大規模言語モデル (LLM) の価値を理解するために、機械学習 (ML) の専門家である必要はありません。 検索結果の改善、視覚障害者向けの画像認識、テキストからの斬新なデザインの作成、インテリジェントなチャットボットは、これらのモデルがさまざまなアプリケーションやタスクをどのように促進しているかを示すほんの一例です。
ML の実践者は、これらのモデルの精度と機能を改善し続けています。 その結果、これらのモデルはサイズが大きくなり、変圧器モデルの進化などでより一般化されます。 前回で説明した 役職 使い方 アマゾンセージメーカー 深層学習コンテナ (DLC) を使用して、GPU ベースのインスタンスを使用してこの種の大規模モデルをデプロイします。
この投稿では、同じアプローチを採用していますが、モデルをホストしています AWS インフェレンシア 2。 私たちは AWS ニューロン Inferentia デバイスにアクセスし、その高性能を活用するためのソフトウェア開発キット (SDK)。 次に、大規模なモデル推論コンテナーを使用します。 ディープJavaライブラリ (DJLServing) をモデル サービング ソリューションとして使用します。 これらの XNUMX つのレイヤーがどのように連携するかをデモンストレーションします。 OPT-13B 上のモデル アマゾン エラスティック コンピューティング クラウド (アマゾン EC2) inf2.48xlarge .
XNUMX本の柱
次の図は、大規模な言語モデルの最適な価格とパフォーマンスを引き出すのに役立つハードウェアとソフトウェアのレイヤーを表しています。 AWS ニューロンと tranformers-neuronx AWS Inferentia で深層学習ワークロードを実行するために使用される SDK です。 最後に、DJLServing はコンテナーに統合されたサービス提供ソリューションです。

ハードウェア: インファレンティア
AWS による推論用に特別に設計された AWS Inferentia は、高性能で低コストの ML 推論アクセラレーターです。 この記事では、第 2 世代の専用 ML 推論アクセラレーターである AWS Inferentia2 (InfXNUMX インスタンス経由で利用可能) を使用します。
各 EC2 Inf2 インスタンスは、最大 12 の電源を供給されます Inferentia2 デバイスから選択できます XNUMX つのインスタンス サイズ.
Amazon EC2 Inf2 は、低レイテンシーで高帯域幅のチップ間相互接続である NeuronLink v2 をサポートしています。 AllReduce & AllGather. これにより、AWS Inferentia2 デバイス間で (Tensor Parallelism などを介して) モデルが効率的にシャード化されるため、レイテンシーとスループットが最適化されます。 これは、大規模な言語モデルの場合に特に役立ちます。 ベンチマークのパフォーマンス数値については、AWS を参照してください ニューロンのパフォーマンス.

Amazon EC2 Inf2 インスタンスの中心にあるのは AWS Inferentia2 デバイスで、それぞれに XNUMX つのデバイスが含まれています。 ニューロンコア-v2. 各 NeuronCore-v2 は、Tensor、Vector、Scalar、および GPSIMD エンジンの 2 つのメイン エンジンを備えた、独立した異種計算ユニットです。 これには、データの局所性を最大化するためのオンチップ ソフトウェア管理 SRAM メモリが含まれています。 次の図は、AWS InferentiaXNUMX デバイス アーキテクチャの内部動作を示しています。

ニューロンとトランスフォーマー-neuronx
ハードウェア レイヤーの上には、AWS Inferentia とやり取りするために使用されるソフトウェア レイヤーがあります。 AWS Neuron は、AWS Inferentia で深層学習ワークロードを実行するために使用される SDK であり、 AWS トレーニング ベースのインスタンス。 これにより、エンド ツー エンドの ML 開発ライフサイクルが可能になり、新しいモデルを構築し、これらのモデルをトレーニングおよび最適化し、本番環境にデプロイできます。 AWS Neuron には深層学習が含まれています コンパイラ, ランタイム, 豊富なツール群 TensorFlow や PyTorch などの一般的なフレームワークとネイティブに統合されています。
