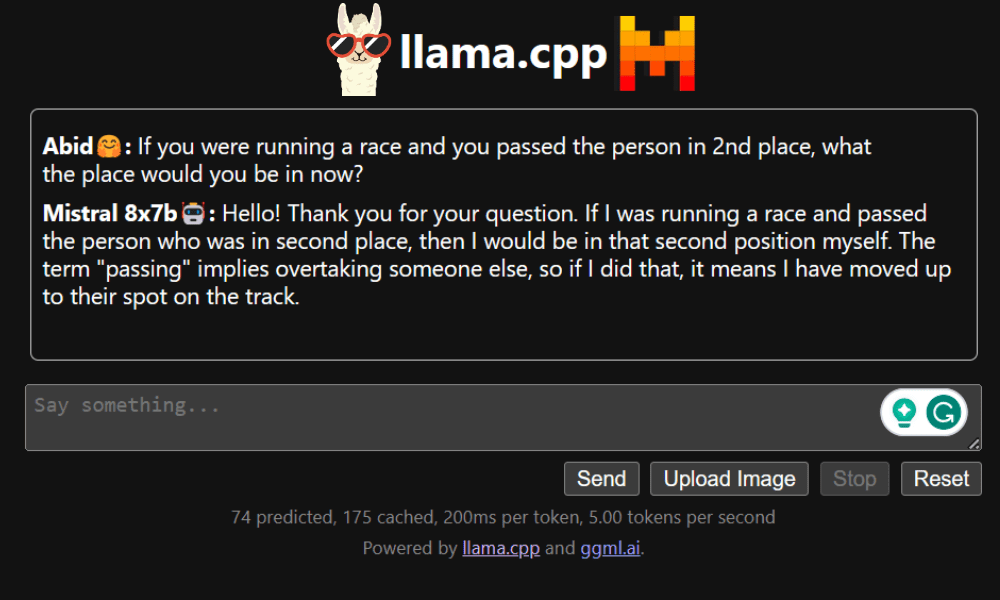
著者による画像
この投稿では、Mixtral 8x7b と呼ばれる新しい最先端のオープンソース モデルについて説明します。また、LLaMA C++ ライブラリを使用してそれにアクセスする方法と、削減されたコンピューティングとメモリで大規模な言語モデルを実行する方法も学びます。
ミストラル 8x7b は、Mistral AI によって作成された、オープンウェイトを備えた高品質のスパース混合エキスパート (SMoE) モデルです。 Apache 2.0 でライセンスされており、ほとんどのベンチマークで Llama 2 70B を上回り、6 倍高速な推論を実現します。 Mixtral は、ほとんどの標準ベンチマークで GPT3.5 に匹敵するかそれを上回り、コスト/パフォーマンスの点で最高のオープンウェイト モデルです。
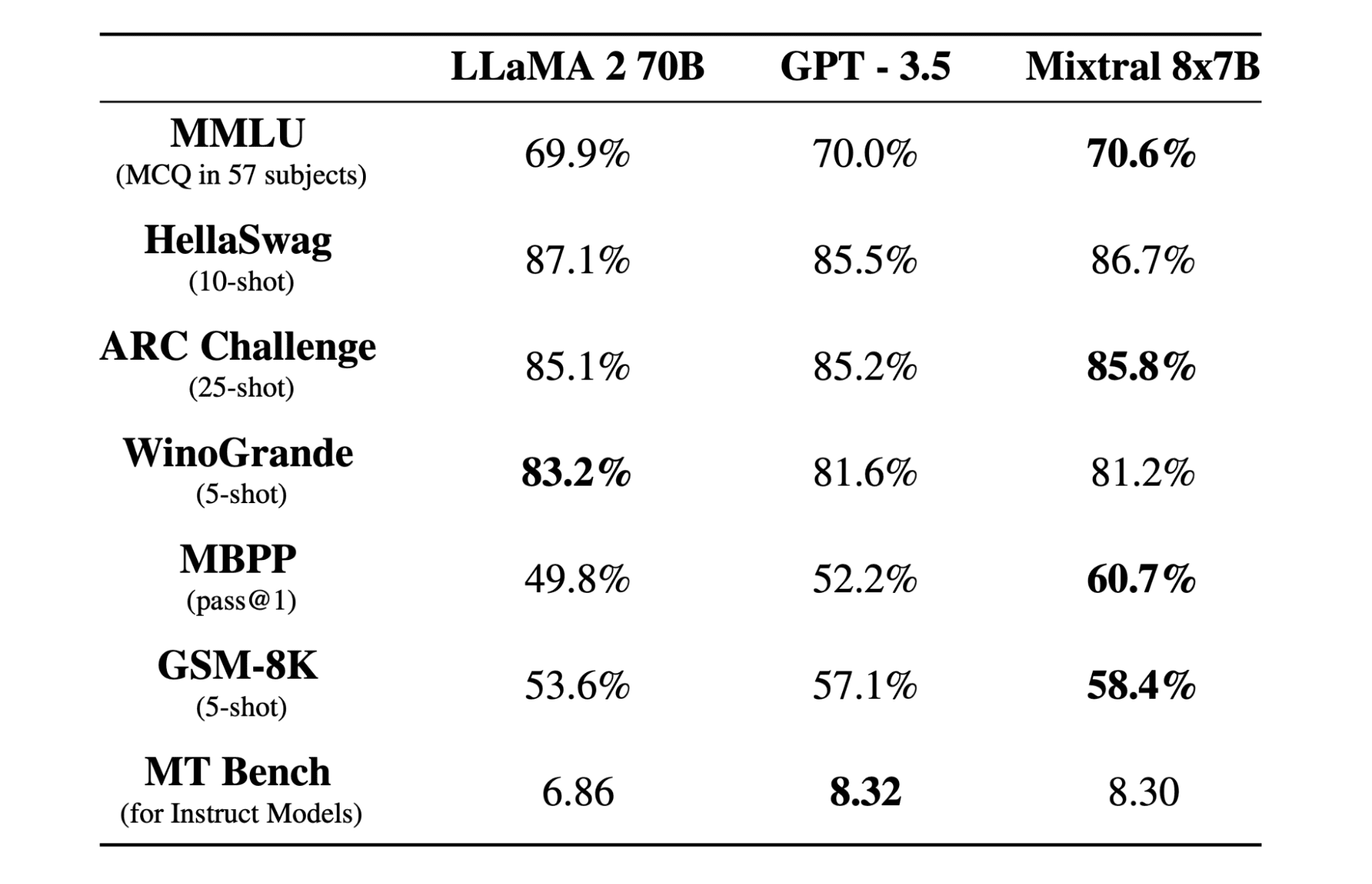
Image from
専門家の混合
Mixtral 8x7B は、デコーダのみの疎な専門家混合ネットワークを使用します。これには、8 つのパラメーター グループから選択するフィードフォワード ブロックが含まれます。ルーター ネットワークはトークンごとにこれらのグループのうち 12.9 つを選択し、その出力を加算的に組み合わせます。この方法では、コストとレイテンシを管理しながらモデルのパラメータ数を強化し、合計 46.7 億のパラメータがあるにもかかわらず、XNUMX 億のモデルと同等の効率性を実現します。
Mixtral 8x7B モデルは、32 トークンの幅広いコンテキストの処理に優れており、英語、フランス語、イタリア語、ドイツ語、スペイン語などの複数の言語をサポートしています。コード生成で強力なパフォーマンスを示し、命令追従モデルに微調整できるため、MT-Bench などのベンチマークで高いスコアを達成できます。
