競争の激しい今日の市場では、機械学習 (ML) モデルを使用してデータ分析を実行することが、組織にとって必要不可欠になっています。 これにより、データの価値を解き放ち、傾向、パターン、予測を特定し、競合他社との差別化を図ることができます。 たとえば、ヘルスケア業界では、ML 駆動型の分析を診断支援や個別化医療に使用できますが、健康保険では予測的ケア管理に使用できます。
ただし、ヘルスケアや健康保険など、潜在的な健康データが存在する業界の組織とユーザーは、人々のプライバシーの保護を優先し、規制を遵守する必要があります。 また、ますます多くのユースケースに ML 主導の分析を使用するという課題にも直面しています。 これらの課題には、限られた数のデータ サイエンス エキスパート、ML の複雑さ、制限された保護対象医療情報 (PHI) とインフラストラクチャ容量による少量のデータが含まれます。
ヘルスケア、臨床、ライフ サイエンスの組織は、データ分析に ML を使用する際にいくつかの課題に直面しています。
- 少量のデータ – プライベートで保護された機密性の高い健康情報に対する制限により、使用可能なデータの量が制限されることが多く、ML モデルの精度が低下します
- 限られた才能 – ML の人材を採用することは十分に困難ですが、ML の経験だけでなく、深い医療知識を備えた人材を採用することはさらに困難です
- インフラ管理 – ML に特化したインフラストラクチャのプロビジョニングは困難で時間のかかる作業であり、企業は複雑な技術インフラストラクチャを管理するよりもコア コンピテンシーに集中したいと考えています。
- マルチモーダル問題の予測 – 脳卒中などの多面的な医療イベントの可能性を予測する場合、病歴、ライフスタイル、人口統計情報などのさまざまな要因を組み合わせる必要があります
考えられるシナリオとして、あなたが 30 人の非臨床医のチームを持ち、医療事例を調査および調査しているヘルスケア テクノロジー企業であるとします。 このチームには医療に関する知識と直感がありますが、モデルを構築して予測を生成するための ML スキルはありません。 これらの臨床医が「健康規制に準拠しながら、プライバシーを侵害することなく有用なデータにアクセスするにはどうすればよいか」などの多変量の質問に対して、これらの臨床医が自分で予測を生成できるようにするセルフサービス環境を展開するにはどうすればよいでしょうか? また、SysOps 担当者が管理する必要があるサーバーの数を爆発的に増やすことなく、それを実現するにはどうすればよいでしょうか?
この投稿では、これらすべての問題を XNUMX つのソリューションで同時に解決します。 まず、データを自動的に匿名化します。 アマゾン・ヘルスレイク. 次に、そのデータをサーバーレス コンポーネントやノーコード セルフサービス ソリューションで使用します。 Amazon SageMaker キャンバス ML モデリングの複雑さを解消し、基盤となるインフラストラクチャを抽象化します。
最新のデータ戦略は、データの管理、アクセス、分析、および行動のための包括的な計画を提供します。 AWS は、すべてのワークロード、すべてのタイプのデータ、およびすべての望ましいビジネス成果について、エンドツーエンドのデータ ジャーニー全体に対して最も完全なサービス セットを提供します。
ソリューションの概要
この投稿は、Amazon HealthLake からの機密データを匿名化し、SageMaker Canvas で利用できるようにすることで、組織はより多くの利害関係者が、脳卒中予測などのマルチモーダル問題の予測を生成できる ML モデルを使用できるようにできることを示しています。機密データへのアクセス。 そして、その匿名化を自動化して、可能な限りスケーラブルでセルフサービスに対応できるようにしたいと考えています。 また、自動化により、匿名化ロジックを反復してコンプライアンス要件を満たすことができ、母集団の健康データが変化したときにパイプラインを再実行する機能が提供されます。
このソリューションで使用されるデータセットは、 シンテア™、Synthetic Patient Population Simulator およびオープンソース プロジェクトであり、 Apacheライセンス2.0.
