その中心に、 ラングチェーン は、言語モデルの機能を活用するアプリケーションを作成するために調整された革新的なフレームワークです。 これは、開発者がコンテキストを認識し、高度な推論が可能なアプリケーションを作成できるように設計されたツールキットです。
これは、LangChain アプリケーションがプロンプトの指示や内容に基づいた応答などのコンテキストを理解し、応答方法や実行するアクションの決定などの複雑な推論タスクに言語モデルを使用できることを意味します。 LangChain は、インテリジェントなアプリケーションを開発するための統一されたアプローチを表し、その多様なコンポーネントによってコンセプトから実行までの行程を簡素化します。
LangChain を理解する
LangChain は単なるフレームワークではありません。 それは、いくつかの不可欠な部分で構成される本格的なエコシステムです。
- まず、Python と JavaScript の両方で利用できる LangChain ライブラリがあります。 これらのライブラリは LangChain のバックボーンであり、さまざまなコンポーネントのインターフェイスと統合を提供します。 これらのコンポーネントを結合して凝集したチェーンとエージェントにするための基本的なランタイムと、すぐに使用できる既製の実装が提供されます。
- 次に、LangChain テンプレートがあります。 これらは、幅広いタスクに合わせて調整された展開可能なリファレンス アーキテクチャのコレクションです。 チャットボットを構築する場合でも、複雑な分析ツールを構築する場合でも、これらのテンプレートは確実な出発点となります。
- LangServe は、LangChain チェーンを REST API としてデプロイするための多用途ライブラリとして機能します。 このツールは、LangChain プロジェクトをアクセス可能でスケーラブルな Web サービスに変えるために不可欠です。
- 最後に、LangSmith は開発者プラットフォームとして機能します。 これは、LLM フレームワーク上に構築されたチェーンをデバッグ、テスト、評価、監視するように設計されています。 LangChain とのシームレスな統合により、アプリケーションを改良して完成させることを目指す開発者にとって、LangChain は不可欠なツールになります。
これらのコンポーネントを組み合わせることで、アプリケーションを簡単に開発、運用、展開できるようになります。 LangChain では、まずライブラリを使用してアプリケーションを作成し、ガイダンスとしてテンプレートを参照します。 LangSmith は、チェーンの検査、テスト、監視を支援し、アプリケーションが継続的に改善され、デプロイの準備が整っていることを確認します。 最後に、LangServe を使用すると、あらゆるチェーンを API に簡単に変換できるため、展開が簡単になります。
次のセクションでは、LangChain のセットアップ方法をさらに詳しく説明し、言語モデルを活用したインテリジェントなアプリケーションの作成を開始します。
Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
インストールとセットアップ
LangChain の世界に飛び込む準備はできていますか? セットアップは簡単で、このガイドではそのプロセスを段階的に説明します。
LangChain の旅の最初のステップは、LangChain をインストールすることです。 これは、pip または conda を使用して簡単に行うことができます。 ターミナルで次のコマンドを実行します。
pip install langchain
最新の機能を好み、もう少し冒険しても平気な方は、LangChain をソースから直接インストールできます。 リポジトリのクローンを作成し、次の場所に移動します。 langchain/libs/langchain ディレクトリ。 次に、次を実行します。
pip install -e .
実験的な機能については、インストールを検討してください。 langchain-experimental。 これは最先端のコードが含まれており、研究および実験目的を目的としたパッケージです。 以下を使用してインストールします。
pip install langchain-experimental
LangChain CLI は、LangChain テンプレートと LangServe プロジェクトを操作するための便利なツールです。 LangChain CLI をインストールするには、以下を使用します。
pip install langchain-cli
LangServe は、LangChain チェーンを REST API としてデプロイするために不可欠です。 これは、LangChain CLI と一緒にインストールされます。
LangChain では、多くの場合、モデル プロバイダー、データ ストア、API などとの統合が必要になります。この例では、OpenAI のモデル API を使用します。 以下を使用して OpenAI Python パッケージをインストールします。
pip install openai
API にアクセスするには、OpenAI API キーを環境変数として設定します。
export OPENAI_API_KEY="your_api_key"
あるいは、Python 環境でキーを直接渡します。
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain を使用すると、モジュールを通じて言語モデル アプリケーションを作成できます。 これらのモジュールは単独で使用することも、複雑な使用例に合わせて構成することもできます。 これらのモジュールは –
- モデルI / O: さまざまな言語モデルとの対話を促進し、入力と出力を効率的に処理します。
- 検索: 動的なデータ活用にとって重要な、アプリケーション固有のデータへのアクセスと対話を可能にします。
- エージェント: アプリケーションが高レベルのディレクティブに基づいて適切なツールを選択できるようにし、意思決定機能を強化します。
- チェーン: アプリケーション開発の構成要素として機能する、事前定義された再利用可能なコンポジションを提供します。
- メモリ: 複数のチェーン実行にわたってアプリケーションの状態を維持します。これは、コンテキストを認識した対話に不可欠です。
各モジュールは特定の開発ニーズを対象としており、LangChain を高度な言語モデル アプリケーションを作成するための包括的なツールキットにしています。
上記のコンポーネントに加えて、 LangChain 式言語 (LCEL)これは、モジュールを簡単に一緒に構成するための宣言的な方法であり、これにより、ユニバーサル Runnable インターフェイスを使用したコンポーネントのチェーン化が可能になります。
LCEL は次のようになります –
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
基本を説明したので、次の作業に進みます。
- 各 Langchain モジュールをさらに詳しく掘り下げます。
- LangChain 式言語の使用方法を学びます。
- 一般的な使用例を調べて実装します。
- LangServe を使用してエンドツーエンド アプリケーションを展開します。
- デバッグ、テスト、監視については LangSmith をチェックしてください。
始めましょう!
モジュール I : モデル I/O
LangChain では、アプリケーションの中核要素は言語モデルを中心に展開します。 このモジュールは、あらゆる言語モデルと効果的にインターフェイスするための重要な構成要素を提供し、シームレスな統合と通信を保証します。
モデル I/O の主要コンポーネント
- LLM とチャット モデル (同じ意味で使用):
- LLM:
- 定義: 純粋なテキスト補完モデル。
- 入力/出力: テキスト文字列を入力として受け取り、テキスト文字列を出力として返します。
- チャットモデル
- LLM:
- 定義: 言語モデルをベースとするが、入力形式と出力形式が異なるモデル。
- 入力/出力: チャット メッセージのリストを入力として受け入れ、チャット メッセージを返します。
- プロンプト: モデル入力をテンプレート化し、動的に選択し、管理します。 言語モデルの応答をガイドする、柔軟でコンテキスト固有のプロンプトを作成できます。
- 出力パーサー: モデル出力から情報を抽出してフォーマットします。 言語モデルの生の出力を、アプリケーションが必要とする構造化データまたは特定の形式に変換するのに役立ちます。
LLM
LangChain と OpenAI、Cohere、Hugging Face などの大規模言語モデル (LLM) との統合は、その機能の基本的な側面です。 LangChain 自体は LLM をホストしませんが、さまざまな LLM と対話するための統一インターフェイスを提供します。
このセクションでは、LangChain での OpenAI LLM ラッパーの使用の概要を説明します。これは他の LLM タイプにも適用できます。 これは「はじめに」セクションですでにインストールされています。 LLM を初期化しましょう。
from langchain.llms import OpenAI
llm = OpenAI()
- LLM は、 実行可能なインターフェースの基本的な構成要素です。 LangChain 式言語 (LCEL)。 これは彼らがサポートしていることを意味します
invoke,ainvoke,stream,astream,batch,abatch,astream_log呼び出します。 - LLM は受け入れます ストリング 入力として、または文字列プロンプトに強制できるオブジェクト(以下を含む)
List[BaseMessage]&PromptValue。 (これらについては後で詳しく説明します)
いくつかの例を見てみましょう。
response = llm.invoke("List the seven wonders of the world.")
print(response)

あるいは、stream メソッドを呼び出してテキスト応答をストリーミングすることもできます。
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

チャットモデル
インタラクティブなチャット アプリケーションの作成には、言語モデルの特殊なバリエーションであるチャット モデルと LangChain の統合が不可欠です。 チャット モデルは内部で言語モデルを利用しますが、入出力としてチャット メッセージを中心とした独特のインターフェイスを提供します。 このセクションでは、LangChain での OpenAI のチャット モデルの使用の詳細な概要を説明します。
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
LangChain のチャット モデルは、次のようなさまざまなメッセージ タイプで動作します。 AIMessage, HumanMessage, SystemMessage, FunctionMessage, ChatMessage (任意のロールパラメータを使用)。 一般的に、 HumanMessage, AIMessage, SystemMessage が最も頻繁に使用されます。
チャットモデルは主に受け入れます List[BaseMessage] 入力として。 文字列は次のように変換できます HumanMessage, PromptValue もサポートされています。
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)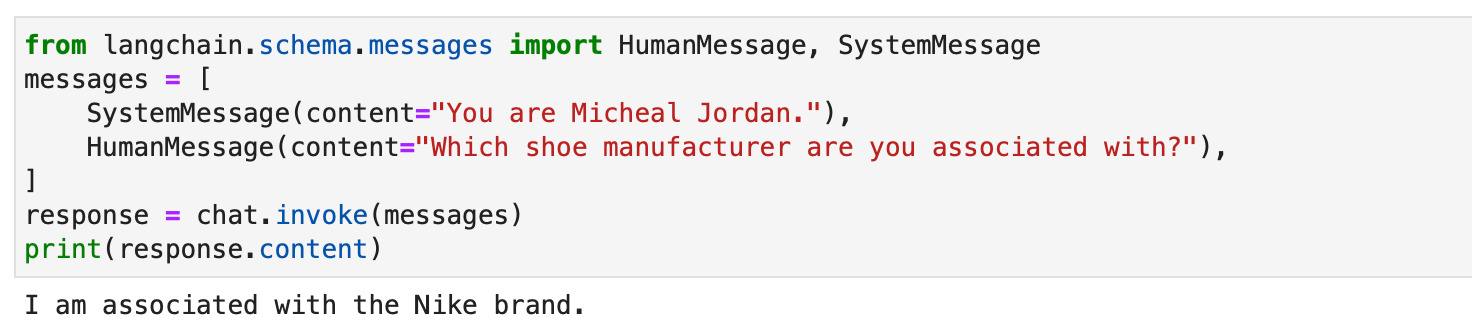
プロンプト
プロンプトは、言語モデルをガイドして関連性のある一貫した出力を生成するために不可欠です。 単純な手順から数ショットの複雑な例まで多岐にわたります。 LangChain では、いくつかの専用のクラスと関数のおかげで、プロンプトの処理は非常に合理化されたプロセスになります。
LangChainの PromptTemplate class は文字列プロンプトを作成するための多用途ツールです。 Python を使用します str.format 構文を使用して、動的なプロンプト生成を可能にします。 プレースホルダーを使用してテンプレートを定義し、必要に応じて特定の値を入力できます。
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)チャット モデルの場合、プロンプトはより構造化されており、特定の役割を持つメッセージが含まれます。 ラングチェーンのオファー ChatPromptTemplate この目的のために。
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
このアプローチにより、動的な応答を備えたインタラクティブで魅力的なチャットボットの作成が可能になります。
両方 PromptTemplate & ChatPromptTemplate LangChain Expression Language (LCEL) とシームレスに統合し、より大規模で複雑なワークフローの一部にできるようにします。 これについては後ほど詳しく説明します。
カスタム プロンプト テンプレートは、独自の書式設定や特定の指示を必要とするタスクに不可欠な場合があります。 カスタム プロンプト テンプレートの作成には、入力変数とカスタム書式設定方法の定義が含まれます。 この柔軟性により、LangChain はアプリケーション固有の幅広い要件に応えることができます。 もっとここを読んでください。
LangChain は少数ショット プロンプトもサポートしており、モデルが例から学習できるようになります。 この機能は、文脈の理解や特定のパターンを必要とするタスクに不可欠です。 少数ショット プロンプト テンプレートは、一連のサンプルから、またはサンプル セレクター オブジェクトを利用して構築できます。 もっとここを読んでください。
出力パーサー
出力パーサーはラングチェーンで重要な役割を果たし、ユーザーが言語モデルによって生成された応答を構造化できるようにします。 このセクションでは、出力パーサーの概念を検討し、Langchain の PydanticOutputParser、SimpleJsonOutputParser、CommaSeparatedListOutputParser、DatetimeOutputParser、および XMLOutputParser を使用したコード例を示します。
PydanticOutputParser
Langchain は、応答を Pydantic データ構造に解析するための PydanticOutputParser を提供します。 以下は、その使用方法の段階的な例です。
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
出力は次のようになります。

SimpleJsonOutputParser
Langchain の SimpleJsonOutputParser は、JSON のような出力を解析する場合に使用されます。 以下に例を示します。
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)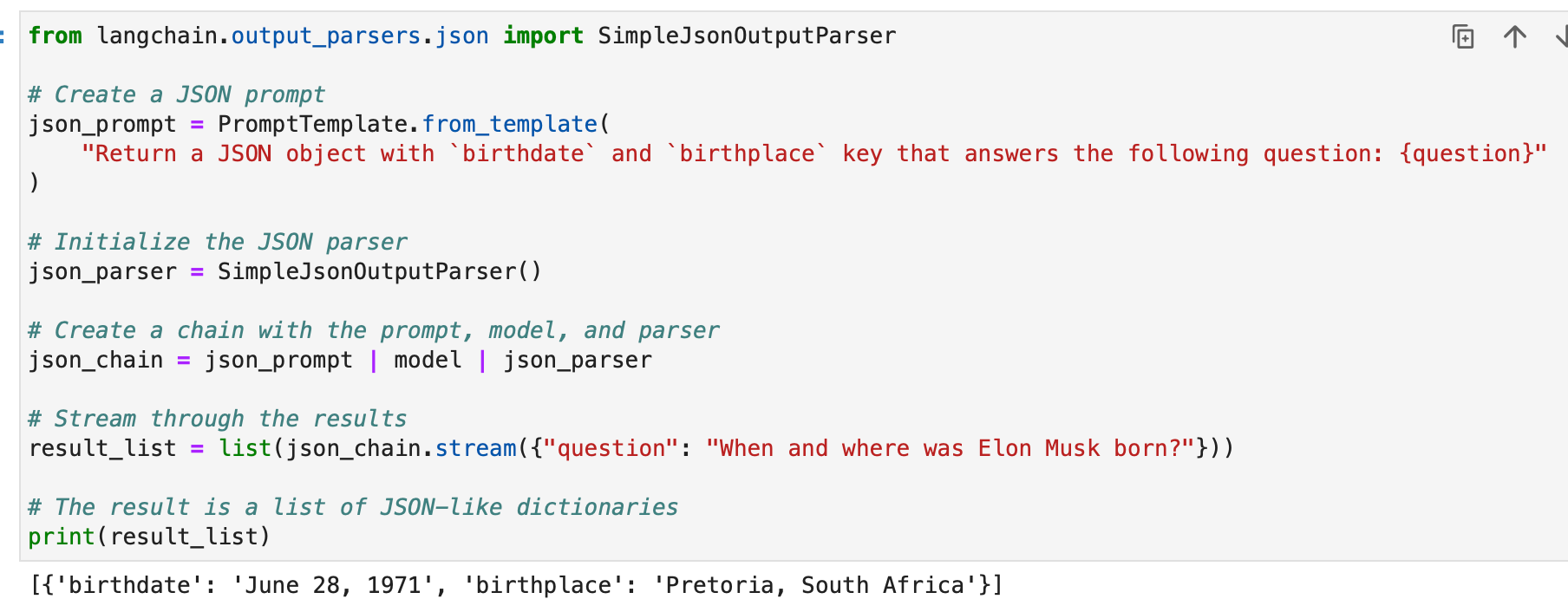
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser は、モデル応答からカンマ区切りのリストを抽出する場合に便利です。 以下に例を示します。
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)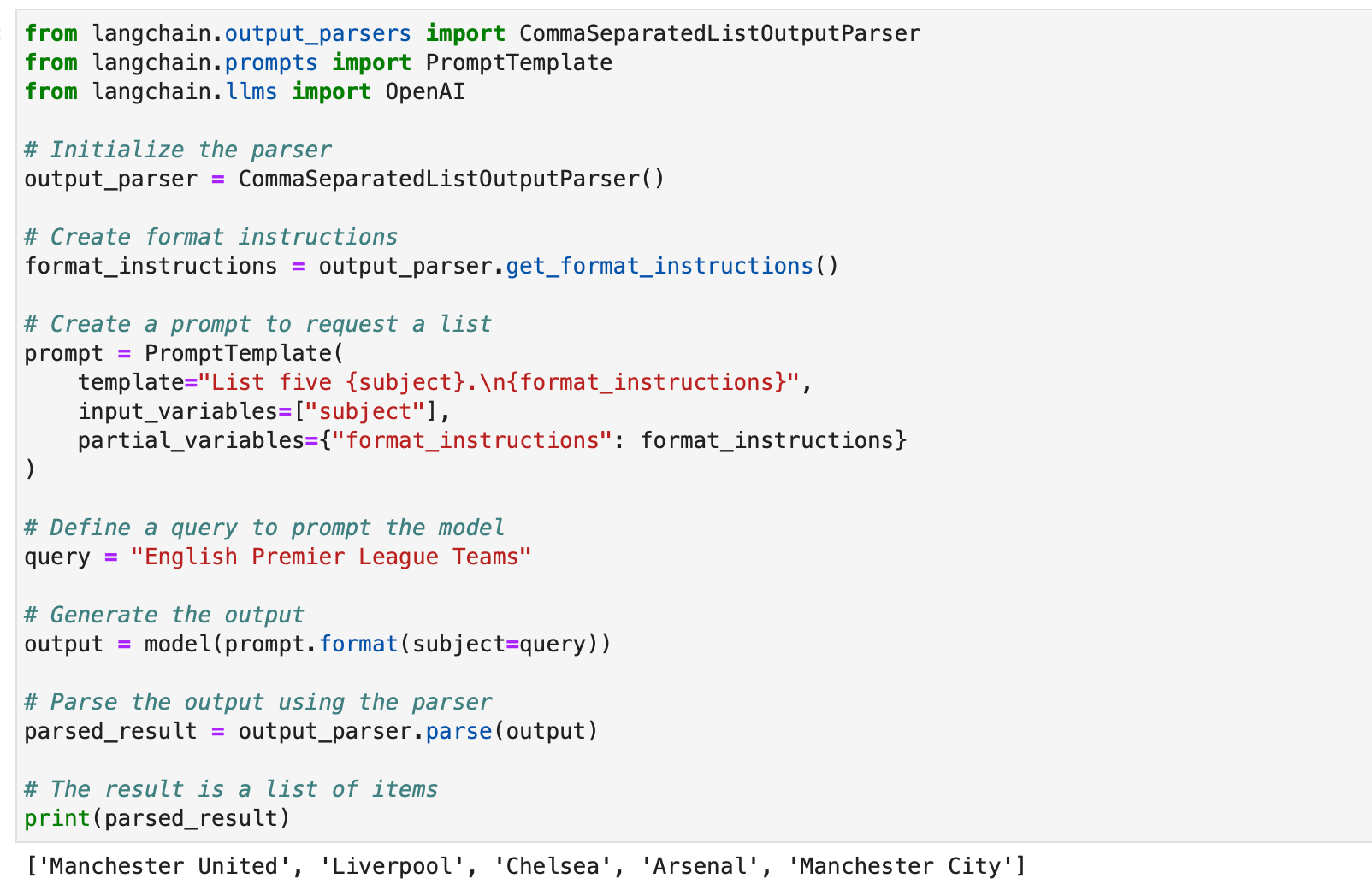
DatetimeOutputParser
Langchain の DatetimeOutputParser は、日時情報を解析するように設計されています。 使用方法は次のとおりです。
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
これらの例は、Langchain の出力パーサーを使用してさまざまなタイプのモデル応答を構造化し、さまざまなアプリケーションや形式に適したものにする方法を示しています。 出力パーサーは、Langchain の言語モデル出力の使いやすさと解釈可能性を向上させるための貴重なツールです。
Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
モジュール II : 検索
LangChain での取得は、モデルのトレーニング セットに含まれていないユーザー固有のデータを必要とするアプリケーションで重要な役割を果たします。 検索拡張生成 (RAG) として知られるこのプロセスには、外部データをフェッチし、それを言語モデルの生成プロセスに統合することが含まれます。 LangChain は、このプロセスを促進するためのツールと機能の包括的なスイートを提供し、単純なアプリケーションと複雑なアプリケーションの両方に対応します。
LangChain は一連のコンポーネントを通じて検索を実現します。これについては XNUMX つずつ説明します。
ドキュメントローダー
LangChain のドキュメント ローダーを使用すると、さまざまなソースからデータを抽出できます。 100 を超えるローダーが利用可能で、さまざまなドキュメント タイプ、アプリ、ソース (プライベート s3 バケット、パブリック Web サイト、データベース) をサポートしています。
要件に基づいてドキュメント ローダーを選択できます こちら.
これらすべてのローダーはデータを取り込みます ドキュメント クラス。 Document クラスに取り込まれたデータの使用方法については、後で学習します。
テキスト ファイル ローダー: シンプルなものをロードする .txt ファイルをドキュメントに変換します。
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
CSVローダー: CSV ファイルをドキュメントにロードします。
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