transformers-neuronx オープンソースです ライブラリ AWS Neuron SDK を使用してトランスフォーマーデコーダー推論ワークフローを実行するのに役立つ AWS Neuron チームによって構築されました。 現在、 例 GPT2、GPT-J、および OPT モデル タイプ、および広範なコード分析と最適化のためにコンパイルされた言語で再実装されたフォワード関数を持つさまざまなモデル サイズ。 お客様は、同じライブラリに基づいて他のモデル アーキテクチャを実装できます。 AWS Neuron に最適化されたトランスフォーマー デコーダー クラスは、PyHLO と呼ばれる構文を使用して XLA HLO (High Level Operations) に再実装されました。 このライブラリは、テンソル並列処理も実装して、モデルの重みを複数の NeuronCore に分割します。
モデルが非常に大きく、XNUMX つのアクセラレータ HBM メモリに収まらないため、テンソル並列処理が必要です。 AWS Neuron ランタイムによるテンソル並列処理のサポート transformers-neuronx などの集団操作を多用します。 AllReduce. 以下は、AWS Neuron 最適化トランスフォーマー デコーダー モデルのテンソル並列度 (シャード行列乗算操作に参加する NeuronCores の数) を設定するためのいくつかの原則です。
- アテンション ヘッドの数は、テンソルの並列度で割り切れる必要があります。
- モデルの重みとキーと値のキャッシュの合計データ サイズは、テンソルの並列度の 16 GB 倍未満である必要があります。
- 現在、Neuron ランタイムは、テンソル並列度 1、2、8、および 32 をサポートしています。 Trn1 Inf1 でテンソル並列度 2、4、8、24、および 2 をサポート
DJLサービング
DJLServing は、2 年 2023 月に AWS InferentiaXNUMX のサポートを追加した高性能モデル サーバーです。AWS モデル サーバー チームは、 コンテナ画像 LLM/AIGC のユースケースに役立ちます。 DJL は、DJLServing と transformers-neuronx. DJLServing モデル サーバーと transformers-neuronx ライブラリは、トランスフォーマー ライブラリを通じてサポートされる LLM を提供するために構築されたコンテナのコア コンポーネントです。 このコンテナと後続の DLC は、インストールされた AWSInferentia ドライバーとツールキットとともに、Amazon EC2 Inf2 ホスト上の AWS Inferentia チップにモデルをロードできます。 この投稿では、コンテナーを実行する XNUMX つの方法について説明します。
最初の方法は、追加のコードを記述せずにコンテナーを実行することです。 を使用できます。 デフォルトのハンドラー シームレスなユーザー エクスペリエンスのために、サポートされているモデル名の 2 つと読み込み時間の構成可能なパラメーターを渡します。 これにより、LLM がコンパイルされ、InfXNUMX インスタンスで提供されます。 次のコードは例を示しています。
engine=Python
option.entryPoint=djl_python.transformers_neuronx
option.task=text-generation
option.model_id=facebook/opt-1.3b
option.tensor_parallel_degree=2
または、独自に作成することもできます model.py ファイルですが、DJLServing API と、この場合は、 transformers-neuronx API。 構成可能なパラメーターを serving.properties モデルのロード中に取得されるファイル。 構成可能なパラメーターの完全なリストについては、次を参照してください。 すべての DJL 構成オプション.
