概要
ストレスは、厳しい状況や困難な状況に対する体と心の自然な反応です。 これは、外部からの圧力や内部の思考や感情に対する身体の反応方法です。 ストレスは、仕事関連のプレッシャー、経済的困難、人間関係の問題、健康上の問題、人生の大きな出来事など、さまざまな要因によって引き起こされる可能性があります。 データ サイエンスと機械学習を活用したストレス検出の洞察は、個人または集団のストレス レベルを予測することを目的としています。 予測モデルは、生理学的測定値、行動データ、環境要因などのさまざまなデータ ソースを分析することで、ストレスに関連するパターンと危険因子を特定できます。

このプロアクティブなアプローチにより、タイムリーな介入とカスタマイズされたサポートが可能になります。 ストレス予測は、早期発見と個別化された介入のための医療分野だけでなく、職場環境を最適化するための職業環境においても可能性を秘めています。 また、公衆衛生への取り組みや政策決定についても情報を提供できます。 ストレスを予測する機能を備えたこれらのモデルは、個人やコミュニティの幸福を改善し、回復力を高めるための貴重な洞察を提供します。
この記事は、の一部として公開されました データサイエンスブログ。
目次
機械学習を使用したストレス検出の概要
機械学習を使用したストレス検出には、データの収集、クリーニング、および前処理が含まれます。 特徴エンジニアリング手法は、意味のある情報を抽出したり、ストレスに関連するパターンを捕捉できる新しい特徴を作成したりするために適用されます。 これには、ストレスの生理学的指標または行動指標を捕捉するための統計的測定値の抽出、周波数領域分析、または時系列分析が含まれる場合があります。 関連する機能が抽出または設計され、パフォーマンスが向上します。

研究者は、ラベル付きデータを利用してストレス レベルを分類することにより、ロジスティック回帰、SVM、デシジョン ツリー、ランダム フォレスト、ニューラル ネットワークなどの機械学習モデルをトレーニングします。 精度、適合率、再現率、F1 スコアなどの指標を使用してモデルのパフォーマンスを評価します。 トレーニングされたモデルを現実世界のアプリケーションに統合することで、リアルタイムのストレス監視が可能になります。 継続的なモニタリング、更新、ユーザーからのフィードバックは、精度を向上させるために非常に重要です。
ストレスに関連する機密の個人データを扱う場合は、倫理上の問題とプライバシーへの懸念を考慮することが重要です。 個人のプライバシーと権利を保護するには、適切なインフォームド・コンセント、データの匿名化、および安全なデータ保管手順に従う必要があります。 プロセス全体を通じて、倫理的配慮、プライバシー、データ セキュリティが重要です。 機械学習ベースのストレス検出により、早期介入、個別のストレス管理、幸福度の向上が可能になります。
データの説明
「ストレス」データセットには、ストレス レベルに関連する情報が含まれています。 データセットの特定の構造と列がなければ、パーセンタイルのデータ記述がどのようなものになるかについての一般的な概要を提供できます。
データセットには、年齢、血圧、心拍数、体重計で測定されたストレス レベルなどの定量的測定値を表す数値変数が含まれる場合があります。 また、性別、職業カテゴリ、さまざまなカテゴリ (低、中、高) に分類されたストレス レベルなどの質的特性を表すカテゴリ変数も含まれる場合があります。
# Array
import numpy as np # Dataframe
import pandas as pd #Visualization
import matplotlib.pyplot as plt
import seaborn as sns # warnings
import warnings
warnings.filterwarnings('ignore') #Data Reading
stress_c= pd.read_csv('/human-stress-prediction/Stress.csv') # Copy
stress=stress_c.copy() # Data
stress.head()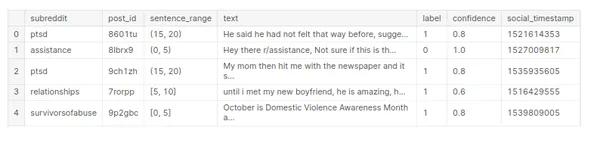
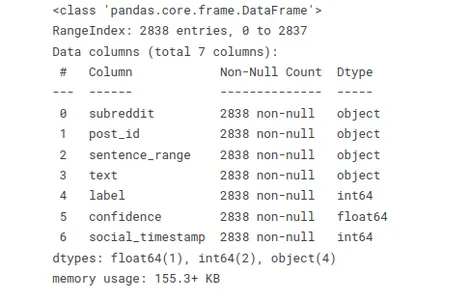
以下の関数を使用すると、データ型を迅速に評価し、欠落値または null 値を見つけることができます。 この概要は、大規模なデータセットを操作する場合、またはデータ クリーニングおよび前処理タスクを実行する場合に役立ちます。
# Info
stress.info()
コードtress.isnull().sum() を使用して、「stress」データセット内の null 値をチェックし、各列の null 値の合計を計算します。
# Checking null values
stress.isnull().sum()

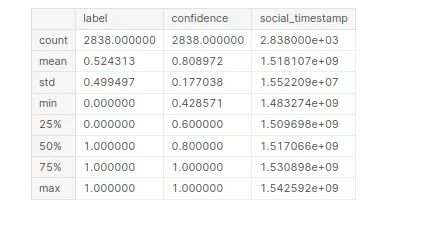
「ストレス」データセットに関する統計情報を生成します。 このコードをコンパイルすると、データセット内の各数値列の記述統計の概要が得られます。
# Statistical Information
stress.describe()
探索的データ分析(EDA)
探索的データ分析 (EDA) は、データセットを理解して分析するための重要なステップです。 データ内の主な特性、パターン、関係を視覚的に探索して要約することが含まれます。
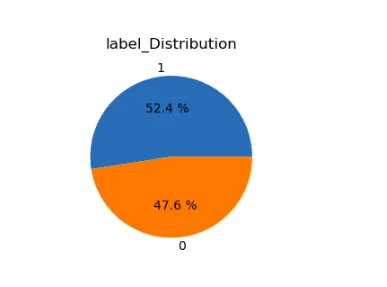
lst=['subreddit','label']
plt.figure(figsize=(15,12))
