多くの組織は、アイデンティティ プロバイダー (IdP) を使用して、ユーザーの認証、属性の管理、グループ メンバーシップの管理を行い、安全で効率的な一元的な ID 管理を実現しています。次を使用してデータ アーキテクチャを最新化している可能性があります。 Amazonレッドシフト データ レイクとデータ ウェアハウス内のデータへのアクセスを可能にし、IdP ID に基づいてデータ アクセスを定義および管理する一元化されたスケーラブルな方法を探しています。 AWSレイクフォーメーション 分析や機械学習 (ML) 用のデータを一元的に管理、保護し、グローバルに共有することが簡単になります。現在、ユーザー ID とグループをマップする必要がある場合があります。 AWS IDおよびアクセス管理 (IAM) ロールとデータ アクセス許可は、Lake Formation 内の IAM ロール レベルで定義されます。新しいグループの作成時に IAM ロール マッピングを使用して IdP グループを設定および維持するには時間がかかり、その時点でどのサービスからどのデータにアクセスしたかを把握することが困難になるため、この設定は効率的ではありません。
アマゾンレッドシフト、 アマゾンクイックサイト、Lake Formation は、新しい信頼できる ID 伝播機能と統合されるようになりました。 AWS IAM アイデンティティ センター サービス間でシームレスにユーザーを認証します。この投稿では、Amazon Redshift と Lake Formation を使用して信頼できる ID 伝播を設定する 2 つのユースケースについて説明します。
ソリューションの概要
信頼できる ID の伝播は、データ権限管理を一元化し、サービス境界を越えて IdP ID に基づいてリクエストを承認したい組織に新しい認証オプションを提供します。 IAM Identity Center を使用すると、既存の IdP を構成してユーザーとグループを管理し、Lake Formation を使用してこれらの IdP ID のカタログ リソースに対するきめ細かいアクセス制御権限を定義できます。 Amazon Redshift は、データをクエリする際の ID 伝播をサポートします。 AmazonRedshiftスペクトラム とと AmazonRedshiftデータ共有、および使用できます AWS クラウドトレイル IdP ID によるデータ アクセスを監査して、組織が規制およびコンプライアンスの要件を満たすのを支援します。
この新機能を使用すると、ユーザーはシングル サインオン エクスペリエンスで QuickSight から Amazon Redshift に接続し、直接クエリ データセットを作成できます。これは、IAM Identity Center を共有アイデンティティ ソースとして使用することで有効になります。信頼できる ID の伝播では、ダッシュボードなどの QuickSight アセットが他のユーザーと共有される場合、各 QuickSight ユーザーのデータベース権限は、エンドユーザー ID を QuickSight から Amazon Redshift に伝播し、個々のデータ権限を強制することによって適用されます。使用例に応じて、作成者は QuickSight で追加の行レベルおよび列レベルのセキュリティを適用できます。
次の図は、ソリューション アーキテクチャの例を示しています。
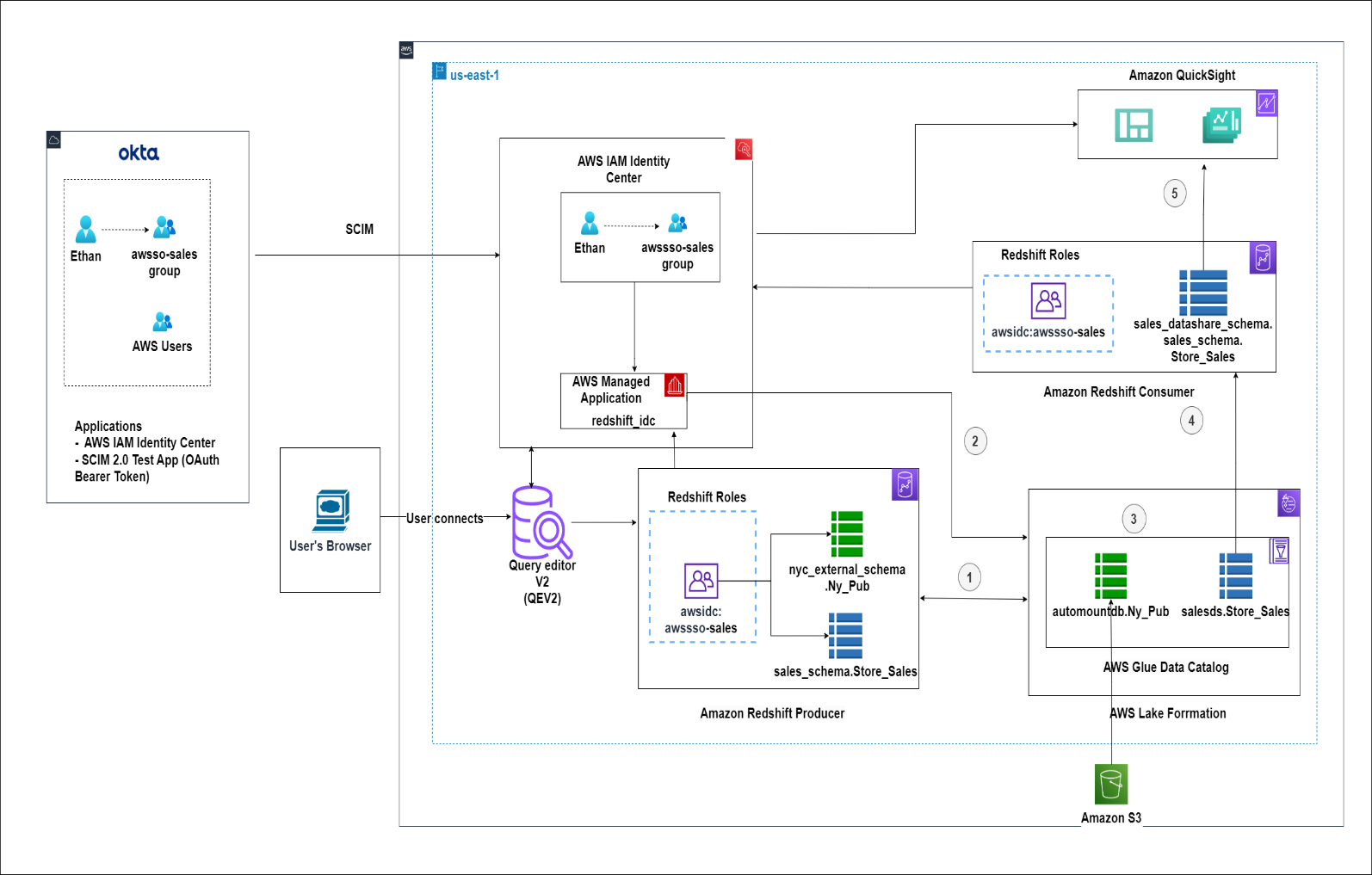
