Klanten worden geconfronteerd met toenemende veiligheidsbedreigingen en kwetsbaarheden in de infrastructuur en applicatiebronnen naarmate hun digitale voetafdruk is uitgebreid en de zakelijke impact van die digitale activa is toegenomen. Een veel voorkomende uitdaging op het gebied van cyberbeveiliging is tweeledig:
- Het verbruiken van logbestanden uit digitale bronnen in verschillende formaten en schema's en het automatiseren van de analyse van bevindingen over bedreigingen op basis van die logbestanden.
- Of logs nu afkomstig zijn van Amazon Web Services (AWS), andere cloudproviders, on-premises of edge-apparaten, klanten moeten beveiligingsgegevens centraliseren en standaardiseren.
Bovendien moeten de analyses voor het identificeren van veiligheidsbedreigingen in staat zijn om te schalen en te evolueren om tegemoet te komen aan een veranderend landschap van bedreigingsactoren, veiligheidsvectoren en digitale activa.
Een nieuwe aanpak om dit complexe scenario voor beveiligingsanalyses op te lossen, combineert de opname en opslag van beveiligingsgegevens met behulp van Amazon Beveiligingsmeer en het analyseren van de beveiligingsgegevens met behulp van machine learning (ML). Amazon Sage Maker. Amazon Security Lake is een speciaal gebouwde service die de beveiligingsgegevens van een organisatie vanuit cloud- en lokale bronnen automatisch centraliseert in een speciaal gebouwd datameer dat is opgeslagen in uw AWS-account. Amazon Security Lake automatiseert het centrale beheer van beveiligingsgegevens, normaliseert logboeken van geïntegreerde AWS-services en services van derden en beheert de levenscyclus van gegevens met aanpasbare retentie en automatiseert ook opslaglagen. Amazon Security Lake neemt logbestanden op in de Open het cyberbeveiligingsschemaraamwerk (OCSF)-formaat, met ondersteuning voor partners zoals Cisco Security, CrowdStrike, Palo Alto Networks en OCSF-logboeken van bronnen buiten uw AWS-omgeving. Dit uniforme schema stroomlijnt het downstream-verbruik en de analyses omdat de gegevens een gestandaardiseerd schema volgen en nieuwe bronnen kunnen worden toegevoegd met minimale wijzigingen in de datapijplijn. Nadat de beveiligingsloggegevens zijn opgeslagen in Amazon Security Lake, rijst de vraag hoe deze moeten worden geanalyseerd. Een effectieve aanpak voor het analyseren van de beveiligingsloggegevens is het gebruik van ML; in het bijzonder anomaliedetectie, waarbij activiteits- en verkeersgegevens worden onderzocht en vergeleken met een basislijn. De basislijn definieert welke activiteit statistisch normaal is voor die omgeving. De detectie van afwijkingen reikt verder dan een individuele gebeurtenissignatuur, en kan evolueren met periodieke herscholing; verkeer dat als abnormaal of abnormaal is geclassificeerd, kan vervolgens met geprioriteerde focus en urgentie worden aangepakt. Amazon SageMaker is een volledig beheerde service waarmee klanten gegevens kunnen voorbereiden en ML-modellen kunnen bouwen, trainen en implementeren voor elk gebruiksscenario met een volledig beheerde infrastructuur, tools en workflows, inclusief aanbiedingen zonder code voor bedrijfsanalisten. SageMaker ondersteunt twee ingebouwde algoritmen voor anomaliedetectie: IP-inzichten en Willekeurig gekapt bos. U kunt SageMaker ook gebruiken om uw eigen aangepaste detectiemodel voor uitschieters te maken met behulp van algoritmen afkomstig van meerdere ML-frameworks.
