Amazon Kinesis データ分析 は、Apache Flink を使用してストリーミング データをリアルタイムで変換および分析する最も簡単な方法です。 顧客はすでに Kinesis Data Analytics を使用して、IoT センサー、変更データキャプチャ (CDC) イベント、ゲーム、ソーシャルメディアなどのデータソースから生成された動きの速いデータに対してリアルタイム分析を実行しています。 ApacheFlink は、ステートフルな計算のための一般的なオープンソース フレームワークおよび分散処理エンジンです。 制限のないデータ ストリームと境界のあるデータ ストリーム.
Apache Flink アプリケーションの構築は通常、データ エンジニアリング チームの責任ですが、展開の自動化とコード (IaC) としてのインフラストラクチャのプロビジョニングは、通常、プラットフォーム (または DevOps) チームが担当します。
以下は、データ エンジニアリングの役割の一般的な責任です。
- リアルタイム分析 Apache Flink アプリケーションのコードを作成する
- アプリケーションの新しいバージョンをロールアウトするか、ロールバックします (たとえば、重大なバグの場合)。
以下は、プラットフォーム ロールの一般的な責任です。
- IaC のコードを書く
- クラウドで必要なリソースをプロビジョニングし、それらのアクセスを管理します
この投稿では、Kinesis Data Analytics アプリケーションのデプロイとバージョン更新を自動化し、プラットフォーム チームとエンジニアリング チームの両方が効果的にコラボレーションし、最終的なソリューションを共同所有できるようにする方法を示します。 AWS コードパイプライン AWSクラウド開発キット (AWS CDK)。
ソリューションの概要
Kinesis Data Analytics アプリケーションの自動デプロイとバージョン更新を示すために、この記事では次のリアルタイム データ分析アーキテクチャの例を使用します。
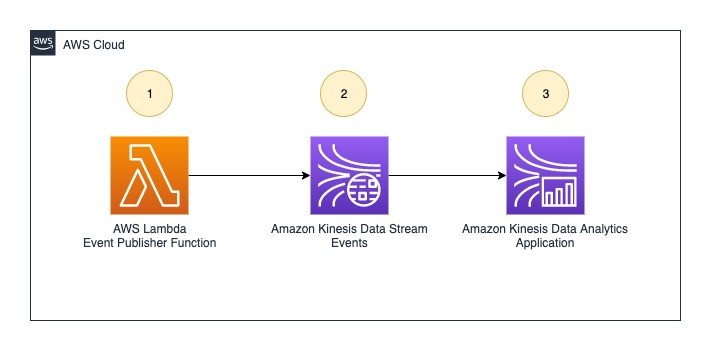
ワークフローには次の手順が含まれます。
- An AWSラムダ 関数 (データ ソースとして機能) は、オンデマンドでイベントをプッシュするイベント プロデューサーです。 Amazon Kinesisデータストリーム 呼び出されたとき。