ワークフローには、クラウド エンジニアとドメイン エキスパートの間の引き継ぎが含まれます。 前者はパイプラインをデプロイできます。 後者は、パイプラインがデータを正しく匿名化しているかどうかを確認し、コードなしで予測を生成できます。 投稿の最後では、匿名化を検証するための追加サービスについて説明します。
ソリューションに含まれる大まかな手順は次のとおりです。
- AWSステップ関数 健康データの匿名化パイプラインを調整します。
- アマゾンアテナ 次のクエリ:
- Amazon HealthLake から非機密の構造化データを抽出します。
- Amazon HealthLake で自然言語処理 (NLP) を使用して、構造化されていない BLOB から非機密データを抽出します。
- でワンホットエンコーディングを実行する AmazonSageMakerデータラングラー.
- 分析と予測には SageMaker Canvas を使用します。
次の図は、ソリューションのアーキテクチャを示しています。
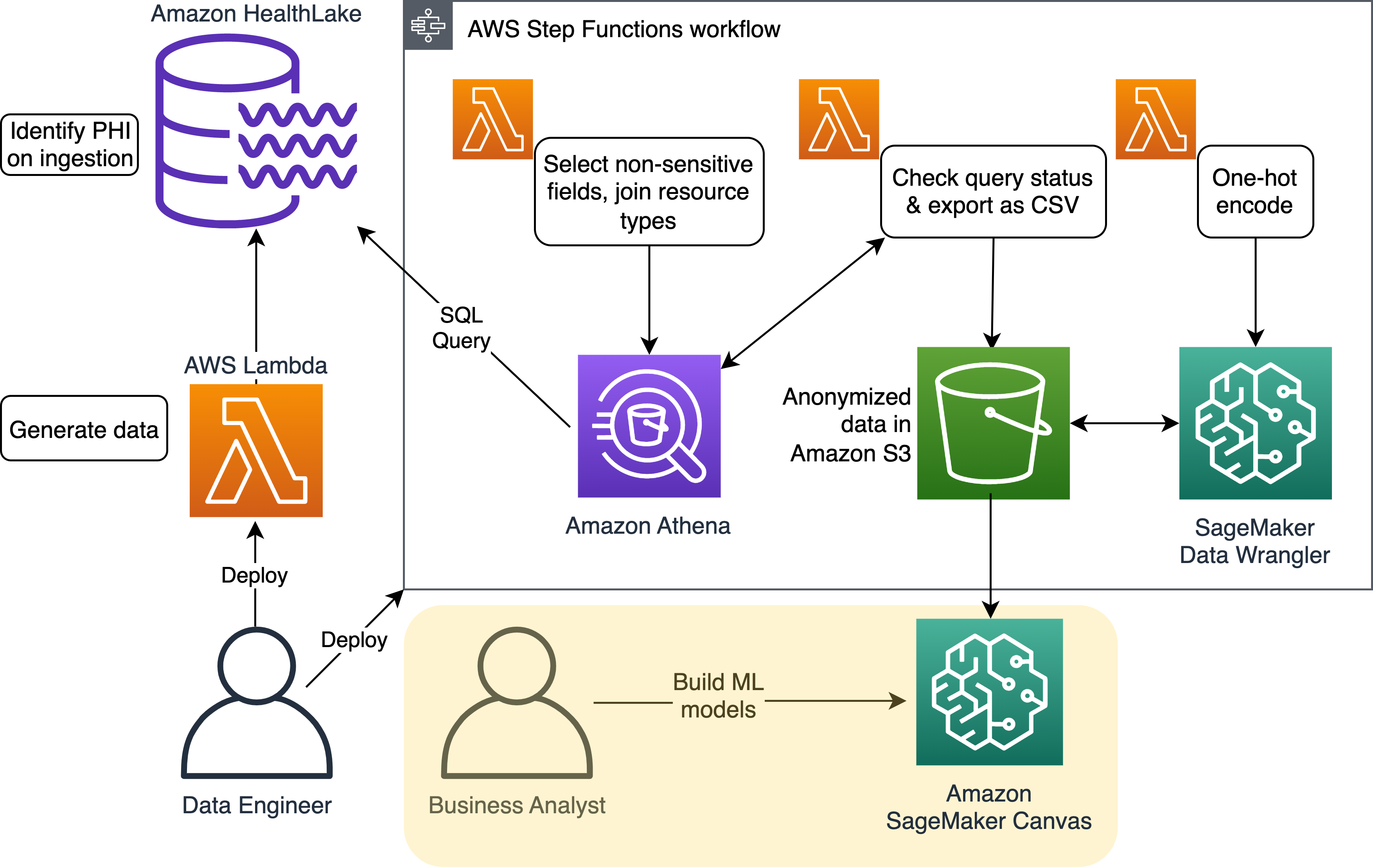
データを準備する
まず、Synthea™ を使用して架空の患者集団を生成し、そのデータを新しく作成した Amazon HealthLake データストアにインポートします。 結果は、ヘルスケア テクノロジー企業がこの投稿で説明されているパイプラインとソリューションを実行できる出発点のシミュレーションです。
Amazon HealthLake がデータを取り込むと、医師のメモなどの非構造化データから患者名や病状などの個別の構造化フィールドに意味が自動的に抽出されます。 非構造化データでこれを実現するには DocumentReference FHIR リソース、Amazon HealthLake が透過的にトリガー アマゾンコンプリヘンドメディカル、エンティティ、オントロジー、およびそれらの関係が抽出され、レコードの拡張セグメント内の個別のデータとして Amazon HealthLake に追加されます。