フィールド名を指定して解析をカスタマイズすることもできます。
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
PDF ローダー: LangChain の PDF ローダーは、PDF ファイルからコンテンツを解析および抽出するためのさまざまな方法を提供します。 各ローダーはさまざまな要件に対応し、さまざまな基礎となるライブラリを使用します。 以下に各ローダーの詳細な例を示します。
PyPDFLoader は、基本的な PDF 解析に使用されます。
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader は、数学的なコンテンツや図を抽出するのに最適です。
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader は高速で、詳細なメタデータ抽出が含まれています。
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Loader は、テキスト抽出をより詳細に制御するために使用されます。
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser は、OCR およびその他の高度な PDF 解析機能に AWS Textract を利用します。
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader は、セマンティック解析のために PDF から HTML を生成します。
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader は詳細なメタデータを提供し、ページごとに XNUMX つのドキュメントをサポートします。
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
統合ローダー: LangChain は、アプリ (Slack、Sigma、Notion、Confluence、Google Drive など) やデータベースからデータを直接ロードし、LLM アプリケーションで使用するためのさまざまなカスタム ローダーを提供します。
完全なリストは次のとおりです こちら.
以下にこれを説明するためのいくつかの例を示します。
例 I – スラック
広く使用されているインスタント メッセージング プラットフォームである Slack は、LLM ワークフローおよびアプリケーションに統合できます。
- Slack ワークスペース管理ページに移動します。
- MFAデバイスに移動する
{your_slack_domain}.slack.com/services/export. - 目的の日付範囲を選択し、エクスポートを開始します。
- エクスポートの準備が完了すると、Slack は電子メールと DM で通知します。
- エクスポートの結果は、
.zipファイルは、ダウンロード フォルダーまたは指定したダウンロード パスにあります。 - ダウンロードしたファイルのパスを割り当てます
.zipファイルへLOCAL_ZIPFILE. -
SlackDirectoryLoaderlangchain.document_loadersパッケージ。
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
例 II – Figma
インターフェイス設計用の人気ツールである Figma は、データ統合用の REST API を提供します。
- URL 形式から Figma ファイル キーを取得します。
https://www.figma.com/file/{filekey}/sampleFilename. - ノードIDはURLパラメータにあります。
?node-id={node_id}. - 次の手順に従ってアクセス トークンを生成します。 Figma ヘルプセンター.
-
FigmaFileLoaderからのクラスlangchain.document_loaders.figmaFigma データをロードするために使用されます。 - などのさまざまな LangChain モジュール
CharacterTextSplitter,ChatOpenAI、等の処理が採用される。
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
-
generate_code関数は、Figma データを使用して HTML/CSS コードを作成します。 - GPT ベースのモデルを使用したテンプレート化された会話が採用されています。
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
-
generate_code関数を実行すると、Figma デザイン入力に基づいて HTML/CSS コードが返されます。
ここで、知識を活用していくつかのドキュメント セットを作成してみましょう。
まず、PDF (BCG 年次持続可能性レポート) を読み込みます。

これには PyPDFLoader を使用します。
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
ここで Airtable からデータを取り込みます。 さまざまな OCR およびデータ抽出モデルに関する情報を含む Airtable があります。
これには、統合ローダーのリストにある AirtableLoader を使用しましょう。
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
それでは、これらのドキュメント クラスの使用方法を学びましょう。
ドキュメントトランスフォーマー
LangChain のドキュメント トランスフォーマーは、前のサブセクションで作成したドキュメントを操作するために設計された重要なツールです。
これらは、長いドキュメントを小さなチャンクに分割、結合、フィルタリングするなどのタスクに使用されます。これらのタスクは、ドキュメントをモデルのコンテキスト ウィンドウに適応させたり、特定のアプリケーションのニーズを満たすために重要です。
そのようなツールの XNUMX つが RecursiveCharacterTextSplitter です。これは、分割に文字リストを使用する多用途のテキスト スプリッターです。 チャンク サイズ、オーバーラップ、開始インデックスなどのパラメーターを使用できます。 Python での使用例を次に示します。
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
もう XNUMX つのツールは CharacterTextSplitter です。これは、指定された文字に基づいてテキストを分割し、チャンク サイズとオーバーラップの制御を含みます。
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter は、セマンティック構造を保持しながら、ヘッダー タグに基づいて HTML コンテンツを分割するように設計されています。
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
HTMLHeaderTextSplitter を Pipelined Splitter などの別のスプリッターと組み合わせることで、より複雑な操作を実現できます。
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain は、Python コード スプリッターや JavaScript コード スプリッターなど、さまざまなプログラミング言語に固有のスプリッターも提供します。
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
トークン制限のある言語モデルに便利な、トークン数に基づいてテキストを分割するには、TokenTextSplitter が使用されます。
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
最後に、LongContextReorder はドキュメントを並べ替えて、長いコンテキストによるモデルのパフォーマンスの低下を防ぎます。
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
これらのツールは、単純なテキストの分割から複雑な並べ替えや言語固有の分割まで、LangChain でドキュメントを変換するさまざまな方法を示します。 より詳細で具体的な使用例については、LangChain のドキュメントと統合セクションを参照してください。
この例では、ローダーによってチャンク化されたドキュメントがすでに作成されており、この部分はすでに処理されています。
テキスト埋め込みモデル
LangChain のテキスト埋め込みモデルは、OpenAI、Cohere、Hugging Face などのさまざまな埋め込みモデル プロバイダーに標準化されたインターフェイスを提供します。 これらのモデルはテキストをベクトル表現に変換し、ベクトル空間でのテキストの類似性による意味検索などの操作を可能にします。
テキスト埋め込みモデルを開始するには、通常、特定のパッケージをインストールし、API キーを設定する必要があります。 これは OpenAI に対してすでに実行済みです
ラングチェーンでは、 embed_documents メソッドは複数のテキストを埋め込むために使用され、ベクトル表現のリストを提供します。 例えば:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
検索クエリなどの単一のテキストを埋め込む場合、 embed_query という方法が使われます。 これは、クエリをドキュメント埋め込みのセットと比較するのに役立ちます。 例えば:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
これらの埋め込みを理解することが重要です。 テキストの各部分はベクトルに変換され、その次元は使用されるモデルによって異なります。 たとえば、OpenAI モデルは通常、1536 次元のベクトルを生成します。 これらの埋め込みは、関連情報を取得するために使用されます。
LangChain の埋め込み機能は OpenAI に限定されず、さまざまなプロバイダーと連携できるように設計されています。 セットアップと使用法はプロバイダーによって若干異なる場合がありますが、ベクトル空間にテキストを埋め込むという中心的な概念は同じです。 高度な構成やさまざまな埋め込みモデル プロバイダーとの統合など、詳細な使用方法については、「統合」セクションの LangChain ドキュメントが貴重なリソースです。
ベクターストア
LangChain のベクター ストアは、テキスト埋め込みの効率的な保存と検索をサポートします。 LangChain は 50 を超えるベクター ストアと統合し、使いやすい標準化されたインターフェイスを提供します。
例: 埋め込みの保存と検索
テキストを埋め込んだ後、次のようなベクター ストアにテキストを保存できます。 Chroma そして類似性検索を実行します。
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
代わりに、FAISS ベクトル ストアを使用してドキュメントのインデックスを作成してみましょう。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

レトリバー
LangChain のレトリバーは、非構造化クエリに応答してドキュメントを返すインターフェイスです。 これらはベクトル ストアよりも汎用的で、保存ではなく検索に重点を置いています。 ベクター ストアはレトリーバーのバックボーンとして使用できますが、他のタイプのレトリーバーも同様に存在します。
クロマレトリーバーをセットアップするには、まず次のコマンドを使用してインストールします。 pip install chromadb。 次に、一連の Python コマンドを使用して、ドキュメントの読み込み、分割、埋め込み、取得を行います。 以下は、クロマ レトリーバーをセットアップするコード例です。
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever は、ユーザー入力クエリに対して複数のクエリを生成し、結果を結合することでプロンプト チューニングを自動化します。 簡単な使用例を次に示します。
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
LangChain のコンテキスト圧縮は、クエリのコンテキストを使用して取得したドキュメントを圧縮し、関連する情報のみが返されるようにします。 これには、コンテンツの削減と関連性の低いドキュメントの除外が含まれます。 次のコード例は、コンテキスト圧縮レトリバーの使用方法を示しています。
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
EnsembleRetriever は、さまざまな検索アルゴリズムを組み合わせて、より優れたパフォーマンスを実現します。 BM25 と FAISS Retriever を組み合わせた例を次のコードに示します。
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
LangChain の MultiVector Retriever を使用すると、ドキュメントごとに複数のベクトルを使用してドキュメントをクエリできます。これは、ドキュメント内のさまざまなセマンティックな側面をキャプチャするのに役立ちます。 複数のベクトルを作成する方法には、より小さなチャンクへの分割、要約、または仮説的な質問の生成が含まれます。 ドキュメントを小さなチャンクに分割するには、次の Python コードを使用できます。
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
より焦点を絞ったコンテンツ表現により検索を向上させるための要約を生成することも、別の方法です。 概要を生成する例を次に示します。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
LLM を使用して各ドキュメントに関連する仮説的な質問を生成することも、別のアプローチです。 これは次のコードで実行できます。
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Parent Document Retriever は、小さなチャンクを保存し、より大きな親ドキュメントを取得することによって、埋め込みの精度とコンテキストの保持の間でバランスをとるもう XNUMX つの取得ツールです。 その実装は次のとおりです。
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
自己クエリ検索リトリーバーは、自然言語入力から構造化クエリを構築し、それを基礎となる VectorStore に適用します。 その実装は次のコードに示されています。
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever は、指定されたクエリに基づいて Web リサーチを実行します。
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
この例では、次のように、ベクトル ストア オブジェクトの一部として既に実装されている標準レトリーバーを使用することもできます。

これで、レトリバーにクエリを実行できるようになりました。 クエリの出力は、クエリに関連するドキュメント オブジェクトになります。 これらは最終的に、後続のセクションで関連する応答を作成するために利用されます。


Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
モジュール III : エージェント
LangChain は、チェーンの概念をまったく新しいレベルに引き上げる「エージェント」と呼ばれる強力な概念を導入しています。 エージェントは言語モデルを活用して、実行するアクションのシーケンスを動的に決定し、信じられないほど多用途で適応性のあるものにします。 アクションがコードにハードコーディングされている従来のチェーンとは異なり、エージェントは言語モデルを推論エンジンとして使用して、どのアクションをどの順序で実行するかを決定します。
エージェント 意思決定を担う中心的なコンポーネントです。 言語モデルとプロンプトの力を利用して、特定の目的を達成するための次のステップを決定します。 エージェントへの入力には通常、次のものが含まれます。
- ツール: 利用可能なツールの説明 (詳細は後ほど)。
- ユーザー入力: ユーザーからの高レベルの目標またはクエリ。
- 中間ステップ: 現在のユーザー入力に到達するまでに実行された (アクション、ツール出力) ペアの履歴。
エージェントの出力は次のようになります。 アクション 行動を起こすこと(エージェントアクション)または決勝 応答 ユーザーに送信する (エージェントフィニッシュ)。 あ アクション を指定します ツール と そのツールのために。
ツール
ツールは、エージェントが世界と対話するために使用できるインターフェイスです。 これにより、エージェントは Web の検索、シェル コマンドの実行、外部 API へのアクセスなどのさまざまなタスクを実行できるようになります。 LangChain では、エージェントの機能を拡張し、エージェントがさまざまなタスクを実行できるようにするためにツールが不可欠です。
LangChain でツールを使用するには、次のスニペットを使用してツールをロードできます。
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
一部のツールでは、初期化に基本言語モデル (LLM) が必要な場合があります。 そのような場合は、LLM も渡すことができます。
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
この設定により、さまざまなツールにアクセスし、それらをエージェントのワークフローに統合できるようになります。 ツールの完全なリストと使用方法のドキュメントは次のとおりです。 こちら.
