概要
コンピューター ビジョンでは、ライブ オブジェクト検出のためのさまざまな技術が存在します。 R-CNN、 SSD, YOLO。各手法には制限と利点があります。 Faster R-CNN は精度では優れているかもしれませんが、リアルタイム シナリオではそれほどパフォーマンスが良くない可能性があり、 YOLO アルゴリズム。
オブジェクト検出はコンピューター ビジョンの基礎であり、マシンがフレームまたは画面内のオブジェクトを識別して位置を特定できるようになります。長年にわたり、さまざまな物体検出アルゴリズムが開発されてきましたが、YOLO は最も成功したアルゴリズムの 8 つとして浮上しています。最近、YOLOvXNUMX が導入され、アルゴリズムの機能がさらに強化されました。
この包括的なガイドでは、Faster R-CNN、SSD (Single Shot MultiBox Detector)、YOLOv8 という XNUMX つの著名な物体検出アルゴリズムについて説明します。仮想環境のセットアップや Streamlit アプリケーションの開発など、これらのアルゴリズムの実装の実践的な側面について説明します。
学習目標
- Faster R-CNN、SSD、YOLO を理解し、それらの違いを分析します。
- OpenCV、Supervision、YOLOv8 を使用したライブ オブジェクト検出システムの実装に関する実践的な経験を積みます。
- Roboflow アノテーションを使用した画像セグメンテーション モデルを理解します。
- 簡単なユーザー インターフェイスを実現する Streamlit アプリケーションを作成します。
YOLOv8 で画像セグメンテーションを行う方法を見てみましょう。
目次
この記事は、の一部として公開されました データサイエンスブログ。
より高速なR-CNN
Faster R-CNN (Faster Regional-based Convolutional Neural Network) は、深層学習ベースの物体検出アルゴリズムです。これは R-CNN および Fast R-CNN フレームワークを使用して評価され、Fast R-CNN の拡張と考えることができます。
このアルゴリズムでは、領域提案ネットワーク (RPN) を導入して領域提案を生成し、R-CNN で使用される選択的検索を置き換えます。 RPN は畳み込み層を検出ネットワークと共有するため、効率的なエンドツーエンドのトレーニングが可能になります。
生成された領域提案は、バウンディング ボックスの改良とオブジェクトの分類のために Fast R-CNN ネットワークに供給されます。
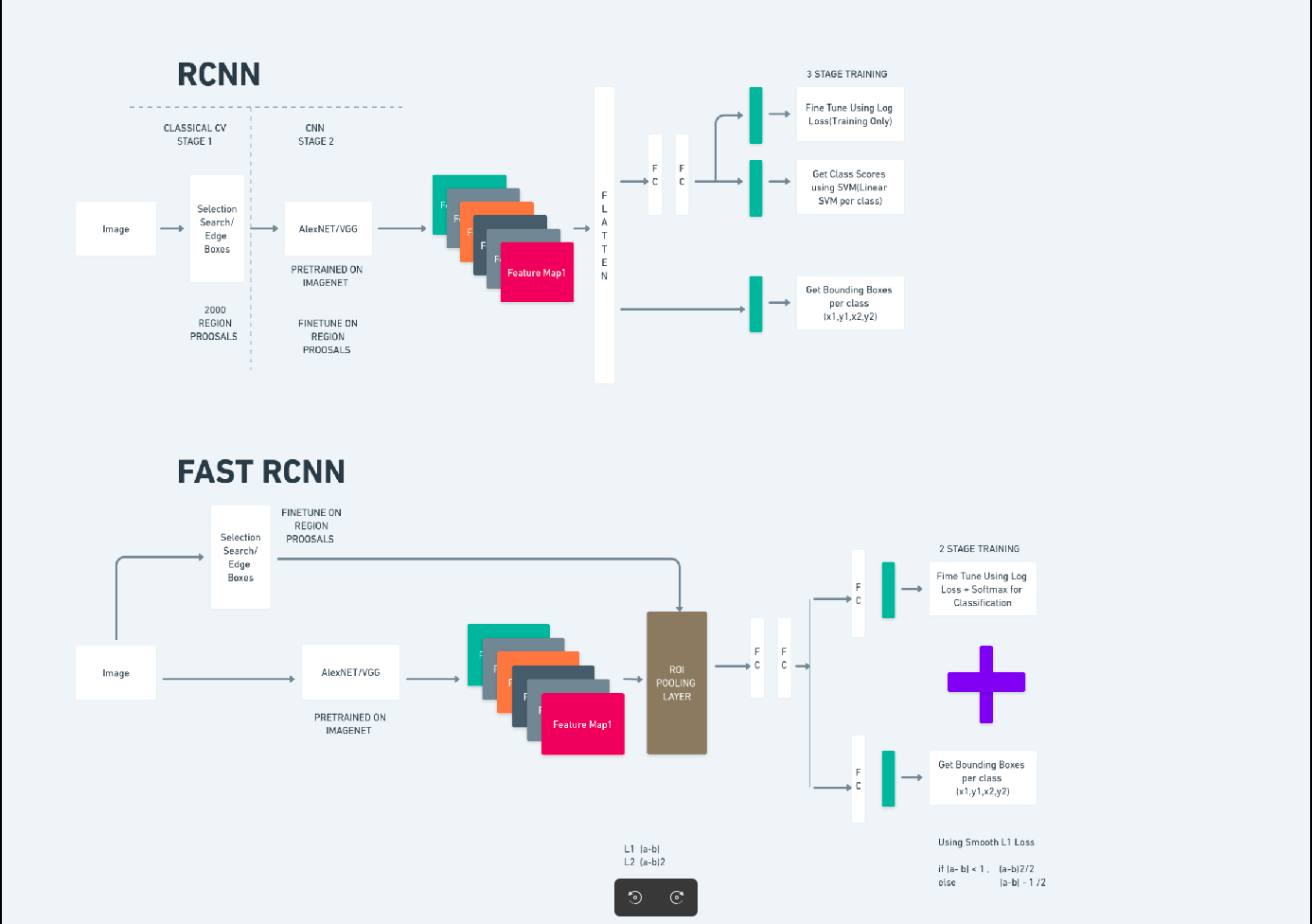
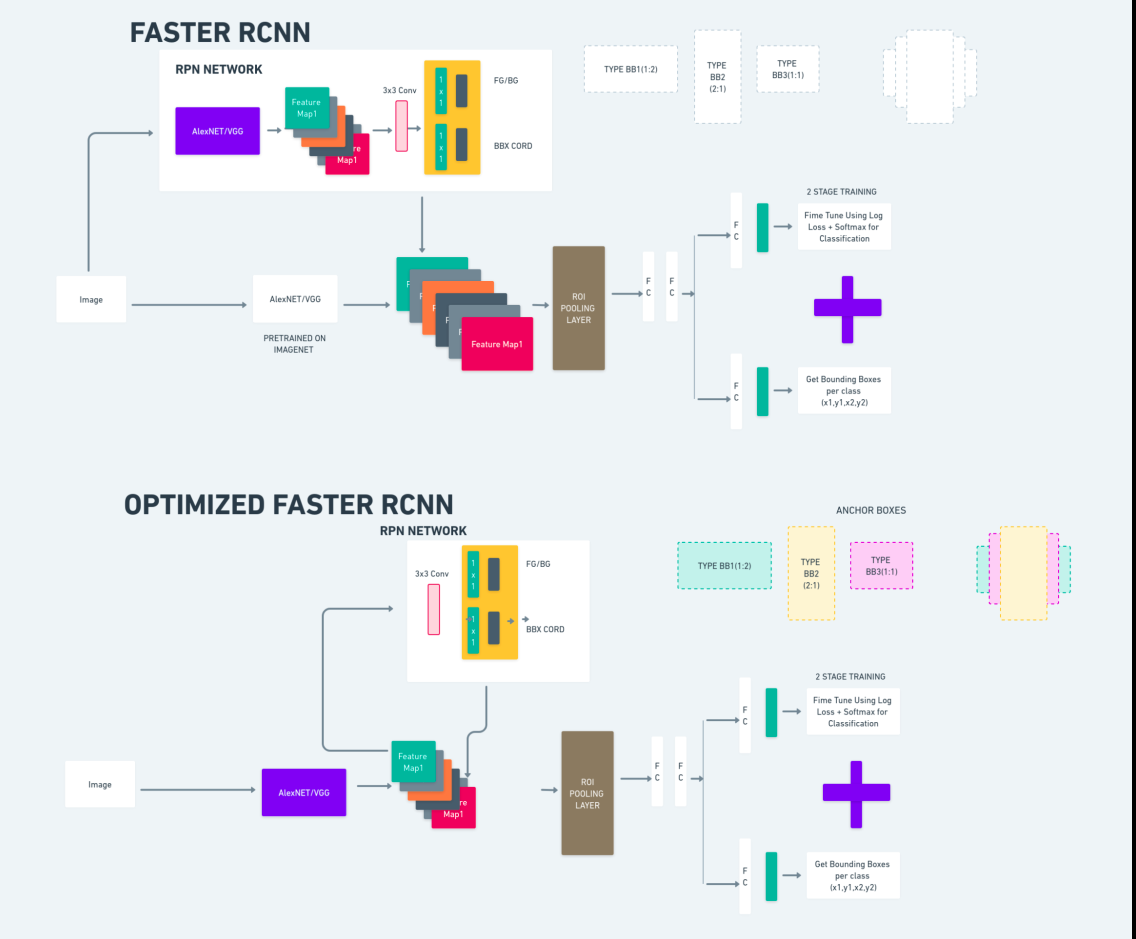
上の図は Faster R-CNN ファミリを包括的に示しており、各アルゴリズムを評価するのに理解しやすいものです。
シングルショットマルチボックス検出器(SSD)
シングルショットマルチボックス検出器 (SSD)) はオブジェクト検出で一般的であり、主にコンピューター ビジョン タスクで使用されます。以前の手法である Faster R-CNN では、2016 つのステップに従いました。最初のステップには検出部分が含まれ、XNUMX 番目のステップには回帰が含まれます。ただし、SSD では、検出ステップは XNUMX つだけ実行されます。 SSD は、高速かつ正確な物体検出モデルのニーズに応えるために XNUMX 年に導入されました。

SSD には、Faster R-CNN などの以前の物体検出方法に比べて、いくつかの利点があります。
- 効率: SSD は単一段階の検出器です。つまり、別の提案生成ステップを必要とせずに、境界ボックスとクラス スコアを直接予測します。これにより、Faster R-CNN のような 2 段階の検出器と比較して高速になります。
- エンドツーエンドのトレーニング: SSD はエンドツーエンドでトレーニングでき、ベース ネットワークと検出ヘッドの両方を共同で最適化するため、トレーニング プロセスが簡素化されます。
- マルチスケールの特徴融合: SSD は複数のスケールの特徴マップ上で動作し、さまざまなサイズのオブジェクトをより効果的に検出できます。
SSD は速度と精度のバランスが取れており、パフォーマンスと効率の両方が重要なリアルタイム アプリケーションに適しています。
一度だけ見る(YOLOv8)
2015 年、You Only Look Once (YOLO) は、Joseph Redmon、Santosh Divvala、Ross Girshick、Ali Farhadi による研究論文で物体検出アルゴリズムとして紹介されました。 YOLO は、入力として完全な画像を使用して境界ボックスとクラス確率を予測するニューラル ネットワークを XNUMX つだけ持たせることにより、単一パスでオブジェクトを直接分類するシングルショット アルゴリズムです。
ここで、精度と速度が向上したリアルタイムの物体検出における最先端の進歩としての YOLOv8 を理解しましょう。 YOLOv8 を使用すると、COCO (Common Objects in Context) などの膨大なデータセットですでにトレーニングされた事前トレーニング済みモデルを活用できます。画像セグメンテーションは各オブジェクトに関するピクセルレベルの情報を提供し、画像コンテンツのより詳細な分析と理解を可能にします。
画像のセグメンテーションは計算コストがかかる場合がありますが、YOLOv8 はこの方法をニューラル ネットワーク アーキテクチャに統合し、効率的かつ正確なオブジェクトのセグメンテーションを可能にします。
YOLOv8 の動作原理
YOLOv8 この機能は、まず入力画像をグリッド セルに分割することによって機能します。 YOLOv8 は、これらのグリッド セルを使用して、クラスの確率で境界ボックス (bbox) を予測します。
その後、YOLOv8 は NMS アルゴリズムを採用して重複を削減します。たとえば、画像内に複数の車が存在し、その結果境界ボックスが重なり合う場合、NMS アルゴリズムはこの重なりを軽減するのに役立ちます。
Yolo V8 のバリアント間の違い: YOLOv8 には、YOLOv8、YOLOv8-L、YOLOv8-X の 8 つのバリアントがあります。バリアント間の主な違いは、バックボーン ネットワークのサイズです。 YOLOv8 のバックボーン ネットワークは最小ですが、YOLOvXNUMX-X のバックボーン ネットワークは最大です。
差異 より高速な R-CNN、SSD、YOLO 間
| 側面 | より高速なR-CNN | SSD | YOLO |
|---|---|---|---|
| アーキテクチャ | RPN と Fast R-CNN を備えた 2 段階検出器 | 単段検出器 | 単段検出器 |
| 地域提案 | 有り | いいえ | いいえ |
| 検出速度 | SSDやYOLOと比べて遅い | Faster R-CNN と比較して高速、YOLO より低速 | 非常に高速 |
| 正確さ | 一般に精度が高くなります | バランスの取れた精度と速度 | 適切な精度 (特にリアルタイム アプリケーションの場合) |
| 柔軟性 | 柔軟性があり、さまざまなオブジェクトのサイズとアスペクト比を処理できます | 複数のスケールのオブジェクトを処理できる | 小さなオブジェクトの正確な位置特定に苦労する可能性がある |
| 統合された検出 | いいえ | いいえ | 有り |
| 速度と精度のトレードオフ | 一般に精度のために速度を犠牲にする | スピードと正確性のバランスをとる | 十分な精度を維持しながら速度を優先 |
セグメンテーションとは何ですか?
ご存知のとおり、セグメンテーションとは、特定の特性に基づいて大きな画像を小さなグループに分割することを意味します。画像を複数の異なるセグメントまたは領域に分割するために使用されるコンピューター ビジョン技術である画像セグメンテーションについて理解しましょう。画像はピクセルで構成されているため、画像セグメンテーションでは、色、強度、テクスチャ、またはその他の視覚的特性の類似性に基づいてピクセルがグループ化されます。
たとえば、画像に木、車、人物が含まれている場合、画像のセグメンテーションにより、意味のあるオブジェクトや画像の一部を表すさまざまなクラスに画像が分割されます。画像セグメンテーションは、医療画像、衛星画像分析、コンピュータ ビジョンでの物体認識などのさまざまな分野で広く使用されています。

セグメンテーションの部分では、最初に Robflow を使用して最初の YOLOv8 セグメンテーション モデルを作成します。次に、セグメンテーション モデルをインポートして、セグメンテーション タスクを実行します。疑問が生じます。タスクは検出アルゴリズムだけで完了できるのに、なぜセグメンテーション モデルを作成するのでしょうか?
セグメンテーションにより、クラスの全身画像を取得できます。検出アルゴリズムはオブジェクトの存在を検出することに重点を置いていますが、セグメンテーションはオブジェクトの正確な境界を描写することにより、より正確な理解を提供します。これにより、画像内に存在するオブジェクトのより正確な位置特定と理解が可能になります。
ただし、セグメンテーションでは、アノテーションの分離やモデルの作成などの追加の手順が必要となるため、通常、検出アルゴリズムに比べて時間の複雑さが高くなります。この欠点にもかかわらず、セグメンテーションによる精度の向上は、オブジェクトの正確な描写が重要なタスクでは計算コストを上回る可能性があります。
YOLOv8 を使用した段階的なライブ検出と画像セグメンテーション
この概念では、conda を使用して仮想環境を作成し、venv をアクティブ化し、pip を使用して要件パッケージをインストールする手順を検討します。まず通常の Python スクリプトを作成してから、streamlit アプリケーションを作成します。
ステップ 1: Conda を使用して仮想環境を作成する
conda create -p ./venv python=3.8 -yステップ 2: 仮想環境をアクティブ化する
conda activate ./venv
ステップ3:requirements.txtを作成する
ターミナルを開き、以下のスクリプトを貼り付けます。
touch requirements.txtステップ 4: Nano コマンドを使用して、requirements.txt を編集します。
requirements.txtを作成した後、requirements.txtを編集するための次のコマンドを記述します。
nano requirements.txt上記のスクリプトを実行すると、この UI が表示されます。
彼女に必要なパッケージを作成します。
ultralytics==8.0.32
supervision==0.2.1
streamlit次に、 「ctrl+o」(このコマンドは編集部分を保存します) を押します。 "入る"
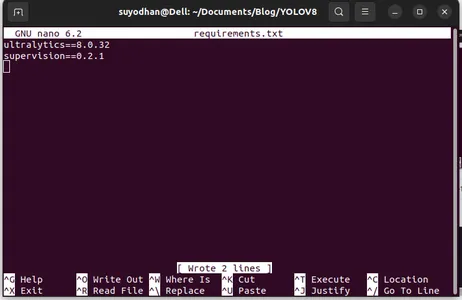