We Step Functions を使用できます データの収集と準備を合理化します。 ワークフロー全体が XNUMX か所に表示され、エラーや例外が強調表示されるため、反復可能、監査可能、および拡張可能なプロセスが可能になります。
Athenaを使用してデータをクエリする
Amazon HealthLake で直接 Athena SQL クエリを実行することにより、個人を特定しないフィールドのみを選択できます。 たとえば、名前と患者 ID を選択せず、生年月日を生年に減らします。 Amazon HealthLake を使用することで、非構造化データ ( DocumentReference) には、検出された PHI のリストが自動的に表示されます。これを使用して、非構造化データの PHI をマスクできます。 さらに、生成された Amazon HealthLake テーブルは AWSレイクフォーメーション、フィールド レベルまで誰がアクセスできるかを制御できます。
以下は、合成データで見つかった非構造化データの例からの抜粋です。 DocumentReference 記録:
# 現病歴
侯爵
45歳です。 患者は、高血圧、ウイルス性副鼻腔炎(障害)、慢性閉塞性気管支炎(障害)、ストレス(所見)、社会的孤立(所見)の病歴を有する。
# 社会の歴史
患者は既婚者です。 患者は 16 歳で禁煙した。
患者は現在 UnitedHealthcare に加入しています。
# アレルギー
既知のアレルギーはありません。
# 薬
アルブテロール 5 mg/ml 吸入液; アムロジピン 2.5 mg 経口錠剤。 60 アクチュアット プロピオン酸フルチカゾン 0.25 mg/アクチュアット / サルメテロール 0.05 mg/アクチュアット 乾燥粉末吸入器
# 評価と計画
患者は脳卒中を呈しています。