In dit bericht leert u hoe u gegevens uit Amazon Security Lake voorbereidt en vervolgens een ML-model traint en implementeert met behulp van een IP Insights-algoritme in SageMaker. Dit model identificeert afwijkend netwerkverkeer of gedrag dat vervolgens kan worden samengesteld als onderdeel van een grotere end-to-end beveiligingsoplossing. Een dergelijke oplossing kan een multi-factor authenticatie (MFA)-controle uitvoeren als een gebruiker zich aanmeldt vanaf een ongebruikelijke server of op een ongebruikelijk tijdstip, het personeel op de hoogte stellen als er een verdachte netwerkscan afkomstig is van nieuwe IP-adressen, beheerders waarschuwen als er een ongebruikelijk netwerk wordt gescand protocollen of poorten worden gebruikt, of verrijk het classificatieresultaat van IP-inzichten met andere gegevensbronnen zoals Amazone-wachtdienst en IP-reputatiescores om bevindingen over bedreigingen te rangschikken.
Overzicht oplossingen
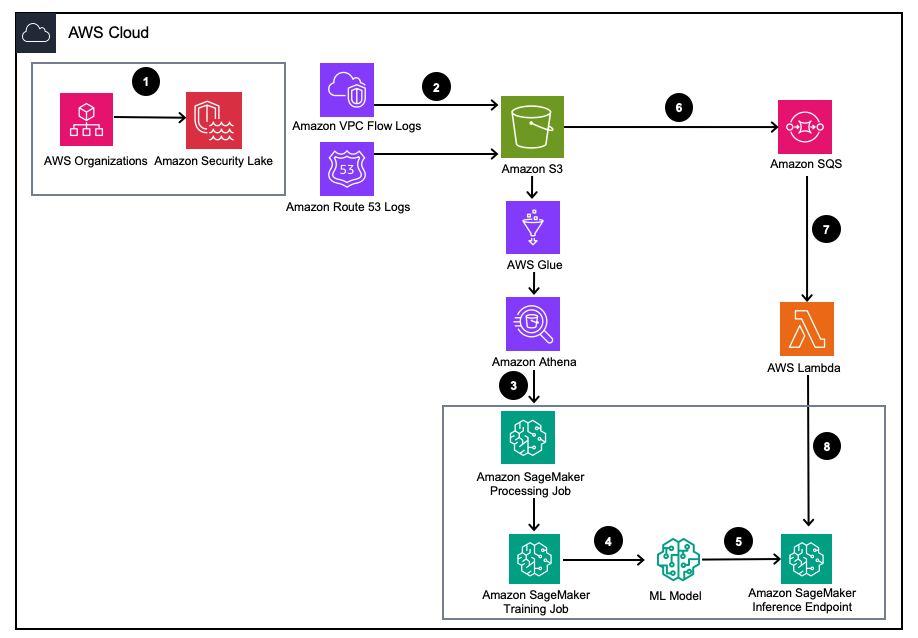
Figuur 1 – Oplossingsarchitectuur
- Schakel Amazon Security Lake in met AWS-organisaties voor AWS-accounts, AWS-regio's en externe IT-omgevingen.
- Stel Security Lake-bronnen in van Amazon virtuele privécloud (Amazon VPC) Stroomlogboeken en Amazoneroute53 DNS logt in bij de Amazon Security Lake S3-bucket.
- Verwerk Amazon Security Lake-loggegevens met behulp van een SageMaker Processing-taak om functies te ontwikkelen. Gebruik Amazone Athene om gestructureerde OCSF-loggegevens op te vragen Eenvoudige opslagservice van Amazon (Amazon S3) door AWS lijm tabellen beheerd door AWS LakeFormation.
- Train een SageMaker ML-model met behulp van een SageMaker Training-taak die de verwerkte Amazon Security Lake-logboeken gebruikt.
- Implementeer het getrainde ML-model op een SageMaker-inferentie-eindpunt.
- Bewaar nieuwe beveiligingslogboeken in een S3-bucket en zet gebeurtenissen in de wachtrij Amazon Simple Queue-service (Amazon SQS).
- Abonneer een AWS Lambda functie naar de SQS-wachtrij.
- Roep het SageMaker-inferentie-eindpunt aan met behulp van een Lambda-functie om beveiligingslogboeken in realtime als afwijkingen te classificeren.