ツールの例をいくつか見てみましょう。
DuckDuckGo
DuckDuckGo ツールを使用すると、その検索エンジンを使用して Web 検索を実行できます。 使用方法は次のとおりです。
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DataForSeo
DataForSeo ツールキットを使用すると、DataForSeo API を使用して検索エンジンの結果を取得できます。 このツールキットを使用するには、API 認証情報を設定する必要があります。 資格情報を構成する方法は次のとおりです。
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
資格情報を設定したら、 DataForSeoAPIWrapper API にアクセスするためのツール:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
DataForSeoAPIWrapper ツールはさまざまなソースから検索エンジンの結果を取得します。
JSON 応答で返される結果とフィールドのタイプをカスタマイズできます。 たとえば、結果のタイプやフィールドを指定し、返される上位の結果の最大数を設定できます。
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
この例では、結果のタイプ、フィールドを指定し、結果の数を制限することにより、JSON 応答をカスタマイズします。
追加のパラメーターを API ラッパーに渡すことで、検索結果の場所と言語を指定することもできます。
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
場所と言語のパラメーターを指定すると、検索結果を特定の地域と言語に合わせて調整できます。
使用する検索エンジンを柔軟に選択できます。 目的の検索エンジンを指定するだけです。
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
この例では、Bing を検索エンジンとして使用するように検索がカスタマイズされています。
API ラッパーを使用すると、実行する検索の種類を指定することもできます。 たとえば、マップ検索を実行できます。
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
これにより、地図関連の情報を取得するように検索がカスタマイズされます。
シェル(バッシュ)
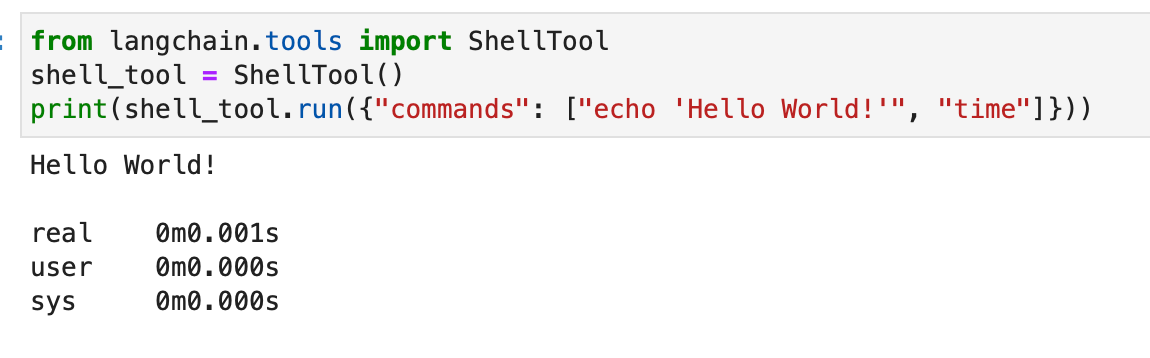
シェル ツールキットは、エージェントにシェル環境へのアクセスを提供し、エージェントがシェル コマンドを実行できるようにします。 この機能は強力ですが、特にサンドボックス環境では注意して使用する必要があります。 シェル ツールの使用方法は次のとおりです。
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
この例では、シェル ツールは XNUMX つのシェル コマンドを実行します。「Hello World!」をエコーします。 そして現在時刻を表示します。
シェル ツールをエージェントに提供して、より複雑なタスクを実行できます。 以下は、エージェントがシェル ツールを使用して Web ページからリンクを取得する例です。
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
このシナリオでは、エージェントはシェル ツールを使用して一連のコマンドを実行し、Web ページから URL を取得、フィルタリング、並べ替えます。
提供されている例は、LangChain で使用できるツールのいくつかを示しています。 これらのツールは最終的にエージェントの機能を拡張し (次のサブセクションで説明します)、エージェントがさまざまなタスクを効率的に実行できるようにします。 要件に応じて、プロジェクトのニーズに最適なツールとツールキットを選択し、エージェントのワークフローに統合できます。
エージェントに戻る
エージェントの話に移りましょう。
AgentExecutor は、エージェントのランタイム環境です。 これは、エージェントを呼び出し、選択したアクションを実行し、アクションの出力をエージェントに返し、エージェントが終了するまでプロセスを繰り返す責任があります。 擬似コードでは、AgentExecutor は次のようになります。
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor は、エージェントが存在しないツールを選択した場合の処理、ツール エラーの処理、エージェント生成の出力の管理、あらゆるレベルでのログ記録と可観測性の提供など、さまざまな複雑さを処理します。
AgentExecutor クラスは LangChain の主要なエージェント ランタイムですが、次のような他のより実験的なランタイムもサポートされています。
- 計画と実行のエージェント
- 赤ちゃんAGI
- 自動 GPT
エージェント フレームワークをより深く理解するために、基本的なエージェントを最初から構築してから、事前に構築されたエージェントの検討に進みましょう。
エージェントの構築に入る前に、いくつかの重要な用語とスキーマを再確認することが重要です。
- エージェントアクション: これは、エージェントが取るべきアクションを表すデータ クラスです。 それは、
toolプロパティ (呼び出すツールの名前) とtool_inputプロパティ (そのツールの入力)。 - エージェント終了: このデータ クラスは、エージェントがタスクを完了し、ユーザーに応答を返す必要があることを示します。 通常、これには戻り値の辞書が含まれており、多くの場合、応答テキストを含むキー「output」が含まれます。
- 中間ステップ: これらは、以前のエージェントのアクションと対応する出力の記録です。 これらは、エージェントの今後の反復にコンテキストを渡すために重要です。
この例では、OpenAI Function Calling を使用してエージェントを作成します。 このアプローチは、エージェントの作成に信頼性があります。 まず、単語の長さを計算する簡単なツールを作成します。 このツールは、言語モデルが単語の長さをカウントする際のトークン化により間違いを犯す可能性があるため便利です。
まず、エージェントの制御に使用する言語モデルをロードしましょう。
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
語長計算を使用してモデルをテストしてみましょう。
llm.invoke("how many letters in the word educa?")
応答では、「educa」という単語の文字数を示す必要があります。
次に、単語の長さを計算する簡単な Python 関数を定義します。
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
という名前のツールを作成しました get_word_length これは単語を入力として受け取り、その長さを返します。
次に、エージェントのプロンプトを作成しましょう。 プロンプトは、出力を推論してフォーマットする方法をエージェントに指示します。 私たちの場合は、最小限の命令を必要とする OpenAI Function Calling を使用しています。 ユーザー入力とエージェントのスクラッチパッド用のプレースホルダーを使用してプロンプトを定義します。
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
では、エージェントはどのツールを使用できるかをどのようにして知るのでしょうか? 私たちは OpenAI 関数呼び出し言語モデルに依存しているため、関数を個別に渡す必要があります。 ツールをエージェントに提供するには、ツールを OpenAI 関数呼び出しとしてフォーマットします。
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
ここで、入力マッピングを定義し、コンポーネントを接続することで、エージェントを作成できます。
これはLCEL言語です。 これについては後で詳しく説明します。
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
ユーザー入力を理解し、利用可能なツールを使用し、出力をフォーマットするエージェントを作成しました。 それでは、それを操作してみましょう:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
エージェントは、次に実行するアクションを示す AgentAction で応答する必要があります。
エージェントを作成しましたが、今度はそのランタイムを作成する必要があります。 最も単純なランタイムは、エージェントを継続的に呼び出し、アクションを実行し、エージェントが終了するまで繰り返すランタイムです。 以下に例を示します。
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
このループでは、エージェントが終了するまで、繰り返しエージェントを呼び出し、アクションを実行し、中間ステップを更新します。 ループ内でのツールの相互作用も処理します。

このプロセスを簡素化するために、LangChain は AgentExecutor クラスを提供します。これはエージェントの実行をカプセル化し、エラー処理、早期停止、トレース、およびその他の改善を提供します。 AgentExecutor を使用してエージェントと対話してみましょう。
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor は実行プロセスを簡素化し、エージェントと対話するための便利な方法を提供します。
記憶については後ほど詳しく説明します。
これまでに作成したエージェントはステートレスです。つまり、以前のインタラクションを記憶していません。 フォローアップの質問や会話を可能にするには、エージェントにメモリを追加する必要があります。 これには次の XNUMX つの手順が含まれます。
- プロンプトにメモリ変数を追加して、チャット履歴を保存します。
- インタラクション中のチャット履歴を追跡します。
プロンプトにメモリ プレースホルダーを追加することから始めましょう。
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
次に、チャット履歴を追跡するリストを作成します。
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
エージェントの作成ステップでは、メモリも含めます。
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
ここで、エージェントを実行するときに、チャット履歴を必ず更新してください。
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
これにより、エージェントは会話履歴を維持し、以前のやり取りに基づいてフォローアップの質問に答えることができます。
おめでとう! LangChain で最初のエンドツーエンド エージェントが正常に作成され、実行されました。 LangChain の機能をさらに詳しく調べるには、次のことを検討できます。
- さまざまなエージェント タイプがサポートされています。
- 事前構築されたエージェント
- ツールとツールの統合を使用する方法。
エージェントの種類
LangChain は、特定のユースケースに適したさまざまなエージェント タイプを提供します。 利用可能なエージェントの一部を次に示します。
- ゼロショット反応: このエージェントは ReAct フレームワークを使用して、その説明のみに基づいてツールを選択します。 ツールごとに説明が必要であり、汎用性が高いです。
- 構造化入力 ReAct: このエージェントは複数の入力ツールを処理し、Web ブラウザーの操作などの複雑なタスクに適しています。 構造化入力にはツールの引数スキーマを使用します。
- OpenAI の機能: このエージェントは、関数呼び出し用に微調整されたモデル向けに特別に設計されており、gpt-3.5-turbo-0613 や gpt-4-0613 などのモデルと互換性があります。 これを使用して、上記の最初のエージェントを作成しました。
- 会話型: 会話設定用に設計されたこのエージェントは、ツールの選択に ReAct を使用し、メモリを利用して以前の対話を記憶します。
- 検索で自問してください: このエージェントは、質問に対する事実に基づく回答を検索する単一のツール「中間回答」に依存しています。 本来のサーチペーパーによる自問に相当します。
- ReAct ドキュメント ストア: このエージェントは、ReAct フレームワークを使用してドキュメント ストアと対話します。 これには「検索」ツールと「ルックアップ」ツールが必要で、元の ReAct 論文の Wikipedia の例と似ています。
これらのエージェント タイプを調べて、LangChain でニーズに最適なものを見つけてください。 これらのエージェントを使用すると、一連のツールをエージェント内にバインドして、アクションを処理し、応答を生成できます。 詳しくはこちら ここのツールを使用して独自のエージェントを構築する方法.
事前構築されたエージェント
LangChain で利用可能な事前構築済みエージェントに焦点を当てて、エージェントの探索を続けましょう。
Gmailの
LangChain は、LangChain メールを Gmail API に接続できる Gmail ツールキットを提供します。 開始するには、認証情報を設定する必要があります。詳細については、Gmail API ドキュメントで説明されています。 ダウンロードしたら、 credentials.json ファイルを作成したら、Gmail API の使用を続行できます。 さらに、次のコマンドを使用して、いくつかの必要なライブラリをインストールする必要があります。
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
Gmail ツールキットは次のように作成できます。
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
ニーズに応じて認証をカスタマイズすることもできます。 バックグラウンドでは、次のメソッドを使用して googleapi リソースが作成されます。
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
ツールキットには、エージェント内で使用できる次のようなさまざまなツールが用意されています。
GmailCreateDraft: 指定されたメッセージフィールドを含む下書き電子メールを作成します。GmailSendMessage: 電子メール メッセージを送信します。GmailSearch: 電子メール メッセージまたはスレッドを検索します。GmailGetMessage: メッセージ ID によって電子メールを取得します。GmailGetThread: 電子メール メッセージを検索します。
エージェント内でこれらのツールを使用するには、次のようにエージェントを初期化します。
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
これらのツールの使用例をいくつか示します。
- 編集用に Gmail の下書きを作成します。
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- 下書きで最新のメールを検索します。
agent.run("Could you search in my drafts for the latest email?")
