
著者による画像
教師ありは、入力と正しい出力の両方を含むラベル付きデータセットからコンピューターが学習する機械学習のサブカテゴリです。 入力 (x) を出力 (y) に関連付けるマッピング関数を見つけようとします。 これは、弟や妹にさまざまな動物の見分け方を教えることだと考えることができます。 何枚かの写真を見せて (x)、それぞれの動物の名前を教えます (y)。 一定の時間が経過すると、子供たちは違いを学習し、新しい画像を正しく認識できるようになります。 これが教師あり学習の背後にある基本的な直観です。 先に進む前に、その仕組みを詳しく見てみましょう。
教師あり学習はどのように機能するのでしょうか?
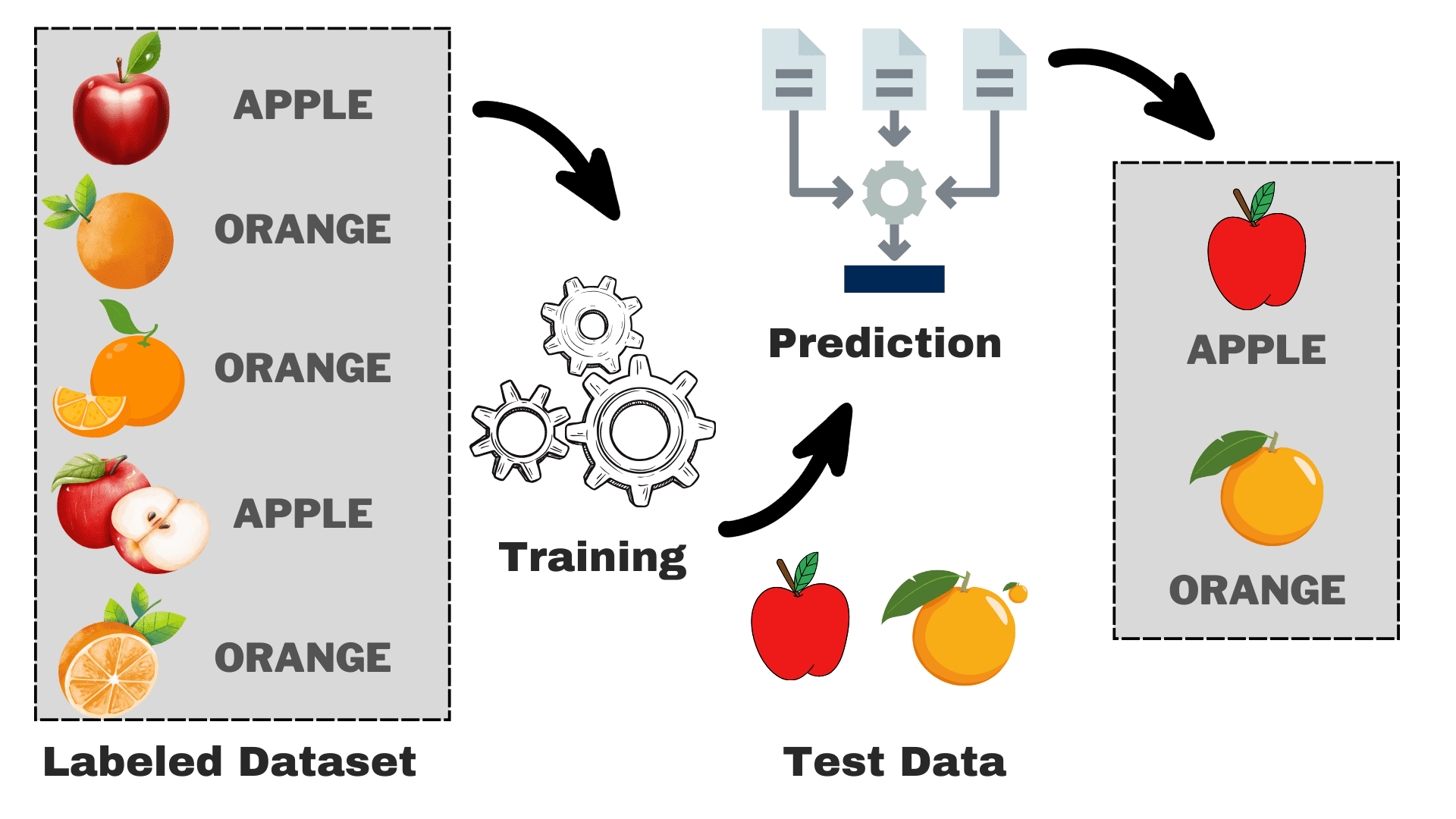
著者による画像
いくつかの特性に基づいてリンゴとオレンジを区別できるモデルを構築するとします。 このプロセスは次のタスクに分類できます。
- データ収集: リンゴとオレンジの写真を含むデータセットを収集すると、各画像に「リンゴ」または「オレンジ」のラベルが付けられます。
- モデルの選択: ここでは、タスクに適した教師あり機械学習アルゴリズムとして知られる適切な分類器を選択する必要があります。 それはちょうどよく見えるようになる適切なメガネを選ぶのと同じです
- モデルをトレーニングする: 次に、リンゴとオレンジのラベル付き画像をアルゴリズムに入力します。 アルゴリズムはこれらの写真を見て、リンゴとオレンジの色、形、大きさなどの違いを認識することを学習します。
- 評価とテスト: モデルが正しく機能しているかどうかを確認するために、いくつかの未表示の画像をモデルにフィードし、予測を実際の予測と比較します。
教師あり学習は、主に XNUMX つのタイプに分類できます。
Classification
分類タスクの主な目的は、一連の離散クラスから特定のカテゴリにデータ ポイントを割り当てることです。 「はい」または「いいえ」、「スパム」または「スパムではない」、「承認」または「拒否」など、考えられる結果が XNUMX つだけである場合、それは二項分類と呼ばれます。 ただし、点数に基づいて学生を評価する場合 (A、B、C、D、F など) のように、XNUMX つ以上のカテゴリまたはクラスが関係する場合、これは多重分類問題の例になります。
不具合
