概要
この記事では、手書きの数字のユニークな表現を生成するための TensorFlow での GAN のアプリケーションを検討します。 GAN フレームワークは、ジェネレーターとディスクリミネーターという XNUMX つの主要なコンポーネントで構成されます。 ジェネレーターはランダムな方法で新しい画像を生成しますが、ディスクリミネーターは本物の画像と偽造画像を区別するように設計されています。 GAN トレーニングを通じて、手書きの数字によく似た画像のコレクションを取得します。 この記事の主な目的は、 MNISTデータセット.
学習目標
- この記事では、 生成的敵対的ネットワーク (GAN) を開発し、画像生成におけるそのアプリケーションを調査します。
- このチュートリアルの主な目的は、TensorFlow ライブラリを使用して GAN を構築する段階的なプロセスを読者に案内することです。 MNIST データセットで GAN をトレーニングして、手書きの数字の新しい画像を生成する方法について説明します。
- この記事では、GAN のアーキテクチャとコンポーネント (ジェネレーターやディスクリミネーターなど) について説明し、読者の基本的な動作についての理解を深めます。
- 学習を支援するために、この記事には、MNIST データセットの読み取りと前処理、GAN アーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価など、さまざまなタスクを示すコード例が含まれています。
- さらに、この記事では、手書きの数字に非常によく似た画像のコレクションである GAN の期待される結果についても考察しています。
この記事は、の一部として公開されました データサイエンスブログ。
目次
私たちは何を構築していますか?
既存の画像データベースを使用して新しい画像を生成することは、敵対的生成ネットワーク (GAN) と呼ばれる特殊なモデルの顕著な機能です。 GAN は、多様な画像データセットを活用して教師なし画像または半教師あり画像を生成することに優れています。
この記事では、GAN の画像生成の可能性を利用して手書きの数字を作成します。 この方法論では、手書きの数字データベース上でネットワークをトレーニングする必要があります。 この教育作品では、Tensorflow ライブラリを利用して基本的な GAN を構築し、MNIST データセットでトレーニングを実施し、手書きの数字の新しい画像を生成します。
これをどのように設定すればよいでしょうか?
この記事の主な焦点は、GAN の画像生成の可能性を活用することにあります。 この手順は、GAN トレーニング プロセスを容易にするための画像データベースの読み込みと前処理から始まります。 データが正常に読み込まれたら、GAN モデルの構築に進み、トレーニングとテストに必要なコードを開発します。 後続のセクションでは、この機能を実装し、MNIST データベースを使用して新しいイメージを生成する方法について詳しく説明します。
モデル構築
私たちが構築しようとしている GAN モデルは、XNUMX つの重要なコンポーネントで構成されています。
- 発生器: このコンポーネントは、新しい画像を生成します。
- 弁別器: このコンポーネントは、生成された画像の品質を評価します。
GAN を使用して画像を生成するために開発する一般的なアーキテクチャを次の図に示します。 次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、およびネットワークのトレーニング方法について簡単に説明します。 さらに、ネットワークを検査して新しいイメージを生成するコードも提供されています。
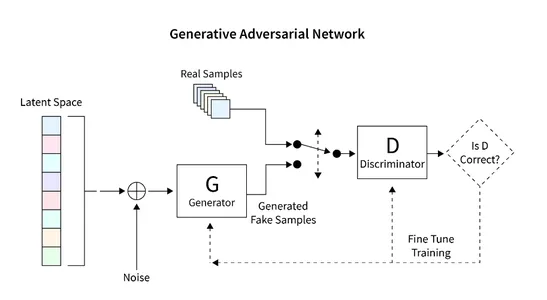
データセットの読み取り
MNIST データセットは、コンピューター ビジョンの分野で非常に著名であり、28 × 28 ピクセルの大きさの手書き数字の膨大なコレクションで構成されています。 このデータセットは、グレースケールのシングルチャネル画像形式であるため、GAN 実装に最適であることがわかります。
後続のコード スニペットは、Tensorflow の組み込み関数を使用して MNIST データセットをロードする方法を示しています。 読み込みが成功したら、画像を正規化して 2 次元形式に再整形します。 この変換により、GAN アーキテクチャ内で XNUMXD 画像データを効率的に処理できるようになります。 さらに、トレーニング データと検証データの両方にメモリが割り当てられます。
各画像の形状は 28x28x1 の行列として定義され、最後の次元は画像内のチャネル数を表します。 MNIST データセットはグレースケール画像で構成されているため、チャネルは XNUMX つだけです。
この特定の例では、「zsize」として示される潜在空間のサイズを 100 に設定します。この値は、特定の要件や好みに応じて調整できます。
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
import sys
import numpy as np num_rows = 28
num_cols = 28
num_channels = 1
input_shape = (num_rows, num_cols, num_channels)
z_size = 100 (train_ims, _), (_, _) = mnist.load_data()
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3) valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
ジェネレーターの定義