次のコードはサンプルです model.py ファイル。 ザ serving.properties ファイルは前に示したものと似ています。
def load_model(properties): """ Load a model based from the framework provided APIs :param: properties configurable properties for model loading specified in serving.properties :return: model and other artifacts required for inference """ batch_size = int(properties.get("batch_size", 2)) tp_degree = int(properties.get("tensor_parallel_degree", 2)) amp = properties.get("dtype", "f16") model_id = "facebook/opt-13b" model = OPTForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True) ... tokenizer = AutoTokenizer.from_pretrained(model_id) model = OPTForSampling.from_pretrained(load_path, batch_size=batch_size, amp=amp, tp_degree=tp_degree) model.to_neuron() return model, tokenizer, batch_size
Inf2 インスタンスでこれがどのように見えるか見てみましょう。
Inferentia ハードウェアを起動する
最初に、OPT-42b モデルをホストするために inf.13xlarge インスタンスを起動する必要があります。 私たちは、 深層学習 AMI ニューロン PyTorch 1.13.0 (Ubuntu 20.04) 20230226 Amazon マシン イメージ (AMI)。Docker イメージと AWS Neuron ランタイムに必要なドライバーが既に含まれているためです。
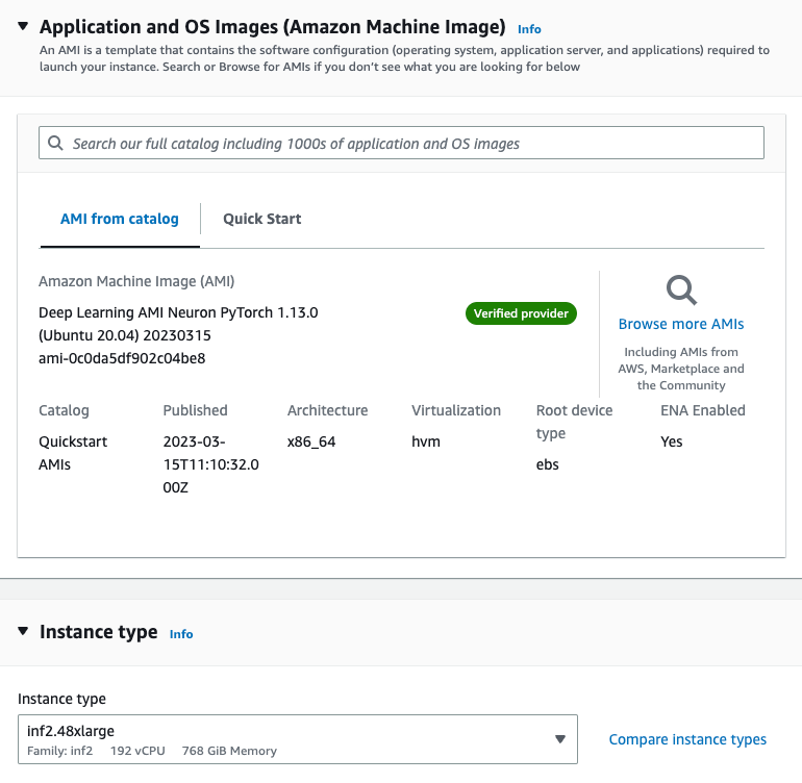
大規模な言語モデルに対応するために、インスタンスのストレージを 512 GB に増やします。

必要な依存関係をインストールしてモデルを作成する
We Jupyter ノートブック サーバーをセットアップする AMI を使用して、ディレクトリとファイルの表示と管理を容易にします。 目的のディレクトリに移動したら、サブディレクトリを設定します logs & models 作成して serving.properties ファイルにソフトウェアを指定する必要があります。

によって提供されるスタンドアロン モデルを使用できます。 DJLサービング 容器。 これは、モデルを定義する必要がないことを意味しますが、モデルを提供する必要があります serving.properties ファイル。 次のコードを参照してください。
option.model_id=facebook/opt-1.3b
option.batch_size=2
option.tensor_parallel_degree=2
option.n_positions=256
option.dtype=fp16
option.model_loading_timeout=600
engine=Python
option.entryPoint=djl_python.transformers-neuronx
#option.s3url=s3://djl-llm/opt-1.3b/ #can also specify which device to load on.
#engine=Python ---because the handles are implement in python.これは、OPT-13B モデルを使用するよう DJL モデル サーバーに指示します。 バッチサイズを 2 に設定し、 dtype=f16 モデルがニューロン デバイスに適合するようにします。 DJL サービングは動的バッチ処理をサポートし、同様の tensor_parallel_degree 複数の NeuronCore に推論を分散するため、推論リクエストのスループットを向上させることができます。 私たちも設定しました n_positions=256 これは、モデルが持つと予想される最大長を通知するためです。
私たちのインスタンスには 12 個の AWS Neuron デバイス、つまり 24 個の NeuronCore がありますが、OPT-13B モデルには 40 個のアテンション ヘッドが必要です。 たとえば、 tensor_parallel_degree=8 これは、8 個の NeuronCore ごとに 40 つのモデル インスタンスがホストされることを意味します。 必要なアテンション ヘッド (8) を NeuronCore の数 (5) で割ると、各 NeuronCore に 10 つのアテンション ヘッド、つまり各 AWS Neuron デバイスに XNUMX のアテンション ヘッドが割り当てられます。
次のサンプルを使用できます model.py モデルを定義し、ハンドラー関数を作成するファイル。 ニーズに合わせて編集できますが、サポートされていることを確認してください transformers-neuronx.