for i in range(len(lst)): plt.subplot(1,2,i+1) a=stress[lst[i]].value_counts() lbl=a.index plt.title(lst[i]+'_Distribution') plt.pie(x=a,labels=lbl,autopct="%.1f %%") plt.show()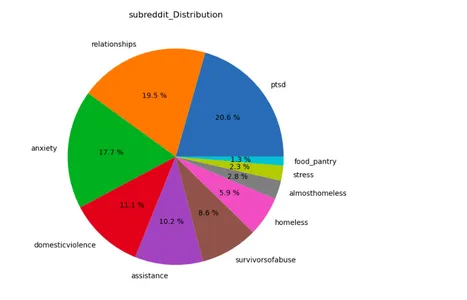
Matplotlib ライブラリと Seaborn ライブラリは、「応力」データセットのカウント プロットを作成します。 さまざまなサブレディットにわたるストレス インスタンスの数を視覚化し、ストレス ラベルをさまざまな色で区別します。
plt.figure(figsize=(20,12))
plt.title('Subreddit wise stress count')
plt.xlabel('Subreddit')
sns.countplot(data=stress,x='subreddit',hue='label',palette='gist_heat')
plt.show()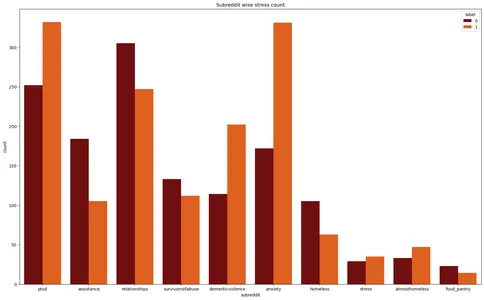
テキストの前処理
テキストの前処理とは、生のテキスト データを、分析またはモデリング タスクに適した、よりクリーンで構造化された形式に変換するプロセスを指します。 特に、ノイズを除去し、テキストを正規化し、関連する特徴を抽出する一連の手順が含まれます。 ここでは、このテキスト処理に関連するすべてのライブラリを追加しました。
# Regular Expression
import re # Handling string
import string # NLP tool
import spacy nlp=spacy.load('en_core_web_sm')
from spacy.lang.en.stop_words import STOP_WORDS # Importing Natural Language Tool Kit for NLP operations
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('omw-1.4') from nltk.stem import WordNetLemmatizer from wordcloud import WordCloud, STOPWORDS
from nltk.corpus import stopwords
from collections import Counter
テキストの前処理で使用される一般的な手法には次のようなものがあります。
テキストクリーニング
- 特殊文字の削除: テキストの意味に寄与しない句読点、記号、または英数字以外の文字を削除します。
- 数値の削除: 分析に関係のない数値を削除します。
- 小文字: テキストの一致と分析の一貫性を確保するために、すべてのテキストを小文字に変換します。
- ストップワードの削除: 「a」、「the」、「is」など、あまり情報を含まない一般的な単語を削除します。
トークン化
- テキストを単語またはトークンに分割する: テキストを個々の単語またはトークンに分割して、さらなる分析の準備をします。 研究者は、ホワイトスペースや、NLTK や spaCy などのライブラリを利用するなど、より高度なトークン化技術を採用することでこれを実現できます。
正規化
- 見出し語化: 単語を基本形式または辞書形式 (見出し語) に変換します。 たとえば、「走る」と「らん」を「走る」に変換します。
- ステミング: 接頭辞または接尾辞を削除して、単語を基本形式に戻します。 たとえば、「走る」と「らん」を「走る」に変換します。
- 発音記号の削除: 文字からアクセント記号またはその他の発音記号を削除します。
#defining function for preprocessing
def preprocess(text,remove_digits=True): text = re.sub('W+',' ', text) text = re.sub('s+',' ', text) text = re.sub("(?<!w)d+", "", text) text = re.sub("-(?!w)|(?<!w)-", "", text) text=text.lower() nopunc=[char for char in text if char not in string.punctuation] nopunc=''.join(nopunc) nopunc=' '.join([word for word in nopunc.split() if word.lower() not in stopwords.words('english')]) return nopunc
# Defining a function for lemitization
def lemmatize(words): words=nlp(words) lemmas = [] for word in words: lemmas.append(word.lemma_) return lemmas #converting them into string
def listtostring(s): str1=' ' return (str1.join(s)) def clean_text(input): word=preprocess(input) lemmas=lemmatize(word) return listtostring(lemmas)# Creating a feature to store clean texts
stress['clean_text']=stress['text'].apply(clean_text)
stress.head()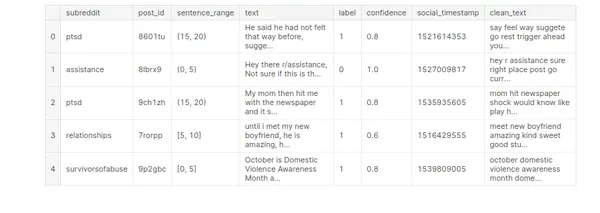
