Amazon Bedrock のナレッジベース、基盤モデル (FM) を安全に接続できます。 アマゾンの岩盤 Retrieval Augmented Generation (RAG) 用に会社のデータに追加します。追加データにアクセスすると、モデルは FM を再トレーニングすることなく、より関連性があり、コンテキスト固有の、正確な応答を生成するのに役立ちます。
この投稿では、Amazon Bedrock のナレッジベースの 2 つの新機能について説明します。 RetrieveAndGenerate API: 結果の最大数を構成し、ナレッジ ベース プロンプト テンプレートを使用してカスタム プロンプトを作成します。これらを検索タイプと一緒にクエリ オプションとして選択できるようになりました。
新機能の概要と利点
結果の最大数オプションを使用すると、ベクター ストアから取得し、応答を生成するために FM に渡す検索結果の数を制御できます。これにより、生成のために提供される背景情報の量をカスタマイズできるため、複雑な質問にはより多くのコンテキストを提供し、単純な質問にはより少ないコンテキストを提供します。最大 100 件の結果を取得できます。このオプションは、関連するコンテキストの可能性を向上させるのに役立ち、それにより、生成された応答の精度が向上し、幻覚が軽減されます。
カスタム ナレッジ ベース プロンプト テンプレートを使用すると、デフォルトのプロンプト テンプレートを独自のプロンプト テンプレートに置き換えて、応答生成のためにモデルに送信されるプロンプトをカスタマイズできます。これにより、ユーザーの質問に応答するときの FM のトーン、出力形式、および動作をカスタマイズできます。このオプションを使用すると、業界やドメイン (医療や法律など) に合わせて用語を微調整できます。さらに、特定のワークフローに合わせたカスタムの手順や例を追加できます。
次のセクションでは、これらの機能を次のいずれかで使用する方法について説明します。 AWSマネジメントコンソール またはSDK。
前提条件
これらの例に従うには、既存のナレッジ ベースが必要です。作成手順については、を参照してください。 知識ベースを作成する.
コンソールを使用して結果の最大数を構成する
コンソールを使用して結果の最大数オプションを使用するには、次の手順を実行します。
- Amazon Bedrock コンソールで、 ナレッジベース 左側のナビゲーションペインで
- 作成したナレッジ ベースを選択します。
- 選択する テストの知識ベース.
- 設定アイコンを選択します。
- 選択する データソースを同期する ナレッジ ベースのテストを開始する前に。

- 構成、用 検索の種類、ユースケースに基づいて検索タイプを選択します。
この投稿では、セマンティック検索とテキスト検索を組み合わせて精度を高めるため、ハイブリッド検索を使用します。ハイブリッド検索の詳細については、次を参照してください。 Amazon Bedrock のナレッジベースがハイブリッド検索をサポートするようになりました.
- 詳細 ソースチャンクの最大数 結果の最大数を設定します。

新しい機能の価値を実証するために、生成される応答の精度を高める方法の例を示します。私たちが使用した 10 年の Amazon 2023K ドキュメント ナレッジベースを作成するためのソースデータとして。実験には次のクエリを使用します。「Amazon の年間収益は何年に 245 億ドルから 434 億ドルに増加しましたか?」
ナレッジベースの文書に基づくと、このクエリに対する正しい応答は「Amazon の年間収益は 245 年の 2019 億ドルから 434 年の 2022 億ドルに増加しました」です。 Claude v2 を FM として使用し、ナレッジ ベースから取得したコンテキスト情報に基づいて最終応答を生成しました。 Claude 3 Sonnet と Claude 3 Haiku も世代 FM としてサポートされています。
別のクエリを実行して、さまざまな構成での取得の比較を示しました。同じ入力クエリ (「Amazon の年間収益は何年に 245 億ドルから 434 億ドルに増加しましたか?」) を使用し、結果の最大数を 5 に設定しました。
次のスクリーンショットに示すように、生成された応答は「申し訳ありませんが、このリクエストではお手伝いできません。」でした。

