この投稿は、FedML の Chaoyang He、Al Nevarez、Salman Avestimehr との共同執筆です。
多くの組織は、自動化と大規模な分散データセットの使用を通じてビジネス上の意思決定を強化するために、機械学習 (ML) を導入しています。データへのアクセスが増えると、ML は比類のないビジネス上の洞察と機会を提供する可能性があります。ただし、サニタイズされていない生の機密情報をさまざまな場所で共有すると、特に医療などの規制のある業界では、重大なセキュリティとプライバシーのリスクが生じます。
この問題に対処するために、フェデレーテッド ラーニング (FL) は、精度と忠実度を維持しながらデータのプライバシーを提供する分散型の協調的な ML トレーニング手法です。従来の ML トレーニングとは異なり、FL トレーニングは、独立した安全なセッションを使用して、隔離されたクライアントの場所内で行われます。クライアントは、出力モデルのパラメーターのみをトレーニング コーディネーターまたは集約サーバーと呼ばれる集中サーバーと共有し、モデルのトレーニングに使用される実際のデータは共有しません。このアプローチにより、データ プライバシーに関する多くの懸念が軽減され、モデル トレーニングにおける効果的なコラボレーションが可能になります。
FL は、より優れたデータ プライバシーとセキュリティを実現するための一歩ですが、保証されたソリューションではありません。アクセス制御や暗号化が欠けている安全でないネットワークでも、機密情報が攻撃者に公開される可能性があります。さらに、ローカルでトレーニングされた情報は、推論攻撃によって再構築された場合にプライベート データが公開される可能性があります。これらのリスクを軽減するために、FL モデルでは、トレーニング コーディネーターと情報を共有する前に、パーソナライズされたトレーニング アルゴリズムと効果的なマスキングとパラメーター化を使用します。ローカルおよび集中化された場所での強力なネットワーク制御により、推論と漏洩のリスクをさらに軽減できます。
この投稿では、次を使用した FL アプローチを共有します。 FedML, Amazon Elastic Kubernetesサービス (Amazon EKS)、および アマゾンセージメーカー データプライバシーとセキュリティの問題に対処しながら、患者の転帰を改善します。
医療におけるフェデレーテッド ラーニングの必要性
医療は、患者ケアに関する正確な予測と評価を行うために分散データ ソースに大きく依存しています。プライバシーを保護するために利用可能なデータソースを制限すると、結果の正確性、そして最終的には患者ケアの質に悪影響を及ぼします。したがって、ML は、患者の治療結果を損なうことなく、分散したエンティティ全体でプライバシーとセキュリティを確保する必要がある AWS の顧客にとって課題となります。
医療組織は、FL ソリューションを導入する際に、米国の医療保険相互運用性と説明責任法 (HIPAA) などの厳格なコンプライアンス規制を順守する必要があります。医療分野ではデータのプライバシー、セキュリティ、コンプライアンスの確保がさらに重要になり、堅牢な暗号化、アクセス制御、監査メカニズム、安全な通信プロトコルが必要になります。さらに、医療データセットには複雑で異種のデータ タイプが含まれることが多く、フロリダ州の設定ではデータの標準化と相互運用性が課題となっています。
ユースケースの概要
この投稿で概説されているユースケースは、さまざまな組織の心臓病データであり、ML モデルはそのデータに基づいて分類アルゴリズムを実行して患者の心臓病を予測します。このデータは組織全体に存在するため、フェデレーテッド ラーニングを使用して調査結果を照合します。
心臓病データセット カリフォルニア大学アーバインの機械学習リポジトリは、心臓血管の研究と予測モデリングに広く使用されているデータセットです。これは 303 のサンプルで構成されており、各サンプルは患者を表しており、臨床的属性と人口統計的属性の組み合わせ、および心臓病の有無が含まれています。
この多変量データセットには患者情報に 76 の属性が含まれており、そのうち 14 の属性は、指定された属性に基づいて心臓病の存在を予測する ML アルゴリズムの開発と評価に最も一般的に使用されます。
FedML フレームワーク
FL フレームワークには幅広い選択肢がありますが、私たちは FedML フレームワーク これはオープンソースであり、いくつかの FL パラダイムをサポートしているため、このユースケースに適しています。 FedML は、フロリダ州向けに人気のオープンソース ライブラリ、MLOps プラットフォーム、アプリケーション エコシステムを提供します。これらにより、FL ソリューションの開発と展開が容易になります。研究者や実践者が分散環境で FL アルゴリズムを実装および実験できるようにするツール、ライブラリ、アルゴリズムの包括的なスイートを提供します。 FedML は、フロリダ州のデータ プライバシー、通信、モデル集約の課題に対処し、ユーザーフレンドリーなインターフェイスとカスタマイズ可能なコンポーネントを提供します。 FedML は、コラボレーションと知識の共有に重点を置き、FL の導入を加速し、この新興分野でのイノベーションを推進することを目指しています。 FedML フレームワークは、最近追加された大規模言語モデル (LLM) のサポートを含め、モデルに依存しません。詳細については、以下を参照してください。 FedLLM のリリース: FedML プラットフォームを使用して独自の大規模言語モデルを独自のデータに基づいて構築する.
