
編集者による画像
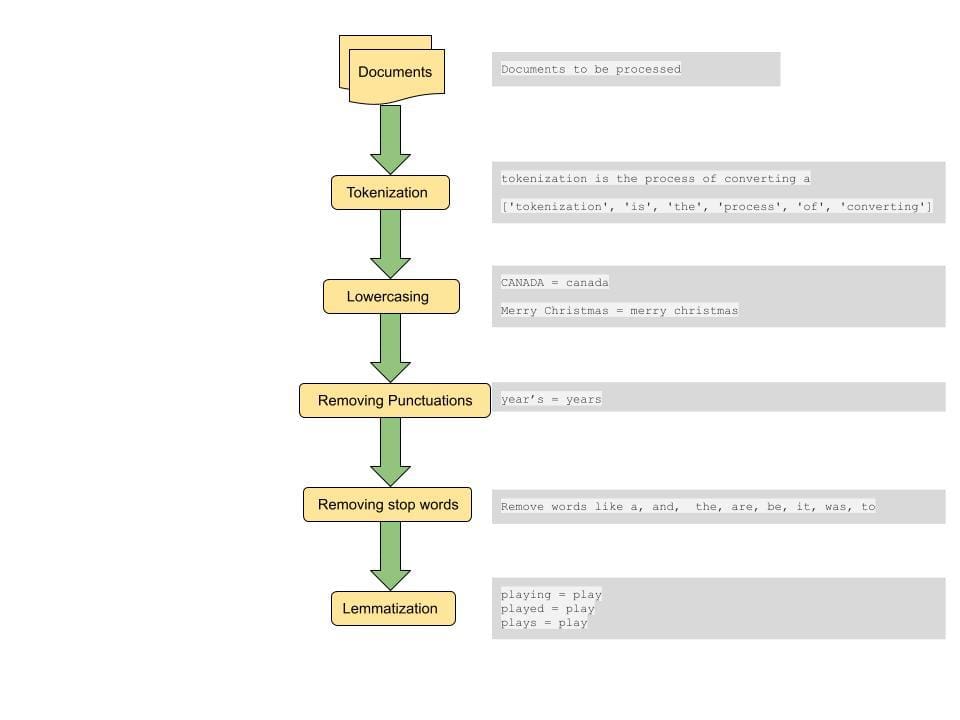
データ サイエンスは、コンピューター サイエンスの分野での進歩により、過去 XNUMX 年間で大幅に成長した分野です。コンピューターやクラウド ストレージのコストが安くなったことで、数年前に比べて非常に低コストで大量のデータを保存できるようになりました。計算能力の向上により、大規模なデータセットに対して機械学習アルゴリズムを実行し、データを撹拌して洞察を生み出すことができます。ネットワークの進歩により、インターネット上でデータを超高速で生成および送信できるようになりました。その結果、私たちは毎秒大量のデータが生成される時代に生きています。私たちは、電子メール、金融取引、ソーシャル メディア コンテンツ、インターネット上の Web ページ、企業の顧客データ、患者の医療記録、スマートウォッチからのフィットネス データ、Youtube のビデオ コンテンツ、スマート デバイスからのテレメトリ、リストなどの形式でデータを保有しています。に行く。構造化形式と非構造化形式の両方のこの豊富なデータにより、私たちはデータ マイニングと呼ばれる分野にたどり着きました。
データマイニング 結果を予測するために、大規模なデータセットからパターン、異常、相関関係を発見するプロセスです。データ マイニング技術はあらゆる形式のデータに適用できますが、データ マイニングのそのような分野の XNUMX つは次のとおりです。 テキストマイニング これは、非構造化テキスト データから意味のある情報を見つけることを指します。このホワイトペーパーでは、文書の類似性を見つけるというテキストマイニングの一般的なタスクに焦点を当てます。
文書の類似性 効率的な情報検索に役立ちます。文書の類似性の応用には、盗作の検出、Web 検索クエリへの効果的な回答、トピックごとの研究論文のクラスタリング、類似のニュース記事の検索、Quora、StackOverflow、Reddit などの Q&A サイトでの類似の質問のクラスタリング、説明に基づいた Amazon での製品のグループ化などがあります。ドキュメントの類似性は、DropBox や Google Drive などの企業でも、同じドキュメントの重複コピーの保存を避け、処理時間とストレージ コストを節約するために使用されています。
ドキュメントの類似性を計算するには、いくつかの手順があります。最初のステップは、ドキュメントをベクトル形式で表現することです。次に、これらのベクトルに対してペアごとの類似度関数を使用できます。類似度関数は、ベクトルのペア間の類似度を計算する関数です。ユークリッド距離、コサイン類似度、ジャカード類似度、ピアソン相関、スピアマン相関、ケンドールのタウなど、いくつかのペアごとの類似度関数があります [2]。ペアごとの類似度関数は、2 つのドキュメント、2 つの検索クエリ、またはドキュメントと検索クエリの間に適用できます。ペアごとの類似度関数は少数のドキュメントを比較するのに適していますが、DocXNUMXVec や BERT などの他のより高度な技術もあり、これらは深層学習技術に基づいており、検索クエリに基づいた効率的な情報検索のために Google などの検索エンジンで使用されています。このホワイトペーパーでは、Jaccard 類似度、ユークリッド距離、コサイン類似度、TF-IDF、DocXNUMXVec、および BERT によるコサイン類似度に焦点を当てます。
前処理