Voorwaarden
Om de oplossing te implementeren, moet u eerst aan de volgende vereisten voldoen:
- Schakel Amazon Security Lake in binnen uw organisatie of één account waarbij zowel VPC Flow Logs als Route 53-resolverlogs zijn ingeschakeld.
- Zorg ervoor dat de AWS identiteits- en toegangsbeheer (IAM) De rol die wordt gebruikt door SageMaker bij het verwerken van taken en notebooks heeft een IAM-beleid gekregen, inclusief de Amazon Security Lake-abonnee vraagt toegangsrechten op voor de beheerde Amazon Security Lake-database en tabellen beheerd door AWS Lake Formation. Deze verwerkingstaak moet worden uitgevoerd vanuit een account voor analyse- of beveiligingstools om aan de regelgeving te blijven voldoen AWS-beveiligingsreferentiearchitectuur (AWS SRA).
- Zorg ervoor dat aan de IAM-rol die door de Lambda-functie wordt gebruikt, een IAM-beleid is toegekend, inclusief de Toestemming voor toegang tot gegevens van Amazon Security Lake-abonnees.
Implementeer de oplossing
Voer de volgende stappen uit om de omgeving in te stellen:
- Lanceer een SageMaker Studio of SageMaker Jupyter-notebook met een
ml.m5.largeaanleg. Opmerking: De instantiegrootte is afhankelijk van de gegevenssets die u gebruikt. - Kloon de GitHub bewaarplaats.
- Open het notitieboek
01_ipinsights/01-01.amazon-securitylake-sagemaker-ipinsights.ipy. - Implementeer de voorzien van IAM-beleid en het bijbehorende IAM-vertrouwensbeleid voor uw SageMaker Studio Notebook-instantie om toegang te krijgen tot alle benodigde gegevens in S3, Lake Formation en Athena.
In deze blog wordt het relevante gedeelte van de code in de notebook besproken nadat deze in uw omgeving is geïmplementeerd.
Installeer de afhankelijkheden en importeer de vereiste bibliotheek
Gebruik de volgende code om afhankelijkheden te installeren, de vereiste bibliotheken te importeren en de SageMaker S3-bucket te maken die nodig is voor gegevensverwerking en modeltraining. Een van de vereiste bibliotheken, awswrangler, is een AWS SDK voor panda's-dataframe die wordt gebruikt om de relevante tabellen binnen de AWS Glue Data Catalog te bevragen en de resultaten lokaal op te slaan in een dataframe.
Query's uitvoeren in de Amazon Security Lake VPC-stroomlogboektabel
Dit codegedeelte gebruikt de AWS SDK voor panda's om de AWS Glue-tabel met betrekking tot VPC Flow Logs op te vragen. Zoals vermeld in de vereisten, worden Amazon Security Lake-tabellen beheerd door AWS Lake-formatie, dus alle juiste machtigingen moeten worden verleend aan de rol die door het SageMaker-notebook wordt gebruikt. Deze zoekopdracht zal meerdere dagen aan VPC-stroomlogboekverkeer verzamelen. De dataset die werd gebruikt tijdens de ontwikkeling van deze blog was klein. Afhankelijk van de schaal van uw gebruiksscenario moet u zich bewust zijn van de limieten van de AWS SDK voor panda's. Wanneer u terabyte-schaal overweegt, moet u rekening houden met AWS SDK voor panda-ondersteuning Modus.
Wanneer u het gegevensframe bekijkt, ziet u een uitvoer van een enkele kolom met algemene velden die u kunt vinden in de Netwerkactiviteit (4001) klasse van de OCSF.
Normaliseer de Amazon Security Lake VPC-stroomloggegevens naar het vereiste trainingsformaat voor IP Insights.