回帰問題では、連続数値を予測しようとします。 たとえば、クラスでの過去の成績に基づいて最終試験の得点を予測することに興味があるかもしれません。 予測スコアは、特定の範囲内の任意の値に及ぶ可能性があり、この場合は通常 0 ~ 100 です。
これで、プロセス全体の基本を理解できました。 一般的な教師あり機械学習アルゴリズム、その使用法、およびその仕組みについて説明します。
1.線形回帰
名前が示すように、株価の予測、気温の予測、病気の進行の可能性の推定などの回帰タスクに使用されます。ラベルのセット (独立変数) を使用してターゲット (従属変数) を予測しようとします。 入力フィーチャとラベルの間に線形関係があることを前提としています。 中心となるアイデアは、実際の値と予測値の間の誤差を最小限に抑えることによって、データ ポイントに最適な線を予測することを中心に展開されます。 この直線は次の方程式で表されます。
ここで、
- Y 予測された出力。
- X = 重線形回帰における入力特徴または特徴行列
- b0 = 切片 (線が Y 軸と交差する場所)。
- b1 = ラインの急勾配を決定する傾きまたは係数。
線の傾き (重み) とその切片 (バイアス) を推定します。 この線をさらに使用して予測を行うことができます。 これはベースラインを作成するための最も単純で便利なモデルですが、ラインの位置に影響を与える可能性のある外れ値に非常に敏感です。
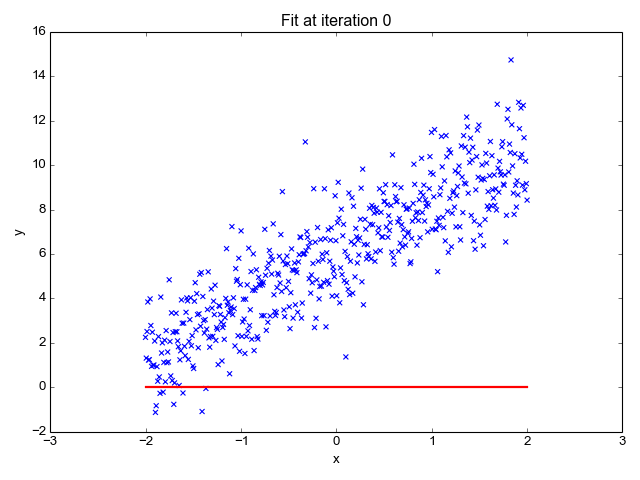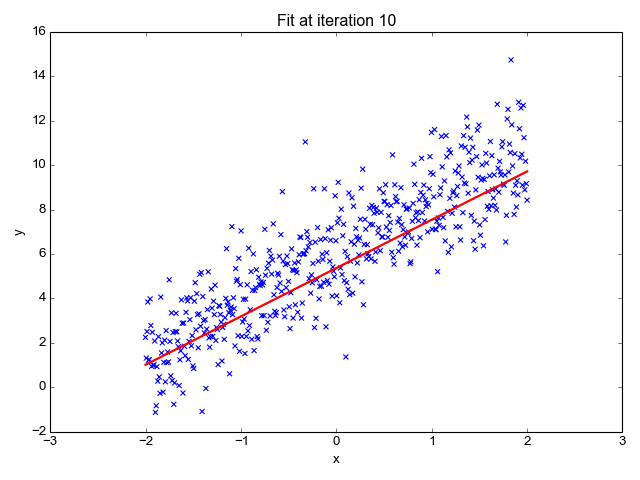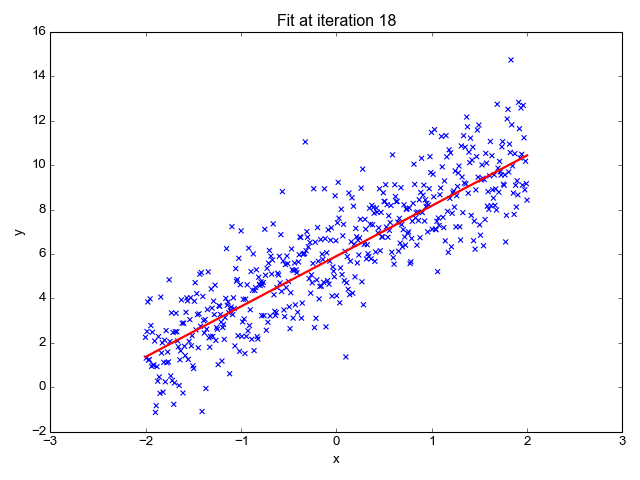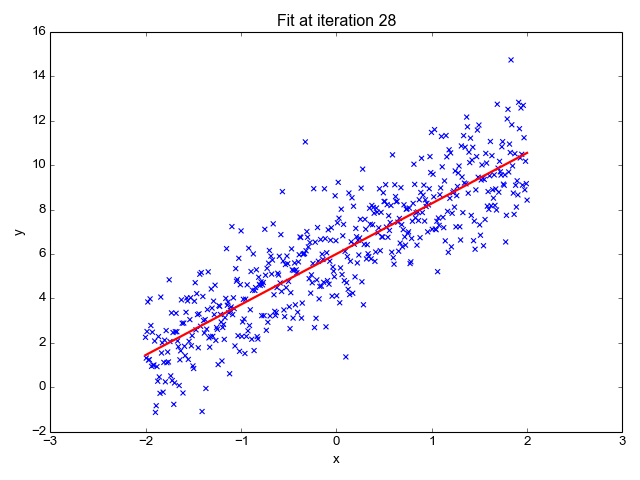
GIF オン プリモ.ai
2.ロジスティック回帰
名前には回帰が付いていますが、基本的には二項分類問題に使用されます。 0 ~ 1 の範囲にある肯定的な結果 (従属変数) の確率を予測します。閾値 (通常は 0.5) を設定することで、データ ポイントを分類します。閾値よりも高い確率を持つデータ ポイントは肯定的なクラスに属します。およびその逆。 ロジスティック回帰では、次のように指定される入力特徴の線形結合に適用されるシグモイド関数を使用して、この確率が計算されます。
ここで、
