大規模言語モデル (LLM) は通常、ドメインに依存しない大規模な公的に利用可能なデータセットでトレーニングされます。例えば、 メタのラマ モデルは次のようなデータセットでトレーニングされます。 コモンクロール, C4、ウィキペディア、および arXivの。これらのデータセットには、幅広いトピックとドメインが含まれています。結果として得られるモデルは、テキスト生成やエンティティ認識などの一般的なタスクに対して驚くほど良好な結果をもたらしますが、ドメイン固有のデータセットでトレーニングされたモデルは LLM のパフォーマンスをさらに向上できるという証拠があります。たとえば、次の目的で使用されるトレーニング データは、 ブルームバーグGPT 金融ニュース、提出書類、その他の財務資料を含むドメイン固有の文書が 51% を占めます。結果として得られる LLM は、財務固有のタスクでテストした場合、ドメイン固有ではないデータセットでトレーニングされた LLM よりも優れたパフォーマンスを発揮します。の著者 ブルームバーグGPT 彼らのモデルは、60 つの財務タスクのうち 100 つについてテストされた他のすべてのモデルよりも優れていると結論付けました。このモデルは、ブルームバーグの社内財務タスクに対してテストした場合、さらに優れたパフォーマンスを示し、(XNUMX 点中) XNUMX ポイントも優れていました。総合評価結果について詳しくは、 紙からキャプチャした次のサンプル。 ブルームバーグGPT この論文では、金融ドメイン固有のデータを使用して LLM をトレーニングする利点を垣間見ることができます。例に示すように、BloombergGPT モデルは正しい答えを提供しましたが、ドメイン固有ではない他のモデルは苦戦しました。
この投稿では、特に金融ドメイン向けに LLM をトレーニングするためのガイドを提供します。次の主要な領域をカバーします。
- データの収集と準備 – 効果的なモデルトレーニングのための関連財務データの調達と収集に関するガイダンス
- 継続的な事前トレーニングと微調整 – LLM のパフォーマンスを最適化するために各手法をいつ使用するか
- 効率的な継続的な事前トレーニング – 継続的な事前トレーニングプロセスを合理化し、時間とリソースを節約する戦略
この投稿では、Amazon Finance Technology 内の応用科学研究チームと、グローバル金融業界の AWS ワールドワイド スペシャリスト チームの専門知識を結集します。内容の一部は論文に基づいています ドメイン固有の大規模言語モデルを構築するための効率的な継続的事前トレーニング.
財務データの収集と準備
ドメインの継続的な事前トレーニングには、大規模で高品質のドメイン固有のデータセットが必要です。ドメイン データセットのキュレーションの主な手順は次のとおりです。
- データ ソースの特定 – ドメイン コーパスの潜在的なデータ ソースには、オープン ウェブ、ウィキペディア、書籍、ソーシャル メディア、内部文書などがあります。
- ドメインデータフィルター – 最終的な目標はドメイン コーパスを厳選することであるため、ターゲット ドメインに無関係なサンプルを除外するために追加の手順を適用する必要がある場合があります。これにより、継続的な事前トレーニングに無駄なコーパスが削減され、トレーニング コストが削減されます。
- 前処理 – データ品質とトレーニング効率を向上させるために、一連の前処理ステップを検討することもできます。たとえば、特定のデータ ソースには、かなりの数のノイズの多いトークンが含まれる可能性があります。重複排除は、データ品質を向上させ、トレーニング コストを削減するための有用なステップであると考えられています。
財務 LLM を開発するには、News CommonCrawl と SEC ファイリングという 2016 つの重要なデータ ソースを使用できます。 SEC 提出書類は、米国証券取引委員会 (SEC) に提出される財務諸表またはその他の正式な文書です。上場企業は定期的にさまざまな書類を提出する必要があります。これにより、長年にわたって大量のドキュメントが作成されます。 News CommonCrawl は、XNUMX 年に CommonCrawl によってリリースされたデータセットです。世界中のニュース サイトからのニュース記事が含まれています。
ニュース CommonCrawl は次のサイトで利用できます。 Amazon シンプル ストレージ サービス (Amazon S3) commoncrawl バケツで crawl-data/CC-NEWS/。ファイルのリストを取得するには、 AWSコマンドラインインターフェイス (AWS CLI) および次のコマンド:
In ドメイン固有の大規模言語モデルを構築するための効率的な継続的事前トレーニングでは、著者らは URL とキーワードベースのアプローチを使用して、一般的なニュースから金融ニュース記事をフィルタリングします。具体的には、著者は重要な金融ニュース報道機関のリストと、金融ニュースに関連する一連のキーワードを管理しています。記事が金融報道機関からのものであるか、URL にキーワードが含まれている場合、その記事は金融ニュースであると識別されます。このシンプルかつ効果的なアプローチにより、金融報道機関だけでなく、一般的な報道機関の財務セクションからも金融ニュースを特定できます。
SEC への提出書類は、オープン データ アクセスを提供する SEC の EDGAR (電子データ収集、分析、検索) データベースを通じてオンラインで入手できます。 EDGAR から直接ファイルを取得することも、API を使用することもできます。 アマゾンセージメーカー 数行のコードで、任意の期間および多数のティッカー (つまり、SEC に割り当てられた識別子) に対応できます。詳細については、を参照してください。 SEC 出願の取得.
