概要
統計モデルは、複雑なデータの使用と予測に重要です。 パターンと関係を確認し、将来の値について正確な予測を行うことができます。 統計モデリングの実行可能な領域は、時系列分析です。
時系列データは時間の経過とともに収集され、金融、経済、テクノロジーなどのさまざまな分野で見つけることができます。 統計モデル この種のデータをよりよく理解し、有意義な洞察を生成し、重要な意思決定に役立つ予測を行うために使用できます。 これらのモデルは、データの動作を数学的に表現したものであり、将来の値を予測するために使用できます。 単純な自己回帰モデルからより複雑な統合移動平均モデルまで、このモデルは時系列データを分析および予測するためのさまざまなオプションを提供します。
この記事では、時系列分析で一般的に使用されるさまざまな統計モデル、それらの長所と短所、およびそれらを実際のアプリケーションに実装する方法について説明します。 それらについて議論する前に、誰もが時系列分析とは何かを知っておく必要があります。
学習目標
- 移動平均値とは何かを理解する。
- いくつかを使用してこのモデルを実装する方法を学びます Pythonライブラリ.
- 時系列分析に使用されるさまざまな統計モデルに精通していること。
- 時系列分析の長所と短所を理解する。
この記事は、の一部として公開されました データサイエンスブログソン.
コンテンツの表
- 時系列分析とは
- 自己回帰モデルの基礎
- 移動平均モデルについて
- 自己回帰統合移動平均モデル: 概要
- ベクトル自己回帰
- 階層時系列モデル: はじめに
- 時系列の統計モデルの変動の調査
- 時系列に統計的方法を使用する利点と欠点
- まとめ
時系列分析とは
時系列分析は、時間の経過とともに収集されたデータ ポイントの調査です。 それは、データのパターン、傾向、関係を特定することです。 過去のデータに基づいて将来の価値を予測することを目的としており、長期にわたって収集されたデータから有意義な洞察と予測を得るための強力なツールです。
時系列分析では、毎日の株価や月間売上高など、継続的に収集されたデータ ポイントを調べます。 このデータを分析すると、将来の価値を予測するのに役立つパターン、傾向、および関係を特定できます。 統計モデルは、時系列分析に欠かせないツールの XNUMX つです。 これらのモデルは、時系列の動作を数学的に表現したものであり、将来の値を予測するために使用できます。 時系列分析用に開発されたさまざまなタイプの統計モデルがあります。
自己回帰モデル、移動平均モデル、移動平均モデルを統合した自己回帰モデル、ベクトル自己回帰モデル、統計モデルの変動、階層的時系列モデルには、それぞれ長所と短所があり、時系列の適切な理論と目的を選択します。あなたの分析。
ソース – Databrio.com
自己回帰モデルの基礎
自己回帰 (AR) モデルは、人気があり影響力のある時系列分析および予測ツールです。 データを生成する基本的なプロセスは、過去の観察結果の線形結合であると想定しています。 このモデルは、時系列を、将来の傾向を予測するために一般的に使用される過去の値の線形結合として説明します。 これは、時系列の現在の値が以前の値に依存しているという考えに基づいています。
AR モデルはモデリングに有益です 一変量時系列 過去の観測に基づいて将来の値を予測することを目的としています。 モデルの次数 (p) は、現在の値を推定するために使用される過去の観測の数によって定義されます。 モデルは履歴データでトレーニングされ、係数は予測値と実際の値の差を最小化することによって決定されます。 その後、モデルは時系列データの将来の値を予測できます。
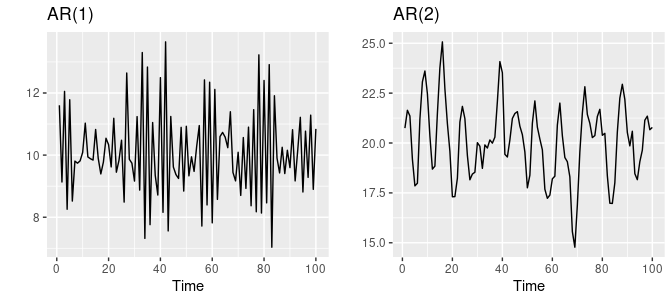
ソース – otexts.com
AR モデルの主な利点は、過去の値を計算することで時系列のダイナミクスを理解できることです。 これは、傾向とパターンを示す時系列に特に役立ちます。
ただし、AR モデルにはいくつかの制限があります。 制限の XNUMX つは、現在の値と過去の値の間の線形性の仮定です。 これは必ずしもそうではありません。 また、正確な予測を行うには大量のデータが必要です。
Python で AR モデルを操作する方法を示すコードを次に示します。 R は統計分析に広く使用されているため、R で行うことをお勧めしますが、ここでは誰もが慣れ親しんでいる Python を使用しました。
