概要
今日のペースの速い地元食材配達の世界では、企業にとって顧客満足度を確保することが重要です。 Zomato や Swiggy などの大手企業がこの業界を支配しています。顧客は新鮮な食品を期待しています。破損した商品を受け取った場合は、返金または割引券を喜んで受け取ります。しかし、食品の鮮度を手動で判断するのは顧客や会社スタッフにとって面倒です。解決策の 1 つは、深層学習モデルを使用してこのプロセスを自動化することです。これらのモデルは食品の鮮度を予測できるため、フラグが立てられた苦情のみを従業員が最終検証のためにレビューできるようになります。モデルが食品の鮮度を確認した場合、苦情は自動的に却下されます。この記事では、深層学習を使用して食品品質検出器を構築します。
人工知能のサブセットであるディープラーニングは、この文脈において重要な有用性を提供します。具体的には、CNN (畳み込みニューラル ネットワーク) を使用して、食品の画像を使用してモデルをトレーニングし、鮮度を識別できます。モデルの精度はデータセットの品質に完全に依存します。理想的には、ユーザーのチャットボットの苦情から実際の食品の画像をハイパーローカルな食品配達アプリに組み込むことで、精度が大幅に向上します。ただし、そのようなデータにアクセスできないため、Kaggle でアクセスできる「Fresh and Rottenクラシフィケーション データセット」として知られる広く使用されているデータセットに依存しています。完全なディープラーニング コードを調べるには、表示される [コピーして編集] ボタンをクリックするだけです。 こちら.
学習目標
- 顧客満足度とビジネスの成長における食品の品質の重要性を学びます。
- 深層学習が食品品質検出器の構築にどのように役立つかをご覧ください。
- このモデルを段階的に実装することで実践的な経験を積みます。
- その実装に伴う課題と解決策を理解します。
この記事は、の一部として公開されました データサイエンスブログ。
目次
食品品質検出器におけるディープラーニングの使用について理解する
深層学習、のサブセット Artificial Intelligenceでは、主に空間データセットを使用してモデルを構築します。ディープ ラーニング内のニューラル ネットワークは、人間の脳の機能を模倣してこれらのモデルをトレーニングするために利用されます。
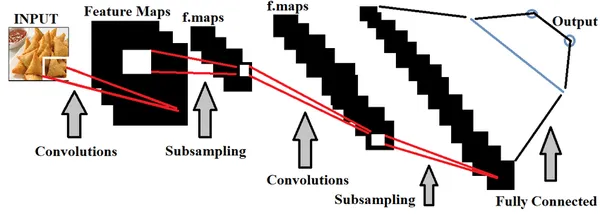
食品品質検出のコンテキストでは、食品の品質が良いものと悪いものを正確に区別するには、広範な食品画像のセットを使用してディープラーニング モデルをトレーニングすることが不可欠です。我々はできる ハイパーパラメータ調整 モデルをより正確にするために、供給されるデータに基づいて行われます。
ハイパーローカルデリバリーにおける食品品質の重要性
この機能をハイパーローカルな食品配達に統合すると、いくつかの利点が得られます。このモデルは、特定の顧客に対する偏見を回避し、正確に予測するため、苦情の解決時間を短縮します。さらに、注文の梱包プロセス中にこの機能を使用して、配達前に食品の品質を検査し、顧客が一貫して新鮮な食品を受け取ることができるようにします。

