概要
毎分飛行機が離着陸する賑やかな空港を想像してみてください。 航空管制官が緊急度に基づいてフライトに優先順位を付けるのと同じように、ヒープは特定の基準に基づいてデータを管理および処理するのに役立ち、最も「緊急」または「重要」なデータが常に上位にアクセスできるようにします。
このガイドでは、ヒープを根本から理解する旅に乗り出します。 まず、ヒープとは何か、そしてその固有の特性をわかりやすく説明することから始めます。 そこから、Python 独自のヒープ実装について詳しく見ていきます。
heapqモジュールを使用して、その豊富な機能セットを探索してください。 したがって、優先度が最も高い (または最も低い) 要素が頻繁に必要となる動的データ セットを効率的に管理する方法を考えたことがあるなら、きっと役に立つでしょう。
ヒープとは何ですか?
ヒープの使用法に入る前に、まず理解しておきたいことは次のとおりです。 ヒープとは何ですか。 ヒープは、データ構造の世界でツリーベースの強力な手段として際立っており、特に次の点に優れています。 秩序と階層を維持する。 素人目には二分木に似ているかもしれませんが、その構造と管理ルールの微妙な違いが明らかに異なります。
ヒープの特徴の XNUMX つは、ヒープの性質です。 完全な二分木。 これは、おそらく最後のレベルを除いて、ツリーのすべてのレベルが完全に埋め尽くされていることを意味します。 この最後のレベル内では、ノードが左から右に配置されます。 このような構造により、配列またはリストを使用してヒープを効率的に表現および操作できるようになり、配列内の各要素の位置がツリー内の配置を反映するようになります。
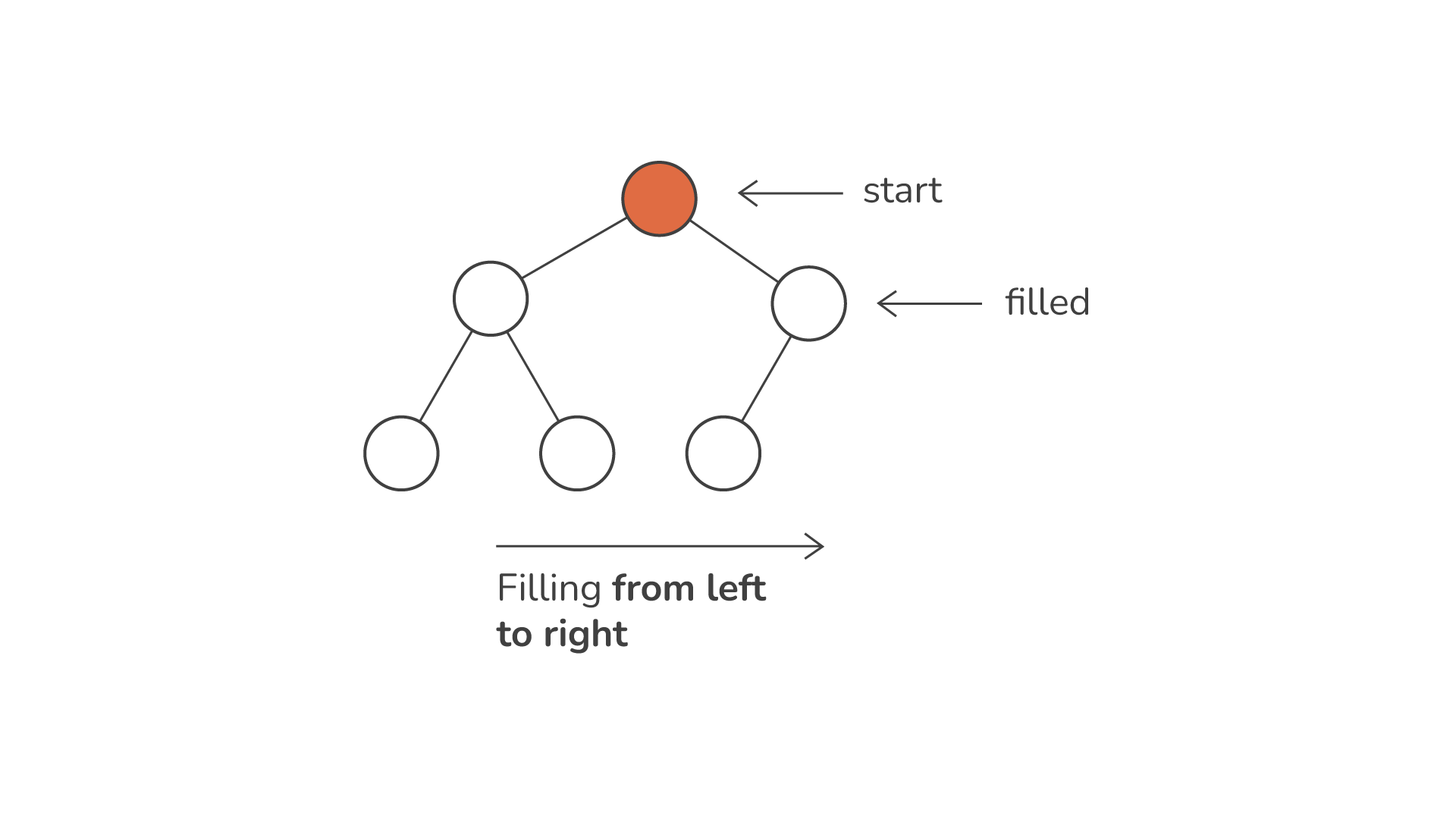
しかし、ヒープの本当の本質は、その中にあります。 発注。 で 最大ヒープ、指定されたノードの値はその子の値を超えるか等しく、最大の要素がルートの右に配置されます。 一方、 最小ヒープ は逆の原則に基づいて動作します。つまり、どのノードの値もその子の値以下になり、最小の要素がルートに配置されるようになります。
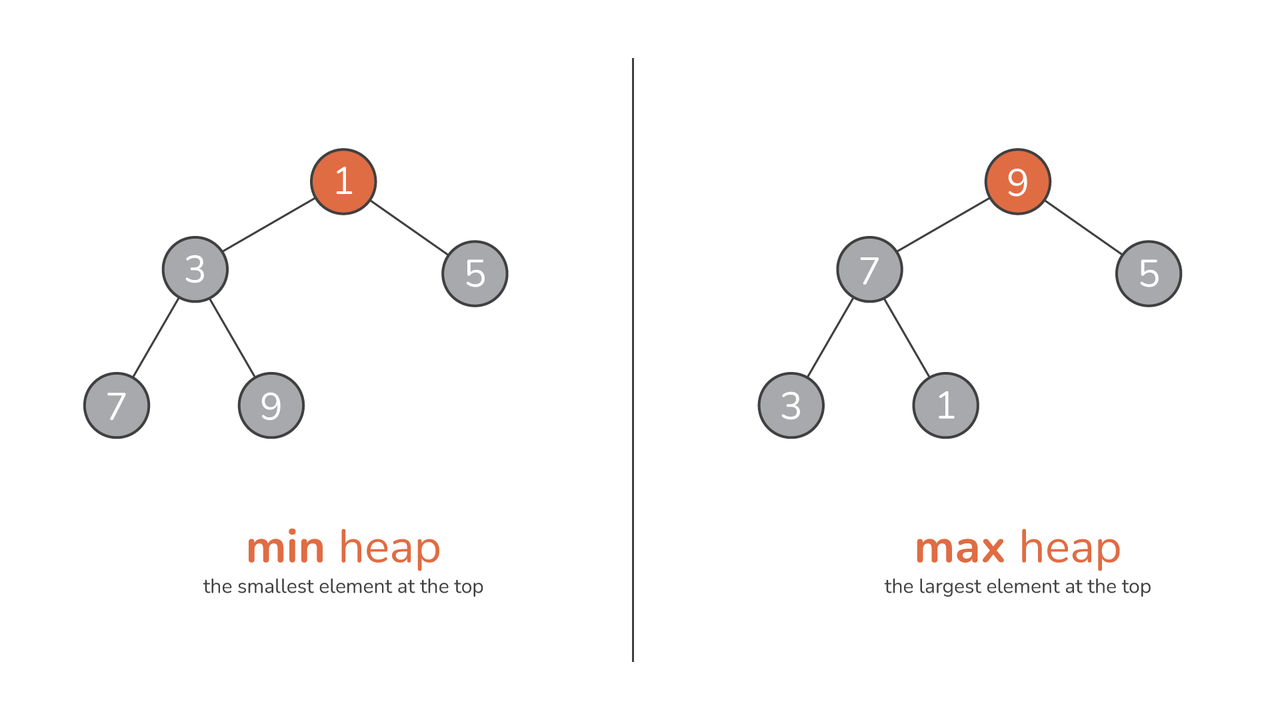
アドバイス: ヒープを次のように視覚化できます。 数字のピラミッド。 最大ヒープの場合、ベースからピークに上がるにつれて数値が増加し、頂点で最大値になります。 対照的に、最小ヒープはピークの最小値から始まり、下に進むにつれて数値が増加します。
