개요
기술 혁명이 진행되는 세상에서 인공지능과 헬스케어의 융합은 의료 진단과 치료의 지형을 바꾸고 있습니다. 이러한 변화 뒤에 숨겨진 영웅 중 하나는 의료, 건강 영역, 주로 텍스트 분석 분야에서 LLM(대형 언어 모델)을 적용한 것입니다. 이 기사에서는 텍스트 기반 의료 애플리케이션의 맥락에서 LLM의 영역을 살펴보고 이러한 강력한 AI 모델이 의료 산업에 어떻게 혁명을 일으키고 있는지 살펴봅니다.

학습 목표
- 의료 텍스트 분석에서 LLM(대형 언어 모델)의 역할을 이해합니다.
- 현대 의료에서 의료 영상의 중요성을 인식합니다.
- 의료 분야의 의료 이미지 양으로 인해 발생하는 문제를 식별합니다.
- LLM이 의료 텍스트 분석 및 진단을 자동화하는 데 어떻게 도움이 되는지 이해하세요.
- 중요한 의료 사례를 분류하는 데 있어서 LLM의 효율성을 높이 평가하십시오.
- LLM이 환자 이력을 기반으로 한 맞춤형 치료 계획에 어떻게 기여하는지 알아보세요.
- 방사선 전문의를 지원하는 LLM의 협력적 역할을 이해합니다.
- LLM이 의대생과 실무자를 위한 교육에 어떻게 도움이 될 수 있는지 알아보세요.
이 기사는 데이터 과학 블로그.
차례
의료 영상 및 의료의 보이지 않는 세계
LLM의 세계로 뛰어들기 전에 잠시 의료 영상의 존재에 대해 알아보겠습니다. 이는 질병을 시각화 및 감지하고 많은 치료 진행 상황을 모니터링하는 데 도움이 되는 현재 테크노 라이프의 현대 의학의 중추입니다. 특히 방사선학은 엑스레이, MRI, CT 스캔 등의 의료 이미지에 크게 의존합니다.
그러나 이러한 의료 이미지의 보고에는 엄청난 양이라는 과제가 따릅니다. 병원과 의료기관에서는 매일 대량의 의료 이미지를 사용합니다. 이 홍수를 수동으로 분석하고 해석하는 것은 어렵고 시간이 많이 걸리며 인적 오류가 발생하기 쉽습니다.

대형 언어 모델은 의료 이미지 분석에서 중요한 역할 외에도 텍스트 기반 의료 정보를 이해하고 처리하는 데에도 뛰어납니다. 복잡한 의학 전문 용어를 명확하게 이해하고 메모와 보고서를 해석하는 데에도 도움이 됩니다. LLM은 보다 효율적이고 정확한 의료 텍스트 분석에 기여하여 의료 전문가 및 의료 분석의 전반적인 역량을 향상시킵니다.
이러한 이해를 바탕으로 LLM이 어떻게 의료 영상 및 텍스트 분석 분야에서 의료 산업에 혁신을 일으키고 있는지 자세히 살펴보겠습니다.
의료 텍스트 분석에 LLM 적용
의료 분야에서 대형 언어 모델이 제공하는 다양한 역할을 이해하기 전에 의료 텍스트 분석 영역에서 주요 응용 프로그램을 간략하게 살펴보겠습니다.
- 질병 진단 및 예후: LLM은 의료 서비스 제공자가 다양한 질병을 진단하는 데 도움을 주기 위해 대규모 의료 텍스트 데이터베이스를 샅샅이 뒤져볼 수 있습니다. 초기 진단에 도움이 될 수 있을 뿐만 아니라 상황에 맞는 충분한 정보가 제공되면 질병 진행 및 예후에 관해 교육적인 추측을 할 수도 있습니다.
- 임상 문서 및 전자 건강 기록: 의료 전문가에게는 광범위한 임상 문서를 처리하는 데 시간이 많이 걸릴 수 있습니다. LLM은 전자 건강 기록(EHR)을 기록, 요약 및 분석하는 보다 효율적인 수단을 제공하므로 의료 서비스 제공자가 환자 치료에 더 집중할 수 있습니다.
