クラウドへの移行は、クラウド リソースの柔軟性と規模の活用を目指す現代の組織にとって不可欠なステップです。 Terraform や AWS CloudFormation は、そのような移行にとって極めて重要であり、複雑なクラウド環境を正確に定義および管理するコードとしてのインフラストラクチャ (IaC) 機能を提供します。ただし、その利点にもかかわらず、IaC の学習曲線と、組織および業界固有のコンプライアンスおよびセキュリティ標準を順守することの複雑さにより、クラウド導入のプロセスが遅くなる可能性があります。通常、組織は大規模なトレーニング プログラムに投資したり、専門スタッフを雇用したりすることでこれらのハードルに対抗しますが、それがコストの増加や移行スケジュールの遅延につながることがよくあります。
生成人工知能 (AI) アマゾンの岩盤 これらの課題に直接対処します。 Amazon Bedrock は、AI21 Labs、Anthropic、Cohere、Meta、Stability AI、Amazon などの大手 AI 企業の高性能基盤モデル (FM) を単一の API で提供するフルマネージド サービスです。セキュリティ、プライバシー、責任ある AI を備えた生成 AI アプリケーションを構築する機能。 Amazon Bedrock を使用すると、チームはコンプライアンスとセキュリティのベストプラクティスをシームレスに統合しながら、組織のニーズに合わせてカスタマイズした Terraform および CloudFormation スクリプトを生成できます。従来、IaC を学習しているクラウド エンジニアは、マニュアルとベスト プラクティスを手作業で精査して、準拠した IaC スクリプトを作成していました。 Amazon Bedrock を使用すると、チームは高レベルのアーキテクチャの説明を入力し、生成 AI を使用して Terraform スクリプトのベースライン構成を生成できます。これらの生成されたスクリプトは、セキュリティとコンプライアンスの業界標準に準拠しながら、組織固有の要件を満たすように調整されています。これらのスクリプトは基礎的な開始点として機能し、実稼働レベルの標準を確実に満たすようにさらなる改良と検証が必要になります。
このソリューションは、移行プロセスを加速するだけでなく、標準化された安全なクラウド インフラストラクチャも提供します。さらに、初心者のクラウド エンジニアに、構築の基礎となる標準テンプレートとして初期スクリプト ドラフトを提供し、IaC の学習を容易にします。
複雑なクラウド移行を進める際には、構造化され、安全で、コンプライアンスに準拠した環境の必要性が最も重要です。 AWS ランディング ゾーン は、AWS リソースをデプロイするための標準化されたアプローチを提供することで、このニーズに対応します。これにより、クラウド基盤が最初から AWS のベストプラクティスに従って構築されるようになります。 AWS Landing Zone を使用すると、セキュリティ設定、リソースのプロビジョニング、アカウント管理における推測を排除できます。これは、ガバナンスや制御に妥協することなく拡張したいと考えている組織にとって特に有益であり、堅牢で効率的なクラウド設定への明確な道筋を提供します。
この投稿では、Amazon Bedrock を使用して、AWS Landing Zone 用にカスタマイズされた準拠した IaC スクリプトを生成する方法を説明します。
クラウド移行のコンテキストにおける AWS Landing Zone アーキテクチャ
