
작성자 별 이미지
세계 굴지의 AI 연구 기업 중 하나인 미스트랄 AI(Mistral AI)가 최근 AI 기반 모델을 공개했다. 미스트랄 7B v0.2.
이 오픈소스 언어 모델은 23년 2024월 XNUMX일 회사의 해커톤 이벤트에서 공개되었습니다.
Mistral 7B 모델에는 7.3억 개의 매개변수가 있어 매우 강력합니다. 거의 모든 벤치마크에서 Llama 2 13B 및 Llama 1 34B보다 성능이 뛰어납니다. 최신 V0.2 모델은 32k 컨텍스트 창을 도입하여 텍스트 처리 및 생성 기능을 향상시켰습니다.
또한 최근 발표된 버전은 지난해 초 출시된 명령어 튜닝 변형 'Mistral-7B-Instruct-V0.2'의 기본 모델이다.
이 튜토리얼에서는 Hugging Face에서 이 언어 모델에 액세스하고 미세 조정하는 방법을 보여 드리겠습니다.
Hugging Face의 AutoTrain 기능을 사용하여 Mistral 7B-v0.2 기본 모델을 미세 조정할 예정입니다.
포옹하는 얼굴 머신러닝 모델에 대한 액세스를 민주화하여 일반 사용자가 고급 AI 솔루션을 개발할 수 있도록 하는 것으로 유명합니다.
Hugging Face의 기능인 AutoTrain은 모델 훈련 프로세스를 자동화하여 접근 가능하고 효율적으로 만듭니다.
이는 모델을 미세 조정할 때 사용자가 최상의 매개변수와 훈련 기술을 선택하는 데 도움이 됩니다. 이는 그렇지 않으면 어렵고 시간이 많이 소요될 수 있는 작업입니다.
Mistral-5B 모델을 미세 조정하는 7단계는 다음과 같습니다.
1. 환경 설정
먼저 Hugging Face로 계정을 생성한 후 모델 리포지토리를 생성해야 합니다.
이를 달성하려면 여기에 제공된 단계를 따르십시오. 링크 이 튜토리얼로 돌아오세요.
우리는 Python으로 모델을 훈련할 것입니다. 교육용 노트북 환경을 선택할 때 다음을 사용할 수 있습니다. 캐글 노트북 or 구글 콜랩, 둘 다 GPU에 대한 무료 액세스를 제공합니다.
훈련 프로세스가 너무 오래 걸리면 AWS Sagemaker 또는 Azure ML과 같은 클라우드 플랫폼으로 전환하는 것이 좋습니다.
마지막으로 이 튜토리얼에 따라 코딩을 시작하기 전에 다음 pip 설치를 수행하십시오.
!pip install -U autotrain-advanced
!pip install datasets transformers2. 데이터 세트 준비
이 튜토리얼에서는 알파카 데이터세트 Hugging Face는 다음과 같습니다.
우리는 명령과 출력 쌍에 따라 모델을 미세 조정하고 평가 프로세스에서 주어진 명령에 응답하는 능력을 평가할 것입니다.
이 데이터세트에 액세스하고 준비하려면 다음 코드 줄을 실행하세요.
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")첫 번째 함수는 "datasets" 라이브러리를 사용하여 Alpaca 데이터세트를 로드하고 정리하여 빈 명령이 포함되지 않았는지 확인합니다. 두 번째 기능은 AutoTrain이 이해할 수 있는 형식으로 데이터를 구성합니다.
위 코드를 실행하면 지정된 경로에 데이터 세트가 로드되고 포맷되어 저장됩니다. 형식이 지정된 데이터세트를 열면 'formatted_text'라는 라벨이 붙은 단일 열이 표시됩니다.
3. 훈련 환경 설정
이제 데이터 세트를 성공적으로 준비했으므로 모델 학습 환경 설정을 진행해 보겠습니다.
이렇게 하려면 다음 매개변수를 정의해야 합니다.
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'위의 사양을 분석하면 다음과 같습니다.