Het IP Insights-algoritme vereist dat de trainingsgegevens de CSV-indeling hebben en twee kolommen bevatten. De eerste kolom moet een ondoorzichtige tekenreeks zijn die overeenkomt met de unieke identificatie van een entiteit. De tweede kolom moet het IPv4-adres van de toegangsgebeurtenis van de entiteit zijn, in decimale puntnotatie. In de voorbeeldgegevensset voor deze blog is de unieke identificatie de exemplaar-ID's van EC2-instanties die zijn gekoppeld aan de instance_id waarde binnen de dataframe. Het IPv4-adres wordt afgeleid van de src_endpoint. Op basis van de manier waarop de Amazon Athena-query is gemaakt, hebben de geïmporteerde gegevens al het juiste formaat voor het trainen van een IP Insights-model, dus er is geen extra functie-engineering vereist. Als u de query op een andere manier wijzigt, moet u mogelijk extra feature-engineering toevoegen.
Query en normaliseer de logtabel van de Amazon Security Lake Route 53-resolver
Net zoals u hierboven deed, voert de volgende stap van de notebook een soortgelijke query uit op de Amazon Security Lake Route 53-resolvertabel. Omdat u alle OCSF-compatibele gegevens in dit notebook gaat gebruiken, blijven alle technische taken voor Route 53-resolverlogboeken hetzelfde als voor VPC-stroomlogboeken. Vervolgens combineert u de twee dataframes tot één dataframe dat wordt gebruikt voor training. Omdat de Amazon Athena-query de gegevens lokaal in het juiste formaat laadt, is er geen verdere feature-engineering vereist.
Ontvang het IP Insights-trainingsbeeld en train het model met de OCSF-gegevens
In dit volgende deel van de notebook traint u een ML-model op basis van het IP Insights-algoritme en gebruikt u het geconsolideerde dataframe van OCSF uit verschillende soorten logboeken. Een lijst met de IP Insights-hyperparmeters kunt u vinden hier. In het onderstaande voorbeeld hebben we hyperparameters geselecteerd die het best presterende model opleverden, bijvoorbeeld 5 voor epoch en 128 voor vector_dim. Omdat de trainingsdataset voor onze steekproef relatief klein was, hebben we gebruik gemaakt van een ml.m5.large voorbeeld. Hyperparameters en uw trainingsconfiguraties, zoals het aantal exemplaren en het exemplaartype, moeten worden gekozen op basis van uw objectieve statistieken en de grootte van uw trainingsgegevens. Een mogelijkheid die u binnen Amazon SageMaker kunt gebruiken om de beste versie van uw model te vinden, is Amazon SageMaker automatische modelafstemming dat zoekt naar het beste model over een reeks hyperparameterwaarden.
Implementeer het getrainde model en test met geldig en afwijkend verkeer
Nadat het model is getraind, implementeert u het model op een SageMaker-eindpunt en verzendt u een reeks unieke ID- en IPv4-adrescombinaties om uw model te testen. Bij dit codegedeelte wordt ervan uitgegaan dat er testgegevens zijn opgeslagen in uw S3-bucket. De testgegevens zijn een CSV-bestand, waarbij de eerste kolom instantie-ID's bevat en de tweede kolom IP's. Het wordt aanbevolen om geldige en ongeldige gegevens te testen om de resultaten van het model te zien. Met de volgende code wordt uw eindpunt geïmplementeerd.
Nu uw eindpunt is geïmplementeerd, kunt u nu gevolgtrekkingsverzoeken indienen om te bepalen of het verkeer mogelijk afwijkend is. Hieronder ziet u een voorbeeld van hoe uw geformatteerde gegevens eruit zouden moeten zien. In dit geval is de eerste kolom-ID een instantie-ID en is de tweede kolom een bijbehorend IP-adres, zoals hieronder weergegeven:
Nadat u uw gegevens in CSV-indeling heeft, kunt u de gegevens voor gevolgtrekking indienen met behulp van de code door uw .csv-bestand vanuit een S3-bucket te lezen.:
De uitvoer voor een IP Insights-model geeft aan hoe statistisch gezien verwacht wordt dat een IP-adres en een online bron zijn. Het bereik voor dit adres en deze bron is echter onbeperkt, dus er zijn overwegingen over hoe u kunt bepalen of een combinatie van exemplaar-ID en IP-adres als afwijkend moet worden beschouwd.