from statsmodels.tsa.ar_model import AR import numpy as np #データを生成 data = np.random.randn(100) #モデルに適合 model = AR(data) model_fit = model.fit() #予測を行う yhat = model_fit.predict( len(データ), len(データ)) print(yhat)
移動平均モデルについて
移動平均 (MA) モデルは、時系列分析で一般的に使用される統計モデルです。 このモデルは、過去の過ちが予測の時系列の将来の値に影響を与えるという考えに基づいています。 過去の値を使用して予測を行う自己回帰 (AR) モデルとは異なり、移動平均モデルは過去の誤差または残差を使用します。
モデルは履歴データでトレーニングされ、係数は予測値と実際の値の差を最小化することによって決定されます。 その後、モデルは時系列データの将来の値を予測できます。
これは、不規則または予期しないイベントの影響を特定して評価するのに役立ちます。 移動平均モデルでは、時系列の現在の値は、過去の誤差または残差の線形結合としてモデル化されます。 モデルの次数 (q) は、現在の誤差項を予測するために使用される過去の誤差の数によって定義されます。
また、MA モデルは多くの場合、自己回帰 (AR) モデルと組み合わされて、ARIMA (自己回帰統合移動平均) と呼ばれるより強力な予測ツールを作成することにも注意してください。

ソース – otexts.com
MA モデルの主な利点の XNUMX つは、予期しないイベントやエラーの影響を経時的に理解できることです。
不規則またはランダムなイベントの影響を特定して評価します。 ただし、線形性の仮定と大量のデータの必要性など、いくつかの制限があります。
これが単純な Python コードです。
from statsmodels.tsa.arima_model import ARMAimport numpy as np#generate datadata = np.random.randn(100)#fit modelmodel = ARMA(data, order=(0, 1))model_fit = model.fit()#make predictionyhat = model_fit.predict(len(data), len(data))print(yhat)
自己回帰統合移動平均モデル: 概要
自己回帰統合移動平均モデルは、時系列分析で一般的に使用される統計モデルです。 ARIMA モデルは、時系列データを分析および予測するための一般的な方法です。 これらは、季節性、傾向、ノイズなどのパターンを示す時系列データのモデル化に役立ちます。
ARIMA モデルは、自己回帰、統合、移動平均の XNUMX つのコンポーネントを組み合わせたものです。 自己回帰コンポーネントは、観測値と多数のラグ観測値の間の依存関係をモデル化します。 このコンポーネントは、時系列データの永続性をモデル化するために使用されます。
統合コンポーネントは、オブザベーションと連続するオブザベーション間の差異との間の依存関係をモデル化します。 このコンポーネントは、時系列データの傾向をモデル化するために使用されます。 移動平均コンポーネントは、観測値と移動平均モデルからの残差誤差との間の依存関係をモデル化します。 これらのコンポーネントは、時系列データのランダムな変動またはノイズをモデル化します。
ARIMA モデルは、時系列データを分析するための強力なツールであり、データの基礎となる構造に関する貴重な洞察を提供できます。

の主な利点 ARIMA モデル トレンドや旬の食材を時系列で捉える力です。 非定常時系列の処理に役立ち、標準的な統計手法と併用して予測精度を向上させることができます。
ただし、線形性の仮定や必要な大量のデータなどの制限があります。
以下は、ARIMA モデルを使用するための単純な Python コードです。
from statsmodels.tsa.arima_model import ARIMA
import numpy as np
#generate data
data = np.random.randn(100)
#fit model
