概要
進化し続ける人工知能の状況において、生成 AI と強化学習という XNUMX つの主要なプレーヤーが新境地を開拓するために集結しました。 これらの最先端テクノロジーである生成 AI と強化学習には、自己改善型 AI システムを作成する可能性があり、自律的に学習して適応する機械の夢の実現に一歩近づきます。 これらのツールは、自らを改善できる AI システムへの道を切り開き、自ら学習して適応できる機械のアイデアに私たちを近づけます。

AI は近年、人間の言語の理解から、コンピュータによる周囲の世界の認識と解釈の支援まで、驚くべき驚異を生み出してきました。 GPT-3 などの生成 AI モデルや Deep Q-Networks などの強化学習アルゴリズムは、この進歩の最前線に立っています。 これらのテクノロジーは個別に変革をもたらしてきましたが、それらが融合することで AI 機能の新たな次元が開かれ、世界の境界が容易になります。
学習目標
- 強化学習とそのアルゴリズム、報酬構造、強化学習の一般的なフレームワーク、および状態アクション ポリシーについて必要な深い知識を取得し、エージェントがどのように意思決定を行うかを理解します。
- 特に意思決定のシナリオにおいて、これら XNUMX つのブランチをどのように共生的に組み合わせて、より適応性のあるインテリジェントなシステムを作成できるかを調査します。
- ヘルスケア、自動運転車、コンテンツ作成などの分野における生成 AI と強化学習の統合の有効性と適応性を実証するさまざまなケーススタディを研究および分析します。
- TensorFlow、PyTorch、OpenAI の Gym、Google の TF-Agents などの Python ライブラリに慣れ、これらのテクノロジーを実装する際の実践的なコーディング経験を積みます。
この記事は、の一部として公開されました データサイエンスブログ。
目次
生成型 AI: マシンに創造性を与える
生成AI OpenAI の GPT-3 のようなモデルは、自然言語、画像、さらには音楽などのコンテンツを生成するように設計されています。 これらのモデルは、特定のコンテキストで次に何が起こるかを予測するという原則に基づいて動作します。 これらは、自動コンテンツ生成から人間の会話を模倣できるチャットボットまで、あらゆる用途に使用されています。 Generative AI の特徴は、学習したパターンから新しいものを生み出す能力です。
強化学習: AI に意思決定を教える
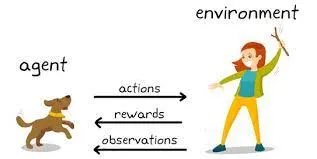
強化学習 (RL) も画期的な分野です。 これは、人工知能に人間と同じように試行錯誤から学習させるテクノロジーです。 AI に Dota 2 や囲碁などの複雑なゲームをプレイするよう教えるために使用されてきました。 RL エージェントは、自分の行動に対する報酬やペナルティを受け取ることで学習し、このフィードバックを時間の経過とともに改善するために使用します。 ある意味、RL は AI に一種の自律性を与え、動的な環境で意思決定を行えるようにします。
強化学習のフレームワーク
このセクションでは、強化学習の主要なフレームワークをわかりやすく説明します。
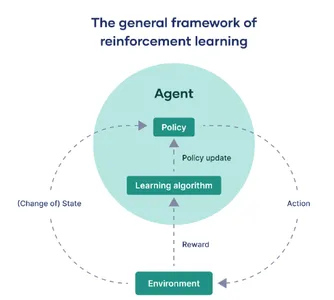
代理エンティティ: エージェント
人工知能と機械学習の分野では、「エージェント」という用語は、指定された外部環境と対話する任務を負った計算モデルを指します。 その主な役割は、定義された目標を達成するか、一連のステップを通じて最大の報酬を蓄積するために意思決定を行い、行動を起こすことです。
世界中: 環境
「環境」とは、エージェントが動作する外部コンテキストまたはシステムを意味します。 本質的に、それはエージェントの制御を超えているが観察可能なすべての要素を構成します。 これは、仮想ゲーム インターフェイスから、迷路を移動するロボットなどの現実世界の設定まで、さまざまです。 環境は、エージェントのパフォーマンスが評価される「根拠となる真実」です。
遷移のナビゲート: 状態の変化
強化学習の専門用語では、「状態」または「s」で示され、エージェントが環境と対話する際に遭遇する可能性のあるさまざまなシナリオを表します。 これらの状態遷移は極めて重要です。 それらはエージェントの観察を知らせ、将来の意思決定メカニズムに大きな影響を与えます。
意思決定ルールブック: ポリシー
「ポリシー」という用語は、さまざまな状態に対応するアクションを選択するためのエージェントの戦略を要約したものです。 これは、状態のドメインから一連のアクションへのマッピング機能として機能し、目標を達成するためのエージェントの行動様式を定義します。
