개요
인공 지능 분야에서는 OpenAI의 GPT-4, Anthropic의 Claude 2, Meta의 Llama, Falcon, Google의 Palm 등과 같은 LLM(대형 언어 모델) 및 생성 AI 모델이 문제 해결 방식에 혁명을 일으켰습니다. LLM은 딥러닝 기술을 사용하여 자연어 처리 작업을 수행합니다. 이 기사에서는 벡터 데이터베이스를 사용하여 LLM 앱을 구축하는 방법을 설명합니다. Amazon 고객 서비스나 Flipkart Decision Assistant와 같은 챗봇과 상호 작용했을 수도 있습니다. 인간과 유사한 텍스트를 생성하고 실제 대화와 거의 구별할 수 없는 대화형 사용자 경험을 제공합니다. 그럼에도 불구하고 이러한 LLM은 특정 사용 사례에 실제로 유용할 수 있도록 관련성이 높고 구체적인 결과를 생성하도록 최적화되어야 합니다.

예를 들어, "안드로이드 앱에서 언어를 어떻게 변경하나요?"라고 묻는다면 Amazon 고객 서비스 앱에는 이 정확한 텍스트에 대한 교육을 받지 못했기 때문에 응답하지 못할 수도 있습니다. 이것이 벡터 데이터베이스가 구출되는 곳입니다. 벡터 데이터베이스는 주문 내역 등을 포함한 모든 사용자의 도메인 텍스트(이 경우 도움말 문서)와 과거 쿼리를 수치 임베딩으로 저장하고 유사한 벡터를 실시간으로 조회하는 기능을 제공합니다. 이 경우, 이 쿼리를 숫자 벡터로 인코딩하고 이를 사용하여 벡터 데이터베이스에서 유사성 검색을 수행하고 가장 가까운 이웃을 찾습니다. 이 도움을 통해 챗봇은 사용자를 Amazon 앱의 "언어 기본 설정 변경" 섹션으로 올바르게 안내할 수 있습니다.
학습 목표
- LLM은 어떻게 작동하고 한계는 무엇이며 벡터 데이터베이스가 필요한 이유는 무엇입니까?
- 임베딩 모델 소개 및 이를 애플리케이션에서 인코딩하고 사용하는 방법.
- 벡터 데이터베이스가 무엇인지, 그리고 이것이 LLM 애플리케이션 아키텍처의 일부인지 알아보세요.
- 벡터 데이터베이스와 텐서플로우를 사용하여 LLM/Generative AI 애플리케이션을 코딩하는 방법을 알아보세요.
이 기사는 데이터 과학 블로그.
차례
LLM이란 무엇입니까?
LLM(대형 언어 모델)은 딥 러닝 알고리즘을 사용하여 자연어를 처리하고 이해하는 기본 기계 학습 모델입니다. 이러한 모델은 언어의 패턴과 엔터티 관계를 학습하기 위해 방대한 양의 텍스트 데이터에 대해 교육을 받습니다. LLM은 언어 번역, 감정 분석, 챗봇 대화 등과 같은 다양한 유형의 언어 작업을 수행할 수 있습니다. 복잡한 텍스트 데이터를 이해하고 데이터 사이의 엔터티와 관계를 식별하며 일관성 있고 문법적으로 정확한 새 텍스트를 생성할 수 있습니다.
LLM에 대해 자세히 알아보기 여기에서 지금 확인해 보세요..
LLM은 어떻게 작동하나요?
LLM은 수십억 또는 수조 개의 매개변수가 포함된 테라바이트, 심지어 페타바이트에 이르는 대용량 데이터를 사용하여 교육되므로 사용자의 프롬프트나 쿼리를 기반으로 관련 응답을 예측하고 생성할 수 있습니다. 단어 임베딩, self-attention 레이어 및 피드포워드 네트워크를 통해 입력 데이터를 처리하여 의미 있는 텍스트를 생성합니다. LLM 아키텍처에 대해 자세히 알아볼 수 있습니다. 여기에서 지금 확인해 보세요..
LLM의 한계
LLM은 꽤 높은 정확도로 응답을 생성하는 것처럼 보이지만 더 많은 표준화된 분야에서 인간보다 테스트, 이러한 모델에는 여전히 제한 사항이 있습니다. 첫째, 추론을 구축하기 위해 훈련 데이터에만 의존하므로 데이터에 특정 정보나 최신 정보가 부족할 수 있습니다. 이로 인해 모델은 일명 "환각"이라는 부정확하거나 비정상적인 반응을 생성하게 됩니다. 지속적인 진행이 있었습니다 노력 이를 완화하기 위해. 둘째, 모델이 사용자의 기대에 부합하는 방식으로 동작하거나 반응하지 않을 수 있습니다.
