개요
정보가 넘쳐나는 세상에서 관련 데이터에 효율적으로 접근하고 추출하는 것은 매우 중요합니다. ResearchBot은 OpenAI의 LLM(대규모 언어 모델) 정보 검색을 위해 Langchain을 사용합니다. 이 기사는 자신만의 ResearchBot을 제작하고 이것이 실제 생활에 어떻게 도움이 될 수 있는지에 대한 단계별 매뉴얼과 같습니다. 이는 마치 데이터의 바다에서 필요한 정보를 찾아주는 지능형 비서를 갖는 것과 같습니다. 코딩을 좋아하든 AI에 관심이 있든 이 가이드는 맞춤형 LLM 기반 AI 도우미를 통해 연구 역량을 강화하는 데 도움이 됩니다. LLM의 잠재력을 활용하고 정보에 접근하는 방법을 혁신하는 것이 여러분의 여정입니다.

학습 목표
- LLM(대형 언어 모델), Langchain, 벡터 데이터베이스 및 임베딩에 대한 보다 심오한 개념을 이해합니다.
- 연구, 고객 지원, 콘텐츠 생성과 같은 분야에서 LLM 및 ResearchBot의 실제 응용 프로그램을 살펴보세요.
- ResearchBot을 기존 프로젝트 또는 워크플로에 통합하여 생산성과 의사 결정을 향상시키는 모범 사례를 알아보세요.
- ResearchBot을 구축하여 데이터 추출 및 쿼리 응답 프로세스를 간소화하세요.
- LLM 기술의 동향과 이 정보에 액세스하고 사용하는 방법을 혁신할 수 있는 잠재력에 대한 최신 정보를 받아보세요.
이 기사는 데이터 과학 블로그.
차례
리서치봇이란 무엇인가요?
ResearchBot은 LLM이 지원하는 연구 조교입니다. 콘텐츠에 빠르게 액세스하고 요약할 수 있는 혁신적인 도구이므로 다양한 산업 분야의 전문가에게 훌륭한 파트너가 됩니다.
여러 기사, 문서 및 웹 사이트 페이지를 읽고 이해하며 관련성 있는 짧은 요약을 제공할 수 있는 개인화된 비서가 있다고 상상해 보십시오. ResearchBot의 목표는 귀하의 연구 목적에 필요한 시간과 노력을 줄이는 것입니다.
실제 사용 사례
- 재무 분석: 최신 시장 뉴스를 받아보고 금융 문의에 대한 빠른 답변을 받아보세요.
- 저널리즘: 기사에 대한 배경 정보, 출처, 참고 자료를 효율적으로 수집하세요.
- 건강 관리: 연구 목적으로 최신 의학 연구 논문 및 요약에 액세스하세요.
- 학계 : 관련 학술 논문, 연구 자료, 연구 질문에 대한 답변을 찾아보세요.
- 합법적 연구: 법적 문제에 대한 법률 문서, 판결, 통찰력을 신속하게 검색하세요.
기술 용어
벡터 데이터베이스
텍스트 데이터의 벡터 임베딩을 저장하는 컨테이너는 효율적인 유사성 기반 검색에 매우 중요합니다.
의미 검색
완벽한 키워드 일치에 전적으로 의존하지 않고 검색을 수행하기 위해 사용자 쿼리 의도와 컨텍스트를 이해합니다.
퍼가기
효율적인 비교 및 검색을 가능하게 하는 텍스트 데이터의 수치 표현입니다.
프로젝트의 기술 아키텍처
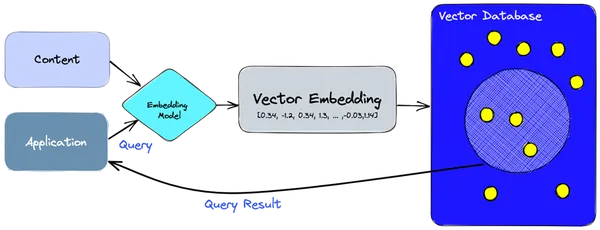
- 우리는 임베딩 모델을 사용하여 인덱싱해야 하는 정보나 콘텐츠에 대한 벡터 임베딩을 만듭니다.
