ペタバイト規模のデータを検出する必要があるデータ レイクのお客様には、 AWSGlueクローラー バックグラウンドでデータを検出してカタログ化する一般的な方法です。 これにより、ユーザーは複数のデータ ソースから関連データを検索して見つけることができます。 多くのお客様は、MongoDB Atlas などの管理された運用データベースにもデータを持っており、それを次のデータと組み合わせる必要があります。 Amazon シンプル ストレージ サービス (Amazon S3) データレイクを使用して洞察を導き出します。 AWS Glue クローラーが MongoDB Atlas をサポートするようになったため、MongoDB コレクションの進化を理解し、意味のある洞察を簡単に抽出できるようになりました。
AWSグルー は、分析、機械学習 (ML)、およびアプリケーション開発のために複数のソースからデータを簡単に検出、準備、移動、および統合できるサーバーレス データ統合サービスです。
MongoDBアトラス は、AWS テクノロジー パートナーの開発者向けデータ サービスです。 モンゴDB株式会社. このサービスは、トランザクション処理、関連性に基づく検索、リアルタイム分析、およびモバイルからクラウドへのデータ同期を統合アーキテクチャに結合します。
本日のローンチにより、MongoDB Atlas をクロールする AWS Glue クローラーを作成およびスケジュールできます。 クローラーのセットアップでは、MongoDB をデータ ソースとして選択できます。 その後、MongoDB Atlas との AWS Glue 接続を作成し、MongoDB Atlas クラスターの名前と認証情報を提供できます。 この投稿では、このプロセスについて説明します。
ソリューションの概要
次のアーキテクチャは、AWS Glue を使用して MongoDB Atlas データベースとコレクションをスキャンする方法を示しています。
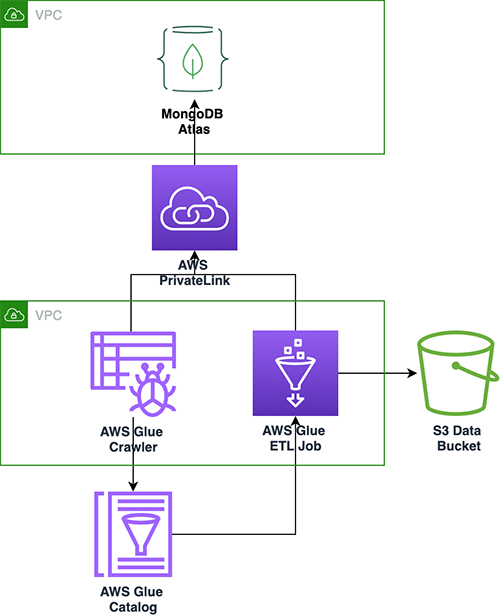
クローラーを実行するたびに、クローラーは、AWS Glue データカタログ内の MongoDB Atlas コレクション、ビュー、具体化されたビューに対する更新または削除など、指定されたコレクションおよびカタログ情報を検査します。 AWS Glue Studio では、AWS Glue Data Catalog をソースとして使用して、MongoDB Atlas からデータをプルし、Amazon S3 ターゲットに入力できます。 最後に、このジョブを実行して MongoDB Atlas からデータを読み取り、結果を Amazon S3 に書き込むことができるため、次のような AWS サービスと統合する可能性が開かれます。 アマゾンセージメーカー, アマゾンクイックサイト、 もっと。
以下のセクションでは、MongoDB Atlas をデータソースとして AWS Glue クローラーを作成する方法について説明します。 次に、AWS Glue 接続を作成し、MongoDB Atlas クラスターの情報と認証情報を提供します。 次に、クロールする MongoDB Atlas データベースとコレクションを指定します。
前提条件
この投稿を進めるには、MongoDB Atlas と AWSマネジメントコンソール. また、サブネットが事前設定された VPC にアクセスできることも前提としています。 アマゾン バーチャル プライベート クラウド (Amazon VPC)。 この記事の後半で構成するクローラーは VPC で実行され、MongoDB Atlas に接続します。 AWS プライベートリンク エンドポイントを使用して定義します
MongoDB Atlas をセットアップする
MongoDB Atlas を構成するには、次の手順を実行します。
- AWS で MongoDB クラスターを構成します。 手順については、を参照してください。 MongoDB クラスターをセットアップする方法.
- で説明されている手順に従って、PrivateLink を構成します。 AWS PrivateLink を使用してアプリケーションを MongoDB Atlas データ プレーンに安全に接続する.
これにより、ネットワーク アーキテクチャを簡素化し、トラフィックが AWS ネットワーク上にとどまるようにすることができます。
次に、MongoDB Atlas コンソールの Connect UI から MongoDB クラスター接続文字列を取得します。
- MongoDB Atlas コンソールで、 お問合せ, プライベート エンドポイント, 接続方法.
- SRV 接続文字列をコピーします。

以降の手順では、この SRV 接続文字列を使用します。
次のスクリーンショットは、MongoDB Atlas にサンプル コレクションを読み込んだことを示しています。これは、次の手順でクロールします。 このコレクションのレコードには、複数の配列とネストされたデータが含まれていることに注意してください。

AWS Glue を使用して MongoDB Atlas 接続をセットアップする
AWS Glue クローラーを設定する前に、AWS Glue で MongoDB Atlas 接続を作成する必要があります。
- AWS Glue Studioコンソールで、 コネクタ ナビゲーションペインに表示されます。
- 選択する 接続を作成する.