FedML タコ
システム階層と異質性は、異なるデータ サイロに CPU と GPU を備えた異なるインフラストラクチャが存在する可能性がある実際の FL の使用例では重要な課題です。このようなシナリオでは、次のように使用できます。 FedML タコ.
FedML Octopus は、組織間およびアカウント間のトレーニングのためのクロスサイロ FL の産業グレードのプラットフォームです。 FedML MLOps と組み合わせることで、開発者や組織は、どこからでも、あらゆる規模で、安全な方法でオープン コラボレーションを行うことができます。 FedML Octopus は、各データ サイロ内で分散トレーニング パラダイムを実行し、同期または非同期トレーニングを使用します。
FedML MLOps
FedML MLOps を使用すると、後で FedML フレームワークを使用してどこにでもデプロイできるコードのローカル開発が可能になります。トレーニングを開始する前に、FedML アカウントを作成し、FedML Octopus でサーバーとクライアントのパッケージを作成してアップロードする必要があります。詳細については、を参照してください。 ステップ & FedML Octopus の紹介: 簡素化された MLOps でフェデレーテッド ラーニングを本番環境に拡張.
ソリューションの概要
実験追跡のために、SageMaker と統合された複数の EKS クラスターに FedML をデプロイします。を使用しております Terraform 用の Amazon EKS ブループリント 必要なインフラストラクチャを展開します。 EKS ブループリントは、ワークロードのデプロイと運用に必要な運用ソフトウェアで完全にブートストラップされた完全な EKS クラスターの構成に役立ちます。 EKS ブループリントを使用すると、コントロール プレーン、ワーカー ノード、Kubernetes アドオンなどの EKS 環境の望ましい状態の構成が、コードとしてのインフラストラクチャ (IaC) ブループリントとして記述されます。ブループリントを構成した後は、継続的なデプロイの自動化を使用して、複数の AWS アカウントおよびリージョンにわたって一貫した環境を作成するために使用できます。
