebouwde algoritmen van Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
Dr Ashish Khetan is een Senior Applied Scientist met ingebouwde algoritmen van Amazon SageMaker en helpt bij het ontwikkelen van algoritmen voor machine learning. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
 Karel Albertsen leidt product, engineering en wetenschap voor Amazon SageMaker Algorithms en JumpStart, SageMaker's machine learning-hub. Hij is gepassioneerd door het toepassen van machine learning om bedrijfswaarde te ontsluiten.
Karel Albertsen leidt product, engineering en wetenschap voor Amazon SageMaker Algorithms en JumpStart, SageMaker's machine learning-hub. Hij is gepassioneerd door het toepassen van machine learning om bedrijfswaarde te ontsluiten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/