Amazon HeathLake NLP は、同じ患者 ID を持ち「脳卒中」を表示する状態レコードをクエリすることで、これを状態「脳卒中」が含まれていると解釈することがわかります。 また、DocumentReference で見つかったエンティティには自動的にラベルが付けられるという事実を利用できます。 SYSTEM_GENERATED:
結果は次のとおりです。
メモ全体を解釈するのではなく、G46.4 などの特定の条件コードを選択できるため、Amazon HealthLake で収集されたデータを分析に効果的に使用できるようになりました。 このデータは CSV ファイルとして保存されます。 Amazon シンプル ストレージ サービス (Amazon S3)。
注: このソリューションを実装するときは、以下に従ってください 説明書 データを HealthLake データ ストアに取り込む前に、サポート ケースを介して HealthLake の統合 NLP 機能を有効にする。
ワンホット エンコーディングを実行する
データの可能性を最大限に引き出すために、ワンホット エンコーディングと呼ばれる手法を使用して、条件列などのカテゴリ列を数値データに変換します。
カテゴリ データを扱う際の課題の XNUMX つは、多くの機械学習アルゴリズムで使用するのに適していないことです。 これを克服するために、列の各カテゴリを個別のバイナリ列に変換するワンホット エンコーディングを使用して、データをより幅広いアルゴリズムに適したものにします。 これは、Data Wrangler を使用して行われます。 組み込み関数を持つ このため:
SageMaker Data Wrangler のワンホット エンコーディング用の組み込み関数
ワンホット エンコーディングは、カテゴリ列の各一意の値をバイナリ表現に変換し、一意の値ごとに新しい列のセットを作成します。 次の例では、条件列が XNUMX つの列に変換され、それぞれが XNUMX つの一意の値を表します。 ワンホット エンコーディングの後、同じ行がバイナリ表現に変わります。