これらの例は、エージェント内の LangChain の Gmail ツールキットの機能を示し、プログラムで Gmail を操作できるようにします。
SQLデータベースエージェント
このセクションでは、SQL データベース、特に Chinook データベースと対話するように設計されたエージェントの概要を説明します。 このエージェントは、データベースに関する一般的な質問に答え、エラーから回復できます。 まだ開発中であるため、すべての答えが正しいわけではないことに注意してください。 データベース上で DML ステートメントを実行する可能性があるため、機密データに対して実行する場合は注意してください。
このエージェントを使用するには、次のように初期化します。
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
このエージェントは、次のコマンドを使用して初期化できます。 ZERO_SHOT_REACT_DESCRIPTION エージェントタイプ。 質問に答え、説明を提供するように設計されています。 または、次のコマンドを使用してエージェントを初期化することもできます。 OPENAI_FUNCTIONS 以前のクライアントで使用した OpenAI の GPT-3.5-turbo モデルのエージェント タイプ。
免責事項
- クエリ チェーンは、挿入/更新/削除クエリを生成する場合があります。 注意して、必要に応じてカスタム プロンプトを使用するか、書き込み権限のない SQL ユーザーを作成してください。
- 「可能な限り最大のクエリを実行する」などの特定のクエリを実行すると、特に SQL データベースに数百万行が含まれている場合に過負荷がかかる可能性があることに注意してください。
- データ ウェアハウス指向のデータベースは、多くの場合、リソースの使用量を制限するためにユーザー レベルのクォータをサポートします。
「playlisttrack」テーブルなどのテーブルについて説明するようにエージェントに依頼できます。 その方法の例を次に示します。
agent_executor.run("Describe the playlisttrack table")
エージェントは、テーブルのスキーマとサンプル行に関する情報を提供します。
存在しないテーブルについて誤って問い合わせた場合、エージェントは復元して、最もよく一致するテーブルに関する情報を提供できます。 例えば:
agent_executor.run("Describe the playlistsong table")
エージェントは最も近い一致するテーブルを見つけて、それに関する情報を提供します。
データベースに対してクエリを実行するようにエージェントに依頼することもできます。 例えば:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
エージェントはクエリを実行し、総売上高が最も多い国などの結果を提供します。
各プレイリスト内のトラックの合計数を取得するには、次のクエリを使用できます。
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
エージェントは、プレイリスト名と対応する合計トラック数を返します。
エージェントでエラーが発生した場合、エージェントは回復して正確な応答を提供できます。 例えば:
agent_executor.run("Who are the top 3 best selling artists?")
最初のエラーが発生した後でも、エージェントは調整して正しい答えを提供します。この場合、それは最も売れているアーティストのトップ 3 です。
パンダデータフレームエージェント
このセクションでは、質問に答える目的で Pandas DataFrame と対話するように設計されたエージェントを紹介します。 このエージェントは、内部で Python エージェントを利用して、言語モデル (LLM) によって生成された Python コードを実行することに注意してください。 LLM によって生成された悪意のある Python コードによる潜在的な危害を防ぐために、このエージェントを使用する場合は注意してください。
次のように Pandas DataFrame エージェントを初期化できます。
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
エージェントに DataFrame 内の行数を数えるように依頼できます。
agent.run("how many rows are there?")
エージェントがコードを実行します df.shape[0] 「データフレームには 891 行あります」などの答えを入力します。
また、3 人以上の兄弟がいる人の数を調べるなど、特定の条件に基づいて行をフィルターするようにエージェントに依頼することもできます。
agent.run("how many people have more than 3 siblings")
エージェントがコードを実行します df[df['SibSp'] > 3].shape[0] 「30 人には 3 人以上の兄弟がいる」などの答えを入力します。
平均年齢の平方根を計算したい場合は、エージェントに次のように尋ねることができます。
agent.run("whats the square root of the average age?")
エージェントは以下を使用して平均年齢を計算します。 df['Age'].mean() 次に、次を使用して平方根を計算します。 math.sqrt()。 「平均年齢の平方根は 5.449689683556195 です。」などの答えが表示されます。
DataFrame のコピーを作成しましょう。欠落している年齢値は平均年齢で埋められます。
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
次に、両方の DataFrame でエージェントを初期化し、質問することができます。
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
エージェントは両方の DataFrame の年齢列を比較し、「年齢列の 177 行が異なります」などの答えを提供します。
Jira ツールキット
このセクションでは、エージェントが Jira インスタンスと対話できるようにする Jira ツールキットの使用方法について説明します。 このツールキットを使用して、問題の検索や問題の作成などのさまざまなアクションを実行できます。 atlassian-python-api ライブラリを利用します。 このツールキットを使用するには、JIRA_API_TOKEN、JIRA_USERNAME、JIRA_INSTANCE_URL などの Jira インスタンスの環境変数を設定する必要があります。 さらに、OpenAI API キーを環境変数として設定する必要がある場合があります。
まず、atlassian-python-api ライブラリをインストールし、必要な環境変数を設定します。
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
エージェントに、概要と説明を含む新しい問題を特定のプロジェクトに作成するように指示できます。
agent.run("make a new issue in project PW to remind me to make more fried rice")
エージェントは、問題を作成するために必要なアクションを実行し、「プロジェクト PW に、概要『もっとチャーハンを作る』と説明『もっとチャーハンを作るようリマインダー』を含む新しい問題が作成されました。」などの応答を提供します。
これにより、自然言語命令と Jira ツールキットを使用して Jira インスタンスと対話できるようになります。
Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
モジュール IV: チェーン
LangChain は、複雑なアプリケーションで大規模言語モデル (LLM) を利用するために設計されたツールです。 LLM や他のタイプのコンポーネントを含むコンポーネントのチェーンを作成するためのフレームワークを提供します。 XNUMX つの主要なフレームワーク
- LangChain 式言語 (LCEL)
- レガシーチェーンインターフェース
LangChain Expression Language (LCEL) は、チェーンを直感的に構成できる構文です。 ストリーミング、非同期呼び出し、バッチ処理、並列化、再試行、フォールバック、トレースなどの高度な機能をサポートします。 たとえば、次のコードに示すように、LCEL でプロンプト、モデル、出力パーサーを作成できます。
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)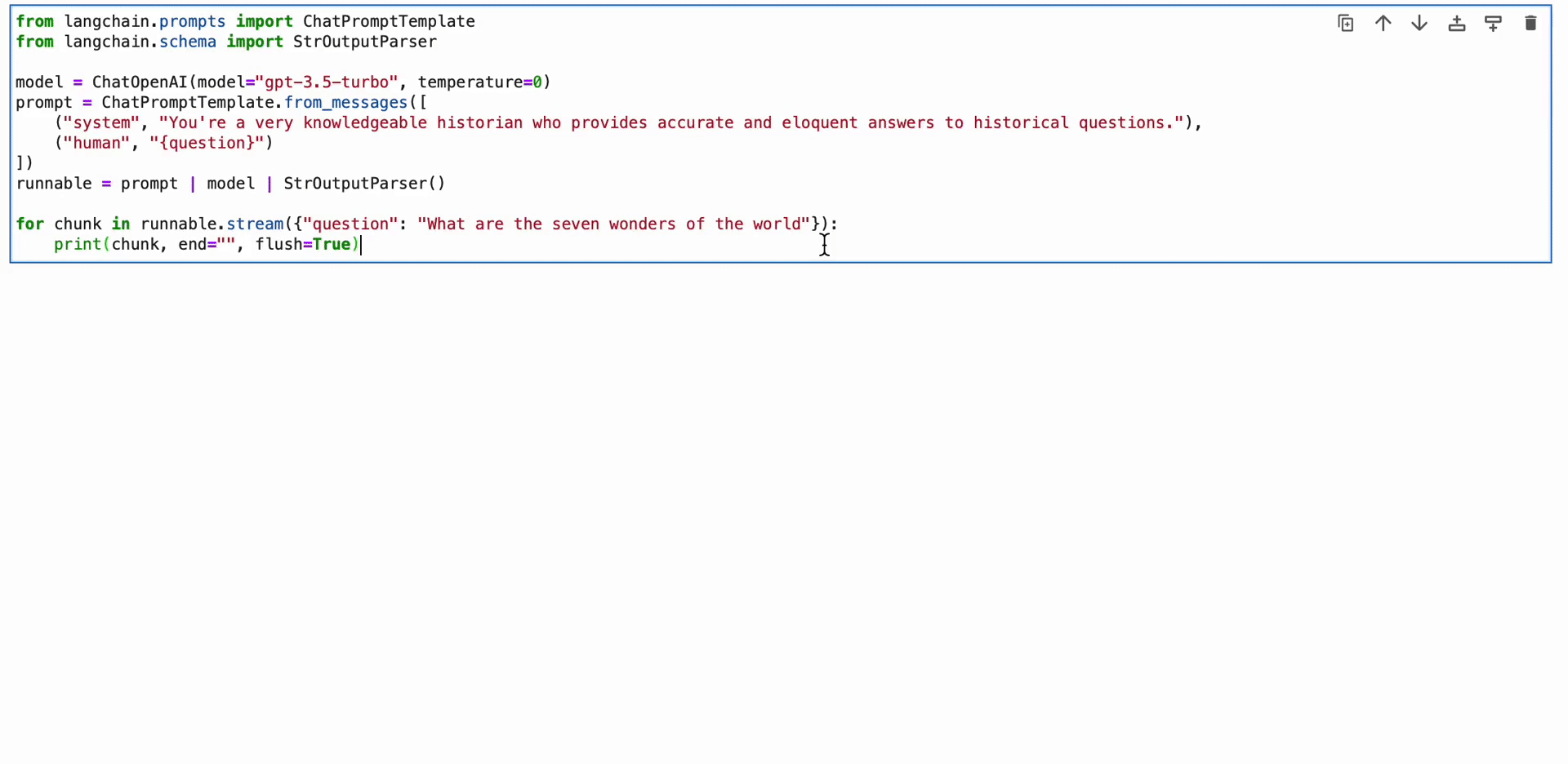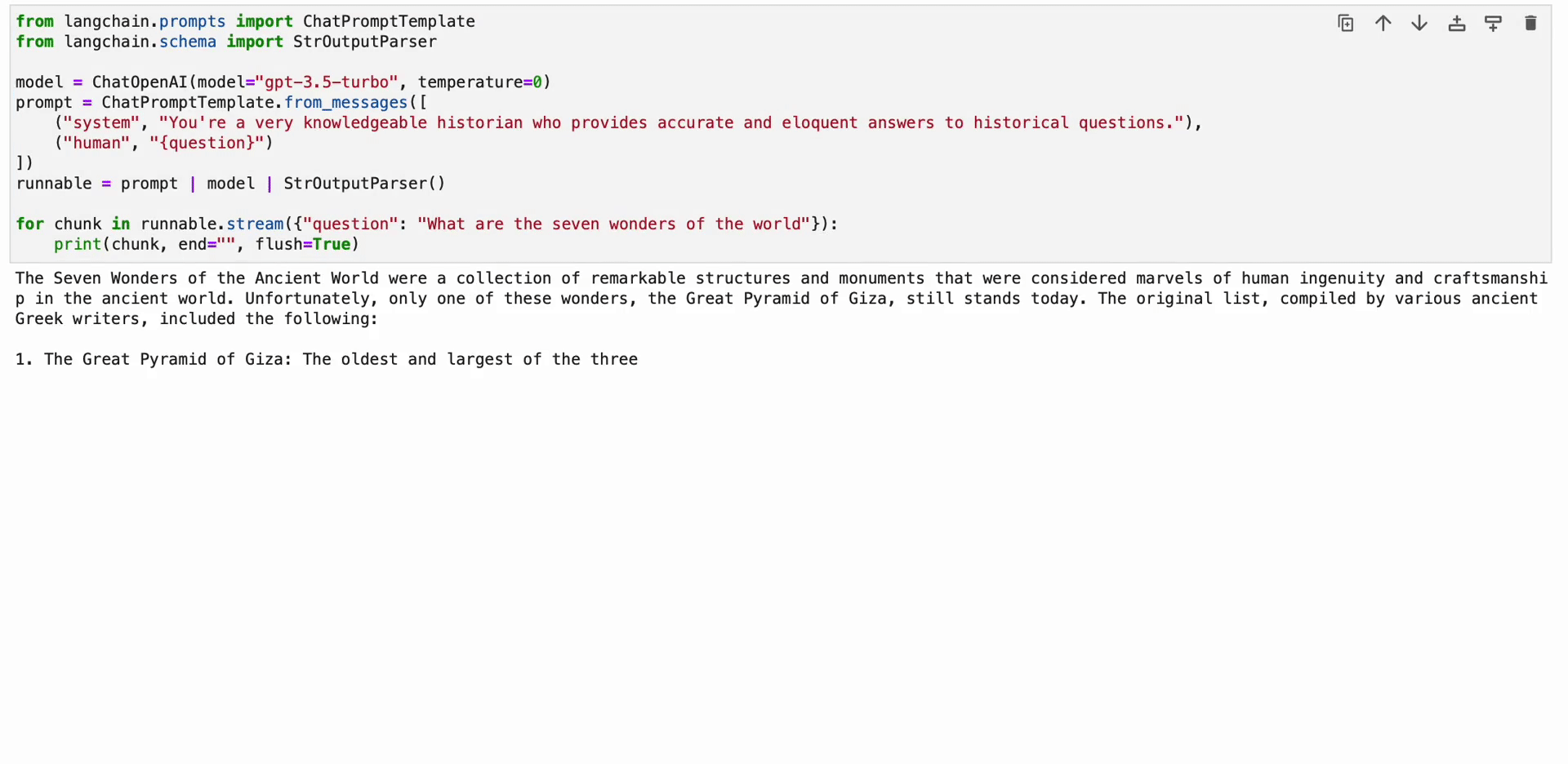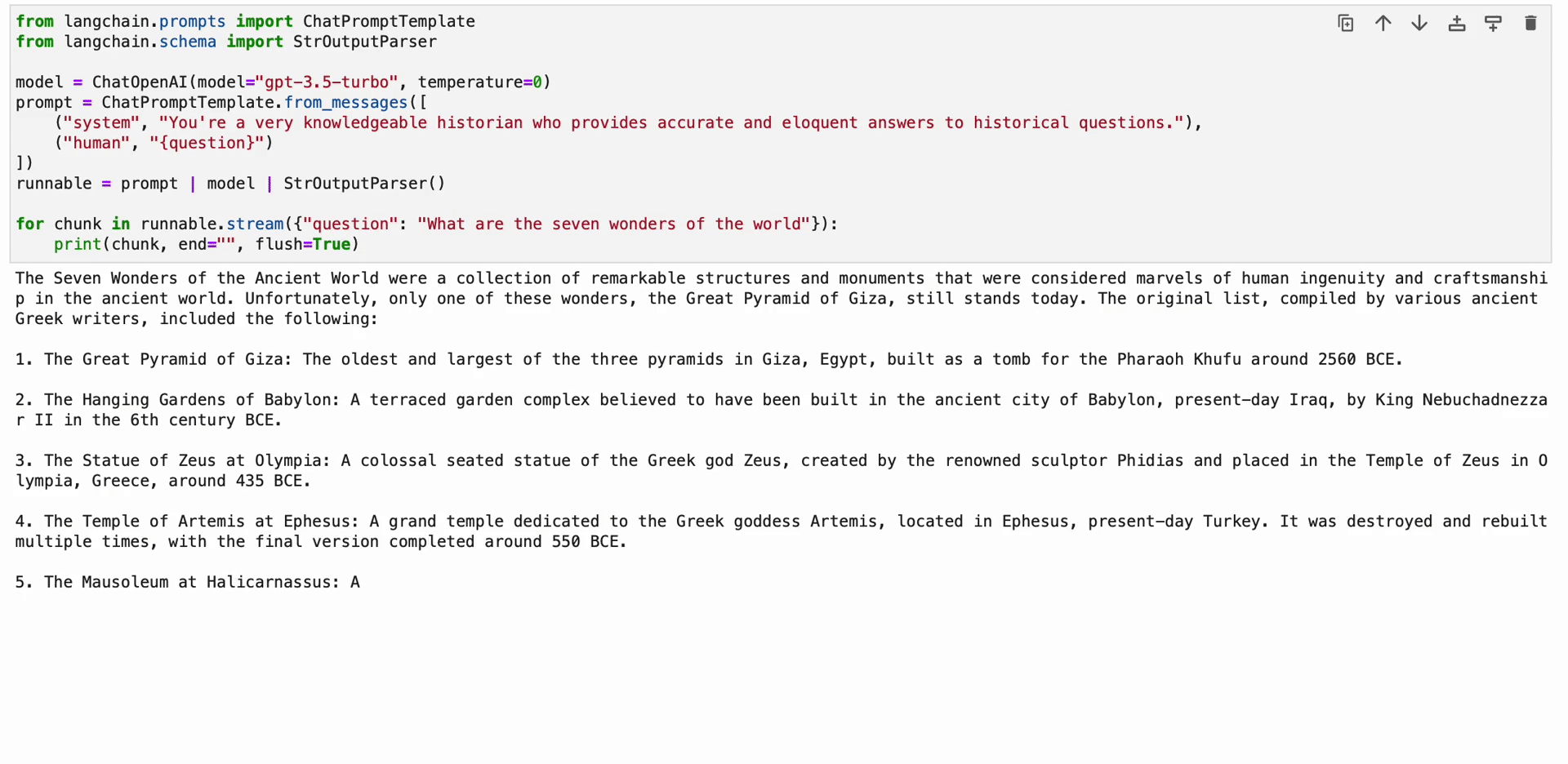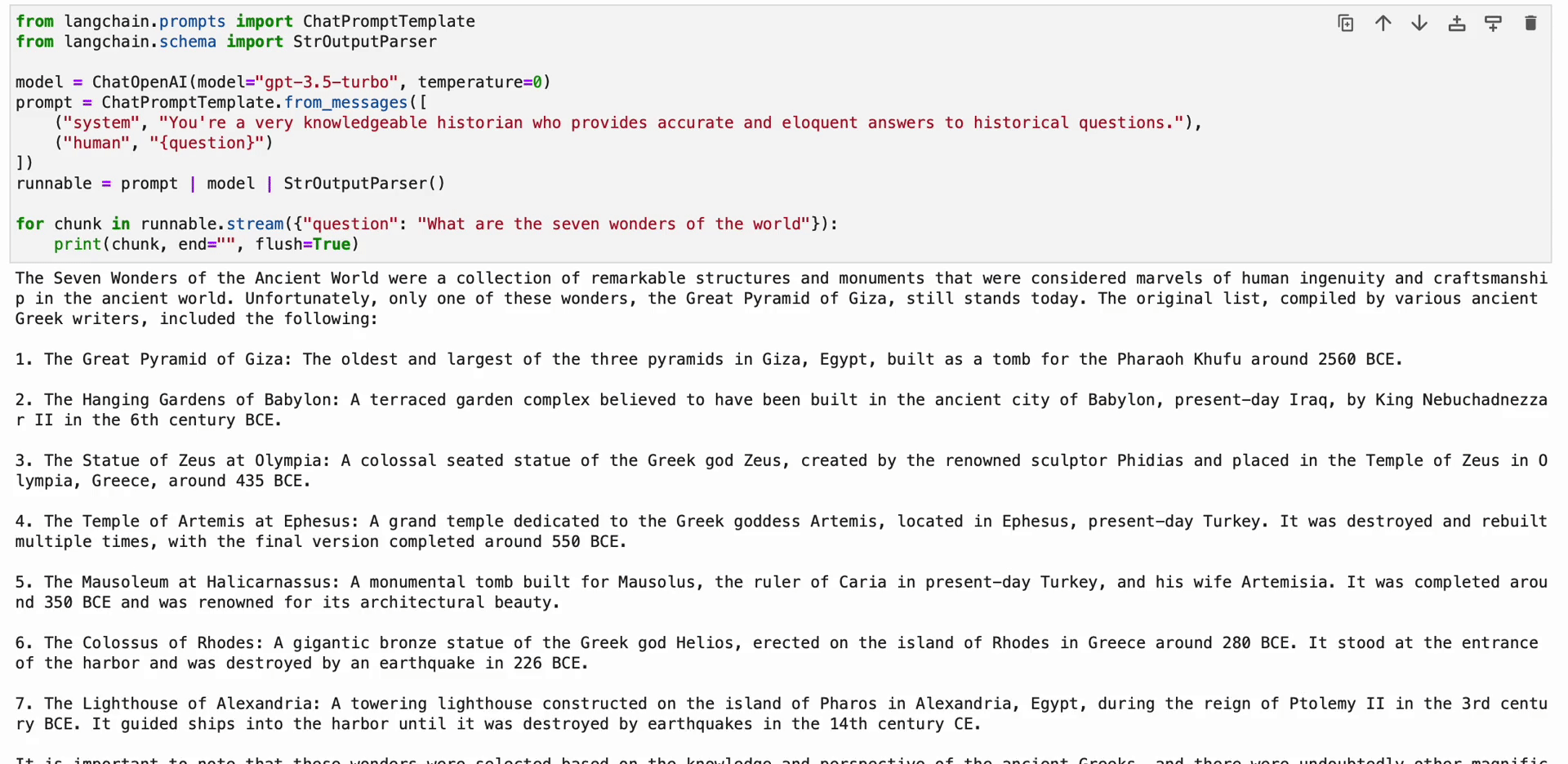
あるいは、LLMChain は、コンポーネントを構成するための LCEL に似たオプションです。 LLMChain の例は次のとおりです。
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
LangChain のチェーンは、Memory オブジェクトを組み込むことでステートフルにすることもできます。 これにより、次の例に示すように、呼び出し間でのデータの永続化が可能になります。
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain は、OpenAI の関数呼び出し API との統合もサポートしています。これは、構造化された出力を取得したり、チェーン内で関数を実行したりするのに役立ちます。 構造化された出力を取得するには、以下に示すように、Pydantic クラスまたは JsonSchema を使用して出力を指定できます。
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
構造化出力の場合、LLMChain を使用した従来のアプローチも利用できます。
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")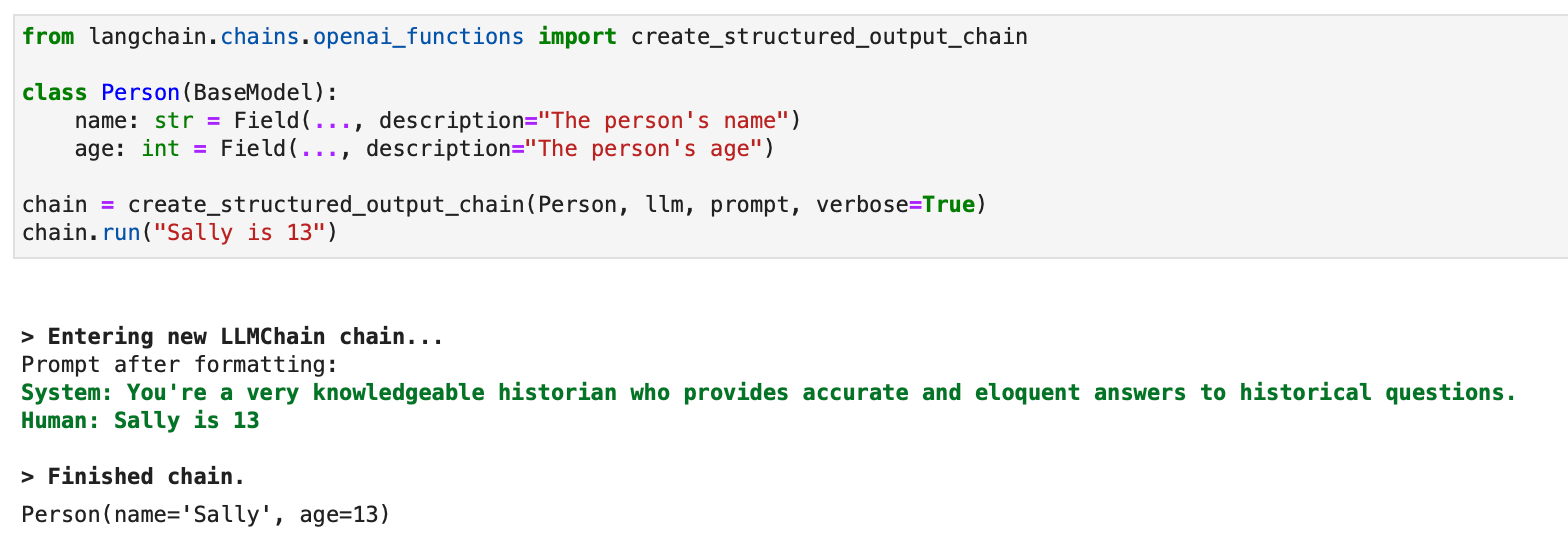
LangChain は OpenAI の機能を活用して、さまざまな目的に応じたさまざまな特定のチェーンを作成します。 これらには、抽出、タグ付け、OpenAPI、および引用を伴う QA のためのチェーンが含まれます。
抽出のコンテキストでは、このプロセスは構造化された出力チェーンと似ていますが、情報またはエンティティの抽出に焦点を当てています。 タグ付けの考え方は、感情、言語、スタイル、取り上げられたトピック、政治的傾向などのクラスでドキュメントにラベルを付けることです。
LangChain でのタグ付けの仕組みの例は、Python コードを使用してデモンストレーションできます。 このプロセスは、必要なパッケージをインストールし、環境をセットアップすることから始まります。
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
タグ付けのスキーマが定義され、プロパティとその予期されるタイプが指定されます。
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
さまざまな入力を使用してタグ付けチェーンを実行する例は、感情、言語、攻撃性を解釈するモデルの能力を示しています。
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
より細かく制御するために、可能な値、説明、必要なプロパティなどを含めて、スキーマをより具体的に定義できます。 この拡張されたコントロールの例を以下に示します。
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Pydantic スキーマはタグ付け基準の定義にも使用でき、必要なプロパティと型を指定するための Python 的な方法を提供します。
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
さらに、LangChain のメタデータ タガー ドキュメント トランスフォーマーを使用して、LangChain ドキュメントからメタデータを抽出することができ、タグ付けチェーンと同様の機能を提供しますが、LangChain ドキュメントに適用されます。
検索ソースの引用は LangChain のもう XNUMX つの機能で、OpenAI 関数を使用してテキストから引用を抽出します。 これは次のコードで示されています。
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
LangChain では、Large Language Model (LLM) アプリケーションでのチェーン化には、通常、プロンプト テンプレートと LLM、およびオプションで出力パーサーを組み合わせることが含まれます。 これを行うために推奨される方法は、LangChain Expression Language (LCEL) を使用することですが、従来の LLMChain アプローチもサポートされています。
LCEL を使用すると、BasePromptTemplate、BaseLanguageModel、および BaseOutputParser はすべて Runnable インターフェイスを実装し、相互に簡単にパイプできます。 これを示す例を次に示します。
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
LangChain のルーティングを使用すると、前のステップの出力が次のステップを決定する非決定的なチェーンを作成できます。 これは、LLM との対話の構造化と一貫性の維持に役立ちます。 たとえば、さまざまなタイプの質問に最適化された XNUMX つのテンプレートがある場合、ユーザーの入力に基づいてテンプレートを選択できます。
RunnableBranch を備えた LCEL を使用してこれを実現する方法を次に示します。RunnableBranch は、(条件、実行可能) ペアのリストとデフォルトの実行可能ファイルで初期化されます。
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
次に、トピック分類子、プロンプト ブランチ、出力パーサーなどのさまざまなコンポーネントを使用して最終チェーンが構築され、入力のトピックに基づいてフローが決定されます。
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