作業を進めるにつれて、ヒープのこれらの固有の特性がどのようにして効率的な操作を可能にするのか、そして Python がどのように機能するのかをさらに深く掘り下げていきます。 heapq モジュールは、ヒープをコーディング作業にシームレスに統合します。
ヒープの特徴とプロパティ
ヒープは、その独自の構造と順序付け原理により、一連の明確な特性とプロパティをもたらし、さまざまな計算シナリオで非常に貴重なものになります。
何よりもまず、ヒープは 本質的に効率的。 ツリーベースの構造、特に完全なバイナリ ツリー形式により、優先要素 (最大または最小) の挿入や抽出などの操作を対数時間で実行できるようになります。 O(log n)。 この効率は、優先要素への頻繁なアクセスを必要とするアルゴリズムやアプリケーションにとって有益です。
ヒープのもう XNUMX つの注目すべき特性は、 メモリ効率。 ヒープは子ノードまたは親ノードへの明示的なポインタを必要とせずに配列またはリストを使用して表現できるため、スペースが節約されます。 配列内の各要素の位置はツリー内の配置に対応するため、予測可能で簡単なトラバースと操作が可能になります。
最大ヒープまたは最小ヒープのいずれであっても、ヒープの順序付けプロパティにより、次のことが保証されます。 ルートは常に最も優先度の高い要素を保持します。 この一貫した順序により、構造全体を検索することなく、最優先の要素に素早くアクセスできるようになります。
さらに、ヒープは 多才な。 バイナリ ヒープ (各親に最大 XNUMX つの子を持つ) が最も一般的ですが、ヒープは XNUMX つ以上の子を持つように一般化できます。 d-ary ヒープ。 この柔軟性により、特定の使用例やパフォーマンス要件に基づいた微調整が可能になります。
最後に、ヒープは 自動調整。 要素が追加または削除されるたびに、構造はそのプロパティを維持するために再配置されます。 この動的なバランシングにより、ヒープは常にそのコア操作に対して最適化された状態に保たれます。
アドバイス: これらの特性により、ヒープ データ構造は効率的な並べ替えアルゴリズム (ヒープ ソート) に適したものになりました。 Python でのヒープ ソートの詳細については、こちらをお読みください。 「Python でのヒープソート」 記事。
Python の実装と実際のアプリケーションを深く掘り下げると、ヒープの真の可能性が目の前に明らかになります。