次の表は、両方のデータ ソースの主要な詳細をまとめたものです。
| . | ニュース CommonCrawl | SECファイリング |
| カバレッジ | 2016-2022 | 1993-2022 |
| サイズ | 25.8億語 | 5.1億語 |
著者らは、データがトレーニング アルゴリズムに入力される前に、いくつかの追加の前処理ステップを実行します。まず、SEC への提出書類には表や図が削除されているためにノイズの多いテキストが含まれていることが観察されているため、作成者は表や図のラベルと思われる短い文を削除しています。次に、局所性を考慮したハッシュ アルゴリズムを適用して、新しい記事と出願書類の重複を排除します。 SEC への提出については、文書レベルではなくセクション レベルで重複排除を行います。最後に、ドキュメントを長い文字列に連結してトークン化し、そのトークン化をトレーニング対象のモデルでサポートされる最大入力長の部分に分割します。これにより、継続的な事前トレーニングのスループットが向上し、トレーニング コストが削減されます。
継続的な事前トレーニングと微調整
利用可能な LLM のほとんどは汎用であり、ドメイン固有の機能がありません。ドメイン LLM は、医療、金融、または科学のドメインでかなりのパフォーマンスを示しています。 LLM がドメイン固有の知識を取得するには、ゼロからのトレーニング、継続的な事前トレーニング、ドメイン タスクの指示の微調整、および検索拡張生成 (RAG) の 4 つの方法があります。
従来のモデルでは、通常、微調整はドメインのタスク固有のモデルを作成するために使用されます。これは、エンティティ抽出、意図分類、センチメント分析、質問応答などの複数のタスクに対して複数のモデルを維持することを意味します。 LLM の出現により、コンテキスト内学習やプロンプトなどの手法を使用することで、個別のモデルを維持する必要はなくなりました。これにより、関連する個別のタスク用のモデルのスタックを維持するために必要な労力が節約されます。
ドメイン固有のデータを使用して、LLM をゼロから直感的にトレーニングできます。ドメイン LLM を作成する作業のほとんどは、ゼロからトレーニングすることに重点が置かれていますが、法外に高価です。たとえば、GPT-4 モデルのコストは次のとおりです。 $ 100万以上 訓練する。これらのモデルは、オープン ドメイン データとドメイン データの組み合わせでトレーニングされます。継続的な事前トレーニングにより、既存のオープン ドメイン LLM をドメイン データのみで事前トレーニングするため、ゼロからの事前トレーニングのコストを発生させることなく、モデルがドメイン固有の知識を獲得できるようになります。
タスクの命令微調整では、LLM は命令微調整データセットに含まれるドメイン情報のみを取得するため、モデルにドメイン知識を取得させることはできません。命令を微調整するための非常に大規模なデータセットが使用されない限り、ドメイン知識を取得するだけでは十分ではありません。高品質の命令データセットを入手することは通常困難であり、これが最初に LLM を使用する理由です。また、1 つのタスクの命令を微調整すると、他のタスクのパフォーマンスに影響を与える可能性があります (例を参照)。 本論文)。ただし、指示の微調整は、トレーニング前の代替手段のいずれよりもコスト効率が高くなります。
次の図は、従来のタスク固有の微調整を比較しています。 vs LLM を使用したコンテキスト内学習パラダイム。