このアプローチは、複雑なクエリを処理し、入力に基づいてクエリを適切にルーティングするという LangChain の柔軟性と能力を実証しています。
言語モデルの領域では、ある呼び出しの出力を次の呼び出しの入力として使用して、最初の呼び出しを一連の後続の呼び出しでフォローアップするのが一般的です。 この逐次的なアプローチは、以前の対話で生成された情報に基づいて構築したい場合に特に有益です。 これらのシーケンスを作成するには LangChain Expression Language (LCEL) が推奨される方法ですが、下位互換性のために SequentialChain メソッドも文書化されています。
これを説明するために、最初に劇の概要を生成し、次にその概要に基づいてレビューを生成するシナリオを考えてみましょう。 Python の使用 langchain.prompts、XNUMXつ作成します PromptTemplate 例: XNUMX つは概要用、もう XNUMX つはレビュー用です。 これらのテンプレートを設定するコードは次のとおりです。
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
LCEL アプローチでは、これらのプロンプトを次のように連鎖させます。 ChatOpenAI & StrOutputParser 最初に概要を生成し、次にレビューを生成するシーケンスを作成します。 コードスニペットは次のとおりです。
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
あらすじとレビューの両方が必要な場合は、次を使用できます。 RunnablePassthrough それぞれに個別のチェーンを作成し、それらを結合するには:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
より複雑なシーケンスを含むシナリオの場合、 SequentialChain という方法が登場します。 これにより、複数の入力と出力が可能になります。 劇のタイトルと時代に基づいたあらすじが必要な場合を考えてみましょう。 設定方法は次のとおりです。
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
チェーン全体またはチェーンの後半部分のコンテキストを維持したいシナリオでは、 SimpleMemory に使える。 これは、複雑な入出力関係を管理する場合に特に役立ちます。 たとえば、演劇のタイトル、時代、あらすじ、レビューに基づいてソーシャル メディアの投稿を生成したいシナリオでは、 SimpleMemory これらの変数の管理に役立ちます。
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
順次チェーンに加えて、ドキュメントを操作するための特殊なチェーンもあります。 これらのチェーンはそれぞれ、文書の結合から、反復的な文書分析に基づく回答の絞り込み、要約のための文書コンテンツのマッピングおよび削減、スコア付けされた回答に基づく再ランキングまで、さまざまな目的を果たします。 これらのチェーンは、柔軟性とカスタマイズ性を高めるために LCEL で再作成できます。
-
StuffDocumentsChainドキュメントのリストを XNUMX つのプロンプトに結合し、LLM に渡します。 -
RefineDocumentsChainドキュメントごとに答えを繰り返し更新します。これは、ドキュメントがモデルのコンテキスト容量を超えるタスクに適しています。 -
MapReduceDocumentsChain各ドキュメントにチェーンを個別に適用し、結果を結合します。 -
MapRerankDocumentsChainドキュメントベースの各回答にスコアを付け、最もスコアの高い回答を選択します。
以下に、セットアップ方法の例を示します。 MapReduceDocumentsChain LCEL を使用して:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
この構成により、LCEL とその基礎となる言語モデルの強みを活用して、文書コンテンツの詳細かつ包括的な分析が可能になります。
Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
モジュール V : メモリ
LangChain では、メモリは会話型インターフェイスの基本的な側面であり、システムが過去の対話を参照できるようになります。 これは、読み取りと書き込みという XNUMX つの主要なアクションによる情報の保存とクエリによって実現されます。 メモリ システムは実行中にチェーンと XNUMX 回対話し、ユーザー入力を強化し、将来の参照のために入力と出力を保存します。
システムにメモリを組み込む
- チャットメッセージの保存: LangChain メモリ モジュールは、メモリ内のリストからデータベースに至るまで、チャット メッセージを保存するためのさまざまな方法を統合します。 これにより、将来の参照のためにすべてのチャットのやり取りが確実に記録されます。
- チャット メッセージのクエリ: LangChain は、チャット メッセージを保存するだけでなく、データ構造とアルゴリズムを採用して、これらのメッセージの有用なビューを作成します。 単純なメモリ システムは最近のメッセージを返す可能性がありますが、より高度なシステムでは過去のインタラクションを要約したり、現在のインタラクションで言及されているエンティティに焦点を当てたりすることができます。
LangChain でのメモリの使用を実証するには、次のことを考慮してください。 ConversationBufferMemory クラス。チャット メッセージをバッファに保存する単純なメモリ フォームです。 以下に例を示します。
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
メモリをチェーンに統合する場合、メモリから返される変数と、それらがチェーン内でどのように使用されるかを理解することが重要です。 たとえば、 load_memory_variables このメソッドは、メモリから読み取られた変数をチェーンの期待に合わせて調整するのに役立ちます。
LangChain を使用したエンドツーエンドの例
使用を検討する ConversationBufferMemory で LLMChain。 このチェーンは、適切なプロンプト テンプレートおよびメモリと組み合わされて、シームレスな会話エクスペリエンスを提供します。 簡略化した例を次に示します。
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
この例は、LangChain のメモリ システムがそのチェーンとどのように統合され、一貫性のあるコンテキストを意識した会話エクスペリエンスを提供するかを示しています。
ラングチェーンのメモリの種類
Langchain は、AI モデルとの対話を強化するために利用できるさまざまなメモリ タイプを提供します。 各メモリ タイプには独自のパラメータと戻り値の型があり、さまざまなシナリオに適しています。 コード例とともに、Langchain で使用できるメモリ タイプのいくつかを見てみましょう。
1. 会話バッファメモリ
このメモリ タイプを使用すると、会話からメッセージを保存したり抽出したりできます。 履歴は文字列またはメッセージのリストとして抽出できます。
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
会話バッファ メモリをチェーンで使用して、チャットのような対話を行うこともできます。
2. 会話バッファウィンドウメモリ
このメモリ タイプは、最近のインタラクションのリストを保持し、最後の K 個のインタラクションを使用して、バッファが大きくなりすぎるのを防ぎます。
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
会話バッファ メモリと同様に、このメモリ タイプをチェーンで使用してチャットのような対話を行うこともできます。
3. 会話エンティティの記憶
このメモリ タイプは、会話内の特定のエンティティに関する事実を記憶し、LLM を使用して情報を抽出します。
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. 会話知識グラフメモリ
このタイプのメモリは、ナレッジ グラフを使用してメモリを再作成します。 メッセージから現在のエンティティとナレッジ トリプレットを抽出できます。
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
このメモリ タイプをチェーンで使用して、会話ベースの知識を取得することもできます。
5. 会話サマリーメモリ
この記憶タイプは、長期にわたる会話の概要を作成し、長い会話からの情報を要約するのに役立ちます。
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. 会話サマリーバッファメモリ
このメモリ タイプは、会話の概要とバッファを組み合わせて、最近のやり取りと概要の間のバランスを維持します。 トークンの長さを使用して、インタラクションをいつフラッシュするかを決定します。
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
これらのメモリ タイプを使用して、Langchain の AI モデルとの対話を強化できます。 各メモリの種類は特定の目的を果たし、要件に基づいて選択できます。
7. 会話トークンバッファメモリ
ConversationTokenBufferMemory は、最近の対話のバッファをメモリ内に保持する別のメモリ タイプです。 インタラクションの数に焦点を当てた以前のメモリ タイプとは異なり、このメモリ タイプはトークンの長さを使用して、インタラクションをいつフラッシュするかを決定します。
LLM でのメモリの使用:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
この例では、インタラクションの数ではなくトークンの長さに基づいてインタラクションを制限するようにメモリが設定されています。
このメモリ タイプを使用すると、履歴をメッセージのリストとして取得することもできます。
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
チェーンで使用する場合:
ConversationTokenBufferMemory をチェーン内で使用して、AI モデルとの対話を強化できます。
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
この例では、ConversationTokenBufferMemory が ConversationChain で使用され、会話を管理し、トークンの長さに基づいて対話を制限します。
8.VectorStoreRetrieverMemory
VectorStoreRetrieverMemory はメモリをベクター ストアに保存し、呼び出されるたびに上位 K 個の最も「顕著な」ドキュメントをクエリします。 このメモリ タイプは、インタラクションの順序を明示的に追跡しませんが、ベクトル検索を使用して関連するメモリをフェッチします。
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
この例では、VectorStoreRetrieverMemory を使用して、ベクトル検索に基づいて会話から関連情報を保存および取得します。
前の例で示したように、会話ベースのナレッジ取得のためにチェーン内で VectorStoreRetrieverMemory を使用することもできます。
Langchain のこれらのさまざまなメモリ タイプは、会話から情報を管理および取得するためのさまざまな方法を提供し、ユーザーのクエリとコンテキストを理解して応答する AI モデルの機能を強化します。 各メモリのタイプは、アプリケーションの特定の要件に基づいて選択できます。
次に、LLMChain でメモリを使用する方法を学びます。 LLMChain のメモリにより、モデルは以前のインタラクションとコンテキストを記憶し、より一貫性のあるコンテキスト認識型の応答を提供できるようになります。
LLMChain にメモリを設定するには、ConversationBufferMemory などのメモリ クラスを作成する必要があります。 設定方法は次のとおりです。
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
この例では、ConversationBufferMemory を使用して会話履歴を保存します。 の memory_key パラメータは、会話履歴を保存するために使用されるキーを指定します。
補完形式のモデルではなくチャット モデルを使用している場合は、プロンプトを別の方法で構成して、メモリをより有効に活用できます。 以下は、メモリを使用してチャット モデル ベースの LLMChain をセットアップする方法の例です。
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
この例では、ChatPromptTemplate を使用してプロンプトを構築し、ConversationBufferMemory を使用して会話履歴を保存および取得します。 このアプローチは、コンテキストと履歴が重要な役割を果たすチャット スタイルの会話に特に役立ちます。
質問/回答チェーンなど、複数の入力を含むチェーンにメモリを追加することもできます。 以下は、質問/回答チェーンでメモリを設定する方法の例です。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
この例では、小さなチャンクに分割された文書を使用して質問に回答します。 ConversationBufferMemory は会話履歴の保存と取得に使用され、モデルがコンテキストを認識した回答を提供できるようにします。
エージェントにメモリを追加すると、エージェントは以前の対話を記憶して使用して質問に答え、コンテキストを認識した応答を提供できるようになります。 エージェントでメモリを設定する方法は次のとおりです。
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
この例では、エージェントにメモリが追加され、エージェントが以前の会話履歴を記憶し、コンテキストを認識した回答を提供できるようになります。 これにより、エージェントはメモリに保存された情報に基づいてフォローアップの質問に正確に答えることができます。
LangChain 式言語
