概要
自然言語処理 (NLP) では、大規模言語モデル (LLM) の開発が変革的かつ革命的な取り組みであることが証明されています。これらのモデルは、膨大なパラメータを備え、広範なデータセットでトレーニングされており、多くの NLP タスクにわたって前例のない熟練度を示しています。しかし、これらのモデルをゼロからトレーニングするには法外なコストがかかるため、研究者は代替戦略を模索するようになりました。大規模言語モデル (LLM) の機能を強化するために登場した先駆的な戦略は知識融合です。この概念は、Wan、Huang、Cai、Quan、および Quan による Knowledge "Fusion of Large Language Models" というタイトルの研究論文で詳しく調査されています。その他。
新しく開発された LLM の機能の冗長性に対処する必要性を認識し、この革新的なアプローチは魅力的なソリューションを提供します。この論文では、さまざまな LLM の知識を統合する複雑なプロセスを詳しく掘り下げ、これらの言語モデルのパフォーマンスを改良および強化するための有望な手段を示しています。
基本的な考え方は、個々のモデルの制限を超えて、既存の LLM の長所と機能を組み合わせることです。既存の事前トレーニング済み LLM をマージすることで、各ソース モデルの個々の強みを超える、より強力なモデルを作成できます。

目次
LLM の知識融合を理解する
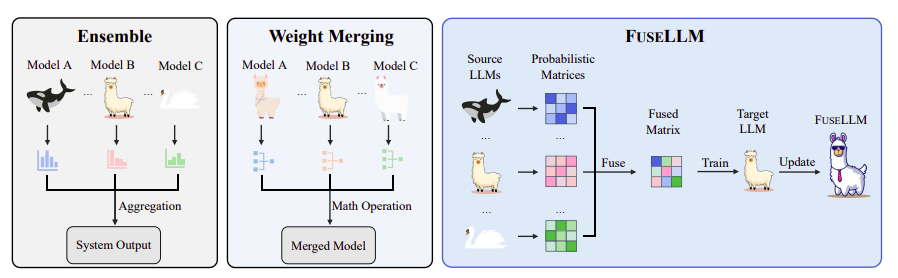
この論文は、LLM をゼロからトレーニングする際の課題とコストを強調することから始めます。著者らは、効率的でコスト効率の高い代替手段として知識融合を提案しています。このアプローチは、重みを直接マージするのではなく、ソース LLM の集合的な知識を外部化し、それをターゲット モデルに転送することに焦点を当てています。この研究では、ソース LLM の生成分布を活用する手法である FUSELLM を導入し、個々のソース LLM を超えてターゲット モデルの機能を強化することを目的としています。
LLM 融合の主な目的は、複数のソース LLM に埋め込まれた固有の知識を外部化し、その機能をターゲット LLM に統合することです。この論文では、特定のテキスト内の次のトークンを予測することによって、LLM が知識を明示できるように刺激することを強調しています。同じテキストに対して異なるソース LLM によって生成された確率分布は単一の表現に融合され、テキスト全体にわたる統一された確率的理解を作成します。
実装の詳細: トークンの調整と融合戦略
この文書では、効果的な知識融合を確実にするための 2 つの重要な実装の詳細、トークン アラインメントと融合戦略を紹介します。
トークンの位置合わせは、Minimum Edit Distance (MinED) 戦略によって実現され、異なる LLM からのトークンの位置合わせの成功率が向上します。
融合戦略、つまり MinCE と AvgCE は、さまざまな LLM の品質を評価し、クロス エントロピー スコアに基づいて、それらの分布行列にさまざまなレベルの重要性を割り当てます。
実験と評価