この投稿で共有されるコンテンツは実際の状況や経験を反映していますが、場所によってはこれらの状況の展開が異なる場合があることに注意することが重要です。私たちは個別の VPC を持つ単一の AWS アカウントを利用していますが、個々の状況や構成は異なる可能性があることを理解することが重要です。したがって、提供される情報は一般的なガイドとして使用する必要があり、特定の要件や地域の状況に基づいて調整が必要になる場合があります。
次の図は、ソリューションアーキテクチャを示しています。
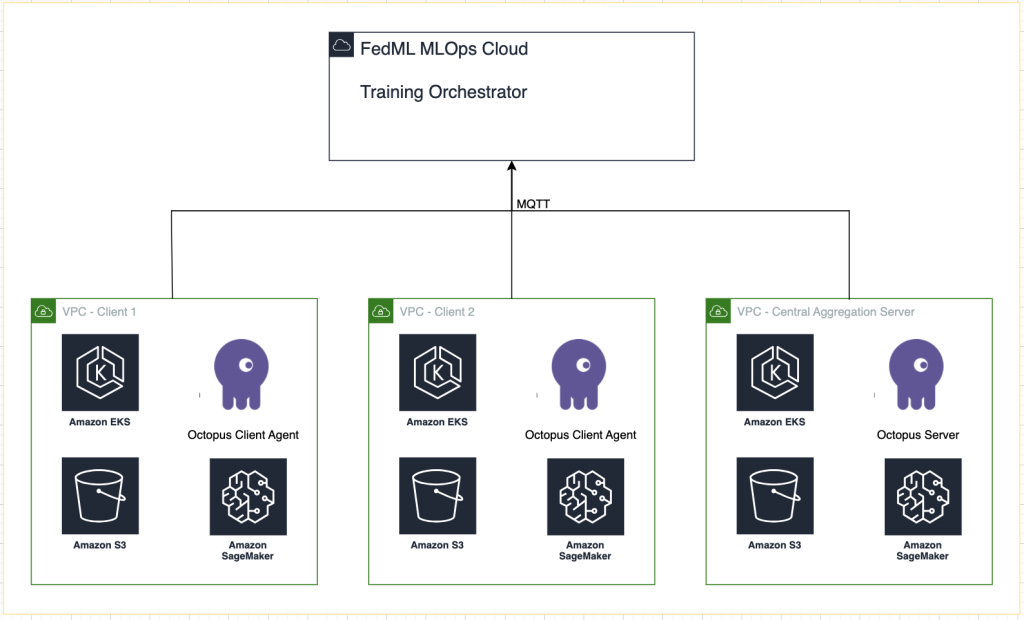
各トレーニング実行に対して FedML MLOps によって提供される追跡に加えて、以下を使用します。 AmazonSageMakerの実験 各クライアント モデルと集中 (アグリゲーター) モデルのパフォーマンスを追跡します。
SageMaker Experiments は、ML 実験を作成、管理、分析、比較できる SageMaker の機能です。実験の詳細、パラメータ、結果を記録することで、研究者は自分の作業を正確に再現し、検証することができます。これにより、さまざまなアプローチの効果的な比較と分析が可能になり、情報に基づいた意思決定が可能になります。さらに、実験を追跡することで、モデルの進行に関する洞察が得られ、研究者が以前の反復から学習できるようにすることで反復的な改善が促進され、最終的にはより効果的なソリューションの開発が加速されます。
実行ごとに以下を SageMaker Experiments に送信します。
- モデルの評価指標 – トレーニングロスと曲線下面積(AUC)
- ハイパーパラメータ – エポック、学習率、バッチサイズ、オプティマイザ、および重み減衰
前提条件
この投稿をフォローするには、次の前提条件が必要です。
