データの急激な増加に伴い、企業は個人を特定できる情報 (PII) を含む、膨大な量の多種多様なデータを処理しています。 PII は、XNUMX 人の個人を特定、連絡、または居場所を特定できる情報に関連する法律用語です。 機密データを大規模に特定して保護することは、ますます複雑になり、費用と時間がかかります。 組織は、データプライバシー、コンプライアンス、および次のような規制要件を遵守する必要があります。 GDPR & CCPA、コンプライアンスを維持するには、PII を特定して保護することが重要です。 名前、社会保障番号 (SSN)、住所、電子メール、運転免許証などの PII を含む機密データを特定する必要があります。 識別した後でも、機密データの編集、マスキング、または暗号化を大規模に実装するのは面倒です。
多くの企業は、PII の特定とラベル付けを手作業で行っており、時間がかかり、間違いが発生しやすくなっています。 レビューをみる。 その結果、機密データが保護されず、規制上の罰則や侵害インシデントに対して脆弱になります。
この投稿では、PII データを検出するための自動ソリューションを提供します。 Amazonレッドシフト AWSグルー.
ソリューションの概要
このソリューションでは、Redshift データ ウェアハウス上のデータ内の PII を検出し、データを取得して保護します。 当社では以下のサービスを利用しております。
- Amazonレッドシフト は、SQL を使用してデータ ウェアハウス、運用データベース、データ レイクにわたる構造化データおよび半構造化データを分析するクラウド データ ウェアハウジング サービスです。また、AWS が設計したハードウェアと機械学習 (ML) を使用して、あらゆる規模で最高の価格/パフォーマンスを提供します。 私たちのソリューションでは、Amazon Redshift を使用してデータを保存します。
- AWSグルー は、分析、ML、アプリケーション開発のためのデータの検出、準備、結合を簡単に行うことができるサーバーレス データ統合サービスです。 AWS Glue を使用して、Amazon Redshift に保存されている PII データを検出します。
- Amazon シンプル ストレージ サービス (Amazon S3) は、業界をリードするスケーラビリティ、データ可用性、セキュリティ、パフォーマンスを提供するストレージ サービスです。
次の図は、ソリューションアーキテクチャを示しています。
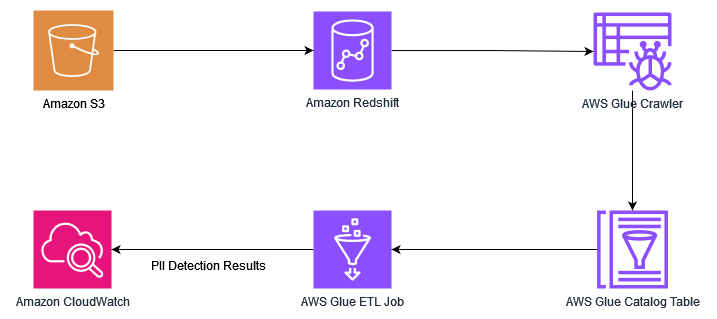
このソリューションには、次の高レベルの手順が含まれています。
- を使用してインフラストラクチャをセットアップする AWS CloudFormation テンプレート。
- Amazon S3 から Redshift データ ウェアハウスにデータをロードします。
- AWS Glue クローラーを実行して、AWS Glue データカタログにテーブルを追加します。
- AWS Glue ジョブを実行して PII データを検出します。
- 次を使用して出力を分析します。 アマゾンクラウドウォッチ.
前提条件
この投稿で作成したリソースは、VPC がプライベート サブネットとその両方の識別子とともに配置されていることを前提としています。 これにより、VPC とサブネットの構成を大幅に変更することがなくなります。 したがって、公開することを選択した VPC とサブネットに基づいて VPC エンドポイントを設定したいと考えています。
始める前に、前提条件として次のリソースを作成します。
- 既存の VPC
- その VPC 内のプライベートサブネット
- VPC ゲートウェイ S3 エンドポイント
- VPC STS ゲートウェイ エンドポイント
AWS CloudFormation を使用してインフラストラクチャをセットアップする
CloudFormation テンプレートを使用してインフラストラクチャを作成するには、次の手順を実行します。
- AWS アカウントで AWS CloudFormation コンソールを開きます。
- 選択する 発射スタック:

- 選択する Next.