- Kinesis データストリームは、リアルタイムのイベントを受信して保存します。
- Kinesis Data Analytics アプリケーションは、データ ストリームからイベントを読み取り、リアルタイム分析を実行します。
汎用アーキテクチャ
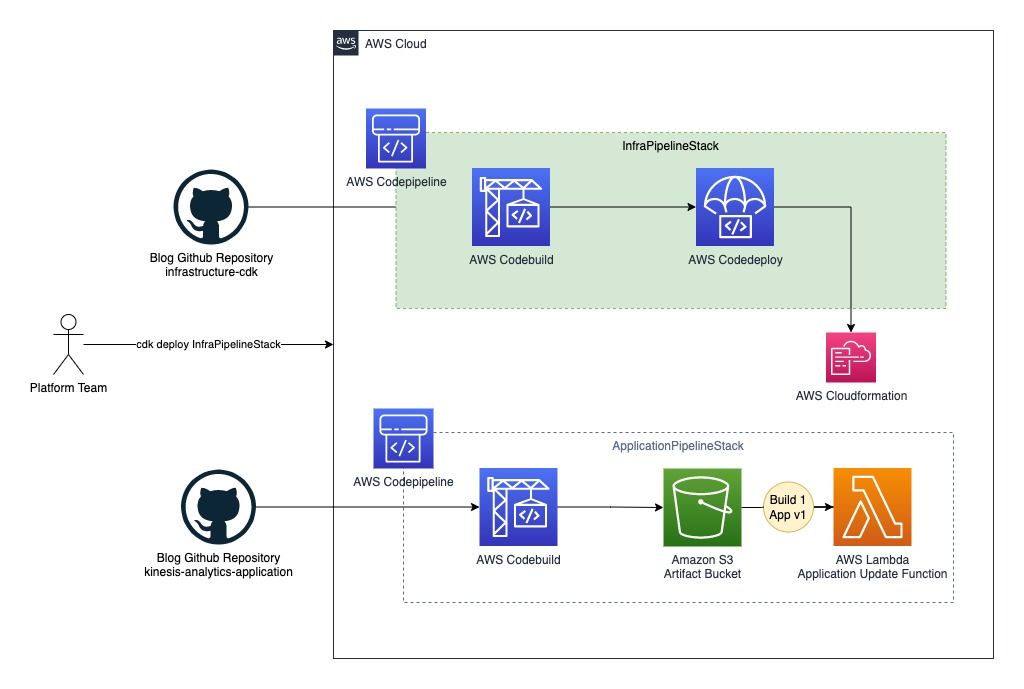
次の汎用アーキテクチャを参照して、この例を好みの CI/CD ツール (Jenkins など) に適合させることができます。 全体的な展開プロセスは、次の XNUMX つの高レベルの部分に分かれています。
- インフラストラクチャ CI/CD – この部分はオレンジ色でハイライトされています。 インフラストラクチャ CI/CD パイプラインは、すべてのリアルタイム ストリーミング アーキテクチャ コンポーネントをデプロイする役割を担います。これには、Kinesis Data Analytics アプリケーションや、通常、 AWS CloudFormation.
- アプリケーションスタック – この部分は灰色で強調表示されます。 アプリケーション スタックは、AWS CloudFormation を使用してインフラストラクチャ CI/CD コンポーネントによってデプロイされます。
- アプリケーション CI/CD – この部分は緑色で強調表示されます。 アプリケーション CI/CD パイプラインは、Kinesis Data Analytics アプリケーションを次の XNUMX つのステップで更新します。
- パイプラインは、Kinesis Data Analytics アプリケーションの Java または Python ソースコードをビルドし、アプリケーションをバイナリファイルとして生成します。
- パイプラインは、最新のバイナリ ファイルを Amazon シンプル ストレージ サービス (Amazon S3) Kinesis Data Analytics アプリケーションバイナリファイルが S3 から参照されるため、ビルドが成功した後のアーティファクトバケット。
- S3 バケットファイル put イベントは Lambda 関数をトリガーし、最新のバイナリをデプロイして Kinesis Data Analytics アプリケーションのバージョンを更新します。
次の図は、このワークフローを示しています。

CodePipeline を使用した CI/CD アーキテクチャ