AWS Landing Zone は、AWS のベストプラクティスに基づいて、安全なマルチアカウント AWS 環境をセットアップするのに役立ちます。マルチアカウント アーキテクチャの使用を開始し、新しいアカウントのセットアップを自動化し、コンプライアンス、セキュリティ、および ID 管理を一元化するためのベースライン環境を提供します。以下は、カスタマイズされた Terraform ベースの AWS Landing Zone ソリューションの例です。各アプリケーションは独自の AWS アカウントに存在します。
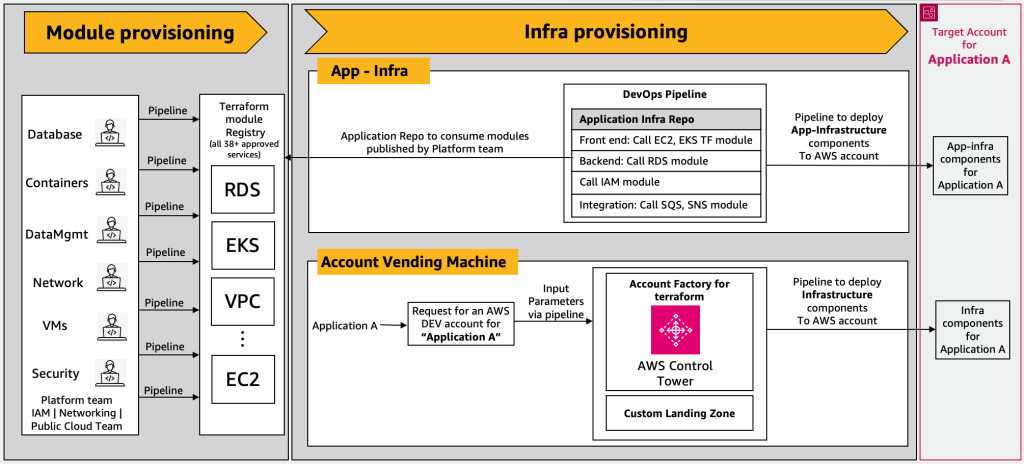
高レベルのワークフローには次のコンポーネントが含まれます。
- モジュールのプロビジョニング – データベース、コンテナ、データ管理、ネットワーキング、セキュリティなどのさまざまなドメインにわたるさまざまなプラットフォーム チームが、認定モジュールまたはカスタム モジュールを開発および公開します。これらは、パイプラインを通じて Terraform プライベート モジュール レジストリに配信され、一貫性と標準化のために組織によって維持されます。
- アカウント自動販売機層 – アカウント自動販売機 (AVM) 層は、次のいずれかを使用します。 AWS Control Tower, Terraform 用の AWS アカウントファクトリー (AFT)、またはアカウントを販売するためのカスタム ランディング ゾーン ソリューション。この投稿では、これらのソリューションを総称して AVM レイヤーと呼びます。アプリケーション所有者が AVM レイヤーにリクエストを送信すると、AVM レイヤーはリクエストからの入力パラメータを処理して、ターゲット AWS アカウントをプロビジョニングします。このアカウントには、AVM のカスタマイズを通じて、調整されたインフラストラクチャ コンポーネントがプロビジョニングされます。 AWS Control Towerのカスタマイズ or AFTのカスタマイズ.
- アプリケーションインフラストラクチャ層 – この層では、アプリケーション チームがインフラストラクチャ コンポーネントをプロビジョニングされた AWS アカウントにデプロイします。これは、アプリケーション固有のリポジトリ内に Terraform コードを記述することで実現されます。 Terraform コードは、プラットフォーム チームによって以前に Terraform プライベート レジストリに公開されたモジュールを呼び出します。
生成 AI でオンプレミスの IaC 移行の課題を克服
オンプレミス アプリケーションを保守するチームは、AWS 環境での IaC の重要なツールである Terraform の学習に苦労することがよくあります。このスキル ギャップは、クラウド移行作業において大きな障害となる可能性があります。 Amazon Bedrock は、生成 AI 機能を備えており、この課題を軽減する上で重要な役割を果たします。これにより、アプリケーション インフラストラクチャ レイヤーの Terraform コード作成の自動化が容易になり、Terraform の経験が限られているチームが AWS に効率的に移行できるようになります。
Amazon Bedrock は、アーキテクチャ記述から Terraform コードを生成します。生成されたコードはカスタムであり、組織のベスト プラクティス、セキュリティ、規制ガイドラインに基づいて標準化されています。この標準化は、高度なプロンプトを併用することで可能になります。 Amazon Bedrock のナレッジベース、組織固有の Terraform モジュールに関する情報が保存されます。このソリューションは、取得拡張生成 (RAG) を使用して、Amazon Bedrock への入力プロンプトをナレッジベースの詳細で強化し、出力される Terraform 設定と README の内容が組織の Terraform のベストプラクティスとガイドラインに準拠していることを確認します。