- 무엇이든 지정할 수 있습니다. 프로젝트 _ 이름. 여기에는 모든 프로젝트와 교육 파일이 저장됩니다.
- XNUMXD덴탈의 모델명 매개변수는 미세 조정하려는 모델입니다. 이 경우에는 경로를 지정했습니다. Mistral-7B v0.2 기본 모델 포옹 얼굴에.
- XNUMXD덴탈의 hf_token 변수는 다음으로 이동하여 얻을 수 있는 Hugging Face 토큰으로 설정되어야 합니다. 이 링크.
- 너의 repo_id 이 튜토리얼의 첫 번째 단계에서 생성한 Hugging Face 모델 저장소로 설정되어야 합니다. 예를 들어 내 저장소 ID는 다음과 같습니다. 나타샤S/Model2.
4. 모델 매개변수 구성
모델을 미세 조정하기 전에 훈련 기간 및 정규화와 같은 모델 동작의 측면을 제어하는 훈련 매개변수를 정의해야 합니다.
이러한 매개변수는 모델 학습 기간, 데이터에서 학습하는 방법, 과적합을 방지하는 방법과 같은 주요 측면에 영향을 미칩니다.
모델에 대해 다음 매개변수를 설정할 수 있습니다.
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. 환경변수 설정
이제 몇 가지 환경 변수를 설정하여 훈련 환경을 준비해 보겠습니다.
이 단계에서는 AutoTrain 기능이 원하는 설정을 사용하여 프로젝트 이름 및 교육 기본 설정과 같은 모델을 미세 조정하도록 합니다.
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. 모델 훈련 시작
마지막으로 다음을 사용하여 모델 학습을 시작하겠습니다. 자동열차 명령. 이 단계에는 아래와 같이 모델, 데이터 세트 및 학습 구성을 지정하는 작업이 포함됩니다.
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )변경하십시오 데이터 경로 훈련 데이터 세트가 있는 위치로 이동합니다.
7. 모델 평가
모델 학습이 완료되면 프로젝트 이름과 동일한 제목의 폴더가 디렉터리에 표시됩니다.
제 경우에는 이 폴더의 제목이 '미스트랄라이,” 아래 이미지에서 볼 수 있듯이 :
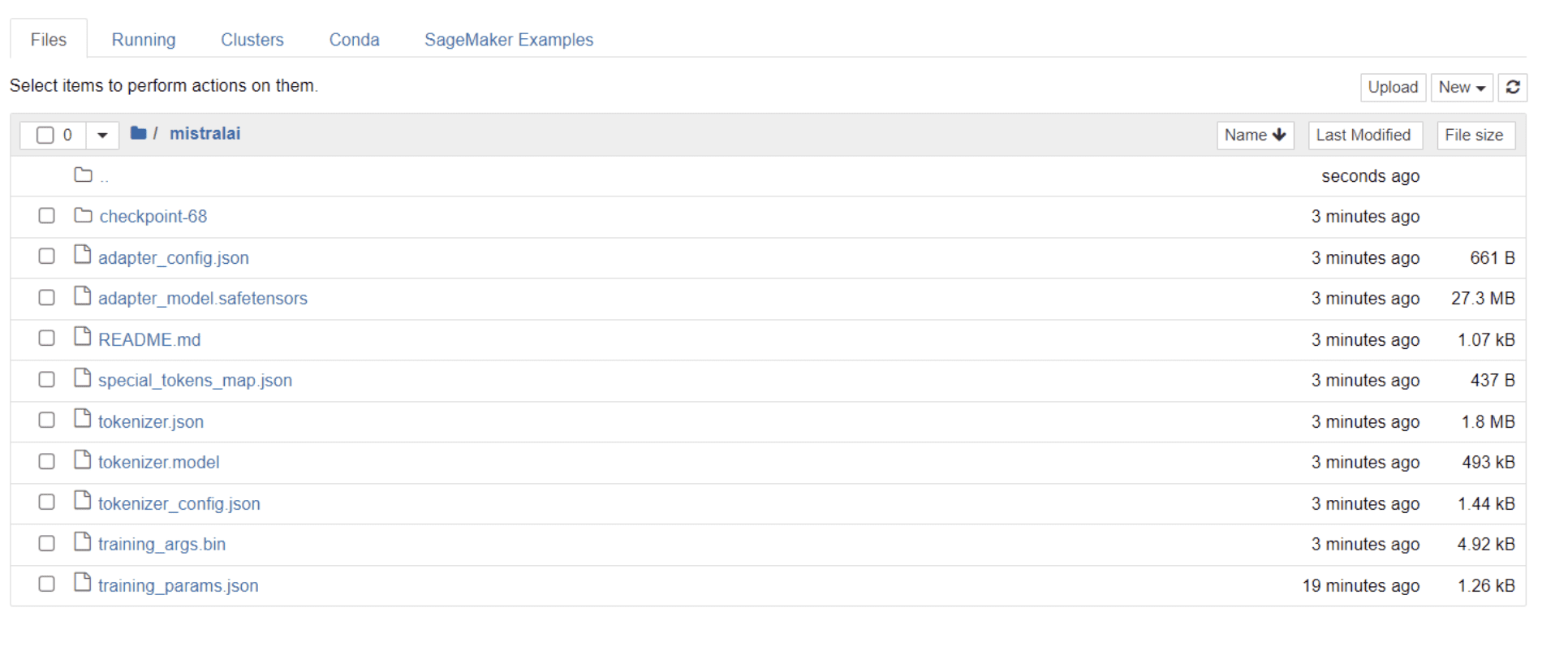
이 폴더 내에서 모델 가중치, 하이퍼파라미터 및 아키텍처 세부 정보를 포함하는 파일을 찾을 수 있습니다.