 RAG は、ドメインに基づいた応答を生成するように LLM を誘導する最も効果的な方法です。ドメインからのファクトを補助情報として提供することでモデルが応答を生成するようにガイドできますが、LLM は依然として非ドメイン言語スタイルに依存して応答を生成しているため、ドメイン固有の言語を取得しません。
RAG は、ドメインに基づいた応答を生成するように LLM を誘導する最も効果的な方法です。ドメインからのファクトを補助情報として提供することでモデルが応答を生成するようにガイドできますが、LLM は依然として非ドメイン言語スタイルに依存して応答を生成しているため、ドメイン固有の言語を取得しません。
継続的な事前トレーニングは、コストの点で事前トレーニングと指導の微調整の間の中間点であり、ドメイン固有の知識とスタイルを獲得するための強力な代替手段です。これは、限られた命令データに対してさらなる命令の微調整を実行できる一般的なモデルを提供できます。継続的な事前トレーニングは、ダウンストリーム タスクのセットが大きいか未知であり、ラベル付けされた命令チューニング データが限られている特殊なドメインにとって、費用対効果の高い戦略となります。他のシナリオでは、命令の微調整または RAG の方が適している可能性があります。
微調整、RAG、モデル トレーニングの詳細については、以下を参照してください。 基礎モデルを微調整する, 検索拡張生成 (RAG), AmazonSageMakerでモデルをトレーニングする、 それぞれ。この投稿では、効率的な継続的な事前トレーニングに焦点を当てます。
効果的な継続的な事前トレーニングの方法論
継続的な事前トレーニングは、次の方法論で構成されます。
- ドメイン適応型継続的事前トレーニング (DACP) – 論文で ドメイン固有の大規模言語モデルを構築するための効率的な継続的事前トレーニング著者らは、金融コーパス上で Pythia 言語モデル スイートを継続的に事前トレーニングして、金融ドメインに適応させています。目的は、金融ドメイン全体のデータをオープンソース モデルにフィードすることで金融 LLM を作成することです。トレーニング コーパスにはドメイン内で厳選されたすべてのデータセットが含まれているため、結果として得られるモデルは財務固有の知識を獲得し、それによってさまざまな財務タスクに汎用性の高いモデルとなるはずです。これにより、FinPythia モデルが作成されます。
- タスク適応型継続的事前トレーニング (TACP) – 著者は、ラベル付きおよびラベルなしのタスク データに基づいてモデルをさらに事前トレーニングし、特定のタスクに合わせて調整します。特定の状況では、開発者は、ドメイン汎用モデルよりも、ドメイン内タスクのグループでより優れたパフォーマンスを提供するモデルを好む場合があります。 TACP は、ラベル付きデータを必要とせず、対象タスクのパフォーマンスを向上させることを目的とした継続的な事前トレーニングとして設計されています。具体的には、作成者はタスク トークン (ラベルなし) でオープンソース モデルを継続的に事前トレーニングします。 TACP の主な制限は、トレーニングにラベルのないタスク データのみを使用するため、基礎 LLM ではなくタスク固有の LLM を構築することにあります。 DACP ははるかに大規模なコーパスを使用しますが、法外に高価です。これらの制限のバランスをとるために、著者は、ターゲット タスクで優れたパフォーマンスを維持しながらドメイン固有の基盤 LLM を構築することを目的とした 2 つのアプローチを提案します。