ドキュメント間の距離やドキュメント間の類似性を計算する一般的な手順は、ドキュメントに対して何らかの前処理を行うことです。前処理ステップには、すべてのテキストの小文字への変換、テキストのトークン化、ストップワードの削除、句読点の削除、単語の見出し語化が含まれます[4]。
トークン化: このステップでは、文をより小さな単位に分割して処理します。トークンは、文を分割できる最小の語彙アトムです。スペースを区切り文字として使用すると、文をトークンに分割できます。これはトークン化の XNUMX つの方法です。たとえば、「トークン化は本当に素晴らしいステップです」という形式の文は、['tokenization', 'is', a, 'really', 'cool', 'step'] という形式のトークンに分割されます。これらのトークンはテキスト マイニングの構成要素を形成し、テキスト データをモデル化する最初のステップの XNUMX つです。
小文字: 一部の特殊なケースでは大文字と小文字の区別が必要になる場合もありますが、ほとんどの場合、大文字と小文字が異なる単語を XNUMX つとして扱いたいと考えています。このステップは、大規模なデータセットから一貫した結果を得るために重要です。たとえば、ユーザーが「インド」という単語を検索している場合、検索クエリに関連する場合は、大文字と小文字が異なる単語を含む関連ドキュメントを「インド」、「INDIA」、「インド」のいずれかで取得したいと考えます。
句読点の削除: 句読点や空白を削除すると、重要な単語やトークンに重点を置いて検索することができます。
ストップワードの削除: ストップワードは英語で一般的に使用される単語のセットであり、このような単語を削除すると、クエリのコンテキストを伝えるより重要な単語に一致するドキュメントを取得するのに役立ちます。これは、特徴ベクトルのサイズを削減することにも役立ち、処理時間の短縮にも役立ちます。
Lemmatization: 見出語化は、単語をそのルート単語にマッピングすることで、スパース性を軽減するのに役立ちます。たとえば、「Plays」、「Played」、「Playing」はすべて play にマッピングされます。これにより、特徴セットのサイズも削減され、さまざまなドキュメント間で単語のすべてのバリエーションが照合され、最も関連性の高いドキュメントが表示されます。
この方法は最も簡単な方法の 3 つです。単語をトークン化し、両方の文書内の用語の合計数の合計に対する共有用語の数の合計を計算します。 XNUMX つのドキュメントが類似している場合、スコアは XNUMX ですが、XNUMX つのドキュメントが異なる場合、スコアは XNUMX です [XNUMX]。
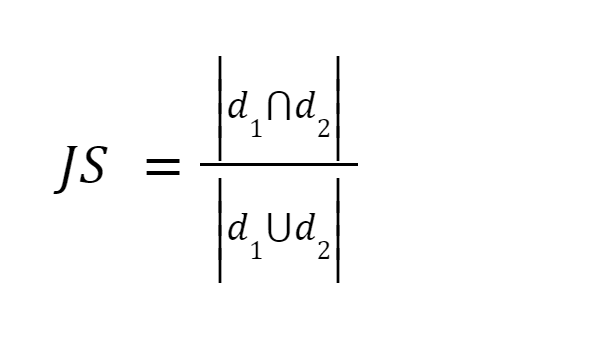
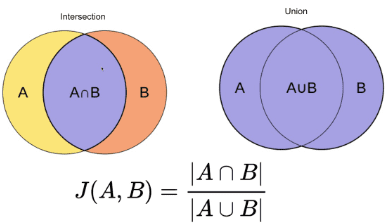
画像出典: オライリー
まとめ: この方法にはいくつかの欠点があります。文書のサイズが大きくなるにつれて、XNUMX つの文書が意味的に異なっていても、共通の単語の数が増加します。
ドキュメントを前処理した後、ドキュメントをベクトルに変換します。ベクトルの重みは、文書内で用語が出現する回数をカウントする用語頻度、または用語の合計数に対する用語のカウントの比率を計算する相対用語頻度のいずれかになります。文書[3]に記載されています。
d1 と d2 を、n 項のベクトル (n 次元を表す) として表される XNUMX つのドキュメントとします。次に、ピタゴラスの定理を使用して XNUMX つのドキュメント間の最短距離を計算し、XNUMX つのベクトル間の直線を見つけます。距離が大きいほど類似性は低くなり、距離が小さいほど XNUMX つのドキュメント間の類似性は高くなります。