- 약물 발견 및 용도 변경: LLM은 수많은 생물의학 문헌을 조사하여 잠재적인 약물 후보를 식별하고 기존 약물에 대한 대체 용도를 제안하여 약리학의 발견 및 용도 변경 프로세스를 가속화할 수 있습니다.
- 생물의학 문헌 분석: 계속해서 늘어나는 의학 문헌의 양은 압도적일 수 있습니다. LLM은 수많은 과학 논문을 조사하고, 주요 결과를 식별하고, 간결한 요약을 제공하여 새로운 지식을 더 빨리 동화할 수 있도록 도와줍니다.
- 환자 지원 및 건강 챗봇: LLM은 일반적인 건강 문의에 대한 답변부터 응급 상황에서의 초기 분류 제공에 이르기까지 다양한 기능을 처리할 수 있는 지능형 챗봇을 지원하여 환자와 의료 서비스 제공자 모두에게 귀중한 지원을 제공합니다.
LLM은 의료 산업에서 어떻게 작동합니까?

- 대형 언어 모델이란 무엇입니까? 대규모 언어 모델은 인간과 같은 텍스트를 이해하고 해석하고 생성하도록 설계된 기계 학습 모델의 하위 집합입니다. 이러한 모델은 책, 기사, 웹사이트 및 기타 텍스트 기반 소스로 구성된 방대한 데이터세트를 기반으로 학습됩니다. 컨텍스트와 의미를 이해할 수 있는 고급 텍스트 분석기 및 생성기 역할을 합니다.
- 의료 분야에서 LLM의 진화: 지난 XNUMX년 동안 LLM은 단순한 챗봇에서 복잡한 의학 문헌을 분석할 수 있는 정교한 도구로 발전하면서 의료 분야에서 두각을 나타냈습니다. 더 강력한 하드웨어와 더 효율적인 알고리즘의 출현으로 이러한 모델은 몇 초 안에 기가바이트의 데이터를 조사하여 실시간 통찰력과 분석을 제공할 수 있게 되었습니다. 그들의 적응성은 새로운 정보로부터 지속적으로 학습할 수 있게 하여 점점 더 정확하고 신뢰할 수 있게 만듭니다.
- LLM은 기존 NLP 방법과 어떻게 다릅니까? 규칙 기반 시스템이나 더 간단한 기계 학습 모델과 같은 전통적인 자연어 처리(NLP) 방법은 맥락을 이해하기 위한 범위가 제한된 고정 알고리즘에서 작동합니다. 그러나 LLM은 딥 러닝을 활용하여 관용어, 의학 전문 용어, 복잡한 문장 구조 등 인간 언어의 복잡성을 파악합니다. 이를 통해 LLM은 기존 NLP 방법이 제공할 수 있는 것보다 훨씬 더 미묘하고 상황에 맞게 정확한 통찰력을 생성할 수 있습니다.
의료 텍스트 분석에서 LLM의 장점 및 기능
- 맥락적 이해: 키워드 일치에 의존하는 기존 검색 알고리즘과 달리 LLM은 텍스트의 맥락을 이해하여 보다 미묘하고 정확한 통찰력을 제공합니다.
- 속도: LLM은 보고서를 빠르게 분석하고 생성하여 중요한 의료 환경에서 귀중한 시간을 절약할 수 있습니다.
- 다기능: 단순한 텍스트 분석을 넘어 진단 보조, 개인별 맞춤 치료 추천, 교육 도구 역할을 할 수 있습니다.
- 적응성: 이러한 모델은 특정 의료 영역이나 기능에 맞게 미세 조정이 가능하여 놀라울 정도로 다재다능합니다.
의료 텍스트 분석에서 LLM의 역할
- 자동화된 분석 및 진단: 대규모 언어 모델은 의학 문헌 및 실시간 사례 연구를 포함한 다양한 데이터 세트를 사용하여 교육됩니다. 그들은 문맥을 이해하는 데 뛰어나고 복잡한 의학 전문 용어를 분석할 수 있습니다. LLM은 자동화된 분석을 제공하고 의학 텍스트에 적용하면 질병을 진단할 수도 있습니다.
