개요
비디오로 채팅하는 것이 얼마나 좋은지 궁금한 적이 있습니까? 블로그를 하는 사람으로서 관련 정보를 찾기 위해 3.5시간 분량의 비디오를 보는 것이 지루할 때가 많습니다. 때로는 비디오에서 유용한 정보를 얻기 위해 비디오를 보는 것이 직업처럼 느껴집니다. 그래서 유튜브 영상이든 어떤 영상이든 채팅할 수 있는 챗봇을 만들었습니다. 이것은 GPT-XNUMX-turbo, Langchain, ChromaDB, Whisper 및 Gradio에 의해 가능해졌습니다. 그래서 이 글에서는 Langchain으로 유튜브 동영상을 위한 기능적인 챗봇을 구축하는 코드 워크스루를 할 것입니다.
학습 목표
- Gradio를 사용하여 웹 인터페이스 구축
- Whisper를 사용하여 YouTube 비디오를 처리하고 텍스트 데이터를 추출합니다.
- 텍스트를 적절하게 처리하고 서식 지정
- 텍스트 데이터 임베딩 생성
- 데이터를 저장하도록 Chroma DB 구성
- OpenAI chatGPT, ChromaDB 및 임베딩 기능으로 Langchain 대화 체인 초기화
- 마지막으로 Gradio 챗봇에 대한 쿼리 및 스트리밍 답변
코딩 부분에 도달하기 전에 사용할 도구와 기술에 익숙해지도록 합시다.
이 기사는 데이터 과학 블로그.
차례
랭체인
Langchain은 대규모 언어 모델 데이터를 인식하고 에이전트로 만드는 Python으로 작성된 오픈 소스 도구입니다. 그래서 그게 무슨 뜻입니까? GPT-3.5 및 GPT-4와 같이 상업적으로 사용 가능한 대부분의 LLM은 훈련되는 데이터에 제한이 있습니다. 예를 들어 ChatGPT는 이미 본 질문에만 답변할 수 있습니다. 2021년 XNUMX월 이후는 아무것도 알 수 없습니다. 이것이 Langchain이 해결하는 핵심 문제입니다. Word 문서든 개인용 PDF든 LLM에 데이터를 공급하고 사람과 같은 응답을 얻을 수 있습니다. 벡터 DB, 채팅 모델 및 포함 기능과 같은 도구에 대한 래퍼가 있어 Langchain만 사용하여 AI 애플리케이션을 쉽게 구축할 수 있습니다.
Langchain을 사용하면 LLM 봇인 에이전트를 구축할 수도 있습니다. 이러한 자율 에이전트는 데이터 분석, SQL 쿼리 및 기본 코드 작성을 비롯한 여러 작업에 대해 구성할 수 있습니다. 이러한 에이전트를 사용하여 자동화할 수 있는 많은 것들이 있습니다. 낮은 수준의 지식 작업을 LLM에 아웃소싱하여 시간과 에너지를 절약할 수 있으므로 도움이 됩니다.
이 프로젝트에서는 Langchain 도구를 사용하여 비디오용 채팅 앱을 빌드합니다. Langchain에 대한 자세한 내용은 공식 사이트.
속삭임
속삭임 OpenAI의 또 다른 자손입니다. 오디오 또는 비디오를 텍스트로 변환할 수 있는 범용 음성-텍스트 모델입니다. 다국어 번역, 음성 인식 및 분류를 수행하기 위해 많은 양의 다양한 오디오를 학습합니다.
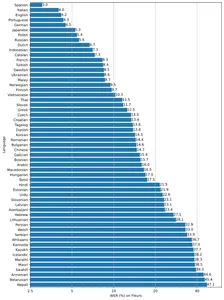
이 모델은 소형, 기본, 중형, 소형 및 대형의 2가지 크기로 제공되며 속도와 정확도는 절충됩니다. 모델의 성능도 언어에 따라 다릅니다. 아래 그림은 large-vXNUMX 모델을 사용하여 Fleur 데이터 세트의 언어별 WER(Word Error Rate) 분석을 보여줍니다.
