今日、 アマゾンセージメーカー 大規模モデル推論 (LMI) 深層学習コンテナ (DLC) の新しいバージョン (0.25.0) を起動し、次のサポートを追加します。 NVIDIA の TensorRT-LLM ライブラリ。 これらのアップグレードにより、最先端のツールに簡単にアクセスして SageMaker 上の大規模言語モデル (LLM) を最適化し、価格パフォーマンスの利点を実現できます。 Amazon SageMaker LMI TensorRT-LLM DLC は、Llama33-60B、Falcon-2B、CodeLlama-70B モデルにおいて、以前のバージョンと比較してレイテンシーを平均 40% 削減し、スループットを平均 34% 向上させました。
LLM は、幅広いアプリケーションにわたって前例のないほど人気が高まっています。 ただし、これらのモデルは多くの場合、単一のアクセラレータまたは GPU デバイスに収まらないほど大きすぎるため、低レイテンシーの推論とスケーリングを実現することが困難になります。 SageMaker は、利用可能なリソースを最大限に活用し、パフォーマンスを向上させるのに役立つ LMI DLC を提供します。 最新の LMI DLC は、スループットを向上させる推論リクエストの継続的なバッチ処理サポート、レイテンシーを改善する効率的な推論集合操作、Pages Attendance V2 (シーケンス長が長いワークロードのパフォーマンスを向上させる)、および NVIDIA の最新の TensorRT-LLM ライブラリを提供して、パフォーマンスを最大化します。 GPU でのパフォーマンス。 LMI DLC は、モデル ID とオプションのモデル パラメーターのみを必要とするだけで TensorRT-LLM でのコンパイルを簡素化するローコード インターフェイスを提供します。 TensorRT-LLM 最適化モデルの構築とモデル リポジトリの作成に必要なすべての重労働は、LMI DLC によって管理されます。 さらに、LMI DLC で利用できる最新の量子化技術 (GPTQ、AWQ、および SmoothQuant) を使用できます。 その結果、SageMaker の LMI DLC を使用すると、生成 AI アプリケーションの価値実現までの時間を短縮し、選択したハードウェアに合わせて LLM を最適化してクラス最高の価格パフォーマンスを達成できます。
この投稿では、LMI DLC の最新リリースの新機能を詳しく説明し、パフォーマンス ベンチマークについて説明し、パフォーマンスを最大化しコストを削減するために LMI DLC を使用して LLM を展開するために必要な手順の概要を説明します。
SageMaker LMI DLC の新機能
このセクションでは、SageMaker LMI DLC の XNUMX つの新機能について説明します。
SageMaker LMI が TensorRT-LLM をサポートするようになりました
SageMaker は現在、最新の LMI DLC リリース (0.25.0) の一部として NVIDIA の TensorRT-LLM を提供しており、NVIDIA GPU を使用する場合に SmoothQuant、FP8、LLM の連続バッチ処理などの最先端の最適化を可能にします。 TensorRT-LLM は、パフォーマンスを大幅に向上させる超低レイテンシ エクスペリエンスへの扉を開きます。 TensorRT-LLM SDK は、シングル GPU 構成からマルチ GPU 構成までのデプロイメントをサポートしており、テンソル並列処理などの技術を通じてさらなるパフォーマンスの向上が可能です。 TensorRT-LLM ライブラリを使用するには、利用可能なライブラリから TensorRT-LLM DLC を選択します。 LMI DLC 設定 engine=MPI とりわけ 設定 など option.model_id。 次の図は、TensorRT-LLM 技術スタックを示しています。

効率的な推論一括操作
LLM の一般的な展開では、単一のアクセラレータに収まらない大規模なモデルの要件に対応するために、モデル パラメーターが複数のアクセラレータに分散されます。 これにより、各アクセラレータが部分的な計算を並行して実行できるようになり、推論速度が向上します。 その後、これらのプロセスの最後に部分的な結果を統合し、アクセラレータ間で再分配するための集合的な操作が導入されます。
P4D インスタンス タイプの場合、SageMaker は GPU 間の通信を高速化する新しい集合操作を実装します。 その結果、最新の LMI DLC では、以前のバージョンと比較して、待ち時間が短縮され、スループットが向上します。 さらに、この機能は LMI DLC ですぐにサポートされており、この機能は SageMaker LMI DLC に埋め込まれており、Amazon SageMaker でのみ利用できるため、使用するために何も設定する必要はありません。
量子化のサポート
SageMaker LMI DLC は、GPTQ による事前量子化モデル、アクティベーション対応重み量子化 (AWQ)、および SmoothQuant のようなジャストインタイム量子化を含む、最新の量子化技術をサポートするようになりました。
GPTQ を使用すると、LMI は Hugging Face の人気のある INT3 および INT4 モデルを実行できます。 シングル GPU/マルチ GPU に適合できる最小のモデル重みを提供します。 LMI DLC は AWQ 推論もサポートしているため、推論速度が向上します。 最後に、LMI DLC は SmoothQuant をサポートするようになりました。これにより、INT8 量子化により、精度の低下を最小限に抑えながらモデルのメモリ フットプリントと計算コストを削減できるようになります。 現在、追加の手順を行わずに、SmoothQuant モデルのジャストインタイム変換を行うことができます。 GPTQ と AWQ は、LMI DLC で使用されるデータセットで量子化する必要があります。 また、LMI DLC で使用するために、人気のある量子化済み GPTQ および AWQ モデルを選択することもできます。 SmoothQuant を使用するには、次のように設定します。 option.quantize=smoothquanと engine=DeepSpeed in serving.properties。 ml.g5.12xlarge で GPT-Neox をホストするために SmoothQuant を使用するサンプル ノートブックは、次の場所にあります。 GitHubの.
SageMaker LMI DLC の使用
コードを変更することなく、新しい LMI DLC 0.25.0 を使用して LLM を SageMaker にデプロイできます。 SageMaker LMI DLC は、DJL サービングを使用して推論用のモデルを提供します。 開始するには、以下を指定する構成ファイルを作成するだけです。 設定 使用するモデルの並列化や推論最適化ライブラリなど。 SageMaker LMI DLC の使用手順とチュートリアルについては、以下を参照してください。 モデルの並列処理と大規模なモデルの推論 と 利用可能な SageMaker LMI DLC のリスト。
DeepSpeed コンテナには、LMI 分散推論ライブラリ (LMI-Dist) と呼ばれるライブラリが含まれています。 LMI-Dist は、vLLM、Text-Generation-Inference (バージョン 0.9.4 まで)、FasterTransformer、および DeepSpeed フレームワークにわたるさまざまなオープンソース ライブラリで使用される最適化を備えた大規模なモデル推論を実行するために使用される推論ライブラリです。 このライブラリには、モデルを高速化してメモリ消費量を削減するために、FlashAttendant、PagesAttention、FusedKernel、効率的な GPU 通信カーネルなどのオープンソースの一般的なテクノロジが組み込まれています。
TensorRT LLM は、NVIDIA が 2023 年 1 月にリリースしたオープンソース ライブラリです。推論の高速化のために TensorRT-LLM ライブラリを最適化し、ジャストインタイムのモデル変換をサポートすることでユーザー エクスペリエンスを簡素化するツールキットを作成しました。 このツールキットを使用すると、ユーザーはハグフェイス モデル ID を提供し、モデルをエンドツーエンドで展開できます。 ストリーミングによる連続バッチ処理もサポートしています。 Llama-2 2B および 7B モデルのコンパイルには約 13 ~ 7 分、70B モデルのコンパイルには約 XNUMX 分かかることが予想されます。 SageMaker エンドポイントのセットアップおよびインスタンスのスケーリング中にこのコンパイルのオーバーヘッドを回避したい場合は、事前 (AOT) コンパイルを使用することをお勧めします。 チュートリアル モデルを準備します。 また、LMI DLC で使用できる Triton Server 用に構築された TensorRT LLM モデルも受け入れます。
パフォーマンスベンチマーク結果
最新の SageMaker LMI DLC バージョン (0.25.0) と以前のバージョン (0.23.0) のパフォーマンスを比較しました。 私たちは Llama-2 70B、Falcon 40B、および CodeLlama 34B モデルで実験を実施し、TensorRT-LLM と効率的な推論集団操作 (SageMaker で利用可能) によるパフォーマンスの向上を実証しました。
SageMaker LMI コンテナには、モデルをロードしてホストするためのデフォルトのハンドラー スクリプトが付属しており、ローコード オプションを提供します。 モデルの読み込み手順をカスタマイズする必要がある場合は、独自のスクリプトを使用するオプションもあります。 必要なパラメータを serving.properties ファイル。 このファイルには、Deep Java Library (DJL) モデル サーバーがモデルをダウンロードしてホストするために必要な構成が含まれています。 次のコードは、 serving.properties 導入とベンチマークに使用されます。
engine パラメータは、DJL モデル サーバーのランタイム エンジンを定義するために使用されます。 ハグ顔モデル ID を指定するか、 Amazon シンプル ストレージ サービス (Amazon S3) を使用したモデルの場所 model_id パラメータ。 タスク パラメーターは、自然言語処理 (NLP) タスクを定義するために使用されます。 の tensor_parallel_degree パラメーターは、テンソル並列モジュールが分散されるデバイスの数を設定します。 の use_custom_all_reduce モデル推論を高速化するために、NVLink が有効になっている GPU インスタンスのパラメーターは true に設定されます。 これは、NVLink が接続されている P4D、P4de、P5、およびその他の GPU に対して設定できます。 の output_formatter パラメータは出力形式を設定します。 の max_rolling_batch_size パラメータは、同時リクエストの最大数の制限を設定します。 の model_loading_timeout 推論を行うためにモデルをダウンロードおよびロードするためのタイムアウト値を設定します。 設定オプションの詳細については、以下を参照してください。 構成と設定.