この投稿では、Amazon Redshift と Lake Formation を使用して信頼できる ID の伝播を設定する方法について説明します。次のユースケースをカバーします。
- 湖の形成による赤方偏移スペクトル
- Lake Formation との Redshift データ共有
前提条件
このチュートリアルでは、この投稿の手順に従うために、Lake Formation 管理者ロールまたは同様のロールを設定していることを前提としています。データ レイク管理者の権限の設定の詳細については、次を参照してください。 データレイク管理者の作成.
さらに、次のリソースを作成する必要があります (詳細については、「 AWS IAM Identity Center を使用して Okta を Amazon Redshift Query Editor V2 と統合し、シームレスなシングル サインオンを実現します:
- ユーザーとグループを同期するために IAM Identity Center と統合された Okta アカウント
- IAM Identity Center を使用した Redshift 管理アプリケーション
- IAM Identity Center 統合が有効になっている Redshift ソースクラスター
- IAM Identity Center 統合が有効になっている Redshift ターゲットクラスター (Amazon Redshift ロールベースのアクセスを設定するセクションをスキップできます)
- Redshift アプリケーションに割り当てられた IAM Identity Center のユーザーとグループ
- Redshift Query Editor v2 へのアクセスを有効にするために AWS アカウントに割り当てられた権限セット
- IAM Identity Center と統合するために、Redshift マネージド アプリケーションで使用される IAM ロールに以下の権限を追加します。
使用例 1: Lake Formation を使用した赤方偏移スペクトル
この使用例では、次の前提条件があることを前提としています。
- にログインします。 AWSマネジメントコンソール IAM管理者として。
- CloudShell または AWS CLI に移動し、データをコピーするバケット名を指定して次の AWS CLI コマンドを実行します。
この投稿では、 AWSGlueクローラー 外部テーブルを作成するには ny_pub Apache Parquet 形式で Amazon S3 の場所に保存されます s3://<bucketname>/data/NY-Pub/。次のステップでは、次を使用してソリューション リソースを作成します。 AWS CloudFormation という名前のスタックを作成します CrawlS3Source-NYTaxiData in us-east-1.
- ダウンロード .yml ファイル or CloudFormation スタックを起動する.
スタックは次のリソースを作成します。
- クローラー
NYTaxiCrawler新しい IAM ロールとともにAWSGlueServiceRole-RedshiftAutoMount - AWS Glue データベース
automountdb
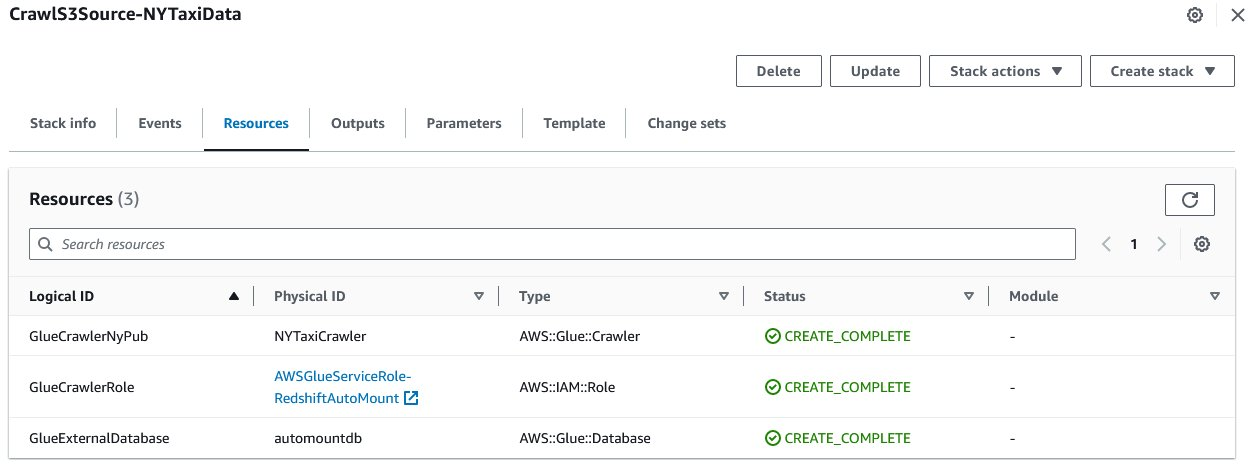
スタックが完了したら、次の手順に進んでリソースのセットアップを完了します。
- AWS Glueコンソールの、 データカタログ ナビゲーション ペインで、 Crawlers.
