개요
현재 트렌드 NLP 수백만 또는 수십억 개의 매개변수가 있는 사전 훈련된 모델의 다운로드 및 미세 조정이 포함됩니다. 그러나 이렇게 큰 훈련된 모델을 저장하고 공유하는 것은 시간이 오래 걸리고 느리고 비용이 많이 듭니다. 이러한 제약은 여러 작업에서 학습할 수 있는 RoBERTa 모델을 사용하여 보다 다목적이고 적응 가능한 NLP 기술의 개발을 방해합니다. 이 문서에서는 시퀀스 분류 작업에 중점을 둘 것입니다. 이것을 고려하면, 어댑터 전체 미세 조정에 대한 작고 가벼우며 매개 변수 효율적인 대안이 제안되었습니다. 이들은 기본적으로 서로 다른 작업 및 언어를 기반으로 사전 훈련된 모델을 사용하여 동적으로 추가할 수 있는 작은 병목 현상 계층입니다.

이 기사에서는 다음에 대한 어댑터를 교육합니다. 로버타 의 도움으로 시퀀스 분류 작업을 위한 Amazon 극성 데이터 세트에 대한 모델 어댑터 변압기, Hugging Face의 트랜스포머 라이브러리의 AdapterHub 적응. 또한 어댑터 모듈의 성능을 동일한 데이터 세트에서 훈련된 완전히 미세 조정된 RoBERTa 모델과 비교할 것입니다.
이 기사를 마치면 다음 내용을 배우게 됩니다.
- 시퀀스 분류 작업을 위해 Amazon Polarity 데이터 세트에서 RoBERTa 모델용 어댑터를 교육하는 방법은 무엇입니까?
- 빠른 예측을 위해 Hugging Face 파이프라인을 사용하여 훈련된 어댑터를 어떻게 사용할 수 있습니까?
- 학습된 모델에서 어댑터를 추출하고 나중에 사용하기 위해 저장하는 방법은 무엇입니까?
- 어댑터를 비활성화하고 삭제하여 기본 모델의 가중치를 원래 형태로 복원하려면 어떻게 해야 합니까?
- 나중에 사용할 수 있도록 훈련된 모델을 Hugging Face 허브로 푸시합니다. 또한 어댑터와 전체 미세 조정 간의 비교를 볼 수 있습니다.
이 기사는 데이터 과학 블로그.
차례
프로젝트 설명
이 프로젝트에는 시퀀스 분류 작업, 특히 감정 분석을 위해 Amazon 극성 데이터 세트에서 RoBERTa 모델용 작업 어댑터 교육이 포함됩니다. 훈련을 위해 Hugging Face 허브의 RoBERTa 기본 모델과 Hugging Face의 변압기 라이브러리의 AdapterHub 적응을 사용합니다. 또한 어댑터 모듈의 성능을 동일한 데이터 세트에서 훈련된 완전히 미세 조정된 RoBERTa 모델과 비교할 것입니다.
어댑터 개요
어댑터는 완전히 미세 조정되고 사전 훈련된 모델에 대한 가벼운 대안입니다. 현재 어댑터는 사전 훈련된 모델의 레이어 사이에 삽입되는 작은 피드포워드 신경망으로 구현됩니다. 전이 학습에 매개변수 효율적이고 계산적으로 효율적이며 모듈식 접근 방식을 제공합니다. 다음 이미지는 추가된 어댑터를 보여줍니다.

출처: 어댑터허브
교육 중에 사전 교육된 모델의 모든 가중치는 고정되어 어댑터 가중치만 업데이트되어 모듈식 지식 표현이 됩니다. 쉽게 추출, 상호 교환, 독립적 배포 및 언어 모델에 동적으로 연결할 수 있습니다. 이러한 특성은 NLP 분야를 천문학적으로 발전시키는 어댑터의 잠재력을 강조합니다.
NLP 전이 학습에서 어댑터의 중요성
다음은 NLP 전이 학습에서 어댑터의 중요성에 관한 몇 가지 중요한 사항입니다.
- 사전 훈련된 모델의 효율적인 사용: BERT, GPT-2 및 RoBERTa와 같은 사전 훈련된 언어 모델은 다양한 NLP 작업에서 효과적인 것으로 입증되었습니다. 그러나 전체 모델을 미세 조정하는 것은 계산 비용과 시간이 많이 소요될 수 있습니다. 어댑터를 사용하면 원래 아키텍처를 수정하지 않고도 작업별 기능을 삽입할 수 있으므로 사전 훈련된 모델을 보다 효율적으로 사용할 수 있습니다.