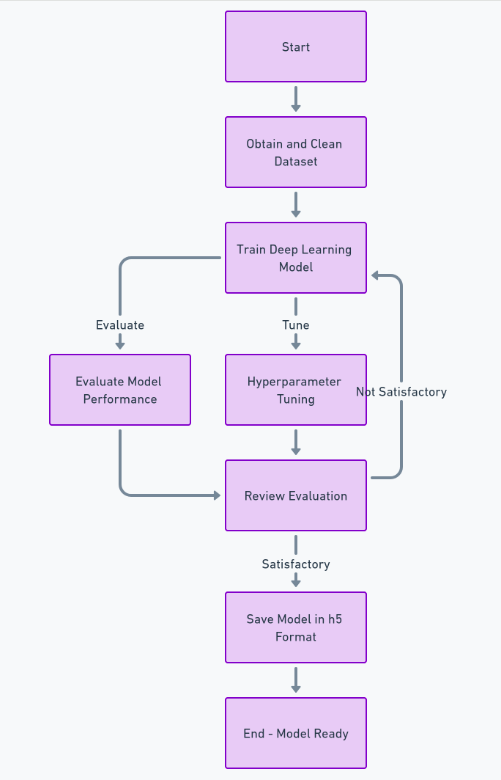
食品品質検出器の開発
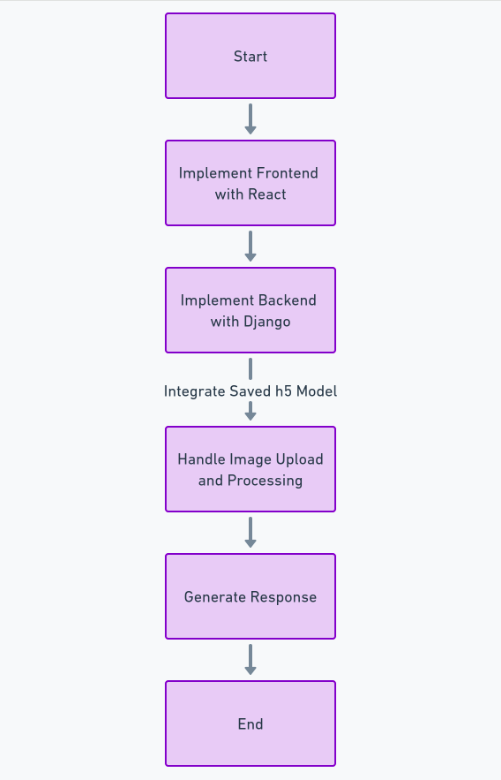
この機能を完全に構築するには、データセットの取得とクリーニング、深層学習モデルのトレーニング、パフォーマンスの評価とハイパーパラメーター調整の実行、最後にモデルを保存するなど、多くの手順に従う必要があります。 h5 フォーマット。この後、次を使用してフロントエンドを実装できます。 反応する、および Python のフレームワークを使用したバックエンド ジャンゴ。 Django を使用して画像のアップロードと処理を行います。
データセットについて
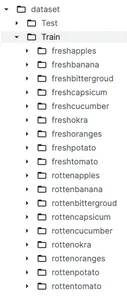
データの前処理とモデルの構築に深く入る前に、データセットを理解することが重要です。前に説明したように、Kaggle の次の名前のデータセットを使用します。 生鮮食品と腐った食品の分類。このデータセットは、という名前の 2 つの主要なカテゴリに分割されます。 トレーニング & ホイール試乗 which それぞれトレーニングとテストの目的で使用されます。 train フォルダーの下には、新鮮な果物と新鮮な野菜の 9 つのサブフォルダーと、腐った果物と腐った野菜の 9 つのサブフォルダーがあります。
データセットの主な特徴
- 画像の多様性: このデータセットには、角度、背景、照明条件のバリエーションが豊富な食べ物の画像が多数含まれています。これにより、モデルに偏りがなくなり、より正確になります。
- 高品質の画像: このデータセットには、さまざまなプロ仕様のカメラで撮影された非常に高品質の画像が含まれています。
データのロードと準備
このセクションでは、まず「」を使用して画像をロードします。tensorflow.keras.preprocessing.image。ロードイメージ' 関数を実行し、matplotlib ライブラリを使用して画像を視覚化します。モデルのトレーニングのためにこれらの画像を前処理することは非常に重要です。これには、モデルに適したものにするために画像を整理して整理することが含まれます。
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)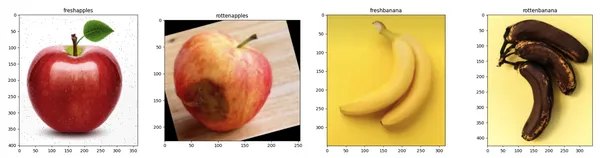
次に、トレーニング画像とテスト画像を変数にロードしましょう。すべての画像を同じ高さと幅 180 にサイズ変更します。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
モデル構築
次に、「tensorflow.keras」の Sequential アルゴリズムを使用して深層学習モデルを構築しましょう。 3 つの畳み込みレイヤーと Adam オプティマイザーを追加します。実際的な部分について詳しく説明する前に、まず「」という用語が何であるかを理解しましょう。シーケンシャルモデル「、」アダム・オプティマイザー'および'畳み込み層' 平均。