「Ctrl+x」。 ファイルを終了できます。そしてメインの道へ。
ステップ5:requirements.txtのインストール
pip install -r requirements.txtステップ6: Python スクリプトを作成する
ターミナルで次のスクリプトを書きます。またはコマンドとも言えます。
touch main.pymain.pyを作成した後、ターミナルでコマンド書き込みを使用してvsコードを開きます。
code ステップ 7: Python スクリプトの作成
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
このコマンドを実行すると、カメラが開いてあなたの一部を検出していることがわかります。性別や背景の部分など。
ステップ7: ストリームリットアプリを作成する
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
このスクリプトでは、streamlit アプリケーションを作成し、ボタンを作成すると、ボタンを押した後にデバイスのカメラが開き、フレーム内のパーツが検出されるようになります。
このコマンドを使用してこのスクリプトを実行します。
streamlit run app.py
# first create the app.py then paste the above code and run this script.上記のコマンドを実行した後、次のようなリーチアウト エラーが発生したとします。
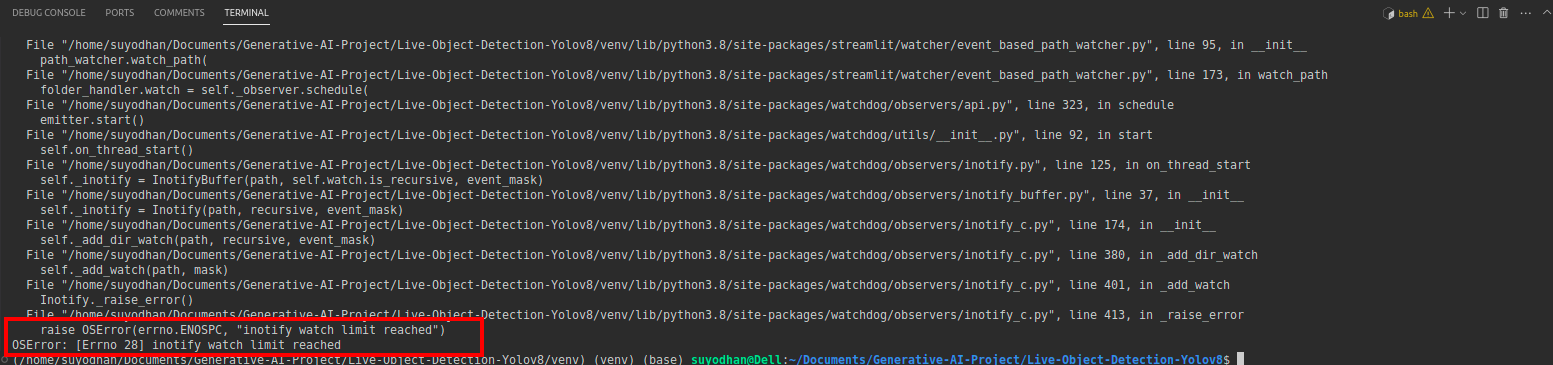
次にこのコマンドを押します。
sudo sysctl fs.inotify.max_user_watches=524288sudo コマンドを使用しているため、パスワードを書き込みたいコマンドを入力した後、sudo は神です:)
スクリプトを再度実行します。ストリームリットされたアプリケーションが表示されます。
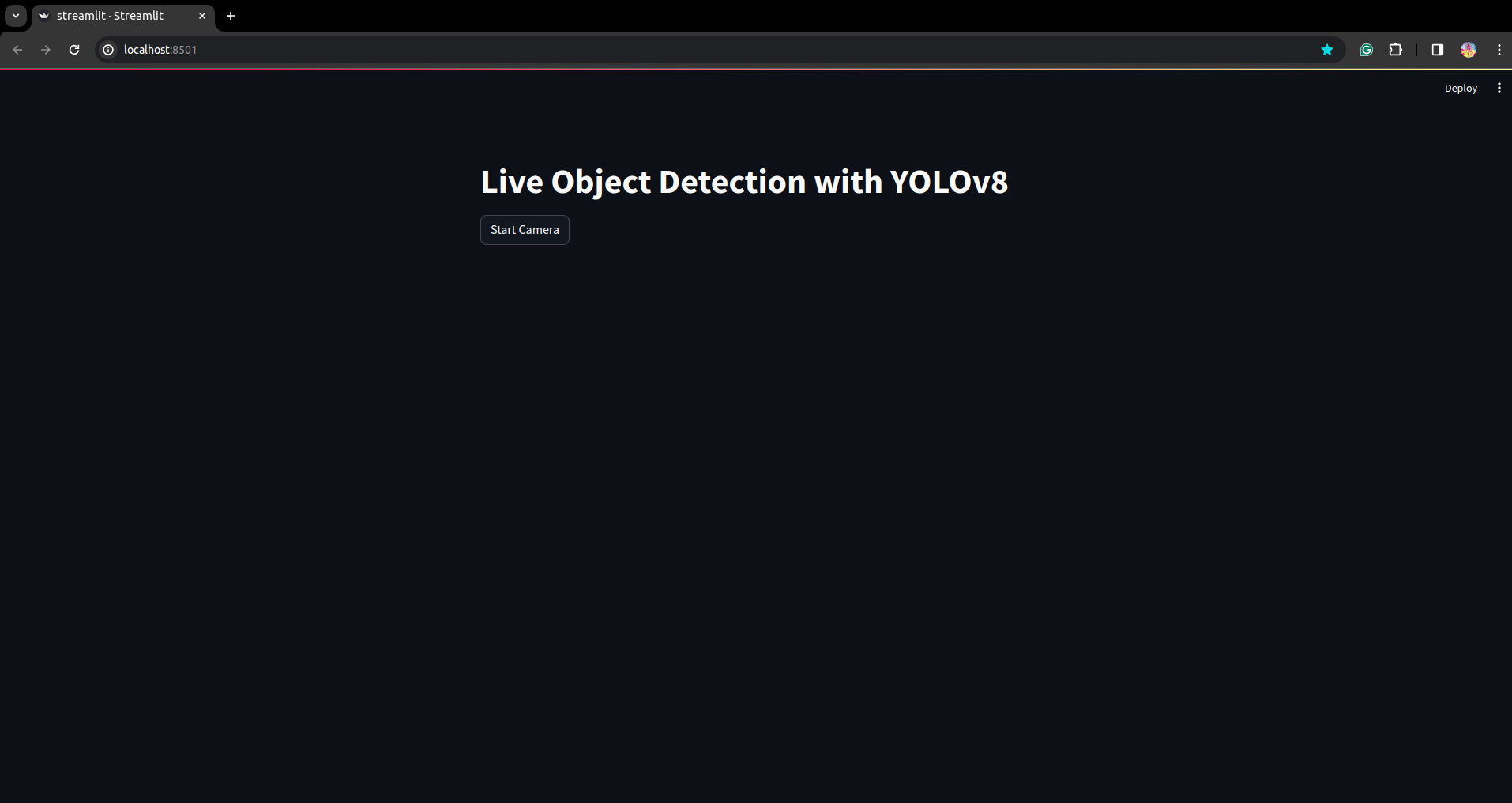
ここでは、次の部分でセグメンテーション部分を見て、成功するライブ検出アプリケーションを作成できます。
注釈の手順