- 接続の詳細を入力するときは、MongoDB Atlas で以前に取得した SRV 接続文字列を使用します。
- ネットワークオプション セクションでは、VPC とサブネットは、以前に構成した PrivateLink 設定に対応している必要があります。

MongoDB クローラーを作成する
接続を作成したら、AWS Glue クローラーを作成できます。
- AWS Glue コンソールで、選択します Crawlers ナビゲーションペインに表示されます。
- 選択する クローラーを作成する.

- 名前 、名前を入力します。
- データ ソースには、前に構成した MongoDB Atlas データ ソースを選択し、MongoDB Atlas データベースとコレクションに対応するパスを指定します。

- セキュリティ設定、出力、およびスケジューリングを構成します。

- ソフトウェア設定ページで、下図のように Crawlers ページ、選択 クローラーを実行する.

クローラーが MongoDB コレクションのクロールを完了すると、そのステータスが次のように表示されます。 記入済みの.
MongoDB AWS Glue データベースとテーブルを確認する
AWS Glue データカタログに移動して、クローラーによって作成されたテーブルを調べることができます。

テーブルを選択して、スキーマとその他のメタデータを表示します。

クローラーがネストされたデータを STRUCT としてキャプチャし、ARRAY フィールドを正しくリストしたことに注意してください。
MongoDB Atlas データを Amazon S3 にインポートする
次に、MongoDB Atlas ベースの AWS Glue Data Catalog テーブルを使用して、コードを記述せずにデータ インポートを実行します。 AWS Glue Studio を使用して定型コードをすばやく構築します。 または、スクリプト エディターでスクリプトを作成することもできます。
- AWS Glue Studioコンソールで、 Jobs > Create New Job ナビゲーションペインに表示されます。
- 選択する ジョブを作成.
- 選択 ソースとターゲットを使用したビジュアル.
- ソースとして Data Catalog テーブルを選択し、ターゲットとして Amazon S3 を選択します。

- AWS Glue Studio UI で、S3 バケット名などの追加パラメータを指定し、ドロップダウン メニューからデータベースとテーブルを選択します。
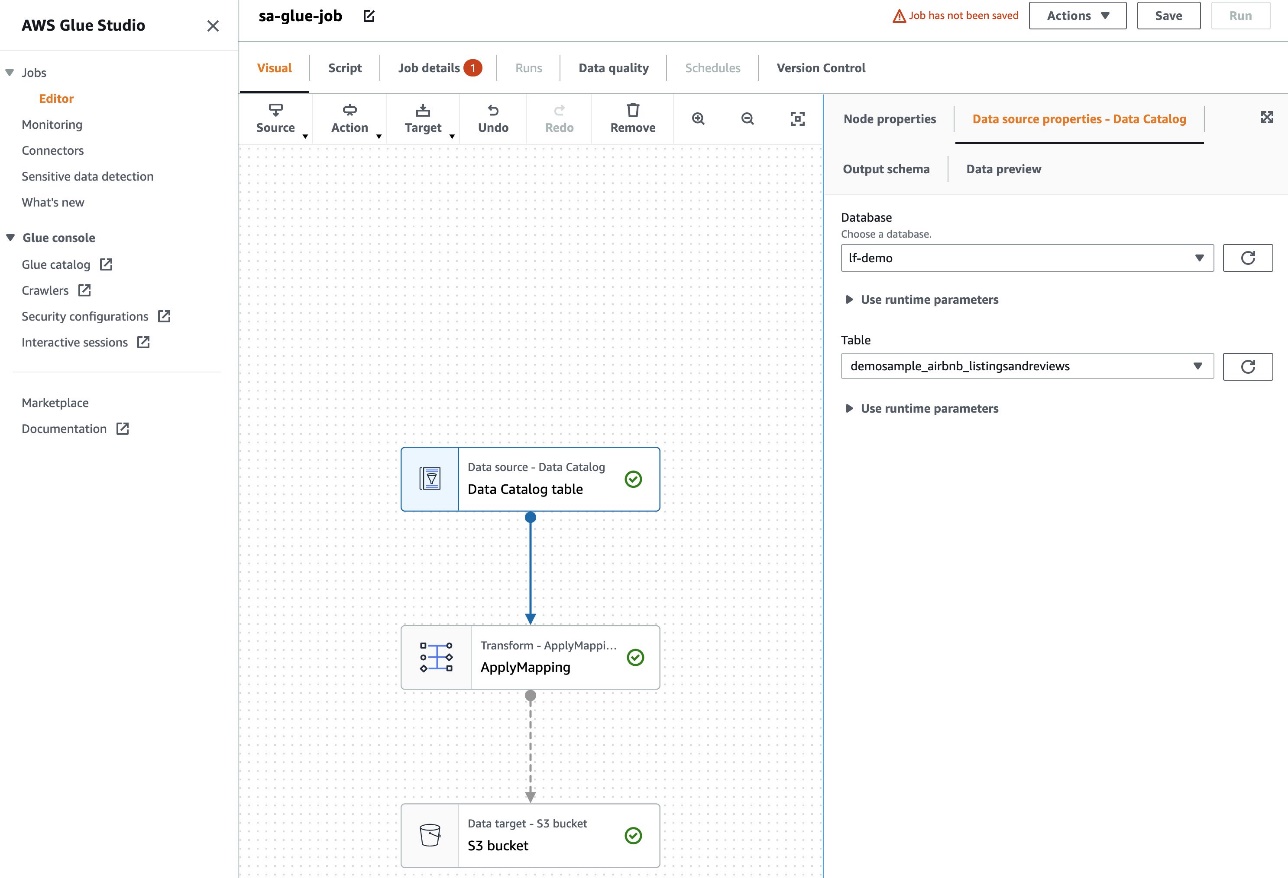
- 次に、AWS Glue Studio によって構築された、生成されたスクリプトを確認します。 次のように、スクリプトにデータベースとコレクションを追加する必要があります。

