概要
4 月は AI 分野で劇的な出来事がありました。 GPT ストア、GPT-3.5-turbo の立ち上げから OpenAI の大失敗までは、かなりの道のりでした。 しかし、これは重要な疑問を引き起こします。クローズドモデルとその背後にいる人々はどの程度信頼できるのでしょうか? 企業内で何らかのトラブルが発生したために、本番環境で使用しているモデルがダウンした場合、それは楽しい経験ではありません。 オープンソース モデルではこれは問題になりません。 デプロイするモデルを完全に制御できます。 データとモデルに対する主権は同様にあなたにあります。 しかし、OS モデルを GPT で置き換えることは可能でしょうか? ありがたいことに、多くのオープンソース モデルはすでに GPT-XNUMX モデルと同等かそれ以上のパフォーマンスを発揮しています。 この記事では、オープンソース LLM および LMM の最もパフォーマンスの高い代替手段のいくつかを検討します。
学習目標
- オープンソースの大規模言語モデルについて話し合います。
- 最先端のオープンソース言語モデルとマルチモーダル モデルを探索します。
- 大規模な言語モデルを量子化するための穏やかな入門書。
- LLM をローカルおよびクラウド上で実行するためのツールとサービスについて学びます。
この記事は、の一部として公開されました データサイエンスブログソン.
目次
オープンソース モデルとは何ですか?
モデルの重みとアーキテクチャが自由に利用できる場合、モデルはオープンソースと呼ばれます。 これらの重みは、大規模な言語モデルの事前トレーニングされたパラメータです。たとえば、 メタのラマ。 これらは通常、微調整のないベース モデルまたはバニラ モデルです。 誰でもモデルを使用し、カスタム データに基づいてモデルを微調整して、ダウンストリーム アクションを実行できます。
しかし、それらは開いていますか? データについてはどうですか? 著作権で保護されたコンテンツやデータの機密性に関する多くの懸念があるため、ほとんどの研究機関は基本モデルのトレーニングに使用されるデータを公開していません。 これは、モデルのライセンスの部分にもつながります。 すべてのオープンソース モデルには、他のオープンソース ソフトウェアと同様のライセンスが付属しています。 Llama-1 などの多くの基本モデルには非商用ライセンスが付属しているため、これらのモデルを収益目的に使用することはできません。 ただし、Mistral7B や Zephyr7B などのモデルには Apche-2.0 および MIT ライセンスが付属しているため、どこでも安心して使用できます。
オープンソースの代替案
Llama の発表以来、OpenAI モデルに追いつくために、オープンソース分野での軍拡競争が行われてきました。 そして、これまでのところ、その結果は励みになります。 XNUMX年以内に GPT-3.5、 より少ないパラメータで GPT-3.5 と同等以上のパフォーマンスを発揮するモデルがあります。 しかし GPT-4 推論や数学からコード生成までの一般的なタスクを実行するのに最適なモデルです。 オープンソース モデルのイノベーションと資金調達のペースをさらに見てみると、GPT-4 のパフォーマンスに近いモデルが間もなく登場するでしょう。 ここでは、これらのモデルに代わる優れたオープンソースの代替案について説明します。
メタのラマ 2
メタがベストモデルをリリース、 ラマ-2、今年2月にリリースされ、その素晴らしい機能によりすぐにヒットしました。 Meta は、パラメーター サイズが異なる 7 つの Llama-13 モデルをリリースしました。 ラマ-34b、70b、7b、および 7b。 これらのモデルは、それぞれのカテゴリで他のオープン モデルを上回るのに十分な優れたものでした。 しかし現在では、mistral-2b や Zephyr-70b などの複数のモデルが、多くのベンチマークで小型の Llama モデルよりも優れたパフォーマンスを示しています。 Llama-4 XNUMXb は依然としてこのカテゴリで最高の製品の XNUMX つであり、要約や機械翻訳などのタスクでは GPT-XNUMX の代替品としての価値があります。
いくつかのベンチマークでは、Llama-2 は GPT-3.5 よりも優れたパフォーマンスを示し、GPT-4 に近づくことができたので、GPT-3.5、場合によっては GPT-4 の代替としてふさわしいものになりました。 次のグラフは、Llama モデルと GPT モデルのパフォーマンスを比較したものです。 スケール.