この投稿では、CodePipeline を使用して汎用アーキテクチャを実装します。 次の図は、更新されたアーキテクチャを示しています。
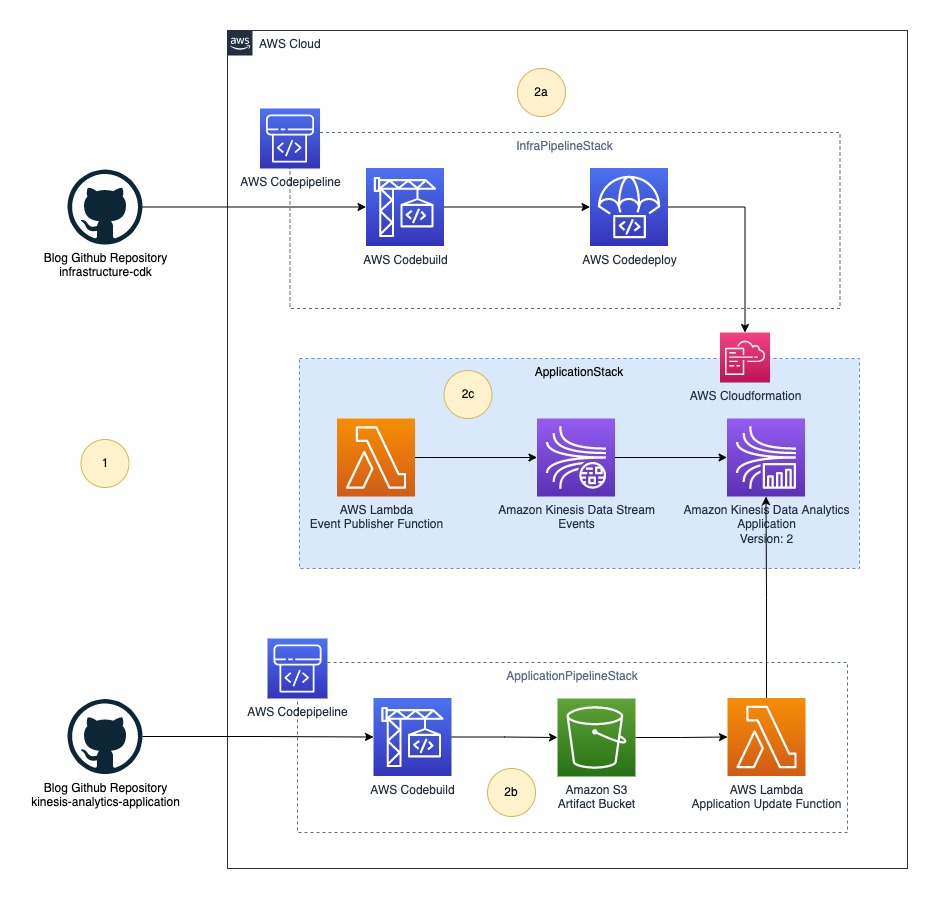
最終的な解決策には、次の手順が含まれます。
- プラットフォーム (DevOps) チームとデータ エンジニアリング チームは、ソース コードをそれぞれのコード リポジトリにプッシュします。
- CodePipeline は、インフラストラクチャ全体を XNUMX つのスタックとしてデプロイします。
- インフラパイプラインスタック – インフラストラクチャ全体を展開するためのパイプラインが含まれています。
- アプリケーションパイプラインスタック – Kinesis Data Analytics アプリケーションバイナリを構築およびデプロイするためのパイプラインが含まれています。 この投稿では、Java ソースを使用してビルドします。 JavaBuildPipeline AWS CDK コンストラクト。 あなたが使用することができます PythonBuildPipeline AWS CDK コンストラクト Python ソースをビルドします。
- アプリケーションスタック – Lambda (データソース)、Kinesis Data Streams (ストレージ)、Kinesis Data Analytics (Apache Flink アプリケーション) などのリアルタイムデータ分析パイプラインリソースが含まれています。
AWS CDK を使用してリソースをデプロイする
以下 GitHubリポジトリ データ パイプラインに必要なすべてのリソースを作成するための AWS CDK コードが含まれています。 これにより、手作業によるエラーの可能性がなくなり、効率が向上し、長期にわたって構成の一貫性が確保されます。 リソースをデプロイするには、次の手順を実行します。
- 次のコマンドを使用して、GitHub リポジトリをローカル コンピューターに複製します。
- ダウンロード 最新の Node.js をインストールします。
- 次のコマンドを実行して、AWS CDK の最新バージョンをインストールします。
- ラン
cdk bootstrapAWS アカウントで AWS CDK 環境を初期化します。 次のコマンドを実行する前に、AWS アカウント ID とリージョンを置き換えてください。
ブートストラップ プロセスの詳細については、次を参照してください。 ブートストラッピング.