時間の経過による改良: ポリシーの更新
「ポリシーの更新」とは、エージェントの既存のポリシーを調整する反復的なプロセスを指します。 これは強化学習の動的な側面であり、エージェントが過去の報酬や新たに取得した経験に基づいてその動作を最適化できるようになります。 これは、エージェントの戦略を再調整する特殊なアルゴリズムによって促進されます。
適応のエンジン: 学習アルゴリズム
学習アルゴリズムは、エージェントがポリシーを調整できるようにする数学的フレームワークを提供します。 コンテキストに応じて、これらのアルゴリズムは、現実世界のインタラクションから直接学習するモデルフリー手法と、学習用の環境のシミュレートされたモデルを利用するモデルベース手法に大別できます。
成功の尺度: 報酬
最後に、「報酬」は環境によって与えられる定量化可能な指標であり、エージェントによって実行されたアクションの即時効果を測定します。 エージェントの包括的な目的は、一定期間にわたるこれらの報酬の合計を最大化することであり、これがパフォーマンス指標として効果的に機能します。
一言で言えば、強化学習は、エージェントとその環境の間の継続的な相互作用に要約できます。 エージェントはさまざまな状態を横断し、特定のポリシーに基づいて意思決定を行い、フィードバックとして機能する報酬を受け取ります。 このポリシーを繰り返し微調整するために学習アルゴリズムが導入され、エージェントが常に環境の制約内で最適化された動作に向けた軌道に乗ることが保証されます。
相乗効果: 生成 AI と強化学習の融合

本当の魔法は、生成 AI が強化学習と出会うときに起こります。 AI 研究者は、AI と強化学習という XNUMX つの領域を組み合わせて、コンテンツを生成するだけでなく、ユーザーのフィードバックから学習して出力を改善し、より良い AI コンテンツを取得できるシステムまたはデバイスを作成する実験と研究を行ってきました。
- 初期コンテンツ生成: GPT-3 のような生成 AI は、特定の入力またはコンテキストに基づいてコンテンツを生成します。 このコンテンツは記事からアートまで何でも構いません。
- ユーザーフィードバックループ: コンテンツが生成されてユーザーに表示されると、与えられたフィードバックは AI システムをさらにトレーニングするための貴重な資産になります。
- 強化学習 (RL) メカニズム: このユーザーのフィードバックを利用して、強化学習アルゴリズムが介入して、コンテンツのどの部分が評価され、どの部分を改善する必要があるかを評価します。
- アダプティブコンテンツ生成: この分析によって得られた情報に基づいて、Generative AI は内部モデルを適応させて、ユーザーの好みに合わせて調整します。 各対話から学んだ教訓を組み込んで、出力を繰り返し改良します。
- テクノロジーの融合: 生成 AI と強化学習の組み合わせにより、生成されたコンテンツが RL エージェントのプレイグラウンドとして機能する動的なエコシステムが作成されます。 ユーザーのフィードバックは報酬信号として機能し、AI に改善方法を指示します。
この生成 AI と強化学習の組み合わせにより、適応性の高いシステムが可能になり、実際のフィードバックの例である人間のフィードバックから学習することもできるため、よりユーザーに合わせた効果的な結果が得られ、人間のニーズに合わせたより良い結果が得られます。
コードスニペットの相乗効果
生成 AI と強化学習の相乗効果を理解しましょう。
import torch
import torch.nn as nn
import torch.optim as optim # Simulated Generative AI model (e.g., a text generator)
class GenerativeAI(nn.Module): def __init__(self): super(GenerativeAI, self).__init__() # Model layers self.fc = nn.Linear(10, 1) # Example layer def forward(self, input): output = self.fc(input) # Generate content, for this example, a number return output # Simulated User Feedback
def user_feedback(content): return torch.rand(1) # Mock user feedback # Reinforcement Learning Update