- 향상된 적응성: 어댑터를 사용하면 사전 훈련된 모델을 새로운 작업에 적용할 때 더 큰 유연성을 얻을 수 있습니다. 전체 모델을 미세 조정하는 대신 어댑터를 사용하면 특정 레이어를 선택적으로 수정할 수 있으므로 새로운 작업에 대한 모델 적응이 향상되고 성능이 향상됩니다.
- 비용 효율적 : 전체 모델을 교육하는 데 필요한 것보다 적은 데이터로 어댑터를 교육할 수 있으므로 교육 비용이 절감되고 모델의 확장성이 향상됩니다.
- 감소된 메모리 요구 사항: 어댑터는 전체 모델보다 더 적은 매개변수를 필요로 하므로 상당한 추가 메모리 없이도 기존 모델에 쉽게 추가할 수 있습니다.
- 언어 간 학습 전이: 어댑터는 또한 언어 간 지식 이전을 가능하게 하여 모델을 소스 언어로 교육한 다음 최소한의 추가 교육으로 대상 언어에 맞게 조정할 수 있습니다. 따라서 자원이 부족한 환경에서도 매우 효과적인 것으로 입증될 수 있습니다.
RoBERTa 모델 개요
Roberta는 Facebook AI에서 개발하여 2019년에 출시한 사전 훈련된 대규모 언어 모델입니다. BERT 모델과 동일한 아키텍처를 공유합니다. 주요 하이퍼파라미터와 임베딩을 약간 조정한 BERT의 수정 버전입니다.
출력 레이어를 제외하고 BERT의 사전 훈련 및 미세 조정 절차는 동일한 아키텍처를 사용합니다. 사전 훈련된 모델 매개변수는 다양한 후속 작업을 위한 모델을 초기화하는 데 활용되며 미세 조정 중에 모든 매개변수가 조정됩니다. 다음 다이어그램은 BERT의 사전 훈련 및 미세 조정 절차를 보여줍니다. 다음 그림은 BERT 아키텍처를 보여줍니다.
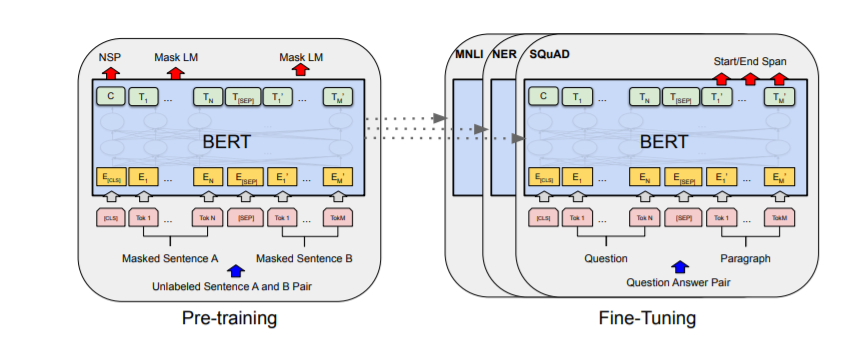
반대로 RoBERTa는 다음 문장 사전 훈련 목표를 사용하지 않지만 훈련 중에 훨씬 더 큰 미니 배치와 학습률을 활용합니다. RoBERTa는 다른 사전 학습 방법을 채택하고 바이트 수준 BPE 토크나이저(GPT-2와 유사)를 문자 수준 BPE 어휘로 대체합니다. 또한 RoBERTa는 "동적 마스킹"을 사용하여 모델이 고정된 토큰 하위 집합을 예측하는 대신 다양한 토큰 집합을 예측하도록 함으로써 입력 텍스트의 보다 강력한 표현을 학습하도록 돕습니다.
이 기사에서는 다음에 대한 어댑터를 교육합니다. RoBERTa베이스 시퀀스 분류 작업을 위한 모델(보다 정확하게는 감정 분석). 간단히 말해 시퀀스 분류 작업은 문장이나 문서와 같은 일련의 단어나 토큰에 레이블이나 범주를 지정하는 것과 관련된 작업입니다.