ソリューションを展開する
まず、サンプル コードをローカルにホストしているリポジトリのクローンを作成します。
次に、次のコマンドを使用してユース ケース インフラストラクチャをデプロイします。
Terraform テンプレートが完全にデプロイされるまでに 20 ~ 30 分かかる場合があります。デプロイ後、次のセクションの手順に従って FL アプリケーションを実行します。
MLOps デプロイメント パッケージを作成する
FedML ドキュメントの一部として、クライアント パッケージとサーバー パッケージを作成する必要があります。MLOps プラットフォームは、トレーニングを開始するためにサーバーとクライアントにこれらのパッケージを配布します。
これらのパッケージを作成するには、ルート ディレクトリにある次のスクリプトを実行します。
これにより、プロジェクトのルート ディレクトリの次のディレクトリにそれぞれのパッケージが作成されます。
パッケージを FedML MLOps プラットフォームにアップロードする
パッケージをアップロードするには、次の手順を実行します。
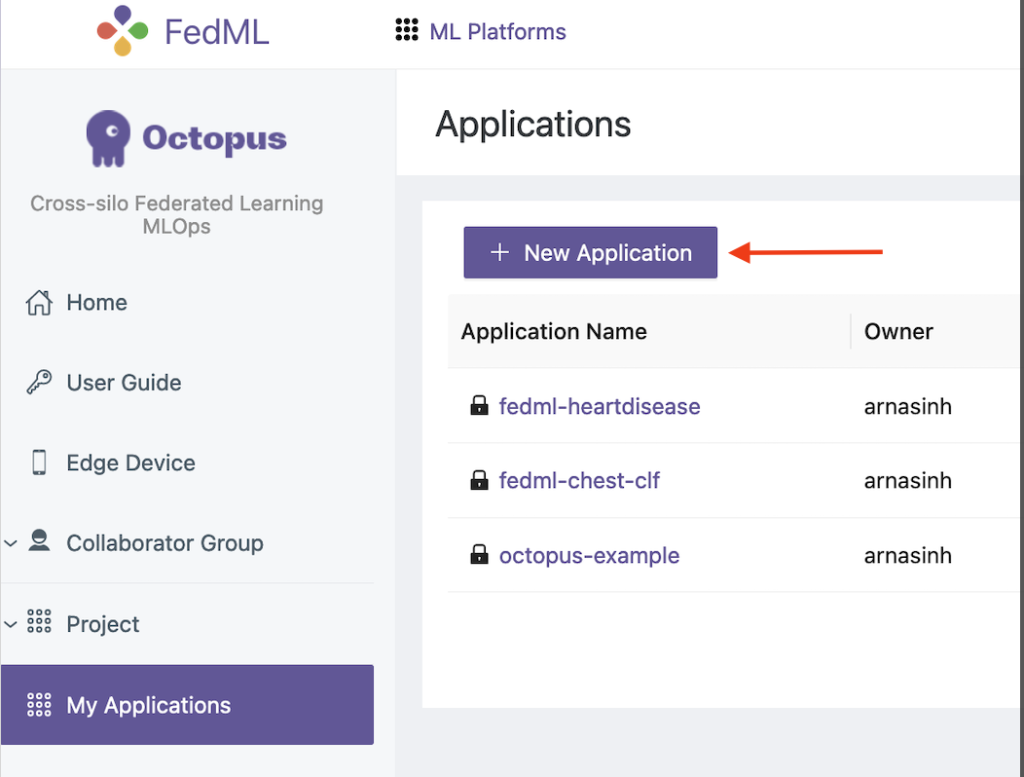
- FedML UI で、次を選択します。 私のアプリケーション ナビゲーションペインに表示されます。
- 選択する 新しいアプリ.
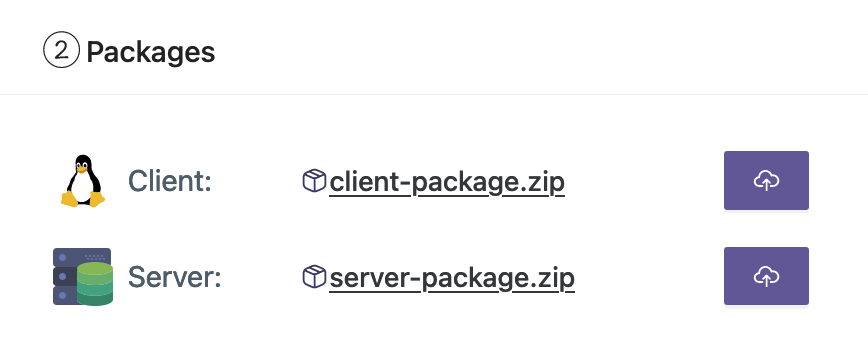
- ワークステーションからクライアントとサーバーのパッケージをアップロードします。
- ハイパーパラメータを調整したり、新しいパラメータを作成したりすることもできます。

フェデレーテッド トレーニングをトリガーする
フェデレーション トレーニングを実行するには、次の手順を実行します。
- FedML UI で、次を選択します。 プロジェクト一覧 ナビゲーションペインに表示されます。
- 選択する 新しいプロジェクトを作成します.
- グループ名とプロジェクト名を入力し、選択します。 OK.