次に、最大結果を 12 に設定し、同じ質問をします。生成された応答は、「Amazon の年間収益は 245 年の 2019 億ドルから 434 年の 2022 億ドルに増加します。」です。

この例のように、検索結果の数に基づいて正解を検索することができます。最終出力を構成するソースの帰属について詳しく知りたい場合は、 ソースの詳細を表示 ナレッジベースに基づいて生成された回答を検証します。
コンソールを使用してナレッジ ベース プロンプト テンプレートをカスタマイズする
ユースケースに基づいて、デフォルトのプロンプトを独自のプロンプトでカスタマイズすることもできます。コンソールでこれを行うには、次の手順を実行します。
- 前のセクションの手順を繰り返して、ナレッジ ベースのテストを開始します。
- 有効にします 応答を生成する.

- 応答生成用に選択したモデルを選択します。
この投稿では例として Claude v2 モデルを使用します。 Claude 3 Sonnet および Haiku モデルも生成できます。
- 選択する 申し込む をクリックして次に進みます。

モデルを選択すると、という新しいセクションが表示されます。 ナレッジベースプロンプトテンプレート の下に表示されます 構成.
- 選択する 編集 プロンプトのカスタマイズを開始します。
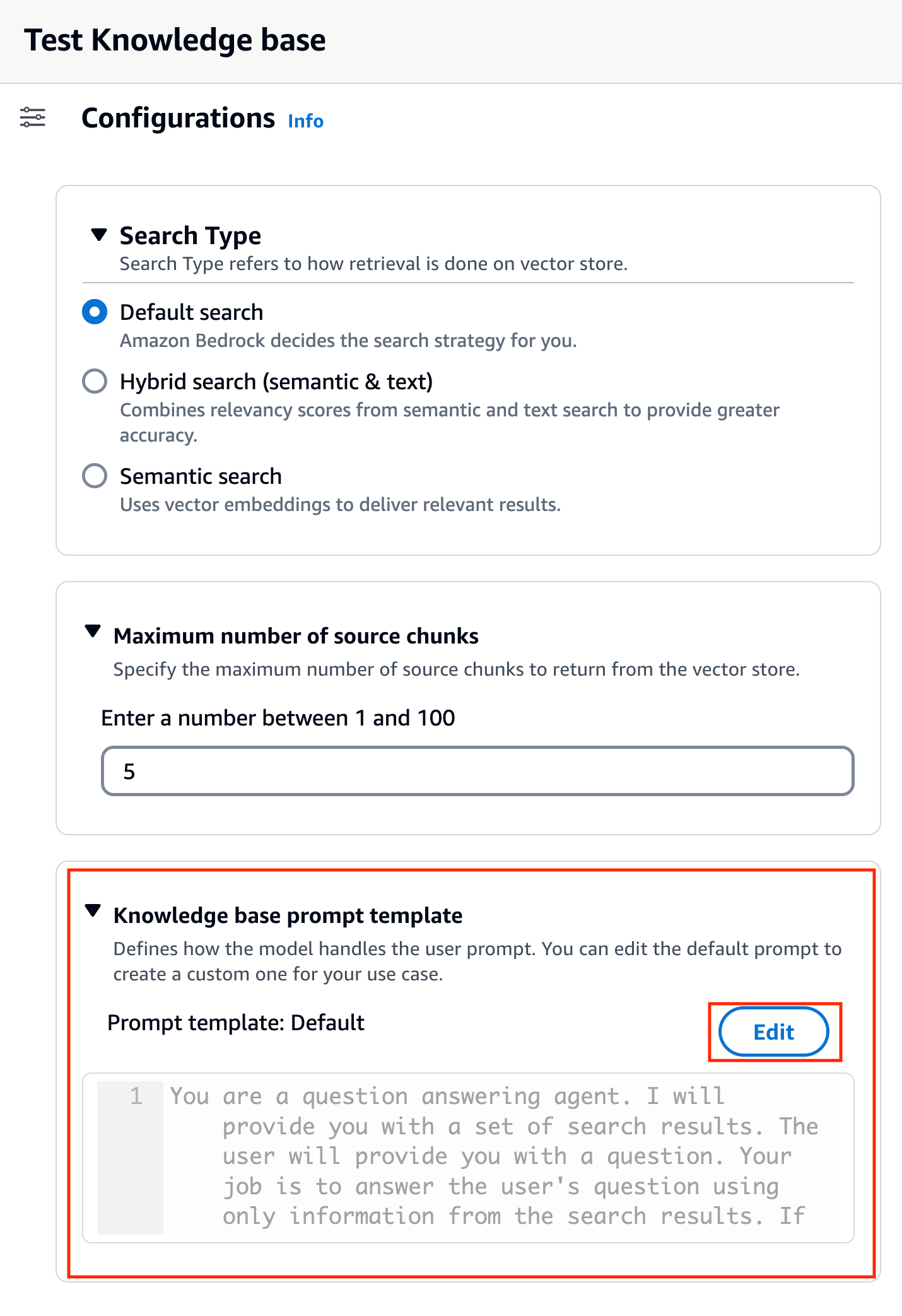
- プロンプト テンプレートを調整して、取得した結果の使用方法とコンテンツの生成方法をカスタマイズします。
この投稿では、カスタム プロンプトを備えた Amazon 財務レポートを使用して「Financial Advisor AI システム」を作成するための例をいくつか示しました。プロンプト エンジニアリングのベスト プラクティスについては、以下を参照してください。 迅速なエンジニアリングガイドライン.
次に、デフォルトのプロンプト テンプレートをいくつかの異なる方法でカスタマイズし、応答を観察します。
まずデフォルトのプロンプトを使用してクエリを試してみましょう。 「2019年と2021年のAmazonの収益はいくらでしたか?」と尋ねます。以下にその結果を示します。