벡터 데이터베이스
대부분의 기계 학습 알고리즘은 이미지, 오디오, 비디오 및 텍스트와 같은 구조화되지 않은 원시 데이터를 처리할 수 없습니다. 그것들은 벡터 임베딩의 행렬로 변환되어야 합니다. 이러한 벡터 임베딩은 다차원 평면에서 해당 데이터를 나타냅니다. 임베딩을 얻으려면 데이터의 의미론적 의미를 캡처할 수 있는 매우 효율적인 딥 러닝 모델이 필요합니다. 이는 모든 AI 앱을 만드는 데 매우 중요합니다. 이 데이터를 저장하고 쿼리하려면 데이터를 효과적으로 처리할 수 있는 데이터베이스가 필요합니다. 이로 인해 벡터 데이터베이스라는 특수 데이터베이스가 생성되었습니다. 여러 오픈 소스 데이터베이스가 있습니다. Chroma, Milvus, Weaviate 및 FAISS가 가장 인기 있는 제품입니다.
벡터 저장소의 또 다른 USP는 비정형 데이터에서 고속 검색 작업을 수행할 수 있다는 것입니다. 임베딩을 얻으면 클러스터링, 검색, 정렬 및 분류에 사용할 수 있습니다. 데이터 포인트가 벡터 공간에 있기 때문에 데이터 포인트 사이의 거리를 계산하여 얼마나 밀접하게 관련되어 있는지 알 수 있습니다. Cosine Similarity, Euclidean Distance, KNN 및 ANN(Approximate Nearest Neighbour)과 같은 여러 알고리즘을 사용하여 유사한 데이터 포인트를 찾습니다.
우리는 크로마 벡터 스토어 – 오픈 소스 벡터 데이터베이스. Chroma에는 Langchain 통합 기능도 있어 매우 편리합니다.
그라 디오
우리 앱 Gradio의 네 번째 기수는 기계 학습 모델을 쉽게 공유할 수 있는 오픈 소스 라이브러리입니다. 또한 Python을 사용하여 구성 요소 및 이벤트로 데모 웹 앱을 빌드하는 데 도움이 될 수 있습니다.
Gradio 및 Langchain에 익숙하지 않은 경우 계속 진행하기 전에 다음 기사를 읽으십시오.
이제 빌드를 시작하겠습니다.
개발 환경 설정
개발 환경을 설정하려면 Python을 만듭니다. 가상 환경 또는 Docker를 사용하여 로컬 개발 환경을 만듭니다.
이제 이러한 모든 종속성을 설치하십시오.
pytube==15.0.0
gradio == 3.27.0
openai == 0.27.4
langchain == 0.0.148
chromadb == 0.3.21
tiktoken == 0.3.3
openai-whisper==20230314 라이브러리 가져 오기
import os
import tempfile
import whisper
import datetime as dt
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from pytube import YouTube
from typing import TYPE_CHECKING, Any, Generator, List
웹 인터페이스 만들기
우리는 Gradio 블록과 구성 요소를 사용하여 애플리케이션의 프런트 엔드를 구축할 것입니다. 따라서 인터페이스를 만드는 방법은 다음과 같습니다. 당신이 적합하다고 생각하는대로 자유롭게 사용자 정의하십시오.
with gr.Blocks() as demo: with gr.Row(): # with gr.Group(): with gr.Column(scale=0.70): api_key = gr.Textbox(placeholder='Enter OpenAI API key', show_label=False, interactive=True).style(container=False) with gr.Column(scale=0.15): change_api_key = gr.Button('Change Key') with gr.Column(scale=0.15): remove_key = gr.Button('Remove Key') with gr.Row(): with gr.Column(): chatbot = gr.Chatbot(value=[]).style(height=650) query = gr.Textbox(placeholder='Enter query here', show_label=False).style(container=False) with gr.Column(): video = gr.Video(interactive=True,) start_video = gr.Button('Initiate Transcription') gr.HTML('OR') yt_link = gr.Textbox(placeholder='Paste a YouTube link here', show_label=False).style(container=False) yt_video = gr.HTML(label=True) start_ytvideo = gr.Button('Initiate Transcription') gr.HTML('Please reset the app after being done with the app to remove resources') reset = gr.Button('Reset App') if __name__ == "__main__": demo.launch() 인터페이스는 다음과 같이 나타납니다

여기에 OpenAI 키를 입력으로 사용하는 텍스트 상자가 있습니다. 또한 API 키를 변경하고 키를 삭제하기 위한 두 개의 키도 있습니다. 또한 왼쪽에는 채팅 UI가 있고 오른쪽에는 로컬 비디오를 렌더링하기 위한 상자가 있습니다. 비디오 상자 바로 아래에 YouTube 링크를 요청하는 상자와 "Initiate Transcription"이라는 버튼이 있습니다.
