株式会社KT 韓国で最大の電気通信プロバイダーのXNUMXつであり、固定線電話、モバイル通信、インターネット、AIサービスなど、幅広いサービスを提供しています。 KTのAI Food Tagは、コンピュータービジョンモデルを使用して写真の食品の種類と栄養含有量を識別するAIベースの食事管理ソリューションです。 KTによって開発されたこのビジョンモデルは、さまざまな食品の栄養含有量とカロリー情報を分析するために、大量の非標識画像データで事前に訓練されたモデルに依存しています。 AIフードタグは、糖尿病などの慢性疾患の患者が食事を管理するのに役立ちます。 KTはAWSを使用しました アマゾンセージメーカー この AI フード タグ モデルを以前より 29 倍の速さでトレーニングし、モデル蒸留技術を使用して実稼働展開に向けて最適化します。 この投稿では、SageMaker を使用した KT のモデル開発の過程と成功について説明します。
KT プロジェクトの紹介と問題の定義
KT によって事前トレーニングされた AI Food Tag モデルは、ビジョン トランスフォーマー (ViT) アーキテクチャに基づいており、精度を向上させるために以前のビジョン モデルよりも多くのモデル パラメーターが含まれています。 実稼働用のモデル サイズを縮小するために、KT は知識蒸留 (KD) 手法を使用して、精度に大きな影響を与えることなくモデル パラメーターの数を削減しています。 知識の蒸留では、事前トレーニングされたモデルは 教師モデル、軽量の出力モデルは次のようにトレーニングされます。 学生モデル、次の図に示されているように。 軽量の学生モデルは、教師よりもモデルパラメーターが少ないため、メモリの要件が削減され、より小さい、安価なインスタンスでの展開が可能になります。 生徒は、教師モデルの出力から学習することで小さくても、許容精度を維持します。

教師モデルはKD中は変わらないままですが、生徒モデルは、教師モデルの出力ロジットをラベルとして使用して損失を計算することをトレーニングします。 このKDパラダイムを使用すると、教師と生徒の両方がトレーニングのために単一のGPUメモリにいる必要があります。 KTは当初、学生モデルを訓練するために内部のオンプレミス環境で100つのGPU(A80 40 GB)を使用しましたが、プロセスは300のエポックをカバーするのに約XNUMX日かかりました。 トレーニングを加速し、より少ない時間で学生モデルを生成するために、KTはAWSと提携しました。 一緒に、チームはモデルトレーニング時間を大幅に短縮しました。 この投稿では、チームがどのように使用したかについて説明します Amazon SageMaker トレーニング SageMakerデータ並列処理ライブラリ, Amazon SageMakerデバッガ, Amazon SageMaker プロファイラー 軽量のAIフードタグモデルを正常に開発する。
SageMaker を使用した分散トレーニング環境の構築
SageMaker Training は、AWS 上のマネージド機械学習 (ML) トレーニング環境であり、次の図に示すように、トレーニング エクスペリエンスを簡素化し、分散コンピューティングで役立つ一連の機能とツールを提供します。
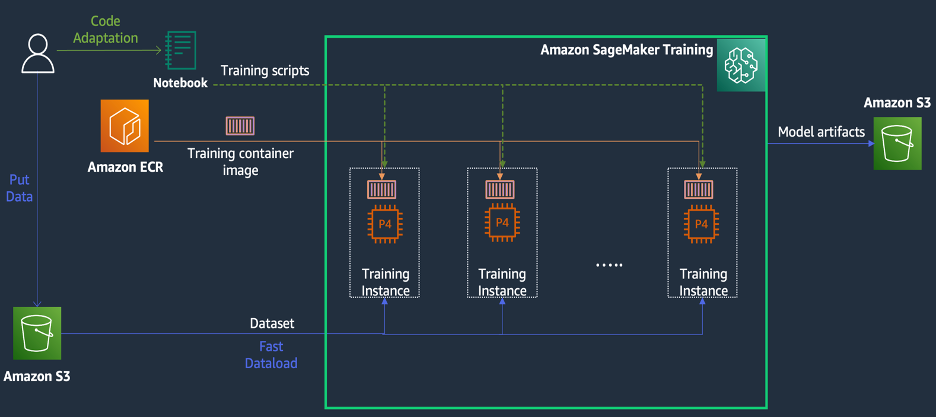