次の図は、このアーキテクチャを示しています。
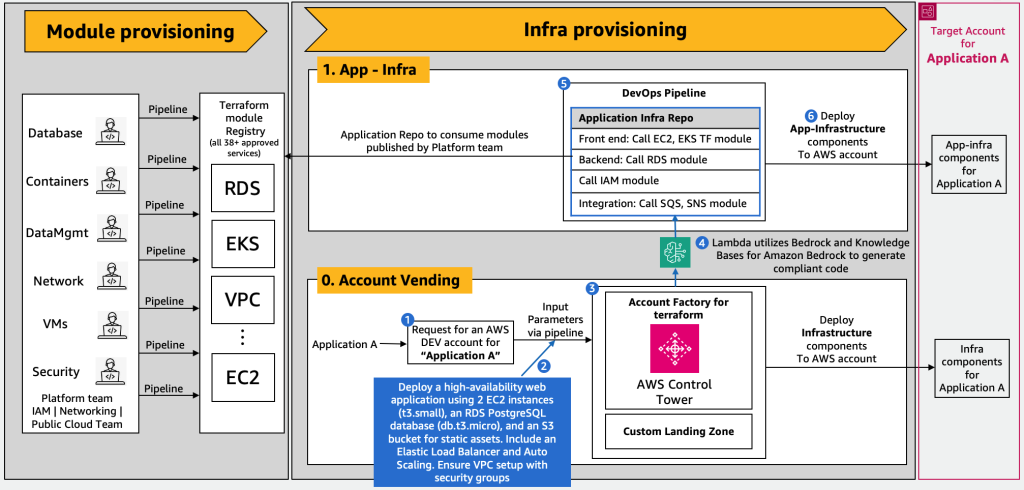
ワークフローは次の手順で構成されます。
- このプロセスは、アプリケーション所有者が新しい AWS アカウントのリクエストを送信するアカウント販売から始まります。これにより AVM が起動され、リクエストパラメータを処理してターゲット AWS アカウントをプロビジョニングします。
- 移行が予定されているアプリケーションのアーキテクチャ記述は、AVM レイヤーへの入力の 1 つとして渡されます。
- アカウントがプロビジョニングされると、AVM カスタマイズが適用されます。これには以下が含まれます AWS Control Towerのカスタマイズ or AFTのカスタマイズ 組織のポリシーに沿って、必要なインフラストラクチャ コンポーネントと構成を使用してアカウントを設定します。
- 並行して、AVM レイヤーは Lambda 関数を呼び出して Terraform コードを生成します。この機能は、カスタマイズされたプロンプトでアーキテクチャの説明を強化し、RAG を利用して、Bedrock のナレッジ ベースからの組織固有のコーディング ガイドラインでプロンプトをさらに強化します。このナレッジ ベースには、組織に固有のベスト プラクティス、セキュリティ ガードレール、ガイドラインが含まれています。実例を見る 例 組織固有の Terraform モジュールの仕様とガイドラインがナレッジ ベースにアップロードされています。
- 導入前に、Terraform コードの最初のドラフトはクラウド エンジニアまたは自動コード レビュー システムによって徹底的にレビューされ、すべての技術基準とコンプライアンス基準を満たしていることが確認されます。
- レビューおよび更新された Terraform スクリプトは、新しくプロビジョニングされた AWS アカウントにインフラストラクチャ コンポーネントをデプロイするために使用され、アプリケーションに必要なコンピューティング、ストレージ、ネットワーク リソースをセットアップします。
ソリューションの概要
AWS Landing Zone デプロイメントでは、アーキテクチャ入力から Terraform スクリプトを生成するために Lambda 関数を使用します。操作の中心となるこの機能は、Amazon Bedrock および Amazon Bedrock のナレッジベースを使用して、これらの入力を準拠コードに変換します。出力は、移行中の特定のアプリケーションに対応する GitHub リポジトリに保存されます。次のセクションでは、このソリューションを実装するために必要な前提条件と具体的な手順について詳しく説明します。
前提条件
次のものが必要です。
カスタムコードを生成するように Lambda 関数を設定する
この Lambda 関数は、AWS サービス用にカスタマイズされた準拠した Terraform 構成の作成を自動化するための重要なコンポーネントです。生成された構成は、組織のベスト プラクティスに合わせて、指定された GitHub リポジトリに直接コミットされます。ファンクションコードについては下記を参照してください。 GitHubレポ。ラムダ関数を作成するには、次の手順に従ってください。 説明書.