データがエンコードされたので、SageMaker Canvas を使用して分析と予測を行うことができます。
分析と予測に SageMaker Canvas を使用する
最終的な CSV ファイルは SageMaker Canvas の入力となり、ヘルスケアアナリスト (ビジネスユーザー) はこれを使用して、ML の専門知識がなくても脳卒中予測などの多変量問題の予測を生成できます。 データには機密情報が含まれていないため、特別なアクセス許可は必要ありません。
ストローク予測の例では、次のスクリーンショットに示すように、SageMaker Canvas は高度な ML モデルを使用して 99.829% の精度を達成することができました。
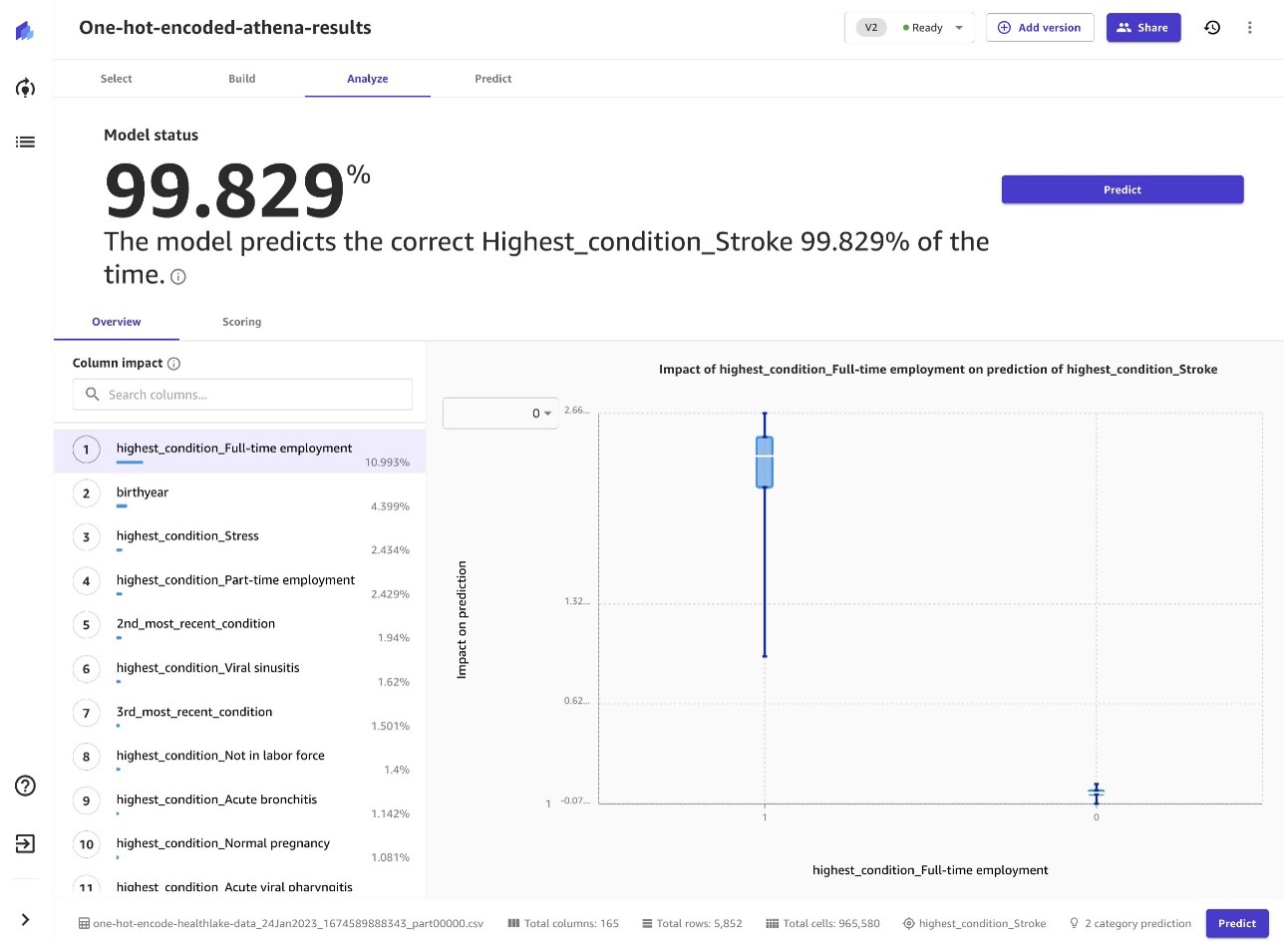
次のスクリーンショットでは、モデルの予測によると、この患者が脳卒中を発症しない確率は 53% であることがわかります。
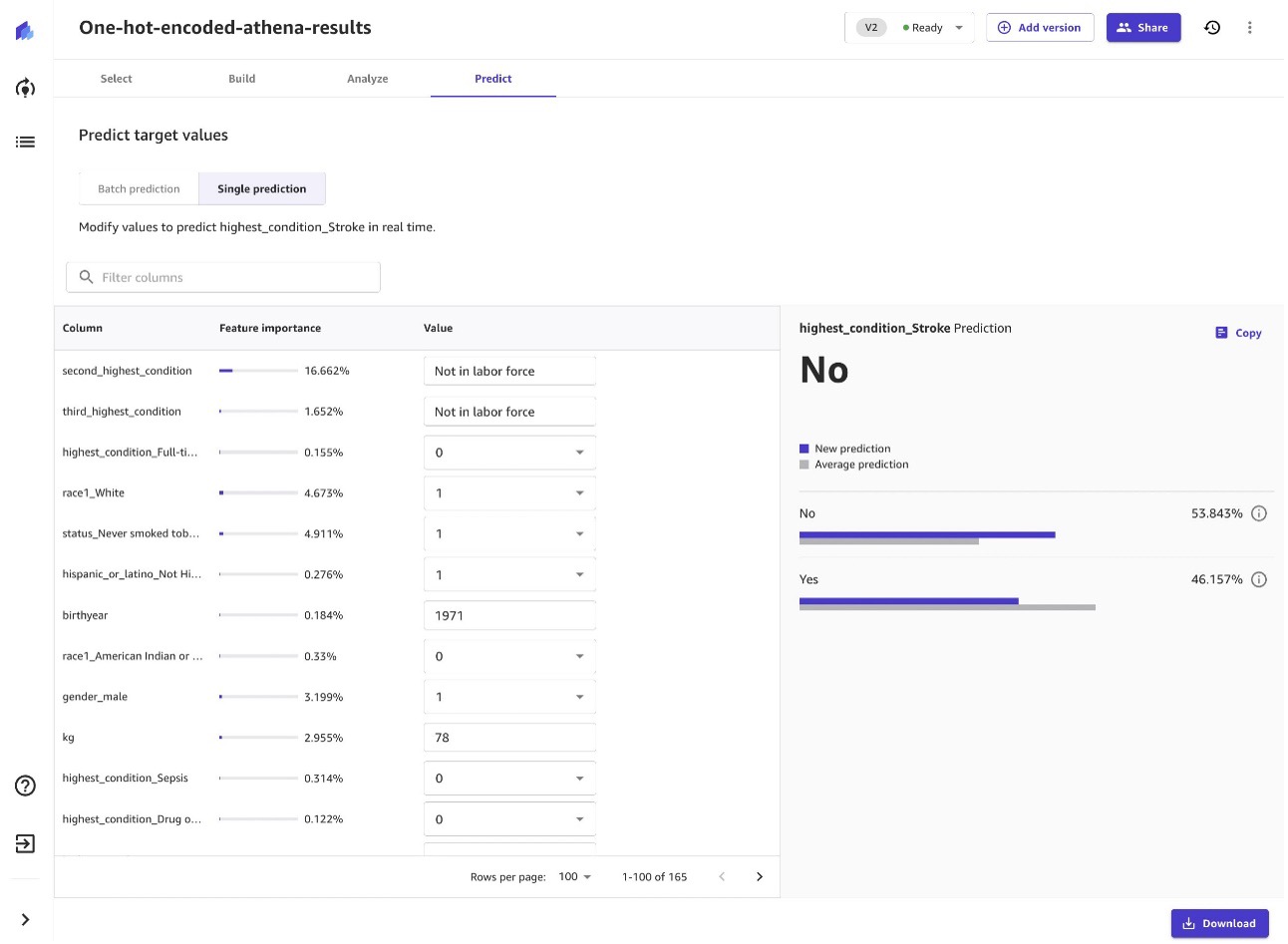
スプレッドシートでルールベースのロジックを使用して、この予測を作成できると仮定するかもしれません。 しかし、これらのルールは特徴の重要性を示していますか? たとえば、予測の 4.9% はタバコを吸ったことがあるかどうかに基づいていますか? 喫煙状況や血圧などの現在の列に加えて、さらに 900 個の列 (特徴) を追加するとどうなるでしょうか? スプレッドシートを使用して、これらすべてのディメンションの組み合わせを維持および管理できますか? 実際のシナリオでは多くの組み合わせが考えられます。課題は、これを適切なレベルの労力で大規模に管理することです。
このモデルができたので、バッチまたは単一の予測を開始して、what-if の質問をすることができます。 たとえば、この人物がすべての変数を同じに保っているが、医療システムとの過去 XNUMX 回の遭遇の時点で、次のように分類されている場合はどうなるでしょうか。 フルタイムの雇用 労働力ではありません?