この研究では、ソース モデルの共通性が最小限に抑えられる、LLM 融合の困難なシナリオに関する実験が行われます。 3 つの代表的なオープンソース モデル – ラマ-2、OpenLLaMA、および MPT – 融合のソース LLM として選択され、別の Llama-2 がターゲット LLM として機能します。実験は、推論、常識、コード生成機能を評価するベンチマークに及びます。
さまざまなベンチマークにわたるパフォーマンス
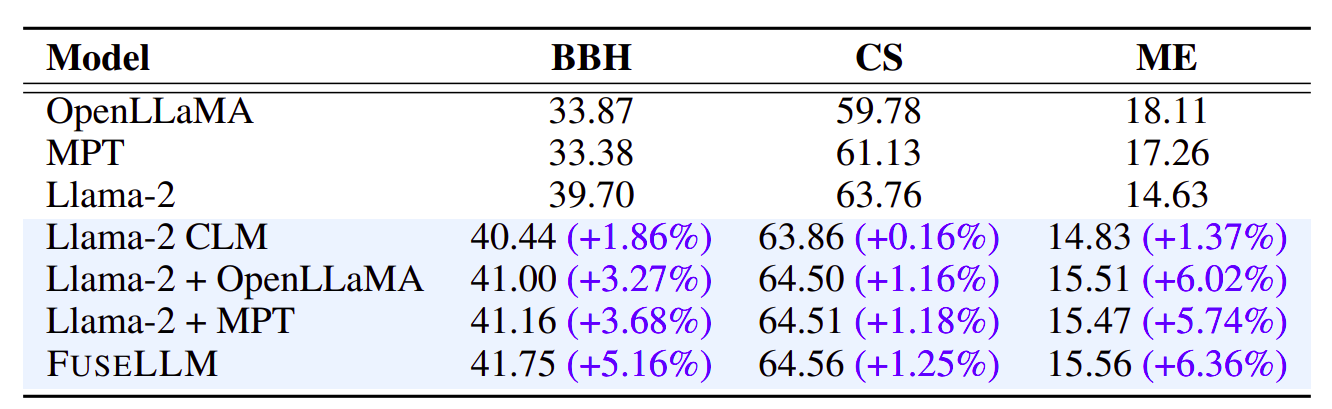
さまざまなベンチマークにわたる FUSELLM のパフォーマンスの包括的な評価により、その有効性についての貴重な洞察が得られます。表 1 は、Big-Bench Hard (BBH) でのベースライン手法と比較した FUSELLM の全体的な結果を示しています。特に、FUSELLM は、5.16 タスクすべてにおいて、元の Llama-2 と比較して平均 27% の相対パフォーマンス向上を示しています。 Hyperbaton などの特定のタスクは大幅な機能強化を示しており、集合的な知識を活用してパフォーマンスを向上させる FUSELLM の能力を強調しています。
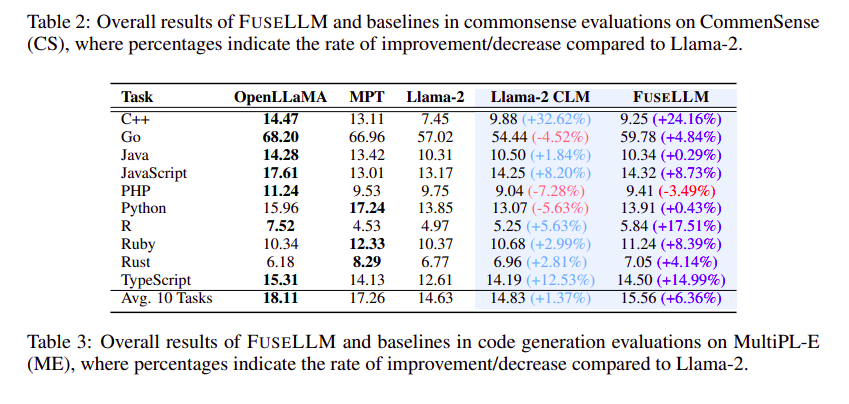
表 2 の Common Sense (CS) ベンチマークに進むと、FUSELLM はすべてのタスクにわたって一貫してベースラインを上回り、Llama-1.25 と比較して 2% の相対的なパフォーマンス向上を達成しています。この傾向は、ARC チャレンジや OpenBookQA などの困難なタスクにも当てはまり、FUSELLM は大幅な改善を示し、複雑な問題への対処におけるその有効性が強調されています。
コード生成の観点から、表 3 は MultiPL-E (ME) ベンチマークでの FUSELLM のゼロショット パフォーマンスを示しています。 FUSELLM は、2 タスク中 9 タスクで Llama-10 を上回り、特に R などの特定のプログラミング言語で pass@1 スコアが顕著に向上しています。OpenLLaMA や MPT と比較したパフォーマンスのギャップにもかかわらず、FUSELLM は依然として、次のような顕著な平均パフォーマンスの向上を達成しています。 6.36% であり、Llama-1.37 CLM で観察された 2% の改善を上回りました。
融合された確率分布: 最適化の加速

FUSELLM の成功の重要な側面は、複数の LLM からの融合された確率分布を利用できることにあります。図 2 は、BBH 上のさまざまなスケールのトレーニング データを使用した Llama-2 CLM と FUSELLM の間の数ショットの思考連鎖 (CoT) パフォーマンスを比較しています。 FUSELLM は完全一致 (EM) の精度を 2.5% 大幅に向上させ、2 億 0.52 万トークン以内で Llama-3.9 CLM の最高のパフォーマンスを達成します。これは、Llama-2 CLM と比較してトークン要件が XNUMX 倍削減されたことを表しており、LLM から導出された確率分布には、元のテキスト シーケンスよりも容易に学習可能な知識が含まれており、それによって最適化プロセスが加速されることを示しています。
導入プロセスの分析
FUSELLM の実装の詳細を詳しく調べると、FUSELLM を成功させるための重要な考慮事項が明らかになります。ソース LLM の数、トークン アライメント基準、および融合関数の選択は、FUSELLM のパフォーマンスを形成する上で極めて重要な役割を果たします。