ステップ 1: Roboflow のセットアップ
署名後、「プロジェクトを作成します。」 ここでプロジェクトと注釈グループを作成できます。

ステップ2: データセットのダウンロード
ここでは単純な例を検討しますが、問題ステートメントで使用したいので、ここではアヒル データセットを使用します。
これに行ってください アヒルのデータセットをダウンロードします。

フォルダーを解凍すると、次の 3 つのフォルダーが表示されます。 トレーニング、テスト、ヴァル。
ステップ3: データセットを roboflow にアップロードする
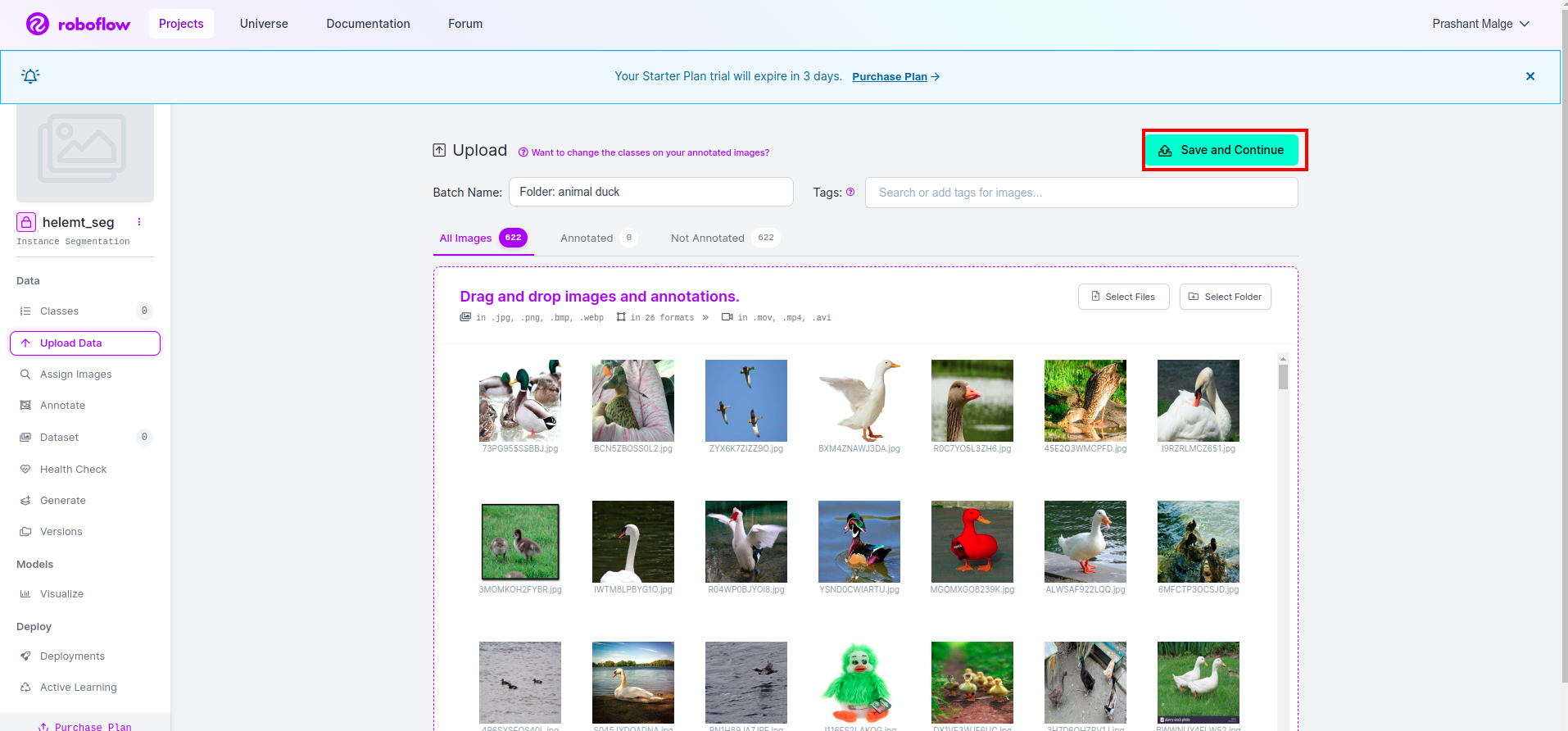
roboflow でプロジェクトを作成した後、ここでこの UI が表示されます。データセットをアップロードできるため、トレーニング パーツの画像のみをアップロードします。「」を選択します。フォルダーを選択" オプションを選択します。
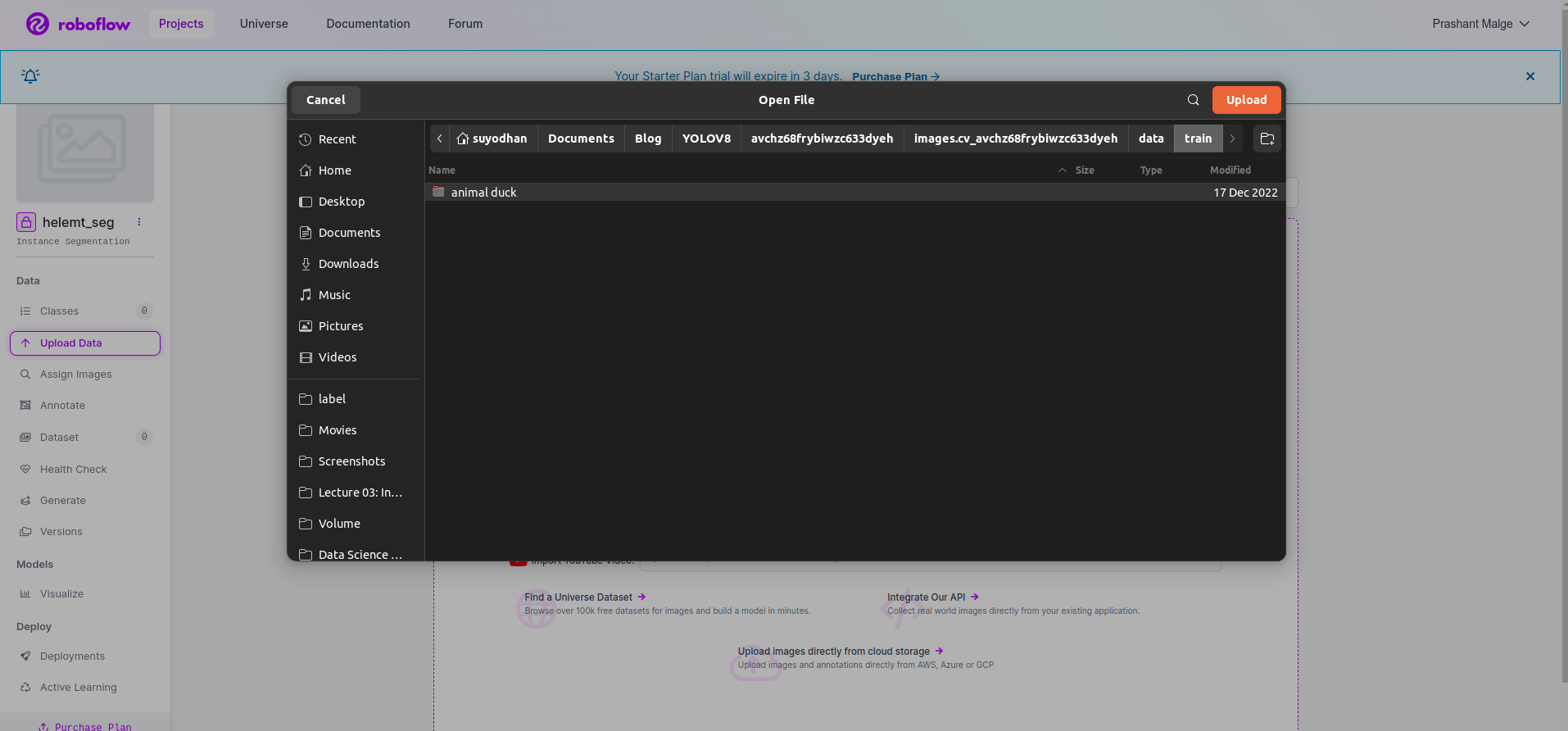
次に、保存して続行" 赤い四角形のボックスにマークを付けたオプション
ステップ4: クラス名を追加する
その後、 クラス部分 左側の赤いボックスにチェックを入れます。クラス名を次のように書きます アヒル、 緑色のボックスをクリックした後。
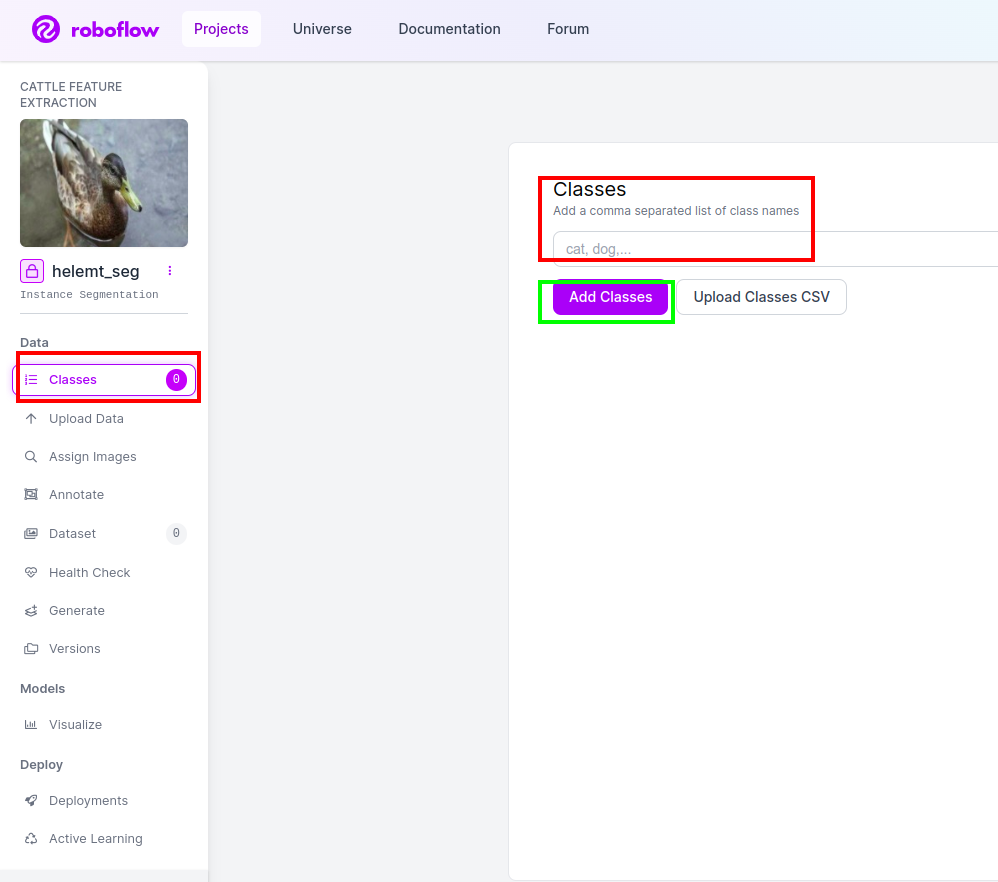
これでセットアップは完了し、注釈部分などの次の部分も簡単になります。
ステップ5: を開始します。 注釈部分
に行きます 注釈オプション 赤いボックスでマークし、緑のボックスでマークした注釈部分の開始をクリックします。
最初の画像をクリックすると、この UI が表示されます。これを確認したら、手動注釈オプションをクリックします。
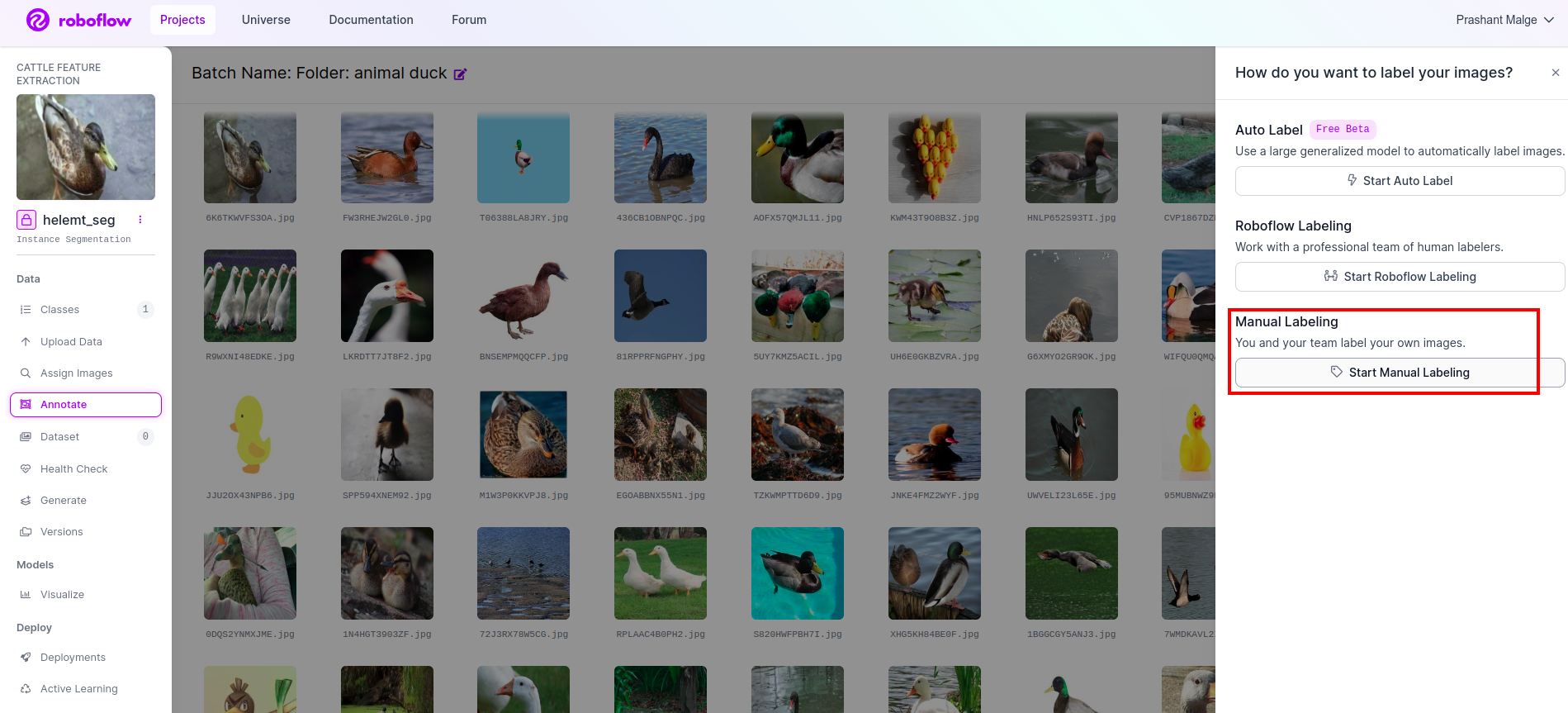
次に、メール ID またはチームメイトの名前を追加して、タスクを割り当てることができます。
最初の画像をクリックすると、この UI が表示されます。ここで赤いボックスをクリックすると、多多項式モデルを選択できます。
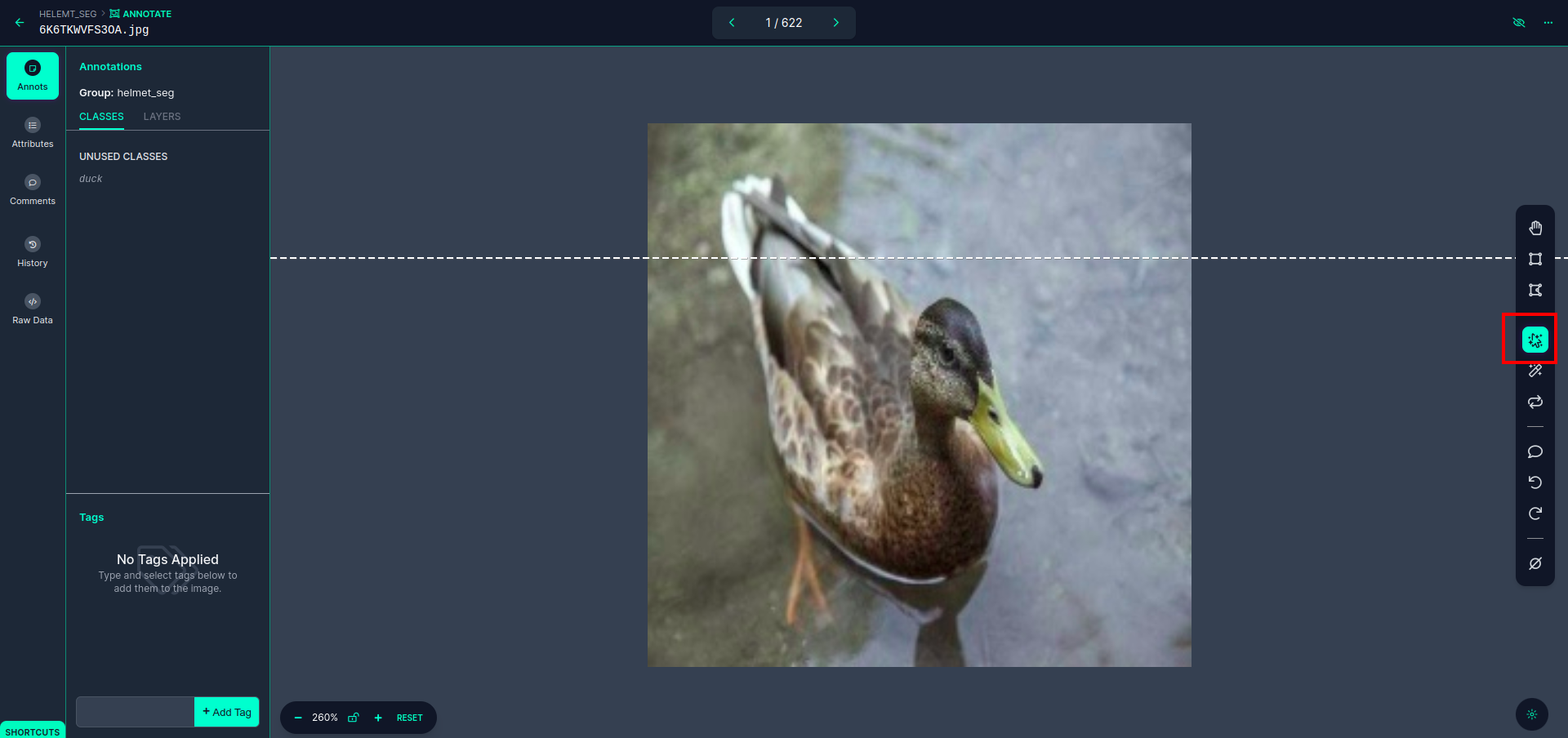