데이터세트 개요
우리는을 사용합니다 아마존 리뷰 극성 Xiang Zhang이 구축한 데이터 세트. 이 데이터 세트는 점수가 1과 2인 리뷰를 부정적으로, 점수가 4와 5인 리뷰를 긍정적으로 분류하여 생성되었습니다. 또한 점수가 3점인 샘플은 무시되었습니다. 각 클래스 1,800,000개의 훈련 샘플과 200,000개의 테스트 샘플이 있습니다.
Amazon Polarity Dataset에서 RoBERTa 모델용 어댑터 교육
시작하려면 라이브러리 설치부터 시작합니다.
!pip install -U adapter-transformers datasets이제 HuggingFace 데이터 세트를 사용하여 Amazon Reviews Polarity 데이터 세트를 로드합니다.
from datasets import load_dataset #Loading the dataset
dataset = load_dataset("amazon_polarity")이제 데이터 세트가 무엇으로 구성되어 있는지 살펴보겠습니다.
dataset출력: 데이터세트딕트({
기차: 데이터세트({
기능: ['라벨', '제목', '콘텐츠'],
num_rows: 3600000
})
테스트: 데이터세트({
기능: ['라벨', '제목', '콘텐츠'],
num_rows: 400000
})
})
따라서 위의 출력에서 Amazon Reviews Polarity 데이터 세트가 3,600,000개의 훈련 샘플과 400,000개의 테스트 샘플로 구성되어 있음을 알 수 있습니다. 이제 열차 세트와 테스트 세트의 샘플이 어떻게 생겼는지 살펴보겠습니다.
dataset["train"][0]출력: {'label': 1, 'title': ''비게이머'라도 놀랍습니다. 'content': '이 사운드트랙은 아름다웠습니다! 마음속 풍경이 너무 잘 그려져서 비디오 게임 음악을 싫어하시는 분들께도 추천드리고 싶어요! 크로노 크로스라는 게임을 해봤는데 지금까지 해본 게임 중에 음악이 제일 좋네요! 훌륭한 기타와 소울풀한 오케스트라와 함께 뒤로 물러나 더 신선한 발걸음을 내딛습니다. 듣고 싶어하는 사람이라면 누구에게나 깊은 인상을 줄 것입니다! ^_^'}
dataset["test"][0]출력: {'label': 1, 'title': 'Great CD', 'title': 'Great CD', 'content': '내 사랑스러운 Pat은 그녀 세대의 훌륭한 목소리 중 하나를 가지고 있습니다. 나는 이 CD를 몇 년 동안 들었지만 여전히 그것을 좋아합니다. 기분이 좋을 때 기분이 좋아집니다. 나쁜 기분은 빗속의 설탕처럼 그냥 증발합니다. 이 CD는 LIFE를 뿜어냅니다. 보컬은 정말 충격적이고 가사는 그냥 죽입니다. 인생의 숨은 보석 중 하나. 이것은 내 책에 있는 무인도 CD입니다. 그녀가 그것을 크게 만들지 않은 이유는 저 밖에 있습니다. 내가 이것을 연주할 때마다, 남성이든 여성이든 상관없이 모두가 한 가지를 말합니다. "그 노래는 누구였지?"'}
print(dataset), dataset["train"][0] 및 dataset["test"][0]의 출력에서 데이터 세트가 세 개의 열, 즉 "label", "title"로 구성되어 있음을 알 수 있습니다. , 그리고 "콘텐츠". 이를 고려하여 어댑터를 교육하는 데 필요하지 않으므로 제목이라는 열을 삭제해야 합니다.
#Removing the column "title" from the dataset
dataset = dataset.remove_columns("title")열 "제목"이 삭제되었는지 확인합시다!
dataset아래는 "제목" 열을 삭제한 후 데이터 세트의 구성을 보여주는 스크린샷입니다.
출력:
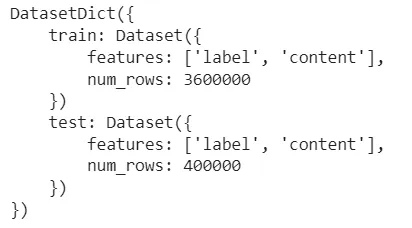
따라서 "제목" 열이 성공적으로 삭제되었으며 더 이상 존재하지 않습니다.
