ズーデジタル は、オリジナルのテレビや映画のコンテンツをさまざまな言語、地域、文化に適応させるためのエンドツーエンドのローカリゼーションおよびメディア サービスを提供します。世界最高のコンテンツクリエイターにとって、グローバル化が容易になります。エンターテイメント業界の大手から信頼されている ZOO Digital は、吹き替え、字幕、スクリプト作成、コンプライアンスなど、高品質のローカリゼーションおよびメディア サービスを大規模に提供しています。
一般的なローカリゼーション ワークフローでは、手動で話者をダイアライゼーションする必要があり、音声ストリームは話者の ID に基づいてセグメント化されます。この時間のかかるプロセスは、コンテンツを別の言語に吹き替える前に完了する必要があります。手動の方法では、30 分のエピソードのローカライズに 1 ~ 3 時間かかる場合があります。 ZOO Digital は自動化により、30 分以内にローカリゼーションを達成することを目指しています。
この投稿では、次を使用してメディア コンテンツを日記化するためのスケーラブルな機械学習 (ML) モデルのデプロイについて説明します。 アマゾンセージメーカー、に焦点を当てて ウィスパーX モデル。
経歴
ZOO Digital のビジョンは、ローカライズされたコンテンツをより迅速に提供することです。この目標は、手動で集中的に行う演習の性質と、コンテンツを手動でローカライズできる熟練した人材の少数の労働力によってさらにボトルネックになっています。 ZOO Digital は 11,000 人を超えるフリーランサーと協力し、600 年だけで 2022 億語以上の単語をローカライズしました。しかし、コンテンツ需要の増加により熟練人材の供給が追いつかなくなり、ローカリゼーション ワークフローを支援する自動化が必要となっています。
機械学習を通じてコンテンツワークフローのローカライゼーションを加速することを目的として、ZOO Digital は、顧客とワークロードを共同構築するための AWS による投資プログラムである AWS プロトタイピングを利用しました。この取り組みでは、ZOO Digital 開発者に SageMaker に関する実践的なトレーニングを提供しながら、ローカリゼーション プロセスの機能的なソリューションを提供することに焦点を当てました。 Amazon Transcribe, Amazon翻訳.
顧客の課題
タイトル (映画またはテレビ シリーズのエピソード) が書き起こされた後、キャラクターを演じるためにキャストされた声優にスピーカーが正しく割り当てられるように、スピーチの各セグメントにスピーカーを割り当てる必要があります。このプロセスは話者ダイアライゼーションと呼ばれます。 ZOO Digital は、経済的に実行可能でありながら、コンテンツを大規模に日記化するという課題に直面しています。
ソリューションの概要
このプロトタイプでは、元のメディア ファイルを指定された場所に保存しました。 Amazon シンプル ストレージ サービス (Amazon S3) バケット。この S3 バケットは、その中で新しいファイルが検出されたときにイベントを発行し、 AWSラムダ 関数。このトリガーの構成手順については、チュートリアルを参照してください。 Amazon S3 トリガーを使用して Lambda 関数を呼び出す。その後、Lambda 関数は推論のために SageMaker エンドポイントを呼び出しました。 Boto3 SageMaker ランタイム クライアント.