- 벡터 임베딩은 임베딩이 생성된 원본 콘텐츠에 대한 일부 참조와 함께 벡터 데이터베이스에 삽입됩니다.
- 애플리케이션이 쿼리를 실행하면 동일한 임베딩 모델을 사용하여 쿼리에 대한 임베딩을 생성하고 해당 임베딩을 사용하여 유사한 벡터 임베딩에 대해 데이터베이스를 쿼리합니다.
- 이러한 유사한 임베딩은 이를 생성하는 데 사용된 원본 콘텐츠와 연결됩니다.
ResearchBot은 어떻게 작동하나요?
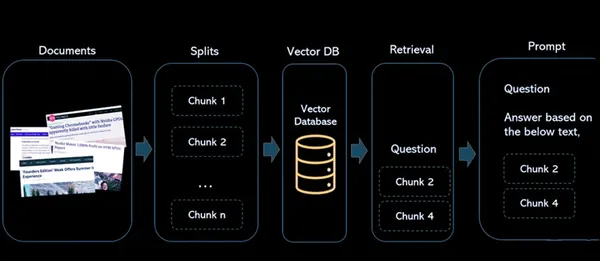
이 아키텍처는 콘텐츠의 저장, 검색 및 상호 작용을 용이하게 하여 ResearchBot을 정보 검색 및 분석을 위한 강력한 도구로 만듭니다. 벡터 임베딩과 벡터 데이터베이스를 활용하여 빠르고 정확한 콘텐츠 검색을 촉진합니다.
구성 요소들
- 서류: 이는 향후 참조 및 검색을 위해 색인을 생성하려는 기사 또는 콘텐츠입니다.
- 분할: 이는 문서를 더 작고 관리 가능한 덩어리로 나누는 프로세스를 처리합니다. 이는 대규모 문서나 기사로 작업하여 언어 모델의 제약 조건에 완벽하게 맞도록 하고 효율적인 색인을 생성하는 데 중요합니다.
- 벡터 데이터베이스: 벡터 데이터베이스는 아키텍처의 중요한 부분입니다. 콘텐츠에서 생성된 벡터 임베딩을 저장합니다. 각 벡터는 파생된 원본 콘텐츠와 연결되어 수치 표현과 원본 자료 간의 링크를 생성합니다.
- 검색: 사용자가 시스템에 쿼리하면 동일한 임베딩 모델이 사용되어 쿼리에 대한 임베딩을 생성합니다. 그런 다음 이러한 쿼리 임베딩은 벡터 데이터베이스에서 유사한 벡터 임베딩을 검색하는 데 사용됩니다. 그 결과 각각 원본 콘텐츠 소스와 연결된 유사한 벡터의 큰 그룹이 생성됩니다.
- 프롬프트 : 사용자가 시스템과 상호 작용하는 위치가 정의됩니다. 사용자가 쿼리를 입력하면 시스템은 이러한 쿼리를 처리하여 벡터 데이터베이스에서 관련 정보를 검색하고 소스 콘텐츠에 대한 답변과 참조를 제공합니다.
LangChain의 문서 로더
문서 로더를 사용하여 소스의 데이터를 문서 형식으로 로드합니다. 문서는 텍스트 및 관련 메타데이터의 일부입니다. 예를 들어, 간단한 .txt 파일을 로드하고, 기사나 블로그의 텍스트 콘텐츠를 로드하고, YouTube 비디오의 스크립트를 로드하는 문서 로더가 있습니다.