그라디오 이벤트
이제 이벤트를 정의하여 앱을 대화형으로 만듭니다. gr.Blocks() 끝에 아래 코드를 추가합니다.
start_video.click(fn=lambda :(pause, update_yt), outputs=[start2, yt_video]).then( fn=embed_video, inputs=, outputs=).success( fn=lambda:resume, outputs=[start2]) start_ytvideo.click(fn=lambda :(pause, update_video), outputs=[start1,video]).then( fn=embed_yt, inputs=[yt_link], outputs = [yt_video, chatbot]).success( fn=lambda:resume, outputs=[start1]) query.submit(fn=add_text, inputs=[chatbot, query], outputs=[chatbot]).success( fn=QuestionAnswer, inputs=[chatbot,query,yt_link,video], outputs=[chatbot,query]) api_key.submit(fn=set_apikey, inputs=api_key, outputs=api_key)
change_api_key.click(fn=enable_api_box, outputs=api_key) remove_key.click(fn = remove_key_box, outputs=api_key)
reset.click(fn = reset_vars, outputs=[chatbot,query, video, yt_video, ])- 시작_동영상: 클릭하면 비디오에서 텍스트를 가져오는 프로세스가 트리거되고 대화 체인이 생성됩니다.
- start_yt동영상: 클릭하면 동일한 작업을 수행하지만 지금은 YouTube 비디오에서 수행되며 완료되면 바로 아래에 YouTube 비디오가 렌더링됩니다.
- 질문: LLM에서 채팅 UI로의 스트리밍 응답을 담당합니다.
나머지 이벤트는 API 키를 처리하고 앱을 재설정하기 위한 것입니다.
이벤트를 정의했지만 이벤트 트리거를 담당하는 기능은 정의하지 않았습니다.
백엔드
복잡하고 지저분하게 만들지 않기 위해 백엔드에서 처리할 프로세스를 간략하게 설명합니다.
- API 키를 처리합니다.
- 업로드된 비디오를 처리합니다.
- 텍스트를 얻으려면 비디오를 기록하십시오.
- 비디오 텍스트에서 청크를 만듭니다.
- 텍스트에서 임베딩을 만듭니다.
- ChromaDB 벡터 저장소에 벡터 임베딩을 저장합니다.
- Langchain으로 대화형 검색 체인을 만듭니다.
- 관련 문서를 OpenAI 채팅 모델(gpt-3.5-turbo)로 보냅니다.
- 답변을 가져와 채팅 UI에서 스트리밍합니다.
몇 가지 예외 처리와 함께 이 모든 작업을 수행할 것입니다.
몇 가지 환경 변수를 정의합니다.
chat_history = []
result = None
chain = None
run_once_flag = False
call_to_load_video = 0 enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set', interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) pause = gr.Button.update(interactive=False)
resume = gr.Button.update(interactive=True)
update_video = gr.Video.update(value = None) update_yt = gr.HTML.update(value=None) API 키 처리
사용자가 키를 제출하면 환경 변수로 설정되며 추가 입력에서 텍스트 상자도 비활성화됩니다. 변경 키를 누르면 다시 변경 가능하게 됩니다. 키 제거를 클릭하면 키가 제거됩니다.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box
def enable_api_box(): return enable_box
def remove_key_box(): os.environ['OPENAI_API_KEY'] = '' return remove_box동영상 처리
다음으로 업로드된 동영상과 YouTube 링크를 다룰 것입니다. 각 경우를 처리하는 두 가지 기능이 있습니다. YouTube 링크의 경우 iframe 포함 링크를 생성합니다. 각각의 경우에 대해 다른 함수를 호출합니다. make_chain() 체인 생성을 담당합니다.