- 新しく作成したプロジェクトを選択し、 新しい実行を作成する トレーニング実行をトリガーします。
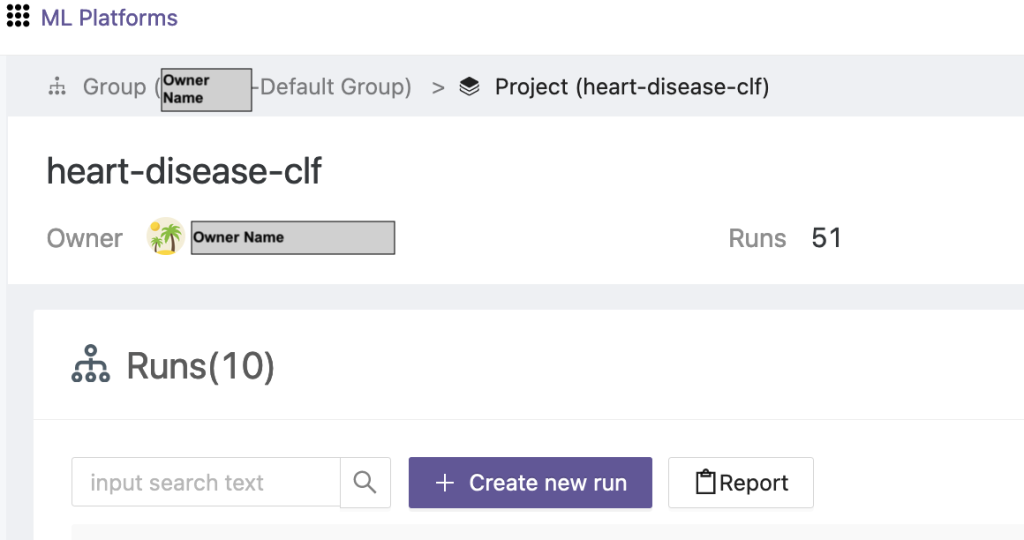
- このトレーニングを実行するためのエッジ クライアント デバイスと中央アグリゲーター サーバーを選択します。
- 前の手順で作成したアプリケーションを選択します。

- いずれかのハイパーパラメータを更新するか、デフォルト設定を使用します。
- 選択する 開始 トレーニングを開始します。

- 選択する 研修状況 タブをクリックして、トレーニングの実行が完了するまで待ちます。利用可能なタブに移動することもできます。
- トレーニングが完了したら、 エントルピー タブをクリックすると、エッジ サーバー上のトレーニング時間と集約イベントが表示されます。
結果と実験の詳細を表示する
トレーニングが完了すると、FedML と SageMaker を使用して結果を表示できます。
FedML UI 上で、 Models タブで、アグリゲーターとクライアント モデルを確認できます。これらのモデルは Web サイトからダウンロードすることもできます。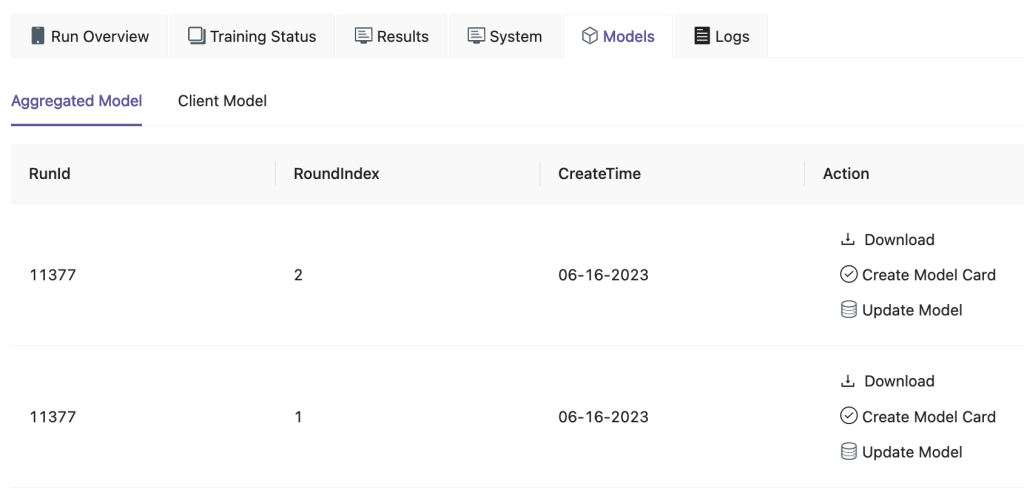
にログインすることもできます Amazon SageMakerスタジオ 選択して 実験 ナビゲーションペインに表示されます。
次のスクリーンショットは、記録された実験を示しています。
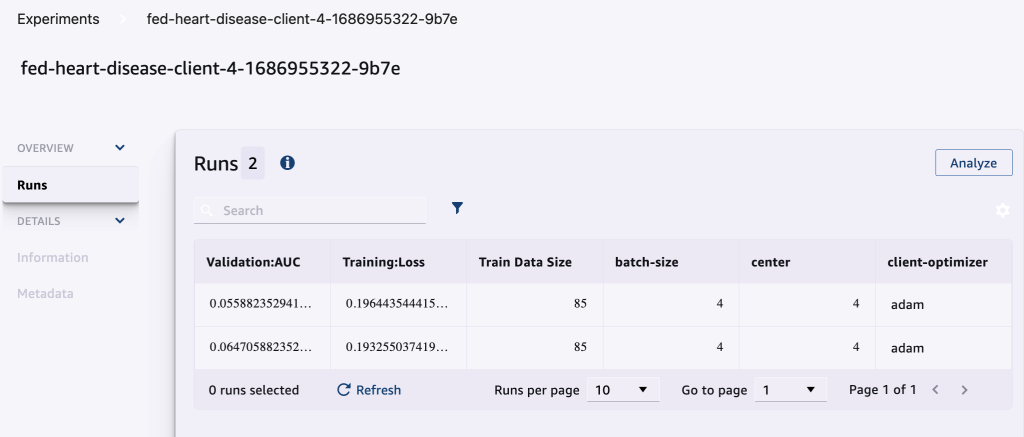
実験用トラッキングコード
このセクションでは、SageMaker 実験追跡と FL フレームワーク トレーニングを統合するコードを検討します。
選択したエディターで次のフォルダーを開いて、トレーニングの一部として SageMaker 実験追跡コードを挿入するためのコードの編集を確認します。
トレーニングを追跡するために、 SageMaker 実験を作成する パラメータとメトリクスは、 log_parameter & log_metric 次のコードサンプルで説明されているように、コマンドを実行します。
のエントリ config/fedml_config.yaml このファイルは、一意の実験名を作成するためにコード内で参照される実験プレフィックスを宣言します。 sm_experiment_name: "fed-heart-disease"。これを任意の値に更新できます。
たとえば、次のコードを参照してください。 heart_disease_trainer.pyこれは、各クライアントが独自のデータセットでモデルをトレーニングするために使用されます。
クライアントの実行ごとに、heart_disease_trainer.py 内の次のコードを使用して実験の詳細が追跡されます。
同様に、次のコードを使用できます。 heart_disease_aggregator.py モデルの重みを更新した後にローカル データに対してテストを実行します。詳細は、クライアントとの通信が実行されるたびにログに記録されます。
クリーンアップ
ソリューションが完了したら、使用したリソースを必ずクリーンアップして、リソースの効率的な利用とコスト管理を確保し、不必要な経費やリソースの浪費を避けてください。使用されていないインスタンスの削除、不要なサービスの停止、一時データの削除など、環境を積極的に整理整頓すると、インフラストラクチャがクリーンで組織化されます。次のコードを使用してリソースをクリーンアップできます。