自然言語処理と機械学習の世界では、複雑な一連の操作を構成するのは困難な作業となることがあります。 幸いなことに、LangChain Expression Language (LCEL) が役に立ち、高度な言語処理パイプラインを構築およびデプロイするための宣言的かつ効率的な方法を提供します。 LCEL はチェーンを構成するプロセスを簡素化するように設計されており、プロトタイピングから生産まで簡単に移行できるようになります。 このブログでは、LCEL とは何か、LCEL を使用する理由について、その機能を説明する実際のコード例とともに説明します。
LCEL (LangChain Expression Language) は、言語処理チェーンを構成するための強力なツールです。 これは、大規模なコード変更を必要とせずに、プロトタイピングから実稼働へのシームレスな移行をサポートすることを目的として構築されました。 単純な「プロンプト + LLM」チェーンを構築している場合でも、数百のステップを含む複雑なパイプラインを構築している場合でも、LCEL が対応します。
言語処理プロジェクトで LCEL を使用する理由は次のとおりです。
- 高速トークン ストリーミング: LCEL は、言語モデルから出力パーサーにリアルタイムでトークンを配信し、応答性と効率を向上させます。
- 汎用性の高い API: LCEL は、プロトタイピングと本番環境での使用のために同期 API と非同期 API の両方をサポートし、複数のリクエストを効率的に処理します。
- 自動並列化: LCEL は可能な場合は並列実行を最適化し、同期インターフェイスと非同期インターフェイスの両方で遅延を削減します。
- 信頼性の高い構成: 開発中のストリーミング サポートにより、大規模なチェーンの信頼性を強化するために再試行とフォールバックを構成します。
- 中間結果のストリーム: ユーザーの更新またはデバッグの目的で、処理中に中間結果にアクセスします。
- スキーマの生成: LCEL は、入力と出力の検証のために Pydantic スキーマと JSONSchema スキーマを生成します。
- 包括的なトレース: LangSmith は、可観測性とデバッグのために、複雑なチェーン内のすべてのステップを自動的にトレースします。
- 簡単な導入: LangServe を使用して、LCEL で作成したチェーンを簡単に導入します。
ここで、LCEL の能力を示す実践的なコード例を見てみましょう。 LCEL が威力を発揮する一般的なタスクとシナリオについて説明します。
プロンプト + LLM
最も基本的な構成には、プロンプトと言語モデルを組み合わせて、ユーザー入力を受け取り、それをプロンプトに追加し、それをモデルに渡し、生のモデル出力を返すチェーンを作成することが含まれます。 以下に例を示します。
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
この例では、チェーンによってクマに関するジョークが生成されます。
チェーンに停止シーケンスを付加して、テキストの処理方法を制御できます。 例えば:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
この設定では、改行文字が見つかったときにテキスト生成を停止します。
LCEL は、チェーンへの関数呼び出し情報の添付をサポートしています。 以下に例を示します。
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
この例では、関数呼び出し情報を添付してジョークを生成します。
プロンプト + LLM + 出力パーサー
出力パーサーを追加して、生のモデル出力をより実行可能な形式に変換できます。 その方法は次のとおりです。
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
出力は文字列形式になり、下流のタスクにとってより便利になりました。
返す関数を指定する場合、LCEL を使用して直接解析できます。 例えば:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
この例では、「joke」関数の出力を直接解析します。
これらは、LCEL が複雑な言語処理タスクを簡素化する方法のほんの数例です。 チャットボットの構築、コンテンツの生成、複雑なテキスト変換の実行のいずれの場合でも、LCEL を使用するとワークフローを合理化し、コードをより保守しやすくできます。
RAG (検索拡張生成)
LCEL を使用すると、検索と言語生成のステップを組み合わせた検索拡張生成チェーンを作成できます。 以下に例を示します。
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
この例では、チェーンはコンテキストから関連情報を取得し、質問に対する応答を生成します。
会話型検索チェーン
会話履歴をチェーンに簡単に追加できます。 会話型検索チェーンの例を次に示します。
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
この例では、チェーンは会話のコンテキスト内でフォローアップの質問を処理します。
メモリとソースドキュメントの返却あり
LCEL は、メモリとソース ドキュメントの返却もサポートしています。 メモリをチェーンで使用する方法は次のとおりです。
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
この例では、会話履歴とソース ドキュメントの保存と取得にメモリが使用されます。
複数のチェーン
Runnables を使用して複数のチェーンを連結できます。 以下に例を示します。
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
この例では、XNUMX つのチェーンが結合されて、指定された言語で都市とその国に関する情報が生成されます。
分岐とマージ
LCEL では、RunnableMaps を使用してチェーンを分割および結合できます。 分岐とマージの例を次に示します。
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
この例では、分岐および結合チェーンを使用して引数を生成し、最終応答を生成する前にその長所と短所を評価します。
LCEL を使用した Python コードの作成
LangChain Expression Language (LCEL) の強力なアプリケーションの XNUMX つは、ユーザーの問題を解決するための Python コードを作成することです。 以下は、LCEL を使用して Python コードを作成する方法の例です。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
この例では、ユーザーが入力を提供し、LCEL が問題を解決するための Python コードを生成します。 次に、Python REPL を使用してコードが実行され、結果の Python コードが Markdown 形式で返されます。
Python REPL を使用すると任意のコードが実行される可能性があるため、使用には注意してください。
チェーンにメモリを追加する
多くの会話型 AI アプリケーションにはメモリが不可欠です。 任意のチェーンにメモリを追加する方法は次のとおりです。
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
この例では、メモリを使用して会話履歴を保存および取得し、チャットボットがコンテキストを維持して適切に応答できるようにします。
ランナブルでの外部ツールの使用
LCEL を使用すると、外部ツールを Runnables とシームレスに統合できます。 DuckDuckGo 検索ツールを使用した例を次に示します。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
この例では、LCEL は DuckDuckGo 検索ツールをチェーンに統合し、ユーザー入力から検索クエリを生成し、検索結果を取得できるようにします。
LCEL の柔軟性により、さまざまな外部ツールやサービスを言語処理パイプラインに簡単に組み込むことができ、その機能を強化できます。
LLM アプリケーションにモデレーションを追加する
LLM アプリケーションがコンテンツ ポリシーに準拠し、モデレーション保護機能が組み込まれていることを確認するには、モデレーション チェックをチェーンに統合します。 LangChain を使用してモデレーションを追加する方法は次のとおりです。
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
この例では、 OpenAIModerationChain LLM によって生成された応答にモデレーションを追加するために使用されます。 モデレーション チェーンは、OpenAI のコンテンツ ポリシーに違反するコンテンツの応答をチェックします。 違反が見つかった場合は、それに応じて応答にフラグが付けられます。
意味的類似性によるルーティング
LCEL を使用すると、ユーザー入力の意味上の類似性に基づいてカスタム ルーティング ロジックを実装できます。 ユーザー入力に基づいてチェーン ロジックを動的に決定する方法の例を次に示します。
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
この例では、 prompt_router 関数は、ユーザー入力と、物理および数学の質問に対する事前定義されたプロンプト テンプレートとの間のコサイン類似度を計算します。 類似性スコアに基づいて、チェーンは最も関連性の高いプロンプト テンプレートを動的に選択し、チャットボットがユーザーの質問に適切に応答するようにします。
エージェントとランナブルの使用
LangChain を使用すると、Runnable、プロンプト、モデル、ツールを組み合わせてエージェントを作成できます。 エージェントを構築して使用する例を次に示します。
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
この例では、モデル、ツール、プロンプト、中間ステップとツール変換用のカスタム ロジックを組み合わせてエージェントが作成されます。 次にエージェントが実行され、ユーザーのクエリに応答します。
SQL データベースのクエリ
LangChain を使用して SQL データベースにクエリを実行し、ユーザーの質問に基づいて SQL クエリを生成できます。 以下に例を示します。
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
この例では、LangChain を使用してユーザーの質問に基づいて SQL クエリを生成し、SQL データベースから応答を取得します。 プロンプトと応答は、データベースとの自然言語対話を提供するようにフォーマットされています。
Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
ラングサーブ & ラングスミス
LangServe は、開発者が LangChain ランナブルとチェーンを REST API としてデプロイするのに役立ちます。 このライブラリは FastAPI と統合されており、データ検証に pydantic を使用します。 さらに、サーバー上にデプロイされたランナブルを呼び出すために使用できるクライアントも提供され、JavaScript クライアントは LangChainJS で使用できます。
特徴
- 入力スキーマと出力スキーマは LangChain オブジェクトから自動的に推論され、すべての API 呼び出しに適用され、豊富なエラー メッセージが表示されます。
- JSONSchema と Swagger を含む API ドキュメント ページが利用可能です。
- 単一サーバー上での多数の同時リクエストをサポートする、効率的な /invoke、/batch、および /stream エンドポイント。
- チェーン/エージェントからすべて (または一部) の中間ステップをストリーミングするための /stream_log エンドポイント。
- /playground にあるプレイグラウンド ページ。ストリーミング出力と中間ステップが含まれます。
- LangSmith への組み込み (オプション) トレース。 API キーを追加するだけです (手順を参照)。
- すべては、FastAPI、Pydantic、uvloop、asyncio など、実戦テスト済みのオープンソース Python ライブラリで構築されています。
制限事項
- クライアント コールバックは、サーバーで発生するイベントに対してはまだサポートされていません。
- Pydantic V2 を使用する場合、OpenAPI ドキュメントは生成されません。 FastAPI は、pydantic v1 と v2 の名前空間の混合をサポートしていません。 詳細については、以下のセクションを参照してください。
LangChain CLI を使用して、LangServe プロジェクトを迅速にブートストラップします。 langchain CLI を使用するには、langchain-cli の最新バージョンがインストールされていることを確認してください。 pip install -U langchain-cli でインストールできます。
langchain app new ../path/to/directory
LangChain テンプレートを使用して、LangServe インスタンスをすぐに開始できます。 その他の例については、テンプレート インデックスまたはサンプル ディレクトリを参照してください。
これは、OpenAI チャット モデル、Anthropic チャット モデル、および Anthropic モデルを使用してトピックについてジョークを言うチェーンをデプロイするサーバーです。
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
上記のサーバーをデプロイしたら、次を使用して生成された OpenAPI ドキュメントを表示できます。
curl localhost:8000/docs
/docs サフィックスを必ず追加してください。
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
TypeScript の場合 (LangChain.js バージョン 0.0.166 以降が必要):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `http://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
リクエストを使用する Python:
import requests
response = requests.post( "http://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
カールを使用することもできます。
curl --location --request POST 'http://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
次のコード:
...