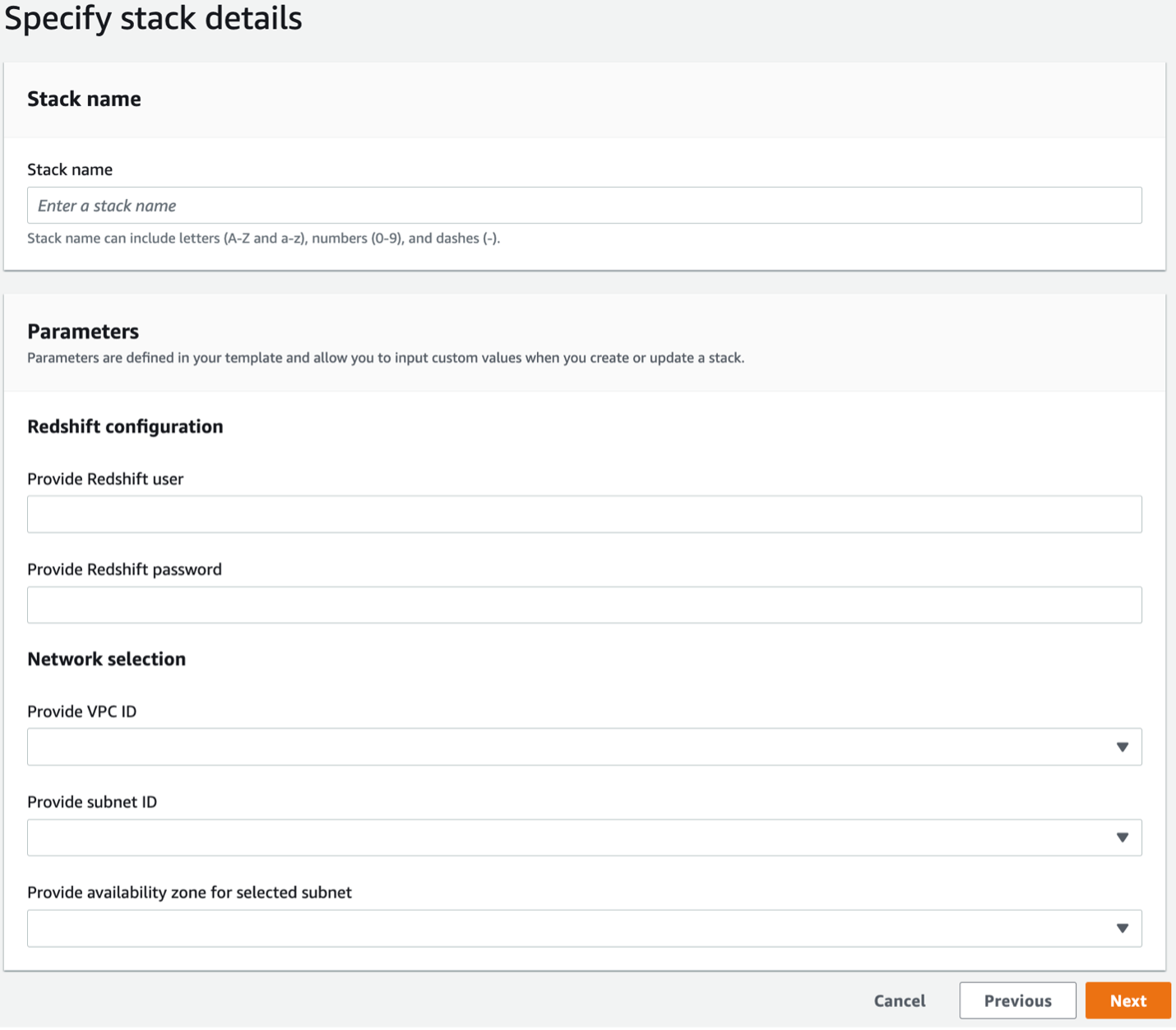
- 次の情報を提供します。
- スタック名
- Amazon Redshift ユーザー名
- Amazon Redshiftのパスワード
- VPC ID
- サブネットID
- サブネット ID のアベイラビリティーゾーン
- 選択する Next.
- 次のページで、 Next.
- 詳細を確認して選択します AWS CloudFormationがIAMリソースを作成する可能性があることを認めます.
- 選択する スタックを作成.