まとめ
Amazon EKS をインフラストラクチャとして使用し、FedML を FL のフレームワークとして使用することで、データプライバシーを尊重しながら、共有モデルのトレーニングとデプロイのためのスケーラブルで管理された環境を提供できます。 FL の分散型の性質により、組織は安全にコラボレーションし、分散データの可能性を解き放ち、データのプライバシーを損なうことなく ML モデルを改善できます。
いつものように、AWS は皆様からのフィードバックをお待ちしております。ご意見やご質問をコメント欄に残してください。
著者について
 ランディ・デフォー AWS のシニア プリンシパル ソリューション アーキテクトです。彼はミシガン大学で修士号を取得しており、そこで自動運転車のコンピューター ビジョンに取り組みました。彼はコロラド州立大学で MBA も取得しています。 Randy は、ソフトウェア エンジニアリングから製品管理に至るまで、テクノロジー分野でさまざまな役職を歴任してきました。彼は 2013 年にビッグデータ分野に参入し、その分野の探索を続けています。彼は ML 分野のプロジェクトに積極的に取り組んでおり、Strata や GlueCon などの多数のカンファレンスで発表しています。
ランディ・デフォー AWS のシニア プリンシパル ソリューション アーキテクトです。彼はミシガン大学で修士号を取得しており、そこで自動運転車のコンピューター ビジョンに取り組みました。彼はコロラド州立大学で MBA も取得しています。 Randy は、ソフトウェア エンジニアリングから製品管理に至るまで、テクノロジー分野でさまざまな役職を歴任してきました。彼は 2013 年にビッグデータ分野に参入し、その分野の探索を続けています。彼は ML 分野のプロジェクトに積極的に取り組んでおり、Strata や GlueCon などの多数のカンファレンスで発表しています。
 アーナブシンハ AWS のシニア ソリューション アーキテクトであり、フィールド CTO として組織がデータセンターの移行、デジタル変革とアプリケーションの最新化、ビッグデータ、機械学習にわたるビジネス成果をサポートするスケーラブルなソリューションの設計と構築を支援します。彼は、エネルギー、小売、製造、ヘルスケア、ライフ サイエンスなど、さまざまな業界の顧客をサポートしてきました。 Arnab は、ML スペシャリティ認定を含むすべての AWS 認定を取得しています。 AWS に入社する前は、Arnab はテクノロジーリーダーであり、以前はアーキテクトおよびエンジニアリングのリーダーとしての役割を担っていました。
アーナブシンハ AWS のシニア ソリューション アーキテクトであり、フィールド CTO として組織がデータセンターの移行、デジタル変革とアプリケーションの最新化、ビッグデータ、機械学習にわたるビジネス成果をサポートするスケーラブルなソリューションの設計と構築を支援します。彼は、エネルギー、小売、製造、ヘルスケア、ライフ サイエンスなど、さまざまな業界の顧客をサポートしてきました。 Arnab は、ML スペシャリティ認定を含むすべての AWS 認定を取得しています。 AWS に入社する前は、Arnab はテクノロジーリーダーであり、以前はアーキテクトおよびエンジニアリングのリーダーとしての役割を担っていました。
