大規模言語モデル (LLM) の分散深層学習の分野では、特に 2022 年 5.32 月の ChatGPT のリリース以降、大きな進歩が見られました。LLM のサイズは数十億、さらには数兆のパラメーターを抱えて成長し続けていますが、多くの場合、その規模は大きくなりません。メモリの制限により、GPU などの単一のアクセラレータ デバイス、または ml.p3xlarge などの単一のノードにさえ適合します。 LLM をトレーニングする顧客は、多くの場合、ワークロードを数百、さらには数千の GPU に分散する必要があります。このような規模でのトレーニングを可能にすることは、分散トレーニングでは依然として課題であり、このような大規模なシステムでの効率的なトレーニングも同様に重要な問題です。過去数年にわたり、分散トレーニング コミュニティは、そのような課題に対処するために XNUMXD 並列処理 (データ並列処理、パイプライン並列処理、テンソル並列処理) やその他の技術 (シーケンス並列処理やエキスパート並列処理など) を導入してきました。
2023 年 XNUMX 月に、Amazon は SageMaker モデル並列ライブラリ 2.0 (SMP) は、大規模なモデルのトレーニングで最先端の効率を実現します。 SageMaker 分散データ並列ライブラリ (SMDDP)。このリリースは 1.x からの重要なアップデートです。SMP はオープンソースの PyTorch と統合されました。 完全にシャード化されたデータ並列 (FSDP) API。大規模なモデルをトレーニングするときに使い慣れたインターフェイスを使用でき、次の API と互換性があります。 変圧器エンジン (TE) は、FSDP と並行してテンソル並列処理技術を初めて解放しました。リリースの詳細については、以下を参照してください。 Amazon SageMaker モデルの並列ライブラリにより、PyTorch FSDP ワークロードが最大 20% 高速化されました.
この投稿では、パフォーマンス上の利点について検討します。 アマゾンセージメーカー (SMP および SMDDP を含む)、およびライブラリを使用して SageMaker で大規模なモデルを効率的にトレーニングする方法について説明します。最大 4 インスタンスの ml.p24d.128xlarge クラスターのベンチマークと、Llama 16 モデルの bfloat2 を使用した FSDP 混合精度で SageMaker のパフォーマンスを実証します。 SageMaker のほぼ線形のスケーリング効率のデモンストレーションから開始し、続いて最適なスループットを実現するために各機能からの寄与を分析し、テンソル並列処理による最大 32,768 までのさまざまなシーケンス長での効率的なトレーニングで終わります。
SageMaker によるほぼ線形のスケーリング
LLM モデルの全体的なトレーニング時間を短縮するには、ノード間通信のオーバーヘッドを考慮して、大規模なクラスター (数千の GPU) に拡張するときに高いスループットを維持することが重要です。この投稿では、SMP と SMDDP の両方を呼び出す p4d インスタンスでの堅牢で線形に近いスケーリング (問題の合計サイズが固定されている場合に GPU の数を変更する) 効率を実証します。
このセクションでは、SMP のほぼ線形なスケーリング パフォーマンスを示します。ここでは、2 の固定シーケンス長、集団通信用の SMDDP バックエンド、TE 対応、グローバル バッチ サイズ 7 万、13 ~ 70 個の p4,096d ノードを使用して、さまざまなサイズ (4B、16B、および 128B パラメーター) の Llama 4 モデルをトレーニングします。 。次の表は、最適な構成とトレーニング パフォーマンス (モデルの XNUMX 秒あたりの TFLOPs) をまとめたものです。
| モデルサイズ | ノードの数 | TFLOPs* | SDP* | tp* | オフロード* | スケーリング効率 |
| 7B | 16 | 136.76 | 32 | 1 | N | 視聴者の38%が |
| 32 | 132.65 | 64 | 1 | N | 視聴者の38%が | |
| 64 | 125.31 | 64 | 1 | N | 視聴者の38%が | |
| 128 | 115.01 | 64 | 1 | N | 視聴者の38%が | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 視聴者の38%が |
| 32 | 139.46 | 256 | 1 | N | 視聴者の38%が | |
| 64 | 132.17 | 128 | 1 | N | 視聴者の38%が | |