Sagemakerのお客様は、モデルトレーニングに必要なさまざまなプリインストールされたディープラーニングフレームワークと、必要なLinux、NCCL、およびPythonパッケージを備えた組み込みのDocker画像にアクセスすることもできます。 モデルトレーニングを実行したいデータサイエンティストまたはMLエンジニアは、トレーニングインフラストラクチャの構成やDockerの管理、およびさまざまなライブラリの互換性を担当することなく、そうすることができます。
1 日間のワークショップ中に、KT の AWS アカウント内で SageMaker に基づく分散トレーニング構成をセットアップし、SageMaker Distributed Data Parallel (DDP) ライブラリを使用して KT のトレーニング スクリプトを高速化し、さらに 4 つの ml を使用してトレーニング ジョブをテストすることができました。 p24d.XNUMXxlarge インスタンス。 このセクションでは、AWS チームと協力し、SageMaker を使用してモデルを開発した KT の経験について説明します。
概念実証では、分散トレーニング中にAWSインフラストラクチャ用に最適化されたSagemaker DDPライブラリを使用して、トレーニングジョブをスピードアップしたかったのです。 Pytorch DDPからSagemaker DDPに変更するには、 torch_smddp パッケージ化してバックエンドを次のように変更します smddp、次のコードに示すように:
SageMaker DDP ライブラリの詳細については、以下を参照してください。 Sagemakerのデータ並列性ライブラリ.
SageMaker デバッガーとプロファイラーを使用してトレーニング速度が遅い原因を分析する
トレーニング ワークロードを最適化し、加速するための最初のステップには、ボトルネックが発生している場所を理解し、診断することが含まれます。 KT のトレーニング ジョブでは、データ ローダー、前方パス、および後方パスの反復ごとのトレーニング時間を測定しました。
| 1 Iter Time - Dataloader:0.00053秒、フォワード:7.77474秒、後方: 1.58002 ドライ |
| 2 Iter Time - Dataloader:0.00063秒、フォワード:0.67429秒、後方: 24.74539 ドライ |
| 3 Iter Time - Dataloader:0.00061秒、フォワード:0.90976秒、後方: 8.31253 ドライ |
| 4 Iter Time - Dataloader:0.00060秒、フォワード:0.60958秒、後方: 30.93830 ドライ |
| 5 Iter Time - Dataloader:0.00080秒、フォワード:0.83237秒、後方: 8.41030 ドライ |
| 6 Iter Time - Dataloader:0.00067秒、フォワード:0.75715秒、後方: 29.88415 ドライ |
各反復の標準出力の時間を確認すると、バックワード パスの実行時間が反復ごとに大幅に変動していることがわかりました。 この変動は異常であり、合計トレーニング時間に影響を与える可能性があります。 この一貫性のないトレーニング速度の原因を見つけるために、まずシステム モニター (SageMaker デバッガー UI) を利用してリソースのボトルネックを特定しようとしました。これにより、SageMaker Training でトレーニング ジョブをデバッグしたり、マネージド トレーニング プラットフォームなどのリソースのステータスを表示したりできます。設定された秒数内の CPU、GPU、ネットワーク、および I/O。