이제 모든 데이터 세트 샘플을 인코딩합니다. 이를 위해 RobertaTokenizer 및 dataset.map() 함수를 사용하여 입력 데이터를 인코딩합니다. 또한 대상 열 클래스의 이름을 변환기 모델이 사용하는 "레이블"로 바꿀 것입니다. 또한 set_format() 함수를 사용하여 PyTorch와 호환되도록 데이터 세트 형식을 설정합니다.
from transformers import AutoTokenizer, RobertaTokenizer tokenizer = RobertaTokenizer.from_pretrained("roberta-base") #Encoding a batch of input data with the help of tokenizer
def encode_batch(batch): return tokenizer(batch["content"], max_length=100, truncation = True, padding="max_length") dataset = dataset.map(encode_batch, batched=True) #Renaming the column "label" to "labels"
dataset = dataset.rename_column("label", "labels") #Setting the dataset format to torch and mentioning the columns we want to format
dataset.set_format(type="torch", columns=["input_ids", "attention_mask", "labels"]) 이제 어댑터 변환기에 고유하고 예측 헤드를 쉽게 추가하고 구성할 수 있는 RobertaModelWithHeads 클래스를 사용합니다.
from transformers import RobertaConfig, RobertaModelWithHeads #Defining the configuration for the model
config = RobertaConfig.from_pretrained("roberta-base", num_labels=2) #Setting up the model
model = RobertaModelWithHeads.from_pretrained("roberta-base", config=config) 이제 add_adapter() 메서드를 사용하여 어댑터를 추가합니다. 이를 위해 어댑터 이름을 전달합니다. "amazon_polarity"를 통과했습니다. 그런 다음 일치하는 분류 헤드도 추가합니다. 마지막으로 train_adapter()를 사용하여 어댑터와 예측 헤드를 활성화합니다.
기본적으로 train_adapter() 메서드는 주로 두 가지 기능을 수행합니다.
- 훈련 중에 어댑터 가중치만 업데이트되도록 사전 훈련된 모델의 모든 가중치를 동결합니다.
- 또한 어댑터와 예측 헤드를 활성화하여 모든 순방향 패스에서 둘 다 사용합니다.
#Adding adapter to the RoBERTa model
model.add_adapter("amazon_polarity") # Adding a matching classification head
model.add_classification_head( "amazon_polarity", num_labels=2, id2label={ 0: "negative", 1: "positive"} ) # Activating the adapter
model.train_adapter("amazon_polarity")TraniningArguments 클래스의 도움으로 훈련 과정을 구성할 것입니다. 다음으로 평가 정확도를 계산하는 함수도 작성합니다. 마지막으로 학습 어댑터에만 최적화된 클래스인 AdapterTrainer에 인수를 전달합니다.
import numpy as np
from transformers import TrainingArguments, AdapterTrainer, EvalPrediction training_args = TrainingArguments( learning_rate=3e-4, max_steps=80000, per_device_train_batch_size=32, per_device_eval_batch_size=32, logging_steps=1000, output_dir="adapter-roberta-base-amazon-polarity", overwrite_output_dir=True, remove_unused_columns=False,
) def compute_accuracy(eval_pred): preds = np.argmax(eval_pred.predictions, axis=1) return {"acc": (preds == eval_pred.label_ids).mean()}
trainer = AdapterTrainer( model=model, args=training_args, train_dataset=dataset["train"], eval_dataset=dataset["test"], compute_metrics=compute_accuracy,
)지금 훈련을 시작합시다!
trainer.train()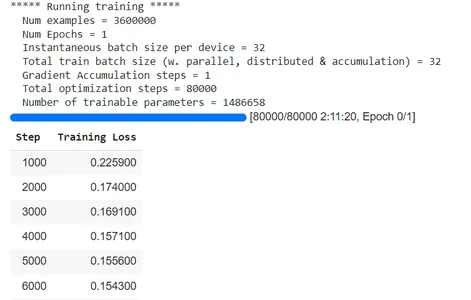
TrainOutput(global_step=80000, training_loss=0.13133217878341674, metrics={'train_runtime': 7884.1676, 'train_samples_per_second': 324.701, 'train_steps_per_second': 10.147, 'total_flos': 1.33836672e+17, 'train_loss': 0.13133217878341674, 'epoch': 0.71})
훈련된 모델 평가
이제 데이터 세트의 테스트 분할에서 어댑터의 성능을 평가해 보겠습니다.