赤いボックスをクリックした後、デフォルトのモデルを選択し、アヒル オブジェクトをクリックします。これにより、画像が自動的に分割されます。次に、次の部分をクリックして保存します。すると、左側が赤いボックスでマークされており、そこにクラス名が表示されます。
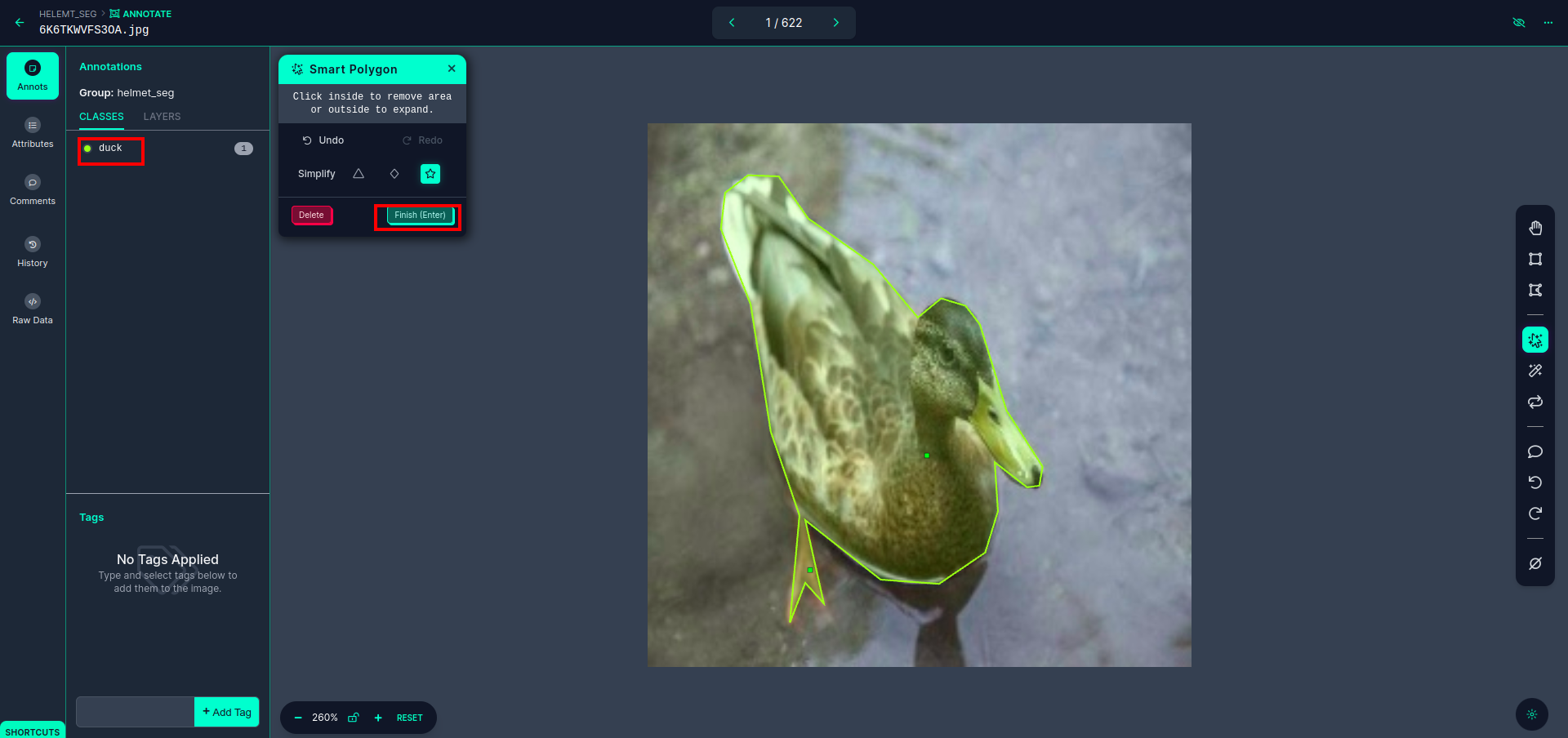
クリック 保存して入力 オプション。すべての画像に注釈を付けます。
YOLOv8 形式の画像を追加します。右側に、注釈セクションに画像を追加するオプションが表示されます。ここでは、注釈付き画像用と注釈なし画像用の XNUMX つの部分が作成されます。
- まず、左側の「」をクリックします。注釈を付ける」 オプション 加えます 画像 データセットに。
- 次に、次の「」をクリックします。画像を追加"
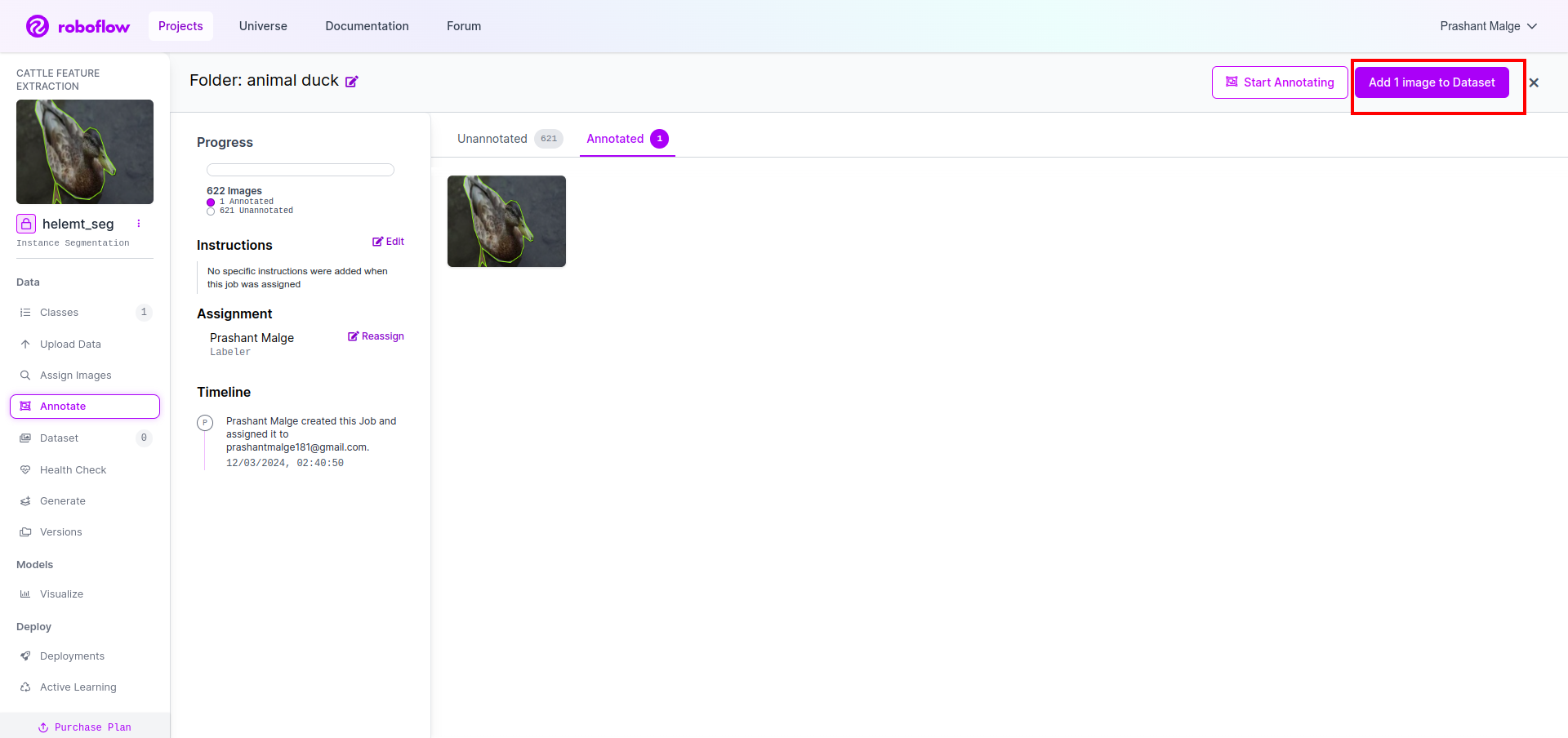
最後に、データセットを作成します。左側の「生成」オプションをクリックし、オプションにチェックを入れて、conitune オプションを押します。
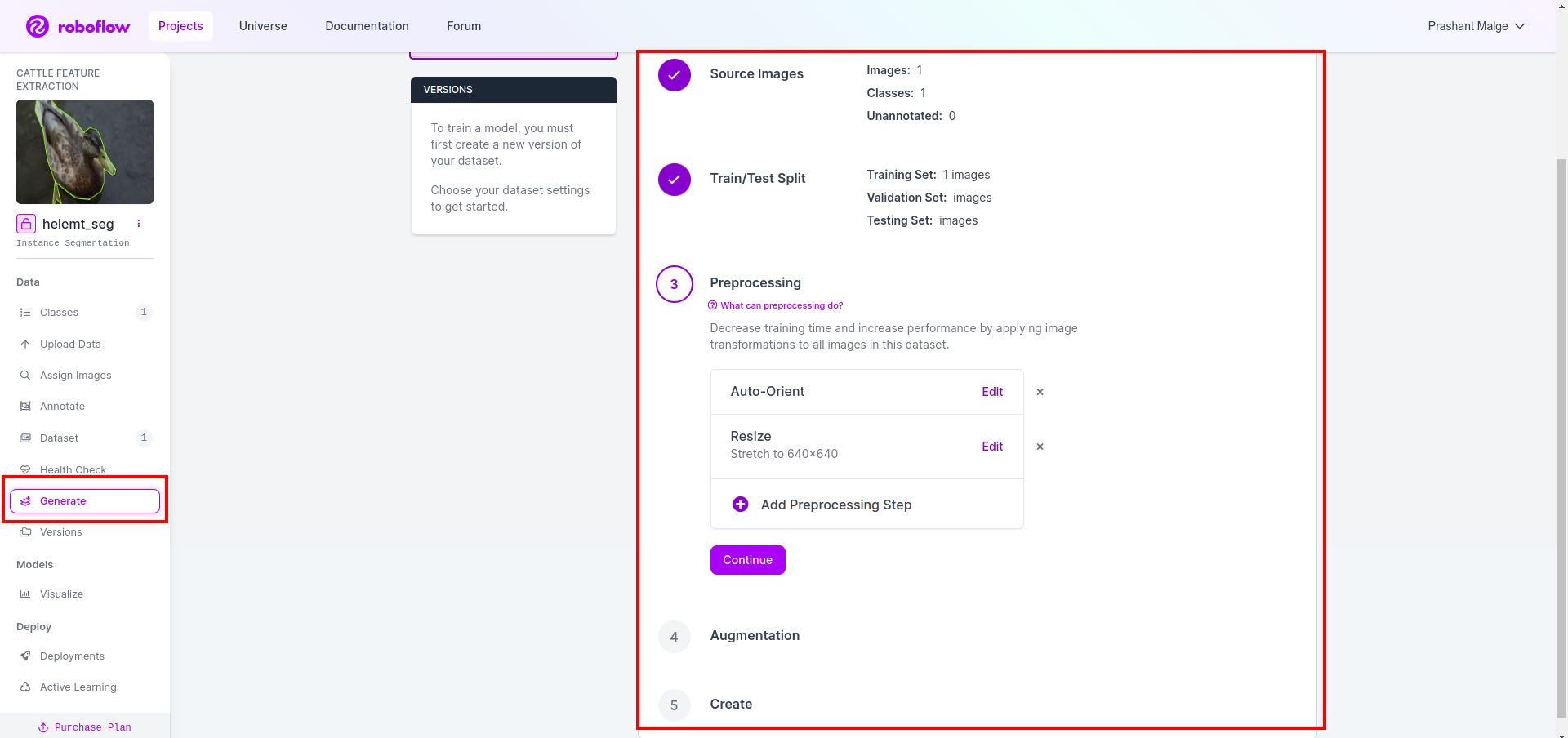
次に、データセット分割オプションの UI を取得します。ここで、train、test、val フォルダーの画像が自動的に分割されていることを確認できます。上の赤枠をクリックします データセットのエクスポート オプション zip ファイルをダウンロードします。 zip ファイルのフォルダー構造は次のようになります…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
ステップ 6: 画像セグメンテーション モデルをトレーニングするためのスクリプトを作成する
このパートでは、まずドライブを使用して Google Collab ファイルを作成し、データセットをアップロードします。 Google Collab を使用して Google ドライブをマウントします。
1. このコマンドを使用するのは、 Google ドライブをマウントする
from google.colab import drive