문서 로더에는 다양한 유형이 있습니다.
| 짐을 싣는 사람 | 용법 |
|---|---|
| 텍스트로더 | 처리할 일반 텍스트 문서를 로드합니다. |
| CSV로더 | CSV 파일에서 데이터를 가져옵니다. |
| 디렉토리로더 | 디렉터리에서 콘텐츠를 읽고 로드합니다. |
| 구조화되지 않은HTMLLoader | 구조화되지 않은 HTML 콘텐츠를 가져와 처리합니다. |
| JSONLoader | JSON 파일에서 데이터를 로드합니다. |
| 구조화되지 않은MarkdownLoader | 구조화되지 않은 Markdown 콘텐츠를 처리하고 로드합니다. |
| PyPDFLoader | 추가 처리를 위해 PDF 파일에서 텍스트 콘텐츠를 추출합니다. |
예 – TextLoader
이 코드는 Langchain의 TextLoader 기능을 보여줍니다. 기존 파일 "Langchain.txt"의 텍스트 데이터를 TextLoader 클래스로 로드하여 추가 처리를 준비합니다. 'file_path' 변수는 향후 목적을 위해 로드되는 파일의 경로를 저장합니다.
# Import the TextLoader class from the langchain.document_loaders module
from langchain.document_loaders import TextLoader # consider the TextLoader class by mentioning the file to load, Here "Langchain.txt"
loader = TextLoader("Langchain.txt") # Load the content from provided file ("Langchain.txt") into the TextLoader class
loader.load() # Check the type of the 'loader' instance, which should be 'TextLoader'
type(loader) # The file path associated with the TextLoader in the 'file_path' variable
loader.file_path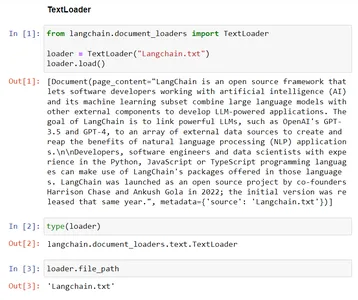
LangChain의 텍스트 분할기
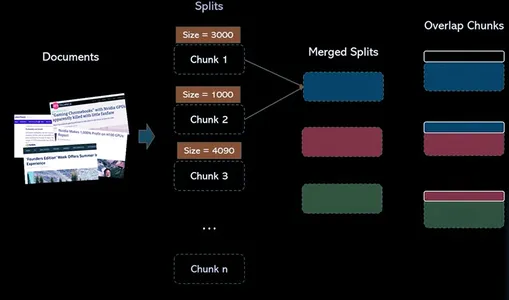
텍스트 분할기는 문서를 더 작은 문서로 분할하는 역할을 합니다. 이러한 작은 단위를 사용하면 콘텐츠를 더 쉽게 작업하고 효율적으로 처리할 수 있습니다. ResearchBot 프로젝트의 맥락에서 우리는 텍스트 분할기를 사용하여 추가 분석 및 검색을 위한 데이터를 준비합니다.
텍스트 분할기가 필요한 이유는 무엇입니까?
LLM에는 토큰 제한이 있습니다. 따라서 각 청크 크기가 토큰 제한 미만이 되도록 큰 텍스트를 작은 청크로 분할해야 합니다.
텍스트를 덩어리로 분할하는 수동 접근 방식
# Taking some random text from wikipedia
text # Say LLM token limit is 100, in our code we can do simple thing such as this text[:100]

글쎄요, 하지만 우리는 완전한 단어를 원하고 전체 텍스트에 대해 이 작업을 수행하고 싶습니다. Python의 분할 기능을 사용할 수 있을까요?
words = text.split(" ")
len(words) chunks = [] s = ""
for word in words: s += word + " " if len(s)>200: chunks.append(s) s = "" chunks.append(s) chunks[:2]
데이터를 청크로 분할하는 것은 기본 Python에서 수행할 수 있지만 이는 깔끔한 프로세스입니다. 또한 필요한 경우 각 청크가 해당 LLM의 토큰 길이 제한을 초과하지 않는지 확인하기 위해 연속적인 방식으로 여러 구분 기호를 실험해야 할 수도 있습니다.