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit()
#make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
ベクトル自己回帰
ベクトル自己回帰 (VAR) は、複数の期間間の動的な関係を調査および分析するための統計モデルです。 自己回帰 (AR) モデルを拡張し、さまざまな従属変数を同時にモデル化できます。 対照的に、VAR は、複数の変数とそれらのラグ値の間の依存関係をモデル化します。
VAR モデルでは、各変数は、すべての変数の過去の値と確率誤差項の線形結合としてモデル化されます。 モデルは最小二乗法を使用して推定され、パラメーターは通常、最尤推定を使用して推定されます。 VAR モデルには、説明変数とも呼ばれる外生変数を含めることができます。これは、変数が自己回帰変数としてモデル化されていないためです。
モデルには、この変数が方程式の追加項として含まれていました。 行列乗算は、VAR モデルの変数間の線形関係を表すために使用されます。 モデルの係数は行列として表され、変数の以前の値にこの行列を掛けて、予測値を取得します。 モデルの次数が増えると、モデルの複雑さも増し、より正確な予測が可能になります。
VAR モデルの主な利点の XNUMX つは、複数の時系列間の動的な相関関係を把握できることです。 ある変数の変化が他の変数にどのように影響するかを理解するのに役立ち、さまざまな変数を同時に予測するためにも使用できます。
それにもかかわらず、計算コストが高く、線形性を前提とし、大量のデータが必要になるなど、いくつかの制限があります。
階層時系列モデル: はじめに
階層型時系列モデルは、階層構造に配置された時系列データを分析および予測するために使用される統計モデルです。 階層構造とは、複数レベルの集約を持つデータ セットを指します。
これらは、地域、部門、開発など、階層的な時系列モデルでさまざまなレベルに分割されます。 次に、個別の時系列モデルが各データセットに適合しました。 これらのモデル パラメーターを組み合わせて、データ セット全体の予測を作成します。
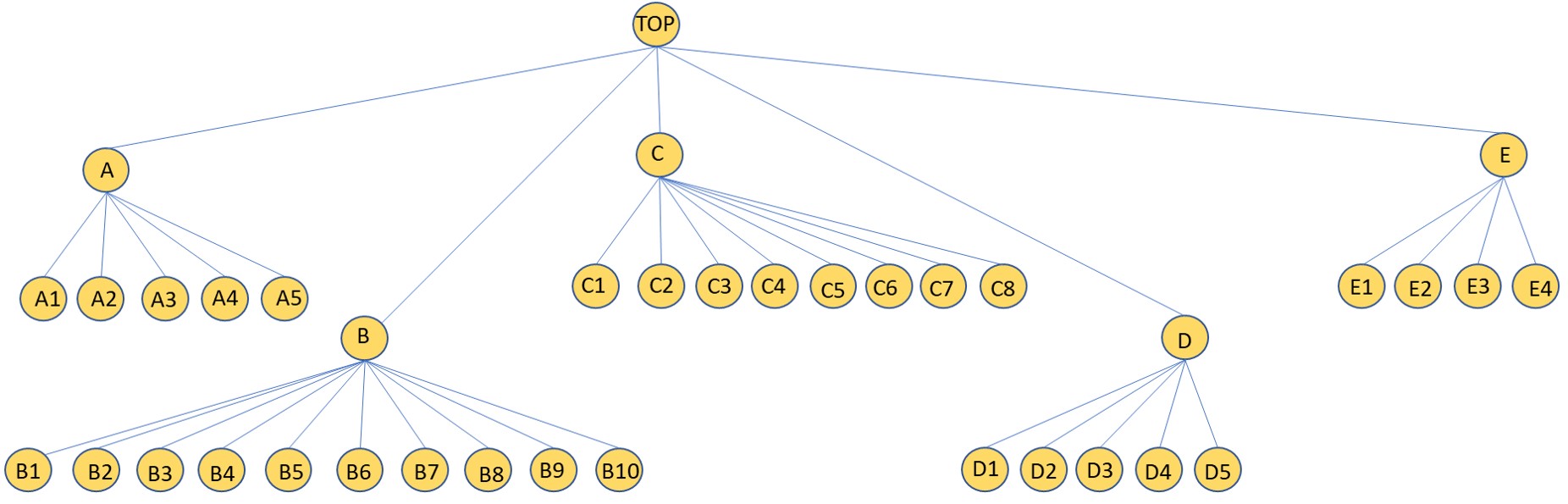
ソース – stackoverflow.com
階層型時系列モデルの主な利点の XNUMX つは、複雑なデータ構造を処理し、グループ間の違いを説明できることです。 また、さまざまな階層レベルで傾向とパターンの変化を検出して予測するのにも役立ちます。 これは、小売売上高の予測、予算編成、およびその他の計画活動など、ビジネスおよび経済学で広く使用されています。
レベルの数または各レベルのユニットの数が増えると、より複雑になり、計算コストが高くなる可能性があります。
時系列の統計モデルの変動の調査
時系列データの分析と予測に使用できる統計モデルのバリエーションはいくつかありますが、最も重要なものをいくつか挙げました。 彼らです
指数平滑法モデル: これらのモデルは、傾向や季節性を示す時系列データの予測に使用されます。 それらは、最近の観察結果を古いものよりも重く重み付けすることに基づいています。
状態空間モデル: これらのモデルは、観測されていない変数を持つ動的システムのモデル化に使用されます。 これらは、複雑なパターンを持つ時系列データをモデル化する場合に特に役立ちます。
GARCHモデル: これらのモデルは、時間の経過とともに変化するボラティリティを持つ時系列データのモデル化に使用されます。 これらは、株式のリターンやその他の金融時系列データをモデル化するために金融で一般的に使用されます。
構造時系列モデル: このモデルは、基礎となる構造と確率的コンポーネントを使用して時系列をモデル化するために使用されます。 それらは、時系列の根底にある因果関係をモデル化するために使用されます。
機械学習モデル: これらのモデルは、ニューラル ネットワーク、デシジョン ツリー、サポート ベクター マシンなどの手法を使用して時系列データを予測するために使用されます。 これらは、複雑なパターンと非線形の関係を持つ時系列データをモデル化するのに特に役立ちます。
時系列分析に統計的手法を使用する利点
説明: 多くの統計手法は単純な数式に基づいており、理解しやすく説明しやすいものです。 これにより、他の人が結果を解釈しやすくなり、意思決定に使用しやすくなります。