- P(Y=1) = 陽性クラスに属するデータ ポイントの確率
- X1 ,…,Xn = 入力特徴
- b0,….,bn = アルゴリズムがトレーニング中に学習する入力重み
このシグモイド関数は、任意のデータ ポイントを 0 ~ 1 の範囲内の確率スコアに変換する S 状の曲線の形式です。 よりよく理解するために、以下のグラフを見ることができます。
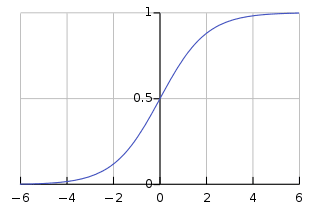
画像オン Wikipedia
値が 1 に近いほど、モデルの予測の信頼度が高いことを示します。 線形回帰と同様に、その単純さで知られていますが、元のアルゴリズムを変更せずに多クラス分類を実行することはできません。
3.ディシジョンツリー
上記 XNUMX つのアルゴリズムとは異なり、デシジョン ツリーは分類タスクと回帰タスクの両方に使用できます。 フローチャートと同じように階層構造になっています。 各ノードでは、いくつかの特徴値に基づいてパスに関する決定が行われます。 最終決定を示す最後のノードに到達しない限り、プロセスは続行されます。 ここでは、知っておく必要がある基本的な用語をいくつか示します。
- ルートノード: データセット全体を含む最上位のノードはルート ノードと呼ばれます。 次に、何らかのアルゴリズムを使用してデータセットを 2 つ以上のサブツリーに分割し、最適な特徴を選択します。
- 内部ノード: 各内部ノードは、特定の特徴と、データ ポイントの次の可能な方向を決定するための決定ルールを表します。
- リーフノード: クラス ラベルを表す終了ノードはリーフ ノードと呼ばれます。
回帰タスクの連続数値を予測します。 データセットのサイズが大きくなるにつれて、過学習につながるノイズが取り込まれます。 これは、決定木を枝刈りすることで処理できます。 決定の精度が大幅に向上しないブランチは削除します。 これにより、ツリーが最も重要な要素に集中し、細部が失われるのを防ぐことができます。
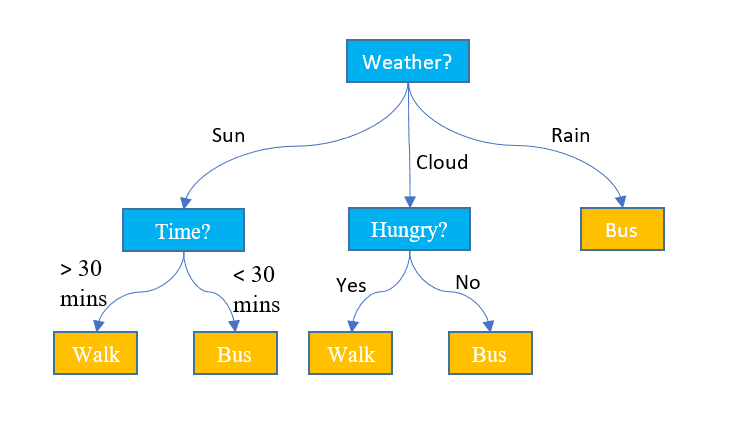
による画像 ジェイク・ホア ディスプレイ上
4.ランダムフォレスト
ランダム フォレストは、分類タスクと回帰タスクの両方に使用することもできます。 これは、最終的な予測を行うために連携するデシジョン ツリーのグループです。 これは、専門家の委員会が集団的な決定を下すものと考えることができます。 その仕組みは次のとおりです。