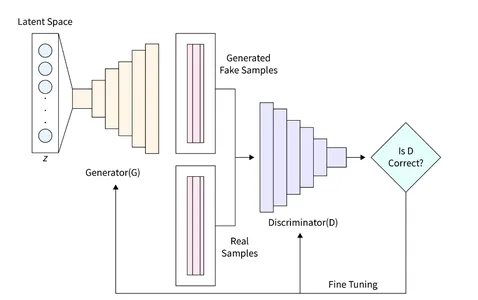
ジェネレーター (D) は、ディスクリミネーターを欺くことができるリアルな画像を生成する役割を担うため、GAN において重要な役割を果たします。 これは、GAN での画像形成の主要コンポーネントとして機能します。 この研究では、完全接続 (FC) 層を組み込み、Leaky ReLU アクティベーションを採用する、ジェネレーターの特定のアーキテクチャを利用します。 ただし、ジェネレーターの最後の層は LeakyReLU ではなく TanH アクティベーションを利用していることに注意してください。 この調整は、生成されたイメージが元の MNIST データベースと同じ間隔 (-1, 1) 内に存在するようにするために行われました。
def build_generator(): gen_model = Sequential() gen_model.add(Dense(256, input_dim=z_size)) gen_model.add(LeakyReLU(alpha=0.2)) gen_model.add(BatchNormalization(momentum=0.8)) gen_model.add(Dense(512)) gen_model.add(LeakyReLU(alpha=0.2)) gen_model.add(BatchNormalization(momentum=0.8)) gen_model.add(Dense(1024)) gen_model.add(LeakyReLU(alpha=0.2)) gen_model.add(BatchNormalization(momentum=0.8)) gen_model.add(Dense(np.prod(input_shape), activation='tanh')) gen_model.add(Reshape(input_shape)) gen_noise = Input(shape=(z_size,)) gen_img = gen_model(gen_noise) return Model(gen_noise, gen_img)
弁別子の定義
Generative Adversarial Network (GAN) では、Discriminator (D) は、実際の画像と生成された画像の信頼性と尤度を評価することでそれらを区別するという重要なタスクを実行します。 このコンポーネントは、二項分類問題として見ることができます。 このタスクに対処するために、完全接続層 (FC)、リーキー ReLU アクティベーション、およびドロップアウト層で構成される簡素化されたネットワーク アーキテクチャを採用できます。 Discriminator の最終層には、FC 層とそれに続く Sigmoid アクティベーションが含まれていることを言及することが重要です。 シグモイド活性化関数は、目的の分類確率を生成します。
def build_discriminator(): disc_model = Sequential() disc_model.add(Flatten(input_shape=input_shape)) disc_model.add(Dense(512)) disc_model.add(LeakyReLU(alpha=0.2)) disc_model.add(Dense(256)) disc_model.add(LeakyReLU(alpha=0.2)) disc_model.add(Dense(1, activation='sigmoid')) disc_img = Input(shape=input_shape) validity = disc_model(disc_img) return Model(disc_img, validity)
損失関数の計算
GAN で適切な画像生成プロセスを保証するには、そのパフォーマンスを評価するための適切な指標を決定することが重要です。 このパラメータは損失関数で定義します。
識別器は、生成された画像を本物か偽物に分け、本物である確率を与える役割を果たします。 この違いを達成するために、Discriminator は、実際の画像が提示された場合には関数 D(x) を最大化し、偽の画像が提示された場合には D(G(z)) を最小化することを目的としています。
一方、ジェネレーターの目的は、誤解される可能性のあるリアルな画像を作成することでディスクリミネーターをだますことです。 数学的には、これには D(G(z)) のスケーリングが含まれます。 ただし、このコンポーネントを損失関数としてのみ依存すると、ネットワークが誤った結果を過信してしまう可能性があります。 この問題を解決するには、損失関数 (D(G(z)) の対数を使用します。
画像を生成するための GAN の全体的なコスト関数は、最小限のゲームとして表現できます。
min_G max_D V(D,G) = E(xp_data(x))(log(D(x))] + E(zp(z))(log(1 – D(G(z)))])
このような GAN トレーニングには微妙なバランスが必要であり、XNUMX 人の対戦相手間の試合と見なすこともできます。 それぞれの側は、MinMax ゲームをプレイすることで、相手に影響を与え、相手を上回ろうとします。
Binary Cross Entropy Loss を使用して、Generator と Discriminator を実装できます。
Generator と Discriminator の実装には、Binary Cross エントロピー損失を利用できます。
# discriminator
disc= build_discriminator()