- Open
NYTaxiCrawler選択して 編集.
- データソースと分類器を選択する、選択する 編集.

- 情報元、選択する S3.
- S3パス、 入る
s3://<bucketname>/data/NY-Pub/. - 選択する S3 データソースを更新する.
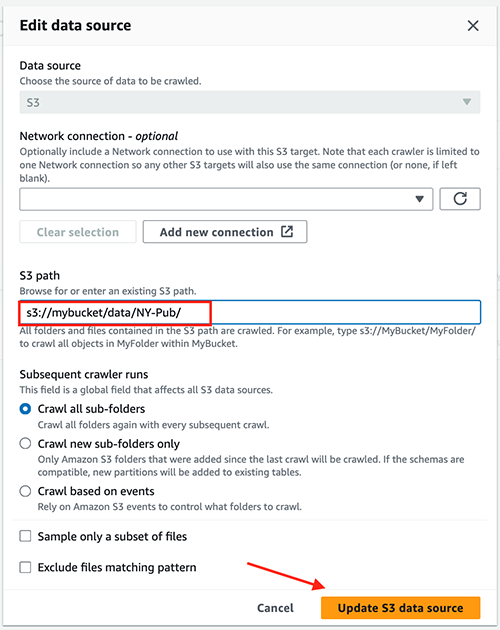
- 選択する Next 選択して アップデイト.
- 選択する クローラーを実行する.

クローラーが完了すると、という新しいテーブルが表示されます。 ny_pub データカタログの automountdb データベース。
リソースを作成したら、次のセクションの手順を実行して、AWS Glue テーブルに Lake Formation のアクセス許可を設定します。 ny_pub sales IdP グループを作成し、Redshift Spectrum 経由でアクセスします。
Redshift 管理アプリケーションの Lake Formation 伝播を有効にする
次の手順を実行して、で作成した Redshift マネージド アプリケーションの Lake Formation 伝播を有効にします。 AWS IAM Identity Center を使用して Okta を Amazon Redshift Query Editor V2 と統合し、シームレスなシングル サインオンを実現します:
- 管理者としてコンソールにログインします。
- Amazon Redshiftコンソールで、 IAM ID センター接続 ナビゲーションペインに表示されます。
- で始まるマネージド アプリケーションを選択します
redshift-iad選択して 編集.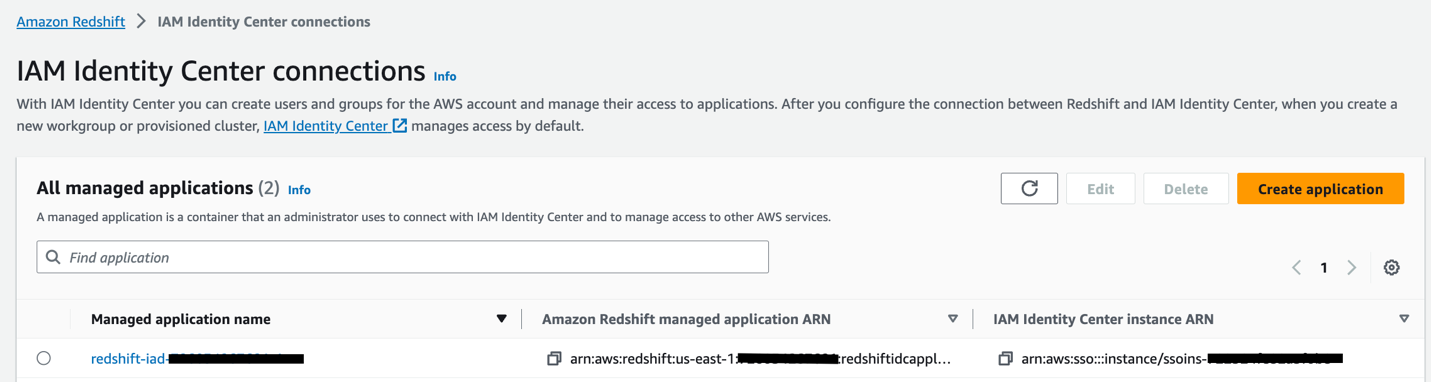
- 選択 AWS Lake Formation のアクセス許可を有効にする 下 信頼できるアイデンティティの伝播 変更を保存します。
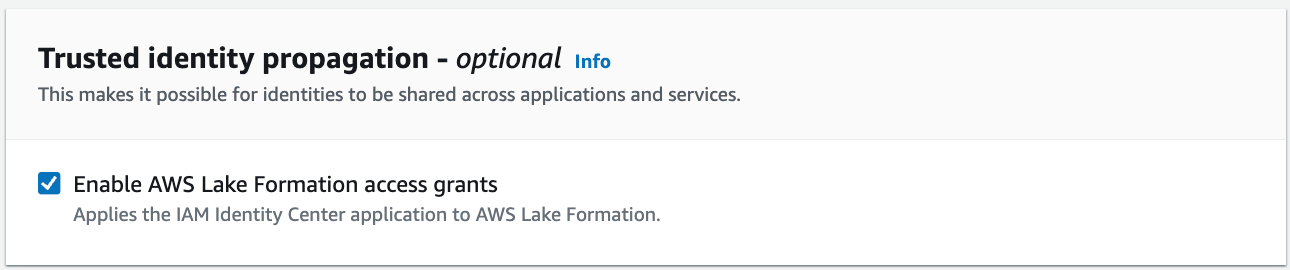
Lake Formation を IAM Identity Center アプリケーションとして設定する
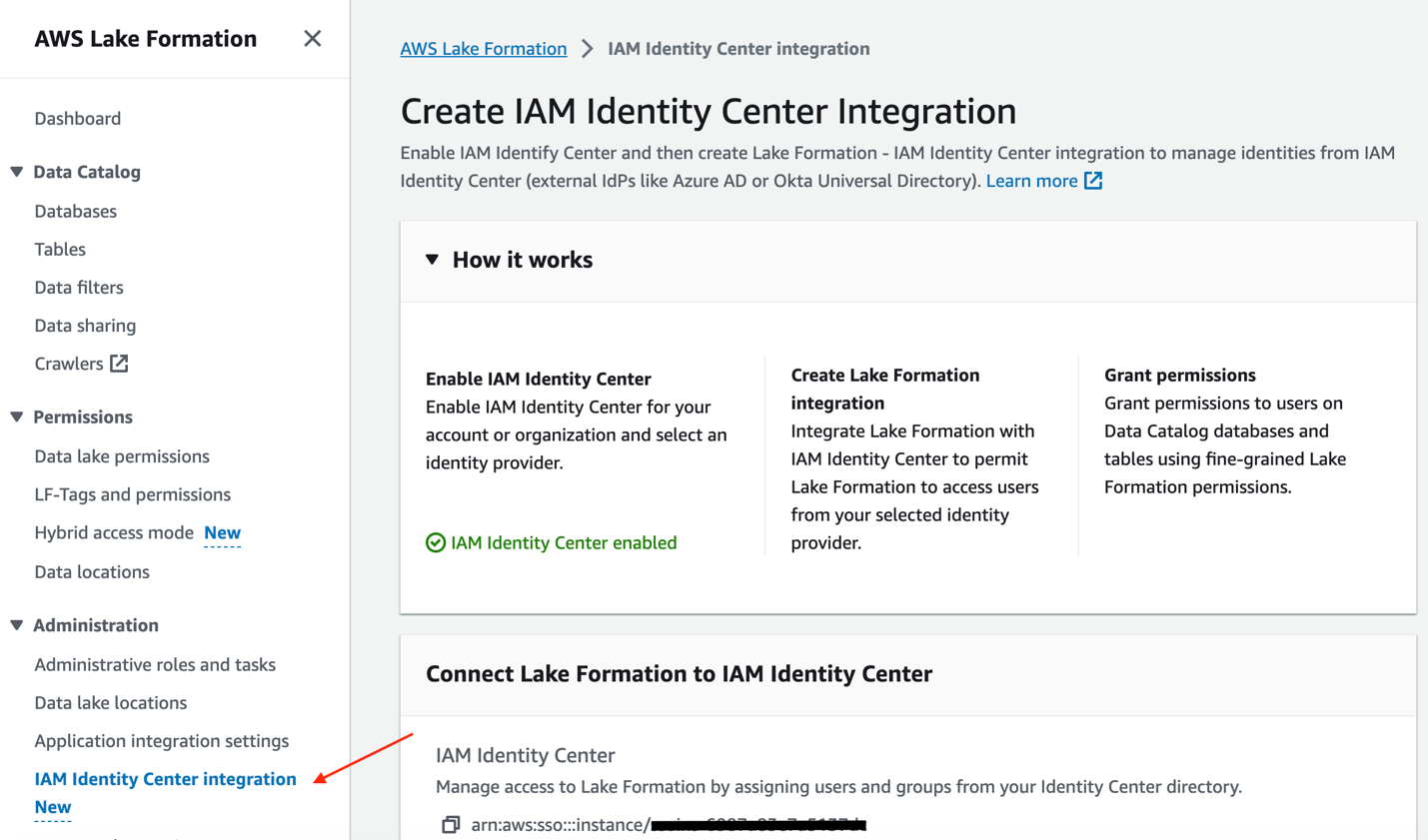
Lake Formation を IAM Identity Center アプリケーションとして設定するには、次の手順を実行します。
- レイクフォーメーションコンソールの 管理部門 ナビゲーション ペインで、 IAM ID センターの統合.