機械学習モデルの構築
機械学習モデルの構築は、パターンを学習し、データから予測や意思決定を行うことができる数学的表現またはモデルを作成するプロセスです。 これには、ラベル付きデータセットを使用してモデルをトレーニングし、そのモデルを使用して新しいまだ見たことのないデータを予測することが含まれます。
利用可能なデータから関連するフィーチャを選択または作成します。 特徴量エンジニアリングの目的は、モデルがパターンを効果的に学習するのに役立つ、生のデータから意味のある情報を抽出することです。
# Vectorization
from sklearn.feature_extraction.text import TfidfVectorizer # Model Building
from sklearn.model_selection import GridSearchCV,StratifiedKFold, KFold,train_test_split,cross_val_score,cross_val_predict
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn import preprocessing
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier,RandomForestClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier #Model Evaluation
from sklearn.metrics import confusion_matrix,classification_report, accuracy_score,f1_score,precision_score
from sklearn.pipeline import Pipeline # Time
from time import time# Defining target & feature for ML model building
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)問題の性質とデータの特性に基づいて、適切な機械学習アルゴリズムまたはモデル アーキテクチャを選択します。 デシジョン ツリー、サポート ベクター マシン、ニューラル ネットワークなどのモデルが異なれば、それぞれ異なる長所と短所があります。
ラベル付きデータを使用して、選択したモデルをトレーニングします。 このステップには、トレーニング データをモデルに供給し、モデルが特徴とターゲット変数の間のパターンと関係を学習できるようにすることが含まれます。
# Self-defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Logistic regression def model_lr_tf(x_train, x_test, y_train, y_test): global acc_lr_tf,f1_lr_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = LogisticRegression() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_lr_tf=accuracy_score(y_test,y_pred) f1_lr_tf=f1_score(y_test,y_pred,average='weighted') print('Time :',time()-t0) print('Accuracy: ',acc_lr_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_lr_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by MultinomialNB def model_nb_tf(x_train, x_test, y_train, y_test): global acc_nb_tf,f1_nb_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = MultinomialNB() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_nb_tf=accuracy_score(y_test,y_pred) f1_nb_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_nb_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_nb_tf # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Decision Tree
def model_dt_tf(x_train, x_test, y_train, y_test): global acc_dt_tf,f1_dt_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = DecisionTreeClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_dt_tf=accuracy_score(y_test,y_pred) f1_dt_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_dt_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_dt_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by