trainer.evaluate()
Hugging Face 파이프라인의 도움으로 훈련된 모델을 사용하여 빠른 예측을 할 수 있습니다.
from transformers import TextClassificationPipeline
classifier = TextClassificationPipeline(model=model, tokenizer=tokenizer, device=training_args.device.index) classifier("I came across a lot of reviews stating that it is the best book out there.")#import csv출력: [{'라벨': '양수', '점수': 0.5589291453361511}]
어댑터 추출 및 저장
궁극적으로 훈련된 모델에서 어댑터를 추출하고 나중에 사용할 수 있도록 저장할 수도 있습니다. save_adapter()는 어댑터 가중치 및 어댑터 구성을 저장하기 위한 파일을 생성합니다.
model.save_adapter("./final_adapter", "amazon_polarity")
!ls -lh final_adapter
어댑터 비활성화 및 삭제
어댑터 작업을 마치고 어댑터가 더 이상 필요하지 않으면 어댑터를 비활성화하고 삭제하여 기본 모델의 가중치를 원래 형식으로 복원할 수 있습니다.
#Deactivating the adapter
model.set_active_adapters(None) #Deleting the added adapter
model.delete_adapter("amazon_polarity")훈련된 모델을 허브로 푸시
나중에 사용할 수 있도록 훈련된 모델을 Hugging Face 허브로 푸시할 수도 있습니다. 이를 위해 라이브러리를 가져오고 git을 설치한 다음 모델을 허브로 푸시합니다.
from huggingface_hub import notebook_login
notebook_login() !apt install git-lfs !git config --global credential.helper store trainer.push_to_hub()모델 카드 링크: https://huggingface.co/DrishtiSharma/adapter-roberta-base-amazon-polarity
전체 미세 조정과 어댑터의 비교
- 어댑터의 미세 조정에는 사전 훈련된 모델의 매개변수가 동결된 상태에서 어댑터 매개변수의 업데이트만 포함되므로 전체 미세 조정과 비교할 때 훈련 시간, 미세 조정 계산 비용 및 어댑터 모듈의 메모리 공간이 크게 줄어듭니다. -동조.
- 어댑터 모듈은 사전 훈련된 모델과 쉽게 통합되어 전체 모델을 재훈련할 필요 없이 새로운 작업에 적응할 수 있습니다. 특히 어댑터 가중치를 포함하는 파일 크기는 3.5MB에 불과합니다. 이 두 가지 측면 모두 여러 작업에서 쉽게 재사용할 수 있는 잠재력을 강조합니다.
- Amazon Review Polarity 데이터 세트에서 RoBERTa 모델을 미세 조정하려고 시도하는 동안 메모리 관련 문제가 발생하여 훈련 세션이 약 40k 단계에서 갑자기 종료되었습니다. 이것은 계산 리소스가 제한된 시나리오에서 어댑터의 이점을 강조합니다. 어댑터는 완전 미세 조정보다 훨씬 더 유망한 접근 방식입니다.
- 더 결론을 내리기 위해, 나는 어댑터 과 로베르타 모델 더 작은 데이터 세트, 즉 "Rotten Tomatoes". 어댑터가 전체 미세 조정 모델보다 더 나은 점수를 받았다는 사실에 기분 좋게 놀랐습니다. 특히 약 113 에포크 동안 어댑터를 교육한 후 eval_acc는 88.93%였으며 모델이 과대적합되기 시작했습니다. 반면에 RoBERTa 모델을 동일한 에포크 수로 학습했을 때 eval_acc는 50%, train_loss 및 eval_loss는 약 0.693이었으며 여전히 감소하고 있었습니다. 그럼에도 불구하고 보다 공정하고 구체적인 결론을 내리기 위해서는 훨씬 더 많은 실험이 수행되어야 합니다.
학습된 어댑터의 응용
다음은 시퀀스 분류 작업을 위해 Amazon Polarity 데이터 세트에서 훈련된 어댑터의 잠재적인 응용 프로그램 중 일부입니다.
- 소셜 미디어 분석: 훈련된 어댑터는 소셜 미디어 게시물 또는 댓글의 근본적인 감정을 분석할 수 있습니다. 기업은 이를 사용하여 고객 감정을 측정하고 적시에 부정적/제한적 피드백에 효과적으로 대응할 수 있습니다.