ヒープの種類
すべてのヒープが同じように作成されるわけではありません。 ヒープはその順序と構造特性に応じてさまざまなタイプに分類でき、それぞれに独自の用途と利点があります。 XNUMX つの主要なカテゴリは次のとおりです 最大ヒープ & 最小ヒープ.
最も際立った特徴は、 最大ヒープ つまり、特定のノードの値がその子の値以上であるということです。 これにより、ヒープ内の最大の要素が常にルートに存在するようになります。 このような構造は、特定の優先キューの実装のように、最大要素に頻繁にアクセスする必要がある場合に特に便利です。
最大ヒープに相当するもの、 最小ヒープ 指定されたノードの値がその子の値以下であることを保証します。 これにより、ヒープの最小要素がルートに配置されます。 最小ヒープは、リアルタイム データ処理を扱うアルゴリズムなど、最小限の要素が最も重要であるシナリオでは非常に貴重です。
これらの主なカテゴリに加えて、ヒープは分岐要素に基づいて区別することもできます。
バイナリ ヒープが最も一般的で、各親には最大でも XNUMX つの子がありますが、ヒープの概念は XNUMX つ以上の子を持つノードに拡張できます。 で d-aryヒープ、各ノードには最大でも d 子供たち。 このバリエーションは、特定の操作を高速化するためにツリーの高さを下げるなど、特定のシナリオに合わせて最適化できます。
二項ヒープ は、再帰的に定義される二項ツリーのセットです。 二項ヒープは優先キューの実装で使用され、効率的なマージ操作を提供します。
有名なフィボナッチ数列にちなんで名付けられました。 フィボナッチヒープ バイナリ ヒープまたは二項ヒープと比較して、多くの操作の実行時間が短縮されます。 これらは、ネットワーク最適化アルゴリズムで特に役立ちます。
Python のヒープ実装 – ヒープク モジュール
Python は、ヒープ操作用の組み込みモジュールを提供します。 heapq モジュール。 このモジュールは、開発者がカスタム実装を必要とせずにリストをヒープに変換し、さまざまなヒープ操作を実行できるようにするヒープ関連関数のコレクションを提供します。 このモジュールの微妙な違いと、それがどのようにヒープの力をもたらすかについて詳しく見てみましょう。
heapq モジュールは個別のヒープ データ型を提供しません。 代わりに、通常の Python リストで動作し、リストを変換して次のように扱う関数を提供します。 バイナリヒープ.