次の図は、この関数のワークフローを示しています。
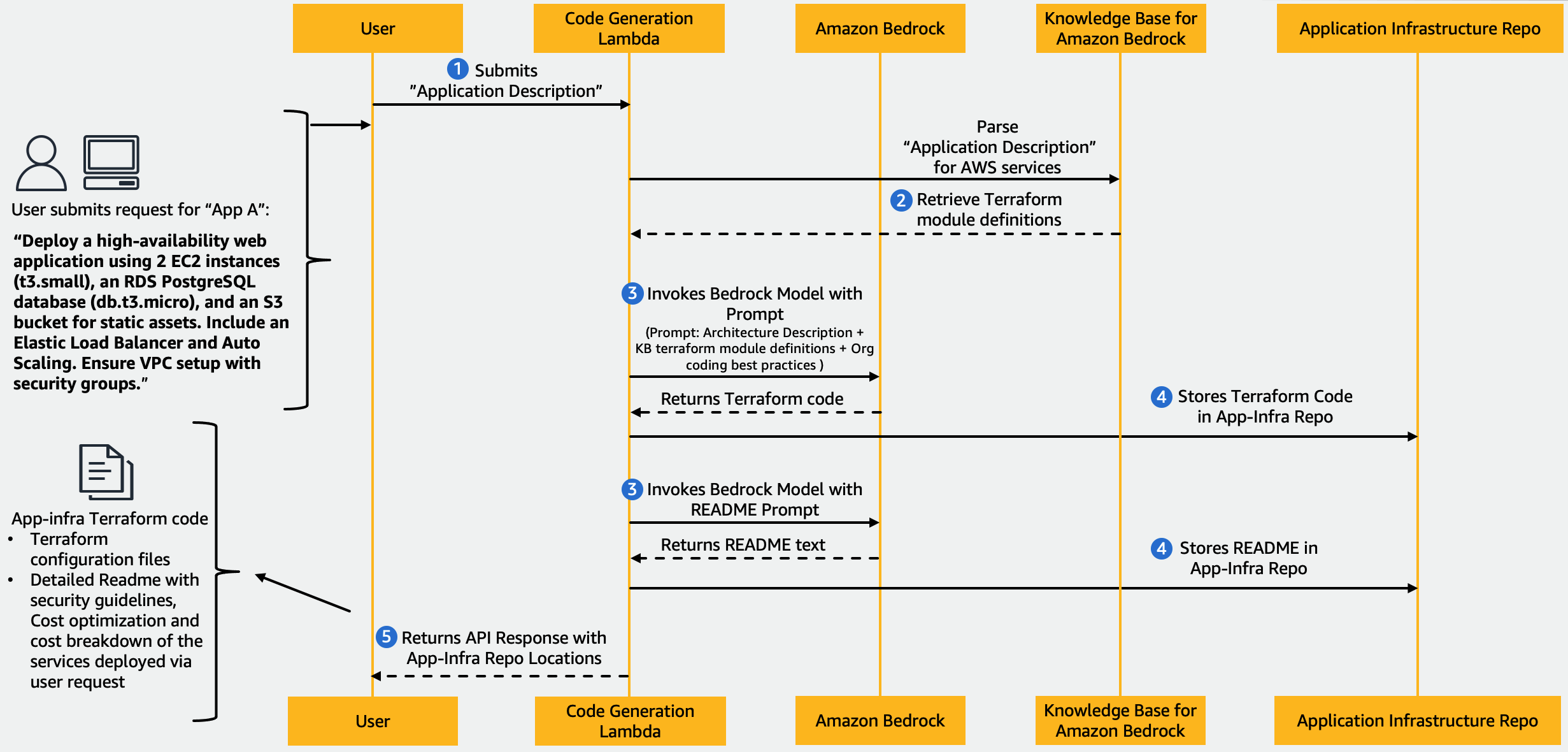
ワークフローには次の手順が含まれます。
- この関数は、アーキテクチャの記述を含む AVM 層からのイベントによって呼び出されます。
- この関数は、ナレッジ ベースから Terraform モジュール定義を取得して使用します。
- この関数は、推奨事項に従って Amazon Bedrock モデルを 2 回呼び出します。 迅速なエンジニアリングガイドライン。この関数は RAG を適用して、入力プロンプトを Terraform モジュール情報で強化し、出力コードが組織のベスト プラクティスを満たしていることを確認します。
- まず、組織のコーディング ガイドラインに従って Terraform 構成を生成し、ナレッジ ベースからの Terraform モジュールの詳細を含めます。たとえば、プロンプトは次のようになります。「AWS サービスの Terraform 構成を生成します。 IAM ロールと最小権限のアクセス許可を使用して、セキュリティのベスト プラクティスに従います。必要なパラメータをすべてデフォルト値とともに含めます。全体的なアーキテクチャと各リソースの目的を説明するコメントを追加してください。」
- 次に、詳細な README ファイルを作成します。例: 「AWS サービスに基づいて、Terraform 構成の詳細な README を生成します。 AWS Well-Architected フレームワークに従ったセキュリティの改善、コスト最適化のヒントに関するセクションが含まれます。また、使用した各 AWS サービスの詳細なコストの内訳を、時間料金と日次および月次の合計コストとともに含めます。」
- 生成された Terraform 構成と README を GitHub リポジトリにコミットし、トレーサビリティと透明性を提供します。
- 最後に、コミットされた GitHub ファイルへの URL を含む成功応答を返すか、トラブルシューティングのための詳細なエラー情報を返します。
Amazon Bedrock のナレッジベースを設定する
Amazon Bedrock でナレッジベースをセットアップするには、次の手順に従います。
- Amazon Bedrock コンソールで、 知識ベース ナビゲーションペインに表示されます。
- 選択する 知識ベースを作成する.