| 128 | 120.75 | 128 | 1 | N | 視聴者の38%が | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 視聴者の38%が |
| 64 | 149.60 | 256 | 1 | N | 視聴者の38%が | |
| 128 | 136.52 | 64 | 2 | N | 視聴者の38%が |
*指定されたモデル サイズ、シーケンス長、およびノード数で、さまざまな sdp、tp、およびアクティベーション オフロードの組み合わせを検討した後、グローバルに最適なスループットと構成を示します。
上の表は、シャード データ並列 (sdp) 度 (通常はフル シャーディングではなく FSDP ハイブリッド シャーディングを使用します。詳細については次のセクションで説明します)、テンソル並列 (tp) 度、およびアクティベーション オフロード値の変更に応じて最適なスループット数値をまとめています。 SMP と SMDDP のほぼ線形のスケーリングを示しています。たとえば、Llama 2 モデルのサイズが 7B、シーケンス長が 4,096 の場合、全体として、97.0、91.6、および 84.1 ノードでそれぞれ 16%、32%、および 64% (128 ノードに対して) のスケーリング効率を達成します。スケーリング効率はモデル サイズが異なっても安定しており、モデル サイズが大きくなるにつれてわずかに増加します。
SMP と SMDDP は、2,048 や 8,192 などの他のシーケンス長に対しても同様のスケーリング効率を示します。
SageMaker モデル並列ライブラリ 2.0 パフォーマンス: Llama 2 70B
LLM コミュニティでは最先端のパフォーマンスが頻繁に更新されるとともに、過去数年間にわたってモデルのサイズが拡大し続けています。このセクションでは、固定モデル サイズ 2B、シーケンス長 70、グローバル バッチ サイズ 4,096 万を使用した Llama 4 モデルの SageMaker のパフォーマンスを示します。前の表のグローバルに最適な構成とスループット (SMDDP バックエンド、通常は FSDP ハイブリッド シャーディングと TE を使用) と比較するために、次の表は、分散バックエンド (NCCL および SMDDP) の追加の仕様を使用して、他の最適なスループット (潜在的にテンソル並列処理を使用) に拡張しています。 、FSDP シャーディング戦略 (フル シャーディングとハイブリッド シャーディング)、および TE を有効にするかどうか (デフォルト)。
| モデルサイズ | ノードの数 | TFLOPS | TFLOP #3 構成 | ベースラインに対する TFLOPs の改善 | ||||||||
| . | . | NCCL フルシャーディング: #0 | SMDDP フルシャーディング: #1 | SMDDP ハイブリッド シャーディング: #2 | TE を使用した SMDDP ハイブリッド シャーディング: #3 | SDP* | tp* | オフロード* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が | |
*指定されたモデル サイズ、シーケンス長、およびノード数で、さまざまな sdp、tp、およびアクティベーション オフロードの組み合わせを検討した後、グローバルに最適なスループットと構成を示します。
SMP および SMDDP の最新リリースは、ネイティブ PyTorch FSDP、拡張されたより柔軟なハイブリッド シャーディング、トランスフォーマー エンジンの統合、テンソル並列処理、最適化されたオール ギャザー集合操作などの複数の機能をサポートしています。 SageMaker が LLM の効率的な分散トレーニングをどのように実現するかをより深く理解するために、SMDDP と次の SMP からの段階的な貢献を調査します。 コア機能:
- FSDP フル シャーディングによる NCCL に対する SMDDP の強化
- FSDP フル シャーディングをハイブリッド シャーディングに置き換え、通信コストを削減してスループットを向上させます。
- テンソル並列処理が無効になっている場合でも、TE を使用するとスループットがさらに向上します。
- リソース設定が低い場合、アクティベーション オフロードを使用すると、メモリ負荷が高いために実行不可能または非常に遅いトレーニングが可能になる可能性があります。
FSDP フル シャーディング: NCCL に対する SMDDP の拡張