이 문제를 해결하기 위해 벡터 데이터베이스와 임베딩 모델은 사용자가 정보를 찾고 있는 유사한 양식(텍스트, 이미지, 비디오 등)에 대한 추가 조회를 제공하여 LLM/생성 AI에 대한 지식을 향상시킵니다. 다음은 LLM에 사용자가 요청한 응답이 없고 대신 벡터 데이터베이스를 사용하여 해당 정보를 찾는 예입니다.

LLM 및 벡터 데이터베이스
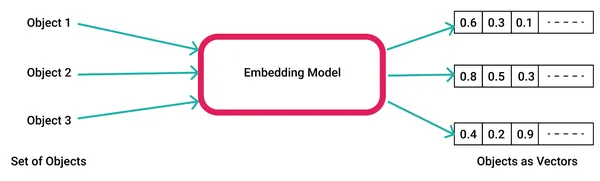
LLM(대형 언어 모델)은 전자상거래, 여행, 검색, 콘텐츠 제작, 금융 등 산업의 여러 부분에서 활용되거나 통합되고 있습니다. 이러한 모델은 텍스트, 이미지, 비디오 및 기타 데이터의 수치 표현을 임베딩이라는 이진 표현으로 저장하는 벡터 데이터베이스라고 하는 비교적 새로운 유형의 데이터베이스에 의존합니다. 이 섹션에서는 벡터 데이터베이스 및 임베딩의 기본 사항을 강조하고, 더 중요하게는 이를 사용하여 LLM 응용 프로그램과 통합하는 방법에 중점을 둡니다.
벡터 데이터베이스는 고차원 공간을 활용하여 임베딩을 저장하고 검색하는 데이터베이스입니다. 이러한 벡터는 데이터의 특징이나 속성을 수치로 표현한 것입니다. 벡터 데이터베이스는 고차원 공간에서 벡터 간의 거리나 유사성을 계산하는 알고리즘을 사용하여 유사한 데이터를 빠르고 효율적으로 검색할 수 있습니다. 행이나 열에 데이터를 저장하고 정확한 일치 또는 키워드 기반 검색 방법을 사용하는 기존 스칼라 기반 데이터베이스와 달리 벡터 데이터베이스는 다르게 작동합니다. 이들은 벡터 데이터베이스를 사용하여 ANN(Approximate Nearest Neighbors)과 같은 기술을 사용하여 매우 짧은 시간(밀리초 단위) 내에 대규모 벡터 컬렉션을 검색하고 비교합니다.
임베딩에 대한 빠른 튜토리얼
AI 모델은 텍스트, 비디오, 이미지 등의 원시 데이터를 벡터 임베딩 라이브러리에 입력하여 임베딩을 생성합니다. 워드2벡 AI 및 기계 학습의 맥락에서 이러한 기능은 패턴 관계 및 기본 구조를 이해하는 데 필수적인 데이터의 다양한 차원을 나타냅니다.
다음은 word2vec을 사용하여 단어 임베딩을 생성하는 방법의 예입니다.
1. 사용자 정의 데이터 코퍼스를 사용하여 모델을 생성하거나 다음에서 사전 구축된 샘플 모델을 사용합니다. 구글 또는 FastText. 직접 생성한 경우 파일 시스템에 "word2vec.model" 파일로 저장할 수 있습니다.
import gensim # Create a word2vec model
model = gensim.models.Word2Vec(corpus) # Save the model file
model.save('word2vec.model')2. 모델을 로드하고, 입력 단어에 대한 벡터 임베딩을 생성하고, 이를 사용하여 벡터 임베딩 공간에서 유사한 단어를 얻습니다.
import gensim
import numpy as np # Load the word2vec model
model = gensim.models.Word2Vec.load('word2vec.model') # Get the vector for the word "king"
king_vector = model['king'] # Get the most similar vectors to the king vector
similar_vectors = model.similar_by_vector(king_vector, topn=5) # Print the most similar vectors
for vector in similar_vectors: print(vector[0], vector[1]) 3. 입력된 단어에 가까운 상위 5개 단어는 다음과 같습니다.