ウィスパーX モデル、に基づいて OpenAIのささやき、メディア資産の文字起こしと日記化を実行します。それは上に構築されています より速いささやき 再実装により、Whisper と比較して単語レベルのタイムスタンプのアライメントが改善され、最大 4 倍高速な文字起こしが可能になります。さらに、オリジナルの Whisper モデルには存在しなかった、スピーカーのダイアライゼーションが導入されています。 WhisperX は文字起こしに Whisper モデルを利用します。 Wav2Vec2 タイムスタンプのアライメントを強化するモデル (書き起こされたテキストと音声のタイムスタンプの同期を確保)、 ピャンノート ダイアライゼーション用のモデル。 FFmpegの ソースメディアからオーディオをロードするために使用され、さまざまなサポート メディア形式。 透過的でモジュール式のモデル アーキテクチャにより、将来必要に応じてモデルの各コンポーネントを交換できるため、柔軟性が得られます。ただし、WhisperX には完全な管理機能がなく、エンタープライズ レベルの製品ではないことに注意することが重要です。メンテナンスとサポートがなければ、運用環境の展開には適さない可能性があります。
このコラボレーションでは、WhisperX を SageMaker にデプロイし、評価しました。 非同期推論エンドポイント モデルをホストします。 SageMaker 非同期エンドポイントは、最大 1 GB のアップロード サイズをサポートし、トラフィックの急増を効率的に軽減し、オフピーク時のコストを節約する自動スケーリング機能を組み込んでいます。非同期エンドポイントは、このユースケースの映画やテレビ シリーズなどの大きなファイルの処理に特に適しています。
次の図は、この共同研究で実施した実験の中核となる要素を示しています。

次のセクションでは、SageMaker 上での WhisperX モデルのデプロイの詳細を掘り下げ、日記作成のパフォーマンスを評価します。
モデルとそのコンポーネントをダウンロードする
WhisperX は、転写、強制アライメント、ダイアライゼーションのための複数のモデルを含むシステムです。推論中にモデル アーティファクトをフェッチする必要がなく、SageMaker をスムーズに操作するには、すべてのモデル アーティファクトを事前にダウンロードすることが不可欠です。これらのアーティファクトは、開始時に SageMaker 提供コンテナにロードされます。これらのモデルには直接アクセスできないため、WhisperX ソースから説明とサンプル コードを提供し、モデルとそのコンポーネントをダウンロードする手順を提供します。
WhisperX は 6 つのモデルを使用します。
これらのモデルのほとんどは次の場所から入手できます。 ハグ顔 ハグフェイス_ハブライブラリを使用します。以下を使用します download_hf_model() これらのモデル成果物を取得する関数。次の pyannote モデルのユーザー契約に同意した後に生成される、Hugging Face からのアクセス トークンが必要です。
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
VAD モデルは Amazon S3 から取得され、Wav2Vec2 モデルは torchaudio.pipelines モジュールから取得されます。次のコードに基づいて、Hugging Face からのものを含むすべてのモデルのアーティファクトを取得し、指定されたローカル モデル ディレクトリに保存できます。
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
モデルを提供するために適切な AWS Deep Learning コンテナを選択します
前述のサンプル コードを使用してモデル アーティファクトを保存した後、事前に構築されたものを選択できます。 AWS深層学習コンテナ (DLC)は以下から GitHubレポ。 Docker イメージを選択するときは、フレームワーク (Hugging Face)、タスク (推論)、Python のバージョン、およびハードウェア (GPU など) の設定を考慮してください。次の画像を使用することをお勧めします。 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 このイメージには、ffmpeg などの必要なシステム パッケージがすべてプリインストールされています。 [REGION] を使用している AWS リージョンに忘れずに置き換えてください。
その他の必要な Python パッケージについては、 requirements.txt パッケージとそのバージョンのリストを含むファイル。これらのパッケージは、AWS DLC のビルド時にインストールされます。 SageMaker で WhisperX モデルをホストするために必要な追加パッケージは次のとおりです。
モデルをロードして推論を実行する推論スクリプトを作成する
次に、カスタムを作成します inference.py WhisperX モデルとそのコンポーネントがコンテナにどのようにロードされるか、および推論プロセスがどのように実行されるかを概説するスクリプト。スクリプトには 2 つの関数が含まれています。 model_fn & transform_fnを選択します。 model_fn 関数が呼び出され、それぞれの場所からモデルがロードされます。その後、これらのモデルは transform_fn 推論中に機能し、転記、位置合わせ、およびダイアライゼーションのプロセスが実行されます。以下はコードサンプルです inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
モデルのディレクトリ内で、 requirements.txt ファイル、存在することを確認します inference.py code サブディレクトリ内。の models ディレクトリは次のようになります。
モデルの tarball を作成する
モデルとコードディレクトリを作成した後、次のコマンドラインを使用してモデルを tarball (.tar.gz ファイル) に圧縮し、Amazon S3 にアップロードできます。執筆時点では、より高速な Whisper Large V2 モデルを使用しているため、SageMaker モデルを表す tarball のサイズは 3 GB です。詳細については、以下を参照してください。 Amazon SageMaker でのモデルホスティングパターン、パート 2: SageMaker でリアルタイムモデルのデプロイを開始する.