ETL ジョブが完了すると、抽出されたデータが Amazon S3 で利用可能になります。
- Amazon S3コンソールで、 バケット ナビゲーションペインに表示されます。
- 抽出されたファイルを含むバケットとフォルダーを選択します。
- ファイルを選択し、 メニュー、選択 S3Selectを使用したクエリ ファイルの内容を表示します。

クリーンアップ
このチュートリアルで使用されるサービスの料金が発生しないようにするには、次の手順を実行してリソースを削除します。
- AWS Glue コンソールで、選択します Crawlers ナビゲーションペインに表示されます。
- クローラーを選択し、 Action メニュー、選択 クローラーを削除する.
- AWS Glue Studioコンソールで、 求人を見る.
- 作成したジョブを選択し、 メニュー、選択 ジョブを削除.
- AWS Glue コンソールに戻り、選択します テーブル類 ナビゲーションペインに表示されます。
- テーブルを選択して選択します 削除.
- 選択する データベース ナビゲーションペインに表示されます。
- データベースを選択して選択します 削除.
- Amazon VPCコンソールで、 エンドポイント ナビゲーションペインに表示されます。
- 作成した PrivateLink エンドポイントを選択し、 メニュー、選択 VPC エンドポイントを削除する.
まとめ
この投稿では、AWS Glue クローラーをセットアップして MongoDB Atlas コレクションをクロールし、メタデータを収集して、AWS Glue データカタログにテーブルレコードを作成する方法を示しました。 Data Catalog テーブルを使用して、AWS Glue Studio UI を使用して ETL プロセスを作成し、コードを 3 行も書かずに MongoDB Atlas コレクションから SXNUMX バケットにデータを抽出しました。
を構成することで、これを自分で試すことができます AWSGlueクローラー、AWS Glue ETL ジョブを作成する AWS グルースタジオ、および起動 QuickStart からの MongoDB Atlas またはから AWS Marketplace の MongoDB Atlas.
このクローラー機能のリリースに貢献してくれた Julio Montes de Oca、Mita Gavade、Alex Prazma に感謝します。
著者について
 イゴール・アレクゼーフ AWS のデータおよび分析ドメインのシニア パートナー ソリューション アーキテクトです。 彼の役割では、Igor は戦略的パートナーと協力して、AWS に最適化された複雑なアーキテクチャの構築を支援しています。 AWS に入社する前は、データ/ソリューション アーキテクトとして、Hadoop エコシステムのいくつかのデータ レイクを含む、ビッグ データ ドメインで多くのプロジェクトを実装しました。 データ エンジニアとして、AI/ML を不正検出やオフィス オートメーションに適用することに携わっていました。
イゴール・アレクゼーフ AWS のデータおよび分析ドメインのシニア パートナー ソリューション アーキテクトです。 彼の役割では、Igor は戦略的パートナーと協力して、AWS に最適化された複雑なアーキテクチャの構築を支援しています。 AWS に入社する前は、データ/ソリューション アーキテクトとして、Hadoop エコシステムのいくつかのデータ レイクを含む、ビッグ データ ドメインで多くのプロジェクトを実装しました。 データ エンジニアとして、AI/ML を不正検出やオフィス オートメーションに適用することに携わっていました。
 サンディープ・アドワンカー AWS のシニア テクニカル プロダクト マネージャーです。 カリフォルニア ベイ エリアに拠点を置く彼は、世界中の顧客と協力して、ビジネス要件と技術要件を製品に変換し、顧客がデータの管理、保護、およびアクセスの方法を改善できるようにしています。
サンディープ・アドワンカー AWS のシニア テクニカル プロダクト マネージャーです。 カリフォルニア ベイ エリアに拠点を置く彼は、世界中の顧客と協力して、ビジネス要件と技術要件を製品に変換し、顧客がデータの管理、保護、およびアクセスの方法を改善できるようにしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/introducing-mongodb-atlas-metadata-collection-with-aws-glue-crawlers/