ラマ-2 70B
Llama-2 70Bの性能比較結果は以下の通りです。 新しい LMI TensorRT LLM DLC により、同時実行数 28 の場合、レイテンシーが 44% 削減され、スループットが 16% 増加しました。


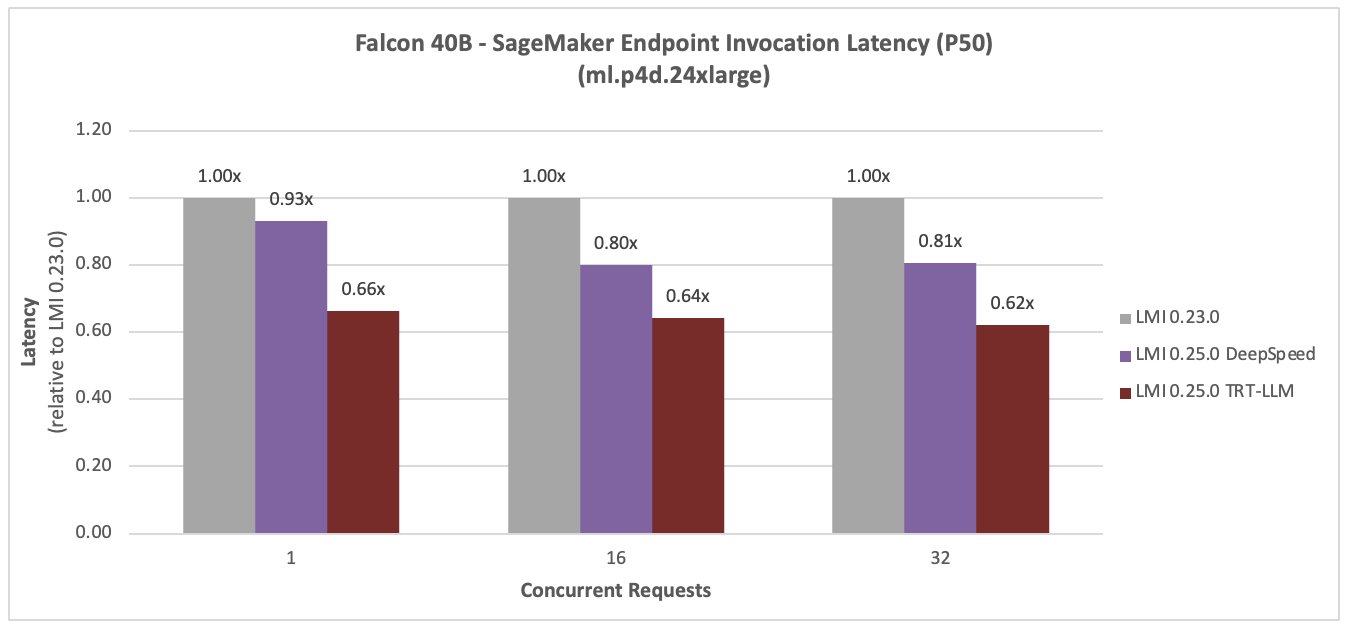
ファルコン40B
次の図は Falcon 40B を比較しています。 新しい LMI TensorRT LLM DLC により、同時実行数 36 の場合、レイテンシーが 59% 減少し、スループットが 16% 増加しました。

コードラマ 34B
次の図は CodeLlama 34B を比較しています。 新しい LMI TensorRT LLM DLC により、同時実行数 36 の場合、レイテンシーが 77% 減少し、スループットが 16% 増加しました。


LLM をホスティングするための推奨構成とコンテナー
最新リリースでは、SageMaker は 0.25.0-deepspeed と 0.25.0-tensorrtllm の XNUMX つのコンテナを提供します。 DeepSpeed コンテナには、LMI 分散推論ライブラリである DeepSpeed が含まれています。 TensorRT-LLM コンテナには以下が含まれます NVIDIA の TensorRT-LLM ライブラリ LLM 推論を高速化します。
次の図に示す展開構成をお勧めします。

まず、サンプル ノートブックを参照してください。
まとめ
この投稿では、SageMaker LMI DLC を使用してビジネス ユースケースに合わせて LLM を最適化し、価格パフォーマンスの利点を実現する方法を説明しました。 LMI DLC 機能の詳細については、次を参照してください。 モデルの並列処理と大規模なモデルの推論。 Amazon SageMaker のこれらの新機能をどのように使用するか楽しみにしています。
著者について
 マイケル・グエン AWS のシニア スタートアップ ソリューション アーキテクトであり、AI/ML を活用してイノベーションを推進し、AWS 上でビジネス ソリューションを開発することを専門としています。 Michael は 12 の AWS 認定資格を取得しており、ペンシルベニア州立大学、ビンガムトン大学、デラウェア大学で電気/コンピューター工学の学士/修士号と MBA を取得しています。
マイケル・グエン AWS のシニア スタートアップ ソリューション アーキテクトであり、AI/ML を活用してイノベーションを推進し、AWS 上でビジネス ソリューションを開発することを専門としています。 Michael は 12 の AWS 認定資格を取得しており、ペンシルベニア州立大学、ビンガムトン大学、デラウェア大学で電気/コンピューター工学の学士/修士号と MBA を取得しています。
 リシャブ・レイ・チョードリー はAmazonSageMakerのシニアプロダクトマネージャーであり、機械学習の推論に重点を置いています。 彼は、AWSで機械学習のお客様がワークロードを拡張できるように、革新と新しいエクスペリエンスの構築に情熱を注いでいます。 余暇には、旅行や料理を楽しんでいます。 あなたは彼を見つけることができます LinkedIn.