disc.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy']) z = Input(shape=(z_size,)) # generator
img = generator(z) disc.trainable = False validity = disc(img) # combined model
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
損失の最適化
ネットワークのトレーニングを促進するために、私たちの目的は GAN を MinMax ゲームに参加させることです。 この学習プロセスは、勾配降下法を使用したネットワークの重みの最適化を中心に展開します。 学習プロセスを加速し、最適ではない損失状況への収束を防ぐために、確率的勾配降下法 (SGD) が採用されています。
Discriminator と Generator に個別の損失があることを考えると、単一の損失関数で両方のシステムを同時に最適化することはできません。 したがって、システムごとに個別の損失関数を利用します。
def intialize_model(): disc= build_discriminator() disc.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy']) generator = build_generator() z = Input(shape=(z_size,)) img = generator(z) disc.trainable = False validity = disc(img) combined = Model(z, validity) combined.compile(loss='binary_crossentropy', optimizer='sgd') return disc, Generator, and combined
必要な機能をすべて指定したら、システムをトレーニングして損失を最適化できます。 GAN をトレーニングして画像を生成する手順は次のとおりです。
- 画像を読み込み、読み込んだ画像と同じサイズのランダムなサウンドを生成します。
- アップロードされた画像と生成された音声を区別し、本物か偽物の可能性を検討します。
- 同じ大きさの別のランダム ノイズを生成し、ジェネレーターへの入力として提供します。
- 特定の期間ジェネレーターをトレーニングします。
- 画像が満足できるまでこれらの手順を繰り返します。
def train(epochs, batch_size=128, sample_interval=50): # load images (train_ims, _), (_, _) = mnist.load_data() # preprocess train_ims = train_ims / 127.5 - 1. train_ims = np.expand_dims(train_ims, axis=3) valid = np.ones((batch_size, 1)) fake = np.zeros((batch_size, 1)) # training loop for epoch in range(epochs): batch_index = np.random.randint(0, train_ims.shape[0], batch_size) imgs = train_ims[batch_index] # create noise noise = np.random.normal(0, 1, (batch_size, z_size)) # predict using a Generator gen_imgs = gen.predict(noise) # calculate loss functions real_disc_loss = disc.train_on_batch(imgs, valid) fake_disc_loss = disc.train_on_batch(gen_imgs, fake) disc_loss_total = 0.5 * np.add(real_disc_loss, fake_disc_loss) noise = np.random.normal(0, 1, (batch_size, z_size)) g_loss = full_model.train_on_batch(noise, valid) # save outputs every few epochs if epoch % sample_interval == 0: one_batch(epoch)
手書き数字の生成
MNIST データセットを使用すると、ジェネレーターを使用して一連の画像の予測を生成するユーティリティ関数を作成できます。 この関数は、ランダムなサウンドを生成し、それをジェネレーターに供給し、それを実行して生成された画像を表示し、特別なフォルダーに保存します。 ネットワークの進行状況を監視するために、このユーティリティ関数を定期的に (200 サイクルごとなど) 実行することをお勧めします。 実装は以下のとおりです。
def one_batch(epoch): r, c = 5, 5 noise_model = np.random.normal(0, 1, (r * c, z_size)) gen_images = gen.predict(noise_model) # Rescale images 0 - 1 gen_images = gen_images*(0.5) + 0.5 fig, axs = plt.subplots(r, c) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(gen_images[cnt, :,:,0], cmap='gray') axs[i,j].axis('off') cnt += 1 fig.savefig("images/%d.png" % epoch) plt.close()
