病院は患者ケアと医療管理の中心地として、多くの場合、膨大な書類や文書を管理します。従来の手動データ入力への依存は貴重な時間を浪費し、重大な結果をもたらす可能性のあるエラーのリスクをもたらします。
光学式文字認識 (OCR) ソフトウェアは、病院における文書作成プロセスの処理方法を再構築する驚異的な技術です。 OCR ソフトウェアは、医療機関が直面する最も差し迫った課題のいくつかに対するソリューションを提供する、革新的なソフトウェアとして登場しました。
これらの課題とは何でしょうか?
- 大量の書類: 病院では、患者記録や処方箋から請求書類や保険フォームに至るまで、毎日大量の事務処理が行われています。この紙の洪水は物流上の悪夢をもたらし、重要な情報の迅速かつ正確な検索を妨げます。
- データの正確性の確保: 医療においては正確さが最も重要であり、患者情報や医療記録に誤りがあると重大な結果を招く可能性があります。手動によるデータ入力は人的ミスが発生しやすく、誤解や転記ミスを引き起こし、患者の安全を危険にさらします。
- コンプライアンスとセキュリティの問題への対処: 医療業界は、医療保険の相互運用性と責任に関する法律 (HIPAA) を患者データのプライバシーとセキュリティを保護するための基礎として、厳格な規制枠組みの下で運営されています。 HIPAA の遵守は医療機関にとって交渉の余地のないものであり、遵守を怠ると重大な結果を招く可能性があります。
時間が死活問題となり得るこの分野では、合理化された文書管理の必要性がこれまで以上に緊急になっています。
10 年の病院向け OCR ソフトウェアのトップ 2024 は次のとおりです。
Nanonet の AI ベースの OCR ソフトウェアを使用して手動データ入力を自動化します。ドキュメントからデータを瞬時に取得し、データ ワークフローを自動化します。所要時間を短縮し、手作業を排除します。
病院向けOCRとは何ですか?
OCR ソフトウェア (光学式文字認識ソフトウェア) は、さまざまな種類の文書を機械可読テキストに変換します。病院では、患者のケア、管理、医療プロセスに関連する膨大な書類や文書をデジタル化して管理する上で、OCR ソフトウェアが非常に重要です。
病院向け OCR ソフトウェアの主な特徴と機能は次のとおりです。
- 文書の電子化
OCR ソフトウェアを使用すると、病院は患者記録、医療カルテ、処方箋、請求情報などの物理的な文書をデジタル形式に変換できます。このデジタル化プロセスにより、重要な医療情報の保管、検索、共有が容易になります。 - テキスト抽出
OCR の主な機能の 1 つは、スキャンした文書または画像からテキストを抽出することです。医療現場では、これは手書きのメモ、印刷された文書、またはフォームから重要な詳細を取得するのに特に役立ち、より効率的なデータ管理に貢献します。 - データ精度
OCR ソフトウェアは、手動データ入力に伴うエラーを最小限に抑えます。文書からのテキスト抽出を自動化すると、転記ミスのリスクが軽減され、患者情報が正確に記録および維持されます。 - ワークフローの効率化
病院環境では、管理プロセスの合理化が不可欠です。 OCR ソフトウェアは文書処理を自動化することでワークフローの効率を高め、医療専門家が事務処理ではなく患者のケアに集中できるようにします。 - 検索と取得
デジタル化された文書は検索可能になり、情報を迅速かつ簡単に検索できるようになります。医療スタッフは特定の患者記録や関連する医療情報を効率的に見つけることができ、より迅速な意思決定と患者ケアの向上に貢献します。 - コンプライアンスとセキュリティ
OCR ソフトウェアは、病院が HIPAA などの医療プライバシー法で概説されている規制基準を含む規制基準を遵守するのに役立ちます。暗号化、アクセス制御、保護された医療情報 (PHI) の編集などの機能により、機密の患者情報を安全に処理します。 - 電子医療記録 (EHR) システムとの統合
多くの OCR ソリューションは、電子医療記録 (EHR) システムとシームレスに統合するように設計されています。この統合により、デジタル化された情報を病院のインフラストラクチャにスムーズに転送できるようになり、医療データ管理への一貫した一元的なアプローチが促進されます。 - 言語サポート
病院では多言語の文書を扱うことがよくあります。堅牢な言語サポートを備えた OCR ソフトウェアは、さまざまな言語で書かれた文書からテキストを正確に処理して抽出し、医療文書の包括性を確保します。
2024 年の病院向け最高の OCR ソフトウェア
病院向けに利用可能な最高の OCR をいくつか見てみましょう。
1. ナノネット
Nanonets は、病院向けの優れた OCR ソフトウェア ソリューションとして際立っており、医療文書で直面する特有の課題に対処するためのカスタマイズされたアプローチを提供します。