def rl_update(model, optimizer, reward): loss = -torch.log(reward) optimizer.zero_grad() loss.backward() optimizer.step() # Initialize model and optimizer
gen_model = GenerativeAI()
optimizer = optim.Adam(gen_model.parameters(), lr=0.001) # Iterative improvement
for epoch in range(100): content = gen_model(torch.randn(1, 10)) # Mock input reward = user_feedback(content) rl_update(gen_model, optimizer, reward)
コードの説明
- 生成 AI モデル: これは、テキスト ジェネレーターのような、コンテンツを生成しようとする機械のようなものです。 この場合、入力を受け取って出力を生成するように設計されています。
- ユーザーフィードバック: AI が生成したコンテンツに対してユーザーがフィードバックを提供するところを想像してください。 このフィードバックは、AI が何が良いか悪いかを学習するのに役立ちます。 このコードでは、例としてランダム フィードバックを使用します。
- 強化学習の最新情報: フィードバックを受け取った後、AI はより良くなるために自らを更新します。 内部設定を調整してコンテンツ生成を改善します。
- 反復的な改善: AI は、コンテンツの生成、フィードバックの取得、そこから学習するという多くのサイクル (このコードでは 100 回) を実行します。 時間が経つにつれて、目的のコンテンツを作成する能力が向上します。
このコードは、基本的な生成 AI モデルとフィードバック ループを定義します。 AI はコンテンツを生成し、ランダムなフィードバックを受け取り、100 回以上繰り返して調整してコンテンツ作成機能を向上させます。
実際のアプリケーションでは、より洗練されたモデルとより微妙なユーザー フィードバックを使用します。 ただし、このコード スニペットは、生成 AI と強化学習を調和させて、コンテンツを生成するだけでなく、フィードバックに基づいてコンテンツの改善を学習するシステムを構築する方法の本質を捉えています。
実際のアプリケーション
生成 AI と強化学習の相乗効果から生まれる可能性は無限です。 実際のアプリケーションを見てみましょう。
コンテンツ生成
AI によって作成されたコンテンツは、個々のユーザーの好みや好みに合わせて、ますますパーソナライズされる可能性があります。
RL エージェントが GPT-3 を使用してパーソナライズされたニュース フィードを生成するシナリオを考えてみましょう。 各記事を読んだ後、ユーザーはフィードバックを提供します。 ここでは、フィードバックが単なる「好き」か「嫌い」であり、それが数値的な報酬に変換されたと仮定してみましょう。
from transformers import GPT2LMHeadModel, GPT2Tokenizer
import torch # Initialize GPT-2 model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2') # RL update function
def update_model(reward, optimizer): loss = -torch.log(reward) optimizer.zero_grad() loss.backward() optimizer.step() # Initialize optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Example RL loop
for epoch in range(10): input_text = "Generate news article about technology." input_ids = tokenizer.encode(input_text, return_tensors='pt') with torch.no_grad(): output = model.generate(input_ids) article = tokenizer.decode(output[0]) print(f"Generated Article: {article}") # Get user feedback (1 for like, 0 for dislike) reward = float(input("Did you like the article? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)アートと音楽