- の値に注意してください。
S3BucketName&RedshiftRoleArnスタックの上にある 出力 タブには何も表示されないことに注意してください。
Amazon S3 から Redshift データ ウェアハウスにデータをロードする
COPYコマンド、3 つ以上の S3 バケットにあるファイルからデータをロードできます。 FROM 句を使用して、COPY コマンドが Amazon S3 内のファイルを検索する方法を示します。 FROM 句の一部としてデータ ファイルへのオブジェクト パスを指定することも、S3 オブジェクト パスのリストを含むマニフェスト ファイルの場所を指定することもできます。 Amazon SXNUMX からの COPY は HTTPS 接続を使用します。
この投稿では、個人の健康状態のサンプルを使用します データセット。 次の手順でデータをロードします。
- Amazon S3 コンソールで、CloudFormation テンプレートから作成された S3 バケットに移動し、データセットを確認します。
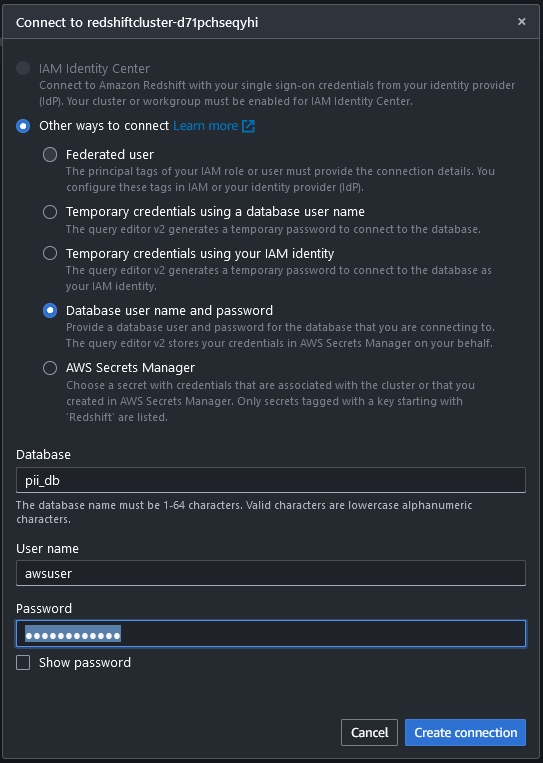
- を使用して Redshift データ ウェアハウスに接続します。 クエリエディタv2 ユーザー名とパスワードとともに CloudFormation スタックを使用して作成したデータベースとの接続を確立します。
接続したら、次のコマンドを使用して Redshift データ ウェアハウスにテーブルを作成し、データをコピーできます。
- 次のクエリを使用してテーブルを作成します。
- S3 バケットからデータをロードします。
次のプレースホルダーに値を指定します。
- 赤方偏移ロールアーン – CloudFormation スタックで ARN を見つけます。 出力 タブ
- S3バケット名 – CloudFormation スタックのバケット名に置き換えます
- AWS リージョン – CloudFormation テンプレートをデプロイしたリージョンに変更します
- データがロードされたことを確認するには、次のコマンドを実行します。

AWS Glue クローラーを実行してデータカタログにテーブルを追加します
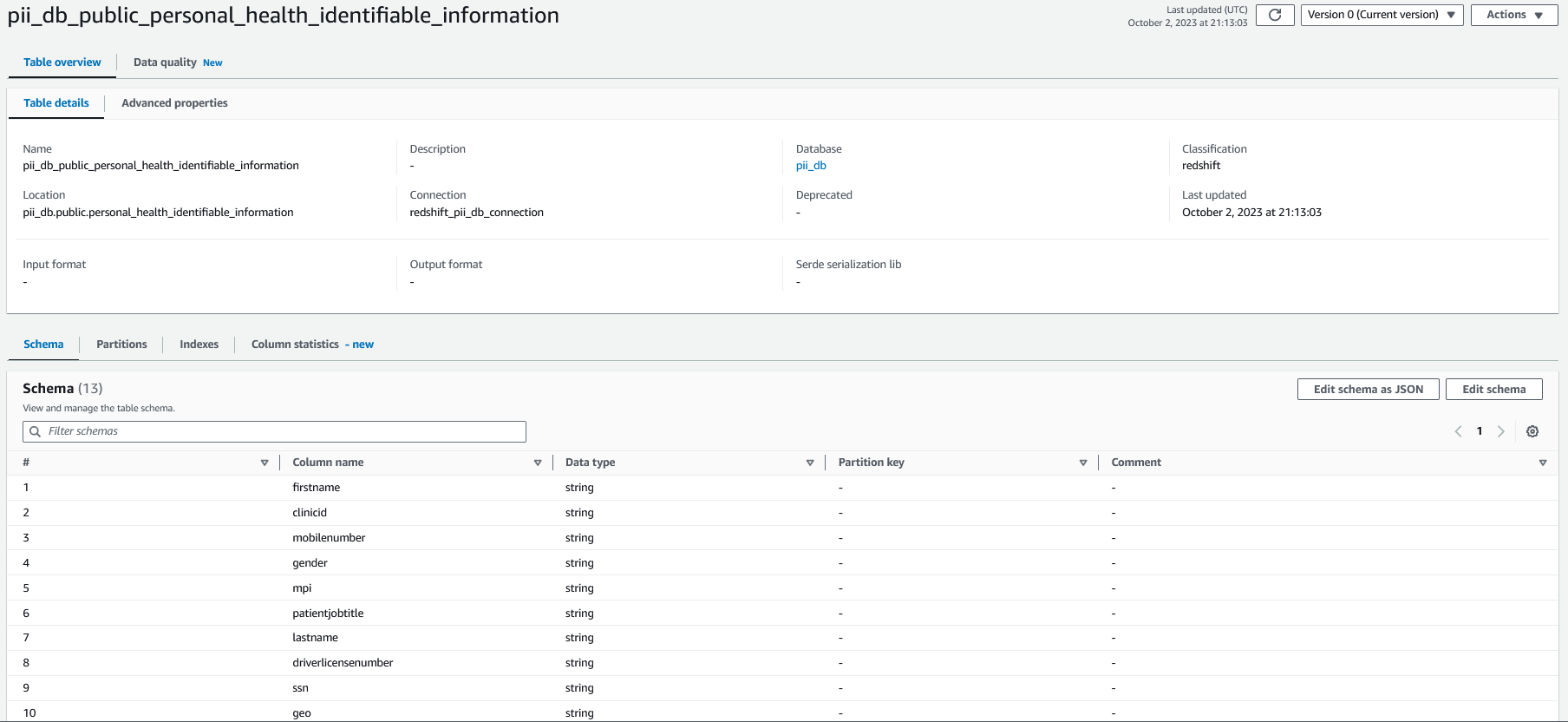
AWS Glue コンソールで、CloudFormation スタックの一部としてデプロイしたクローラを次の名前で選択します。 crawler_pii_db、を選択します クローラーを実行する.

クローラーが完了すると、データベース内に次の名前のテーブルが作成されます。 pii_db は AWS Glue データ カタログに入力され、テーブル スキーマは次のスクリーンショットのようになります。