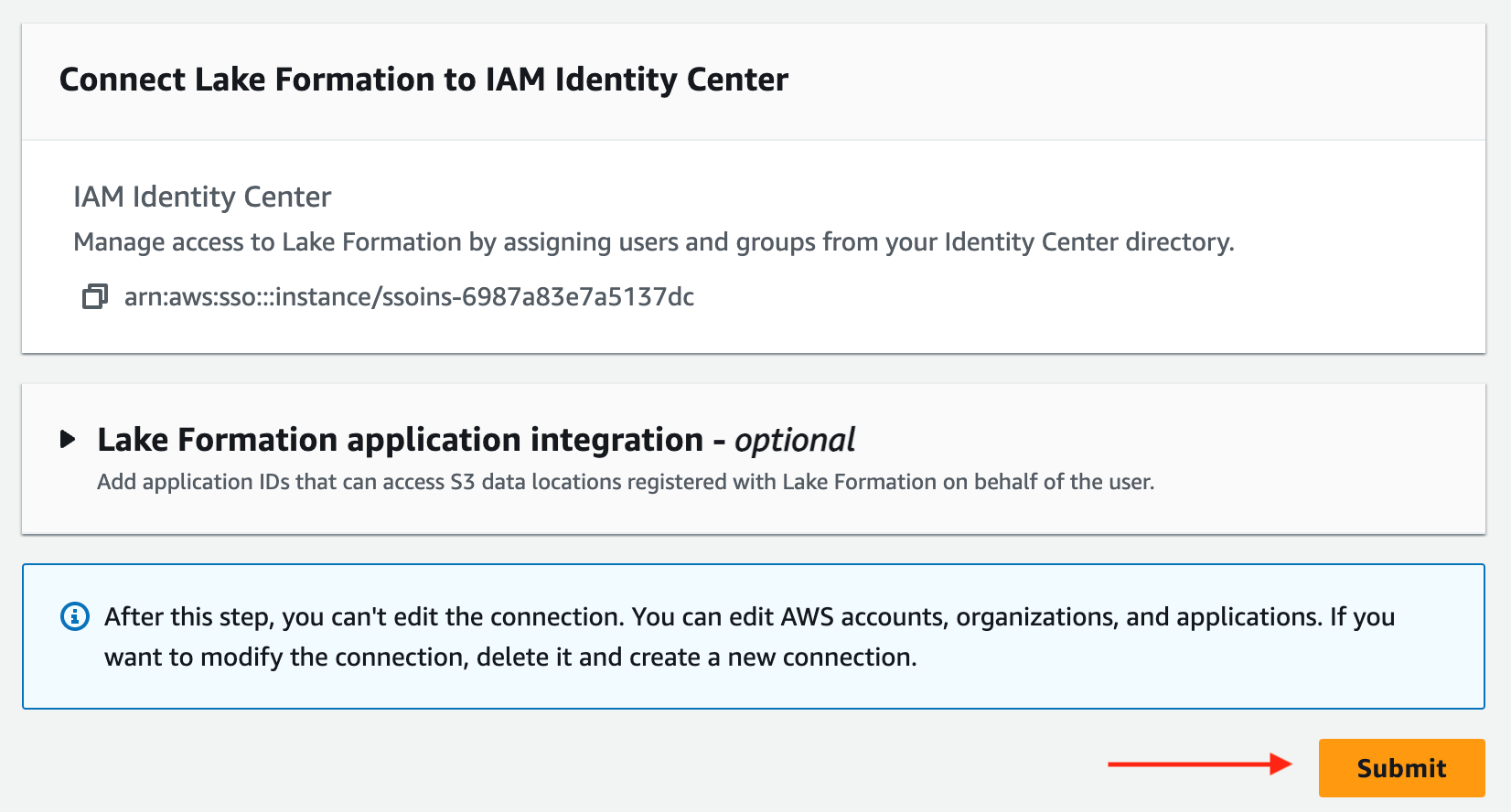
- オプションを確認して選択します 送信 Lake Formation の統合を有効にします。
統合ステータスは次のように更新されます。 ご注文完了.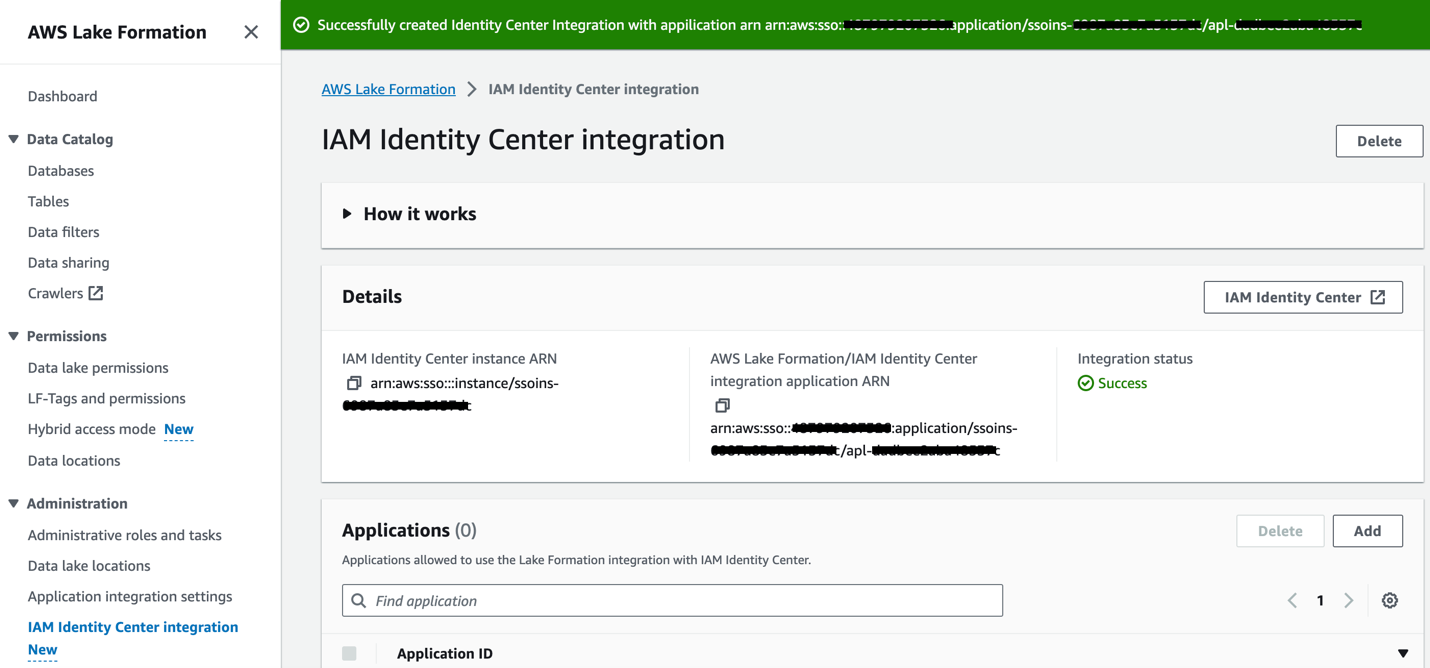 あるいは、次のコマンドを実行することもできます。