이 기능은 누군가 동영상을 업로드하거나 YouTube 링크를 제공하고 기록 버튼을 누를 때 트리거됩니다.
def embed_yt(yt_link: str): # This function embeds a YouTube video into the page. # Check if the YouTube link is valid. if not yt_link: raise gr.Error('Paste a YouTube link') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Set the global variable `call_to_load_video` to 0. # This is used to keep track of how many times the function has been called. call_to_load_video = 0 # Create a chain using the YouTube link. make_chain(url=yt_link) # Get the URL of the YouTube video. url = yt_link.replace('watch?v=', '/embed/') # Create the HTML code for the embedded YouTube video. embed_html = f"""<iframe width="750" height="315" src="{url}" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>""" # Return the HTML code and an empty list. return embed_html, [] def embed_video(video=str | None): # This function embeds a video into the page. # Check if the video is valid. if not video: raise gr.Error('Upload a Video') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Create a chain using the video. make_chain(video=video) # Return the video and an empty list. return video, []체인 만들기
이것은 가장 중요한 단계 중 하나입니다. 여기에는 Chroma 벡터 저장소 및 Langchain 체인 생성이 포함됩니다. 사용 사례에 대해 대화형 검색 체인을 사용합니다. OpenAI 임베딩을 사용하지만 실제 배포에는 Huggingface 문장 인코더 등과 같은 무료 임베딩 모델을 사용하십시오.
def make_chain(url=None, video=None) -> (ConversationalRetrievalChain | Any | None): global chain, run_once_flag # Check if a YouTube link or video is provided if not url and not video: raise gr.Error('Please provide a YouTube link or Upload a video') if not run_once_flag: run_once_flag = True # Get the title from the YouTube link or video title = get_title(url, video).replace(' ','-') # Process the text from the video grouped_texts, time_list = process_text(url=url) if url else process_text(video=video) # Convert time_list to metadata format time_list = [{'source': str(t.time())} for t in time_list] # Create vector stores from the processed texts with metadata vector_stores = Chroma.from_texts(texts=grouped_texts, collection_name='test', embedding=OpenAIEmbeddings(), metadatas=time_list) # Create a ConversationalRetrievalChain from the vector stores chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.0), retriever= vector_stores.as_retriever( search_kwargs={"k": 5}), return_source_documents=True) return chain
- YouTube URL 또는 동영상 파일에서 텍스트와 메타데이터를 가져옵니다.
- 텍스트 및 메타데이터에서 Chroma 벡터 저장소를 만듭니다.
- OpenAI gpt-3.5-turbo 및 크로마 벡터 저장소를 사용하여 체인을 구축합니다.
- 리턴 체인.
프로세스 텍스트
이 단계에서는 비디오에서 텍스트를 적절하게 슬라이싱하고 위의 체인 구축 프로세스에서 사용한 메타데이터 개체도 생성합니다.
def process_text(video=None, url=None) -> tuple[list, list[dt.datetime]]: global call_to_load_video if call_to_load_video == 0: print('yes') # Call the process_video function based on the given video or URL result = process_video(url=url) if url else process_video(video=video) call_to_load_video += 1 texts, start_time_list = [], [] # Extract text and start time from each segment in the result for res in result['segments']: start = res['start'] text = res['text'] start_time = dt.datetime.fromtimestamp(start) start_time_formatted = start_time.strftime("%H:%M:%S") texts.append(''.join(text)) start_time_list.append(start_time_formatted) texts_with_timestamps = dict(zip(texts, start_time_list)) # Convert the timestamp strings to datetime objects formatted_texts = { text: dt.datetime.strptime(str(timestamp), '%H:%M:%S') for text, timestamp in texts_with_timestamps.items() } grouped_texts = [] current_group = '' time_list = [list(formatted_texts.values())[0]] previous_time = None time_difference = dt.timedelta(seconds=30) # Group texts based on time difference for text, timestamp in formatted_texts.items(): if previous_time is None or timestamp - previous_time <= time_difference: current_group += text else: grouped_texts.append(current_group) time_list.append(timestamp) current_group = text previous_time = time_list[-1] # Append the last group of texts if current_group: grouped_texts.append(current_group) return grouped_texts, time_list
- process_text 함수는 URL 또는 비디오 경로를 사용합니다. 그런 다음 이 비디오는 process_video 함수에 전사되고 최종 텍스트를 얻습니다.
- 그런 다음 (Whisper에서) 각 문장의 시작 시간을 가져오고 30초 안에 그룹화합니다.
- 마지막으로 그룹화된 텍스트와 각 그룹의 시작 시간을 반환합니다.
프로세스 비디오
이 단계에서는 비디오 또는 오디오 파일을 전사하고 텍스트를 가져옵니다. 녹음에 Whisper 기본 모델을 사용합니다.
def process_video(video=None, url=None) -> dict[str, str | list]: if url: file_dir = load_video(url) else: file_dir = video print('Transcribing Video with whisper base model') model = whisper.load_model("base") result = model.transcribe(file_dir) return resultYouTube 동영상의 경우 직접 처리할 수 없으므로 별도로 처리해야 합니다. YouTube 동영상의 오디오 또는 동영상을 다운로드하기 위해 Pytube라는 라이브러리를 사용합니다. 그래서, 당신이 그것을 할 수 있는 방법은 다음과 같습니다.
def load_video(url: str) -> str: # This function downloads a YouTube video and returns the path to the downloaded file. # Create a YouTube object for the given URL. yt = YouTube(url) # Get the target directory. target_dir = os.path.join('/tmp', 'Youtube') # If the target directory does not exist, create it. if not os.path.exists(target_dir): os.mkdir(target_dir) # Get the audio stream of the video. stream = yt.streams.get_audio_only() # Download the audio stream to the target directory. print('----DOWNLOADING AUDIO FILE----') stream.download(output_path=target_dir) # Get the path of the downloaded file. path = target_dir + '/' + yt.title + '.mp4' # Return the path of the downloaded file. return path
- 주어진 URL에 대한 YouTube 개체를 만듭니다.
- 임시 대상 디렉토리 경로 생성
- 경로가 존재하는지 확인하십시오. 그렇지 않으면 디렉토리를 만드십시오.
- 파일의 오디오를 다운로드합니다.
- 비디오의 경로 디렉토리 가져오기
이것은 비디오에서 텍스트를 가져오는 것부터 체인을 만드는 것까지 상향식 프로세스였습니다. 이제 남은 것은 챗봇을 구성하는 것입니다.
챗봇 구성
이제 필요한 것은 쿼리와 chat_history를 보내서 답변을 가져오는 것입니다. 따라서 쿼리가 제출될 때만 트리거되는 함수를 정의합니다.
def add_text(history, text): if not text: raise gr.Error('enter text') history = history + [(text,'')] return history def QuestionAnswer(history, query=None, url=None, video=None) -> Generator[Any | None, Any, None]: # This function answers a question using a chain of models. # Check if a YouTube link or a local video file is provided. if video and url: # Raise an error if both a YouTube link and a local video file are provided. raise gr.Error('Upload a video or a YouTube link, not both') elif not url and not video: # Raise an error if no input is provided. raise gr.Error('Provide a YouTube link or Upload a video') # Get the result of processing the video. result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) # Add the question and answer to the chat history. chat_history += [(query, result["answer"])] # For each character in the answer, append it to the last element of the history. for char in result['answer']: history[-1][-1] += char yield history, ''
대화의 맥락을 유지하기 위해 쿼리와 함께 채팅 기록을 제공합니다. 마지막으로 답변을 다시 챗봇으로 스트리밍합니다. 모든 값을 재설정하려면 재설정 기능을 정의하는 것을 잊지 마십시오.
그래서 이것이 전부였습니다. 이제 응용 프로그램을 시작하고 비디오 채팅을 시작하십시오.
이것이 최종 제품의 모습입니다.
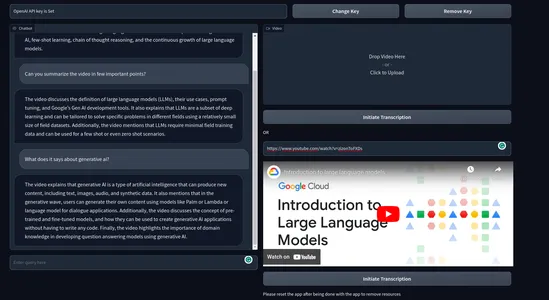
비디오 데모 :
[포함 된 콘텐츠]
실제 사용 사례
최종 사용자가 모든 비디오 또는 오디오와 채팅할 수 있는 애플리케이션은 다양한 사용 사례를 가질 수 있습니다. 다음은 이 챗봇의 실제 사용 사례입니다.
- 교육: 학생들은 종종 몇 시간짜리 비디오 강의를 듣습니다. 이 챗봇은 학생들이 강의 동영상을 통해 학습을 돕고 유용한 정보를 빠르게 추출하여 시간과 에너지를 절약할 수 있습니다. 이렇게 하면 학습 경험이 크게 향상됩니다.
- 적법한: 법률 전문가는 사건 분석, 문서 준비, 연구 또는 규정 준수 모니터링을 위해 긴 법적 절차 및 증언을 거치는 경우가 많습니다. 이와 같은 챗봇은 이러한 작업을 정리하는 데 큰 도움이 될 수 있습니다.
- 콘텐츠 요약: 이 앱은 비디오 콘텐츠를 분석하고 요약된 텍스트 버전을 생성할 수 있습니다. 이를 통해 사용자는 비디오를 완전히 보지 않고도 비디오의 하이라이트를 파악할 수 있습니다.
- 고객 상호 작용: 브랜드는 제품이나 서비스에 비디오 챗봇 기능을 통합할 수 있습니다. 이는 가격이 비싸거나 많은 설명이 필요한 제품이나 서비스를 판매하는 비즈니스에 도움이 될 수 있습니다.
- 비디오 번역: 텍스트 코퍼스를 다른 언어로 번역할 수 있습니다. 이것은 언어 간 의사소통, 언어 학습 또는 비원어민의 접근성을 용이하게 할 수 있습니다.
다음은 내가 생각할 수 있는 몇 가지 잠재적인 사용 사례입니다. 비디오용 챗봇의 훨씬 더 유용한 응용 프로그램이 있을 수 있습니다.
결론
따라서 비디오용 챗봇을 위한 기능적인 데모 웹 앱을 구축하는 것이 전부였습니다. 기사 전체에서 많은 개념을 다루었습니다. 다음은 기사의 주요 내용입니다.
- 우리는 AI 애플리케이션을 쉽게 만들 수 있는 인기 있는 도구인 Langchain에 대해 배웠습니다.
- Whisper는 OpenAI의 강력한 음성-텍스트 모델입니다. 오디오 및 비디오를 텍스트로 변환할 수 있는 오픈 소스 모델입니다.
- 벡터 데이터베이스가 벡터 임베딩의 효과적인 저장 및 쿼리를 용이하게 하는 방법을 배웠습니다.
- 우리는 Langchain, Chroma 및 OpenAI 모델을 사용하여 완전히 작동하는 웹 앱을 처음부터 구축했습니다.
- 우리는 또한 챗봇의 잠재적인 실제 사용 사례에 대해서도 논의했습니다.
이것이 전부였습니다. 마음에 드셨기를 바라며 저를 팔로우해 주세요. 트위터 개발과 관련된 더 많은 것들을 위해.
GitHub 저장소: sunilkumardash9/chatgpt-for-videos. 이것이 도움이 된다면 저장소를 ⭐ 수행하십시오.
자주 묻는 질문
A. LangChain은 대규모 언어 모델을 사용하여 애플리케이션 생성을 단순화하는 오픈 소스 프레임워크입니다. 챗봇, 문서 분석, 코드 분석, 질의 응답, 생성 작업 등 다양한 작업에 사용할 수 있습니다.
A. 체인은 순서대로 실행되는 일련의 단계입니다. 특정 작업이나 프로세스를 정의하는 데 사용됩니다. 예를 들어 체인을 사용하여 문서를 요약하거나 질문에 답하거나 창의적인 텍스트를 생성할 수 있습니다.
에이전트는 체인보다 더 복잡합니다. 어떤 단계를 실행할지 결정할 수 있고 경험을 통해 배울 수도 있습니다. 에이전트는 데이터 분석 및 코드 생성과 같이 많은 창의성이나 추론이 필요한 작업에 자주 사용됩니다.
A. 1. 액션: 액션 에이전트는 취할 액션을 결정하고 한 번에 한 단계씩 그 액션을 실행한다. 그들은 더 전통적이며 작은 작업에 적합합니다.
2. 계획 및 실행 에이전트는 먼저 수행할 작업 계획을 결정한 다음 해당 작업을 한 번에 하나씩 실행합니다. 더 복잡하고 더 많은 계획과 유연성이 필요한 작업에 적합합니다.
A. Langchain은 LLM과 채팅 모델을 통합할 수 있습니다. LLM은 문자열 입력을 받고 문자열 응답을 반환하는 모델입니다. 채팅 모델은 채팅 메시지 목록을 입력으로 사용하고 채팅 메시지를 출력합니다.
A. 예, Lagchain은 무료로 사용할 수 있는 오픈 소스 도구이지만 대부분의 작업에는 요금이 부과되는 OpenAI API 키가 필요합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/06/build-a-chatgpt-for-youtube-videos-with-langchain/