その高度な機械学習アルゴリズムは、手書きのメモや複雑なフォームを含むさまざまな医療文書からテキストを正確に抽出することに優れています。 Nanonets の卓越したデータ精度により、患者記録の正確な転記が保証され、エラーのリスクが最小限に抑えられ、医療従事者が最適なケアを提供できるようにサポートされます。
Nanonets の主な強みの 1 つは、電子医療記録 (EHR) システムとのシームレスな統合であり、紙からデジタル ワークフローへの移行を簡単に合理化します。暗号化や PII 編集などのソフトウェアの堅牢なセキュリティ機能は、HIPAA などの医療規制の厳格なコンプライアンス要件に準拠しています。
Nanonets は、効率とデータの正確性を高めることで病院の文書管理に革命を起こすだけでなく、医療機関が規制基準を満たし、患者の機密保持を優先できるようにします。
ナノネットの紹介
長所:
- 近代的なUI
- 大量のドキュメントを処理します
- 合理的な価格
- 使いやすさ
- ゼロショットまたはゼロトレーニングデータ抽出
- データの認知的キャプチャ –最小限の介入で
- 開発者の社内チームは必要ありません
- アルゴリズム/モデルはトレーニング/再トレーニング可能
- 優れたドキュメントとサポート
- 多くのカスタマイズオプション
- 統合オプションの幅広い選択肢
- 正確な多言語 OCR
- 複数の会計ソフトウェアとのシームレスな双方向統合
- 開発者向けの優れたOCRAPI
短所:
- テーブルキャプチャUIが改善される可能性があります
Nanonetsの事前トレーニング済みOCRエクストラクタまたは あなた自身のものをつくる カスタムOCRモデル。 あなたもすることができます デモを予約する OCRの詳細については ユースケース!

2. ABBYY フレキシカプチャー
ABBYY FlexiCapture は、さまざまな医療文書からデータをキャプチャしてデジタル化することに優れた OCR ソリューションです。 FlexiCapture は、高度な機械学習アルゴリズムを備えているため、高精度でテキストを抽出できるため、患者記録、処方箋、その他の医療関連の書類の転記に最適です。
請求書用のABBYYFlexiCapture–デモビデオ
長所:
- 画像を非常によく認識します
- ハードコピーの結果をシステムに簡単に保存できます
- ERPシステムとうまく統合
- ドキュメントからのデータ抽出を(ある程度まで)自動化します
短所:
- 初期設定は困難で複雑になる可能性があります
- 医療文書の自動処理が設定されていません
- 既製のテンプレートはありません
- カスタマイズが難しい
- 利用可能なリソースがありません
- RPAソリューションとの統合が改善される可能性があります
- 低解像度の画像/ドキュメントでの低精度
- 特定のセクションでエラーが発生した場合でも、バッチ検証は保留されます
- スキップする必要があるアイテムについても、広告申込情報のエラーメッセージがポップアップ表示されます
- オンプレミスバージョンではRESTfulAPIは使用できません
3. ABBYY ファインリーダー
FineReader は主に個人ユーザーおよび中小企業向けに設計されており、スキャンされた文書、画像、PDF を編集可能および検索可能な形式に変換する強力な OCR 機能を提供します。印刷文書のデジタル化、書籍からのテキストの抽出、または紙ベースのコンテンツの電子形式への変換に最適です。 FineReader は多用途でユーザーフレンドリーですが、医療現場で一般的な複雑で大規模な文書処理に不可欠な高度な自動化機能やデータキャプチャ機能が欠けている場合があります。
ABBYY FineReader を使用すると、印刷された医療文書をデジタル形式に変換したり、医学教科書からテキストを抽出したりできます。
ABBYY FineReaderサーバーを使用したドキュメントの処理–デモビデオ
長所:
- 手動修正用のキーボード対応のOCRエディター
- 非常にクリアなインターフェース
- 複数の形式へのエクスポート
- 独自のドキュメント比較機能
短所:
- 高速検索のための全文索引付けが不足している
- 学習曲線が必要
- 価格設定は法外なものになる可能性があります
- ドキュメントの変更履歴を表示できない
- 複数のファイルをXNUMXつにマージすることはできません
- 後処理が必要な場合があります
- UIは最初は圧倒される可能性があります
- 大きなファイルの処理が遅い
画像からテキストへの抽出または PDF データ抽出のための OCR ソフトウェアが必要ですか?ナノネットの動作をチェックしてください!