drive.mount('/content/gdrive')2. データディレクトリを定義する 定数変数を使用します。
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. 必要なパッケージをインストールすると、 ウルトラリティクスをインストールする
!pip install ultralytics4. ライブラリのインポート
import os
from ultralytics import YOLO5.ロード 事前トレーニング済み YOLOv8 モデル(ここでは別のモデルもあります。公式ドキュメントを確認すると、別のモデルが確認できます)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. モデルをトレーニングする
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together ドライブをチェックしません。モデル名フォルダーが作成され、そこに、このモデルが必要な予測用のモデルが保存されます。
7. モデルを予測する
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)ここで、セグメンテーション画像が保存されていることがわかります。

これで、ついにライブ検出モデルと画像セグメンテーション モデルの両方を構築できるようになりました。
まとめ
このブログでは、YOLOv8 を使用したライブ オブジェクトの検出と画像のセグメンテーションについて説明します。ライブ検出では、事前トレーニングされた YOLOv8 モデルをインポートし、コンピューター ビジョン ライブラリである OpenCV を利用してカメラを開いてオブジェクトを検出します。さらに、魅力的なユーザー インターフェイスを実現する Streamlit アプリケーションを作成します。
次に、YOLOv8 を使用した画像セグメンテーションについて詳しく説明します。事前トレーニングされたモデルをインポートし、カスタム データセットで転移学習を実行します。これに先立ち、私たちはデータセットのアノテーションのために Roboflow を検討し、次のようなツールの使いやすい代替手段を提供しました。 ラベル画像.