- 「AWS Account Setup Knowledge Base For Amazon Bedrock」など、ナレッジベースの目的を反映した明確でわかりやすい名前を入力します。
- 必要な権限を持つ事前構成された IAM ロールを割り当てます。通常は、Amazon Bedrock にこのロールを作成させて、適切な権限があることを確認することが最善です。
- セキュリティのために暗号化を有効にして、JSON ファイルを S3 バケットにアップロードします。このファイルには、AWS サービスと Terraform モジュールの構造化されたリストが含まれている必要があります。 JSON 構造の場合は、次を使用します。 例 GitHub リポジトリから。
- デフォルトの埋め込みモデルを選択します。
- Amazon Bedrock がベクター ストアを作成および管理できるようにします。 AmazonOpenSearchサービス.
- 情報が正確であるかどうかを確認してください。 S3 バケット URI と IAM ロールの詳細には特に注意してください。
- ナレッジ ベースを作成します。
これらのコンポーネントをデプロイして構成した後、AWS Landing Zone ソリューションが Lambda 関数を呼び出すと、次のファイルが生成されます。
- Terraform 構成ファイル – このファイルはインフラストラクチャのセットアップを指定します。
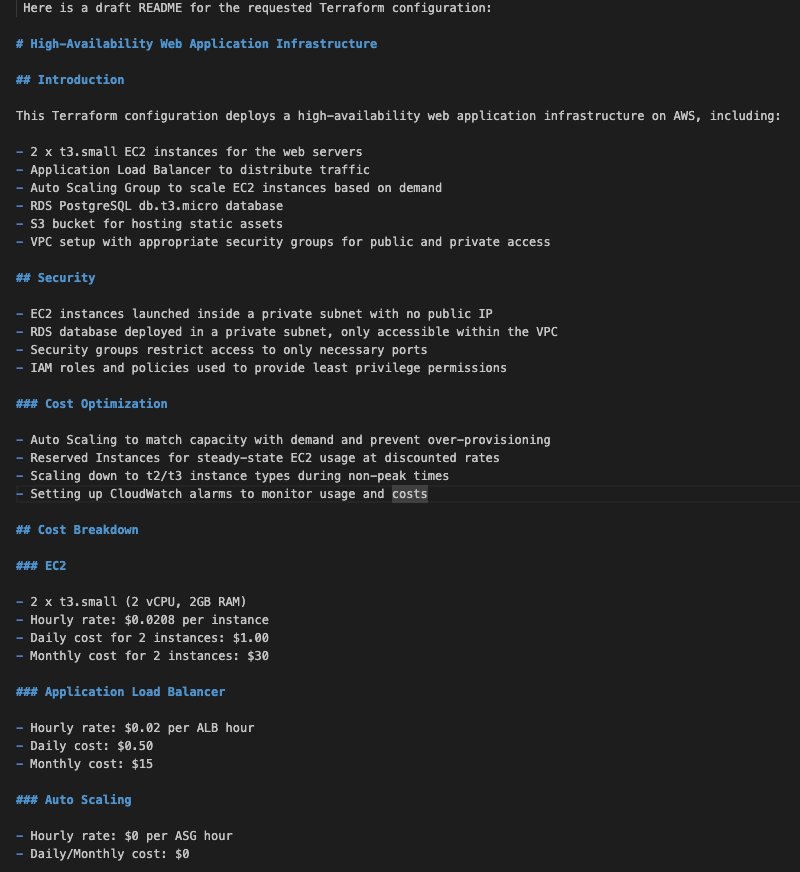
- 包括的な README ファイル – このファイルには、コード内に埋め込まれたセキュリティ標準が文書化されており、最初のセクションで概説したセキュリティ慣行と一致していることが確認されます。さらに、この README には、アーキテクチャの概要、コスト最適化のヒント、Terraform 構成で説明されているリソースの詳細なコストの内訳が含まれています。
次のスクリーンショットは、Terraform 構成ファイルの例を示しています。

次のスクリーンショットは、README ファイルの例を示しています。
クリーンアップ
リソースをクリーンアップするには、次の手順を実行します。
- Lambda 関数が不要になった場合は削除します。
- Terraform 状態ストレージに使用される S3 バケットを空にして削除します。
- 生成された Terraform スクリプトと README ファイルを GitHub リポジトリから削除します。
- ナレッジベースを削除する 不要になった場合。
まとめ