- 効率的なタスク類似 DACP (ETS-DACP) – 著者らは、埋め込み類似性を使用してタスク データに非常に類似した金融コーパスのサブセットを選択することを提案しています。このサブセットは、継続的な事前トレーニングをより効率的に行うために使用されます。具体的には、著者らは、配布の対象タスクに近い金融コーパスから抽出された小さなコーパス上で、オープンソースの LLM を継続的に事前トレーニングします。ラベル付きデータが必要ないにもかかわらず、タスク トークンの配布にこのモデルを採用するため、これはタスクのパフォーマンスの向上に役立ちます。
- 効率的なタスク非依存型 DACP (ETA-DACP) – 著者らは、効率的な継続的な事前トレーニングのために金融コーパスからサンプルを選択するためにタスクデータを必要としない、パープレキシティやトークンタイプのエントロピーなどのメトリクスを使用することを提案しています。このアプローチは、タスク データが利用できないシナリオ、またはより広範なドメイン向けのより汎用性の高いドメイン モデルが好まれるシナリオに対処するように設計されています。著者らは、新規性と多様性という 2 つの次元を採用して、事前トレーニング ドメイン データのサブセットからドメイン情報を取得するために重要なデータ サンプルを選択します。ターゲット モデルによって記録された複雑さによって測定される新規性は、以前に LLM によって認識されなかった情報を指します。新規性の高いデータは LLM にとって新しい知識を示しており、そのようなデータは学習がより難しいと見なされます。これにより、継続的な事前トレーニング中に集中的なドメイン知識を備えた汎用 LLM が更新されます。一方、多様性は、ドメイン コーパス内のトークン タイプの分布の多様性を捉えます。これは、言語モデリングに関するカリキュラム学習の研究において有用な特徴として文書化されています。
次の図は、ETS-DACP (左) と ETA-DACP (右) の例を比較しています。

当社では、厳選された金融コーパスからデータ ポイントを積極的に選択するために、ハード サンプリングとソフト サンプリングという 2 つのサンプリング スキームを採用しています。前者は、最初に対応するメトリクスによって財務コーパスをランク付けし、次に上位 k 個のサンプルを選択することによって行われます。ここで、k はトレーニング予算に従って事前に決定されます。後者の場合、著者はメトリック値に従って各データ ポイントにサンプリングの重みを割り当て、トレーニング予算を満たすために k 個のデータ ポイントをランダムにサンプリングします。
結果と分析
著者らは、継続的な事前トレーニングの有効性を調査するために、一連の財務タスクに関して結果として得られる財務 LLM を評価します。
- 金融フレーズバンク – 金融ニュースに関するセンチメント分類タスク。
- FiQA SA – 金融ニュースとヘッドラインに基づいた、側面ベースのセンチメント分類タスク。
- 見出し – 金融エンティティのヘッドラインに特定の情報が含まれているかどうかに関する二項分類タスク。
- NER – SEC レポートの信用リスク評価セクションに基づく金融固有エンティティ抽出タスク。このタスクの単語には、PER、LOC、ORG、および MISC の注釈が付けられます。
財務 LLM は命令が細かく調整されているため、著者らは堅牢性を確保するためにタスクごとに 5 ショット設定でモデルを評価しています。平均して、FinPythia 6.9B は 6.9 つのタスク全体で Pythia 10B を 1% 上回っており、ドメイン固有の継続的な事前トレーニングの有効性を示しています。 2B モデルの場合、改善の程度はそれほど大きくありませんが、それでもパフォーマンスは平均 XNUMX% 向上します。