パート 1: データ エンジニアリング チームとプラットフォーム チームがソース コードをコード リポジトリにプッシュする
次の図に示すように、データ エンジニアリング チームとプラットフォーム チームは、それぞれのコード リポジトリで作業を開始します。
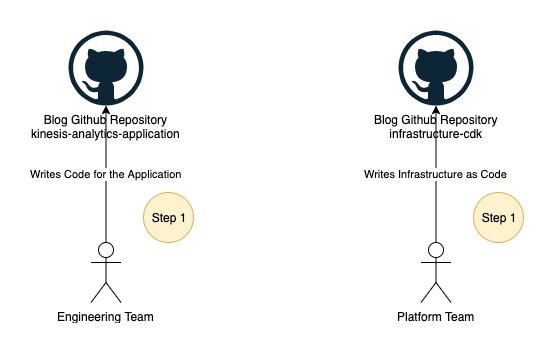
この投稿では、複製されたリポジトリのルート フォルダーの下にある XNUMX つの GitHub リポジトリの代わりに、XNUMX つのフォルダーを使用します。
- キネシス分析アプリケーション – このフォルダには、Kinesis Data Analytics アプリケーションのサンプル ソース コードが含まれています。 これは、データエンジニアリングチームによって開発された Kinesis Data Analytics アプリケーションのソースコードを表しています。
- インフラストラクチャ-cdk – このフォルダには、必要なすべてのリソースと CodePipeline をプロビジョニングするために使用される最終的なソリューションのサンプル AWS CDK ソース コードが含まれています。 このコードを Kinesis Data Analytics アプリケーションのデプロイに再利用できます。
アプリケーション開発チームは通常、アプリケーションのソース コードを git リポジトリに保存します。 デモンストレーションの目的で、CodePipeline を Github リポジトリに接続する代わりに、Github からダウンロードした zip ファイルとしてソース コードを使用します。 ソース リポジトリを CodePipeline に直接接続することもできます。 接続方法の詳細については、を参照してください。 GitHub への接続を作成する.
パート 2: プラットフォーム チームがアプリケーション パイプラインをデプロイする
次の図は、ワークフローの次のステップを示しています。

このステップでは、Java ソース コードをビルドするための最初のパイプラインをデプロイします。 kinesis-analytics-application. 次の手順を実行してデプロイします ApplicationPipelineStack:
- OS に応じて、ターミナル、bash、またはコマンド ウィンドウを開きます。
- 現在のパスをフォルダーに切り替える
infrastructure-cdk. - ラン
npm installすべての依存関係をダウンロードします。 - ラン
cdk deploy ApplicationPipelineStackアプリケーション パイプラインをデプロイします。
このプロセスには約時間がかかります 5 minutes 前の図で緑色で強調表示されている次のリソースを完成させ、AWS アカウントにデプロイします。
- のステージを含む CodePipeline AWS コードビルド および AWS コードデプロイ
- バイナリを保存する S3 バケット
- 手動承認後に Kinesis Data Analytics アプリケーション JAR を更新する Lambda 関数
アプリケーション パイプラインの自動ビルドをトリガーする
後に cdk deploy コマンドが成功したら、次の手順を完了して、パイプラインを自動的に実行します。
- ダウンロード ソース コード .zip ファイル.
- AWS CloudFormationコンソールで、 スタック ナビゲーションペインに表示されます。
- スタックを選択します
ApplicationPipelineStack.
- ソフトウェア設定ページで、下図のように 出力 タブで、キーのリンクを選択します
ArtifactBucketLink.![[出力] タブで、キー ArtifactBucketLink のリンクを選択します。](https://zephyrnet.com/wp-content/uploads/2023/01/automate-deployment-and-version-updates-for-amazon-kinesis-data-analytics-applications-with-aws-codepipeline-6.jpg)
S3 アーティファクト バケットにリダイレクトされます。
- 選択する アップロード.