In het voorgaande voorbeeld zijn vier verschillende ID- en IP-combinaties aan het model toegevoegd. De eerste twee combinaties waren geldige exemplaar-ID- en IP-adrescombinaties die worden verwacht op basis van de trainingsset. De derde combinatie heeft de juiste unieke identificatie, maar een ander IP-adres binnen hetzelfde subnet. Het model moet vaststellen dat er sprake is van een bescheiden afwijking, aangezien de inbedding enigszins afwijkt van de trainingsgegevens. De vierde combinatie heeft een geldige unieke identificatie, maar een IP-adres van een niet-bestaand subnet binnen een VPC in de omgeving.
Opmerking: Normale en abnormale verkeersgegevens zullen veranderen op basis van uw specifieke gebruikssituatie, bijvoorbeeld: als u extern en intern verkeer wilt monitoren, heeft u een unieke identificatie nodig die is afgestemd op elk IP-adres en een schema om de externe identificaties te genereren.
Om te bepalen wat uw drempel moet zijn om te bepalen of verkeer abnormaal is, kunt u gebruik maken van bekend normaal en abnormaal verkeer. De stappen beschreven in dit voorbeeldnotitieboekje zijn als volgt:
- Construeer een testset die normaal verkeer representeert.
- Voeg abnormaal verkeer toe aan de dataset.
- Teken de verdeling van
dot_productscores voor het model op normaal verkeer en op afwijkend verkeer. - Selecteer een drempelwaarde die de normale subset onderscheidt van de abnormale subset. Deze waarde is gebaseerd op uw fout-positieve tolerantie
Zorg voor continue monitoring van nieuw VPC-stroomlogverkeer.
Om te demonstreren hoe dit nieuwe ML-model op een proactieve manier kan worden gebruikt met Amazon Security Lake, zullen we een Lambda-functie configureren die op elk apparaat moet worden aangeroepen. PutObject gebeurtenis binnen de door Amazon Security Lake beheerde bucket, met name de VPC-stroomlogboekgegevens. Binnen Amazon Security Lake bestaat het concept van een abonnee, die logs en gebeurtenissen van Amazon Security Lake gebruikt. Aan de Lambda-functie die op nieuwe gebeurtenissen reageert, moet een abonnement voor gegevenstoegang worden verleend. Abonnees voor gegevenstoegang worden op de hoogte gesteld van nieuwe Amazon S3-objecten voor een bron terwijl de objecten naar de Security Lake-bucket worden geschreven. Abonnees hebben rechtstreeks toegang tot de S3-objecten en ontvangen meldingen van nieuwe objecten via een abonnementseindpunt of door een Amazon SQS-wachtrij te pollen.
- Open de Beveiliging Lake-console.
- Selecteer in het navigatievenster abonnees.
- Kies op de pagina Abonnees Abonnee aanmaken.
- Voer in voor abonneegegevens
inferencelambdaFor Naam van abonnee en een optionele Omschrijving. - De Regio wordt automatisch ingesteld als uw momenteel geselecteerde AWS-regio en kan niet worden gewijzigd.
- Voor Logboek- en gebeurtenisbronnen, kiezen Specifieke logboek- en gebeurtenisbronnen En kies VPC-stroomlogboeken en Route 53-logboeken
- Voor Methode voor gegevenstoegang, kiezen S3.
- Voor AbonneegegevensGeef uw AWS-account-ID op van het account waar de Lambda-functie zich zal bevinden en een door de gebruiker opgegeven externe identiteitskaart.
Opmerking: Als u dit lokaal binnen een account doet, hoeft u geen externe ID te hebben. - Kies creëren.