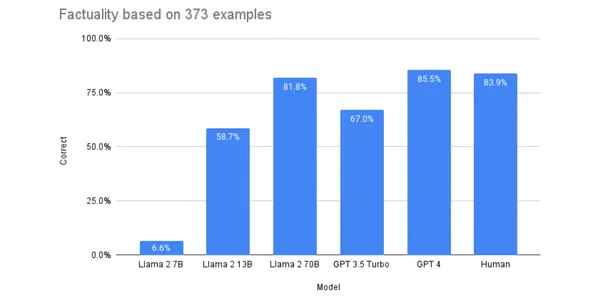
Llama-2 の詳細については、こちらを参照してください。 ブログ ハギングフェイスで。 これらの LLM は、カスタム データセットに対して微調整すると良好なパフォーマンスを発揮することが示されています。 モデルを微調整して、特定のタスクのパフォーマンスを向上させることができます。
さまざまな研究機関も、Llama-2 の微調整されたバージョンをリリースしています。 これらのモデルは、多くのベンチマークで元のモデルよりも優れた結果を示しています。 この微調整された Llama-2 モデルは、 ヌース・ヘルメス・ラマ2-70b Nous Research の製品は 300,000 を超えるカスタム命令に基づいて微調整されており、オリジナルよりも優れています。 メタラマ/ラマ-2-70b-チャット-hf.
ハギングフェイスをチェックしてみよう リーダー。 元のモデルよりも優れた結果をもたらす、微調整された Llama-2 モデルを見つけることができます。 これは OS モデルの長所の XNUMX つです。 要件に応じて選択できるモデルが豊富にあります。
ミストラル-7B
Mistral-7B のリリース以来、それはオープンソース コミュニティの最愛の人になりました。 このカテゴリのどのモデルよりもはるかに優れたパフォーマンスを示し、GPT-3.5 の機能に迫ることが示されています。 このモデルは、要約、言い換え、分類など、多くの場合に Gpt-3.5 の代替として使用できます。
モデル パラメーターが少ないため、小規模なモデルをローカルで実行したり、大規模なモデルよりも安価な料金でホストしたりできます。 オリジナルのhuggingFaceスペースはこちら ミストラル-7b。 優れたパフォーマーであることに加えて、Mistral-7b を際立たせている点の XNUMX つは、検閲のない生のモデルであることです。 ほとんどのモデルは重力でロボトミー手術を受けています RLHF 起動前なので、多くのタスクにとって望ましくないものになります。 しかし、このため、現実世界の主題固有のタスクを実行するには、Mistral-7B が望ましいものになります。
活気に満ちたオープンソース コミュニティのおかげで、オリジナルの Mistral7b モデルよりも優れたパフォーマンスを備えた、細かく調整された代替品が数多く存在します。
オープンエルメス-2.5
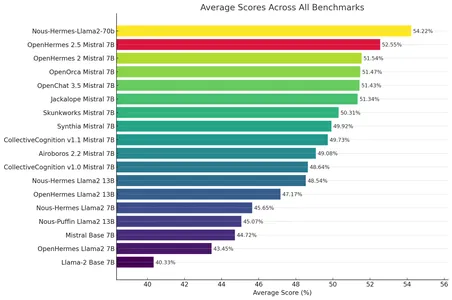
OpenHermes-2.5はミストラルをファインチューニングしたモデルです。 評価指標 (GPT4ALL、TruthfullQA、AgiEval、BigBench) 全体で顕著な結果を示しています。 多くのタスクでは、これは GPT-3.5 と区別できません。 OpenHermes の詳細については、次の HF リポジトリを参照してください。 テクニウム/オープンエルメス-2.5-ミストラル-7B.
ゼファー7b
Zephyr-7b は、HuggingFace による Mistral-7b のもう 7 つの微調整モデルです。 ハギングフェイスは、DPO (Direct Preference Optimization) を使用して Mistral-7b を完全に微調整しました。 Zephyr-3.5b-beta は、執筆、人文科学の科目、ロールプレイなどの多くのタスクにおいて、GPT-2 や Llama-70-7b などの大型モデルと同等のパフォーマンスを発揮します。 以下は、MTbench での Zephyr-3.5b と他のモデルの比較です。 これは、さまざまな点で GPT-XNUMX の優れた代替品となります。
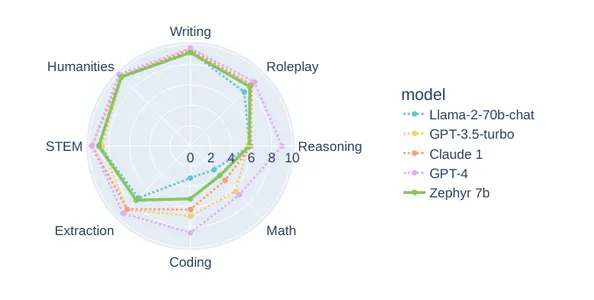
公式HuggingFaceリポジトリは次のとおりです。 ハグフェイスH4/ゼファー-7b-ベータ.