堅牢性: 統計手法は、データ内の外れ値やその他の形式のノイズに対して堅牢になるように設計できます。これは、多くのアプリケーションで重要になる可能性があります。 効率: 多くの統計手法は計算効率が高く、大規模で複雑な時系列データ セットの分析を可能にします。
信頼性の向上: 統計的手法は、通常、外れ値やその他のデータ タイプに対してより信頼性が高く、実際のデータでの使用に適しています。
予測分析: 統計手法を使用して、時系列の将来の値を予測できます。 これは、意思決定、予算編成、およびその他の計画活動に役立ちます。
完全: 統計手法は長年にわたって開発され、使用されてきました。また、豊富な知識とソフトウェアを利用して、私たちの仕事を容易にしています。 時系列分析の統計的手法には多くの利点がありますが、考慮すべき潜在的な欠点もいくつかあります。
時系列分析の統計的手法には多くの利点がありますが、考慮すべき潜在的な欠点もいくつかあります。
時系列分析に統計的方法を使用することの欠点
仮定: 多くの統計手法では、定常性、線形性、正規性など、実際には満たすことができない重要なデータ プロパティに関する仮定が行われます。
複雑: VAR や SSM などの一部の統計手法は非常に複雑であり、それらを適用して解釈するには高度な専門知識が必要です。
データ要件: 一部の統計手法では、正確な結果を得るために大量のデータが必要になります。これは、データが限られている場合や品質が低い場合に問題になる可能性があります。
データ品質: 統計手法は高品質のデータに依存しており、低品質のデータは不正確な結果につながる可能性があります。
オーバーフィット: 一部のモデルはデータに適合しすぎて、新しいデータにうまく一般化できない場合があります。
限られた精度: 統計手法は過去の観測に依存しており、過去のデータに含まれていない将来のイベントを把握することはできません。
まとめ
統計手法は、時系列データを分析および予測するための強力なツールです。 それらは、データの基礎となる構造に対する貴重な洞察を提供し、将来の価値について予測を行うことができます。 利用可能な統計モデルにはさまざまな種類があり、それぞれに長所と短所があり、さまざまな種類の時系列データに使用できます。
ただし、選択したモデルの前提条件と要件を認識することが重要です。 さらに、統計手法を適用する前に、時系列データの特性を慎重に検討することが不可欠です。 さらに、統計的手法が時系列分析への唯一のアプローチではないことに注意することが重要です。 他の方法やモデルも検討する価値があります。
さらに、統計的手法を使用して得られた結果は常に批判的に評価する必要があることを覚えておくことが重要です。 ドメイン知識は、結果を解釈して理解するために使用する必要があります。
主要な取り組み
- 時系列分析は、時間の経過に伴うデータのパターンと傾向を理解し、予測するための強力なツールです。
- 自己回帰 (AR)、移動平均 (MA)、自己回帰統合移動平均 (ARIMA)、ベクトル自己回帰 (VAR)、階層時系列モデルなどの統計手法は、時系列データの分析に広く使用されています。
- これらの方法にはそれぞれ長所と短所があります。 どの方法を選択するかは、時系列データの特定の特性と対処する研究課題によって異なります。
- 単一のモデルがすべての時系列データに適しているわけではないことを覚えておくことが重要です。 したがって、正確な予測を行うには、モデルと手法の組み合わせが必要になる場合があります。
- 正確な予測と結論を得るには、モデルの根底にある仮定と制限を完全に理解することが重要です。
- これらのモデルは、さまざまな Python、R、およびその他のプログラミング言語ライブラリを使用して実装できます。
- 要約すると、時系列分析の統計手法は、時系列データを理解して予測するための柔軟で強力なツールを提供します。
- ただし、その制限を認識し、他の方法やドメイン知識と組み合わせて使用することが重要です。
上記以外のものを共有したいですか? 考え? 以下にコメントしてください。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/01/learning-time-series-analysis-modern-statistical-models/

