教師なし機械学習 アナリティクスは、次のような強力なツールとして登場しました。 異常検出 今日のデータが豊富な状況では、特に機械生成データの量が増加しています。インストリーム異常検出により、データ異常に対するリアルタイムの洞察が得られ、プロアクティブな対応が可能になります。 Amazon OpenSearch サーバーレス シームレスなスケーラビリティの提供と検索ワークロードの管理に重点を置きます。 Amazon OpenSearch の取り込み は、インデックス付きデータの異常検出のための堅牢なソリューションを提供することでこれを補完します。
この投稿では、OpenSearch Ingestion を使用して、独自の AWS 環境内でインストリーム異常検出を実行できるソリューションを提供します。
OpenSearch インジェストによるインストリーム異常検出
OpenSearch Ingestion により、インストリーム異常検出のプロセスが簡単かつ低コストになります。インストリーム異常検出により、インデックス作成を節約し、ビッグデータを処理するための膨大なリソースの必要性を回避できます。これにより、組織は適切なリソースを適切なタイミングで適用できるようになり、大規模なデータを効率的に管理し、コストを節約できます。ピア フォワーダーと集約プロセッサを使用すると、処理がより複雑になり、コストがかかる可能性があります。 OpenSearch インジェストはこれらの問題を軽減します。
インストリーム異常検出のための OpenSearch Ingestion 構成 YAML を示すユースケースを見てみましょう。
ソリューションの概要
この例では、ランダム カット フォレスト異常検出器を使用して 5 分間のログ数を監視する OpenSearch Ingestion のセットアップについて説明します。また、生のログにインデックスを付けて、受信データ フローの包括的なデモンストレーションを提供します。ユースケースで生のログの分析が必要な場合は、最初のパイプラインをバイパスしてプロセスを合理化し、インストリームの異常検出に直接集中して、特定された異常のみにインデックスを付けることができます。
次の図は、ソリューションアーキテクチャを示しています。
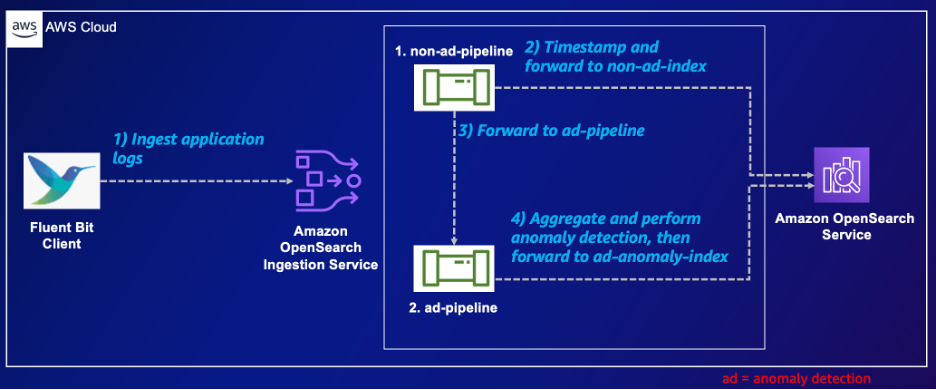
この構成では、5 つの OpenSearch インジェスト パイプラインの概要を説明します。最初の非広告パイプラインは、HTTP データを取り込んでタイムスタンプを付け、広告パイプラインと非広告インデックスの OpenSearch インデックスの両方に転送します。 XNUMX 番目の広告パイプラインは、このデータを受信し、XNUMX 分のウィンドウ内で ID に基づいて集計を実行し、異常検出を実行します。結果はインデックス ad-anomaly-index に保存されます。このセットアップでは、OpenSearch Service 内でのデータ処理、異常検出、ストレージを紹介し、分析機能を強化します。
ソリューションを実装する
ソリューションをセットアップするには、次の手順を実行します。
- パイプラインロールを作成する.
- コレクションを作成する.