- 고객 서비스 : 훈련된 어댑터를 사용하여 제기된 고객 지원 티켓을 긍정적 또는 부정적으로 자동 분류하여 지원 팀이 보다 효과적이고 시기 적절하게 고객 불만을 처리하고 우선 순위를 지정할 수 있습니다.
- 제품/서비스 리뷰: 훈련된 어댑터는 제품/서비스 리뷰를 긍정적 또는 부정적으로 자동 분류할 수 있으므로 기업이 제품에 대한 고객 만족도를 신속하게 측정할 수 있습니다.
- 시장 조사: 훈련된 어댑터는 고객 피드백 설문 조사, 시장 조사 양식 등의 정서를 분석하는 데에도 사용할 수 있으며, 이를 통해 제품/서비스/브랜드에 대한 고객 정서에 대한 통찰력을 얻을 수 있습니다.
- 브랜드 모니터링: 훈련된 모델은 브랜드 또는 제품에 대한 온라인 언급을 모니터링하고 감정에 따라 분류하는 데 사용할 수 있으므로 기업은 온라인 평판을 추적하고 부정적인 피드백이나 불만에 대응할 수 있습니다.
어댑터의 장단점
어댑터는 기존 방법에 비해 몇 가지 장점이 있습니다. 다음은 NLP에서 어댑터의 몇 가지 장점입니다.
- 효율적인 미세 조정: 어댑터는 처음부터 전체 모델을 교육하는 것보다 더 적은 매개변수로 새 작업에서 미세 조정할 수 있습니다.
- 모듈 형 : 어댑터는 모듈식/교체 가능합니다. 사전 학습된 모델에 쉽게 교체하거나 추가할 수 있습니다.
- 도메인별 적응: 어댑터는 도메인별 작업에서 미세 조정될 수 있으므로 해당 작업에서 더 나은 성능을 얻을 수 있습니다.
- 증분 학습: 증분 학습에 어댑터를 사용할 수 있으므로 효율적이고 지속적인 학습이 가능하고 사전 훈련된 모델을 새 데이터에 적용할 수 있습니다.
- 더 빠른 교육: 어댑터는 처음부터 전체 모델을 교육하는 것보다 빠르게 교육할 수 있으므로 더 빠른 실험 및 프로토타이핑에 도움이 됩니다.
- 더 작은 크기: 어댑터는 미세 조정된 모델보다 훨씬 작기 때문에 더 빠른 추론과 적은 메모리 소비가 가능합니다.
어댑터에는 몇 가지 장점이 있지만 몇 가지 단점도 있습니다. 어댑터의 몇 가지 단점은 다음과 같습니다.
- 성능 저하: 추가 어댑터 계층이 사전 훈련된 모델 위에 추가되기 때문에 모델에 계산 오버헤드가 추가되고 추론 속도 및 정확도와 관련하여 모델의 성능에 영향을 미칠 수 있습니다.
- 복잡성 증가: 다시 말하지만 어댑터가 사전 학습된 모델에 추가되면 어댑터 계층의 입력 및 출력을 허용하도록 모델을 수정해야 합니다. 그러면 모델의 전체 아키텍처가 더 복잡해질 수 있습니다.
- 제한된 표현력: 어댑터는 작업에 따라 다르며 특정 작업, 특히 복잡한 작업 또는 도메인별 지식이 필요한 작업에 대해 미세 조정된 완전히 훈련된 모델만큼 표현력이 없을 수 있습니다.
- 제한된 양도 가능성: 어댑터는 제한된 작업별 데이터에 대해 교육을 받기 때문에 새 작업이나 도메인에 대해 잘 일반화할 수 없기 때문에 작업이나 도메인이 어댑터가 교육받은 것과 다를 때 유용성이 떨어질 수 있습니다.
- 과적합 가능성: 이 기사 자체에서 수행한 실험은 어댑터가 특정 단계 후에 과적합되기 시작하여 다운스트림 작업에서 성능이 저하될 수 있음을 보여주었습니다.
향후 연구 방향
다음은 어댑터의 고급 개발 및 사용을 촉진하는 데 도움이 될 수 있는 몇 가지 잠재적인 연구 방향입니다.