出力から、取得した知識に基づいて自由形式の応答を生成していることがわかります。参考までに引用箇所も記載しておきます。
生成されたレスポンスを JSON として標準化するなど、フォーマットする方法について追加の指示を与えたいとします。これらの指示は、情報を取得した後の別のステップとして、プロンプト テンプレートの一部として追加できます。
最終的な応答には必要な構造が含まれています。

プロンプトをカスタマイズすることにより、生成される応答の言語を変更することもできます。次の例では、スペイン語で回答するようにモデルに指示します。

取り外した後 $output_format_instructions$ デフォルトのプロンプトからは、生成された応答からの引用が削除されます。
次のセクションでは、SDK でこれらの機能を使用する方法について説明します。
SDKを使用して結果の最大数を構成する
SDK を使用して結果の最大数を変更するには、次の構文を使用します。この例のクエリは、「Amazon の年間収益は何年に 245 億ドルから 434 億ドルに増加しましたか?」です。正解は「Amazon の年間収益は 245 年の 2019 億ドルから 434 年の 2022 億ドルに増加します。」です。
'numberOfResults' の下のオプション 'retrievalConfiguration' を使用すると、取得する結果の数を選択できます。の出力 RetrieveAndGenerate API には、生成された応答、ソースの帰属、および取得されたテキスト チャンクが含まれます。
以下は、「」のさまざまな値の結果です。numberOfResults' パラメーター。まず、設定します numberOfResults = 5.
それから設定します numberOfResults = 12.
SDKを使用してナレッジベースのプロンプトテンプレートをカスタマイズする
SDK を使用してプロンプトをカスタマイズするには、さまざまなプロンプト テンプレートで次のクエリを使用します。この例のクエリは「2019 年と 2021 年の Amazon の収益はいくらですか?」です。
以下はデフォルトのプロンプト テンプレートです。
以下は、カスタマイズされたプロンプト テンプレートです。
デフォルトのプロンプト テンプレートを使用すると、次の応答が得られます。
![]()
応答を特定の形式 (JSON など) で標準化するなど、応答生成の出力形式に関する追加の指示を提供する場合は、追加のガイダンスを提供して既存のプロンプトをカスタマイズできます。カスタム プロンプト テンプレートを使用すると、次の応答が得られます。