AI は人間の感情に共鳴するアートや音楽を生成し、視聴者のフィードバックに基づいてスタイルを進化させることができます。 RL エージェントは、フィードバックに基づいてニューラル スタイル転送アルゴリズムのパラメーターを最適化し、人間の感情によりよく共鳴するアートや音楽を作成できます。
# Assuming a function style_transfer(image, style) exists
# RL update function similar to previous example # Loop through style transfers
for epoch in range(10): new_art = style_transfer(content_image, style_image) show_image(new_art) reward = float(input("Did you like the art? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)会話型AI
チャットボット また、仮想アシスタントは、より自然で状況を認識した会話を行うことができるため、顧客サービスに非常に役立ちます。 チャットボットは強化学習を利用して、会話履歴とユーザーのフィードバックに基づいて会話モデルを最適化できます。
# Assuming a function chatbot_response(text, model) exists
# RL update function similar to previous examples for epoch in range(10): user_input = input("You: ") bot_response = chatbot_response(user_input, model) print(f"Bot: {bot_response}") reward = float(input("Was the response helpful? (1 for yes, 0 for no): ")) update_model(torch.tensor(reward), optimizer)自律車両
自動運転車の AI システムは、現実世界の運転経験から学習し、安全性と効率性を向上させることができます。 自動運転車の RL エージェントは、燃料効率、時間、安全性などのさまざまな報酬に基づいて、リアルタイムで経路を調整できます。
# Assuming a function drive_car(state, policy) exists
# RL update function similar to previous examples for epoch in range(10): state = get_current_state() # e.g., traffic, fuel, etc. action = drive_car(state, policy) reward = get_reward(state, action) # e.g., fuel saved, time taken, etc. update_model(torch.tensor(reward), optimizer)これらのコード スニペットは説明用であり、簡略化されています。 これらは、Generative AI と RL が連携してさまざまなドメイン全体でユーザー エクスペリエンスを向上できるという概念を明確にするのに役立ちます。 各スニペットは、レーダー画像セグメンテーションの Unet などの深層学習モデルを繰り返し改善する方法と同様に、エージェントが受け取った報酬に基づいてポリシーを繰り返し改善する方法を示しています。
ケーススタディ
ヘルスケアの診断と治療の最適化
- 問題: 医療においては、正確かつタイムリーな診断が非常に重要です。 医療従事者にとって、膨大な量の医学文献や進化するベストプラクティスを把握し続けることは、多くの場合困難です。
- ソリューション: BERT のような生成 AI モデルは、医学書から洞察を抽出できます。 RL エージェントは、過去の患者データと最新の研究に基づいて治療計画を最適化できます。
- ケーススタディ: IBM の Watson for Oncology は、Generative AI と RL を使用して、膨大な医学文献に照らして患者の医療記録を分析することにより、腫瘍学者が治療法を決定するのを支援します。 これにより、治療推奨の精度が向上しました。
小売およびパーソナライズされたショッピング