- ダウンロードしたソース コードの .zip ファイルをアップロードします。
最初のパイプラインの実行 (次の図では Auto Build として示されています) は自動的に開始され、約 5 minutes 手動承認段階に到達します。 パイプラインはアーティファクト バケットからソース コードを自動的にダウンロードし、Java プロジェクトをビルドします。 kinesis-analytics-application Maven を使用して、出力バイナリ JAR ファイルをディレクトリの下のアーティファクト バケットにパブリッシュします。 jars.

アプリケーション パイプラインの実行を表示する
アプリケーション パイプラインの実行を表示するには、次の手順を実行します。
- AWS CloudFormation コンソールで、スタックに移動します
ApplicationPipelineStack. - ソフトウェア設定ページで、下図のように 出力 タブで、キーのリンクを選択します
ApplicationCodePipelineLink.![[出力] タブで、キー ApplicationCodePipelineLink のリンクを選択します。](https://zephyrnet.com/wp-content/uploads/2023/01/automate-deployment-and-version-updates-for-amazon-kinesis-data-analytics-applications-with-aws-codepipeline-8.jpg)
パイプラインの詳細ページにリダイレクトされます。 各ステージの各アクションの状態や遷移の状態など、パイプラインの詳細ビューを確認できます。
手動承認段階のビルドはまだ承認しないでください。 これは後で行います。
パート 3: プラットフォーム チームがインフラストラクチャ パイプラインをデプロイする
アプリケーション パイプラインの実行により、次の名前の JAR ファイルが発行されます。 kinesis-analytics-application-final.jar アーティファクト バケットに。 次に、Kinesis Data Analytics アーキテクチャをデプロイします。 サンプル フローをデプロイするには、次の手順を実行します。
- OS に応じて、ターミナル、bash、またはコマンド ウィンドウを開きます。
- 現在のパスをフォルダーに切り替える
infrastructure-cdk. - ラン
cdk deploy InfraPipelineStackインフラストラクチャ パイプラインをデプロイします。
このプロセスには約時間がかかります 5 minutes 次の図で緑色で強調表示されているように、CodeBuild と CodeDeploy のステージを含むパイプラインを完成させ、AWS アカウントにデプロイします。
時 cdk deploy が完了すると、インフラストラクチャ パイプラインの実行が自動的に開始され (次の図では Auto Build 1 として示されています)、約 10 minutes アーティファクト バケットからソース コードをダウンロードするには、AWS CDK プロジェクトをビルドします。 infrastructure-stack、およびデプロイ ApplicationStack AWS アカウントに自動的に送信されます。 インフラストラクチャ パイプラインの実行が完了すると、次のリソースがアカウントにデプロイされます (次の図では緑色で示されています)。
- という名前の CloudFormation テンプレート