- 효율적인 분류: 응급실에서는 매 순간이 중요합니다. 대규모 언어 모델은 의료 보고서나 진료소 텍스트 메모를 분석하고 출혈이나 이상과 같은 심각한 상태를 표시하여 사례를 신속하게 분류할 수 있습니다. 이를 통해 환자 치료를 신속하게 처리하고 자원 할당을 최적화합니다.
- 맞춤형 치료 계획: 의료 영상 LLM은 유전학, 알레르기 및 과거 치료 반응을 포함한 환자 이력을 분석하여 맞춤형 의학에 기여합니다. 그들은 이 정보를 바탕으로 맞춤형 치료 계획을 추천할 수 있습니다.
- 방사선 전문의 지원: 대형 언어 모델은 방사선 전문의의 보조자 역할을 합니다. 의료 보고서를 사전에 검사하고, 이상 징후를 강조하고, 가능한 진단을 제안할 수 있습니다. 이러한 협력적 접근 방식은 진단의 정확성을 높이고 방사선 전문의의 피로를 줄여줍니다.
- 교육 도구: 대규모 언어 모델은 의대생과 실무자를 위한 교육 목적의 도구로 도움이 될 수 있습니다. 텍스트 설명을 바탕으로 3D 재구성을 생성하고, 의료 시나리오를 시뮬레이션하고, 교육 목적으로 자세한 설명을 제공할 수 있습니다.
진단을 위해 LLM을 어떻게 자동화할 수 있나요?
다음은 언어 모델(예: GPT-3)을 사용하여 의료 텍스트를 기반으로 한 자동화된 분석 및 진단에 대규모 언어 모델을 사용할 수 있는 방법을 보여주는 단순화된 코드 조각입니다.
import openai
import time # Your OpenAI API key
api_key = "YOUR_API_KEY" # Patient's medical report medical_report = """
Patient: John Doe
Age: 45
Symptoms: Persistent cough, shortness of breath, fever. Medical History:
- Allergies: None
- Medications: None
- Past Illnesses: None Diagnosis:
Based on the patient's symptoms and medical history, John Doe is suffering from a respiratory infection, possibly pneumonia. Further tests and evaluation are recommended for confirmation. """ # Initialize OpenAI's GPT-3 model
openai.api_key = api_key # Define a language model
prompt = f"Diagnose the condition by seeing the following report:n{medical_report}nDiagnosis:" while True: try: # Generate a diagnosis using the language model response = openai.Completion.create( engine="davinci", prompt=prompt, max_tokens=50 # Adjust the number of tokens based on your requirements ) # Extract and print the generated diagnosis diagnosis = response.choices[0].text.strip() print("Generated Diagnosis:") print(diagnosis) # Break out of the loop once the response is successfully obtained break except openai.error.RateLimitError as e: # If you hit the rate limit, wait for a moment and retry print("Rate limit exceeded. Waiting for rate limit reset...") time.sleep(60) # Wait for 1 minute (adjust as needed) except Exception as e: # Handle other exceptions print(f"An error occurred: {e}") break # Break out of the loop on other errors
출력:

- openai 라이브러리 가져오기 및 OpenAI 키 설정
- 환자 정보, 증상 및 병력을 포함하는 의료 보고서를 작성하십시오.
- OpenAI의 GPT-3 모델을 초기화하고 제공된 보고서를 기반으로 모델에 건강 상태를 진단하도록 요청하는 프롬프트를 정의합니다.
- 진단을 생성하려면 openai.Completion을 사용하세요. 생성된 텍스트의 길이를 제어하려면 max_tokens 매개변수를 조정하세요.
- 생성된 진단을 추출하고 인쇄합니다.
샘플 출력
Generated Diagnosis: "Based on the patient's symptoms and medical history, it is likely that John Doe is suffering from a respiratory infection, possibly pneumonia.
Further tests and evaluation are recommended for confirmation."이 코드는 텍스트 의료 보고서를 기반으로 자동화된 의료 진단을 생성하는 데 대형 언어 모델이 어떻게 도움이 될 수 있는지 보여줍니다. 실제 의료 진단에는 항상 의료 전문가와의 상담이 필요하며 AI 생성 진단에 의존해서는 안 된다는 점을 기억하세요.