私たちの実験では、バッチ サイズ 10,000 を使用して約 32 エポックにわたって GAN をトレーニングしました。トレーニングの進行状況を追跡するために、生成された画像を 200 エポックごとに保存し、「images」という指定フォルダーに保存しました。
disc, gen, full_model = intialize_model()
train(epochs=10000, batch_size=32, sample_interval=200)ここで、初期化、400 エポック、5000 エポック、および 10000 エポックの最終結果というさまざまな段階での GAN シミュレーションの結果を調べてみましょう。
最初に、ジェネレーターへの入力としてランダム ノイズから始めます。

400 エポックのトレーニング後、生成された画像は依然として実際の数値とは大幅に異なりますが、ある程度の進歩を観察できます。

5000 エポックのトレーニング後、生成された図が MNIST データセットに似始めていることがわかります。

トレーニングの 10,000 エポック全体を完了すると、次の出力が得られます。

これらの生成された画像は、ネットワークをトレーニングするための手書きの番号データによく似ています。 これらの画像はトレーニング セットの一部ではなく、完全にネットワークによって生成されることに注意することが重要です。
次のステップ
GAN の画像生成で良い結果が得られたので、それをさらに改善できる方法はたくさんあります。 この議論の範囲内で、さまざまなパラメータを試してみることを検討するかもしれません。 以下にいくつかの提案を示します。
- 潜在空間変数 z_size のさまざまな値を調べて、効率が向上するかどうかを確認します。
- トレーニング エポックの数を 10,000 以上に増やします。 トレーニング時間を XNUMX 倍または XNUMX 倍にすると、結果の改善または低下が明らかになる場合があります。
- ファッション MNIST や移動 MNIST など、さまざまなデータセットを使用してみてください。 これらのデータセットは MNIST と同じ構造を持っているため、既存のコードを適応させます。
- CycleGun、DCGAN などの代替アーキテクチャを試してみることを検討してください。 これらのモデルを調査するには、ジェネレーター関数とディスクリミネーター関数を変更するだけで十分な場合があります。
これらの変更を実装することで、GAN の機能をさらに強化し、画像生成の新たな可能性を探ることができます。
これらの生成された画像は、ネットワークのトレーニングに使用される手書きの数字データによく似ています。 これらの画像はトレーニング セットの一部ではなく、完全にネットワークによって生成されます。
まとめ
要約すると、GAN は、既存のデータベースに基づいて新しい画像を生成できる強力な機械学習モデルです。 このチュートリアルでは、例として Tensorflow ライブラリと MNIST データベースを使用して、単純な GAN を設計およびトレーニングする方法を示しました。
主要な取り組み
- GAN は、ランダムな入力から新しい画像を生成する役割を担うジェネレーターと、本物の画像と偽の画像を区別することを目的とするディスクリミネーターという XNUMX つの重要なコンポーネントで構成されます。
- 学習プロセスを通じて、サンプル画像に示すように、手書きの数字によく似た一連の画像を作成することに成功しました。
- GAN のパフォーマンスを最適化するために、本物の画像と偽の画像を区別するのに役立つマッチング メトリクスと損失関数を提供します。 目に見えないデータで GAN を評価し、ジェネレーターを使用することで、これまでに見たことのない新しい画像を生成できます。
- 全体として、GAN は画像生成において興味深い可能性を提供し、機械学習やコンピューター ビジョンなどのいくつかのアプリケーションに大きな可能性を秘めています。
よくある質問
A. Generative Adversarial Networks (GAN) は、特定のトレーニング セットに類似した統計を含む新しいデータを生成できる機械学習フレームワークの一種です。 画像、ビデオ、テキストなどのさまざまな種類のデータに GAN を使用します。
A. 生成モデルは、一連の入力データに基づいて新しいデータを生成する機械学習アルゴリズムです。 これらのモデルは、画像生成、テキスト生成、その他の形式のデータ合成などのタスクに使用します。
A. 損失関数は、XNUMX つのデータ セット間の差を測定する数学関数です。 GAN のコンテキストでは、通常はクラス レコードと注釈付き画像を使用して、生成されたデータとトレーニング データの差を定義する損失関数を最適化することでモデル ジェネレーターをトレーニングします。
A. CNN (畳み込みニューラル ネットワーク) と GAN (敵対的生成ネットワーク) はどちらも深層学習アーキテクチャですが、目的が異なります。 GAN は特定のトレーニング セットに似た新しいデータを生成することを目的とした生成モデルであり、CNN は分類と認識タスクを目的としています。 CNN を可変オートエンコーダー (VAE) として構成することで生成モデルとして使用することは可能ですが、CNN は識別トレーニングに優れており、コンピューター ビジョンでの画像分類タスクにおいてはより効果的です。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/06/using-gans-in-tensorflow-generate-images/