De Lambda-functie maken
Om de Lambda-functie te maken en te implementeren, kunt u de volgende stappen uitvoeren of de vooraf gebouwde SAM-sjabloon implementeren 01_ipinsights/01.02-ipcheck.yaml in de GitHub-repository. Voor de SAM-sjabloon moet u de SQS ARN en de SageMaker-eindpuntnaam opgeven.
- Kies op de Lambda-console Maak functie.
- Kies Auteur vanaf nul.
- Voor Functie Naam, ga naar binnen
ipcheck. - Voor Runtime, kiezen Python 3.10.
- Voor Architectuurselecteer x86_64.
- Voor Uitvoeringsrolselecteer Een nieuwe rol maken met Lambda-machtigingen.
- Nadat u de functie hebt gemaakt, voert u de inhoud van het ipcheck.py bestand uit de GitHub-repository.
- Kies in het navigatievenster Omgevingsvariabelen.
- Kies Edit.
- Kies Voeg omgevingsvariabele toe.
- Voer voor de nieuwe omgevingsvariabele in
ENDPOINT_NAMEen voer voor waarde het eindpunt ARN in dat is uitgevoerd tijdens de implementatie van het SageMaker-eindpunt. - kies Bespaar.
- Kies Implementeren.
- Kies in het navigatievenster Configuratie.
- kies triggers.
- kies Trigger toevoegen.
- Onder Selecteer een bron, kiezen SQS.
- Onder SQS-wachtrijVoer de ARN in van de hoofd-SQS-wachtrij die is gemaakt door Security Lake.
- Vink het selectievakje aan voor Activeer trekker.
- kies Toevoegen.
Valideer Lambda-bevindingen
- Open de Amazon CloudWatch-console.
- Selecteer in het linkerdeelvenster Log groepen.
- Voer in de zoekbalk ipcheck in en selecteer vervolgens de loggroep met de naam
/aws/lambda/ipcheck. - Selecteer de meest recente logstream onder Streams loggen.
- In de logboeken zou u voor elk nieuw Amazon Security Lake-logboek de volgende resultaten moeten zien:
{'predictions': [{'dot_product': 0.018832731992006302}, {'dot_product': 0.018832731992006302}]}
Deze Lambda-functie analyseert voortdurend het netwerkverkeer dat wordt opgenomen door Amazon Security Lake. Hierdoor kunt u mechanismen bouwen om uw beveiligingsteams op de hoogte te stellen wanneer een opgegeven drempelwaarde wordt overschreden, wat zou duiden op afwijkend verkeer in uw omgeving.
Opruimen
Wanneer u klaar bent met het experimenteren met deze oplossing en om kosten voor uw account te voorkomen, ruimt u uw bronnen op door de S3-bucket en het SageMaker-eindpunt te verwijderen, de computer uit te schakelen die is gekoppeld aan de SageMaker Jupyter-notebook, de Lambda-functie te verwijderen en Amazon Security uit te schakelen Meer in uw account.
Conclusie
In dit bericht heb je geleerd hoe je netwerkverkeersgegevens afkomstig van Amazon Security Lake kunt voorbereiden voor machinaal leren, en vervolgens een ML-model hebt getraind en geïmplementeerd met behulp van het IP Insights-algoritme in Amazon SageMaker. Alle stappen die in het Jupyter-notebook worden beschreven, kunnen worden gerepliceerd in een end-to-end ML-pijplijn. Je hebt ook een AWS Lambda-functie geïmplementeerd die nieuwe Amazon Security Lake-logboeken gebruikte en gevolgtrekkingen indiende op basis van het getrainde anomaliedetectiemodel. De door AWS Lambda ontvangen ML-modelreacties kunnen beveiligingsteams proactief op de hoogte stellen van afwijkend verkeer wanneer aan bepaalde drempels wordt voldaan. Voortdurende verbetering van het model kan worden mogelijk gemaakt door uw beveiligingsteam te betrekken bij de lusbeoordelingen om te labelen of verkeer dat als afwijkend is geïdentificeerd al dan niet vals-positief was. Dit kan vervolgens worden toegevoegd aan uw trainingsset en ook aan uw trainingsset een verkeersdataset bij het bepalen van een empirische drempel. Dit model kan mogelijk afwijkend netwerkverkeer of gedrag identificeren, waarbij het kan worden opgenomen als onderdeel van een grotere beveiligingsoplossing om een MFA-controle te initiëren als een gebruiker zich aanmeldt vanaf een ongebruikelijke server of op een ongebruikelijk tijdstip, en het personeel te waarschuwen als er een verdachte situatie is netwerkscan afkomstig van nieuwe IP-adressen, of combineer de IP-inzichtscore met andere bronnen zoals Amazon Guard Duty om bevindingen over bedreigingen te rangschikken. Dit model kan aangepaste logboekbronnen bevatten, zoals Azure Flow Logs of on-premises logboeken door aangepaste bronnen toe te voegen aan uw Amazon Security Lake-implementatie.