종합적인 의료 영상 분석을 위해 VIT와 LLM 결합
의료 영상에 LLM을 적용하는 방법을 보여주는 몇 가지 코드 조각을 살펴보겠습니다.
import torch
from transformers import ViTFeatureExtractor, ViTForImageClassification # Load a pre-trained Vision Transformer (ViT) model
model_name = "google/vit-base-patch16-224-in21k"
feature_extractor = ViTFeatureExtractor(model_name)
model = ViTForImageClassification.from_pretrained(model_name) # Load and preprocess a medical image
from PIL import Image image = Image.open("chest_xray.jpg")
inputs = feature_extractor(images=image, return_tensors="pt") # Get predictions from the model
outputs = model(**inputs)
logits_per_image = outputs.logits이 코드에서는 ViT(Vision Transformer) 모델을 사용하여 의료 영상을 분류합니다. ViT와 같은 LLM은 의료 영상 분야의 다양한 이미지 관련 작업에 적용할 수 있습니다.
이상 자동 감지
import torch
import torchvision.transforms as transforms
from PIL import Image
from transformers import ViTFeatureExtractor, ViTForImageClassification # Load a pre-trained Vision Transformer (ViT) model
model_name = "google/vit-base-patch16-224-in21k"
feature_extractor = ViTFeatureExtractor(model_name)
model = ViTForImageClassification.from_pretrained(model_name) # Load and preprocess a medical image
image = Image.open("chest_xray.jpg")
transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(),
])
input_image = transform(image).unsqueeze(0) # Extract features from the image
inputs = feature_extractor(images=input_image)
outputs = model(**inputs)
logits_per_image = outputs.logits이 코드에서는 ViT(Vision Transformer) 모델을 사용하여 의료 영상의 이상 현상을 자동으로 감지합니다. 모델은 이미지에서 특징을 추출하고 logits_per_image 변수에는 모델의 예측이 포함됩니다.
의료 이미지 캡션
import torch
from transformers import ViTFeatureExtractor, ViTForImageToText # Load a pre-trained ViT model for image captioning
model_name = "google/vit-base-patch16-224-in21k-cmlm"
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name)
model = ViTForImageToText.from_pretrained(model_name) # Load and preprocess a medical image
image = Image.open("MRI_scan.jpg")
inputs = feature_extractor(images=image, return_tensors="pt")
output = model.generate(input_ids=inputs["pixel_values"]) caption = feature_extractor.decode(output[0], skip_special_tokens=True)
print("Image Caption:", caption)이 코드는 LLM이 의료 이미지에 대한 설명 캡션을 생성하는 방법을 보여줍니다. 사전 훈련된 ViT(Vision Transformer) 모델을 사용합니다.
의료 텍스트 분석에서 LLM의 기술 워크플로
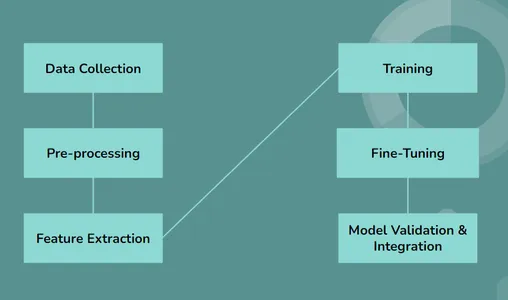
- 데이터 수집: LLM은 의료 보고서, 연구 논문, 임상 노트 등 다양한 데이터 세트를 사용하고 수집하여 프로세스를 시작합니다.
- 전처리 : 수집된 데이터는 분석을 위해 텍스트를 표준화하고 정리하고 구성하는 전처리 과정을 거칩니다.
- 특징 추출: 대규모 언어 모델은 고급 방법을 사용하여 텍스트 데이터에서 중요하고 유용한 정보를 얻거나 찾고 주요 세부 사항과 의학적 문제를 식별합니다.
- 훈련: 대형 언어 모델은 텍스트 형식의 정보 내에서 패턴과 의학적 상태를 찾고 관찰하는 데 도움이 되는 딥 러닝을 사용하여 훈련됩니다.