あるいは、次のコマンドを実行することもできます。
Lake Formationにデータを登録する
このセクションでは、Lake Formation にデータを登録します。次の手順を実行します。
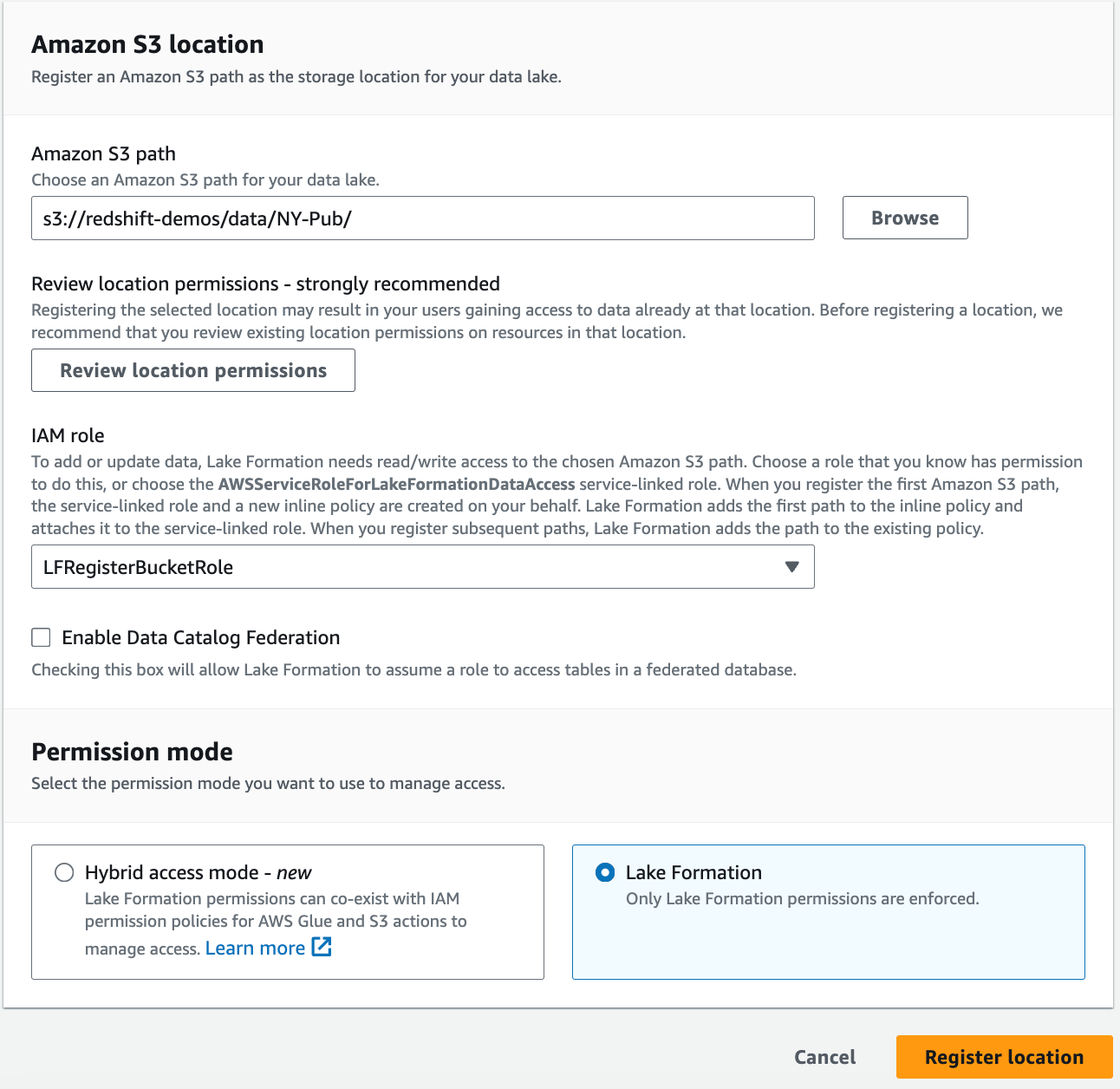
- レイクフォーメーションコンソールの 管理部門 ナビゲーション ペインで、 データレイクの場所.
- 選択する 登録場所.