- 다양한 어댑터 아키텍처 탐색: 어댑터는 현재 사전 훈련된 모델의 레이어 사이에 삽입된 작은 피드포워드 신경망으로 구현됩니다. 특정 작업에 대해 더 나은 성능을 제공할 수 있는 어댑터에 대한 다양한 아키텍처를 탐색할 수 있는 엄청난 잠재력이 있습니다. 여기에는 매개변수 공유를 위한 새로운 방법 조사, 여러 계층이 있는 어댑터 설계, 다양한 활성화 기능 탐색, 주의 통합 등이 포함될 수 있습니다.
- 어댑터 크기의 영향 연구: 더 큰 어댑터는 더 작은 어댑터보다 더 잘 작동하는 것으로 나타났습니다. 그러나 여기에는 모델의 "대형"이 추론 속도와 계산 비용/요구 사항에 영향을 미친다는 주의 사항이 있습니다. 따라서 특정 작업을 기반으로 어댑터의 최적 크기를 탐색하기 위해 추가 연구가 수행될 수 있습니다.
- 다층 어댑터 조사: 현재 어댑터는 선행 학습된 모델의 단일 계층에 추가됩니다. 주어진 작업에 대해 모델의 여러 계층을 조정할 수 있는 다중 계층 어댑터를 탐색할 수 있는 범위가 있습니다.
- 다른 방식에 적응하기: 어댑터는 주로 NLP와 관련하여 개발, 연구 및 테스트되었지만 이미지, 오디오 처리 등과 같은 다른 양식에 대한 사용을 연구할 수 있는 범위가 있습니다.
- 효율성 및 확장성 개선: 어댑터 교육의 효율성과 확장성은 현재보다 훨씬 더 향상될 수 있습니다.
- 다중 영역 적응 및 다중 작업 학습: 어댑터는 새로운 도메인과 작업에 빠르게 적응하는 것으로 나타났습니다. 향후 연구는 여러 도메인에 동시에 적응할 수 있는 어댑터를 개발하는 데 도움이 될 수 있습니다.
- 어댑터를 사용한 압축 및 가지치기: 어댑터의 효율성을 유지하면서 어댑터를 압축하거나 잘라내는 방법을 개발하여 어댑터의 효율성을 더욱 높일 수 있습니다.
- 강화 학습을 위한 어댑터: 강화 학습을 위한 어댑터 사용을 조사하면 에이전트가 복잡한 환경에서 더 빠르고 효과적으로 학습할 수 있습니다.
결론
이 기사는 당면한 작업을 기반으로 주어진 사전 훈련된 모델의 가중치를 변경하도록 어댑터 모델을 훈련시키는 방법을 제시합니다. 또한 작업이 완료되면 어댑터를 비활성화하고 삭제하여 기본 모델의 가중치를 원래 형태로 쉽게 복원할 수 있음을 확인했습니다.
요약하면 이 기사의 주요 내용은 다음과 같습니다.
- 어댑터는 다양한 작업 및 언어를 기반으로 선행 학습된 모델에 동적으로 추가할 수 있는 작은 병목 현상 계층입니다.
- 우리는 HuggingFace의 변환기 라이브러리의 AdapterHub 적응인 어댑터 변환기의 도움을 받아 감정 분류 작업을 위한 Amazon 극성 데이터 세트에서 RoBERTa 모델용 어댑터를 교육했습니다.
- train_adapter() 메서드는 훈련 중에 어댑터 가중치만 업데이트되도록 사전 훈련된 모델의 모든 가중치를 동결합니다. 또한 어댑터와 예측 헤드를 활성화하여 모든 순방향 패스에서 둘 다 사용합니다.
- 학습된 모델의 어댑터를 추출하여 나중에 사용할 수 있도록 저장할 수 있습니다. save_adapter()는 어댑터 가중치 및 어댑터 구성을 저장하기 위한 파일을 생성합니다.
- 어댑터가 필요하지 않은 경우 어댑터를 비활성화하고 삭제하여 기본 모델의 가중치를 원래 형태로 복원할 수 있습니다.
- 완전히 미세 조정된 RoBERTa 모델보다 어댑터가 더 나은 성능을 보이는 것처럼 보였지만 구체적인 결론을 내리기 위해서는 더 많은 실험을 수행해야 합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/04/training-an-adapter-for-roberta-model-for-sequence-classification-task/