Sagemaker Debugger UIは、トレーニングジョブでボトルネックを特定して診断するのに役立つ詳細かつ不可欠なデータを提供します。 具体的には、インスタンステーブルごとにCPU使用率ラインチャートとCPU/GPU利用ヒートマップが目を引きました。
CPU利用ラインチャートでは、一部のCPUが100%使用されていることに気付きました。
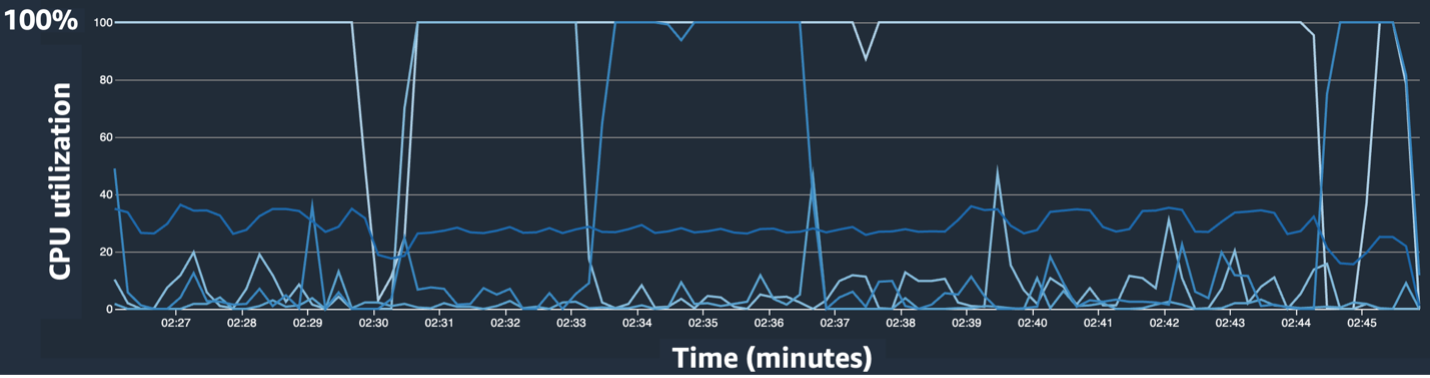
ヒートマップ(暗い色がより高い利用率を示している)では、いくつかのCPUコアがトレーニングを通して高い利用率が高いのに対し、GPUの利用は時間の経過とともに一貫して高くはありませんでした。

ここから、トレーニング速度が遅い理由のXNUMXつはCPUボトルネックであると疑い始めました。 トレーニングスクリプトコードを確認して、何かがCPUボトルネックを引き起こしているかどうかを確認しました。 最も疑わしい部分は、の大きな値でした num_workers データ ローダーではこの値が 0 または 1 に変更され、CPU 使用率が削減されました。 次に、トレーニング ジョブを再度実行し、結果を確認しました。
次のスクリーンショットは、CPUボトルネックを緩和した後のCPU使用率ラインチャート、GPU利用、ヒートマップを示しています。
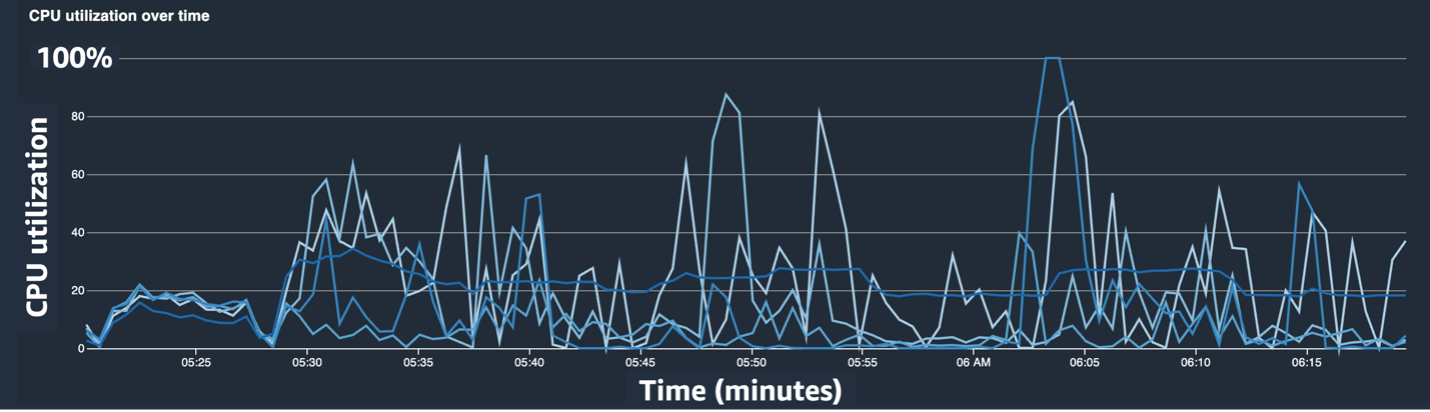


変えるだけで num_workers、CPU使用率の大幅な減少とGPU利用率の全体的な増加が見られました。 これは、トレーニング速度を大幅に改善する重要な変更でした。 それでも、GPU使用率を最適化できる場所を確認したかったのです。 このために、Sagemaker Profilerを使用しました。
SageMaker Profiler は、トレーニング スクリプト内の GPU と CPU の使用率メトリクスや GPU/CPU のカーネル消費量の追跡など、オペレーションによる使用率を可視化することで、最適化の手がかりを特定するのに役立ちます。 これは、どの操作がリソースを消費しているかをユーザーが理解するのに役立ちます。 まず、SageMaker Profiler を使用するには、以下を追加する必要があります ProfilerConfig 次のコードに示すように、Sagemaker SDKを使用してトレーニングジョブを呼び出す関数に。
Sagemaker Python SDKでは、 annotate SageMaker Profiler がプロファイリングを必要とするトレーニング スクリプト内のコードまたはステップを選択するための関数。 以下は、トレーニング スクリプトで SageMaker Profiler に対して宣言する必要があるコードの例です。
前述のコードを追加した後、トレーニング スクリプトを使用してトレーニング ジョブを実行すると、一定期間のトレーニングの実行後に GPU カーネルによって消費された操作に関する情報を取得できます (次の図を参照)。 KT のトレーニング スクリプトの場合、XNUMX エポック実行して次の結果が得られました。
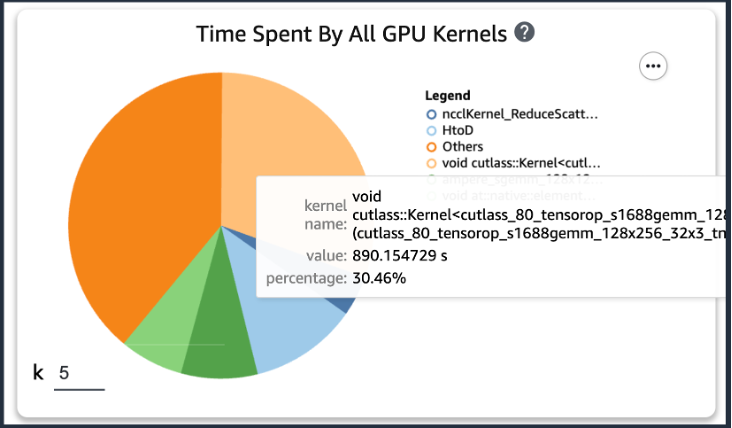