Omnipage は、大量の医療文書処理タスクの自動化を処理できる強力な PDF OCR ソフトウェアです。このソフトウェアには、スキャンされた文書からテキストとデータを正確に抽出するための高度な OCR 機能が装備されています。医療において、この機能は、医療記録や処方箋などのさまざまなソースから関連情報を取得するために非常に重要です。
利点:
- 高精度のテキスト抽出と、処方箋や検査レポートなどの医療文書からのデータにより、下流のデータ フロー エラーを最小限に抑えます。
- OCR の前にスキャンまたは写真撮影された医療文書の品質を向上させるための幅広い組み込みフィルターとツールを提供します。
制限事項:
- AP 自動化ワークフローまたは API 統合のセットアップには、技術者以外のユーザーには適さない複雑なセットアップが必要です。
- このインターフェイスは学習曲線が急峻で、より直観的であるため、病院での採用が妨げられる可能性があります。
- UI は直感的ではないため、忙しい医療従事者には適していない可能性があります。
5. IBM データキャップ
IBM Datacap は、堅牢な文書キャプチャおよび処理ソフトウェアです。 Datacap は、医療文書の取得、認識、分類を合理化することで、医療機関が患者記録、処方箋、その他の文書をデジタル化するのに役立ちます。 AI を活用したインテリジェントな処理や機械学習などの高度な機能を備えた Datacap は、複雑な文書の処理を自動化し、精度を高め、手動データ入力の負担を軽減します。
Datacap と IBM Cloud Pak for Business Automation の統合により、医療文書管理のための包括的なソリューションが提供されます。マルチチャンネル入力、さまざまなアプリケーションへのエクスポート、および適応性の高いルールベースのキャプチャ ワークフローをサポートします。
長所:
- データキャプチャで複雑なアプリケーションを構成します
- スキャンメカニズム
- 使いやすさ
短所:
- オンラインサポートはほとんどありません
- UIはより直感的になる可能性があります
- セットアップが面倒な場合があります
- 遅く
- カスタマイズされたフローの作成は簡単ではありません
- バッチコミットには時間がかかります
使い始める 自動化のためのナノネット。 さまざまなOCRモデルを試してみるか デモをリクエストする 。 詳細 Nanonetsのユースケースを製品にどのように適用できるか。
6. GoogleドキュメントAI
Google Document AI は、機械学習を利用して非構造化ドキュメントから貴重な情報を抽出する強力なドキュメント処理ツールです。 Document AI は、医療記録、処方箋、請求書からの重要なデータの抽出を自動化することで、医療分野の管理タスクを効率化できます。自然言語処理とインテリジェントなデータ抽出における高度な機能は、ドキュメント処理の精度と効率の向上に貢献します。
長所:
- セットアップが簡単
- 他のGoogleサービスと非常によく統合します
- 情報の保存
- 速度
短所:
- AIモジュールには適切なドキュメントがありません
- 既存のモジュールとライブラリのカスタマイズは難しい
- Pythonやその他のコーディング言語には適していません
- 古いAPIドキュメント
- 高価な
- ハイブリッドクラウドの展開には適していません
- カスタムAIアルゴリズムを必要とするユースケースには適していません
AWS テキストラクト は、アマゾン ウェブ サービスによる光学式文字認識 (OCR) エンジンです。スキャンした画像や文書を機械可読テキストに変換でき、医療を含むさまざまな業界に応用できます。
Tesseract のさまざまな種類の文書や言語のテキストを認識する多機能性により、医療システムの相互運用性が強化されます。 AWS Tesseract は、紙ベースのドキュメントのデジタル形式への変換を自動化することで、医療機関における効率の向上、データの精度の向上、および全体的な患者ケアの向上に貢献します。
長所:
- 従量課金制
- 使いやすさ
- テーブルやフォームに適しています
短所:
- 訓練できません
- さまざまな精度
- 手書き文書用ではありません
PDF ドキュメントからデータをスクレイピングしたり、PDF テーブルを Excel に変換したり、テーブル抽出を自動化したりしたいですか? Nanonets PDF スクレーパーをチェックするか、 PDFパーサー PDF データをスクレイピングしたり、大規模に PDF を解析したりできます。
8. ドパーサー
Docparser は、請求書、フォーム、領収書などの非構造化ドキュメントを構造化データに変換するドキュメント解析およびデータ抽出プラットフォームです。 Docparser は、医療記録、保険フォーム、その他の医療関連文書から重要な情報を自動的に抽出することで、医療分野の文書処理を合理化できます。高度な解析機能により、特定のデータ フィールドの抽出が可能になり、患者情報の正確かつ効率的なデジタル化が促進されます。
長所:
- 簡単なセットアップ
- ザピアの統合
短所:
- Webhookが失敗することがあります
- 解析ルールを理解するには、ある程度のトレーニングが必要です
- テンプレートが足りない
- ゾーンOCR アプローチ–不明なテンプレートを処理できません
- UIはもっと良いかもしれません
- ページの読み込みが遅い
- ドキュメントはもっと良いかもしれません
9.アドビ アクロバットDC
Adobe Acrobat は、PDF (Portable Document Format) ファイルの作成、編集、変換、管理のために Adobe Inc. が開発した包括的なソフトウェアおよびサービス ファミリです。光学式文字認識は、スキャンした紙の文書または画像を編集および検索可能なテキストに変換する Adobe Acrobat 内の機能です。
Adobe Acrobat OCR を使用すると、ユーザーはスキャンした文書からテキストを認識して抽出でき、PDF ファイル内のコンテンツを編集、検索、操作できるようになります。この機能は、元のドキュメントが編集不可能な画像形式でのみ存在するシナリオで特に役立ち、テキストベースの情報を操作する際の柔軟性とアクセシビリティが向上します。
長所:
- 安定性/互換性
- 使いやすさ
短所:
- 高価な
- 排他的なOCRソフトウェアではありません
- システムに重い
- ハードディスク上で多くのスペースを占有します
- SharepointやDropboxなどのサービスとの統合が難しい
- Adobe Creative Cloud ライセンスが必要です
10. クリッパ
Klippa は、高度な OCR (光学式文字認識) および機械学習テクノロジーを使用して、非構造化文書から関連情報を正確に識別、分類、抽出し、手動によるデータ入力とエラーのリスクを軽減します。
医療における Klippa のアプリケーションは、効率の向上、データ管理の精度の向上、規制基準への準拠の強化につながる可能性があります。
長所:
- 迅速なセットアップ
- 素晴らしいサポート
- 開発者向けの優れたAPI
- 明確で簡潔なAPIドキュメント
- 会計プログラムとうまくリンクします
- 競争力のある価格
- インテグレーション
短所:
- OCR認識が向上する可能性があります
- 限られたテンプレートのカスタマイズ
- 限定的なホワイトラベルのカスタマイズ
- 一括調整はサポートされていません
- VATが正しく表示されないことがよくあります
- アプリがよく落ちる
- OCRモデルをトレーニングできません
- 選択肢が多いため、選択プロセスは簡単ではありません
ナノネット OCR API 多くの興味深いものがあります ユースケース ビジネスパフォーマンスを最適化し、コストを節約し、, そして成長を促進します。 詳細 Nanonetsのユースケースを製品にどのように適用できるか。
その他の注目すべき言及は次のとおりです。 ベリーフィ, リードアイリス, 侵害する, ロッサム & ハイパトス。主要な作品もチェックしてください ナノネットの代替品.