cat serving.propertiesoption.tensor_parallel_degree=2 option.batch_size=2 option.dtype=f16 engine=Pythoncat model.pyimport torch
import tempfile
import os from transformers.models.opt import OPTForCausalLM
from transformers import AutoTokenizer
from transformers_neuronx import dtypes
from transformers_neuronx.module import save_pretrained_split
from transformers_neuronx.opt.model import OPTForSampling
from djl_python import Input, Output model = None def load_model(properties): batch_size = int(properties.get("batch_size", 2)) tp_degree = int(properties.get("tensor_parallel_degree", 2)) amp = properties.get("dtype", "f16") model_id = "facebook/opt-13b" load_path = os.path.join(tempfile.gettempdir(), model_id) model = OPTForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True) dtype = dtypes.to_torch_dtype(amp) for block in model.model.decoder.layers: block.self_attn.to(dtype) block.fc1.to(dtype) block.fc2.to(dtype) model.lm_head.to(dtype) save_pretrained_split(model, load_path) tokenizer = AutoTokenizer.from_pretrained(model_id) model = OPTForSampling.from_pretrained(load_path, batch_size=batch_size, amp=amp, tp_degree=tp_degree) model.to_neuron() return model, tokenizer, batch_size def infer(seq_length, prompt): with torch.inference_mode(): input_ids = torch.as_tensor([tokenizer.encode(text) for text in prompt]) generated_sequence = model.sample(input_ids, sequence_length=seq_length) outputs = [tokenizer.decode(gen_seq) for gen_seq in generated_sequence] return outputs def handle(inputs: Input): global model, tokenizer, batch_size if not model: model, tokenizer, batch_size = load_model(inputs.get_properties()) if inputs.is_empty(): # Model server makes an empty call to warmup the model on startup return None data = inputs.get_as_json() seq_length = data["seq_length"] prompt = data["text"] outputs = infer(seq_length, prompt) result = {"outputs": outputs} return Output().add_as_json(result)
mkdir -p models/opt13b logs
mv serving.properties model.py models/opt13b
サービング コンテナを実行する
推論前の最後のステップは、DJL サービング コンテナーの Docker イメージをプルし、インスタンスで実行することです。
docker pull deepjavalibrary/djl-serving:0.21.0-pytorch-inf2コンテナー イメージをプルしたら、次のコマンドを実行してモデルをデプロイします。 を含む正しいディレクトリにいることを確認してください logs & models コマンドがこれらをコンテナーのサブディレクトリにマップするため /opt/ディレクトリ。
docker run -it --rm --network=host -v `pwd`/models:/opt/ml/model -v `pwd`/logs:/opt/djl/logs -u djl --device /dev/neuron0 --device /dev/neuron10 --device /dev/neuron2 --device /dev/neuron4 --device /dev/neuron6 --device /dev/neuron8 --device /dev/neuron1 --device /dev/neuron11 -e MODEL_LOADING_TIMEOUT=7200 -e PREDICT_TIMEOUT=360 deepjavalibrary/djl-serving:0.21.0-pytorch-inf2 serve
推論を実行する
モデルをデプロイしたので、簡単な CURL コマンドでテストして、JSON データをエンドポイントに渡します。 バッチ サイズを 2 に設定しているため、対応する入力数を渡します。
curl -X POST "http://127.0.0.1:8080/predictions/opt13b" -H 'Content-Type: application/json' -d '{"seq_length":2048, "text":[ "Hello, I am a language model,", "Welcome to Amazon Elastic Compute Cloud," ] }'
上記のコマンドは、コマンド ラインで応答を生成します。 モデルはかなりおしゃべりですが、その応答はモデルを検証します。 Inferentia のおかげで、LLM で推論を実行できました。
クリーンアップ
コストを節約するために、完了したら EC2 インスタンスを削除することを忘れないでください。
まとめ
この投稿では、Amazon EC2 Inf2 インスタンスをデプロイして LLM をホストし、大規模なモデル推論コンテナを使用して推論を実行しました。 AWS Inferentia と AWS Neuron SDK がどのように相互作用して、最適な価格対性能比で推論用の LLM を簡単にデプロイできるかを学びました。 Inferentia のその他の機能と新しいイノベーションに関する最新情報にご期待ください。 Neuron のその他の例については、次を参照してください。 aws-ニューロン-サンプル.