SageMaker Profiler の結果のうち、GPU カーネルの演算消費時間の上位 XNUMX つを確認したところ、KT トレーニング スクリプトでは、一般行列乗算 (GEMM) 演算である行列積演算に最も多くの時間が消費されていることがわかりました。 GPU 上で。 SageMaker Profiler からのこの重要な洞察をもとに、これらの操作を高速化し、GPU 使用率を向上させる方法の調査を開始しました。
トレーニング時間をスピードアップします
マトリックス増殖の計算時間を短縮するさまざまな方法を確認し、XNUMXつのPytorch関数を適用しました。
Shard Optimizerは、ZeroredUndancyOptimizerを備えています
あなたがもし ゼロ冗長オプティマイザー(ゼロ)DeepSpeed/ZeRO テクニックを使用すると、モデルが使用するメモリの冗長性を排除することで、より優れたトレーニング速度で大規模なモデルを効率的にトレーニングできます。 ZeroredUndancyOptimizer Pytorchでは、オプティマイザー状態をシャードする手法を使用して、分散データ並列(DDP)のプロセスごとにメモリ使用量を削減します。 DDPは、バックワードパスの同期された勾配を使用して、すべてのオプティマイザーレプリカが同じパラメーターと勾配値を反復するようにしますが、すべてのモデルパラメーターを持つ代わりに、各オプティマイザー状態は、メモリ使用量を減らすために異なるDDPプロセスのみをシャードすることによって維持されます。
これを使用するには、既存のオプティマイザーをそのままにしておくことができます。 optimizer_class そして宣言します ZeroRedundancyOptimizer 残りのモデルパラメータと学習率をパラメータとして使用します。
自動混合精度
自動混合精度(AMP) 一部の操作では torch.float32 データ型を使用し、 トーチ.bfloat16 または、他の人向けのtorch.float16、迅速な計算とメモリ使用量の削減の利便性。 特に、ディープラーニングモデルは通常、計算の分数ビットよりも指数ビットに対してより敏感であるため、TORCH.BFLOAT16はTORCH.FLOAT32の指数ビットと同等であり、最小限の損失で迅速に学習できるようにします。 Torch.Bfloat16は、ML.P100D.4XLARGE、ML.P24DE.4XLARGE、ML.P24XLARGEなど、A5.48 NVIDIAアーキテクチャ(アンペア)以上のインスタンスでのみ実行されます。
アンプを適用するには、宣言できます torch.cuda.amp.autocast 上のコードに示されているトレーニングスクリプトで dtype TORCH.BFLOAT16として。
サージメーカープロファイラーの結果
XNUMX つの関数をトレーニング スクリプトに適用し、XNUMX エポックのトレーニング ジョブを再度実行した後、SageMaker Profiler で GPU カーネルの上位 XNUMX つのオペレーション消費時間を確認しました。 次の図は結果を示しています。
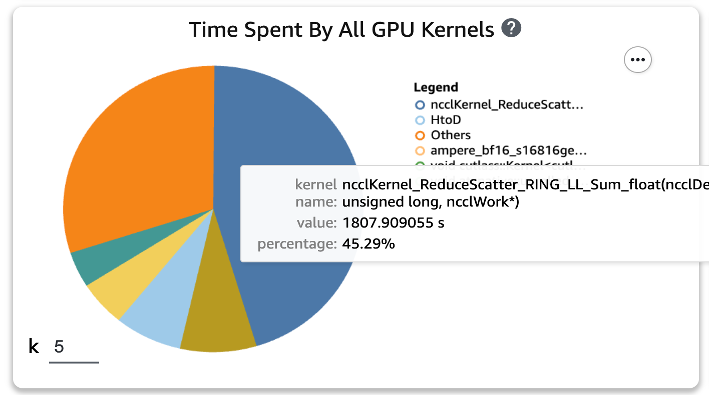
XNUMX つの Torch 関数を適用する前はリストの先頭にあった GEMM 演算が上位 XNUMX つの演算から消え、通常は分散トレーニングで発生する ReduceScatter 演算に置き換えられていることがわかります。
KT蒸留モデルのトレーニング速度結果