KNN def model_knn_tf(x_train, x_test, y_train, y_test): global acc_knn_tf,f1_knn_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = KNeighborsClassifier() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_knn_tf=accuracy_score(y_test,y_pred) f1_knn_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_knn_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Random Forest def model_rf_tf(x_train, x_test, y_train, y_test): global acc_rf_tf,f1_rf_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = RandomForestClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_rf_tf=accuracy_score(y_test,y_pred) f1_rf_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_rf_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Adaptive Boosting def model_ab_tf(x_train, x_test, y_train, y_test): global acc_ab_tf,f1_ab_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = AdaBoostClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_ab_tf=accuracy_score(y_test,y_pred) f1_ab_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_ab_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) モデル評価
モデルの評価は、トレーニングされたモデルのパフォーマンスと有効性を評価するための機械学習における重要なステップです。 これには、複数のモデルが目に見えないデータに対してどの程度一般化されているか、およびそれが望ましい目的を満たしているかどうかを測定することが含まれます。 トレーニング済みモデルのパフォーマンスをテスト データで評価します。 精度、精度、再現率、F1 スコアなどの評価指標を計算して、ストレス検出におけるモデルの有効性を評価します。 モデルを評価すると、モデルの長所、短所、および意図したタスクへの適合性についての洞察が得られます。
# Evaluating Models print('********************Logistic Regression*********************')
print('n')
model_lr_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
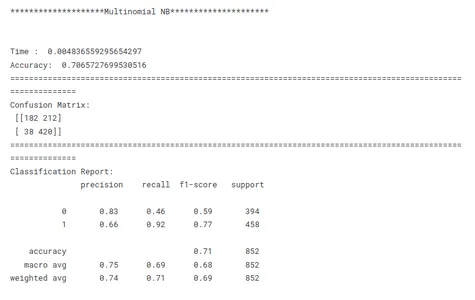
print('********************Multinomial NB*********************')
print('n')
model_nb_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
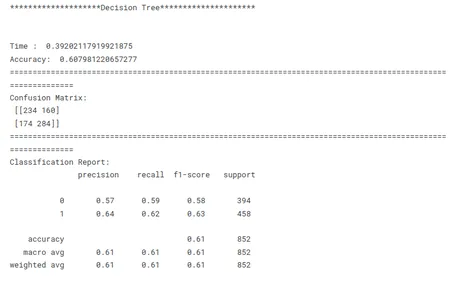
print('********************Decision Tree*********************')
print('n')
model_dt_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
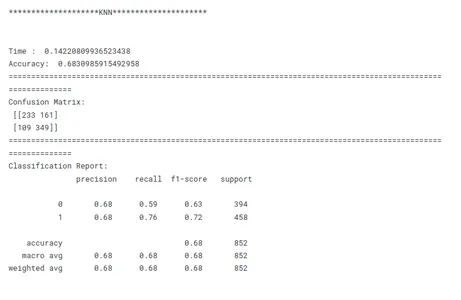
print('********************KNN*********************')
print('n')
model_knn_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
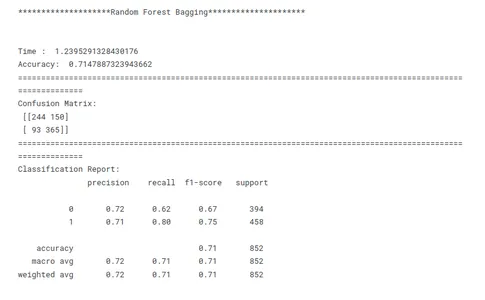
print('********************Random Forest Bagging*********************')
print('n')
model_rf_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
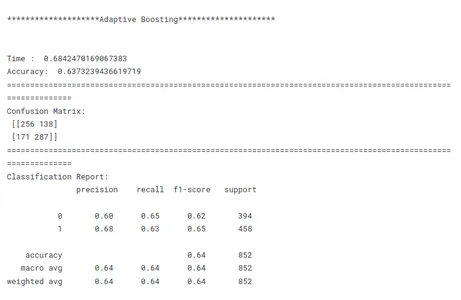
print('********************Adaptive Boosting*********************')
print('n')
model_ab_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')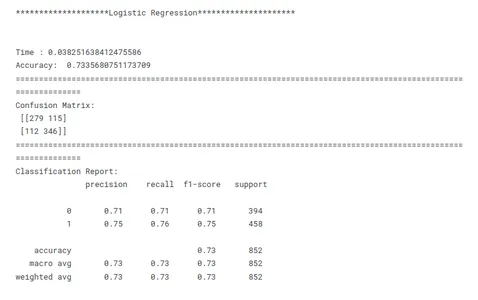
モデルの性能比較