add_routes( app, runnable, path="/my_runnable",
)
これらのエンドポイントをサーバーに追加します。
- POST /my_runnable/invoke – 単一の入力でランナブルを呼び出します
- POST /my_runnable/batch – 入力のバッチに対してランナブルを呼び出します
- POST /my_runnable/stream – 単一の入力で呼び出し、出力をストリーミングします
- POST /my_runnable/stream_log – 単一の入力で呼び出し、生成された中間ステップの出力を含む出力をストリーミングします。
- GET /my_runnable/input_schema – ランナブルへの入力用の json スキーマ
- GET /my_runnable/output_schema – ランナブルの出力用の json スキーマ
- GET /my_runnable/config_schema – ランナブルの構成用の json スキーマ
ランナブルのプレイグラウンド ページは /my_runnable/playground にあります。 これにより、ストリーミング出力と中間ステップを使用してランナブルを構成および呼び出すためのシンプルな UI が公開されます。
クライアントとサーバーの両方の場合:
pip install "langserve[all]"
または、クライアント コードの場合は pip install “langserve[client]”、サーバー コードの場合は pip install “langserve[server]” です。
サーバーに認証を追加する必要がある場合は、FastAPI のセキュリティ ドキュメントとミドルウェア ドキュメントを参照してください。
次のコマンドを使用して GCP Cloud Run にデプロイできます。
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe は、いくつかの制限付きで Pydantic 2 をサポートします。 Pydantic V2 を使用する場合、OpenAPI ドキュメントは invoke/batch/stream/stream_log に対して生成されません。 Fast API は、pydantic v1 と v2 の名前空間の混合をサポートしていません。 LangChain は、Pydantic v1 の v2 名前空間を使用します。 LangChain との互換性を確保するには、次のガイドラインをお読みください。 これらの制限を除き、API エンドポイント、プレイグラウンド、その他の機能が期待どおりに動作することが期待されます。
LLM アプリケーションはファイルを扱うことがよくあります。 ファイル処理を実装するために作成できるさまざまなアーキテクチャがあります。 高いレベルで:
- ファイルは専用のエンドポイントを介してサーバーにアップロードされ、別のエンドポイントを使用して処理される場合があります。
- ファイルは、値 (ファイルのバイト数) または参照 (ファイル コンテンツへの s3 URL など) のいずれかによってアップロードできます。
- 処理エンドポイントはブロッキングまたはノンブロッキングの場合があります。
- 重要な処理が必要な場合、その処理は専用のプロセス プールにオフロードされる場合があります。
アプリケーションにとって適切なアーキテクチャは何かを判断する必要があります。 現在、値によってファイルを実行可能ファイルにアップロードするには、ファイルに Base64 エンコードを使用します (multipart/form-data はまだサポートされていません)。
これが 例 これは、base64 エンコードを使用してファイルをリモート実行可能ファイルに送信する方法を示しています。 ファイルはいつでも参照 (s3 URL など) によってアップロードしたり、マルチパート/フォームデータとして専用のエンドポイントにアップロードしたりできることに注意してください。
入力タイプと出力タイプはすべてのランナブルで定義されます。 input_schema プロパティと Output_schema プロパティを介してアクセスできます。 LangServe は、検証と文書化にこれらの型を使用します。 デフォルトの推論型をオーバーライドする場合は、with_types メソッドを使用できます。
このアイデアを説明するためのおもちゃの例を次に示します。
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
データを同等の dict 表現ではなく pydantic モデルに逆シリアル化する場合は、CustomUserType から継承します。 現時点では、このタイプはサーバー側でのみ機能し、必要なデコード動作を指定するために使用されます。 この型を継承する場合、サーバーはデコードされた型を dict に変換するのではなく、pydantic モデルとして保持します。
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
プレイグラウンドを使用すると、バックエンドから実行可能ファイルのカスタム ウィジェットを定義できます。 ウィジェットはフィールド レベルで指定され、入力タイプの JSON スキーマの一部として出荷されます。 ウィジェットには、よく知られたウィジェットのリストの XNUMX つである値を持つ type と呼ばれるキーが含まれている必要があります。 他のウィジェット キーは、JSON オブジェクト内のパスを記述する値に関連付けられます。
一般的なスキーマ:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
Base64 エンコードされた文字列としてアップロードされるファイルの UI プレイグラウンドでのファイル アップロード入力の作成を許可します。 完全な例は次のとおりです。
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
ラングスミスの紹介
LangChain を使用すると、LLM アプリケーションとエージェントのプロトタイプを簡単に作成できます。 ただし、LLM アプリケーションを実稼働環境に配信することは、一見すると難しい場合があります。 高品質の製品を作成するには、プロンプト、チェーン、その他のコンポーネントを大幅にカスタマイズして反復する必要があるでしょう。
このプロセスを支援するために、LLM アプリケーションのデバッグ、テスト、監視のための統合プラットフォームである LangSmith が導入されました。
これはいつ役立つでしょうか? 新しいチェーン、エージェント、または一連のツールをすばやくデバッグしたい場合、コンポーネント (チェーン、LLMS、レトリバーなど) がどのように関係し使用されているかを視覚化したい場合、単一コンポーネントのさまざまなプロンプトや LLM を評価したい場合に便利です。データセット上で特定のチェーンを数回実行して品質基準を常に満たしていることを確認したり、使用状況トレースをキャプチャして LLM または分析パイプラインを使用して洞察を生成したりできます。
受験資格:
- LangSmith アカウントを作成し、API キーを作成します (左下隅を参照)。
- ドキュメントを読んでプラットフォームについてよく理解してください。
さあ、始めましょう!
まず、LangChain にトレースを記録するように環境変数を設定します。 これを行うには、LANGCHAIN_TRACING_V2 環境変数を true に設定します。 LANGCHAIN_PROJECT 環境変数を設定することで、どのプロジェクトにログを記録するかを LangChain に指示できます (これが設定されていない場合、実行はデフォルトのプロジェクトに記録されます)。 これにより、プロジェクトが存在しない場合は自動的に作成されます。 LANGCHAIN_ENDPOINT および LANGCHAIN_API_KEY 環境変数も設定する必要があります。
注: Python のコンテキスト マネージャーを使用して、次のようにトレースをログに記録することもできます。
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
ただし、この例では環境変数を使用します。
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
API と対話するための LangSmith クライアントを作成します。
from langsmith import Client client = Client()
LangChain コンポーネントを作成し、実行をプラットフォームに記録します。 この例では、一般的な検索ツール (DuckDuckGo) にアクセスできる ReAct スタイルのエージェントを作成します。 エージェントのプロンプトは、次のハブで表示できます。
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
待ち時間を短縮するために、複数の入力に対してエージェントを同時に実行しています。 実行はバックグラウンドで LangSmith に記録されるため、実行レイテンシは影響を受けません。
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
環境が正常にセットアップされていると仮定すると、エージェント トレースがアプリのプロジェクト セクションに表示されるはずです。 おめでとうございます!