AWS Glue ジョブを実行して PII データを検出し、Amazon Redshift の対応する列をマスクします。
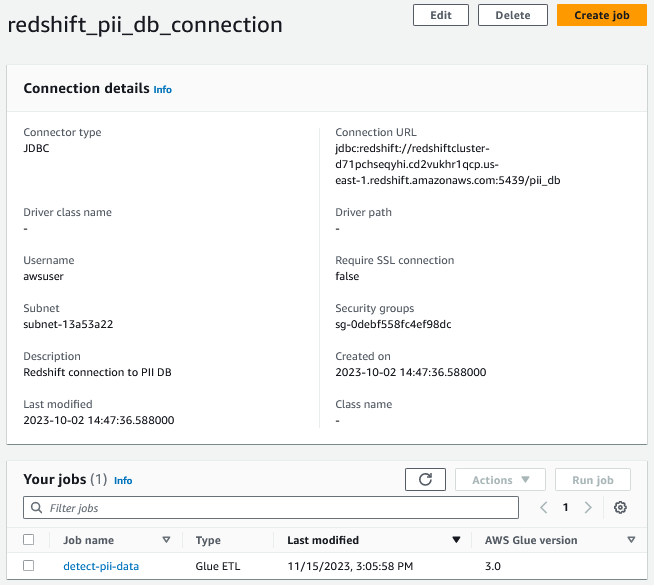
AWS Glue コンソールで、選択します ETL ジョブ ナビゲーション ペインで detect-pii-data ジョブを見つけて、その構成を理解します。 基本プロパティと詳細プロパティは、CloudFormation テンプレートを使用して構成されます。
基本的なプロパティは次のとおりです。
- タイプ – スパーク
- 接着剤バージョン – グルー 4.0
- 言語設定 -Python
デモンストレーションの目的で、ジョブ ブックマーク オプションと自動スケール機能は無効になっています。

また、接続とジョブ パラメーターに関する詳細プロパティも構成します。
Amazon Redshift に存在するデータにアクセスするために、JDBC 接続を利用する AWS Glue 接続を作成しました。
カスタム パラメーターもキーと値のペアとして提供します。 この投稿では、PII を XNUMX つの異なる検出カテゴリに分類します。
- ユニバーサル –
PERSON_NAME,EMAIL,CREDIT_CARD - ヒパー –
PERSON_NAME,PHONE_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT,USA_DRIVING_LICENSE,USA_HCPCS_CODE,USA_NATIONAL_DRUG_CODE,USA_NATIONAL_PROVIDER_IDENTIFIER,USA_DEA_NUMBER,USA_HEALTH_INSURANCE_CLAIM_NUMBER,USA_MEDICARE_BENEFICIARY_IDENTIFIER - ネットワーキング –
IP_ADDRESS,MAC_ADDRESS - アメリカ –
PHONE_NUMBER,USA_PASSPORT_NUMBER,USA_SSN,USA_ITIN,BANK_ACCOUNT - カスタム – 座標
このソリューションは米国地域に基づいて作成されているため、他の国からこのソリューションを試している場合は、カスタム カテゴリを使用してカスタム PII フィールドを指定できます。
デモンストレーションの目的で、単一のテーブルを使用し、それを次のパラメータとして渡します。
--table_name: table_nameこの投稿では、テーブルに名前を付けます personal_health_identifiable_information.