インテルニューラルチャット
ニューラルチャットは7Bです LLM Intel によって Mistral-7B から微調整されたモデル。 すべての 7B モデルの中で Huggingface リーダーボードのトップに立つなど、目覚ましいパフォーマンスを示しています。 NeuralChat-7b は、AI タスクを高速化するための Intel チップである Gaudi-2 上で微調整およびトレーニングされています。 NeuralChat の優れたパフォーマンスは、監視された微調整と、Orca およびスリム Orca データセットに対する直接最適化設定 (DPO) の結果です。
NeuralChat の HuggingFace リポジトリは次のとおりです。 インテル/ニューラルチャット-7b-v3-1.
オープンソースの大規模マルチモーダル モデル
GPT-4 Vision のリリース後、次のような関心が高まっています。 マルチモーダルモデル。 ビジョンを備えた大規模言語モデルは、画像に対する質問応答やビデオのナレーションなど、多くの実世界のユースケースで優れた効果を発揮します。 そのようなユースケースの XNUMX つでは、 トルドロー をリリースしました AIホワイトボード 画像をコードに解釈する GPT-4V の非常識な機能を使用して、ホワイトボード上の描画から Web コンポーネントを作成できます。
しかし、オープンソースはより早くそこに到達しています。 多くの研究機関が、Llava、Baklava、Fuyu-8b などの大規模なマルチモーダル モデルをリリースしました。
ラヴァ
Llava (大型言語および視覚アシスタント) は、13 億のパラメーターを備えたマルチモーダル モデルです。 Llava は Vicuna-13b LLM と事前トレーニングされたビジュアル エンコーダーを接続します クリップViT-L/14。 Visual Chat と Science QA データセットに基づいて微調整されており、多くの場合で GPT-4V と同様のパフォーマンスを実現しています。 これは、ビジュアル QA タスクで使用できます。
バクラヴァ
SkunkWorksAI の BakLlava も、大規模なマルチモーダル モデルです。 ベース LLM として Mistral-7b があり、Llava-1.5 アーキテクチャで強化されています。 小型であるにもかかわらず、Llava-13b と同等の有望な結果を示しています。 これは、優れた視覚的推論を備えた小規模なモデルが必要な場合に探すべきモデルです。
冬-8b
もう 8 つのオープンソースの代替案は Fuyu-XNUMXb です。 これは、Adept が提供する有能なマルチモーダル言語モデルです。 Fuyu は、ビジュアル エンコーダーを持たないデコーダーのみのトランスフォーマーです。 これは、CLIP が使用される Llava とは異なります。
画像エンコーダを使用して LLM に画像データを供給する他のマルチモーダル モデルとは異なり、画像の部分をトランスフォーマーの最初の層に線形に投影します。 トランスフォーマー デコーダーを画像トランスフォーマーとして扱います。 以下は、Fuyu のアーキテクチャの図です。
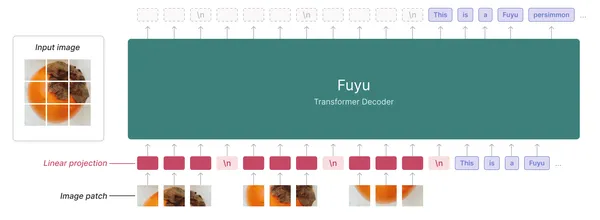
Fuyu-8bについて詳しくはこちらをご覧ください。 記事。 ハグフェイスリポジトリ 達人/冬-8b
オープン LLM の使用方法?
