개요
RAG(Retrieval Augmented-Generation)는 처음부터 폭풍으로 전 세계를 사로잡았습니다. RAG는 LLM(대형 언어 모델)이 정확하고 사실에 기반한 답변을 제공하거나 생성하는 데 필요한 것입니다. 우리는 RAG를 통해 LLM의 사실성을 해결합니다. 여기서는 LLM이 사용자 쿼리와 상황적으로 유사한 컨텍스트를 제공하여 LLM이 이 컨텍스트와 함께 작동하고 사실적으로 올바른 응답을 생성하도록 합니다. 이를 위해 데이터와 사용자 쿼리를 벡터 임베딩 형식으로 표현하고 코사인 유사성을 수행합니다. 그러나 문제는 모든 기존 접근 방식이 단일 임베딩으로 데이터를 표현한다는 것입니다. 이는 좋은 경우에는 이상적이지 않을 수 있습니다. 검색 시스템. 이 가이드에서는 기존 바이 인코더 모델보다 더 나은 정확도로 검색을 수행하는 ColBERT를 살펴보겠습니다.
학습 목표
- RAG의 검색이 높은 수준에서 작동하는 방식을 이해합니다.
- 검색 시 단일 임베딩 제한 사항을 이해합니다.
- ColBERT의 토큰 임베딩으로 검색 컨텍스트를 개선합니다.
- ColBERT의 늦은 상호작용이 어떻게 검색을 향상하는지 알아보세요.
- 정확한 검색을 위해 ColBERT로 작업하는 방법을 알아보세요.
이 기사는 데이터 과학 블로그.
차례
RAG란 무엇인가요?
LLM은 의미 있고 문법적으로 올바른 텍스트를 생성할 수 있지만 환각이라는 문제를 안고 있습니다. LLM의 환각 LLM이 자신있게 잘못된 답변을 생성하는 개념입니다. 즉, 그것이 사실이라고 믿게 만드는 방식으로 잘못된 답변을 구성합니다. 이는 LLM 도입 이후 주요 문제였습니다. 이러한 환각은 부정확하고 사실적으로 잘못된 답변으로 이어집니다. 따라서 검색 증강 생성(Retrieval Augmented Generation)이 도입되었습니다.
RAG에서는 문서 목록/문서 덩어리를 가져와 이러한 텍스트 문서를 벡터 임베딩이라는 숫자 표현으로 인코딩합니다. 여기서 단일 벡터 임베딩은 단일 문서 덩어리를 나타내고 이를 다음과 같은 데이터베이스에 저장합니다. 벡터 저장소. 이러한 청크를 임베딩으로 인코딩하는 데 필요한 모델을 인코딩 모델 또는 이중 인코더라고 합니다. 이러한 인코더는 대규모 데이터 코퍼스에 대해 학습되므로 단일 벡터 임베딩 표현으로 문서 덩어리를 인코딩할 수 있을 만큼 강력합니다.
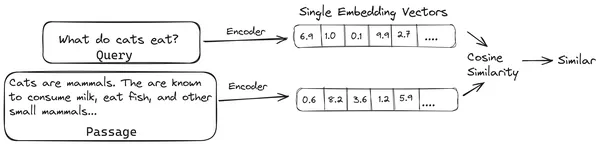
이제 사용자가 LLM에 쿼리를 요청하면 이 쿼리를 동일한 인코더에 제공하여 단일 벡터 임베딩을 생성합니다. 그런 다음 이 임베딩을 사용하여 문서 청크의 다양한 다른 벡터 임베딩과의 유사성 점수를 계산하여 문서의 가장 관련성이 높은 청크를 얻습니다. 가장 관련성이 높은 청크 또는 사용자 쿼리와 함께 가장 관련성이 높은 청크 목록이 LLM에 제공됩니다. 그런 다음 LLM은 이 추가 상황 정보를 수신한 다음 사용자 쿼리에서 받은 상황에 맞는 답변을 생성합니다. 이를 통해 LLM에서 생성된 콘텐츠가 사실이고 필요한 경우 역추적할 수 있는 콘텐츠인지 확인합니다.