Output: man 0.85
prince 0.78
queen 0.75
lord 0.74
emperor 0.72벡터 데이터베이스를 사용한 LLM 애플리케이션 아키텍처
높은 수준에서 벡터 데이터베이스는 임베딩 생성 및 쿼리를 모두 처리하기 위해 임베딩 모델을 사용합니다. 수집 경로에서는 코퍼스 콘텐츠가 임베딩 모델을 사용하여 벡터로 인코딩되어 Pinecone, ChromaDB, Weaviate 등과 같은 벡터 데이터베이스에 저장됩니다. 읽기 경로에서는 애플리케이션이 문장이나 단어를 사용하여 쿼리를 수행하고 다시 인코딩됩니다. 임베딩 모델을 통해 벡터에 넣은 다음 벡터 db에 쿼리하여 결과를 가져옵니다.
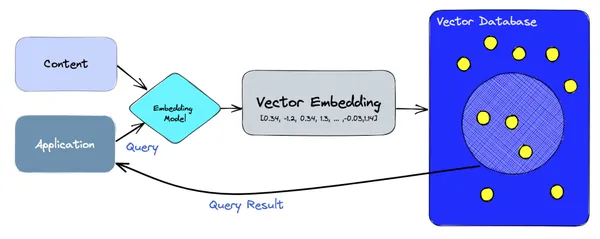
벡터 데이터베이스를 사용하는 LLM 응용 프로그램
LLM은 언어 작업에 도움이 되며 다음과 같은 더 광범위한 모델 클래스에 포함됩니다. 제너레이티브 AI 텍스트 외에 이미지와 비디오를 생성할 수 있습니다. 이 섹션에서는 벡터 데이터베이스를 사용하여 실용적인 LLM/Generative AI 애플리케이션을 구축하는 방법을 알아봅니다. 나는 언어 모델을 위해 변환기와 토치 라이브러리를 사용했고 피네 코네 벡터 데이터베이스로. LLM/임베딩을 위한 언어 모델과 저장 및 검색을 위한 벡터 데이터베이스를 선택할 수 있습니다.
챗봇 앱
벡터 데이터베이스를 사용하여 챗봇을 구축하려면 다음 단계를 따르세요.
- Pinecone, Chroma, Weaviate, AWS Kendra 등과 같은 벡터 데이터베이스를 선택합니다.
- 챗봇에 대한 벡터 인덱스를 만듭니다.
- 선택한 큰 텍스트 코퍼스를 사용하여 언어 모델을 훈련합니다. 예를 들어 뉴스 챗봇의 경우 뉴스 데이터를 제공할 수 있습니다.
- 벡터 데이터베이스와 언어 모델을 통합합니다.
다음은 벡터 데이터베이스와 언어 모델을 사용하는 챗봇 애플리케이션의 간단한 예입니다.
import pinecone
import transformers # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the language model
model = transformers.AutoModelForCausalLM.from_pretrained("google/bigbird-roberta-base") # Define a function to generate text
def generate_text(prompt): inputs = model.prepare_inputs_for_generation(prompt, return_tensors="pt") outputs = model.generate(inputs, max_length=100) return outputs[0].decode("utf-8") # Define a function to retrieve the most similar vectors to the user's query vector
def retrieve_similar_vectors(query_vector): results = client.search("my_index", query_vector) return results # Define a function to generate a response to the user's query
def generate_response(query): # Retrieve the most similar vectors to the user's query vector similar_vectors = retrieve_similar_vectors(query) # Generate text based on the retrieved vectors response = generate_text(similar_vectors[0]) return response # Start the chatbot
while True: # Get the user's query query = input("What is your question? ") # Generate a response to the user's query response = generate_response(query) # Print the response print(response)이 챗봇 애플리케이션은 벡터 데이터베이스에서 사용자의 쿼리 벡터와 가장 유사한 벡터를 검색한 다음 검색된 벡터를 기반으로 언어 모델을 사용하여 텍스트를 생성합니다.
ChatBot > What is your question?
User_A> How tall is the Eiffel Tower?
ChatBot>The height of the Eiffel Tower measures 324 meters (1,063 feet) from its base to the top of its antenna. 이미지 생성기 앱
두 가지를 모두 사용하는 이미지 생성기 앱을 구축하는 방법을 살펴보겠습니다. 제너레이티브 AI 및 LLM 라이브러리.
- 이미지 벡터를 저장할 벡터 데이터베이스를 만듭니다.