最もパフォーマンスの高いオープンソース LLM と LMM のいくつかについては理解できたので、問題はオープン モデルから推論を取得する方法です。 オープンソース モデルから推論を取得するには XNUMX つの方法があります。 個人のハードウェアにモデルをダウンロードするか、クラウド プロバイダーに加入します。 さて、これはユースケースによって異なります。 これらのモデルは、たとえ小規模であっても、大量の計算を必要とし、大量の RAM と VRAM を必要とします。 商用ハードウェア上でこれらのバニラ モデルを推論することは非常に困難です。 これを簡単にするには、モデルを量子化する必要があります。 それでは、モデルの量子化とは何かを理解しましょう。
量子化
量子化は、浮動小数点整数の精度を下げる技術です。 通常、ラボは、最先端 (SOTA) パフォーマンスを達成するために、より高い浮動小数点精度の重みとアクティベーションを備えたモデルをリリースします。 このため、モデルのコンピューティングには負荷がかかり、ローカルでの実行やクラウドでのホスティングには理想的ではなくなります。 この問題の解決策は、重みと埋め込みの精度を下げることです。 これを量子化といいます。
SOTA モデルは通常、float32 精度を持ちます。 量子化には、fp32 -> fp16、fp-32 -> int8、fp32 -> fp8、fp32 -> fp4 というさまざまなケースがあります。 このセクションでは、int8 または 8 ビット整数量子化への量子化についてのみ説明します。
int8 への量子化
int8 表現は 256 文字 (符号付き [-128,127]、符号なし [0, 256]) のみを収容できますが、fp32 では広範囲の数値を使用できます。 アイデアは、[a,b] の fp32 値の int8 形式への同等の射影を見つけることです。
X が範囲 [a,b,] の fp32 数値である場合、量子化スキームは次のようになります。
X = S*(X_q – z)
- X_q = X に関連付けられた量子化された値
- S はスケーリングパラメータです。 正の fp32 数値。
- z はゼロ点です。 これは、fp8 の値 0 に対応する int32 値です。
したがって、X_q =round(X/S + z) ∀X ∈ [a,b]
fp3,2 の場合、[a,b] を超える値は最も近い表現にクリップされます。
X_q = クリップ( X_q = ラウンド(a/S + z) + ラウンド(X/S + z) + X_q = ラウンド(b/S + z) )
- この数値形式では、round(a/S + z) が最小の数値であり、round(b/S + z) が最大の数値です。
これは次の方程式です アフィンまたはゼロ点量子化。 これは 8 ビット整数量子化に関するものでした。 8 ビット fp8、4 ビット (fp4、nf4)、および 2 ビット (fp2) の量子化スキームもあります。 量子化の詳細については、この記事を参照してください。 HuggingFace。
モデルの量子化は複雑なタスクです。 LLM を量子化するためのオープンソース ツールは複数あります。 ラマ.cpp, AutoGPTQ, llm-awqllama cpp は GGUF を使用してモデルを量子化し、AutoGPTQ は GPTQ を使用して、llm-awq は AWQ 形式を使用してモデルを量子化します。 これらは、モデル サイズを削減するためのさまざまな量子化方法です。
したがって、推論にオープンソース モデルを使用したい場合は、量子化モデルを使用するのが合理的です。 ただし、ある程度の推論品質を犠牲にして、大金をかけずに小さなモデルを手に入れることになります。
量子化モデルについては、この HuggingFace リポジトリを確認してください。 https://huggingface.co/TheBloke
モデルをローカルで実行する
多くの場合、さまざまなニーズに応じて、モデルをローカルで実行する必要があります。 モデルをローカルで実行するときは、非常に自由度が高くなります。 機密文書用のカスタム ソリューションを構築する場合でも、実験目的の場合でも、ローカル LLM はクローズド ソース モデルよりもはるかに高い自由と安心を提供します。
モデルをローカルで実行するためのツールは複数あります。 最も人気のあるものは、vLLM、Ollama、LMstudio です。
VLLM
vLLM で書かれたオープンソースの代替ソフトウェアです。 Python これにより、LLM をローカルで実行できるようになります。 vLLM でモデルを実行するには、一般に、16 を超える vRAM コンピューティング能力と XNUMX GB 以上の RAM を備えた特定のハードウェア仕様が必要です。 テストのために Collab で実行できるはずです。 VLLM は現在、AWQ 量子化形式をサポートしています。 使用できるモデルは次のとおりです vLLM。 これがモデルをローカルで実行する方法です。
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="mistralai/Mistral-7B-v0.1")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")vLLM は OpenAI エンドポイントもサポートします。 したがって、このモデルを既存の OpenAI 実装のドロップイン置換として使用できます。