このアプローチはメモリ効率が高く、Python の既存のデータ構造とシームレスに統合されます。
つまり、 ヒープはリストとして表現されます in heapq。 この表現の美しさはそのシンプルさです。ゼロから始まるリスト インデックス システムは暗黙的なバイナリ ツリーとして機能します。 位置にある任意の要素に対して i、 その:
- 左側の子が位置にあります
2*i + 1 - 右の子が位置にいます
2*i + 2 - 親ノードは の位置にあります
(i-1)//2
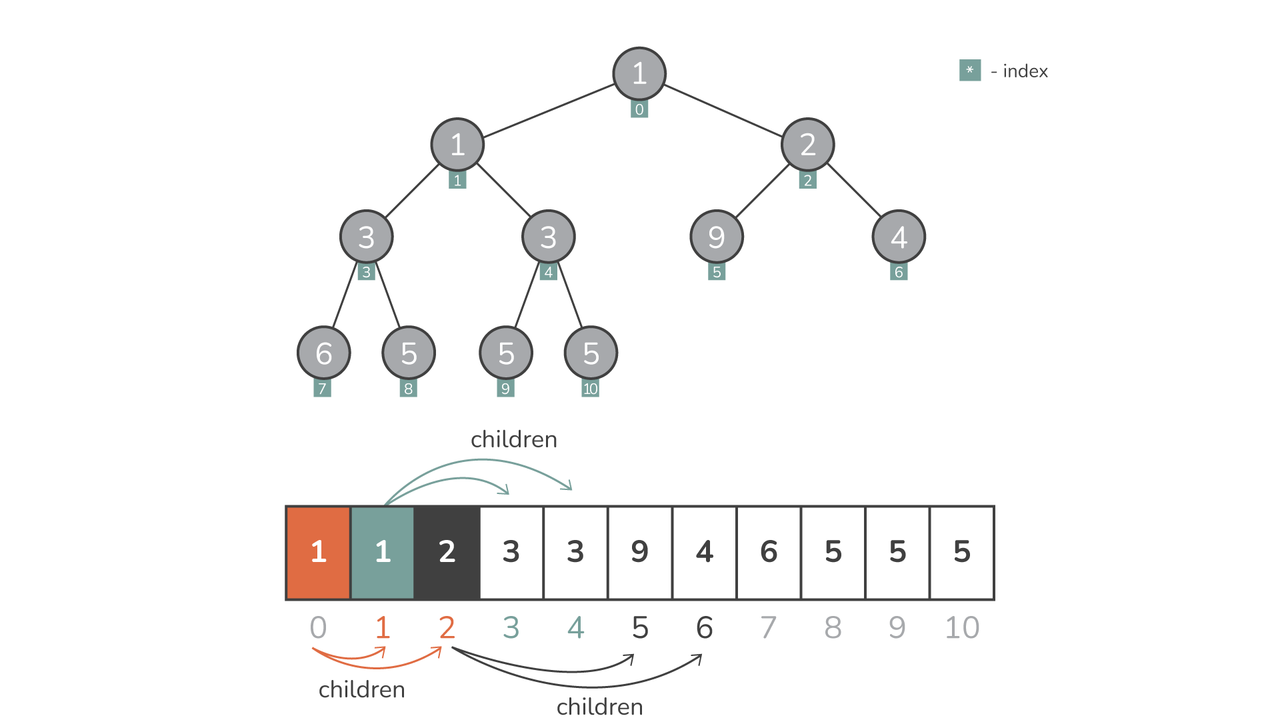
この暗黙的な構造により、個別のノードベースのバイナリ ツリー表現が不要になり、操作が簡単になり、メモリ使用量が最小限に抑えられます。
スペースの複雑さ: ヒープは通常、バイナリ ツリーとして実装されますが、子ノードの明示的なポインタを格納する必要はありません。 これにより、スペース効率が向上し、スペースの複雑さが軽減されます。 O(N) n 個の要素を格納します。
重要な注意点は、 heapq モジュール デフォルトで最小ヒープを作成します。 これは、最小の要素が常にルート (またはリストの最初の位置) にあることを意味します。 最大ヒープが必要な場合は、要素に次の値を乗算して順序を反転する必要があります。 -1 またはカスタム比較関数を使用します。
Pythonの heapq モジュールは、開発者がリストに対してさまざまなヒープ操作を実行できるようにする一連の関数を提供します。
注: 使用するには heapq アプリケーション内のモジュールを使用するには、単純なメソッドを使用してインポートする必要があります。 import heapq.