SageMaker モデルを作成し、非同期プレディクターを備えたエンドポイントをデプロイする
これで、SageMaker モデル、エンドポイント構成、および非同期エンドポイントを作成できるようになりました。 非同期予測子 前のステップで作成したモデル tarball を使用します。手順については、を参照してください。 非同期推論エンドポイントを作成する.
ダイアライゼーションのパフォーマンスを評価する
さまざまなシナリオにおける WhisperX モデルの日記化パフォーマンスを評価するために、30 つの英語のタイトルから 45 つのエピソードをそれぞれ選択しました。XNUMX つは XNUMX 分のエピソードで構成されるドラマ タイトル、もう XNUMX つは XNUMX 分のエピソードで構成されるドキュメンタリー タイトルです。 pyannote のメトリクス ツールキットを利用しました。 pyannote.metricsを計算するには、 ダイアライゼーションエラー率 (DER)。評価では、ZOO から提供された手動で転写および日記化されたトランスクリプトがグランド トゥルースとして機能しました。
DER を次のように定義しました。
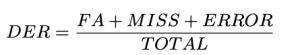
トータル グラウンドトゥルースビデオの長さです。 FA (False Alarm) は、予測では音声とみなされますが、グラウンド トゥルースでは音声としてみなされないセグメントの長さです。 ミス グラウンド トゥルースでは音声とみなされますが、予測では認識されないセグメントの長さです。 エラーとも呼ばれ、 混乱、予測およびグラウンド トゥルースにおいて異なる話者に割り当てられるセグメントの長さです。すべての単位は秒単位で測定されます。 DER の一般的な値は、特定のアプリケーション、データセット、およびダイアライゼーション システムの品質によって異なります。 DER は 1.0 より大きくなる可能性があることに注意してください。 DERは低いほど良いです。
メディアの DER を計算できるようにするには、WhisperX で転写およびダイアライズされた出力だけでなく、グラウンド トゥルースダイアライズも必要です。これらは解析され、メディア内の各音声セグメントの話者ラベル、音声セグメントの開始時刻、および音声セグメントの終了時刻を含むタプルのリストが生成される必要があります。発言者のラベルは、WhisperX とグラウンド トゥルース ダイアライゼーションの間で一致する必要はありません。結果は主にセグメントの時間に基づいています。 pyannote.metrics は、これらのグラウンド トゥルースダイアライゼーションと出力ダイアライゼーションのタプルを受け取ります (pyannote.metrics ドキュメントでは次のように呼ばれます)。 参照 & 仮説) を使用して DER を計算します。次の表に結果をまとめます。
| ビデオタイプ | DER | 正解 | ミス | エラー | 誤報 |
| ドラマ | 0.738 | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が |
| ドキュメンタリー | 1.29 | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が |
| 平均 | 0.901 | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が | 視聴者の38%が |
これらの結果は、ドラマ タイトルとドキュメンタリー タイトルのパフォーマンスに大きな違いがあることを明らかにしており、このモデルでは、ドキュメンタリー タイトルと比較してドラマ エピソードの方が顕著に優れた結果 (集計指標として DER を使用) を達成しています。タイトルを詳しく分析すると、このパフォーマンスのギャップに寄与する潜在的な要因がわかります。重要な要因の 1 つは、ドキュメンタリーのタイトルの音声と重なるバックグラウンド ミュージックが頻繁に存在することである可能性があります。背景ノイズを除去して音声を分離するなど、ダイアライゼーションの精度を高めるためのメディアの前処理は、このプロトタイプの範囲を超えていましたが、WhisperX のパフォーマンスを向上させる可能性のある将来の作業への道が開かれました。