- 미세 조정: 모델은 훈련 과정 후에 특정 의료 작업에 맞게 미세 조정됩니다. 예를 들어 의료 보고서에서 특정 질병이나 상태를 식별하는 방법을 학습할 수 있습니다.
- 모델 검증: LLM의 성능은 별도의 데이터 세트를 사용하여 엄격하게 검증되어 의료 텍스트 분석의 정확성과 신뢰성을 보장합니다.
- 완성: 검증된 모델은 의료 시스템 및 워크플로에 통합되어 의료 전문가가 의료 텍스트 데이터를 분석하고 해석하는 데 도움을 줄 수 있습니다.
틀림없이! 다음은 의료 분야에서 의료 텍스트 기반 작업에 GPT-3(LLM 유형, 대형 언어 모델)와 같은 언어 모델을 사용하는 방법을 이해하는 데 도움이 되는 단순화된 코드 조각입니다. 이 코드 조각에서는 OpenAI GPT-3 API를 사용하여 환자의 증상과 병력을 기반으로 의료 진단 보고서를 생성하는 Python 스크립트를 만듭니다.
그 전에 OpenAI Python 패키지(openai)가 설치되어 있는지 확인하세요. OpenAI의 API 키가 필요합니다.
import openai # Set your OpenAI API key here
api_key = "YOUR_API_KEY" # Function to generate a medical diagnosis report
def generate_medical_diagnosis_report(symptoms, medical_history): prompt = f"Patient presents with the following symptoms: {symptoms}. Medical history: {medical_history}. Please provide a diagnosis and recommended treatment." # Call the OpenAI GPT-3 API response = openai.Completion.create( engine="text-davinci-002", # You can choose the appropriate engine prompt=prompt, max_tokens=150, # Adjust max_tokens based on the desired response length api_key=api_key ) # Extract and return the model's response diagnosis_report = response.choices[0].text.strip() return diagnosis_report # Example usage
if __name__ == "__main__": symptoms = "Persistent cough, fever, and chest pain" medical_history = "Patient has a history of asthma and allergies." diagnosis_report = generate_medical_diagnosis_report(symptoms, medical_history) print("Medical Diagnosis Report:") print(diagnosis_report)
이는 단순화된 예이며 실제 의료 애플리케이션에서는 데이터 개인 정보 보호, 규정 준수 및 의료 전문가와의 상담을 고려합니다. 이러한 모델을 항상 책임감 있게 사용하고 실제 의료 진단 및 치료를 위해서는 의료 전문가와 상담하세요.
대규모 언어 모델: 예측을 뛰어넘는 힘
대규모 언어 모델은 또한 의료의 다른 부분으로 이동하고 있습니다.
- 약물 발견: LLM은 대규모 화학 물질 데이터 세트를 연구하고 화학 물질의 작동 방식을 예측하며 약물 개발 속도를 높여 약물 발견을 돕습니다.
- 전자 건강 기록(EHR): LLM을 EHR과 함께 사용하면 환자 기록을 신속하게 분석하여 위험을 예측하고 치료법을 제안하며 치료법이 환자의 건강에 미치는 영향을 연구할 수 있습니다.
- 의학 문헌 요약: LLM은 광범위한 의학 문헌을 조사하고, 주요 통찰력을 추출하고, 간결한 요약을 생성하여 연구원과 의료 종사자에게 도움을 줄 수 있습니다.
- 원격 의료 및 가상 건강 보조원: LLM은 환자의 질문을 이해하고 건강 정보를 제공하며 증상 및 치료 옵션에 대한 지침을 제공하는 가상 건강 보조원을 강화할 수 있습니다.

윤리적 고려 사항
- 환자 개인정보 보호: 기밀을 유지하기 위해 환자 데이터를 엄격하게 보호합니다.
- 데이터 바이어스: 공평한 진단을 보장하기 위해 LLM 내의 편견을 지속적으로 평가하고 수정합니다.
- 동의: AI 지원 진단 및 치료에 대한 환자 동의를 확보하세요.
- 투명성 : 의료 서비스 제공자를 위한 AI 생성 권장 사항의 투명성을 보장합니다.