次のセクションでは、これらの基本的な操作をそれぞれ深く掘り下げ、その仕組みとユースケースを探っていきます。
リストをヒープに変換する方法
heapify() function は、多くのヒープ関連タスクの開始点です。 これは反復可能 (通常はリスト) を受け取り、最小ヒープのプロパティを満たすようにその要素をその場で再配置します。
ベストプラクティス、業界で認められた標準、および含まれているチートシートを含む、Gitを学習するための実践的で実用的なガイドを確認してください。 グーグルGitコマンドを停止し、実際に 学ぶ それ!
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
heapq.heapify(data)
print(data)
これにより、有効な最小ヒープを表す並べ替えられたリストが出力されます。
[1, 1, 2, 3, 3, 9, 4, 6, 5, 5, 5]
時間計算量: を使用して、順序なしリストをヒープに変換します。 heapify 関数は O(N) 手術。 これは直観に反するように思えるかもしれませんが、そうであると予想されるかもしれません。 O(nlogn)ですが、ツリー構造の特性により、線形時間で達成できます。
ヒープに要素を追加する方法
heappush() 関数を使用すると、ヒープのプロパティを維持しながら新しい要素をヒープに挿入できます。
import heapq heap = []
heapq.heappush(heap, 5)
heapq.heappush(heap, 3)
heapq.heappush(heap, 7)
print(heap)
コードを実行すると、最小ヒープ プロパティを維持する要素のリストが表示されます。
[3, 5, 7]
時間計算量: ヒープへの挿入操作 (ヒープ プロパティを維持しながら新しい要素をヒープに配置する操作) の時間計算量は次のとおりです。 O(logn)。 これは、最悪の場合、要素がリーフからルートまで移動しなければならない可能性があるためです。
ヒープから最小の要素を削除して返す方法
heappop() 関数は、ヒープ (最小ヒープ内のルート) から最小の要素を抽出して返します。 削除後も、リストが有効なヒープのままであることが保証されます。
import heapq heap = [1, 3, 5, 7, 9]
print(heapq.heappop(heap))
print(heap)
注: heappop() は、ヒープ ソート アルゴリズムなど、要素を昇順で処理する必要があるアルゴリズムや、タスクが緊急度に基づいて実行される優先キューを実装する場合に非常に役立ちます。
これにより、最小の要素と残りのリストが出力されます。
1
[3, 7, 5, 9]
ここでは、 1 からの最小要素です heap、残りのリストは、削除した後でもヒープ プロパティを維持します。 1.