私たちのモデルと、Synthea から入力した合成データによると、その人が脳卒中になるリスクは 62% です。
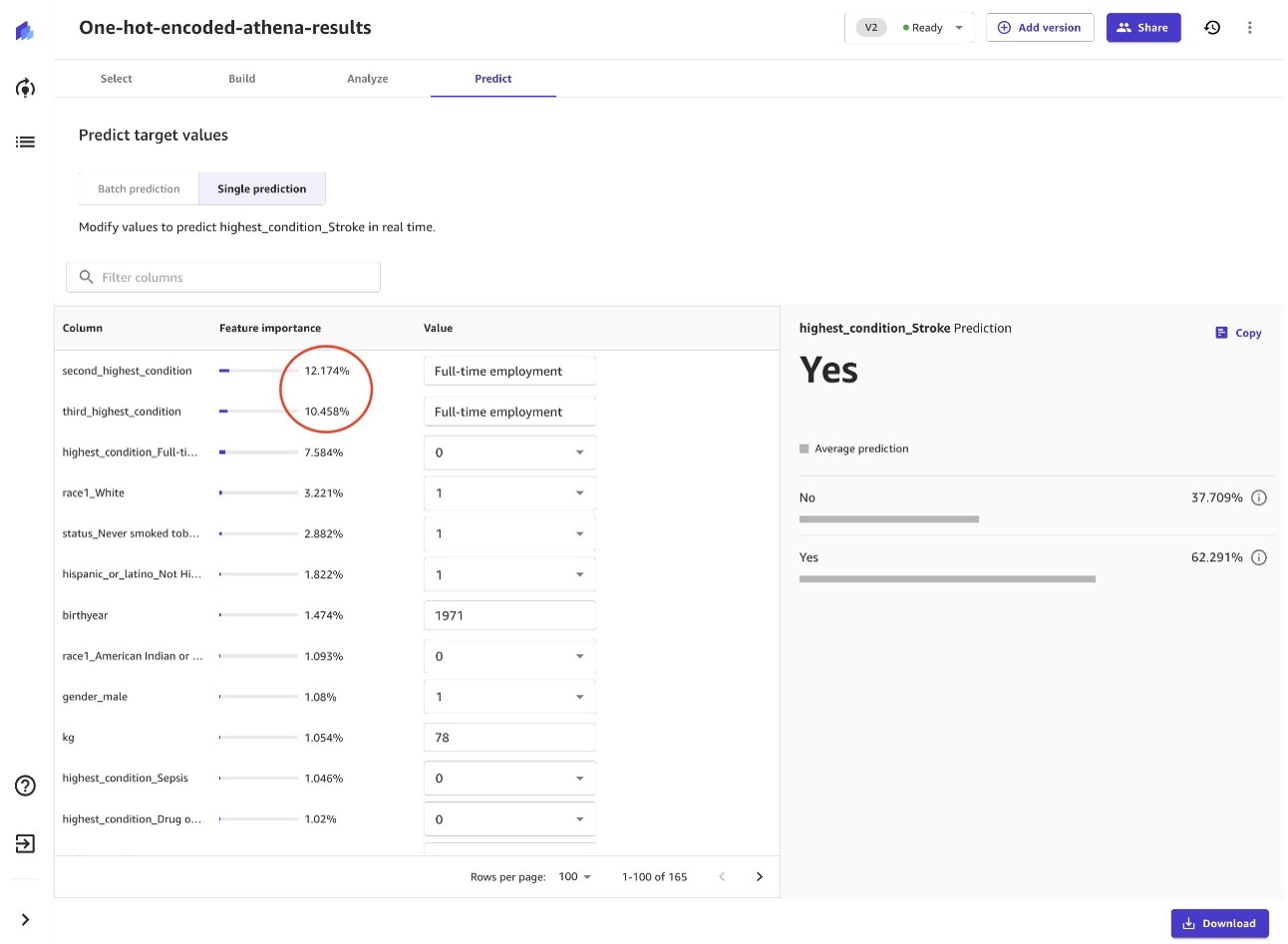
丸で囲まれた 12% と 10% が、医療システムとの最近の XNUMX つの遭遇からの状態の特徴の重要性からわかるように、フルタイムで雇用されているかどうかは、脳卒中のリスクに大きな影響を与えます。 このモデルの調査結果を超えて、同様のリンクを示す研究があります。
これらの研究は、大規模な人口ベースのサンプルを使用し、他のリスク要因を制御していますが、本質的に観察的であり、因果関係を確立していないことに注意することが重要です. フルタイムの雇用と脳卒中リスクとの関係を完全に理解するには、さらなる研究が必要です。
機能強化と代替方法
コンプライアンスをさらに検証するために、次のようなサービスを使用できます アマゾンメイシーこれにより、S3 バケット内の CSV ファイルがスキャンされ、機密データがある場合はアラートが送信されます。 これにより、匿名化されたデータの信頼レベルが向上します。
この投稿では、Amazon S3 を SageMaker Canvas の入力データ ソースとして使用しました。 ただし、データを直接 SageMaker Canvas にインポートすることもできます。 AmazonRedShift Snowflake — 多くの顧客がデータと一般的なサードパーティ ソリューションを整理するために使用する、人気のあるエンタープライズ データ ウェアハウス サービスです。 これは、他の BI 分析に使用されている Snowflake または Amazon Redshift のいずれかにデータを既に持っているお客様にとって特に重要です。
Step Functions を使用してソリューションを調整することで、ソリューションの拡張性が向上します。 Macie を呼び出す別のトリガーの代わりに、別のステップをパイプラインの最後に追加して、Macie を呼び出して PHI を再確認することができます。 データ パイプラインの品質を経時的に監視するルールを追加する場合は、次のステップを追加できます。 AWS Glue データ品質.
オーダーメイドの統合をさらに追加したい場合は、Step Functions を使用してスケールアウトし、必要なだけのデータまたは少量のデータを並行して処理し、使用した分だけ支払うことができます。 並列化の側面は、数百 GB のデータを処理している場合に役立ちます。これは、すべてを XNUMX つの関数に詰め込もうとしないためです。 代わりに、単一のキューで処理されるのを待たないように、分割して並行して実行する必要があります。 これは、店舗のレジの列に似ています。レジ係を XNUMX 人も必要としません。
クリーンアップ
将来のセッション料金が発生しないようにするには、SageMaker Canvas からログアウトします。
まとめ