これは、特定のタスクに対して最もパフォーマンスの高いモデルを特定するための機械学習における重要なステップです。 モデルを比較するときは、明確な目的を念頭に置くことが重要です。 精度の最大化、速度の最適化、または解釈可能性の優先のいずれであっても、評価指標と手法は特定の目的に沿ったものである必要があります。
モデルのパフォーマンスを比較するには、一貫性が重要です。 すべてのモデルにわたって一貫した評価指標を使用することで、公平で有意義な比較が保証されます。 すべてのモデルにわたって一貫してデータをトレーニング、検証、テスト セットに分割することも重要です。 モデルが同じデータ サブセットで評価されるようにすることで、研究者はパフォーマンスを公平に比較できるようになります。
これらの上記の要素を考慮すると、研究者は包括的かつ公正なモデルのパフォーマンス比較を行うことができ、それが当面の特定の問題に対するモデルの選択に関する情報に基づいた決定につながります。
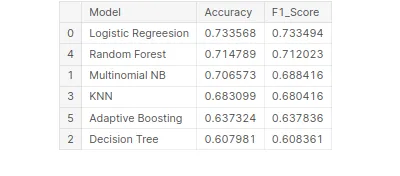
# Creating tabular format for better comparison
tbl=pd.DataFrame()
tbl['Model']=pd.Series(['Logistic Regreesion','Multinomial NB', 'Decision Tree','KNN','Random Forest','Adaptive Boosting'])
tbl['Accuracy']=pd.Series([acc_lr_tf,acc_nb_tf,acc_dt_tf,acc_knn_tf, acc_rf_tf,acc_ab_tf])
tbl['F1_Score']=pd.Series([f1_lr_tf,f1_nb_tf,f1_dt_tf,f1_knn_tf, f1_rf_tf,f1_ab_tf])
tbl.set_index('Model')
# Best model on the basis of F1 Score
tbl.sort_values('F1_Score',ascending=False)
過剰適合を避けるための相互検証
相互検証は、機械学習モデルをトレーニングする際の過学習を回避するのに役立つ貴重な手法です。 トレーニングとテストにデータの複数のサブセットを使用することで、モデルのパフォーマンスの堅牢な評価を提供します。 目に見えないデータに対するパフォーマンスを推定することで、モデルの汎化能力を評価するのに役立ちます。
# Using cross validation method to avoid overfitting
import statistics as st
vector = TfidfVectorizer() x_train_v = vector.fit_transform(x_train)
x_test_v = vector.transform(x_test) # Model building
lr =LogisticRegression()
mnb=MultinomialNB()
dct=DecisionTreeClassifier(random_state=1)
knn=KNeighborsClassifier()
rf=RandomForestClassifier(random_state=1)
ab=AdaBoostClassifier(random_state=1)
m =[lr,mnb,dct,knn,rf,ab]
model_name=['Logistic R','MultiNB','DecTRee','KNN','R forest','Ada Boost'] results, mean_results, p, f1_test=list(),list(),list(),list() #Model fitting,cross-validating and evaluating performance def algor(model): print('n',i) pipe=Pipeline([('model',model)]) pipe.fit(x_train_v,y_train) cv=StratifiedKFold(n_splits=5) n_scores=cross_val_score(pipe,x_train_v,y_train,scoring='f1_weighted', cv=cv,n_jobs=-1,error_score='raise') results.append(n_scores) mean_results.append(st.mean(n_scores)) print('f1-Score(train): mean= (%.3f), min=(%.3f)) ,max= (%.3f), stdev= (%.3f)'%(st.mean(n_scores), min(n_scores), max(n_scores),np.std(n_scores))) y_pred=cross_val_predict(model,x_train_v,y_train,cv=cv) p.append(y_pred) f1=f1_score(y_train,y_pred, average = 'weighted') f1_test.append(f1) print('f1-Score(test): %.4f'%(f1)) for i in m: algor(i) # Model comparison By Visualizing fig=plt.subplots(figsize=(20,15))
plt.title('MODEL EVALUATION BY CROSS VALIDATION METHOD')
plt.xlabel('MODELS')
plt.ylabel('F1 Score')
plt.boxplot(results,labels=model_name,showmeans=True)
