
編集者による画像
PyTorch Lightning は、スケーラブルな最先端の AI 研究作業をサポートする強力なディープ ラーニング フレームワークです。 研究作業用にコードを構造化し、プロジェクトの複雑さが増していくのを防ぎます。
しかし、コードの複雑さが何を伴うのかを理解する前に、モデル構築プロセスを促進するための努力において、PyTorch ライトニング (この記事ではライトニングと呼ばれます) の構造化コードがどのように役立つかを詳しく調べてみましょう。 機械学習モデルをコーディングする準備を整えるとき、通常は、モデル アーキテクチャを設計し、特定のデータセットに適したオプティマイザーを選択します。 これらすべての側面が与えられたので、トレーニングと検証のためにデータのバッチを反復処理するなどの手順を含む Python コードを実際に作成する準備が整いました。 機械学習プロジェクトでは避けられない定期的なデバッグ対策を忘れないでください。
さらに、コードの複雑さには、複数の GPU の使用、早期停止基準、チェックポイントの必要性、16 ビット精度、TPU アクセラレータでのトレーニングなど、複数の要因が関係しています。Lightning では、CPU、GPU、または TPU でモデルを変更せずにトレーニングできます。 Pytorch コードと再現可能なモデルの構築を支援します。
から直接利益を引用する ライトニングクリエーター – 「PyTorch Lightning は、プロの研究者や博士号を取得するために作成されました。 AI研究に取り組んでいる学生。 最先端の AI 研究技術 (TPU トレーニングなど) を簡単にしながら、非常に拡張できるように設計されています。」
PyTorch の特性を理解して、Lightning が提供する機能と利点を理解することが重要です。
PyTorch は、ニューラル ネットワーク モデルの構築に広く使用されている Python ベースのオープンソース ライブラリです。 プロダクション モデルを構築するための最も一般的な代替手段である TensorFlow と比較して、広大なコミュニティ ベースを享受しており、主に研究環境で使用されています。 PyTorch の基本を学ぶことに興味がある場合、このドキュメントは優れたドキュメントとして役立ちます。 参照.
PyTorch は研究者を対象としていますが、モデルのトレーニングとチューニングに関連する取り組みに関して、すぐにエンジニアリングおよびコード駆動型になります。
Lightning は、PyTorch がモデル トレーニングに提供する柔軟性に基づいて構築され、複数の最先端の実験の迅速な反復を容易にします。 再現性をさらに高めた構造にすることで、コードの可読性を向上させます。
次の点を除いて、大部分のコードは同じままです。
- トレーニングと検証のループは、トレーナーによって抽象化されています。
- さらに、コード ブロックの一部、つまりデータ ローダー、フォワード パス、オプティマイザーなどは再構築されており、開発者による最小限の詳細が必要です。
たとえば、Lightning はデフォルトでモデル チェックポイントを自動的に保存しますが、Pytorch は開発者がチェックポイントのためにそのロジックを挿入することを期待しています。 Lightning は、重みの要約、チェックポイント、早期停止、およびテンソルボード ログのログも提供します。
ターミナル (MAC/Linux の場合) またはコマンド ライン (Windows の場合) で以下のコマンドを実行できます。
pip install pytorch-lightning
を使用して数字を認識する画像分類モデルを構築しましょう。 MNISTデータセット. torchvision モジュールを介して複数のデータセットをインポートする方法について学ぶことができます Pytorch の公式ドキュメント ページ.

情報源: MLM
ニューラル ネットワーク モデルを構築する際の XNUMX つのコア コンポーネントには、モデル、データ、損失、オプティマイザーが含まれます。
ニューラル ネットワーク アーキテクチャから始めましょう。
- このデモでは、入力層と出力層を含む 4 層 (入力層が明示的にカウントされない場合は 3 層) の完全に接続されたディープ ニューラル ネットワーク アーキテクチャを構築します。
- ただし、正方形の画像 (サイズ 28 * 28) は、ニューラル ネットワークによって入力として使用されるように、ベクトル化または平坦化する必要があります。 したがって、入力層のニューロンの数は、画像の幅 * 高さ、つまり 784 (28*28) に等しくなります。 フラット化プロセスでは、以下に示すように、各行の値がベクトルに配置されます。
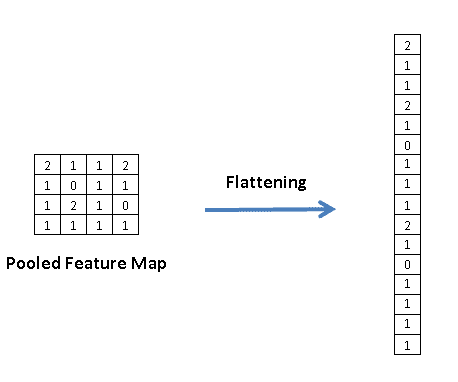
情報源: Keras を使用した畳み込みニューラル ネットワーク (CNN) の実践ガイド
- 一方、出力層のニューロンの数は、ラベルの数、つまり 10 (0 から 9 までの数字) に等しくなります。
- 隠れ層のニューロンの数を選択するオプションがあります。 一般的に言えば、ニューロンの数が少ないと入力層からの情報が失われる可能性がありますが、ニューロンの数が多いとニューロンからの情報が重複する可能性があります。 最初の隠れ層に 128 個のニューロン、256 番目の隠れ層に XNUMX 個のニューロンを選びましょう。