この投稿では、脳卒中などの重大な健康問題の予測は、医療専門家が複雑な ML モデルを使用してコーディングなしで実行できることを示しました。 これにより、専門分野の知識はあるが ML の経験がない人を含めることで、リソースのプールが大幅に増加します。 また、サーバーレス サービスとマネージド サービスを使用すると、既存の IT 担当者は、可用性、回復力、スケーラビリティなどのインフラストラクチャの課題を少ない労力で管理できます。
この投稿を出発点として、他の複雑なマルチモーダル予測を調査することができます。これらは、医療業界をより良い患者ケアに導くための鍵となります。 近日中に、エンジニアがこの投稿で提示した種類のアイデアをより迅速に立ち上げるのに役立つ GitHub リポジトリを用意する予定です。
今すぐ SageMaker Canvas のパワーを体験し、ユーザーフレンドリーなグラフィカルインターフェースを使用してモデルを構築してください。 2 か月間の無料利用枠 SageMaker Canvas が提供するものです。 開始するのにコーディングの知識は必要ありません。さまざまなオプションを試して、モデルのパフォーマンスを確認できます。
リソース
SageMaker Canvas の詳細については、以下を参照してください。
SageMaker Canvas で解決できるその他のユースケースについて詳しくは、以下をご覧ください。
Amazon HealthLake の詳細については、以下を参照してください。
著者について
 ヤン・ストーンマン マサチューセッツ州ボストンを拠点とする AWS のソリューション アーキテクトであり、AI/ML Technical Field Community (TFC) のメンバーです。 Yann は、ジュリアード音楽院で学士号を取得しました。 グローバル企業のワークロードをモダナイズしていないとき、Yann はピアノを弾き、React と Python をいじくり回し、定期的に YouTube で彼のクラウド ジャーニーを紹介しています。
ヤン・ストーンマン マサチューセッツ州ボストンを拠点とする AWS のソリューション アーキテクトであり、AI/ML Technical Field Community (TFC) のメンバーです。 Yann は、ジュリアード音楽院で学士号を取得しました。 グローバル企業のワークロードをモダナイズしていないとき、Yann はピアノを弾き、React と Python をいじくり回し、定期的に YouTube で彼のクラウド ジャーニーを紹介しています。
 ラメシュ・ドワラカナト マサチューセッツ州ボストンを拠点とする AWS のプリンシパル ソリューション アーキテクトです。 彼は、北東地域の企業のクラウド ジャーニーに取り組んでいます。 彼の関心のある分野は、コンテナーと DevOps です。 余暇には、Ramesh はテニス、ラケットボールを楽しんでいます。