기존 바이인코더의 문제점
all-miniLM과 같은 기존 인코더 모델의 문제점, OpenAI 임베딩 모델과 다른 인코더 모델은 전체 텍스트를 단일 벡터 임베딩 표현으로 압축한다는 점입니다. 이러한 단일 벡터 임베딩 표현은 유사한 문서를 효율적이고 빠르게 검색하는 데 도움이 되므로 유용합니다. 그러나 문제는 쿼리와 문서 간의 컨텍스트성에 있습니다. 단일 벡터 임베딩은 문서 청크의 문맥 정보를 저장하는 데 충분하지 않아 정보 병목 현상이 발생할 수 있습니다.
500개의 단어가 크기 782의 단일 벡터로 압축되고 있다고 상상해 보십시오. 단일 벡터 임베딩으로 이러한 청크를 표현하는 것만으로는 충분하지 않을 수 있으므로 대부분의 경우 검색 시 수준 이하의 결과를 제공합니다. 복잡한 쿼리나 문서의 경우 단일 벡터 표현이 실패할 수도 있습니다. 그러한 솔루션 중 하나는 단일 임베딩 벡터 대신 임베딩 벡터 목록으로 문서 청크 또는 쿼리를 나타내는 것입니다. 이것이 바로 ColBERT가 사용되는 곳입니다.
ColBERT란 무엇인가요?
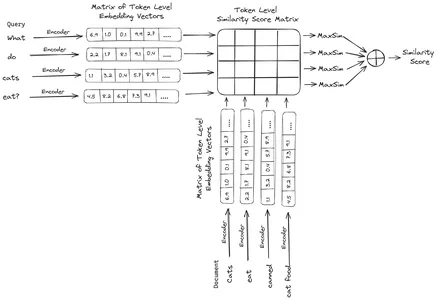
ColBERT(Contextual Late Interactions BERT)는 다중 벡터 임베딩 표현으로 텍스트를 나타내는 이중 인코더입니다. 쿼리 또는 문서 덩어리/작은 문서를 가져와 토큰 수준에서 벡터 임베딩을 생성합니다. 즉, 각 토큰은 자체 벡터 임베딩을 가지며 쿼리/문서는 토큰 수준 벡터 임베딩 목록으로 인코딩됩니다. 토큰 수준 임베딩은 사전 훈련된 데이터에서 생성됩니다. BERT 모델 따라서 이름은 BERT입니다.
그런 다음 벡터 데이터베이스에 저장됩니다. 이제 쿼리가 들어오면 이에 대한 토큰 수준 임베딩 목록이 생성된 다음 사용자 쿼리와 각 문서 간에 행렬 곱셈이 수행되어 유사성 점수가 포함된 행렬이 생성됩니다. 전반적인 유사성은 각 쿼리 토큰에 대한 문서 토큰 전체의 최대 유사성의 합을 취하여 달성됩니다. 이에 대한 공식은 아래 그림에서 볼 수 있습니다.
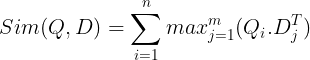
위 방정식에서는 쿼리 토큰 매트릭스(N 토큰 수준 벡터 임베딩 포함)와 문서 토큰 전치 매트릭스(M 토큰 수준 벡터 임베딩 포함) 사이에 내적을 수행한 다음 최대 유사성을 취하는 것을 볼 수 있습니다. 각 쿼리 토큰에 대한 문서 토큰을 교차합니다. 그런 다음 이러한 최대 유사성을 모두 합산하여 문서와 쿼리 간의 최종 유사성 점수를 제공합니다. 이것이 효과적이고 정확한 검색을 생성하는 이유는 여기서 토큰 수준 상호 작용이 있기 때문입니다. 이는 쿼리와 문서 간의 보다 상황에 맞는 이해를 위한 여지를 제공합니다.
ColBERT라는 이름이 붙은 이유는 무엇입니까?
자체적으로 임베딩 벡터 목록을 계산하고 모델 추론 중에 이 MaxSim(최대 유사성) 작업만 수행하므로 이를 늦은 상호 작용 단계라고 부르며, 토큰 수준 상호 작용을 통해 더 많은 상황 정보를 얻으므로 상황별이라고 합니다. 늦은 상호작용. 따라서 상황별 늦은 상호작용이라는 이름이 붙었습니다. BERT 또는 ColBERT. 이러한 계산은 병렬로 수행될 수 있으므로 효율적으로 계산할 수 있습니다. 마지막으로 한 가지 우려 사항은 공간입니다. 즉, 이 토큰 수준 벡터 임베딩 목록을 저장하려면 많은 공간이 필요합니다. 이 문제는 잔여 압축이라는 기술을 통해 임베딩을 압축하여 활용 공간을 최적화하는 ColBERTv2에서 해결되었습니다.