最後に、アヒルが含まれる画像を予測します。画像ではオブジェクトは鳥のように見えますが、クラス名を「」とします。カモ」をデモンストレーション目的で使用します。
主要な取り組み
- Faster R-CNN、SSD、最新の YOLOv8 などの物体検出モデルについて学習します。
- アノテーション ツール Roboflow と、YOLOv8 セグメンテーション モデルのデータセット作成におけるその役割を理解します。
- OpenCV (cv2) と Supervision を使用したライブ オブジェクト検出を検討し、実践的なスキルを強化します。
- YOLOv8 を使用してセグメンテーション モデルをトレーニングおよびデプロイし、実践的な経験を積みます。
よくある質問
A. オブジェクト検出には、通常、オブジェクトの周囲に境界ボックスを描画することによって、画像内の複数のオブジェクトを識別して位置を特定することが含まれます。一方、画像セグメンテーションは、ピクセルの類似性に基づいて画像をセグメントまたは領域に分割し、オブジェクトの境界をより詳細に理解できるようにします。
A. YOLOv8 は、ネットワーク アーキテクチャ、トレーニング技術、最適化の進歩を組み込むことにより、以前のバージョンを改良しています。 YOLOv3 と比較して、精度、速度、効率が向上する可能性があります。
A. YOLOv8 は、ハードウェア機能とモデルの最適化に応じて、組み込みデバイスでのリアルタイムのオブジェクト検出に使用できます。ただし、リソースに制約のあるデバイスでリアルタイムのパフォーマンスを実現するには、モデルの枝刈りや量子化などの最適化が必要になる場合があります。
A. Roboflow は、直感的な注釈ツール、データセット管理機能、およびさまざまな注釈形式のサポートを提供します。注釈プロセスを合理化し、コラボレーションを可能にし、バージョン管理を提供することで、コンピューター ビジョン プロジェクトのデータセットの作成と管理が容易になります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