次の図は、両モデルの DACP 前後のパフォーマンスの違いを示しています。

次の図は、Pythia 6.9B と FinPythia 6.9B によって生成された 6.9 つの定性的な例を示しています。投資家マネージャーと財務用語に関する 6.9 つの財務関連の質問について、Pythia XNUMXB は用語を理解しないか名前を認識しませんが、FinPythia XNUMXB は詳細な回答を正しく生成します。定性的な例は、継続的な事前トレーニングにより、LLM がプロセス中にドメイン知識を獲得できることを示しています。

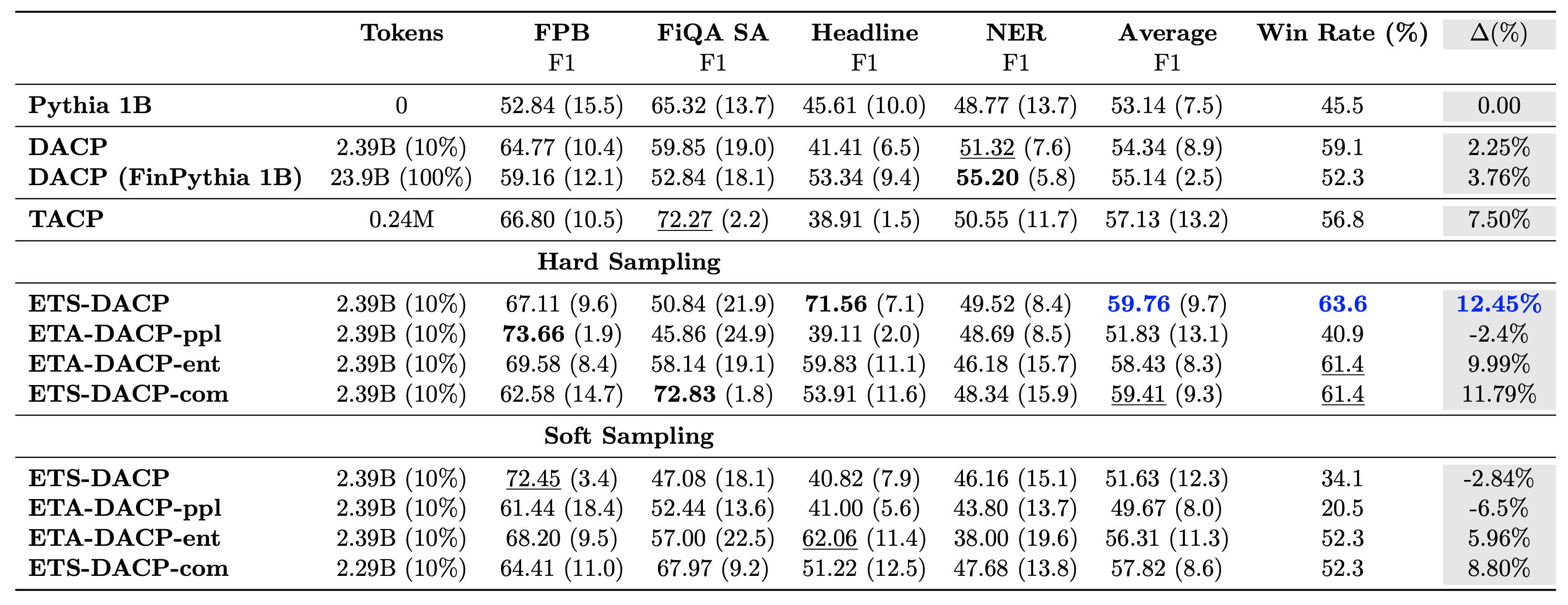
次の表は、さまざまな効率的な継続的事前トレーニング アプローチを比較しています。 ETA-DACP-ppl はパープレキシティ (新規性) に基づく ETA-DACP であり、ETA-DACP-ent はエントロピー (多様性) に基づく ETA-DACP です。 ETS-DACP-com は、3 つのメトリクスすべてを平均することでデータを選択する DACP に似ています。結果から得られるポイントをいくつか以下に示します。
- データ選択方法が効率的である – わずか 10% のトレーニング データで、標準的な継続的な事前トレーニングを上回ります。タスク類似 DACP (ETS-DACP)、エントロピーに基づくタスク非依存 DACP (ESA-DACP-ent)、および 10 つのメトリクスすべてに基づくタスク類似 DACP (ETS-DACP-com) を含む効率的な継続的事前トレーニングは、標準 DACP を上回るパフォーマンスを発揮します。彼らは金融コーパスのわずか XNUMX% についてトレーニングを受けているにもかかわらず、平均して
- タスクを意識したデータ選択は、小規模な言語モデルの研究に合わせて最適に機能します – ETS-DACP は、すべてのメソッドの中で最高の平均パフォーマンスを記録し、3 つのすべてのメトリクスに基づいて、2 番目に優れたタスク パフォーマンスを記録します。これは、LLM の場合、ラベルのないタスク データの使用がタスクのパフォーマンスを向上させる効果的なアプローチであることを示唆しています。
- タスクに依存しないデータ選択は僅差で 2 番目にあります – ESA-DACP-ent は、タスクを意識したデータ選択アプローチのパフォーマンスに従います。これは、特定のタスクに関連付けられていない高品質のサンプルを積極的に選択することによって、タスクのパフォーマンスを向上させることができることを意味します。これにより、優れたタスク パフォーマンスを達成しながら、ドメイン全体の財務 LLM を構築する道が開かれます。
継続的な事前トレーニングに関する重要な問題の 1 つは、それが非ドメイン タスクのパフォーマンスに悪影響を与えるかどうかです。著者らはまた、質問応答、推論、完了の能力を測定する、ARC、MMLU、TruthQA、および HellaSwag という広く使用されている 4 つの一般的なタスクについて、継続的に事前トレーニングされたモデルを評価しています。著者らは、継続的な事前トレーニングが非ドメインのパフォーマンスに悪影響を及ぼさないことを発見しました。詳細については、を参照してください。 ドメイン固有の大規模言語モデルを構築するための効率的な継続的事前トレーニング.