前の表に示されているように、モデルが FSDP で完全にシャーディングされている場合、NCCL (TFLOP #0) と SMDDP (TFLOP #1) のスループットは 32 ノードまたは 64 ノードで同等ですが、NCCL から SMDDP への大幅な向上が 50.4% あります。 128 ノードで。
SMDDP は通信ボトルネックを効果的に軽減できるため、より小さいモデル サイズでは、より小さいクラスター サイズから始めて、NCCL よりも SMDDP による一貫した大幅な改善が見られます。
通信コストを削減するFSDPハイブリッドシャーディング
SMP 1.0 では、 シャードされたデータの並列処理、Amazon 社内で活用された分散トレーニング手法 MiCS テクノロジー。 SMP 2.0 では、SMP ハイブリッド シャーディングを導入しました。これは、FSDP フル シャーディングの場合のように、すべてのトレーニング GPU ではなく、GPU のサブセット間でモデルをシャーディングできるようにする、拡張可能でより柔軟なハイブリッド シャーディング手法です。これは、GPU ごとのメモリ制約を満たすためにクラスター全体でシャーディングする必要がない中規模のモデルに役立ちます。これにより、クラスターに複数のモデル レプリカが存在し、実行時に各 GPU が通信するピアの数が減ります。
SMP のハイブリッド シャーディングにより、メモリ不足の問題が発生しない最小のシャードレベルから、クラスター サイズ全体 (フル シャーディングに相当) まで、広範囲にわたる効率的なモデル シャーディングが可能になります。
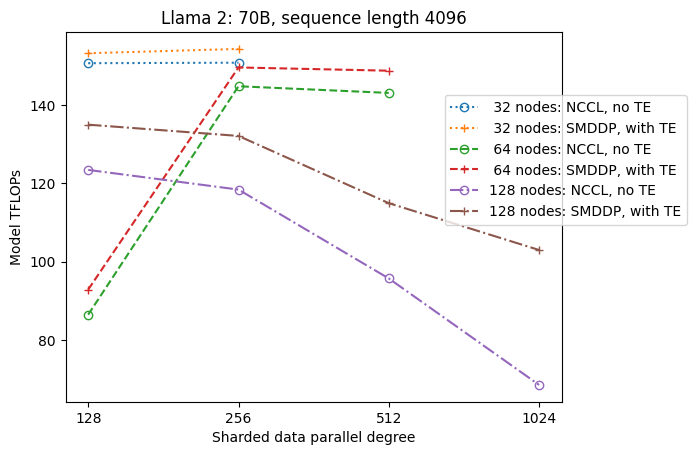
次の図は、簡単にするために tp = 1 での sdp へのスループットの依存性を示しています。これは、前の表の NCCL または SMDDP フル シャーディングの最適な tp 値と必ずしも同じではありませんが、数値は非常に近いです。これは、128 ノードという大きなクラスター サイズでのフル シャーディングからハイブリッド シャーディングへの切り替えの価値を明確に検証しており、NCCL と SMDDP の両方に適用できます。モデル サイズが小さい場合、ハイブリッド シャーディングによる大幅な改善はより小さいクラスター サイズから始まり、その差はクラスター サイズが増加するにつれて増加し続けます。
TE による改善
TE は、NVIDIA GPU での LLM トレーニングを高速化するように設計されています。 FP8 は p4d インスタンスでサポートされていないため使用しませんでしたが、p4d 上で TE を使用すると大幅な高速化が見られます。
SMDDP バックエンドでトレーニングされた MiCS に加えて、TE は、テンソル並列処理が無効になっている場合でも (テンソル並列次数が 128)、すべてのクラスター サイズにわたってスループットの一貫した向上を導入しています (唯一の例外は 1 ノードでのフル シャーディングです)。
モデル サイズが小さい場合やさまざまなシーケンス長の場合、TE ブーストは安定しており、約 3 ~ 7.6% の範囲で簡単ではありません。
低リソース設定でのアクティベーションオフロード
リソース設定が低い場合 (ノード数が少ない場合)、アクティベーション チェックポイントが有効になっていると、FSDP で高いメモリ負荷が発生する可能性があります (最悪の場合はメモリ不足になることもあります)。メモリがボトルネックになっているこのようなシナリオでは、アクティブ化オフロードを有効にすることがパフォーマンスを向上させるオプションになる可能性があります。
たとえば、前に見たように、モデル サイズ 2B、シーケンス長 13 の Llama 4,096 は、アクティベーション チェックポイント機能を使用し、アクティベーション オフロードなしで少なくとも 32 ノードで最適にトレーニングできますが、16 に制限された場合、アクティベーション オフロードを使用すると最高のスループットを達成します。ノード。
長いシーケンスでのトレーニングを有効にする: SMP テンソル並列処理
長い会話やコンテキストにはより長いシーケンス長が望まれており、LLM コミュニティでより注目を集めています。したがって、次の表にさまざまなロングシーケンスのスループットを報告します。この表は、2 から 2,048 までのさまざまなシーケンス長での、SageMaker での Llama 32,768 トレーニングの最適なスループットを示しています。シーケンス長 32,768 では、グローバル バッチ サイズ 32 万で 4 ノードではネイティブ FSDP トレーニングは実行できません。
| . | . | . | TFLOPS | ||