Amazon Bedrock の生成 AI 機能は、AWS デプロイメント用の準拠した Terraform スクリプトの作成を効率化するだけでなく、オンプレミスのアプリケーションを AWS に移行する初心者のクラウド エンジニアにとって極めて重要な学習支援としても機能します。このアプローチにより、クラウド移行プロセスが加速され、ベスト プラクティスを遵守するのに役立ちます。また、このソリューションを使用して移行後に価値を提供し、継続的なインフラストラクチャやコストの最適化などの日常業務を強化することもできます。この投稿では主に Terraform に焦点を当てましたが、これらの原則は AWS CloudFormation のデプロイメントを強化し、インフラストラクチャのニーズに合わせた多用途のソリューションを提供することもできます。
Amazon Bedrock の生成 AI を使用してクラウド移行プロセスを簡素化する準備はできていますか?まずは探索してみましょう Amazon Bedrock ユーザーガイド 組織のクラウドへの取り組みをどのように合理化できるかを理解するために。さらに支援と専門知識が必要な場合は、次の利用を検討してください。 AWSプロフェッショナルサービス クラウド移行の行程を合理化し、Amazon Bedrock の利点を最大限に活用するのに役立ちます。
Amazon Bedrock を使用して、迅速、安全、効率的なクラウド導入の可能性を解き放ちます。今すぐ最初の一歩を踏み出し、それが組織のクラウド変革の取り組みをどのように強化できるかを発見してください。
著者について

エビー・トーマス は、生成 AI を使用してクラウド インフラストラクチャの自動化を強化することに重点を置き、カスタム AWS Landing Zone リソースの戦略化と開発を専門としています。 AWS プロフェッショナル サービスでの役割において、Ebbey の専門知識は、クラウドの導入を合理化し、AWS ユーザーに安全で効率的な運用フレームワークを提供するソリューションの設計の中心となっています。彼は、クラウドの課題に対する革新的なアプローチと、クラウド サービスの機能を推進する取り組みで知られています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/generate-customized-compliant-application-iac-scripts-for-aws-landing-zone-using-amazon-bedrock/