 プラチ クルカルニ AWS のシニア ソリューション アーキテクトです。彼女の専門は機械学習で、さまざまな AWS ML、ビッグデータ、分析サービスを使用したソリューションの設計に積極的に取り組んでいます。 Prachi は、ヘルスケア、福利厚生、小売、教育などの複数の分野での経験があり、製品エンジニアリングとアーキテクチャ、管理、カスタマー サクセスのさまざまな役職で働いてきました。
プラチ クルカルニ AWS のシニア ソリューション アーキテクトです。彼女の専門は機械学習で、さまざまな AWS ML、ビッグデータ、分析サービスを使用したソリューションの設計に積極的に取り組んでいます。 Prachi は、ヘルスケア、福利厚生、小売、教育などの複数の分野での経験があり、製品エンジニアリングとアーキテクチャ、管理、カスタマー サクセスのさまざまな役職で働いてきました。
 テイマー・シェリフ AWS のプリンシパル ソリューション アーキテクトであり、ソリューション アーキテクトとして 17 年以上にわたり、テクノロジーおよびエンタープライズコンサルティングサービスの分野で多様な背景を持っています。インフラストラクチャに焦点を当てたテイマーの専門知識は、商業、ヘルスケア、自動車、公共部門、製造、石油とガス、メディア サービスなどを含む幅広い業界をカバーしています。彼の専門知識は、クラウド アーキテクチャ、エッジ コンピューティング、ネットワーキング、ストレージ、仮想化、ビジネスの生産性、技術的リーダーシップなど、さまざまな領域に及びます。
テイマー・シェリフ AWS のプリンシパル ソリューション アーキテクトであり、ソリューション アーキテクトとして 17 年以上にわたり、テクノロジーおよびエンタープライズコンサルティングサービスの分野で多様な背景を持っています。インフラストラクチャに焦点を当てたテイマーの専門知識は、商業、ヘルスケア、自動車、公共部門、製造、石油とガス、メディア サービスなどを含む幅広い業界をカバーしています。彼の専門知識は、クラウド アーキテクチャ、エッジ コンピューティング、ネットワーキング、ストレージ、仮想化、ビジネスの生産性、技術的リーダーシップなど、さまざまな領域に及びます。
 ハンス・ネスビット 南カリフォルニアを拠点とする AWS のシニア ソリューション アーキテクトです。彼は米国西部の顧客と協力して、拡張性、柔軟性、回復力の高いクラウド アーキテクチャを構築しています。余暇には、家族と過ごしたり、料理をしたり、ギターを弾いたりすることを楽しんでいます。
ハンス・ネスビット 南カリフォルニアを拠点とする AWS のシニア ソリューション アーキテクトです。彼は米国西部の顧客と協力して、拡張性、柔軟性、回復力の高いクラウド アーキテクチャを構築しています。余暇には、家族と過ごしたり、料理をしたり、ギターを弾いたりすることを楽しんでいます。
 何朝陽 FedML, Inc. の共同創設者兼 CTO です。FedML, Inc. は、どこからでも、どんな規模でも、オープンで協調的な AI を構築するコミュニティを運営するスタートアップです。彼の研究は、分散型および連合型の機械学習アルゴリズム、システム、およびアプリケーションに焦点を当てています。彼は南カリフォルニア大学でコンピューター サイエンスの博士号を取得しました。