- パイプラインを作成する ここでパイプラインの役割を指定します。
パイプラインは、OpenSearch サーバーレス コレクション エンドポイントへのリクエストに署名するためにこの役割を引き受けます。次のパイプライン構成内のキーの値を指定します。
-
sts_role_arn、作成したパイプラインロールの Amazon リソースネーム (ARN) を指定します。 -
hosts、作成したコレクションのエンドポイントを指定します。 - 作成セッションプロセスで
serverless真実に。
必要なパラメータと制限事項に関する詳細なガイドについては、を参照してください。 Amazon OpenSearch インジェスト パイプラインでサポートされているプラグインとオプション.
- 構成を更新した後、選択してパイプライン設定が有効であることを確認します。 パイプラインの検証.
検証が成功すると、次のようなメッセージが表示されます。 「パイプライン構成の検証が成功しました。」次のスクリーンショットに示すように。

検証が失敗した場合は、以下を参照してください。 Amazon OpenSearch サービスのトラブルシューティング トラブルシューティングとガイダンスのために。
OpenSearch インジェストのコスト見積もり
料金は枚数分のみ発生します インジェスト OpenSearch コンピューティング ユニット (取り込み OCU) は、パイプラインを流れるデータがあるかどうかに関係なく、パイプラインに割り当てられます。 OpenSearch Ingestion は、使用状況に基づいてパイプライン容量を拡大または縮小することで、ワークロードに即座に対応します。費用の概要については、こちらをご覧ください。 Amazon OpenSearch の取り込み.
次の表は、指定されたスループットとコンピューティングのニーズに基づいたおおよその月額コストを示しています。平日の午前 8 時から午後 00 時まで操作が行われ、OCU あたり 8 時間あたり 00 ドルのコストがかかると仮定します。
式は次のようになります。 合計コスト/月 = OCU 要件 * OCU 価格 * 時間/日 * 日/月.
| スループット | コンピューティングが必要 (OCU) | 1 か月あたりの総コスト (USD) |
| 1 Gbps | 10 | 576 |
| 10 Gbps | 100 | 5760 |
| 50 Gbps | 500 | 28800 |
| 100 Gbps | 1000 | 57600 |
| 500 Gbps | 5000 | 288000 |
クリーンアップ
ソリューションの使用が完了したら、パイプライン ロール、パイプライン、コレクションなど、作成したリソースを削除します。
まとめ
OpenSearch Ingestion を使用すると、OpenSearch Service によるインストリーム異常検出を探索できます。この投稿の使用例は、OpenSearch Ingestion がどのようにプロセスを簡素化し、より少ないリソースでより多くの成果を達成するかを示しています。これは、ログ レートを分析し、異常通知を生成し、異常に対するプロアクティブな対応を可能にするサービスの機能を示しています。 OpenSearch Ingestion を使用すると、運用効率を向上させ、リアルタイムのリスク管理機能を強化できます。
ご意見やご質問があればコメントに残してください。
著者について
 ルペシュ・ティワリは、AWS ソリューションアーキテクトであり、データ分析、OpenSearch、生成 AI に重点を置いたアプリケーションの最新化を専門としています。彼は、革新的なビジネス成果のためにクラウド テクノロジーを活用するスケーラブルで安全なソリューションを作成することで知られており、コミュニティへの関与や専門知識の共有にも時間を割いています。
ルペシュ・ティワリは、AWS ソリューションアーキテクトであり、データ分析、OpenSearch、生成 AI に重点を置いたアプリケーションの最新化を専門としています。彼は、革新的なビジネス成果のためにクラウド テクノロジーを活用するスケーラブルで安全なソリューションを作成することで知られており、コミュニティへの関与や専門知識の共有にも時間を割いています。
 ムトゥ・ピッチャイマニ Amazon OpenSearch Service の検索スペシャリストです。 彼は大規模な検索アプリケーションとソリューションを構築しています。 Muthu はネットワーキングとセキュリティのトピックに関心があり、テキサス州オースティンを拠点としています。
ムトゥ・ピッチャイマニ Amazon OpenSearch Service の検索スペシャリストです。 彼は大規模な検索アプリケーションとソリューションを構築しています。 Muthu はネットワーキングとセキュリティのトピックに関心があり、テキサス州オースティンを拠点としています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/in-stream-anomaly-detection-with-amazon-opensearch-ingestion-and-amazon-opensearch-serverless/