Langchain은 텍스트 분할기 클래스를 통해 더 나은 방법을 제공합니다. 이를 가능하게 하는 랭체인에는 여러 개의 텍스트 분할기 클래스가 있습니다.
1. 문자 텍스트 분할기
이 클래스는 특정 구분 기호를 기반으로 텍스트를 더 작은 덩어리로 분할하도록 설계되었습니다. 단락, 마침표, 쉼표 및 줄 바꿈(n)과 같습니다. 추가 처리를 위해 텍스트를 여러 덩어리로 나누는 데 더 유용합니다.
from langchain.text_splitter import CharacterTextSplitter splitter = CharacterTextSplitter( separator = "n", chunk_size=200, chunk_overlap=0
) chunks = splitter.split_text(text)
len(chunks) for chunk in chunks: print(len(chunk))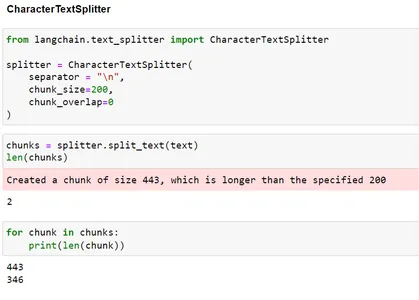
보시다시피, 분할이 n을 기반으로 했기 때문에 청크 크기를 200으로 주었지만 결국 크기 200보다 큰 청크가 생성되었습니다.
Langchain의 또 다른 클래스를 사용하여 구분 기호 목록을 기반으로 텍스트를 재귀적으로 분할할 수 있습니다. 이 클래스는 RecursiveTextSplitter입니다. 그것이 어떻게 작동하는지 봅시다.
2. 재귀 텍스트 분할기
이는 텍스트의 문자를 재귀적으로 분석하여 작동하는 일종의 텍스트 분할기입니다. 텍스트와 다양한 유형의 셸을 효과적으로 분할하는 분할 접근 방식을 식별할 때까지 텍스트를 여러 문자로 분할하려고 시도하고 다양한 문자 조합을 반복적으로 찾습니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter r_splitter = RecursiveCharacterTextSplitter( separators = ["nn", "n", " "], # List of separators chunk_size = 200, # size of each chunk created chunk_overlap = 0, # size of overlap between chunks length_function = len # Function to calculate size,
) chunks = r_splitter.split_text(text) for chunk in chunks: print(len(chunk)) first_split = text.split("nn")[0]
first_split
len(first_split) second_split = first_split.split("n")
second_split
for split in second_split: print(len(split)) second_split[2]
second_split[2].split(" ")
이러한 청크를 어떻게 구성했는지 이해해 보겠습니다.
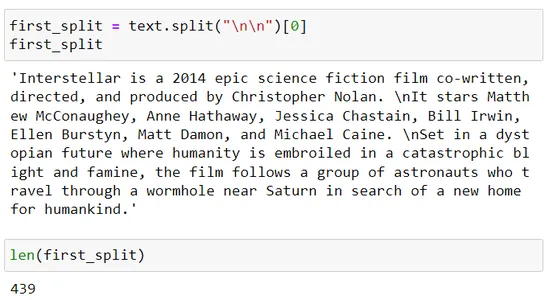
재귀 텍스트 분할기는 구분 기호 목록을 사용합니다. 즉, 구분 기호 = [“nn”, “n”, “.”]
따라서 이제 먼저 nn을 사용하여 분할한 다음 결과 청크 크기가 이 장면에서 200인 Chunk_size 매개변수보다 크면 다음 구분 기호인 n을 사용합니다.