これは、いくつかの重要なOCRソフトウェアの機能とパラメーター全体で上記のすべてのOCRソフトウェアを簡単に比較したものです。
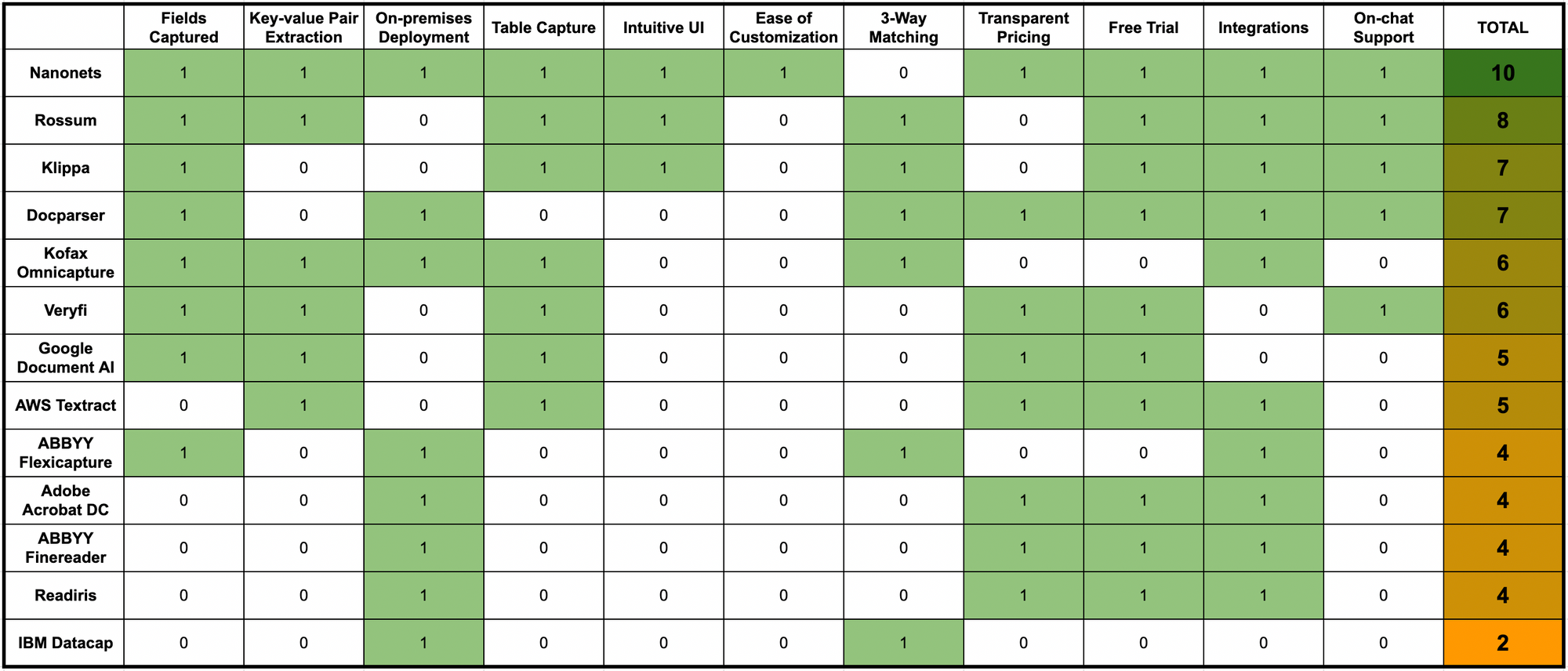
Nanonets が病院向けの最も包括的な OCR ソフトウェアであるのはなぜですか?
NanonetsOCRソフトウェアは セットアップが簡単で柔軟所要時間はわずか 1 日程度です。の インテリジェント自動化プラットフォーム ハンドル 非構造化データ それほど難しいことはなく、AI も処理します。 一般的なデータの制約 簡単に。
病院における Nanonets OCR のメリットは、精度、経験、拡張性の向上だけではありません。
- データのキャプチャと入力—Nanonets OCR を使用すると、処方箋、請求書、従来の医療データなどから数秒以内にデータを正確にキャプチャできます。抽出されたデータは病院管理ソフトウェアに直接接続できるため、手動でのデータ入力の必要性が減り、精度が向上します。
- 文書化と保管— Nanonets OCR は、すべての医療文書の編集可能なデジタル コピーを簡単に作成できます。これらの文書は、必要に応じていつでも簡単に保存および取得できます。
- 品質管理-Nanonets OCR は、ドキュメントがシステムに取り込まれる前、または承認のために送信される前に、複数の承認ステップを提供できます。これにより、エラーを早期に特定し、再作業に必要なリソースとコストを削減できます。
- ユーザーフレンドリーなインターフェース: Nanonets は直観的でユーザーフレンドリーなインターフェイスを備えており、広範な技術トレーニングを受けていなくても医療従事者がアクセスできます。
病院向けの無料の OCR ソフトウェアはありますか?
オープンソース OCR エンジン (Tesseract など) で実行されるこれらの無料ソリューションは、写真の変換に役立ちます。 PDFファイル、TIFF、またはスキャンしたドキュメントを編集可能なデジタル テキスト形式に変換します。複雑な医療記録を大規模に処理することはできないかもしれませんが、単純な書式設定の単純な文書からテキストを抽出するのには十分です。
無料の OCR ソフトウェアは、手書きの文書、複数列の表、長い行の項目、または低品質の画像/スキャンの処理に失敗することがよくあります。
以下に、無料の光学式文字認識ツールをいくつか紹介しますので、ぜひご検討ください。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/ocr-for-hospitals/