まとめ
この投稿では、金融ドメインの LLM をトレーニングするためのデータ収集と継続的な事前トレーニング戦略についての洞察を提供しました。次を使用して、財務タスク用に独自の LLM のトレーニングを開始できます。 Amazon SageMaker トレーニング or アマゾンの岩盤 。
著者について
 ヨン・シェ Amazon FinTech の応用科学者です。彼は、金融向けの大規模言語モデルと生成 AI アプリケーションの開発に重点を置いています。
ヨン・シェ Amazon FinTech の応用科学者です。彼は、金融向けの大規模言語モデルと生成 AI アプリケーションの開発に重点を置いています。
 カラン・アガルワル Amazon FinTech の上級応用科学者であり、金融ユースケース向けの生成 AI に重点を置いています。カランは時系列分析と NLP に豊富な経験があり、限られたラベル付きデータから学習することに特に興味を持っています。
カラン・アガルワル Amazon FinTech の上級応用科学者であり、金融ユースケース向けの生成 AI に重点を置いています。カランは時系列分析と NLP に豊富な経験があり、限られたラベル付きデータから学習することに特に興味を持っています。
 アイツァズ・アフマド Amazon の応用科学マネージャーであり、金融における機械学習と生成 AI のさまざまなアプリケーションを構築する科学者チームを率いています。彼の研究対象は、NLP、生成 AI、LLM エージェントです。彼はテキサス A&M 大学で電気工学の博士号を取得しました。
アイツァズ・アフマド Amazon の応用科学マネージャーであり、金融における機械学習と生成 AI のさまざまなアプリケーションを構築する科学者チームを率いています。彼の研究対象は、NLP、生成 AI、LLM エージェントです。彼はテキサス A&M 大学で電気工学の博士号を取得しました。
 チンウェイ・リー アマゾン ウェブ サービスの機械学習スペシャリストです。彼は博士号を取得しました。顧問の研究助成金口座を破棄し、約束していたノーベル賞を授与できなかったため、オペレーションズ・リサーチの博士号を取得した。現在、彼は金融サービスの顧客が AWS で機械学習ソリューションを構築するのを支援しています。
チンウェイ・リー アマゾン ウェブ サービスの機械学習スペシャリストです。彼は博士号を取得しました。顧問の研究助成金口座を破棄し、約束していたノーベル賞を授与できなかったため、オペレーションズ・リサーチの博士号を取得した。現在、彼は金融サービスの顧客が AWS で機械学習ソリューションを構築するのを支援しています。
 ラグベンダー・アルニ AWS 業界内のカスタマー アクセラレーション チーム (CAT) を率いています。 CAT は、顧客対応のクラウド アーキテクト、ソフトウェア エンジニア、データ サイエンティスト、AI/ML の専門家とデザイナーからなるグローバルな部門横断型チームであり、高度なプロトタイピングを通じてイノベーションを推進し、専門的な技術的専門知識を通じてクラウドの運用上の卓越性を推進します。
ラグベンダー・アルニ AWS 業界内のカスタマー アクセラレーション チーム (CAT) を率いています。 CAT は、顧客対応のクラウド アーキテクト、ソフトウェア エンジニア、データ サイエンティスト、AI/ML の専門家とデザイナーからなるグローバルな部門横断型チームであり、高度なプロトタイピングを通じてイノベーションを推進し、専門的な技術的専門知識を通じてクラウドの運用上の卓越性を推進します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