128 つのトーチ関数の適用によるメモリ節約を考慮して、トレーニング バッチ サイズをさらに 1152 増やしました。その結果、最終的なバッチ サイズは 1024 ではなく 210 になりました。最終的なスチューデント モデルのトレーニングは、1 日あたり XNUMX エポックを実行できました。 ; KT の内部トレーニング環境と SageMaker の間のトレーニング時間とスピードアップを次の表にまとめます。
| トレーニング環境 | トレーニング用GPUスペック。 | GPUの数 | トレーニング時間(時間) | エポック | エポックあたりの時間数 | 減速比 |
| KTの社内研修環境 | A100(80GB) | 2 | 960 | 300 | 3.20 | 29 |
| アマゾンセージメーカー | A100(40GB) | 32 | 24 | 210 | 0.11 | 1 |
AWSのスケーラビリティにより、トレーニングジョブは、施設で29つではなく32 GPUを使用する前よりも2倍速く完了することができました。 その結果、Sagemakerでより多くのGPUを使用すると、全体的なトレーニングコストに差がなく、トレーニング時間が大幅に短縮されます。
まとめ
KTのConvergence Technology CenterのAI2XL LabのPark Sang-Min(Vision AI Serving Technologyチームリーダー)は、AIフードタグモデルを開発するためにAWSとのコラボレーションについてコメントしました。
「最近、ビジョン分野でトランスベースのモデルが増えているため、モデルのパラメータと必要な GPU メモリが増加しています。 この問題を解決するために軽量化技術を使用していますが、4回の学習に24か月程度と非常に時間がかかります。 AWS とのこの PoC を通じて、SageMaker Profiler と Debugger の助けを借りてリソースのボトルネックを特定し、それらを解決した後、SageMaker のデータ並列処理ライブラリを使用して、XNUMX つの ml.pXNUMXd 上で最適化されたモデル コードを使用してトレーニングを約 XNUMX 日で完了することができました。 XNUMXxlarge インスタンス。」
SageMaker は、Sang-min チームのモデルのトレーニングと開発にかかる時間を数週間節約するのに役立ちました。
Visionモデルでのこのコラボレーションに基づいて、AWSとSagemakerチームは、さまざまなAI/MLの研究プロジェクトでKTと協力して、Sagemaker機能を適用してモデルの開発とサービスの生産性を向上させ続けます。
SageMaker の関連機能の詳細については、以下を確認してください。
著者について
 崔ヨンジュン, AI/ML Expert SA は、開発者、アーキテクト、データ サイエンティストとして、製造、ハイテク、金融などのさまざまな業界のエンタープライズ IT を経験してきました。 彼は、機械学習と深層学習、特にハイパーパラメータの最適化やドメイン適応などのトピックについて研究を実施し、アルゴリズムや論文を発表しました。 AWS では、さまざまな業界にわたる AI/ML を専門とし、分散トレーニング/大規模モデルと MLOps の構築に AWS サービスを使用した技術検証を提供しています。 AI/MLエコシステムの拡大への貢献を目指し、アーキテクチャの提案や検討を行っている。