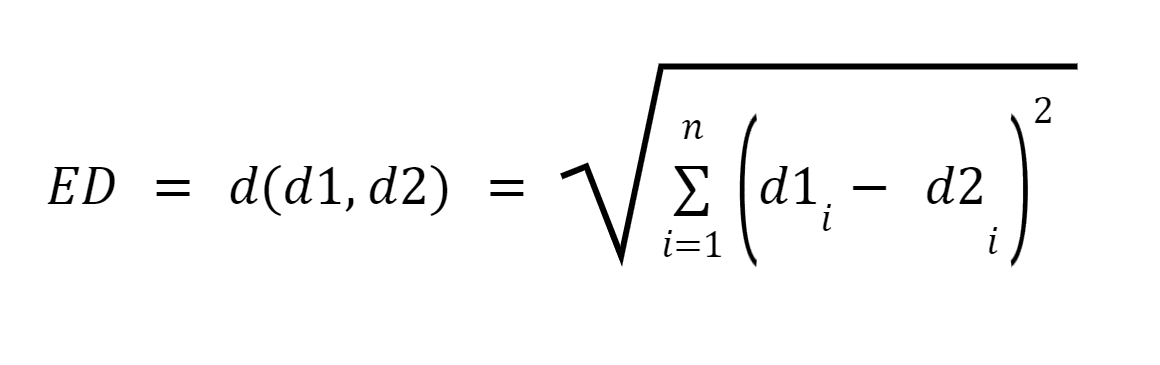
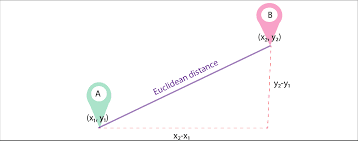
画像ソース:Medium.com
概要 このアプローチの主な欠点は、ドキュメントのサイズが異なる場合、XNUMX つのドキュメントの性質が似ているにもかかわらず、ユークリッド距離のスコアが低くなることです。ベクトルの大きさは文書内の単語数に正比例するため、全体の距離は大きくなります。ドキュメントが小さいほどベクトルは小さくなり、ドキュメントが大きいほどベクトルは大きくなります。
コサイン類似度は、0 つのベクトル間の角度のコサインを測定することにより、ドキュメント間の類似性を測定します。コサイン類似度の結果は 1 から 1 までの値をとります。ベクトルが同じ方向を向いている場合、類似度は 0 であり、ベクトルが反対方向を向いている場合、類似度は 6 です。[XNUMX]。
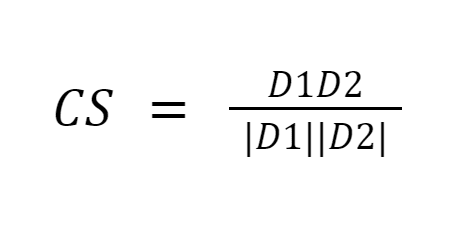
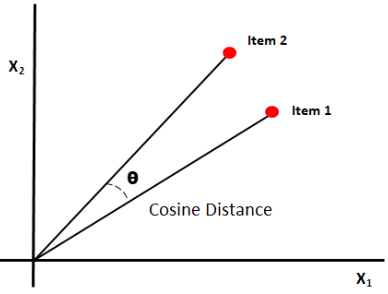
画像ソース:Medium.com
まとめ: コサイン類似度の良い点は、大きさではなくベクトル間の方向を計算することです。したがって、サイズが異なるにもかかわらず類似している XNUMX つのドキュメント間の類似性を捕捉します。
上記の XNUMX つのアプローチの根本的な欠点は、測定によってセマンティクスによる類似のドキュメントの検出が失われることです。また、これらの手法はすべてペアごとにのみ実行できるため、より多くの比較が必要になります。
ドキュメントの類似性を見つけるこの方法は、ElasticSearch のデフォルトの検索実装で使用されており、1972 年から存在しています [4]。 tf-idf は、用語頻度 - 逆ドキュメント頻度を表します。まず、次の式を使用して用語の頻度を計算します。
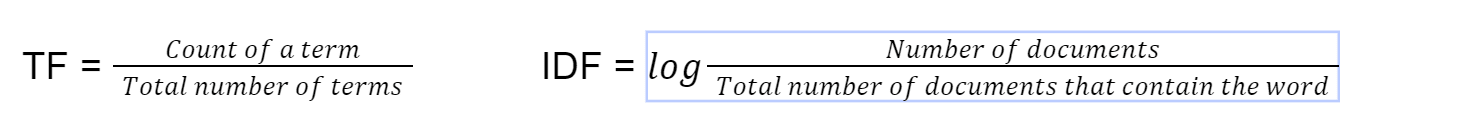
最後に、TF*IDF を乗算して tf-idf を計算します。次に、ベクトルの重みとして tf-idf を使用して、ベクトルのコサイン類似度を使用します。
まとめ: 用語の出現頻度と文書出現頻度の逆数を乗算すると、文書間で一般的により頻繁に出現する一部の単語が相殺され、文書間で異なる単語に焦点が当てられます。この手法は、重要なキーワードに焦点を当てて検索することで、検索クエリに一致するドキュメントを見つけるのに役立ちます。
ドキュメントの個々の単語 (BOW – Bag of Words) を使用してベクトルに変換する方が実装は簡単かもしれませんが、文内の単語の順序には意味がありません。 Doc2Vec は Word2Vec の上に構築されています。 Word2Vec が単語の意味を表すのに対し、Doc2Vec は文書または段落の意味を表します [5]。
このメソッドは、ドキュメントの意味論的な意味を保持しながら、ドキュメントをそのベクトル表現に変換するために使用されます。このアプローチは、文、段落、ドキュメントなどの可変長テキストをベクトルに変換します [5]。次に、doc2vec モードがトレーニングされます。モデルのトレーニングは、トレーニング セットとテスト セットのドキュメントを選択し、より良い結果が得られるように調整パラメーターを調整することにより、他の機械学習モデルをトレーニングするのと似ています。