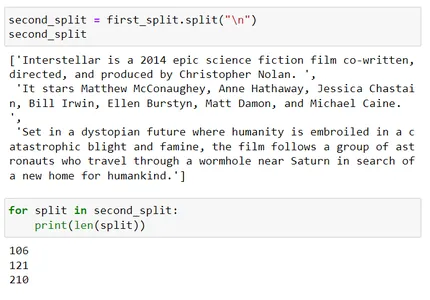
세 번째 분할이 청크 크기 200을 초과합니다. 이제 ' '(공백)인 세 번째 구분 기호를 사용하여 추가로 분할을 시도합니다.
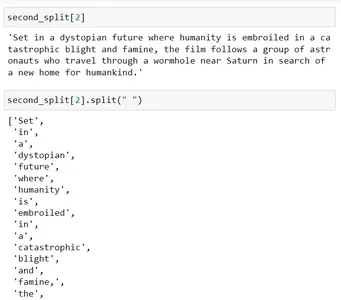
공백을 사용하여 이를 분할하면(예: second_split[2].split(" ")) 각 단어가 분리된 다음 크기가 200에 가까워지도록 해당 청크가 병합됩니다.
벡터 데이터베이스
이제 수백만 또는 심지어 수십억 개의 단어 임베딩을 저장해야 하는 시나리오를 생각해 보십시오. 이는 실제 애플리케이션에서 중요한 장면이 될 것입니다. 관계형 데이터베이스는 구조화된 데이터를 저장할 수 있지만 더 많은 양의 데이터를 처리하는 데 한계가 있기 때문에 적합하지 않을 수 있습니다.
여기가 벡터 데이터베이스가 작동하는 곳입니다. 벡터 데이터베이스는 벡터 데이터를 효율적으로 저장하고 검색하도록 설계되어 단어 임베딩에 적합합니다.
벡터 데이터베이스는 의미 검색을 사용하여 정보 검색에 혁명을 일으키고 있습니다. 단어 임베딩과 스마트 색인 기술의 강력한 기능을 활용하여 더 빠르고 정확한 검색을 수행합니다.
벡터 인덱스와 벡터 데이터베이스의 차이점은 무엇입니까?
다음과 같은 독립형 벡터 인덱스 파이스 (Facebook AI 유사성 검색)은 벡터 임베딩의 검색 및 검색을 향상시킬 수 있지만 db(데이터베이스) 중 하나에 존재하는 기능이 부족합니다. 반면에 벡터 데이터베이스는 벡터 임베딩을 관리하기 위해 특별히 구축되어 독립형 벡터 인덱스를 사용하는 것보다 여러 전문가를 제공합니다.
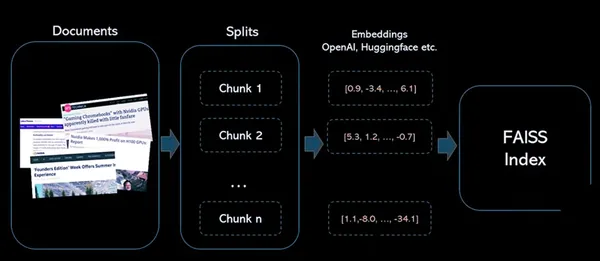
단계 :
1 : 텍스트 열에 대한 소스 임베딩을 만듭니다.
2: 벡터에 대한 FAISS 지수 구축
3 : 소스 벡터를 정규화하고 인덱스에 추가
4 : 동일한 인코더를 사용하여 검색 텍스트를 인코딩하고 출력 벡터를 정규화합니다.