何朝陽 FedML, Inc. の共同創設者兼 CTO です。FedML, Inc. は、どこからでも、どんな規模でも、オープンで協調的な AI を構築するコミュニティを運営するスタートアップです。彼の研究は、分散型および連合型の機械学習アルゴリズム、システム、およびアプリケーションに焦点を当てています。彼は南カリフォルニア大学でコンピューター サイエンスの博士号を取得しました。
 アル・ネバレス FedML の製品管理ディレクターです。 FedML に入社する前は、Google でグループ プロダクト マネージャーを務め、LinkedIn でデータ サイエンスのシニア マネージャーを務めていました。彼はデータ製品関連の特許をいくつか取得しており、スタンフォード大学で工学を学びました。
アル・ネバレス FedML の製品管理ディレクターです。 FedML に入社する前は、Google でグループ プロダクト マネージャーを務め、LinkedIn でデータ サイエンスのシニア マネージャーを務めていました。彼はデータ製品関連の特許をいくつか取得しており、スタンフォード大学で工学を学びました。
 サルマン・アヴェスティメル FedML の共同創設者兼 CEO です。彼は、USC の学部長教授、USC-Amazon Center on Trustworthy AI のディレクター、および Alexa AI の Amazon Scholar を務めています。彼は、フェデレーテッドおよび分散型機械学習、情報理論、セキュリティ、プライバシーの専門家です。彼は IEEE のフェローであり、カリフォルニア大学バークレー校で EECS の博士号を取得しています。
サルマン・アヴェスティメル FedML の共同創設者兼 CEO です。彼は、USC の学部長教授、USC-Amazon Center on Trustworthy AI のディレクター、および Alexa AI の Amazon Scholar を務めています。彼は、フェデレーテッドおよび分散型機械学習、情報理論、セキュリティ、プライバシーの専門家です。彼は IEEE のフェローであり、カリフォルニア大学バークレー校で EECS の博士号を取得しています。
 サミール・ラッド は、AWS の熟練したエンタープライズテクノロジストであり、顧客の経営幹部と緊密に連携しています。複数のフォーチュン 100 企業の変革を推進してきた元経営幹部として、サミールは、クライアントが自らの変革の旅を成功させるのを支援するための貴重な経験を共有しています。
サミール・ラッド は、AWS の熟練したエンタープライズテクノロジストであり、顧客の経営幹部と緊密に連携しています。複数のフォーチュン 100 企業の変革を推進してきた元経営幹部として、サミールは、クライアントが自らの変革の旅を成功させるのを支援するための貴重な経験を共有しています。
 スティーブン・クレーマー 彼は AWS の取締役会および CxO アドバイザーであり、元幹部でもあります。スティーブンは、成功の基盤として文化とリーダーシップを提唱しています。彼は、セキュリティとイノベーションが、競争力の高いデータドリブンな組織を可能にするクラウド変革の原動力であると公言しています。
スティーブン・クレーマー 彼は AWS の取締役会および CxO アドバイザーであり、元幹部でもあります。スティーブンは、成功の基盤として文化とリーダーシップを提唱しています。彼は、セキュリティとイノベーションが、競争力の高いデータドリブンな組織を可能にするクラウド変革の原動力であると公言しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