plt.show() 
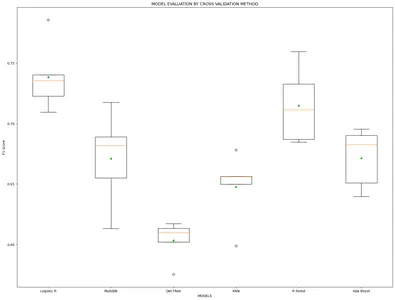
モデルの F1 スコアはどちらの方法でも非常に似ています。 そこで現在、Leave One Out メソッドを適用して、最もパフォーマンスの高いモデルを構築しています。
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1) vector = TfidfVectorizer()
x_train = vector.fit_transform(x_train)
x_test = vector.transform(x_test)
model_lr_tf=LogisticRegression() model_lr_tf.fit(x_train,y_train)
y_pred=model_lr_tf.predict(x_test)
# Model Evaluation conf=confusion_matrix(y_test,y_pred)
acc_lr=accuracy_score(y_test,y_pred)
f1_lr=f1_score(y_test,y_pred,average='weighted') print('Accuracy: ',acc_lr)
print('F1 Score: ',f1_lr)
print(10*'===========')
print('Confusion Matrix: n',conf)
print(10*'===========')
print('Classification Report: n',classification_report(y_test,y_pred))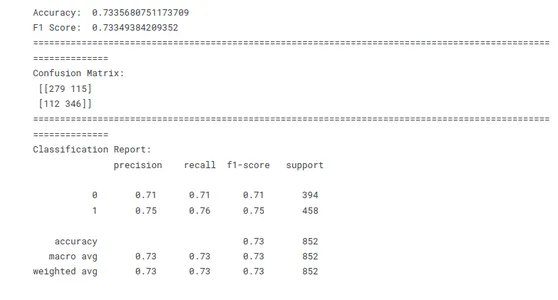
強調された単語と強調されていない単語の単語雲
データセットには、ストレスまたは非ストレスとしてラベル付けされたテキスト メッセージまたはドキュメントが含まれています。 コードは XNUMX つのラベルをループして、WordCloud ライブラリを使用して各ラベルのワード クラウドを作成し、ワード クラウドの視覚化を表示します。 各単語クラウドは、それぞれのカテゴリで最も一般的に使用される単語を表し、単語が大きいほど頻度が高いことを示します。 カラー マップ (「冬」、「秋」、「マグマ」、「ウィリディス」、「プラズマ」) の選択によって、ワード クラウドの配色が決まります。 結果として得られる視覚化により、強調されたメッセージまたは文書または強調されていないメッセージまたは文書に関連する最も頻繁に使用される単語が簡潔に表現されます。
以下は、ストレス検出に一般的に関連付けられるストレスのある単語とストレスのない単語を表すワード クラウドです。
for label, cmap in zip([0,1], ['winter', 'autumn', 'magma', 'viridis', 'plasma']): text = stress.query('label == @label')['text'].str.cat(sep=' ') plt.figure(figsize=(12, 9)) wc = WordCloud(width=1000, height=600, background_color="#f8f8f8", colormap=cmap) wc.generate_from_text(text) plt.imshow(wc) plt.axis("off") plt.title(f"Words Commonly Used in ${label}$ Messages", size=20) plt.show()

予測
新しい入力データは前処理され、モデルの期待に一致するように特徴が抽出されます。 次に、予測関数を使用して、抽出された特徴に基づいて予測を生成します。 最後に、予測は印刷されるか、必要に応じてさらなる分析や意思決定に利用されます。
data=["""I don't have the ability to cope with it anymore. I'm trying, but a lot of things are triggering me, and I'm shutting down at work, just finding the place I feel safest, and staying there for an hour or two until I feel like I can do something again. I'm tired of watching my back, tired of traveling to places I don't feel safe, tired of reliving that moment, tired of being triggered, tired of the stress, tired of anxiety and knots in my stomach, tired of irrational thought when triggered, tired of irrational paranoia. I'm exhausted and need a break, but know it won't be enough until I journey the long road through therapy. I'm not suicidal at all, just wishing this pain and misery would end, to have my life back again."""] data=vector.transform(data)
model_lr_tf.predict(data)