- 데이터 품질: 신뢰할 수 있는 결과를 위해 데이터 품질과 정확성을 유지하세요.
- 편견 완화: 윤리적 의료 지원을 위해 LLM의 지속적인 편견 완화에 우선순위를 둡니다.
결론
끊임없이 변화하는 의료 및 AI 세계에서 LLM(대형 언어 모델)과 의료 영상의 팀워크는 매우 중요하고 중요합니다. 사람의 노하우를 대체하는 것이 아니라, 사람의 개입 없이도 이를 개선하고 사람과 같은 결과를 얻는 것입니다. LLM은 신속한 진단과 맞춤형 치료를 지원하므로 의료 전문가가 환자를 신속하게 도울 수 있습니다.
하지만 이 기술을 사용하면서 윤리적이어야 하며 환자 정보를 보다 안전하게 보호해야 한다는 점을 잊어서는 안 됩니다. 가능성은 높고 거대하지만 우리에게는 큰 책임도 있습니다. 이는 발전과 사람 보호 사이의 적절한 균형을 찾는 것입니다.
여행은 이제 막 시작되었습니다. LLM을 통해 우리는 보다 정확한 진단, 더 나은 환자 결과, 효율적이고 자비로운 의료 시스템으로 이어지는 길을 걷고 있습니다. LLM이 이끄는 의료의 미래는 모두를 위한 더 건강한 세상을 약속합니다.
주요 요점
- LLM(대형 언어 모델)은 의료 텍스트 분석 방법에 혁명을 일으키고 진단 및 치료 계획에 큰 진전을 이루고 있습니다.
- 의료 보고서와 임상 기록에서 문제를 신속하게 식별하여 응급 치료를 신속하게 처리합니다.
- LLM은 텍스트 기반 이미지 해석을 대체하는 대신 텍스트 기반 해석을 지원하여 포괄적인 데이터 이해를 지원함으로써 방사선 전문의의 역량을 향상시킵니다.
- 이러한 모델은 교육에서 유용성을 찾고 의료 부문 내에서 다양한 응용 프로그램을 제공합니다.
- 의료 분야에서 LLM을 활용하려면 환자 개인 정보 보호, 데이터 공정성 및 모델 투명성을 신중하게 고려해야 합니다.
- LLM과 의료 전문가의 공동 노력은 의료 서비스의 품질과 동정심을 향상시킬 수 있습니다.
자주 묻는 질문
A. 아니요, LLM은 의료 영상 분야의 방사선 전문의를 대체하지 않습니다. 대신 그들은 함께 일하고 있습니다. LLM은 문제를 신속하게 발견하고 프로세스를 더 빠르게 만들어 방사선 전문의를 돕습니다. 그들은 가르치는 데 사용하고 다른 의료 용도로 사용합니다. 의학에서 LLM을 사용할 때 환자의 개인정보 보호와 데이터의 공정성은 필수적입니다.
A. LLM은 각 영상 양식에 특정한 다양한 데이터 세트를 미세 조정하여 다양한 의료 영상에 적응합니다. 이 과정에서 텍스트 기반의 X선, MRI, CT 스캔을 통해 고유한 특징과 패턴을 배웁니다. 교차 모드 교육 기술을 사용하면 양식별 뉘앙스를 이해하는 동시에 정확성을 유지하면서 여러 양식에 걸쳐 지식을 전달할 수 있습니다.
A. 의료 영상 분야에서 LLM의 과제에는 데이터 편견 해결 및 완화, AI 지원 진단에 대한 환자의 사전 동의 확보, 윤리를 유지하면서 AI 생성 권장 사항이 공식화 및 제시되는 방식에 대한 투명성 보장 등이 포함됩니다.
A. 네, LLM은 의료 분야의 교육 도구 역할을 할 수 있습니다. 그들은 의학 개념을 가르치는 데 도움을 주고 이해하기 쉬운 방식으로 귀중한 정보를 공유합니다. 이는 다양한 유형의 학생, 의료 전문가, 심지어 자신의 상태에 대해 더 자세히 알고 싶어하는 환자에게 도움이 될 수 있습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/10/the-impact-of-large-language-models-on-medical-text-analysis/