'promptTemplate' のオプションgenerationConfiguration' を使用すると、プロンプトをカスタマイズして、回答生成をより適切に制御できます。
まとめ
この投稿では、Amazon Bedrock のナレッジベースに 2 つの新機能を導入しました。それは、検索結果の最大数の調整と、デフォルトのプロンプトテンプレートのカスタマイズです。 RetrieveAndGenerate API。生成される応答のパフォーマンスと精度を向上させるために、コンソールおよび SDK 経由でこれらの機能を構成する方法を示しました。最大結果を増やすと、より包括的な情報が提供されます。一方、プロンプト テンプレートをカスタマイズすると、基礎モデルの指示を微調整して、特定のユースケースに合わせて調整することができます。これらの機能強化により、柔軟性と制御が向上し、RAG ベースのアプリケーションに合わせたエクスペリエンスを提供できるようになります。
AWS 環境での実装を開始するための追加リソースについては、以下を参照してください。
著者について
 サンディープ・シン アマゾン ウェブ サービスのシニア ジェネレーティブ AI データ サイエンティストで、ジェネレーティブ AI による企業のイノベーションを支援しています。専門は生成 AI、人工知能、機械学習、システム設計です。彼は、さまざまな業界の複雑なビジネス問題を解決し、効率と拡張性を最適化する、最先端の AI/ML を活用したソリューションの開発に情熱を注いでいます。
サンディープ・シン アマゾン ウェブ サービスのシニア ジェネレーティブ AI データ サイエンティストで、ジェネレーティブ AI による企業のイノベーションを支援しています。専門は生成 AI、人工知能、機械学習、システム設計です。彼は、さまざまな業界の複雑なビジネス問題を解決し、効率と拡張性を最適化する、最先端の AI/ML を活用したソリューションの開発に情熱を注いでいます。
 ワン・スイン AWS の AI/ML スペシャリスト ソリューション アーキテクトです。 彼女は、機械学習、金融情報サービス、経済学の学際的な教育背景を持ち、現実世界のビジネス上の問題を解決するデータ サイエンスおよび機械学習アプリケーションの構築に長年の経験を持っています。 彼女は、顧客が適切なビジネス上の質問を特定できるよう支援し、適切な AI/ML ソリューションを構築することに喜びを感じています。 余暇には、歌うことと料理が大好きです。
ワン・スイン AWS の AI/ML スペシャリスト ソリューション アーキテクトです。 彼女は、機械学習、金融情報サービス、経済学の学際的な教育背景を持ち、現実世界のビジネス上の問題を解決するデータ サイエンスおよび機械学習アプリケーションの構築に長年の経験を持っています。 彼女は、顧客が適切なビジネス上の質問を特定できるよう支援し、適切な AI/ML ソリューションを構築することに喜びを感じています。 余暇には、歌うことと料理が大好きです。
 シェリー・ディン は、アマゾン ウェブ サービス (AWS) のシニア人工知能 (AI) および機械学習 (ML) スペシャリスト ソリューション アーキテクトです。 彼女は機械学習に関して豊富な経験を持ち、コンピューター サイエンスの博士号を取得しています。 彼女は主に公共部門の顧客と協力して AI/ML 関連のさまざまなビジネス課題に取り組み、AWS クラウドでの機械学習の取り組みを加速できるよう支援しています。 顧客をサポートしていないときは、屋外アクティビティを楽しんでいます。
シェリー・ディン は、アマゾン ウェブ サービス (AWS) のシニア人工知能 (AI) および機械学習 (ML) スペシャリスト ソリューション アーキテクトです。 彼女は機械学習に関して豊富な経験を持ち、コンピューター サイエンスの博士号を取得しています。 彼女は主に公共部門の顧客と協力して AI/ML 関連のさまざまなビジネス課題に取り組み、AWS クラウドでの機械学習の取り組みを加速できるよう支援しています。 顧客をサポートしていないときは、屋外アクティビティを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