シーケンシャルモデル
シーケンシャル モデルはレイヤーのスタックで構成され、Keras の基本構造を提供します。これは、ニューラル ネットワークが単一の入力テンソルと単一の出力テンソルを備えているシナリオに最適です。実行順序に従ってレイヤーを追加するため、レイヤーを積み重ねた単純なモデルの構築に適しています。このシンプルさにより、シーケンシャル モデルは非常に便利になり、実装が容易になります。
アダム・オプティマイザー
Adam の略称は「Adaptive Moment Estimation」です。これは、確率的勾配降下法に代わる最適化アルゴリズムとして機能し、ネットワークの重みを繰り返し更新します。 Adam Optimizer は、ネットワークの重みごとに学習率 (LR) を維持するため、データ内のノイズを処理するのに有利です。
畳み込み層 (Conv2D)
これは、畳み込みニューラル ネットワーク (CNN) の主要コンポーネントです。主に画像などの空間データセットの処理に使用されます。この層は、畳み込み関数または演算を入力に適用し、結果を次の層に渡します。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)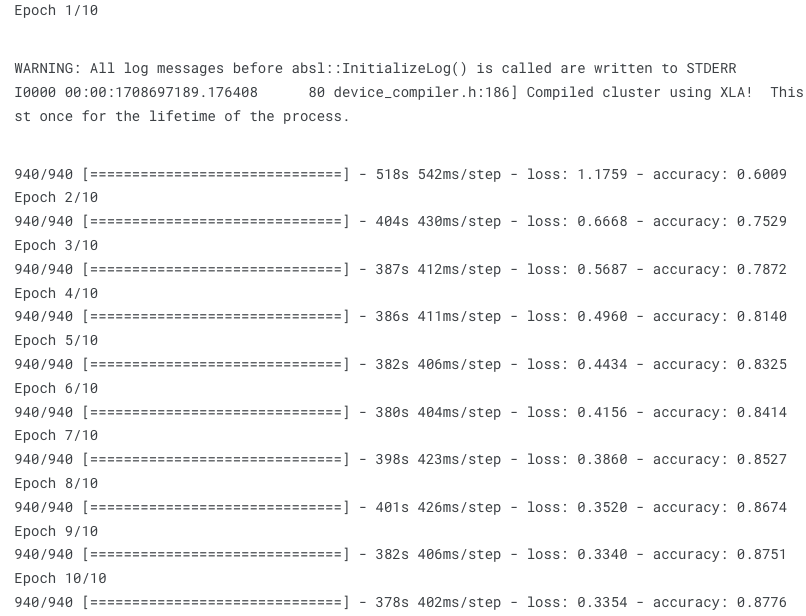
食品品質検出器のテスト
次に、新しい食べ物の画像を与えてモデルをテストし、新鮮な食べ物と腐った食べ物をどれだけ正確に分類できるかを見てみましょう。
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
ご覧のとおり、モデルは正しく予測しました。私たちが与えたように 腐ったオレンジ 入力としての画像、モデルはそれを正しく予測しました ロットン.
フロントエンド (React) とバックエンド (Django) のコードについては、GitHub で私の完全なコードをここで参照できます。 リンク
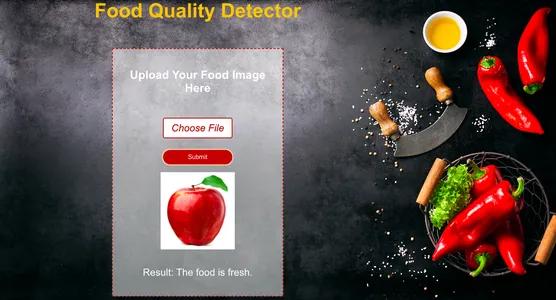
まとめ
結論として、ハイパーローカル デリバリー アプリでの食品品質に関する苦情を自動化するために、Web アプリと統合された深層学習モデルを構築することを提案します。ただし、トレーニング データが限られているため、モデルはすべての食品画像を正確に検出できない可能性があります。この実装は、より大規模なソリューションに向けた基礎的なステップとして機能します。これらのアプリ内でユーザーがアップロードした画像にリアルタイムでアクセスできれば、モデルの精度が大幅に向上します。
主要な取り組み
- 食品の品質は、ハイパーローカルな食品配達市場で顧客満足度を達成する上で重要な役割を果たします。
- 深層学習テクノロジーを利用して、正確な食品品質予測子をトレーニングできます。
- このステップバイステップ ガイドを使用して Web アプリを構築する実践的な経験を積みました。
- 正確なモデルを構築するにはデータセットの品質が重要であることが理解できました。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/