- データサンプリング: データセット全体を一度に取得するのではなく、ブートストラップまたはバギングと呼ばれるプロセスを通じてランダムなサンプルを取得します。
- 機能の選択: ランダム フォレスト内の各デシジョン ツリーでは、完全な特徴セットではなく、特徴のランダムなサブセットのみが意思決定の対象となります。
- 投票: 分類では、ランダム フォレスト内の各デシジョン ツリーが投票し、最も高い投票数を獲得したクラスが選択されます。 回帰では、すべてのツリーから得られた値を平均します。
個々の決定木によって引き起こされる過剰適合の影響は軽減されますが、計算コストが高くなります。 文献でよく目にする単語の XNUMX つは、ランダム フォレストはアンサンブル学習方法である、つまり、複数のモデルを組み合わせて全体のパフォーマンスを向上させるというものです。
5. サポート ベクター マシン (SVM)
これは主に分類問題に使用されますが、回帰タスクも処理できます。 ロジスティック回帰の確率的アプローチとは異なり、統計的アプローチを使用して、個別のクラスを分離する最適な超平面を見つけようとします。 線形分離可能なデータには線形 SVM を使用できます。 ただし、現実世界のデータのほとんどは非線形であるため、カーネル トリックを使用してクラスを分離します。 それがどのように機能するかを詳しく見てみましょう。
- 超平面の選択: 二項分類では、SVM はマージンを最大化しながらクラスを分離する最適な超平面 (2-D ライン) を見つけます。 マージンは、超平面とその超平面に最も近いデータ点の間の距離です。
- カーネルのトリック: 線形分離不可能なデータの場合、元のデータ空間を線形分離できる高次元空間にマッピングするカーネル トリックを採用します。 一般的なカーネルには、線形、多項式、動径基底関数 (RBF)、およびシグモイド カーネルが含まれます。
- マージンの最大化: SVM はまた、マージンの最大化を増やすことでモデルの一般化を改善しようとします。
- 分類: モデルがトレーニングされると、超平面に対する相対的な位置に基づいて予測を行うことができます。
SVM には、マージンの最大化と分類誤差の最小化の間のトレードオフを制御する C と呼ばれるパラメータもあります。 高次元の非線形データをうまく処理できますが、適切なカーネルとハイパーパラメータを選択することは、思っているほど簡単ではありません。