ただし、エージェントはツールを効果的に使用していないようです。 これを評価してベースラインを決めましょう。
LangSmith では、実行のログを記録するだけでなく、LLM アプリケーションをテストおよび評価することもできます。
このセクションでは、LangSmith を利用してベンチマーク データセットを作成し、エージェント上で AI 支援エバリュエーターを実行します。 これはいくつかの手順で行います。
- LangSmith データセットを作成します。
以下では、LangSmith クライアントを使用して、上記の入力質問とリスト ラベルからデータセットを作成します。 後でこれらを使用して、新しいエージェントのパフォーマンスを測定します。 データセットはサンプルのコレクションであり、アプリケーションのテスト ケースとして使用できる入出力ペアにすぎません。
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- ベンチマークを行うために新しいエージェントを初期化します。
LangSmith を使用すると、LLM、チェーン、エージェント、さらにはカスタム関数を評価できます。 会話エージェントはステートフルです (メモリを持っています)。 この状態がデータセットの実行間で共有されないようにするには、chain_factory (
別名コンストラクター) 呼び出しごとに初期化する関数:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- 評価を構成します。
UI でチェーンの結果を手動で比較することは効果的ですが、時間がかかる可能性があります。 コンポーネントのパフォーマンスを評価するには、自動化されたメトリクスと AI 支援のフィードバックを使用すると便利です。
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- エージェントとエバリュエーターを実行します。
run_on_dataset (または非同期 arun_on_dataset) 関数を使用してモデルを評価します。 この意志:
- 指定されたデータセットからサンプル行をフェッチします。
- 各例でエージェント (または任意のカスタム関数) を実行します。
- 結果として得られる実行トレースと対応する参照例にエバリュエーターを適用して、自動フィードバックを生成します。
結果は LangSmith アプリに表示されます。
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
テスト実行の結果が得られたので、エージェントに変更を加えてベンチマークを行うことができます。 別のプロンプトでこれをもう一度試して、結果を見てみましょう。
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
LangSmith を使用すると、Web アプリでデータを CSV や JSONL などの一般的な形式に直接エクスポートできます。 クライアントを使用して、さらなる分析のために実行を取得したり、独自のデータベースに保存したり、他のユーザーと共有したりすることもできます。 評価実行から実行トレースを取得しましょう。
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
これは開始するためのクイック ガイドでしたが、LangSmith を使用して開発フローを高速化し、より良い結果を生み出す方法は他にもたくさんあります。
LangSmith を最大限に活用する方法の詳細については、LangSmith のドキュメントを参照してください。
ナノネットでレベルアップ
LangChain は言語モデル (LLM) をアプリケーションに統合するための貴重なツールですが、エンタープライズでの使用例となると制限に直面する可能性があります。 Nanonets が LangChain を超えてこれらの課題にどのように対処するかを見てみましょう。
1. 包括的なデータ接続:
LangChain はコネクタを提供しますが、企業が依存するすべてのワークスペース アプリとデータ形式をカバーしているわけではありません。 Nanonets は、Slack、Notion、Google Suite、Salesforce、Zendesk など、広く使用されている 100 を超えるワークスペース アプリ用のデータ コネクタを提供します。 また、CSV、スプレッドシート、MongoDB、SQL データベースなどの構造化データ型だけでなく、PDF、TXT、画像、音声ファイル、ビデオ ファイルなどのすべての非構造化データ型もサポートしています。

2. ワークスペース アプリのタスク自動化:
テキスト/応答の生成はうまく機能しますが、自然言語を使用してさまざまなアプリケーションでタスクを実行する場合、LangChain の機能は制限されます。 Nanonets は、最も人気のあるワークスペース アプリ用のトリガー/アクション エージェントを提供しており、イベントをリッスンしてアクションを実行するワークフローを設定できます。 たとえば、電子メールの応答、CRM エントリ、SQL クエリなどをすべて自然言語コマンドを通じて自動化できます。
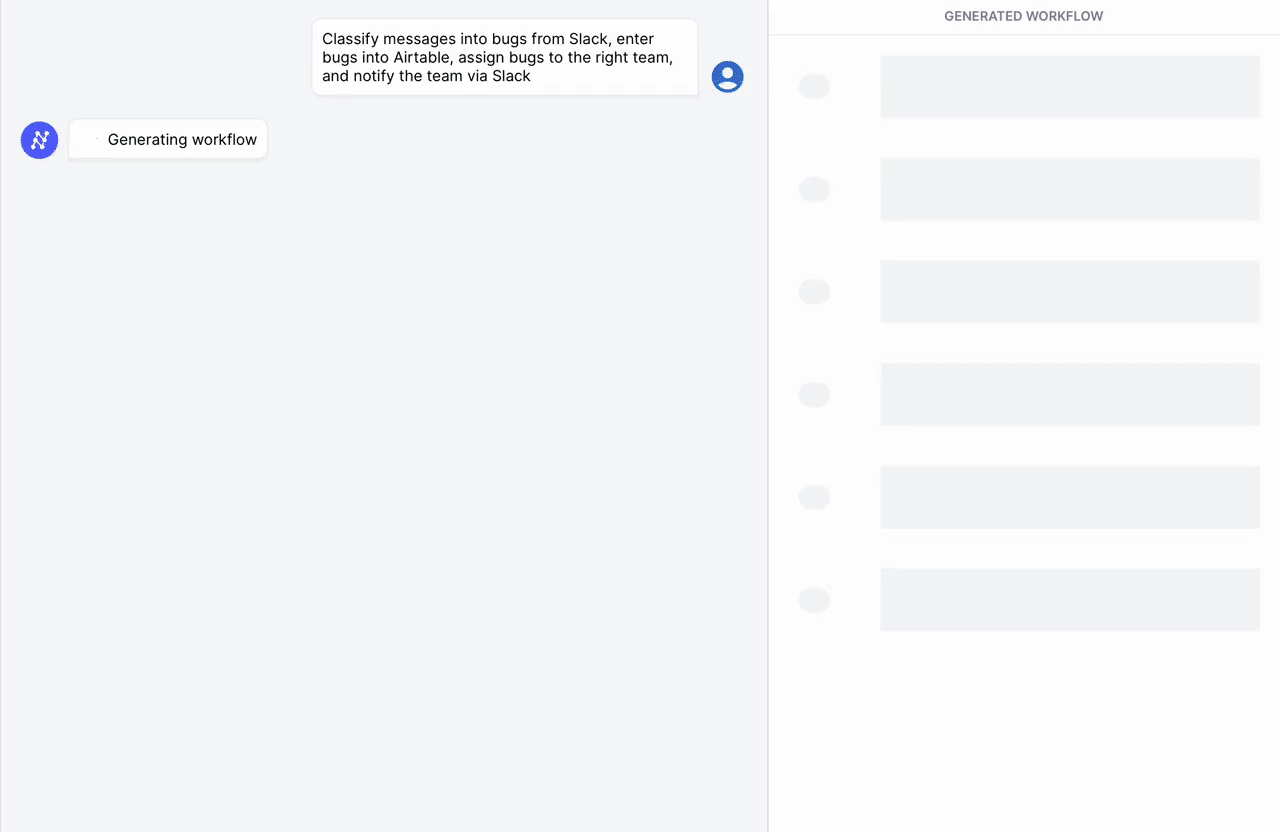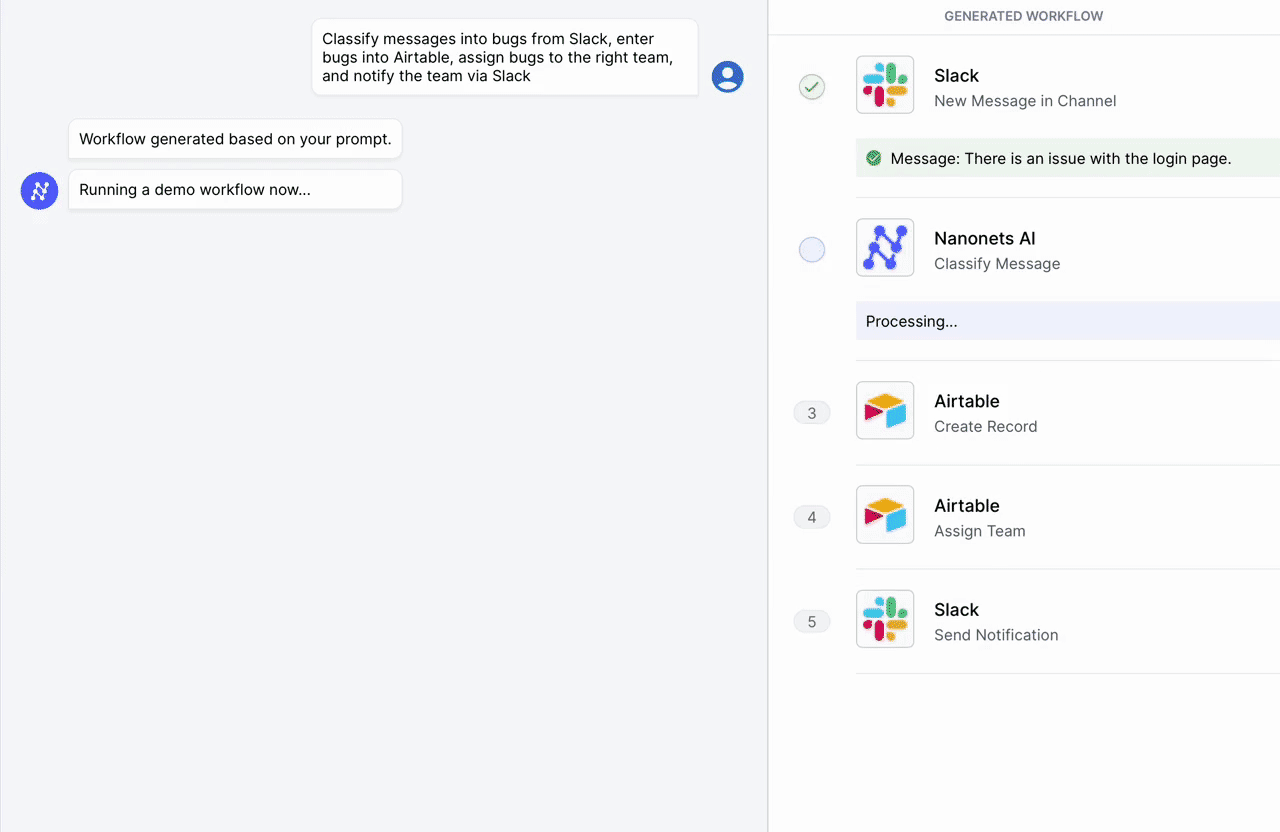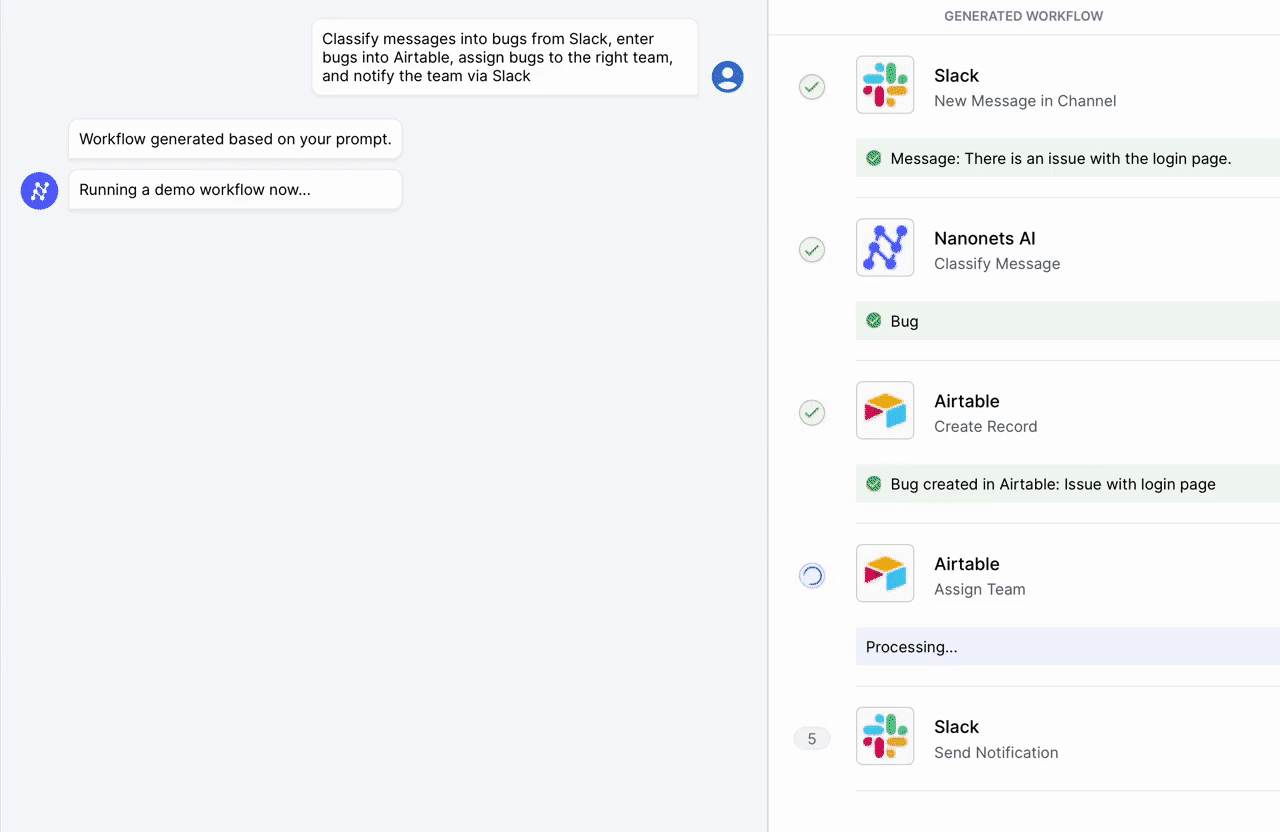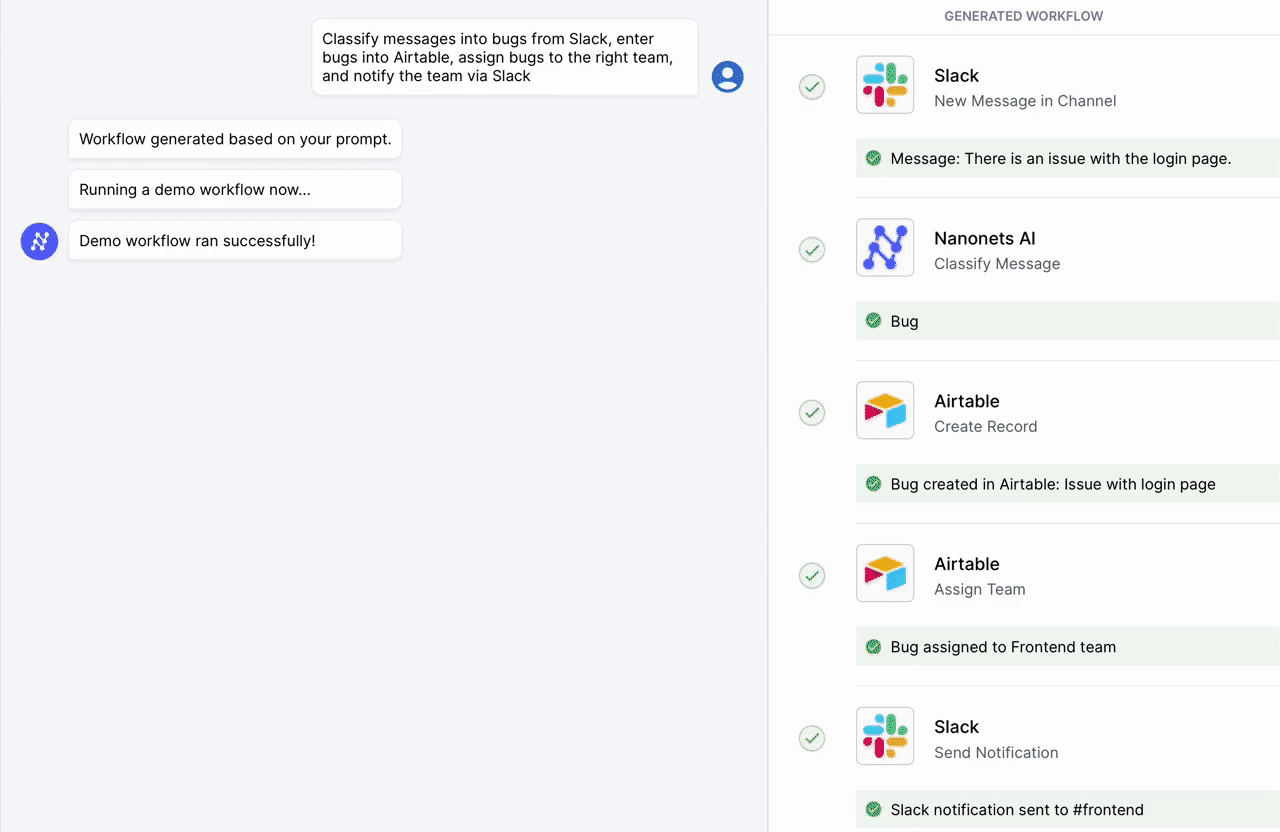
3. リアルタイムのデータ同期:
LangChain はデータ コネクタを使用して静的データを取得しますが、ソース データベースのデータ変更に追いつかない可能性があります。 対照的に、Nanonets はデータ ソースとのリアルタイム同期を保証し、常に最新の情報を使用して作業できるようにします。

3. 簡素化された構成:
レトリーバーやシンセサイザーなどの LangChain パイプラインの要素の構成は、複雑で時間のかかるプロセスになる場合があります。 Nanonets は、データの種類ごとに最適化されたデータの取り込みとインデックス作成を提供することでこれを合理化し、すべて AI アシスタントによってバックグラウンドで処理されます。 微調整の負担が軽減され、セットアップや使いやすさが向上します。
4. 統合ソリューション:
タスクごとに独自の実装が必要な LangChain とは異なり、Nanonets はデータを LLM に接続するためのワンストップ ソリューションとして機能します。 LLM アプリケーションを作成する必要がある場合でも、AI ワークフローを作成する必要がある場合でも、Nanonets はさまざまなニーズに対応する統合プラットフォームを提供します。
ナノネット AI ワークフロー
Nanonets Workflows は、知識とデータの LLM との統合を簡素化し、コードなしのアプリケーションとワークフローの作成を容易にする、安全な多目的 AI アシスタントです。 使いやすいユーザー インターフェイスを提供し、個人と組織の両方がアクセスできるようにします。
まず、当社の AI 専門家との通話をスケジュールすることができます。専門家は、お客様の特定のユースケースに合わせてカスタマイズされた Nanonets ワークフローのデモとトライアルを提供できます。
セットアップが完了すると、自然言語を使用して、LLM を活用した複雑なアプリケーションやワークフローを設計および実行し、アプリやデータとシームレスに統合できるようになります。

Nanonets AI でチームを強化し、アプリを作成し、データを AI 主導のアプリケーションやワークフローと統合して、チームが本当に重要なことに集中できるようにします。
Nanonets がお客様とお客様のチーム向けに設計した AI 主導のワークフロー ビルダーを使用して、手動タスクとワークフローを自動化します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/langchain/