崔ヨンジュン, AI/ML Expert SA は、開発者、アーキテクト、データ サイエンティストとして、製造、ハイテク、金融などのさまざまな業界のエンタープライズ IT を経験してきました。 彼は、機械学習と深層学習、特にハイパーパラメータの最適化やドメイン適応などのトピックについて研究を実施し、アルゴリズムや論文を発表しました。 AWS では、さまざまな業界にわたる AI/ML を専門とし、分散トレーニング/大規模モデルと MLOps の構築に AWS サービスを使用した技術検証を提供しています。 AI/MLエコシステムの拡大への貢献を目指し、アーキテクチャの提案や検討を行っている。
 ジョン・フン・キム AWS KoreaのアカウントSAです。 ハイテク、製造、金融、公共部門などのさまざまな業界でのアプリケーションの設計、開発、システムモデリングの経験に基づいて、彼はAWSクラウドジャーニーとAWSのワークロードの最適化に取り組んでいます。
ジョン・フン・キム AWS KoreaのアカウントSAです。 ハイテク、製造、金融、公共部門などのさまざまな業界でのアプリケーションの設計、開発、システムモデリングの経験に基づいて、彼はAWSクラウドジャーニーとAWSのワークロードの最適化に取り組んでいます。
 ロックサコン KT R&D の研究員です。 さまざまな分野で視覚AIの研究開発を行っており、主に顔に関する顔属性(性別/メガネ、帽子など)・顔認識技術を行っている。 現在、彼はビジョンモデルの軽量化技術に取り組んでいます。
ロックサコン KT R&D の研究員です。 さまざまな分野で視覚AIの研究開発を行っており、主に顔に関する顔属性(性別/メガネ、帽子など)・顔認識技術を行っている。 現在、彼はビジョンモデルの軽量化技術に取り組んでいます。
 マノジ・ラヴィ Amazon SageMaker のシニアプロダクトマネージャーです。 彼は次世代 AI 製品の構築に情熱を持っており、顧客にとって大規模な機械学習を容易にするソフトウェアやツールの開発に取り組んでいます。 ハース ビジネス スクールで MBA を取得し、カーネギー メロン大学で情報システム管理の修士号を取得しています。 余暇には、マノージはテニスをしたり、風景写真を撮ったりすることを楽しんでいます。
マノジ・ラヴィ Amazon SageMaker のシニアプロダクトマネージャーです。 彼は次世代 AI 製品の構築に情熱を持っており、顧客にとって大規模な機械学習を容易にするソフトウェアやツールの開発に取り組んでいます。 ハース ビジネス スクールで MBA を取得し、カーネギー メロン大学で情報システム管理の修士号を取得しています。 余暇には、マノージはテニスをしたり、風景写真を撮ったりすることを楽しんでいます。
 ロバート・ヴァン・デューセン Amazon Sagemakerのシニアプロダクトマネージャーです。 彼は、ディープラーニングトレーニングのためのフレームワーク、コンパイラ、および最適化技術をリードしています。
ロバート・ヴァン・デューセン Amazon Sagemakerのシニアプロダクトマネージャーです。 彼は、ディープラーニングトレーニングのためのフレームワーク、コンパイラ、および最適化技術をリードしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/kts-journey-to-reduce-training-time-for-a-vision-transformers-model-using-amazon-sagemaker/