リシャブ・レイ・チョードリー はAmazonSageMakerのシニアプロダクトマネージャーであり、機械学習の推論に重点を置いています。 彼は、AWSで機械学習のお客様がワークロードを拡張できるように、革新と新しいエクスペリエンスの構築に情熱を注いでいます。 余暇には、旅行や料理を楽しんでいます。 あなたは彼を見つけることができます LinkedIn.
 青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
 ジャン・シェン はアマゾン ウェブ サービスのソフトウェア開発エンジニアであり、機械学習システムのいくつかの重要な側面に取り組んできました。 彼は SageMaker Neo サービスの主要な貢献者であり、深層学習のコンパイルとフレームワークのランタイム最適化に重点を置いています。 最近では、大規模モデル推論のための機械学習システムの最適化に尽力し、貢献しています。
ジャン・シェン はアマゾン ウェブ サービスのソフトウェア開発エンジニアであり、機械学習システムのいくつかの重要な側面に取り組んできました。 彼は SageMaker Neo サービスの主要な貢献者であり、深層学習のコンパイルとフレームワークのランタイム最適化に重点を置いています。 最近では、大規模モデル推論のための機械学習システムの最適化に尽力し、貢献しています。
 Vivek ガンガサニ は、AWS のジェネレーティブ AI スタートアップ向けの AI/ML スタートアップ ソリューション アーキテクトです。 彼は、新興の GenAI スタートアップ企業が AWS のサービスと高速化されたコンピューティングを使用して革新的なソリューションを構築するのを支援しています。 現在、大規模言語モデルの推論パフォーマンスを微調整および最適化するための戦略の開発に重点を置いています。 自由時間には、ヴィヴェクはハイキング、映画鑑賞、さまざまな料理の試食を楽しんでいます。
Vivek ガンガサニ は、AWS のジェネレーティブ AI スタートアップ向けの AI/ML スタートアップ ソリューション アーキテクトです。 彼は、新興の GenAI スタートアップ企業が AWS のサービスと高速化されたコンピューティングを使用して革新的なソリューションを構築するのを支援しています。 現在、大規模言語モデルの推論パフォーマンスを微調整および最適化するための戦略の開発に重点を置いています。 自由時間には、ヴィヴェクはハイキング、映画鑑賞、さまざまな料理の試食を楽しんでいます。
 ハリッシュ・トゥマラチェラ SageMaker のディープラーニング パフォーマンス チームのソフトウェア エンジニアです。 彼は、SageMaker 上で大規模な言語モデルを効率的に提供するためのパフォーマンス エンジニアリングに取り組んでいます。 余暇には、ランニング、サイクリング、スキー登山を楽しんでいます。
ハリッシュ・トゥマラチェラ SageMaker のディープラーニング パフォーマンス チームのソフトウェア エンジニアです。 彼は、SageMaker 上で大規模な言語モデルを効率的に提供するためのパフォーマンス エンジニアリングに取り組んでいます。 余暇には、ランニング、サイクリング、スキー登山を楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-llms-with-new-amazon-sagemaker-containers/