data=["""In case this is the first time you're reading this post... We are looking for people who are willing to complete some online questionnaires about employment and well-being which we hope will help us to improve services for assisting people with mental health difficulties to obtain and retain employment. We are developing an employment questionnaire for people with personality disorders; however we are looking for people from all backgrounds to complete it. That means you do not need to have a diagnosis of personality disorder – you just need to have an interest in completing the online questionnaires. The questionnaires will only take about 10 minutes to complete online. For your participation, we’ll donate £1 on your behalf to a mental health charity (Young Minds: Child & Adolescent Mental Health, Mental Health Foundation, or Rethink)"""] data=vector.transform(data)
model_lr_tf.predict(data)
まとめ
機械学習技術をストレスレベルの予測に応用することで、精神的健康に関する個人に合わせた洞察が得られます。 機械学習モデルは、数値測定値 (血圧、心拍数) やカテゴリ特性 (性別、職業など) などのさまざまな要因を分析することで、パターンを学習し、個人のストレス レベルを予測できます。 機械学習は、ストレスレベルを正確に検出および監視する機能により、精神的健康を管理および強化するための予防的な戦略と介入の開発に貢献します。
私たちは、ストレス予測における機械学習の使用から得られる洞察と、この重要な問題に対処するアプローチに革命をもたらす可能性を探りました。
- 正確な予測: 機械学習アルゴリズムは、膨大な量の履歴データを分析してストレスの発生を正確に予測し、貴重な洞察と予測を提供します。
- 早期発見:機械学習により危険な兆候を早期に検出できるため、脆弱な領域での予防的な対策とタイムリーなサポートが可能になります。
- 強化された計画とリソース割り当て:機械学習により、街路のホットスポットと強度の予測が可能になり、救急サービスや医療施設などのリソースの割り当てが最適化されます。
- 治安の改善: 機械学習の予測を通じて発行されるタイムリーなアラートと警告により、個人は必要な予防策を講じることができ、ストリートの影響が軽減され、公共の安全が強化されます。
結論として、このストレス予測分析は、機械学習を使用したストレス レベルとその予測に関する貴重な洞察を提供します。 その結果を利用してストレス管理のためのツールや介入を開発し、全体的な幸福と生活の質の向上を促進します。
よくある質問
A:1。 客観的な評価:ストレスレベルを評価するための客観的かつデータ主導のアプローチを提供し、主観的な評価で生じる可能性のある潜在的なバイアスを排除します。
2. スケーラビリティ: 機械学習アルゴリズムは、大量のテキスト データを効率的に処理できるため、幅広いテキスト表現を分析できるように拡張可能です。
3. リアルタイム監視:ストレス検出を自動化することで、ストレスレベルをリアルタイムでモニタリングできるようになり、タイムリーな介入やサポートが可能になります。
4. 洞察と調査:ストレスに関連する洞察と傾向を明らかにし、ストレスの引き金、影響、潜在的な介入の理解に貢献します。
A:1。 ソーシャルメディアの投稿: Twitter、Facebook、または個人が自分の考えや感情を表現するオンライン フォーラムなどのプラットフォームからのテキスト コンテンツ。
2. チャットログ: メッセージング アプリ、オンライン サポート システム、またはメンタルヘルス チャットボットからの会話データ。
3. オンライン調査またはアンケート: ストレスや精神的健康に関する質問に対するテキストでの回答。
4. 電子健康記録 (Electronic Health Records): ストレス関連の経験に関する関連情報を含む臨床メモまたは患者の物語。
A: 1. ストレスの文章表現は個人によって大きく異なるため、関連する指標やパターンをすべて把握することが困難になります。
2. 同じテキストでも文脈や個人によって読み方が異なるため、ストレスの検出には文脈の理解が重要です。
3. 機械学習モデルをトレーニングするためのラベル付きデータの取得には時間とリソースが大量に消費されるため、専門家の意見や主観的な判断が必要になります。
4. ストレスに関連するテキスト データを扱う場合、データのプライバシー、機密保持、メンタルヘルスの機密情報の倫理的な取り扱いを確保することが最も重要です。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/06/machine-learning-unlocks-insights-for-stress-detection/