- 問題:電子商取引では、顧客のショッピング体験をパーソナライズすることが売上を伸ばすために不可欠です。
- ソリューション: GPT-3 のような生成 AI は、製品の説明、レビュー、推奨事項を生成できます。 RL エージェントは、ユーザーの対話とフィードバックに基づいてこれらの推奨事項を最適化できます。
- ケーススタディ: Amazon は、Generative AI を使用して商品説明を生成し、RL を使用して商品の推奨を最適化します。 これにより、売上と顧客満足度が大幅に向上しました。
コンテンツの作成とマーケティング
- 問題: マーケティング担当者は、魅力的なコンテンツを大規模に作成する必要があります。 何が視聴者の共感を呼ぶかを知るのは難しい。
- ソリューション: GPT-2 などの生成 AI は、ブログ投稿、ソーシャル メディア コンテンツ、広告コピーを生成できます。 RL は、エンゲージメント指標に基づいてコンテンツ生成を最適化できます。
- ケーススタディ: マーケティング プラットフォームである HubSpot は、Generative AI を使用してコンテンツの作成を支援します。 RL を使用してユーザー エンゲージメントに基づいてコンテンツ戦略を微調整し、より効果的なマーケティング キャンペーンを実現します。
ビデオゲーム開発
- 問題: プレイヤーのアクションに適応する現実的な動作とゲーム環境を備えたノンプレイヤー キャラクター (NPC) の作成は複雑で時間がかかります。
- ソリューション: 生成 AI は、ゲームのレベル、キャラクター、ダイアログをデザインできます。 RL エージェントは、プレイヤーのインタラクションに基づいて NPC の動作を最適化できます。
- ケーススタディ: ゲーム業界では、Ubisoft のようなスタジオが世界構築にジェネレーティブ AI を使用し、NPC AI に RL を使用しています。 このアプローチにより、よりダイナミックで魅力的なゲームプレイ エクスペリエンスが実現しました。
金融取引
- 問題:競争の激しい金融取引の世界では、収益性の高い戦略を見つけるのは困難な場合があります。
- ソリューション: 生成 AI はデータ分析と戦略生成を支援します。 RL エージェントは、市場データとユーザー定義の目標に基づいて取引戦略を学習し、最適化できます。
- ケーススタディ:ルネッサンス・テクノロジーズのようなヘッジファンドは、ジェネレーティブ AI と RL を活用して、収益性の高い取引アルゴリズムを発見しています。 これにより、多額の投資収益が得られました。
これらのケーススタディは、生成 AI と強化学習の組み合わせがタスクの自動化、エクスペリエンスのパーソナライズ、意思決定プロセスの最適化によってさまざまな業界をどのように変革しているかを示しています。
倫理的配慮
AIの公平性
AI システムの公平性を確保することは、偏見や差別を防ぐために重要です。 AI モデルは、多様で代表的なデータセットでトレーニングする必要があります。 AI モデルのバイアスを検出して軽減することは、継続的な課題です。 これは、偏ったアルゴリズムが現実世界に重大な影響を及ぼす可能性がある融資や雇用などの分野では特に重要です。
説明責任と責任
AI システムが進化し続けるにつれて、説明責任と責任が中心となります。 開発者、組織、規制当局は、明確な責任範囲を定義する必要があります。 個人や組織に AI システムの決定や行動に対する責任を負わせるためには、倫理的なガイドラインと基準を確立する必要があります。 たとえば医療分野では、患者の安全と AI 支援診断に対する信頼を確保するために、説明責任が最も重要です。
透明性と説明可能性
一部の AI モデルの「ブラック ボックス」の性質が懸念されています。 AI の倫理的かつ責任感を確保するには、AI の意思決定プロセスが透明性があり、理解できることが重要です。 研究者とエンジニアは、説明可能で特定の決定が行われた理由についての洞察を提供する AI モデルの開発に取り組む必要があります。 これは、AI システムによる決定が個人の生活に大きな影響を与える可能性がある刑事司法などの分野にとって非常に重要です。
データのプライバシーと同意
データプライバシーの尊重は、倫理的な AI の基礎です。 AI システムはユーザー データに依存することが多く、データ使用についてのインフォームド コンセントを取得することが最も重要です。 ユーザーは自分のデータを管理できる必要があり、機密情報を保護するためのメカニズムが整備されている必要があります。 この問題は、レコメンデーション エンジンや仮想アシスタントなどの AI 主導のパーソナライゼーション システムにおいて特に重要です。
危害の軽減