| モデルサイズ | シーケンスの長さ | ノードの数 | ネイティブ FSDP および NCCL | SMP と SMDDP | SMPの改善 |
| 7B | 2048 | 32 | 129.25 | 138.17 | 視聴者の38%が |
| 4096 | 32 | 124.38 | 132.65 | 視聴者の38%が | |
| 8192 | 32 | 115.25 | 123.11 | 視聴者の38%が | |
| 16384 | 32 | 100.73 | 109.11 | 視聴者の38%が | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 視聴者の38%が |
| 4096 | 32 | 133.30 | 139.46 | 視聴者の38%が | |
| 8192 | 32 | 125.04 | 130.08 | 視聴者の38%が | |
| 16384 | 32 | 111.58 | 117.01 | 視聴者の38%が | |
| 32768 | 32 | NA | 92.38 | . | |
| *: 最大 | . | . | . | . | 視聴者の38%が |
| *: 中央値 | . | . | . | . | 視聴者の38%が |
クラスター サイズが大きく、グローバル バッチ サイズが固定されている場合、組み込みのパイプラインまたはテンソル並列処理のサポートがないため、ネイティブ PyTorch FSDP では一部のモデル トレーニングが実行できない可能性があります。前の表では、グローバル バッチ サイズが 4 万、ノード数が 32、シーケンス長が 32,768 であるとすると、GPU あたりの有効なバッチ サイズは 0.5 (たとえば、バッチ サイズ 2 の tp = 1) になります。これは、次の方法を導入しないと実行不可能です。テンソル並列性。
まとめ
この投稿では、p4d インスタンス上で SMP および SMDDP を使用した効率的な LLM トレーニングを実証しました。これは、NCCL に対する SMDDP の強化、フル シャーディングではなく柔軟な FSDP ハイブリッド シャーディング、TE 統合、およびテンソル並列処理の有効化など、複数の重要な機能に貢献していると考えられます。シーケンスの長さが長い。さまざまなモデル、モデル サイズ、シーケンス長を使用した幅広い設定でテストされた後、SageMaker 上で最大 128 個の p4d インスタンスまで、堅牢なほぼ線形のスケーリング効率を示します。要約すると、SageMaker は LLM 研究者や実践者にとって強力なツールであり続けます。
詳細については、を参照してください。 SageMaker モデル並列処理ライブラリ v2、または次の SMP チームにお問い合わせください。 sm-model-Parallel-フィードバック@amazon.com.
謝辞
建設的なフィードバックと議論をしていただいた Robert Van Dusen、Ben Snyder、Gautam Kumar、Luis Quintela に感謝いたします。
著者について

シンレ・シェイラ・リウ は Amazon SageMaker の SDE です。余暇には、読書やアウトドア スポーツを楽しんでいます。
 スヒット・コドゥグル は、AWS 人工知能グループのソフトウェア開発エンジニアであり、深層学習フレームワークに取り組んでいます。余暇には、ハイキング、旅行、料理を楽しんでいます。
スヒット・コドゥグル は、AWS 人工知能グループのソフトウェア開発エンジニアであり、深層学習フレームワークに取り組んでいます。余暇には、ハイキング、旅行、料理を楽しんでいます。
 ビクター・ジュー アマゾン ウェブ サービスの分散ディープラーニングのソフトウェア エンジニアです。彼はサンフランシスコのベイエリア周辺でハイキングやボードゲームを楽しんでいます。
ビクター・ジュー アマゾン ウェブ サービスの分散ディープラーニングのソフトウェア エンジニアです。彼はサンフランシスコのベイエリア周辺でハイキングやボードゲームを楽しんでいます。
 デリヤ・キャヴダル AWS でソフトウェア エンジニアとして働いています。彼女の興味には、深層学習と分散トレーニングの最適化が含まれます。
デリヤ・キャヴダル AWS でソフトウェア エンジニアとして働いています。彼女の興味には、深層学習と分散トレーニングの最適化が含まれます。
 テン・シュウ は、AWS AI の分散トレーニング グループのソフトウェア開発エンジニアです。彼は読書が好きです。
テン・シュウ は、AWS AI の分散トレーニング グループのソフトウェア開発エンジニアです。彼は読書が好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