ラメシュ・ドワラカナト マサチューセッツ州ボストンを拠点とする AWS のプリンシパル ソリューション アーキテクトです。 彼は、北東地域の企業のクラウド ジャーニーに取り組んでいます。 彼の関心のある分野は、コンテナーと DevOps です。 余暇には、Ramesh はテニス、ラケットボールを楽しんでいます。
 バハ・ヌルザノフ AWS の相互運用性ソリューション アーキテクトであり、AWS のヘルスケアおよびライフ サイエンスの技術分野コミュニティのメンバーです。 Bakha はワシントン大学でコンピューター サイエンスの修士号を取得し、余暇には家族と過ごしたり、読書、サイクリング、新しい場所の探索を楽しんでいます。
バハ・ヌルザノフ AWS の相互運用性ソリューション アーキテクトであり、AWS のヘルスケアおよびライフ サイエンスの技術分野コミュニティのメンバーです。 Bakha はワシントン大学でコンピューター サイエンスの修士号を取得し、余暇には家族と過ごしたり、読書、サイクリング、新しい場所の探索を楽しんでいます。
 スコット・シュレッケンガウスト 生物医学工学の学位を取得しており、キャリアの初期からベンチで科学者と一緒にデバイスを発明してきました。 彼は科学、テクノロジー、エンジニアリングが大好きで、ヘルスケアおよびライフ サイエンス分野のスタートアップから大規模な多国籍組織まで数十年の経験があります。 Scott は、ロボット液体ハンドラーのスクリプト作成、機器のプログラミング、自社開発システムのエンタープライズ システムへの統合、および規制環境での完全なソフトウェア展開のゼロからの開発に慣れています。 人々を助けるだけでなく、構築することにも力を注いでおり、顧客の科学的なワークフローとその問題をハッシュ化し、それらを実行可能なソリューションに変換する旅を楽しんでいます。
スコット・シュレッケンガウスト 生物医学工学の学位を取得しており、キャリアの初期からベンチで科学者と一緒にデバイスを発明してきました。 彼は科学、テクノロジー、エンジニアリングが大好きで、ヘルスケアおよびライフ サイエンス分野のスタートアップから大規模な多国籍組織まで数十年の経験があります。 Scott は、ロボット液体ハンドラーのスクリプト作成、機器のプログラミング、自社開発システムのエンタープライズ システムへの統合、および規制環境での完全なソフトウェア展開のゼロからの開発に慣れています。 人々を助けるだけでなく、構築することにも力を注いでおり、顧客の科学的なワークフローとその問題をハッシュ化し、それらを実行可能なソリューションに変換する旅を楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/extract-non-phi-data-from-amazon-healthlake-reduce-complexity-and-increase-cost-efficiency-with-amazon-athena-and-amazon-sagemaker-canvas/