이제 이 미세 조정된 모델이 데이터 세트의 질문에 정확하게 응답할 수 있는지 확인해 보겠습니다. 이를 달성하려면 먼저 다음 코드 줄을 실행하여 데이터 세트에서 5개의 샘플 입력 및 출력을 생성해야 합니다.
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")5개의 샘플 데이터 포인트를 보여주는 다음과 같은 응답이 표시됩니다.
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.위의 명령 중 하나를 모델에 입력하고 정확한 출력이 생성되는지 확인하겠습니다. 다음은 모델에 명령을 제공하고 모델로부터 응답을 받는 함수입니다.
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer마지막으로 아래와 같이 이 함수에 질문을 입력합니다.
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)모델은 아래와 같이 훈련 데이터 세트의 해당 출력과 동일한 응답을 생성해야 합니다.
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business and지정된 토큰 수로 인해 응답이 불완전하거나 끊어진 것처럼 보일 수 있습니다. 보다 확장된 응답을 허용하려면 "max_length" 값을 자유롭게 조정하세요.
여기까지 오셨다면 축하드립니다!
Hugging Face의 기능과 함께 Mistral 7B v-0.2의 성능을 활용하여 최첨단 언어 모델을 성공적으로 미세 조정했습니다.
그러나 여정은 여기서 끝나지 않습니다.
다음 단계에서는 모델 성능을 최적화하기 위해 다양한 데이터세트를 실험하거나 특정 훈련 매개변수를 조정하는 것이 좋습니다. 더 큰 규모로 모델을 미세 조정하면 유용성이 향상되므로 더 큰 데이터 세트나 PDF 및 텍스트 파일과 같은 다양한 형식으로 실험해 보세요.
이러한 경험은 조직에서 종종 지저분하고 구조화되지 않은 실제 데이터로 작업할 때 매우 중요합니다.
나타샤 셀 바라지 글쓰기에 대한 열정을 갖고 독학한 데이터 과학자입니다. 나타샤는 데이터 과학과 관련된 모든 것에 대해 글을 쓰고 있으며, 모든 데이터 주제의 진정한 대가입니다. 당신은 그녀와 연결할 수 있습니다 링크드인 또는 그녀를 확인 YouTube 채널.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