LLaMA.cpp は、Facebook の LLM アーキテクチャに基づいた大規模言語モデル (LLM) 用の高性能インターフェイスを提供する C/C++ ライブラリです。これは、テキストの生成、翻訳、質問応答など、さまざまなタスクに使用できる軽量で効率的なライブラリです。 LLaMA.cpp は、LLaMA、LLaMA 2、Falcon、Alpaca、Mistral 7B、Mixtral 8x7B、GPT4ALL など、幅広い LLM をサポートしています。すべてのオペレーティング システムと互換性があり、CPU と GPU の両方で機能します。
このセクションでは、Colab 上で llama.cpp Web アプリケーションを実行します。数行のコードを記述するだけで、PC または Google Colab 上で新しい最先端モデルのパフォーマンスを体験できるようになります。
スタートガイド
まず、以下のコマンドラインを使用して、llama.cpp GitHub リポジトリをダウンロードします。
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitその後、ディレクトリをリポジトリに変更し、`make` コマンドを使用して llama.cpp をインストールします。 CUDA がインストールされた NVidia GPU 用の llama.cpp をインストールします。
%cd llama.cpp
!make LLAMA_CUBLAS=1モデルをダウンロード
適切なバージョンの `.gguf` モデル ファイルを選択することで、Hugging Face Hub からモデルをダウンロードできます。さまざまなバージョンの詳細については、次のサイトを参照してください。 TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
Image from
TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
コマンド `wget` を使用して、現在のディレクトリにモデルをダウンロードできます。
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufLLaMAサーバーの外部アドレス
LLaMA サーバーを実行すると、Colab では役に立たないローカルホスト IP が与えられます。 Colab カーネル プロキシ ポートを使用してローカルホスト プロキシに接続する必要があります。
以下のコードを実行すると、グローバル ハイパーリンクが取得されます。後でこのリンクを使用して Web アプリにアクセスします。
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/サーバーの実行
LLaMA C++ サーバーを実行するには、サーバー コマンドにモデル ファイルの場所と正しいポート番号を指定する必要があります。ポート番号が、前の手順でプロキシ ポートに対して開始したものと一致していることを確認することが重要です。
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
サーバーがローカルで実行されていないため、前の手順でプロキシ ポートのハイパーリンクをクリックすると、チャット Web アプリにアクセスできます。
LLaMA C++ ウェブアプリ
チャットボットの使用を開始する前に、チャットボットをカスタマイズする必要があります。プロンプトセクションの「LLaMA」をモデル名に置き換えます。さらに、生成された応答を区別するためにユーザー名とボット名を変更します。
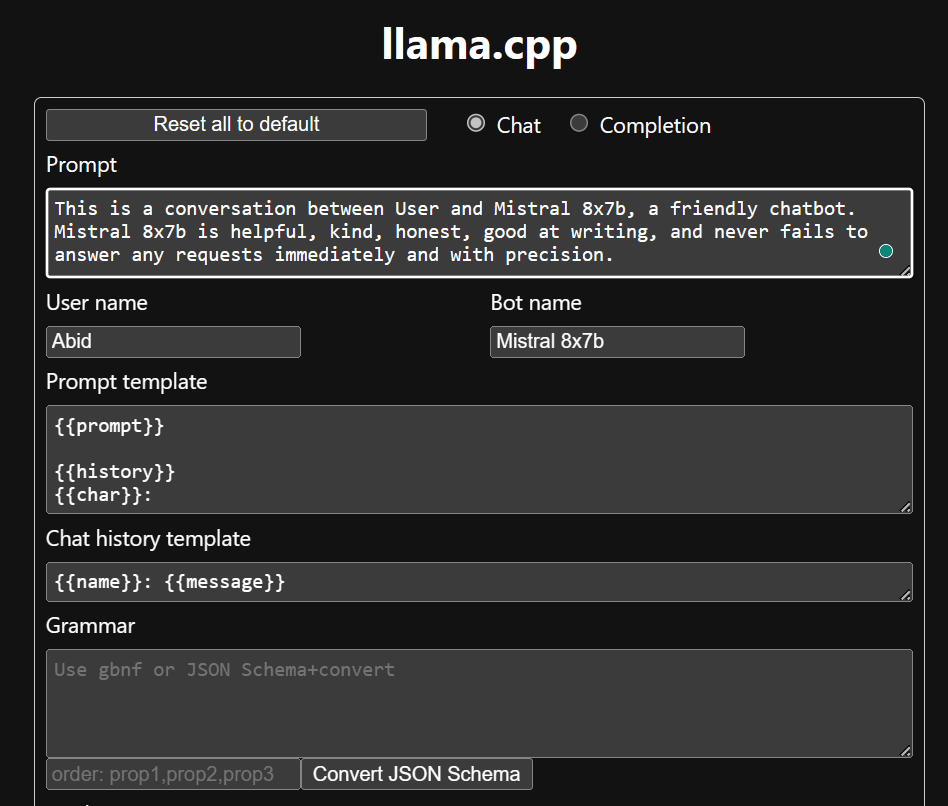