5: 생성된 FAISS 인덱스에서 유사 벡터 검색
df = pd.read_csv("sample_text.csv")
df # Step 1 : Create source embeddings for the text column
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("all-mpnet-base-v2")
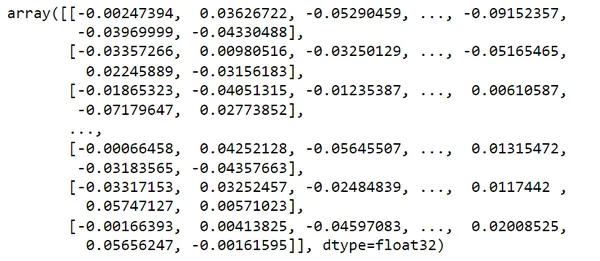
vectors = encoder.encode(df.text)
vectors # Step 2 : Build a FAISS Index for vectors
import faiss
index = faiss.IndexFlatL2(dim) # Step 3 : Normalize the source vectors and add to index
index.add(vectors)
index # Step 4 : Encode search text using same encoder
search_query = "looking for places to visit during the holidays"
vec = encoder.encode(search_query)
vec.shape
svec = np.array(vec).reshape(1,-1)
svec.shape # Step 5: Search for similar vector in the FAISS index
distances, I = index.search(svec, k=2)
distances
row_indices = I.tolist()[0]
row_indices
df.loc[row_indices]이 데이터세트를 확인해 보면,
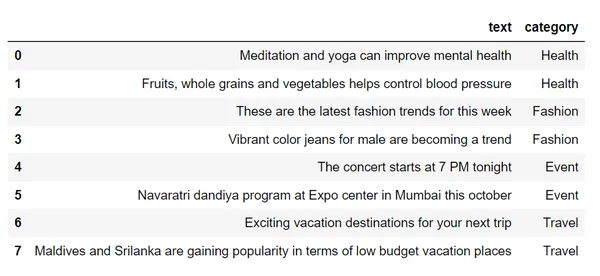
단어 임베딩을 사용하여 이 텍스트를 벡터로 변환하겠습니다.
내 검색어를 고려하면 = "연휴에 가볼 곳을 찾고 있어요"

여행 카테고리의 의미 검색을 이용하여 내 검색어와 가장 유사한 2개의 결과를 제공하고 있습니다.
검색 쿼리를 수행하면 데이터베이스는 LSH(Locity-Sensitive Hashing)와 같은 기술을 사용하여 프로세스 속도를 높입니다. LSH는 유사한 벡터를 버킷으로 그룹화하여 보다 빠르고 표적화된 검색을 가능하게 합니다. 즉, 쿼리 벡터를 저장된 모든 벡터와 비교할 필요가 없습니다.
검색
사용자가 시스템에 쿼리하면 동일한 임베딩 모델이 사용되어 쿼리에 대한 임베딩을 생성합니다. 그런 다음 이러한 쿼리 임베딩은 벡터 데이터베이스에서 유사한 벡터 임베딩을 검색하는 데 사용됩니다. 그 결과 각각 원본 콘텐츠 소스와 연결된 유사한 벡터 그룹이 생성됩니다.
검색의 과제
의미론적 검색에서의 검색은 GPT-3과 같은 언어 모델에 의해 부과된 토큰 제한과 같은 몇 가지 문제를 보여줍니다. 여러 관련 데이터 청크를 처리할 때 응답 제한을 초과하는 일이 발생합니다.
물건 방법
이 모델에서는 벡터 데이터베이스에서 모든 관련 데이터 청크를 수집하고 이를 프롬프트(개별)로 결합하는 작업이 포함됩니다. 이 프로세스의 가장 큰 단점은 토큰 제한을 초과하여 불완전한 응답이 발생한다는 것입니다.