AI システムは、有害な情報、誤解を招く情報、または虚偽の情報の作成を防ぐように設計される必要があります。 これは、コンテンツ生成の領域に特に関係します。 アルゴリズムはヘイトスピーチ、誤った情報、または有害な行為を助長するコンテンツを生成してはなりません。 ユーザー作成コンテンツが蔓延するプラットフォームでは、より厳格なガイドラインと監視が不可欠です。
人間の監視と倫理的専門知識
人間による監視は引き続き重要です。 AI がより自律的になったとしても、さまざまな分野の人間の専門家が AI と連携して作業する必要があります。 彼らは倫理的な判断を下し、AI システムを微調整し、必要に応じて介入することができます。 たとえば、自動運転車では、人間のセーフティ ドライバーが、複雑な状況や予期せぬ状況で制御を引き継ぐ準備ができていなければなりません。
これらの倫理的配慮は AI の開発と展開の最前線にあり、公平性、説明責任、透明性の原則を守りながら AI テクノロジーが社会に利益をもたらすことを保証します。 これらの問題に対処することは、責任を持って倫理的に AI を私たちの生活に組み込むために極めて重要です。
まとめ
私たちは、生成 AI と強化学習が融合し始めるエキサイティングな時代を目の当たりにしています。 この融合により、革新的な創造と効果的な意思決定の両方が可能な、自己改善型 AI システムへの道が切り開かれています。 しかし、大きな力には大きな責任が伴います。 AI の急速な進歩には、AI を責任を持って導入するために不可欠な倫理的考慮事項が伴います。 理解するだけでなく学習して適応する AI を作成するこの旅に乗り出すことで、イノベーションの無限の可能性が開かれます。 それにもかかわらず、倫理的な誠実さを持って前進し、私たちが生み出すテクノロジーが善の力として機能し、人類全体に利益をもたらすようにすることが重要です。
主要な取り組み
- 生成 AI と強化学習 (RL) は自己改善システムを作成するために融合しており、前者はコンテンツ生成に重点が置かれ、後者は試行錯誤による意思決定に重点が置かれています。
- RL では、主要なコンポーネントには意思決定を行うエージェントが含まれます。 エージェントが対話する環境。 そして報酬はパフォーマンスの指標として機能します。 ポリシーと学習アルゴリズムにより、エージェントは時間の経過とともに改善されます。
- Generative AI と RL を組み合わせることで、コンテンツを生成し、ユーザーのフィードバックに基づいて適応するシステムが可能になり、その結果、出力が反復的に改善されます。
- Python コード スニペットは、コンテンツ生成用のシミュレートされた Generative AI モデルと、ユーザーのフィードバックに基づいて最適化する RL を組み合わせることによるこの相乗効果を示しています。
- 現実世界のアプリケーションは、パーソナライズされたコンテンツの生成、アートや音楽の作成、会話型 AI、さらには自動運転車など、膨大です。
- これらのテクノロジーを組み合わせることで、AI が人間のニーズや好みと相互作用し、それに適応する方法に革命をもたらし、よりパーソナライズされた効果的なソリューションにつながる可能性があります。
よくある質問
A. 生成 AI と強化学習を組み合わせると、新しいデータを生成するだけでなく、その有効性を最適化するインテリジェント システムが作成されます。 この相乗関係により、AI アプリケーションの範囲と効率が広がり、AI アプリケーションの多用途性と適応性が高まります。
A. 強化学習は、システムの意思決定の中核として機能します。 報酬を中心としたフィードバック ループを採用することで、Generative AI モジュールから生成されたコンテンツを評価し、適応させます。 この反復プロセスにより、時間の経過とともにデータ生成戦略が最適化されます。
A. 実際の応用範囲は多岐にわたります。 医療分野では、このテクノロジーにより、リアルタイムの患者データを使用して治療計画を動的に作成し、調整することができます。 一方、自動車分野では、自動運転車が道路状況の変動に応じてルートをリアルタイムに調整できるようになる可能性がある。
A. Python は、その包括的なエコシステムにより、依然として頼りになる言語です。 TensorFlow や PyTorch などのライブラリは生成 AI タスクによく使用されますが、OpenAI の Gym や Google の TF-Agents は強化学習実装の一般的な選択肢です。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/10/generative-ai-and-reinforcement-learning/