- ニューラル ネットワーク アーキテクチャは、下の画像のようになります。
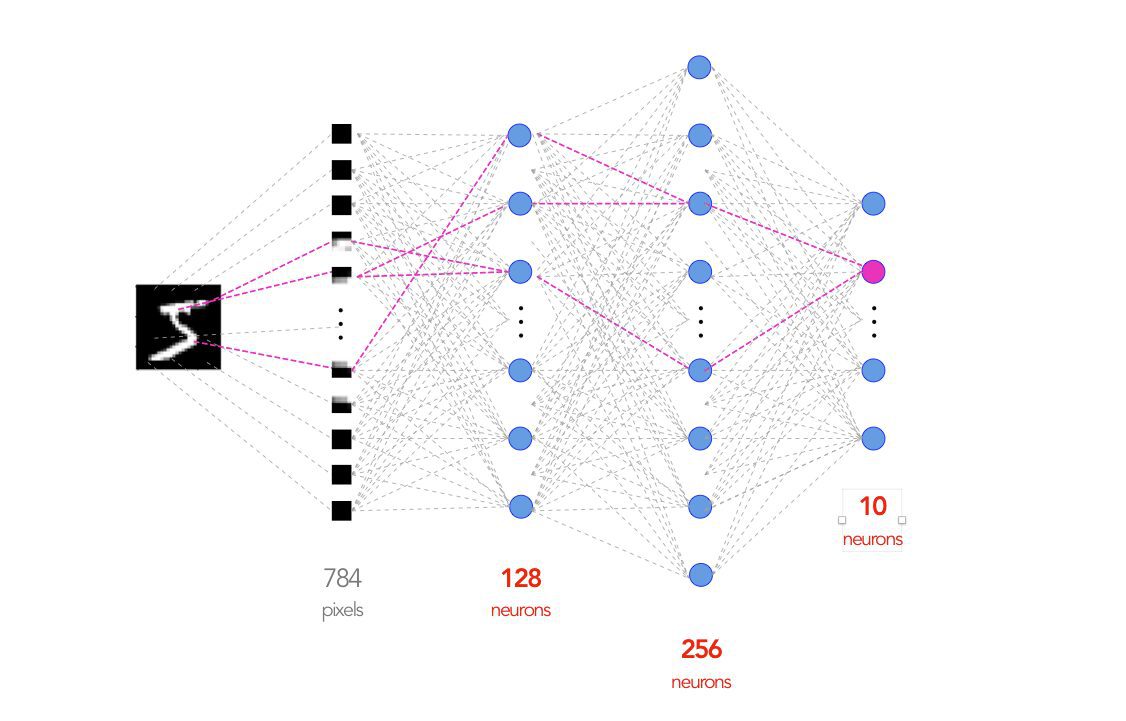
情報源: PyTorch ライトニングの紹介
- また、順伝播関数を指定する必要があります。非表示層の ReLu 活性化関数と出力層の Softmax 活性化関数を選択しましょう。
- ネットワークでのトレーニングまたは検証の実行には、出力確率を計算するための順伝播が含まれ、続いて Adam オプティマイザーを使用してネットワーク パラメーターを調整するための損失計算が行われます。
上記で詳述したニューラル ネットワーク アーキテクチャ、損失、およびオプティマイザーの選択は、コードに示されています (「PyTorch から PyTorch Lightning へ – はじめに") 下:
import torch
from torch import nn
import pytorch_lightning as pl
from torch.utils.data import DataLoader, random_split
from torch.nn import functional as F
from torchvision.datasets import MNIST
from torchvision import datasets, transforms
import os class PLClassifier(pl.LightningModule): def __init__(self): super(PLClassifier, self).__init__() self.input = torch.nn.Linear(28 * 28, 128) self.hidden1 = torch.nn.Linear(128, 256) self.hidden2 = torch.nn.Linear(256, 10) def forward(self, x): batch, channels, width, height = x.size() x = x.view(batch, -1) x = self.input(x) x = torch.relu(x) x = self.hidden1(x) x = torch.relu(x) x = self.hidden2(x) x = torch.log_softmax(x, dim=1) return x def training_step(self, batch, batch_idx): x, y = train_batch logits = self.forward(x) loss = F.nll_loss(logits, y) self.log('train_loss', loss) return loss def validation_step(self, batch, batch_idx): x, y = train_batch logits = self.forward(x) loss = F.nll_loss(logits, y) self.log('val_loss', loss) def configure_optimizers(self): opt = torch.optim.Adam(self.parameters(), lr=1e-3) return opt # initialize and train
model = PLClassifier()
trainer = pl.Trainer() trainer.fit(model)
以下のコードに従って、トレーニングとテストのデータをダウンロードできます。
train = MNIST(os.getcwd(), train=True, download=True)
test = MNIST(os.getcwd(), train=False, download=True)
トレーニング データを取り込むときは train 引数が True に設定され、テスト データの場合は False に設定されることに注意してください。
トレーニング データは、さらにトレーニングと検証に分割できます。
train, val = random_split(train, [50000, 10000])
この投稿では、Lightning の利点を説明し、Python コードを使用して最初のモデルを構築する方法を示しました。 さらに、ビデオ レッスンから学習したい場合は、ボーナス リソース リストを参照できます。 バイトサイズのビデオ チュートリアル.
ヴィディ・チュー スケーラブルな機械学習システムを構築するために、製品、科学、エンジニアリングの交差点で働く AI ストラテジストであり、デジタル トランスフォーメーションのリーダーです。 彼女は受賞歴のあるイノベーション リーダーであり、作家であり、国際的な講演者でもあります。 彼女は、機械学習を民主化し、誰もがこの変革に参加できるよう専門用語を打ち破ることを使命としています。
- コインスマート。 ヨーロッパで最高のビットコインと暗号通貨取引所。ここをクリック
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2022/12/getting-started-pytorch-lightning.html?utm_source=rss&utm_medium=rss&utm_campaign=getting-started-with-pytorch-lightning-2