- AmazonS3パス、テーブル データが存在するバケットを入力します (
s3://<bucketname>/data/NY-Pub/). - IAMの役割、Lake Formation のユーザー定義ロールを選択します。詳細については、以下を参照してください。 ロケーションの登録に使用されるロールの要件.
- 許可モード選択 湖の形成.
- 選択する 登録場所.
次に、 IAMAllowedPrincipal グループにはデータベースに対する権限がありません。
- レイクフォーメーションコンソールの データカタログ ナビゲーション ペインで、 データベース.
- 選択
automountdbそして、上 メニュー、選択 権限の表示. - If
IAMAllowedPrincipalがリストされている場合は、プリンシパルを選択して、 取り消す.
- これらの手順を繰り返して、テーブルの権限を確認します。
ny_pub.
AWS Glue データベースとテーブルに対する IAM Identity Center グループのアクセス許可を付与します。
IAM Identity Center グループにデータベース権限を付与するには、次の手順を実行します。
- レイクフォーメーションコンソールの データカタログ ナビゲーション ペインで、 データベース.
- データベースを選択します
automountdbそして、上 メニュー、選択 グラント. - 選択する 助成金データベース.
- [プリンシパル] で、次を選択します。 IAM アイデンティティ センター 選択して Add.

- ユーザーとグループを初めて割り当てる場合は、ポップアップ ウィンドウで、 始める.
- 検索バーに「IAM Identity Center」グループを入力し、グループを選択します。
- 選択する 割り当てます.
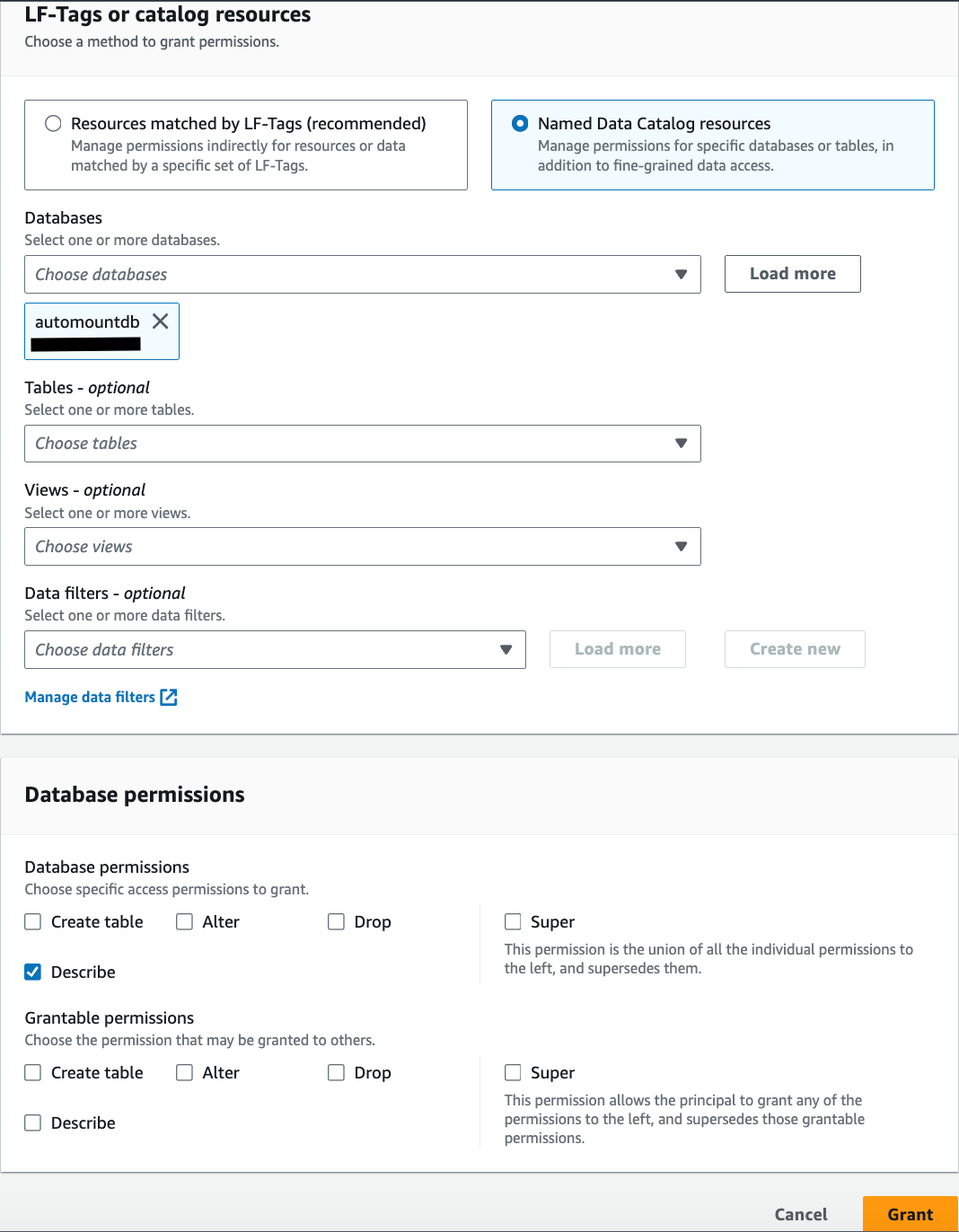
- LF-タグまたはカタログリソース,
automountdbはすでに選択されています データベース. - 選択 説明する for データベースのアクセス許可.