時間計算量: ルート要素 (最小ヒープ内で最小のもの、または最大ヒープ内で最大のもの) を削除し、ヒープを再編成する場合にも時間がかかります。 O(logn) 時間。
新しいアイテムをプッシュして最小のアイテムをポップする方法
heappushpop() 関数は、新しい項目をヒープにプッシュし、次にヒープから最小の項目をポップして返す複合操作です。
import heapq heap = [3, 5, 7, 9]
print(heapq.heappushpop(heap, 4)) print(heap)
これは出力します 3、最小の要素、新しい要素を出力します。 heap 現在含まれているリスト 4 ヒープのプロパティを維持しながら:
3
[4, 5, 7, 9]
注: 使い方 heappushpop() この関数は、新しい要素をプッシュし、最小の要素をポップする操作を個別に実行するよりも効率的です。
最小のアイテムを置き換えて新しいアイテムをプッシュする方法
heapreplace() 関数は、最小の要素をポップし、新しい要素をヒープにプッシュします。これをすべて XNUMX 回の効率的な操作で実行します。
import heapq heap = [1, 5, 7, 9]
print(heapq.heapreplace(heap, 4))
print(heap)
これは印刷します 1、最小の要素、リストには 4 が含まれ、ヒープ プロパティが維持されます。
1
[4, 5, 7, 9]
Note: heapreplace() ローリング ウィンドウ操作やリアルタイム データ処理タスクなど、現在の最小要素を新しい値に置き換えるストリーミング シナリオで有益です。
Python のヒープ内で複数の極値を見つける
nlargest(n, iterable[, key]) & nsmallest(n, iterable[, key]) 関数は、反復可能オブジェクトから複数の最大または最小の要素を取得するように設計されています。 少数の極値のみが必要な場合は、反復可能全体をソートするより効率的です。 たとえば、次のリストがあり、リスト内で XNUMX つの最小値と XNUMX つの最大値を見つけたいとします。
data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
ここでは、 nlargest() & nsmallest() 関数は便利です:
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
print(heapq.nlargest(3, data)) print(heapq.nsmallest(3, data)) これにより XNUMX つのリストが得られます。XNUMX つは XNUMX つの最大値を含み、もう XNUMX つは、 data リスト:
[9, 6, 5]
[1, 1, 2]
カスタム ヒープを構築する方法
一方、パイソンは heapq モジュールはヒープを操作するための強力なツールのセットを提供しますが、デフォルトの最小ヒープ動作では十分ではないシナリオがあります。 最大ヒープの実装を検討している場合でも、カスタム比較関数に基づいて動作するヒープが必要な場合でも、カスタム ヒープを構築することが解決策となる可能性があります。 特定のニーズに合わせてヒープを調整する方法を見てみましょう。
を使用して最大ヒープを実装する heapq
デフォルトでは、 heapq 作成します。 最小ヒープ。 ただし、簡単なトリックを使用すると、最大ヒープを実装することができます。 このアイデアは、要素に次の値を乗算して要素の順序を反転することです。 -1 ヒープに追加する前に:
import heapq class MaxHeap: def __init__(self): self.heap = [] def push(self, val): heapq.heappush(self.heap, -val) def pop(self): return -heapq.heappop(self.heap) def peek(self): return -self.heap[0]
このアプローチでは、(絶対値に関して) 最大の数が最小になり、 heapq 最大ヒープ構造を維持する機能。
カスタム比較関数を使用したヒープ
場合によっては、要素の自然な順序に基づいて比較するだけではないヒープが必要になることがあります。 たとえば、複雑なオブジェクトを扱っている場合、または特定の並べ替え基準がある場合、カスタム比較関数が不可欠になります。
これを実現するには、比較演算子をオーバーライドするヘルパー クラスで要素をラップします。
import heapq class CustomElement: def __init__(self, obj, comparator): self.obj = obj self.comparator = comparator def __lt__(self, other): return self.comparator(self.obj, other.obj) def custom_heappush(heap, obj, comparator=lambda x, y: x < y): heapq.heappush(heap, CustomElement(obj, comparator)) def custom_heappop(heap): return heapq.heappop(heap).obj
この設定を使用すると、任意のカスタム コンパレータ関数を定義し、それをヒープで使用できます。
まとめ
ヒープは多くの操作に対して予測可能なパフォーマンスを提供するため、優先度ベースのタスクにとって信頼できる選択肢となります。 ただし、当面のアプリケーションの特定の要件と特性を考慮することが重要です。 場合によっては、ヒープの実装を調整したり、代替のデータ構造を選択したりすることで、実際のパフォーマンスが向上する可能性があります。
これまで説明してきたように、ヒープは単なるデータ構造ではありません。 それらは、効率、構造、適応性の融合を表しています。 基本的なプロパティから Python での実装まで heapq モジュール、ヒープは、無数の計算上の課題、特に優先順位を中心とした課題に対する堅牢なソリューションを提供します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://stackabuse.com/guide-to-heaps-in-python/