これらのパラメータは、個々のビジネス ユースケースに基づいてカスタマイズできます。
ジョブを実行して、 Success 状態。
この仕事にはXNUMXつの目標があります。 最初の目標は、Redshift テーブル内の PII データ関連の列を特定し、これらの列名のリストを作成することです。 XNUMX 番目の目標は、ターゲット テーブルの特定の列のデータを難読化することです。 XNUMX 番目の目標の一部として、テーブル データを読み取り、ユーザー定義のマスキング関数をそれらの特定の列に適用し、Redshift ステージング テーブルを使用してターゲット テーブル内のデータを更新します (stage_personal_health_identifiable_information) アップサート用。
あるいは、動的データ マスキング (DDM) Amazon Redshift でデータ ウェアハウス内の機密データを保護します。
CloudWatch を使用して出力を分析する
ジョブが完了したら、CloudWatch ログを確認して、AWS Glue ジョブがどのように実行されたかを理解しましょう。 を選択すると、CloudWatch ログに移動できます。 出力ログ AWS Glue コンソールのジョブの詳細ページ。

このジョブは、AWS Glue ジョブの機密データ検出フィールドを使用して渡されたカスタム フィールドを含む、PII データを含むすべての列を識別しました。

クリーンアップ
インフラストラクチャをクリーンアップして追加料金を回避するには、次の手順を実行します。
- S3 バケットを空にします。
- 作成したエンドポイントを削除します。
- AWS CloudFormation コンソールから CloudFormation スタックを削除し、残りのリソースを削除します。

まとめ
このソリューションを使用すると、AWS Glue ジョブを使用して Redshift クラスターにあるデータを自動的にスキャンし、PII を特定し、必要なアクションを実行できます。 これは、組織のセキュリティ、コンプライアンス、ガバナンス、データ保護機能に役立ち、データ セキュリティとデータ ガバナンスに貢献します。
著者について
 マニカンタ ゴナ は、AWS プロフェッショナル サービスのデータおよび ML エンジニアです。 彼は IT 分野で 2021 年以上の経験を持ち、6 年に AWS に入社しました。 AWS では、Amazon OpenSearch Service を使用したデータ レイクの実装と検索、分析ワークロードに重点を置いています。 余暇には、ガーデニングをしたり、夫と一緒にハイキングやサイクリングに出かけたりするのが大好きです。
マニカンタ ゴナ は、AWS プロフェッショナル サービスのデータおよび ML エンジニアです。 彼は IT 分野で 2021 年以上の経験を持ち、6 年に AWS に入社しました。 AWS では、Amazon OpenSearch Service を使用したデータ レイクの実装と検索、分析ワークロードに重点を置いています。 余暇には、ガーデニングをしたり、夫と一緒にハイキングやサイクリングに出かけたりするのが大好きです。
 デニス・ノヴィコフ は、アマゾン ウェブ サービスのプロフェッショナル サービス チームのシニア データ レイク アーキテクトです。 彼は、企業顧客向けの分析、データ管理、ビッグデータ システムの設計と実装を専門としています。
デニス・ノヴィコフ は、アマゾン ウェブ サービスのプロフェッショナル サービス チームのシニア データ レイク アーキテクトです。 彼は、企業顧客向けの分析、データ管理、ビッグデータ システムの設計と実装を専門としています。
 アンジャン・ムケルジー AWS のデータ レイク アーキテクトであり、ビッグデータと分析ソリューションを専門としています。 彼は、顧客が AWS プラットフォーム上でスケーラブルで信頼性が高く、安全で高性能なアプリケーションを構築できるよう支援しています。
アンジャン・ムケルジー AWS のデータ レイク アーキテクトであり、ビッグデータと分析ソリューションを専門としています。 彼は、顧客が AWS プラットフォーム上でスケーラブルで信頼性が高く、安全で高性能なアプリケーションを構築できるよう支援しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/automatically-detect-personally-identifiable-information-in-amazon-redshift-using-aws-glue/