In deel 2 van deze serie blogposts leert u hoe u een anomaliedetectiemodel kunt bouwen met behulp van de Willekeurig gekapt bos algoritme getraind met aanvullende Amazon Security Lake-bronnen die netwerk- en hostbeveiligingsloggegevens integreren en de classificatie van beveiligingsafwijkingen toepassen als onderdeel van een geautomatiseerde, uitgebreide oplossing voor beveiligingsmonitoring.
Over de auteurs
 Joe Morotti is Solutions Architect bij Amazon Web Services (AWS) en helpt Enterprise-klanten in het middenwesten van de VS. Hij heeft een breed scala aan technische rollen vervuld en geniet ervan om de kunst van de klant van het mogelijke te laten zien. In zijn vrije tijd brengt hij graag quality time door met zijn gezin om nieuwe plaatsen te verkennen en de prestaties van zijn sportteam te overanalyseren
Joe Morotti is Solutions Architect bij Amazon Web Services (AWS) en helpt Enterprise-klanten in het middenwesten van de VS. Hij heeft een breed scala aan technische rollen vervuld en geniet ervan om de kunst van de klant van het mogelijke te laten zien. In zijn vrije tijd brengt hij graag quality time door met zijn gezin om nieuwe plaatsen te verkennen en de prestaties van zijn sportteam te overanalyseren
 Bishr Tabbaa is een oplossingsarchitect bij Amazon Web Services. Bishr is gespecialiseerd in het helpen van klanten met toepassingen voor machine learning, beveiliging en observatie. Buiten zijn werk houdt hij van tennissen, koken en tijd doorbrengen met zijn gezin.
Bishr Tabbaa is een oplossingsarchitect bij Amazon Web Services. Bishr is gespecialiseerd in het helpen van klanten met toepassingen voor machine learning, beveiliging en observatie. Buiten zijn werk houdt hij van tennissen, koken en tijd doorbrengen met zijn gezin.
 Sriharsh Adari is Senior Solutions Architect bij Amazon Web Services (AWS), waar hij klanten helpt terug te werken vanuit bedrijfsresultaten om innovatieve oplossingen op AWS te ontwikkelen. In de loop der jaren heeft hij meerdere klanten geholpen bij transformaties van dataplatforms in verschillende branches. Zijn kernexpertise omvat technologiestrategie, data-analyse en datawetenschap. In zijn vrije tijd speelt hij graag tennis, bingewatcht hij tv-shows en speelt hij graag Tabla.
Sriharsh Adari is Senior Solutions Architect bij Amazon Web Services (AWS), waar hij klanten helpt terug te werken vanuit bedrijfsresultaten om innovatieve oplossingen op AWS te ontwikkelen. In de loop der jaren heeft hij meerdere klanten geholpen bij transformaties van dataplatforms in verschillende branches. Zijn kernexpertise omvat technologiestrategie, data-analyse en datawetenschap. In zijn vrije tijd speelt hij graag tennis, bingewatcht hij tv-shows en speelt hij graag Tabla.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/identify-cybersecurity-anomalies-in-your-amazon-security-lake-data-using-amazon-sagemaker/