まとめ: このようなベクトル化された形式の文書では、類似したコンテキストまたは意味を持つ段落がベクトルに変換される際に互いに近づくため、文書の意味論的な意味が保持されます。
BERT は、Google によって開発された、NLP タスクで使用されるトランスフォーマー ベースの機械学習モデルです。
BERT (トランスフォーマーによる双方向エンコーダー表現) の出現により、NLP モデルは、テキストを右から左と左から右の両方で見るラベルのない巨大なテキスト コーパスでトレーニングされます。 BERT は、結果を向上させるために「アテンション」と呼ばれる手法を使用します。 BERT の使用後、Google の検索ランキングは大幅に向上しました [4]。 BERT のユニークな機能には次のようなものがあります。
- 104 か国語の Wikipedia 記事で事前トレーニング済み。
- テキストを左から右と右から左の両方で確認します
- コンテキストを理解するのに役立ちます
まとめ: その結果、BERT は、タスク固有のアーキテクチャを大幅に変更することなく、質問応答、文の言い換え、スパム分類器、言語検出器の構築などの多くのアプリケーションに合わせて微調整できます。
文書の類似性を見つける際に類似度関数がどのように使用されるかについて学ぶことができてとてもよかったです。現在、シナリオに最も適した類似度関数を選択するのは開発者の責任です。たとえば、tf-idf は現在、ドキュメント照合の最先端技術であり、クエリ検索の最先端技術は BERT です。シナリオに基づいてどの類似度関数が最適であるかを自動検出するツールを構築し、メモリと処理時間に最適化された類似度関数を選択できれば素晴らしいでしょう。これは、履歴書と職務内容の自動照合、カテゴリごとの文書のクラスタリング、患者の医療記録に基づいた異なるカテゴリへの患者の分類などのシナリオで非常に役立ちます。
このホワイトペーパーでは、文書の類似性を計算するためのいくつかの注目すべきアルゴリズムについて説明しました。これは決して完全なリストではありません。ドキュメントの類似性を見つける方法は他にもいくつかあり、適切な方法を選択する決定は、特定のシナリオとユースケースによって異なります。 tf-idf、Jaccard、ユークリディエン、コサイン類似度などの単純な統計手法は、より単純なユースケースに適しています。 Python、R で利用可能な既存のライブラリを使用して簡単にセットアップでき、重機や処理能力を必要とせずに類似性スコアを計算できます。 BERT などのより高度なアルゴリズムは、事前トレーニングのニューラル ネットワークに依存します。これには何時間もかかりますが、ドキュメントのコンテキストの理解を必要とする分析では効率的な結果が得られます。
参照
[1] ハイダリアン、A.、ディニーン、M. J. (2016)。文書間の類似性レベルと文書クラスタリングを測定するためのハイブリッド幾何学的アプローチ。 2016 IEEE 第 XNUMX 回ビッグ データ コンピューティング サービスおよびアプリケーションに関する国際会議 (BigDataService)1-5。 https://doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A、Philip, M.、Lubna, K. (2013)。文書クラスタリングにおける類似性尺度の比較分析。 2013 年グリーン コンピューティング、通信、エネルギー保全に関する国際会議 (ICGCE)1-4。 https://doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S.、Jiang, J.-Y.、Lee, S.-J. (2014年)。テキストの分類とクラスタリングのための類似性測定。 知識とデータエンジニアリングに関するIEEEトランザクション, 26(7)、1575-1590。 https://doi.org/10.1109/tkde.2013.19