- 훈련 데이터에서 이미지 벡터를 추출합니다.
- 이미지 벡터를 벡터 데이터베이스에 삽입합니다.
- 생성적 적대 신경망(GAN)을 훈련시킵니다. 읽다 여기에서 지금 확인해 보세요. GAN에 대한 소개가 필요한 경우.
- 벡터 데이터베이스와 GAN을 통합합니다.
다음은 벡터 데이터베이스와 GAN을 통합하여 이미지를 생성하는 프로그램의 간단한 예입니다.
import pinecone
import torch
from torchvision import transforms # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the GAN
generator = torch.load("generator.pt") # Define a function to generate an image from a vector
def generate_image(vector): # Convert the vector to a tensor tensor = torch.from_numpy(vector).float() # Generate the image image = generator(tensor) # Transform the image to a PIL image image = transforms.ToPILImage()(image) return image # Start the image generator
while True: # Get the user's query query = input("What kind of image would you like to generate? ") # Retrieve the most similar vector to the user's query vector similar_vectors = client.search("my_index", query) # Generate an image from the retrieved vector image = generate_image(similar_vectors[0]) # Display the image image.show()이 프로그램은 벡터 데이터베이스에서 사용자의 쿼리 벡터와 가장 유사한 벡터를 검색한 후 검색된 벡터를 기반으로 GAN을 사용하여 이미지를 생성합니다.
ImageBot>What kind of image would you like to generate?
Me>An idyllic image of a mountain with a flowing river.
ImageBot> Wait a minute! Here you go...
특정 요구 사항에 맞게 이 프로그램을 사용자 정의할 수 있습니다. 예를 들어 인물 사진이나 풍경 사진과 같은 특정 유형의 이미지를 생성하는 데 특화된 GAN을 훈련할 수 있습니다.
영화 추천 앱
영화 코퍼스에서 영화 추천 앱을 구축하는 방법을 살펴보겠습니다. 유사한 아이디어를 사용하여 제품이나 기타 엔터티에 대한 추천 시스템을 구축할 수 있습니다.
- 영화 벡터를 저장할 벡터 데이터베이스를 만듭니다.
- 영화 메타데이터에서 영화 벡터를 추출합니다.
- 영화 벡터를 벡터 데이터베이스에 삽입합니다.
- 사용자에게 영화를 추천합니다.
다음은 Pinecone API를 사용하여 사용자에게 영화를 추천하는 방법의 예입니다.
import pinecone # Create an API client
client = pinecone.Client(api_key="YOUR_API_KEY") # Get the user's vector
user_vector = client.get_vector("user_index", user_id) # Recommend movies to the user
results = client.search("movie_index", user_vector) # Print the results
for result in results: print(result["title"])다음은 사용자를 위한 샘플 권장사항입니다.
The Shawshank Redemption
The Dark Knight
Inception
The Godfather
Pulp Fiction벡터 검색/데이터베이스를 사용한 LLM의 실제 사용 사례
- Microsoft와 TikTok은 장기 메모리와 빠른 조회를 위해 Pinecone과 같은 벡터 데이터베이스를 사용합니다. 이는 LLM이 벡터 데이터베이스 없이는 혼자서는 할 수 없는 일입니다. 사용자가 과거 질문/응답을 저장하고 세션을 재개하는 데 도움이 됩니다. 예를 들어 사용자는 "지난 주에 논의한 파스타 레시피에 대해 더 자세히 알려주세요."라고 질문할 수 있습니다. 읽다 여기에서 지금 확인해 보세요..

- Flipkart의 Decision Assistant는 먼저 쿼리를 벡터 임베딩으로 인코딩하고 관련 제품을 고차원 공간에 저장하는 벡터를 조회하여 사용자에게 제품을 추천합니다. 예를 들어 '랭글러 가죽 자켓 브라운 남성 미디엄'을 검색하면 벡터 유사 검색을 통해 사용자에게 관련 상품을 추천해 줍니다. 그렇지 않으면 제품 카탈로그에 그러한 제목이나 제품 세부 정보가 포함되어 있지 않으므로 LLM에는 권장 사항이 없습니다. 당신은 그것을 읽을 수 있습니다 여기에서 지금 확인해 보세요..
- 아프리카의 핀테크 기업인 Chipper Cash는 벡터 데이터베이스를 사용하여 사기 사용자 가입을 10배 줄였습니다. 이전 사용자 가입의 모든 이미지를 벡터 임베딩으로 저장하여 이를 수행합니다. 이후 신규 사용자가 가입하면 이를 벡터로 인코딩해 기존 사용자와 비교해 사기 행위를 탐지한다. 당신은 그것을 읽을 수 있습니다 여기에서 지금 확인해 보세요..

- Facebook은 다음과 같은 벡터 검색 라이브러리를 사용해 왔습니다. 파이스 (블로그) 내부적으로 Instagram Reels 및 Facebook Stories를 포함한 많은 제품에서 멀티미디어를 빠르게 검색하고 유사한 후보를 찾아 사용자에게 더 나은 제안을 표시합니다.
결론
벡터 데이터베이스는 이미지 생성, 영화 또는 제품 추천, 챗봇과 같은 다양한 LLM 애플리케이션을 구축하는 데 유용합니다. LLM이 교육을 받지 않은 추가 또는 유사한 정보를 LLM에 제공합니다. 벡터 임베딩을 고차원 공간에 효율적으로 저장하고 가장 가까운 이웃 검색을 사용하여 높은 정확도로 유사한 임베딩을 찾습니다.
주요 요점
이 기사의 핵심 내용은 벡터 데이터베이스가 LLM 앱에 매우 적합하며 사용자가 통합할 수 있는 다음과 같은 중요한 기능을 제공한다는 것입니다.
- 퍼포먼스: 벡터 데이터베이스는 고성능 LLM 앱 개발에 중요한 벡터 데이터를 효율적으로 저장하고 검색하도록 특별히 설계되었습니다.
- Precision: 벡터 데이터베이스는 약간의 차이가 있더라도 유사한 벡터를 정확하게 일치시킬 수 있습니다. 유사한 벡터를 계산하기 위해 가장 가까운 이웃 알고리즘을 사용합니다.
- 다중 모드: 벡터 데이터베이스는 텍스트, 이미지, 사운드를 포함한 다양한 다중 모드 데이터를 수용할 수 있습니다. 이러한 다양성 덕분에 다양한 데이터 유형으로 작업해야 하는 LLM/Generative AI 앱에 이상적인 선택이 됩니다.
- 개발자 친화적: 벡터 데이터베이스는 기계 학습 기술에 대한 광범위한 지식이 없는 개발자에게도 비교적 사용자 친화적입니다.
또한 기존의 많은 SQL/NoSQL 솔루션에 이미 벡터 임베딩 스토리지, 인덱싱 및 더 빠른 유사성 검색 기능이 추가되어 있다는 점을 강조하고 싶습니다. PostgreSQL 과 Redis. 이는 빠르게 발전하는 공간이므로 앱 개발자는 가까운 미래에 혁신적인 앱을 구축할 수 있는 다양한 옵션을 갖게 될 것입니다.
자주 묻는 질문
A. 대규모 언어 모델(LLM)은 맥락에 따라 인간과 유사한 반응을 모방하기 위해 신경망을 사용하여 대규모 텍스트 데이터 모음에 대해 훈련된 고급 인공 지능(AI) 프로그램입니다. 그들은 훈련받은 영역에서 텍스트 데이터를 예측하고, 대답하고, 생성할 수 있습니다.
A. 임베딩은 텍스트, 이미지, 비디오 또는 기타 데이터 형식을 숫자로 표현한 것입니다. 이를 통해 고차원 공간에서 의미적으로 유사한 객체를 더 쉽게 함께 배치하고 찾을 수 있습니다.
A. 데이터베이스는 지역 구분 해싱과 같은 최근접 알고리즘을 사용하여 유사한 벡터를 찾기 위해 고차원 벡터 임베딩을 저장하고 쿼리합니다. LLM/Generative AI는 LLM 자체를 미세 조정하는 대신 유사한 벡터에 대한 추가 조회를 제공하는 데 도움이 필요합니다.
A. 벡터 데이터베이스는 벡터 임베딩을 색인화하고 검색하는 데 도움이 되는 틈새 데이터베이스입니다. 이는 오픈 소스 커뮤니티에서 널리 인기가 있으며 많은 조직/앱이 이를 통합하고 있습니다. 그러나 기존의 많은 SQL/NoSQL 데이터베이스에는 유사한 기능이 추가되어 개발자 커뮤니티가 가까운 미래에 많은 옵션을 갖게 될 것입니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/10/how-to-build-llm-apps-using-vector-database/