- ソース LLM の数: 表 4 は、さまざまなモデル数による FUSELLM のパフォーマンスの向上を示しています。結果は、モデルの数が 1 から 3 に増加するにつれて明らかな強化を示しており、BBH では一貫した改善が観察されています。
- トークン調整の基準: LLM の融合時には、適切なトークンの配置が重要です。提案された MinED メソッドは一貫して EM メソッドよりも優れており、複数のモデルからのトークンを調整する際の MinED の有効性を示しています。
- 融合機能: 融合関数の選択は重要であり、MinCE を使用した FUSELLM は、すべてのベンチマークにわたって一貫して AvgCE を上回ります。これは、個々の LLM の明確な利点を維持する上での融合機能の重要性を強調しています。
FUSELLM vs. 知識の蒸留とアンサンブル/マージ
知識の蒸留やアンサンブル/マージなどの伝統的な手法との比較分析により、FUSELLM の独自の強みが明らかになります。
- FUSELLM と知識の蒸留: FUSELLM は、特に BBH において知識蒸留より優れており、FUSELLM によって達成された改善 (5.16%) は知識蒸留のわずかな増加 (2.97%) を上回っています。これは、複数の LLM からの集合的な知識をより効果的に活用する FUSELLM の能力を強調しています。
- FUSELLM vs. アンサンブル/マージ: 複数の LLM が同じベース モデルに由来するが、別個のコーパスでトレーニングされたシナリオでは、FUSELLM は、アンサンブルおよびウェイト マージ手法と比較して、3 つのドメイン全体で一貫して最も低い平均パープレキシティを達成します。これにより、従来の融合手法よりも効果的に集合知識を活用できる FUSELLM の可能性が強化されます。
コード、モデルの重み、およびデータはここで公開されています。 GitHub フューセルム

結論: 将来の可能性を明らかにする
この論文は、個々のソース LLM および確立されたベースラインに対する FUSELLM の有効性を示す説得力のある結果で締めくくられています。この研究は、LLM 融合における将来の探求に有望な道を切り開きます。この調査結果は、構造的に異なる LLM の多様な機能と強みを組み合わせることの可能性を強調し、大規模な言語モデルを開発するための費用対効果の高い強力なアプローチに光を当てています。
大規模な言語モデルの知識の融合は、高度な自然言語処理機能への需要が高まり続ける世界において革新的なソリューションです。この研究は、多様な LLM の集合知を活用する統合モデルを作成する将来の取り組みへの道を開き、自然言語の理解と生成の領域で達成可能な限界を押し広げます。
大規模言語モデル (LLM) の知識融合に関するあなたの意見を知りたいと思っています。他の注目に値する有益な論文についての洞察を、コメントセクションでお気軽に共有してください。
また、お読みください。 大規模な言語モデルを微調整するための包括的なガイド
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/02/knowledge-fusion-of-large-language-models-llms/