app-ApplicationStack - データ ソースとして機能する Lambda 関数
- ストリーム ストレージとして機能する Kinesis データ ストリーム
- 最初のバージョンの Kinesis Data Analytics アプリケーション
kinesis-analytics-application-final.jar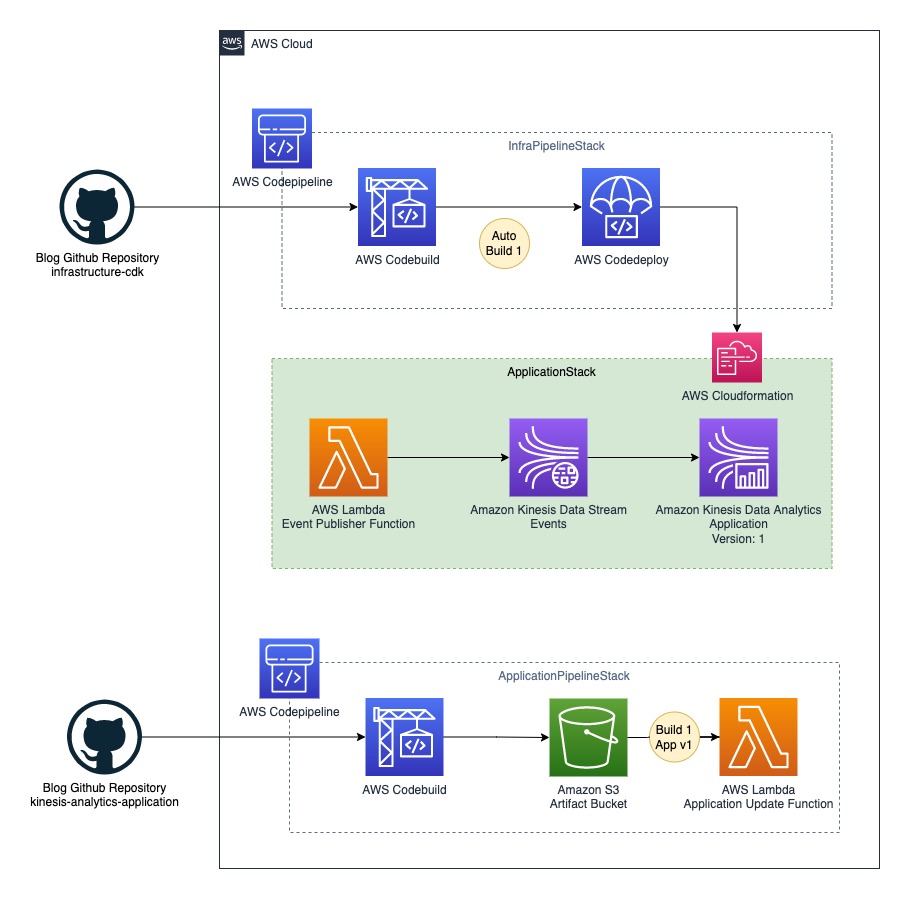
インフラストラクチャ パイプラインの実行を表示する
アプリケーション パイプラインの実行を表示するには、次の手順を実行します。
- AWS CloudFormation コンソールで、スタックに移動します
InfraPipelineStack.
- ソフトウェア設定ページで、下図のように 出力 タブで、キーのリンクを選択します
InfraCodePipelineLink.![[出力] タブで、キー InfraCodePipelineLink のリンクを選択します。](https://zephyrnet.com/wp-content/uploads/2023/01/automate-deployment-and-version-updates-for-amazon-kinesis-data-analytics-applications-with-aws-codepipeline-12.jpg)
パイプラインの詳細ページにリダイレクトされます。 各ステージの各アクションの状態や遷移の状態など、パイプラインの詳細ビューを確認できます。
ステップ 4: データ エンジニアリング チームがアプリケーションをデプロイする
これで、データ エンジニアリング チームが独立して作業し、Kinesis Data Analytics アプリケーションの新しいバージョンをロールアウトするためのすべてがアカウントに配置されました。 アプリケーション パイプラインからそれぞれのアプリケーション ビルドを承認して、新しいバージョンのアプリケーションをデプロイできます。 次の図は、完全なワークフローを示しています。

ソース コードの変更が検出されると、ビルド プロセスが自動的に開始されます。 ソースコードの .zip ファイルを S3 アーティファクトバケットに再アップロードすることで、バージョンの更新をテストできます。 実際のユースケースでは、プル リクエストまたは変更のマージによってメイン ブランチを更新すると、このアクションによって新しいパイプラインの実行が自動的にトリガーされます。
現在のアプリケーション バージョンを表示する
Kinesis Data Analytics アプリケーションの現在のバージョンを表示するには、次の手順を実行します。
- AWS CloudFormation コンソールで、スタックに移動します
InfraPipelineStack. - ソフトウェア設定ページで、下図のように 出力 タブで、キーのリンクを選択します
KDAApplicationLink.![[出力] タブで、キー KDAApplicationLink のリンクを選択します。](https://zephyrnet.com/wp-content/uploads/2023/01/automate-deployment-and-version-updates-for-amazon-kinesis-data-analytics-applications-with-aws-codepipeline-14.jpg)
Kinesis Data Analytics アプリケーションの詳細ページにリダイレクトされます。 アプリケーションの現在のバージョンは、以下を参照して確認できます。 バージョン ID.

アプリケーションの展開を承認する
Kinesis Data Analytics アプリケーションのデプロイ (またはバージョンの更新) を承認するには、次の手順を実行します。
- AWS CloudFormation コンソールで、スタックに移動します
ApplicationPipelineStack. - ソフトウェア設定ページで、下図のように 出力 タブで、キーのリンクを選択します
ApplicationCodePipelineLink. - 選択する レビュー パイプラインの承認段階から。
![パイプライン承認ステージから [レビュー] を選択します](https://zephyrnet.com/wp-content/uploads/2023/01/automate-deployment-and-version-updates-for-amazon-kinesis-data-analytics-applications-with-aws-codepipeline-16.jpg)
- プロンプトが表示されたら、を選択します。 承認 Kinesis Data Analytics アプリケーションのデプロイまたはバージョン更新の承認を提供する (オプションでコメントを追加する)。
![[承認] を選択して承認を提供します](https://zephyrnet.com/wp-content/uploads/2023/01/automate-deployment-and-version-updates-for-amazon-kinesis-data-analytics-applications-with-aws-codepipeline-17.jpg)
- 前述の手順を繰り返して、現在のアプリケーション バージョンを表示します。
で定義されているアプリケーションのバージョンが表示されます。 バージョン ID 次のスクリーンショットに示すように、XNUMX ずつ増加します。

Kinesis Data Analytics アプリケーションの新しいバージョンをデプロイすると、ダウンタイムが約 5 minutes バージョンの更新を担当する Lambda 関数が API 呼び出しを行うため アプリケーションの更新、バージョンの更新後にアプリケーションを再起動します。 ただし、アプリケーションは、再起動後に中断したところからストリーム処理を再開します。
クリーンアップ
リソースを削除してコストの発生を防ぐには、次の手順を実行します。
- AWS CloudFormation コンソールで、スタックを選択します
InfraPipelineStack選択して 削除. - スタックを選択します
app-ApplicationStack選択して 削除. - スタックを選択
ApplicationPipelineStack選択して 削除. - Amazon S3 コンソールで、名前が で始まるバケットを選択します。
javaappCodePipeline選択して 空の. - 完全に削除と入力して、選択を確認します。
- バケットをもう一度選択して、 削除.
- プロンプトが表示されたらバケット名を入力して、アクションを確認します。
- これらの手順を繰り返して、名前が で始まるバケットを削除します
infrapipelinestack-pipelineartifactsbucket.
まとめ
この投稿では、CodePipeline と AWS CDK を使用して、Kinesis Data Analytics アプリケーションのデプロイとバージョン更新を自動化する方法を示しました。
詳細については、を参照してください。 CDK パイプラインを使用した継続的な統合と配信 (CI/CD) および CodePipeline チュートリアル.
著者について
 アナンドシャー AWS のビッグデータ プロトタイピング ソリューション アーキテクトです。 彼は AWS の顧客とそのエンジニアリングチームと協力して、AWS 分析サービスと専用データベースを使用してプロトタイプを構築しています。 Anand は、可能な技術の芸術を使用して、顧客が最も困難な問題を解決するのを支援します。 彼は余暇にビーチを楽しんでいます。
アナンドシャー AWS のビッグデータ プロトタイピング ソリューション アーキテクトです。 彼は AWS の顧客とそのエンジニアリングチームと協力して、AWS 分析サービスと専用データベースを使用してプロトタイプを構築しています。 Anand は、可能な技術の芸術を使用して、顧客が最も困難な問題を解決するのを支援します。 彼は余暇にビーチを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/automate-deployment-and-version-updates-for-amazon-kinesis-data-analytics-applications-with-aws-codepipeline/