[4] 西村正人(2020年9月XNUMX日)。 2020 年のベスト ドキュメント類似性アルゴリズム: 初心者向けガイド – データ サイエンスに向けて。 中くらい。 https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020、10 月 XNUMX 日)。 Doc2vec によるドキュメントの類似性の検出 – データ サイエンスに向けて。 中くらい。 https://towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019 年 18 月 XNUMX 日)。 類似性の計算 – 最も関連性の高い指標の要約 – データ サイエンスに向けて。 中くらい。 https://towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019 年 27 月 XNUMX 日)。 類似性の尺度 — テキスト記事のスコアリング – データ サイエンスに向けて。 中くらい。 https://towardsdatascience.com/similarity-measures-e3dbd4e58660
プールニマ・ムトゥクマール Microsoft のシニア テクニカル プロダクト マネージャーであり、クラウド コンピューティング、人工知能、分散システム、ビッグ データ システムなど、さまざまなドメイン向けの革新的なソリューションの開発と提供に 10 年以上の経験があります。私はワシントン大学でデータ サイエンスの修士号を取得しています。私は Microsoft で AI/ML およびビッグ データ システムを専門とする 2016 つの特許を取得しており、2023 年のグローバル ハッカソンでは人工知能部門で優勝しました。私は、今年 2023 年の Grace Hopper Conference のソフトウェア エンジニアリング カテゴリの審査委員会に参加できたことを光栄に思いました。これらの分野の才能ある女性からの提出物を読んで評価し、テクノロジー分野での女性の進歩にも貢献できたのは、やりがいのある経験でした。彼らの研究と洞察から学ぶために。私は、XNUMX 年 XNUMX 月の Microsoft Machine Learning AI and Data Science (MLADS) カンファレンスの委員会メンバーでもありました。私は、Women in Data Science Worldwide コミュニティと Women Who Code Data Science コミュニティのアンバサダーでもあります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/evaluating-methods-for-calculating-document-similarity?utm_source=rss&utm_medium=rss&utm_campaign=evaluating-methods-for-calculating-document-similarity