まとめ
この投稿では、SageMaker と WhisperX モデルによる機械学習技術を採用して日記作成ワークフローを強化する、AWS と ZOO Digital 間の協力パートナーシップについて調査しました。 AWS チームは、特に日記作成用に設計されたカスタム ML モデルのプロトタイピング、評価、効果的な展開を理解する際に、ZOO を支援する上で重要な役割を果たしました。これには、SageMaker を使用したスケーラビリティのための自動スケーリングの組み込みが含まれます。
AI をダイアライゼーションに活用すると、ZOO 用のローカライズされたコンテンツを生成する際のコストと時間の両方が大幅に節約されます。このテクノロジーは、文字起こし者が話者を迅速かつ正確に作成して識別できるようにすることで、従来は時間がかかり、間違いが発生しやすいタスクの性質に対処します。従来のプロセスでは、エラーを最小限に抑えるために、ビデオを複数回通過させたり、追加の品質管理ステップを行ったりすることがよくあります。ダイアライゼーションに AI を採用することで、より的を絞った効率的なアプローチが可能になり、より短期間で生産性が向上します。
SageMaker 非同期エンドポイントに WhisperX モデルをデプロイするための主要な手順を概説しました。提供されたコードを使用して自分で試してみることをお勧めします。 ZOO Digital のサービスとテクノロジーについてさらに詳しく知りたい場合は、次のサイトをご覧ください。 ZOO Digital公式サイト。 SageMaker への OpenAI Whisper モデルのデプロイとさまざまな推論オプションの詳細については、以下を参照してください。 Amazon SageMaker で Whisper モデルをホストする: 推論オプションの探索。コメントでお気軽にあなたの考えを共有してください。
著者について
 ホウ・イン博士は、AWS の機械学習プロトタイピング アーキテクトです。彼女の主な関心分野は、GenAI、コンピューター ビジョン、NLP、時系列データ予測を中心とした深層学習です。余暇には、家族と充実した時間を過ごしたり、小説に没頭したり、英国の国立公園でハイキングしたりすることを楽しんでいます。
ホウ・イン博士は、AWS の機械学習プロトタイピング アーキテクトです。彼女の主な関心分野は、GenAI、コンピューター ビジョン、NLP、時系列データ予測を中心とした深層学習です。余暇には、家族と充実した時間を過ごしたり、小説に没頭したり、英国の国立公園でハイキングしたりすることを楽しんでいます。
 イーサン・カンバーランド ZOO Digital の AI 研究エンジニアであり、AI と機械学習を支援テクノロジーとして使用して、音声、言語、ローカリゼーションのワークフローを改善することに取り組んでいます。彼はソフトウェア エンジニアリングと、セキュリティとポリシングの領域での研究のバックグラウンドを持ち、Web から構造化情報を抽出し、収集したデータを分析して強化するためのオープンソース ML モデルの活用に重点を置いています。
イーサン・カンバーランド ZOO Digital の AI 研究エンジニアであり、AI と機械学習を支援テクノロジーとして使用して、音声、言語、ローカリゼーションのワークフローを改善することに取り組んでいます。彼はソフトウェア エンジニアリングと、セキュリティとポリシングの領域での研究のバックグラウンドを持ち、Web から構造化情報を抽出し、収集したデータを分析して強化するためのオープンソース ML モデルの活用に重点を置いています。
 ガウラフ・カイラ 英国とアイルランドの AWS プロトタイピング チームを率いています。彼のチームは、さまざまな業界の顧客と協力して、AWS サービスの導入を加速するという使命を帯びて、ビジネスに不可欠なワークロードを考案し、共同開発しています。
ガウラフ・カイラ 英国とアイルランドの AWS プロトタイピング チームを率いています。彼のチームは、さまざまな業界の顧客と協力して、AWS サービスの導入を加速するという使命を帯びて、ビジネスに不可欠なワークロードを考案し、共同開発しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