import openai
# Modify OpenAI's API key and API base to use vLLM's API server.
openai.api_key = "EMPTY"
openai.api_base = "http://localhost:8000/v1"
completion = openai.Completion.create(model="mistralai/Mistral-7B-v0.1",
prompt="San Francisco is a")
print("Completion result:", completion)ここではOpenAI SDKを使ってローカルモデルから推論してみます。
オラマ
Ollama は、Go のもう XNUMX つのオープンソース代替 CLI ツールで、ローカル ハードウェア上でオープンソース モデルを実行できるようにします。 Ollama は GGUF 量子化モデルをサポートしています。
ディレクトリに Model ファイルを作成して実行します
FROM ./mistral-7b-v0.1.Q4_0.ggufモデル ファイルから Ollama モデルを作成します。
ollama create example -f Modelfile次に、モデルを実行します。
ollama run example "How to kill a Python process?"Ollama では、Pytorch モデルと HuggingFace モデルを実行することもできます。 詳細については、彼らの資料を参照してください。 公式リポジトリ.
LMスタジオ
LMstudio は、PC 上であらゆるモデルを簡単に実行できるクローズド ソース ソフトウェアです。 これは、モデルを実行するための専用ソフトウェアが必要な場合に最適です。 ローカルモデルを使用するための優れたUIを備えています。 Mac(M1、M2)、Linux(ベータ)、Windowsで利用可能です。
GGUF 形式のモデルもサポートします。 彼らのをチェックしてください official page 多くのための。 ハードウェア仕様をサポートしていることを確認してください。
クラウドプロバイダーのモデル
モデルをローカルで実行することは、実験やカスタムのユースケースには最適ですが、アプリケーションでモデルを使用するには、モデルをクラウドでホストする必要があります。 専用の LLM モデル プロバイダーを介してクラウド上でモデルをホストできます。 複製する & ブレブ開発。 モデルをホストし、微調整し、モデルから推論を取得することができます。 これらは、LLM をホスティングするための柔軟でスケーラブルなサービスを提供します。 リソースの割り当てはモデルのトラフィックに応じて変化します。
まとめ
オープンソース モデルの開発は猛烈なペースで行われています。 XNUMX年以内に AI言語モデルを活用してコードのデバッグからデータの異常検出まで、、多くのベンチマークで競合するよりもはるかに小さいモデルがあります。 これはほんの始まりにすぎず、GPT-4 と同等のモデルがもうすぐ登場するかもしれません。 最近、クローズドソース モデルの背後にある組織の完全性に関して疑問が提起されています。 開発者としては、モデルとその上に構築されたサービスが危険にさらされることを望まないでしょう。 オープンソースはこれを解決します。 あなたは自分のモデルを知っており、そのモデルを所有しています。 オープンソース モデルには多くの自由があります。 OS および OpenAI モデルとのハイブリッド構造を採用して、コストと依存性を削減することもできます。 したがって、この記事は、いくつかの優れたパフォーマンスの OS モデルとその実行に関連する概念の紹介でした。
したがって、重要なポイントは次のとおりです。
- オープンモデルは主権と同義です。 オープンソース モデルは、クローズド モデルでは実現できない、切望されている信頼要素を提供します。
- Llama-2 や Mistral などの大規模な言語モデルとその微調整は、多くのタスクで GPT-3.5 を上回っており、理想的な代替品となっています。
- Llava、BakLlava、Fuyu-8b などの大規模なマルチモーダル モデルは、多くの QA タスクや分類タスクで役立つことがわかっています。
- LLM は大規模で、大量の計算を必要とします。 したがって、ローカルで実行するには量子化が必要です。
- 量子化は、重みとアクティベーションフロートをより小さなビットにキャストすることでモデルのサイズを削減する手法です。
- OS モデルからローカルでホストおよび推論するには、LMstudio、Ollama、vLLM などのツールが必要です。 クラウドに展開するには、Replicate や Brev などのサービスを使用します。
よくある質問
A. はい、ChatGPT の代替手段として、Llama-2 チャット、Mistral-7b、Vicuna-13b などがあります。
A. LMstudio、Ollama、vLLM などのツールを使用して、ローカル マシン上でオープンソース LLM を実行できます。 また、ローカル マシンの能力にも依存します。
A. オープンソース モデルは、多くのタスクにおいて Gpt-3.5 よりも優れており、より効果的ですが、それでも GPT-4 が利用可能な最良のモデルです。
A. ユースケースによっては、オープンソース モデルは GPT モデルよりも安価である可能性がありますが、特定のタスクでより優れたパフォーマンスを発揮するには微調整する必要があります。
答え。 チャットボットは、チャットのような会話を細かく調整した LLM です。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/11/open-source-alternatives-to-openai-models/