著者について
 チンウェイ・リー アマゾンウェブサービスの機械学習スペシャリストです。 彼は博士号を取得しました。 アドバイザーの研究助成金口座を破り、約束したノーベル賞を授与できなかった後、オペレーションズリサーチで。 現在、彼は金融サービスおよび保険業界の顧客がAWSで機械学習ソリューションを構築するのを支援しています。 暇なときは、読書と教育が好きです。
チンウェイ・リー アマゾンウェブサービスの機械学習スペシャリストです。 彼は博士号を取得しました。 アドバイザーの研究助成金口座を破り、約束したノーベル賞を授与できなかった後、オペレーションズリサーチで。 現在、彼は金融サービスおよび保険業界の顧客がAWSで機械学習ソリューションを構築するのを支援しています。 暇なときは、読書と教育が好きです。
 ピーター・チョン はAWSのソリューションアーキテクトであり、お客様がデータから洞察を発見できるよう支援することに情熱を注いでいます。 彼は、組織が公共部門と民間部門の両方でデータ主導の意思決定を行うのに役立つソリューションを構築してきました。 彼は、すべてのAWS認定とXNUMXつのGCP認定を保持しています。 彼はコーヒーを飲み、料理をし、活動を続け、家族と過ごす時間を楽しんでいます。
ピーター・チョン はAWSのソリューションアーキテクトであり、お客様がデータから洞察を発見できるよう支援することに情熱を注いでいます。 彼は、組織が公共部門と民間部門の両方でデータ主導の意思決定を行うのに役立つソリューションを構築してきました。 彼は、すべてのAWS認定とXNUMXつのGCP認定を保持しています。 彼はコーヒーを飲み、料理をし、活動を続け、家族と過ごす時間を楽しんでいます。
 アーキブ・アンサリ は、Amazon SageMakerInferenceチームのソフトウェア開発エンジニアです。 彼は、SageMakerの顧客がモデルの推論とデプロイを加速するのを支援することに焦点を当てています。 余暇には、ハイキング、ランニング、写真撮影、スケッチを楽しんでいます。
アーキブ・アンサリ は、Amazon SageMakerInferenceチームのソフトウェア開発エンジニアです。 彼は、SageMakerの顧客がモデルの推論とデプロイを加速するのを支援することに焦点を当てています。 余暇には、ハイキング、ランニング、写真撮影、スケッチを楽しんでいます。
 青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
青蘭 AWS のソフトウェア開発エンジニアです。 彼は、高性能 ML 推論ソリューションや高性能ロギング システムなど、Amazon でいくつかの挑戦的な製品に取り組んできました。 Qing のチームは、Amazon Advertising で最初の XNUMX 億パラメータ モデルを成功裏に立ち上げ、非常に低いレイテンシーを必要としました。 Qing は、インフラストラクチャの最適化とディープ ラーニングの高速化に関する深い知識を持っています。
 フランク・リュー AWSディープラーニングのソフトウェアエンジニアです。 彼は、ソフトウェアエンジニアと科学者のための革新的な深層学習ツールの構築に焦点を当てています。 余暇には、友達や家族と一緒にハイキングを楽しんでいます。
フランク・リュー AWSディープラーニングのソフトウェアエンジニアです。 彼は、ソフトウェアエンジニアと科学者のための革新的な深層学習ツールの構築に焦点を当てています。 余暇には、友達や家族と一緒にハイキングを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/deploy-large-language-models-on-aws-inferentia2-using-large-model-inference-containers/