예제가 포함된 ColBERT 실습
이 섹션에서는 ColBERT를 직접 사용해 보고 일반 임베딩 모델과 비교하여 성능이 어떤지 확인합니다.
1단계: 라이브러리 다운로드
다음 라이브러리를 다운로드하는 것부터 시작하겠습니다.
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- 라가투이: 이 라이브러리를 사용하면 ColBERT와 같은 최첨단(SOTA) 검색 방법을 사용하기 쉬운 방식으로 사용할 수 있습니다. 데이터 세트에 대한 인덱스를 생성하고, 이에 대해 쿼리하고, 데이터에 대해 ColBERT 모델을 교육할 수도 있는 옵션을 제공합니다.
- 랭체인: 이 라이브러리를 사용하면 오픈 소스 임베딩 모델을 사용하여 ColBERT와 비교할 때 다른 임베딩 모델이 얼마나 잘 작동하는지 테스트할 수 있습니다.
- langchain_openai: 다음을 설치합니다. 랭체인 OpenAI에 대한 종속성. OpenAI Embedding 모델을 사용하여 ColBERT에 대한 성능을 확인할 수도 있습니다.
- 크로마DB: 이 라이브러리를 사용하면 데이터에 대해 생성한 임베딩을 저장하고 나중에 쿼리와 저장된 임베딩 간에 의미 체계 검색을 수행할 수 있도록 환경에 벡터 저장소를 만들 수 있습니다.
- 아이놉스: 이 라이브러리는 효율적인 텐서 행렬 곱셈에 필요합니다.
- 문장 변환기 그리고 틱토큰 오픈 소스 임베딩 모델이 제대로 작동하려면 라이브러리가 필요합니다.
2단계: 사전 학습된 모델 다운로드
다음 단계에서는 사전 훈련된 ColBERT 모델을 다운로드하겠습니다. 이를 위해 코드는 다음과 같습니다.
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- 먼저 RAGatouille 라이브러리에서 RAGPretrainedModel 클래스를 가져옵니다.
- 그런 다음 .from_pretrained()를 호출하고 모델 이름을 "colbert-ir/colbertv2.0"으로 지정합니다.
위의 코드를 실행하면 ColBERT RAG 모델이 인스턴스화됩니다. 이제 Wikipedia 페이지를 다운로드하고 검색을 수행해 보겠습니다. 이를 위한 코드는 다음과 같습니다:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille에는 문자열을 가져와 해당 Wikipedia 페이지를 가져오는 get_wikipedia_page라는 편리한 함수가 함께 제공됩니다. 여기에서는 Elon Musk의 Wikipedia 콘텐츠를 다운로드하여 변수 문서에 저장합니다. 문서에 있는 단어 수와 문서의 처음 몇 줄을 인쇄해 보겠습니다.
여기서 우리는 그림에서 출력을 볼 수 있습니다. Elon Musk의 Wikipedia 페이지에는 총 64,668개의 단어가 있음을 알 수 있습니다.
3단계: 인덱싱
이제 이 문서에 대한 색인을 생성하겠습니다.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)여기서는 RAG의 .index()를 호출하여 문서를 색인화합니다. 이를 위해 다음을 전달합니다.
- 수집: 이것은 우리가 색인을 생성하려는 문서의 목록입니다. 여기에는 문서가 하나만 있으므로 단일 문서 목록이 있습니다.
- 문서_ID: 각 문서에는 고유한 문서 ID가 필요합니다. 여기서는 문서가 Elon Musk에 관한 것이므로 elon_musk라는 이름을 전달합니다.
- document_metadatas: 각 문서에는 해당 메타데이터가 있습니다. 이는 다시 사전 목록으로, 각 사전에는 특정 문서에 대한 키-값 쌍 메타데이터가 포함되어 있습니다.
- 색인_이름: 생성 중인 인덱스의 이름입니다. 이름을 Elon2로 지정하겠습니다.
- 최대_문서_크기: 이는 청크 크기와 유사합니다. 우리는 각 문서 청크의 양을 지정합니다. 여기서는 값 256을 지정합니다. 값을 지정하지 않으면 256이 기본 청크 크기로 사용됩니다.
- 분할_문서: 이는 부울 값입니다. 여기서 True는 주어진 청크 크기에 따라 문서를 분할하려는 것을 나타내고 False는 전체 문서를 단일 청크로 저장하려는 것을 나타냅니다.
위의 코드를 실행하면 문서를 청크당 256개의 크기로 청크한 다음 ColBERT 모델을 통해 임베드합니다. 그러면 각 청크에 대한 토큰 수준 벡터 임베딩 목록이 생성되고 최종적으로 인덱스에 저장됩니다. 이 단계는 실행하는 데 약간의 시간이 걸리며 GPU가 있는 경우 가속화될 수 있습니다. 마지막으로 인덱스가 저장되는 디렉터리를 만듭니다. 여기서 디렉토리는 ".ragatouille/colbert/indexes/Elon2"입니다.
4단계: 일반 쿼리
이제 검색을 시작하겠습니다. 이를 위해 코드는 다음과 같습니다.
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- 여기서는 먼저 RAG 객체의 .search() 메소드를 호출합니다.
- 이를 위해 쿼리 이름, k(검색할 문서 수), 검색할 인덱스 이름을 포함하는 변수를 제공합니다.
- 여기서는 "Elon Musk가 어떤 회사를 찾았습니까?"라는 쿼리를 제공합니다. 얻은 결과는 콘텐츠, 점수, 순위, 문서 ID, 통로 ID 및 문서 메타데이터와 같은 키를 포함하는 사전 형식 목록입니다.
- 따라서 우리는 검색된 문서를 깔끔하게 인쇄하기 위해 아래 코드를 사용합니다.
- 여기서는 사전 목록을 살펴보고 문서의 내용을 인쇄합니다.
코드를 실행하면 다음과 같은 결과가 생성됩니다.
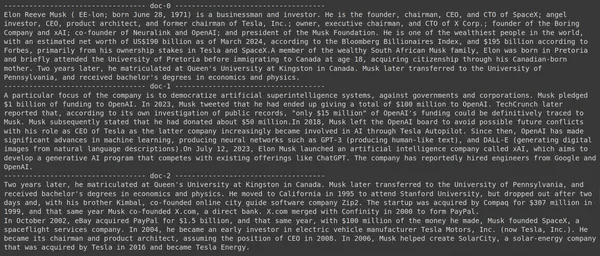
사진에서 우리는 첫 번째와 마지막 문서가 Elon Musk가 설립한 다양한 회사를 완전히 다루고 있음을 알 수 있습니다. ColBERT는 쿼리에 응답하는 데 필요한 관련 청크를 올바르게 검색할 수 있었습니다.
5단계: 특정 쿼리
이제 한 단계 더 나아가 구체적인 질문을 해보자.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])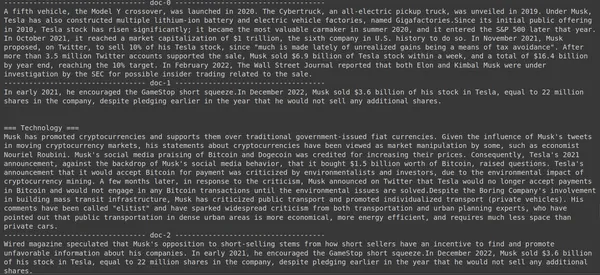
위 코드에서는 2022년 1월에 Tesla Elon의 주식이 얼마나 팔렸는지에 대한 매우 구체적인 질문을 하고 있습니다. 여기서 출력을 볼 수 있습니다. doc-3.6에는 질문에 대한 답변이 포함되어 있습니다. Elon은 Tesla 주식 XNUMX억 달러 상당을 매각했습니다. 이번에도 ColBERT는 주어진 쿼리에 대한 관련 청크를 성공적으로 검색할 수 있었습니다.
6단계: 다른 모델 테스트
이제 오픈 소스 및 비공개 모델 모두에 대해 동일한 질문을 시도해 보겠습니다.
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- 먼저 Transformers 라이브러리의 AutoModel 클래스를 통해 모델을 다운로드하는 것부터 시작합니다.
- 그런 다음 model_name과 model_kwargs를 해당 변수에 저장합니다.
- 이제 LangChain에서 이 모델을 사용하기 위해 다음에서 HuggingFaceEmbedding을 가져옵니다. 랭체인 모델 이름과 model_kwargs를 지정합니다.
이 코드를 실행하면 Jina 임베딩 모델을 다운로드하고 로드하여 작업할 수 있습니다.
7단계: 임베딩 생성
이제 문서 분할을 시작한 다음 문서에서 임베딩을 생성하고 이를 Chroma 벡터 저장소에 저장해야 합니다. 이를 위해 다음 코드를 사용하여 작업합니다.
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- LangChain 라이브러리에서 Chroma 및 RecursiveCharacterTextSplitter를 가져오는 것부터 시작합니다.
- 그런 다음 RecursiveCharacterTextSplitter의 .from_tiktoken_encoder를 호출하고 이에 Chunk_size 및 Chun_overlap을 전달하여 text_splitter를 인스턴스화합니다.
- 여기서는 ColBERT에 제공한 것과 동일한 Chunk_size를 사용합니다.
- 그런 다음 이 text_splitter의 .split_text() 메서드를 호출하고 Elon Musk에 대한 Wikipedia 정보가 포함된 문서를 제공합니다. 그런 다음 주어진 청크 크기에 따라 문서를 분할하고 마지막으로 문서 청크 목록이 변수 분할에 저장됩니다.
- 마지막으로 Chroma 클래스의 .from_texts() 함수를 호출하여 벡터 저장소를 생성합니다. 이 함수에는 분할, 임베딩 모델 및 collection_name을 제공합니다.
- 이제 벡터 저장소 개체의 .as_retriever() 함수를 호출하여 검색기를 만듭니다. k 값에 3을 부여합니다.
이 코드를 실행하면 문서를 가져와 청크당 256 크기의 더 작은 문서로 분할한 다음 이러한 작은 청크를 Jina 임베딩 모델에 임베드하고 이러한 임베딩 벡터를 크로마 벡터 저장소에 저장합니다.
8단계: 리트리버 만들기
마지막으로 우리는 그것으로부터 검색자를 만듭니다. 이제 벡터 검색을 수행하고 결과를 확인하겠습니다.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)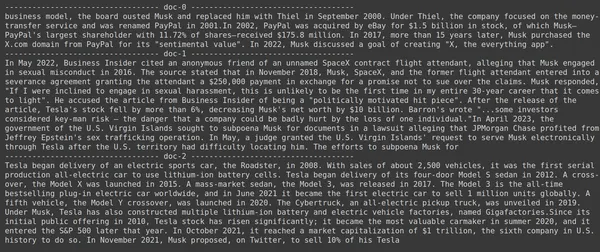
- 검색기 개체의 .get_relevent_documents() 함수를 호출하고 동일한 쿼리를 제공합니다.
- 그런 다음 검색된 상위 3개 문서를 깔끔하게 인쇄합니다.
- 그림에서 우리는 Jina Embedder가 널리 사용되는 임베딩 모델임에도 불구하고 쿼리 검색이 좋지 않음을 알 수 있습니다. 올바른 문서 청크를 가져오지 못했습니다.
각 청크를 단일 벡터 임베딩으로 표현하는 임베딩 모델인 Jina와 각 청크를 토큰 수준 임베딩 벡터 목록으로 표현하는 ColBERT 모델의 차이점을 명확하게 확인할 수 있습니다. 이 경우 ColBERT가 확실히 더 나은 성능을 발휘합니다.
9단계: OpenAI 임베딩 모델 테스트
이제 OpenAI Embedding 모델과 같은 비공개 소스 임베딩 모델을 사용해 보겠습니다.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})여기서 코드는 방금 작성한 코드와 매우 유사합니다.
- 유일한 차이점은 환경 변수를 설정하기 위해 OpenAI API 키를 전달한다는 것입니다.
- 그런 다음 LangChain에서 가져와서 OpenAI Embedding 모델의 인스턴스를 생성합니다.
- 그리고 컬렉션 이름을 생성하는 동안 OpenAI Embedding 모델의 임베딩이 다른 컬렉션에 저장되도록 다른 컬렉션 이름을 지정합니다.
이 코드를 실행하면 문서를 다시 가져와 크기 256의 더 작은 문서로 청크한 다음 OpenAI 임베딩 모델을 사용하여 단일 벡터 임베딩 표현에 임베딩하고 마지막으로 이러한 임베딩을 Chroma Vector Store에 저장합니다. 이제 다른 질문에 관련 문서를 검색해 보겠습니다.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)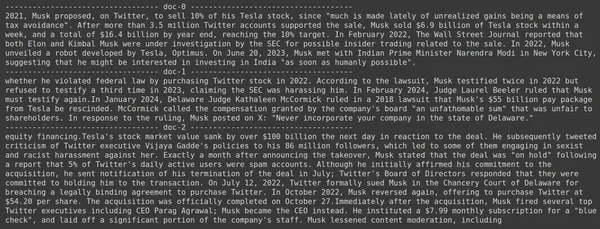
- 우리가 기대하는 답변이 검색된 청크 내에서 발견되지 않음을 알 수 있습니다.
- 청크 2022에는 XNUMX년 Tesla 주식에 대한 정보가 포함되어 있지만 Elon이 이를 판매하는 것에 대해서는 언급하지 않습니다.
- 나머지 두 개의 문서 덩어리에서도 마찬가지입니다. 여기에 포함된 정보는 Tesla와 해당 주식에 대한 정보이지만 이는 우리가 기대하는 정보가 아닙니다.
- 위에서 검색된 청크는 LLM이 우리가 제공한 쿼리에 응답할 수 있는 컨텍스트를 제공하지 않습니다.
여기에서도 단일 벡터 임베딩 표현과 다중 벡터 임베딩 표현 간의 명확한 차이점을 볼 수 있습니다. 다중 임베딩 표현은 복잡한 쿼리를 명확하게 캡처하여 보다 정확한 검색을 제공합니다.
결론
결론적으로 ColBERT는 텍스트를 토큰 수준에서 다중 벡터 임베딩으로 표현함으로써 기존 바이 인코더 모델에 비해 검색 성능이 크게 향상되었음을 보여줍니다. 이 접근 방식을 사용하면 쿼리와 문서 간의 보다 미묘한 상황별 이해가 가능해 검색 결과가 더욱 정확해지고 LLM에서 흔히 관찰되는 환각 문제가 완화됩니다.
주요 요점
- RAG는 사실적 답변 생성을 위한 상황별 정보를 제공하여 LLM의 환각 문제를 해결합니다.
- 기존 바이 인코더는 전체 텍스트를 단일 벡터 임베딩으로 압축하여 검색 정확도가 낮기 때문에 정보 병목 현상이 발생합니다.
- 토큰 수준 임베딩 표현을 갖춘 ColBERT는 쿼리와 문서 간의 상황별 이해를 향상시켜 검색 성능을 향상시킵니다.
- 토큰 수준 상호 작용과 결합된 ColBERT의 후기 상호 작용 단계는 상황별 뉘앙스를 고려하여 검색 정확도를 향상시킵니다.
- ColBERTv2는 검색 효율성을 유지하면서 잔여 압축을 통해 저장 공간을 최적화합니다.
- 실습 실험은 Jina 및 OpenAI Embedding과 같은 기존 및 오픈 소스 임베딩 모델에 비해 검색 성능에서 ColBERT의 우월성을 보여줍니다.
자주 묻는 질문
A. 기존 바이 인코더는 전체 텍스트를 단일 벡터 임베딩으로 압축하므로 문맥 정보가 손실될 수 있습니다. 이로 인해 검색 작업, 특히 복잡한 쿼리나 문서의 효율성이 제한됩니다.
A. ColBERT(Contextual Late Interactions BERT)는 토큰 수준 벡터 임베딩을 사용하여 텍스트를 표현하는 바이 인코더 모델입니다. 쿼리와 문서 간의 보다 미묘한 상황별 이해가 가능해 검색 정확도가 향상됩니다.
A. ColBERT는 쿼리 및 문서에 대한 토큰 수준 임베딩을 생성하고 행렬 곱셈을 수행하여 유사성 점수를 계산한 다음 토큰 전체의 최대 유사성을 기반으로 가장 관련성이 높은 정보를 선택합니다. 이를 통해 상황에 맞는 이해를 바탕으로 효과적인 검색이 가능합니다.
A. ColBERTv2는 잔여 압축 방법을 통해 Space를 최적화하여 검색 정확도를 유지하면서 토큰 수준 임베딩에 대한 저장 요구 사항을 줄입니다.
A. RAGatouille과 같은 라이브러리를 사용하면 ColBERT를 쉽게 사용할 수 있습니다. 문서와 쿼리를 색인화하면 효율적인 검색 작업을 수행하고 상황에 맞는 정확한 답변을 생성할 수 있습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