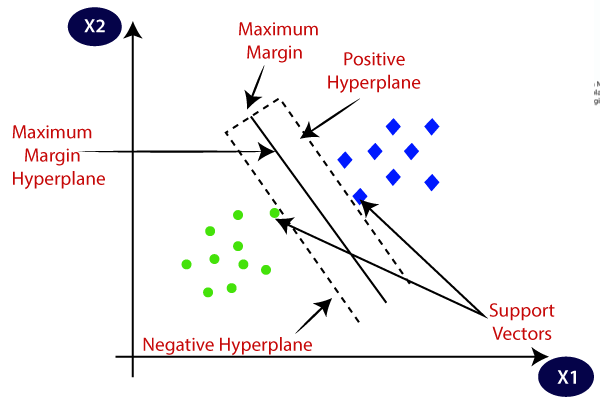
画像オン ジャバトポイント
6. k 最近傍 (k-NN)
K-NN は、主に分類タスクに使用される最も単純な教師あり学習アルゴリズムです。 データについて何の仮定も行わず、既存のデータ ポイントとの類似性に基づいて新しいデータ ポイントにカテゴリを割り当てます。 トレーニング段階では、データセット全体を参照ポイントとして保持します。 次に、距離メトリック (ユーシリン距離など) を使用して、新しいデータ ポイントと既存のすべてのポイントの間の距離を計算します。 これらの距離に基づいて、これらのデータ ポイントに最も近い K 個の近傍を特定します。 次に、K 個の最近傍の各クラスの出現をカウントし、最も頻繁に出現するクラスを最終予測として割り当てます。
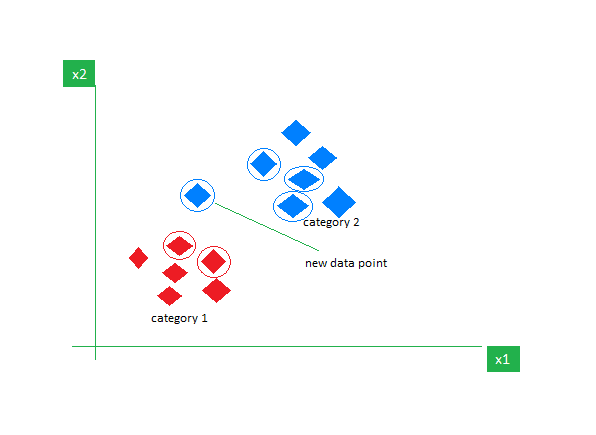
画像オン おたく
K の正しい値を選択するには実験が必要です。 ノイズの多いデータに対しては堅牢ですが、高次元のデータセットには適しておらず、すべてのデータ ポイントからの距離を計算するためコストが高くなります。
この記事の締めくくりとして、読者の皆様には、さらにアルゴリズムを検討し、ゼロから実装してみることをお勧めします。 これにより、物事が内部でどのように機能しているかについての理解が深まります。 開始に役立つ追加のリソースをいくつか紹介します。
カンワル・メーリーン は、データ サイエンスと医療における AI の応用に強い関心を持つ意欲的なソフトウェア開発者です。 Kanwal は、APAC 地域の Google Generation Scholar 2022 に選ばれました。 Kanwal は、流行のトピックに関する記事を書いて技術知識を共有することを好み、技術業界における女性の割合を改善することに情熱を注いでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- チャートプライム。 ChartPrime でトレーディング ゲームをレベルアップしましょう。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview