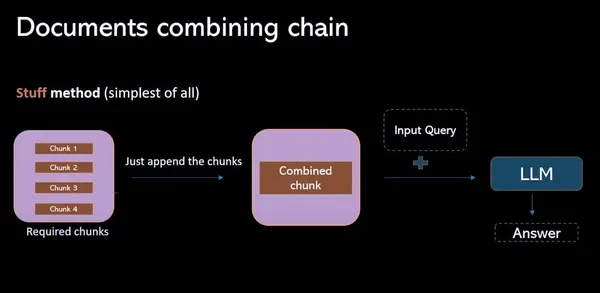
지도 축소 방법
토큰 제한 문제를 극복하고 검색 QA 프로세스를 간소화하기 위해 이 프로세스는 관련 청크를 프롬프트(개별)로 결합하는 대신 4개의 청크가 있는 경우 솔루션을 제공합니다. 개별 격리된 LLM을 모두 통과합니다. 이러한 질문은 언어 모델이 각 청크의 내용에 독립적으로 집중할 수 있도록 하는 상황별 정보를 제공합니다. 결과적으로 각 청크에 대한 단일 답변 세트가 생성됩니다. 마지막으로 이러한 모든 개별 답변을 결합하여 각 청크에서 수집된 통찰력을 기반으로 최상의 답변을 찾기 위한 최종 LLM 호출이 이루어집니다.
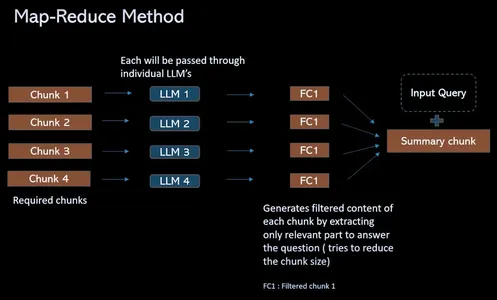
ResearchBot의 작업 흐름
(1) 데이터 로드
이 단계에서는 텍스트나 문서와 같은 데이터를 가져와서 추가 처리할 준비가 되어 분석에 사용할 수 있습니다.
#provide urls to scrape the data loaders = UnstructuredURLLoader(urls=[ "", ""
])
data = loaders.load() len(data)(2) 데이터를 분할하여 청크 생성
데이터는 더 작고 관리하기 쉬운 섹션이나 덩어리로 나누어져 있어 큰 텍스트나 문서를 효율적으로 처리하고 처리할 수 있습니다.
text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200
) # use split_documents over split_text in order to get the chunks.
docs = text_splitter.split_documents(data)
len(docs)
docs[0](3) 이러한 청크에 대한 임베딩을 생성하고 FAISS 인덱스에 저장합니다.
텍스트 청크는 숫자 벡터 표현(임베딩)으로 변환되고 Faiss 인덱스에 저장되어 유사한 벡터 검색을 최적화합니다.
# Create the embeddings of the chunks using openAIEmbeddings
embeddings = OpenAIEmbeddings() # Pass the documents and embeddings inorder to create FAISS vector index
vectorindex_openai = FAISS.from_documents(docs, embeddings) # Storing vector index create in local
file_path="vector_index.pkl"
with open(file_path, "wb") as f: pickle.dump(vectorindex_openai, f) if os.path.exists(file_path): with open(file_path, "rb") as f: vectorIndex = pickle.load(f)(4) 주어진 질문에 대한 유사한 임베딩을 검색하고 LLM을 호출하여 최종 답변을 검색합니다.
특정 쿼리에 대해 유사한 임베딩을 검색하고 이러한 벡터를 사용하여 언어 모델(LLM)과 상호 작용하여 정보 검색을 간소화하고 사용자 질문에 대한 최종 답변을 제공합니다.
# Initialise LLM with the necessary parameters
llm = OpenAI(temperature=0.9, max_tokens=500) chain = RetrievalQAWithSourcesChain.from_llm( llm=llm, retriever=vectorIndex.as_retriever()
)
chain query = "" #ask your query langchain.debug=True chain({"question": query}, return_only_outputs=True)최종 지원서
이러한 모든 단계(문서 로더, 텍스트 분할기, 벡터 DB, 검색, 프롬프트)를 사용하고 Streamlit의 도움으로 애플리케이션을 구축한 후. ResearchBot 구축을 완료했습니다.
이것은 블로그나 기사의 URL이 삽입되는 페이지의 섹션입니다. 2023년에 출시된 최신 Iphone 모바일의 링크를 제공했습니다. 이 애플리케이션 ResearchBot 구축을 시작하기 전에 모두가 이미 ChatGPT가 있는데 왜 이 ResearchBot을 구축하는지에 대한 질문을 갖게 될 것입니다. 대답은 다음과 같습니다.
ChatGPT의 답변:

ResearchBot의 답변:
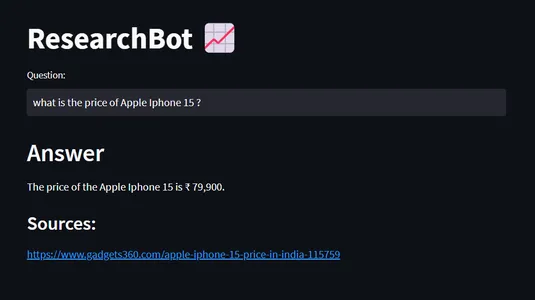
여기, 내 쿼리는 “애플 아이폰15 가격은 얼마예요?”
이 데이터는 2023년의 데이터이며 ChatGPT 3.5에서는 이 데이터를 사용할 수 없지만 iPhone에 대한 최신 정보로 ResearchBot을 교육했습니다. 그래서 우리는 ResearchBot으로부터 필요한 답변을 얻었습니다.
ChatGPT 사용 시 발생하는 3가지 문제는 다음과 같습니다.
- 기사 내용을 복사하여 붙여넣는 것은 지루한 작업입니다.
- 우리는 종합적인 지식 베이스가 필요합니다.
- 단어 제한 – 3000 단어
결론
우리는 실제 시나리오에서 의미 검색 및 벡터 데이터베이스의 개념을 목격했습니다. 의미론적 검색을 사용하여 벡터 데이터베이스에서 답변을 효율적으로 검색하는 ResearchBot의 기능인 ResearchBot은 정보 검색 및 질문 답변 시스템 영역에서 심층 LLM(adv)의 엄청난 잠재력을 보여줍니다. 우리는 높은 능력과 검색 기능으로 중요한 정보를 쉽게 찾고 요약할 수 있는 매우 수요가 많은 도구를 만들었습니다. 지식을 찾는 사람들을 위한 강력한 솔루션입니다. 이 기술은 정보 검색 및 질문 답변 시스템에 대한 새로운 지평을 열어 데이터 기반 통찰력을 찾는 모든 사람에게 획기적인 변화를 가져올 것입니다.
자주 묻는 질문
A. 현대 의미 검색 엔진의 중추입니다. 벡터 데이터베이스는 고차원 벡터 데이터를 처리하도록 설계된 특수 데이터베이스입니다. 이는 데이터의 복잡성과 세분성에 따라 텍스트나 기타 유형을 나타내는 벡터와 같은 고차원 데이터를 저장하고 검색하는 효율적인 방법을 제공합니다.
A. 단어의 의미를 해석하는 데에는 의미 검색 엔진이 더 좋습니다. 쿼리 의도를 더 잘 이해할 수 있으며 기존 검색 엔진이 표시할 수 있는 것보다 검색자에게 더 관련성이 높은 검색 결과를 생성할 수 있습니다.
A. FAISS는 벡터 데이터베이스 자체가 아니라 벡터 검색 라이브러리입니다. 벡터 검색 라이브러리이자 벡터 유사성 검색을 수행하는 데 사용되는 독립형 라이브러리입니다. 널리 사용되는 예로는 FAISS, HNSW, Annoy 등이 있습니다.
A. LLM(대형 언어 모델)은 딥 러닝 기술과 대규모 데이터 세트를 사용하여 새로운 콘텐츠를 이해, 요약, 생성 및 예측하는 일종의 인공 지능(AI) 알고리즘입니다. 이러한 챗봇은 자연어 이해 및 대화에 많은 기술을 갖고 있습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/10/empower-your-research-with-a-tailored-llm-powered-ai-assistant/