下にスクロールしてチャット セクションに入力してチャットを開始します。他のオープンソース モデルでは適切に答えられなかった技術的な質問を遠慮なくしてください。
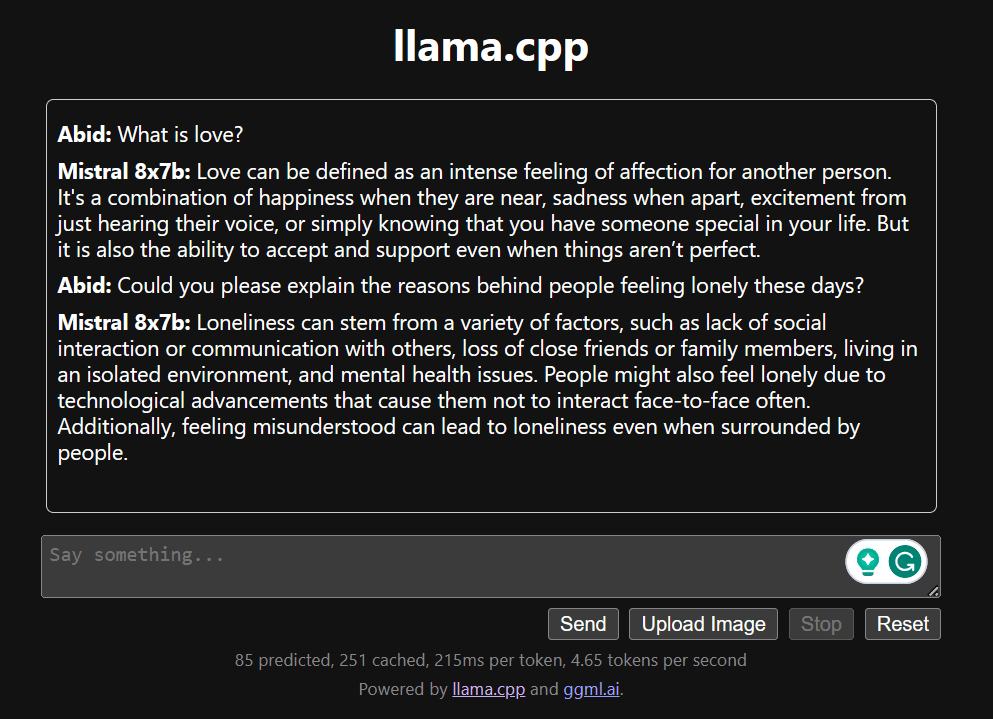
アプリで問題が発生した場合は、Google Colab を使用して自分で実行してみてください: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
このチュートリアルでは、LLaMA C++ ライブラリを使用して、Google Colab 上で高度なオープンソース モデル Mixtral 8x7b を実行する方法についての包括的なガイドを提供します。他のモデルと比較して、Mixtral 8x7b は優れたパフォーマンスと効率を提供するため、大規模な言語モデルを試したいが、広範な計算リソースを持たない人にとっては優れたソリューションになります。ラップトップまたは無料のクラウド コンピューティングで簡単に実行できます。ユーザーフレンドリーで、チャット アプリを展開して他の人が使用したり実験したりすることもできます。
大規模なモデルを実行するためのこの簡単なソリューションがお役に立てば幸いです。私は常にシンプルでより良い選択肢を探しています。もっと良い解決策があればぜひ教えてください。次回はそれについて説明します。
アビッド・アリ・アワン (@ 1abidaliawan)は、機械学習モデルの構築を愛する認定データサイエンティストの専門家です。 現在、彼はコンテンツの作成と、機械学習とデータサイエンステクノロジーに関する技術ブログの執筆に注力しています。 Abidは、技術管理の修士号と電気通信工学の学士号を取得しています。 彼のビジョンは、精神疾患に苦しんでいる学生のためにグラフニューラルネットワークを使用してAI製品を構築することです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free