- 選択する グラント 権限を適用します。
あるいは、次のコマンドを実行することもできます。
次に、テーブル権限を IAM Identity Center グループに付与します。
- データカタログ ナビゲーション ペインで、 データベース.
- データベースを選択します
automountdbそして、上 メニュー、選択 グラント. - プリンシパル選択 IAM アイデンティティ センター 選択して Add.
- 検索バーに「IAM Identity Center」グループを入力し、グループを選択します。
- 選択する 割り当てます.
- LF-タグまたはカタログリソース,
automountdbはすでに選択されています データベース. - テーブル類、選択する
ny_pub.
- 選択 説明する & 選択 for テーブルのアクセス許可.
- 選択する グラント 権限を適用します。
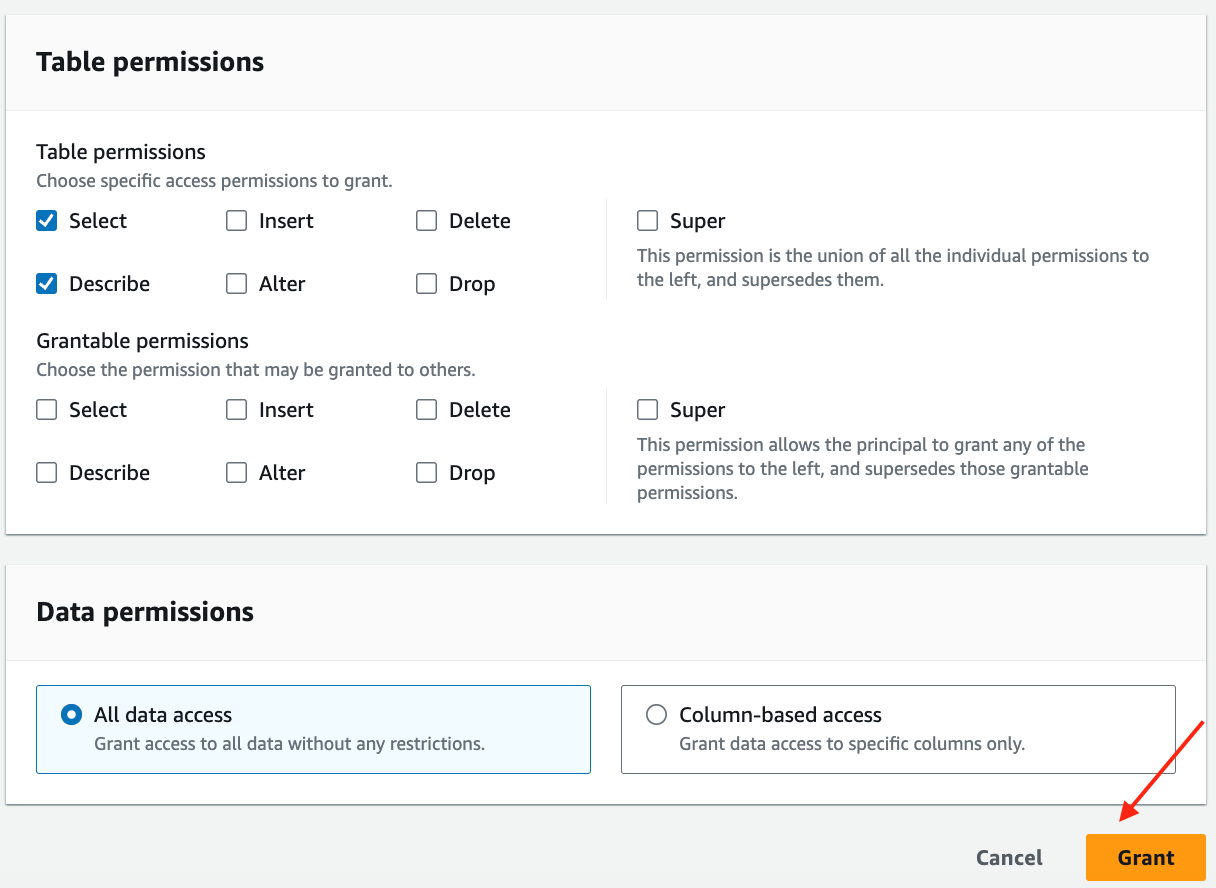
-
-
あるいは、次のコマンドを実行することもできます。
IAM Identity Center グループの Redshift Spectrum テーブル アクセスをセットアップする
Redshift Spectrum テーブルへのアクセスを設定するには、次の手順を実行します。
- 管理者ロールを使用して Amazon Redshift コンソールにサインインします。
- クエリ エディター v2 に移動します。
- クラスターの横にあるオプション メニュー (3 つのドット) を選択し、 接続を作成する.
- 管理者ユーザーとして接続し、次のコマンドを実行して、
ny_pub営業グループが利用できる S3 データレイク内のデータ:
IAM Identity Center ユーザーとして Redshift Spectrum アクセスを検証する
アクセスを検証するには、次の手順を実行します。
- Amazon Redshift コンソールで、Query Editor v2 に移動します。
- クラスターの横にあるオプション メニュー (3 つのドット) を選択し、 接続を作成する
- [接続] オプションで [IAM ID センター] オプションを選択します。ブラウザーのポップアップで Okta のユーザー名とパスワードを入力します。
- フェデレーション ユーザーとして接続したら、次の SQL コマンドを実行して ny_pub データ レイク テーブルをクエリします。
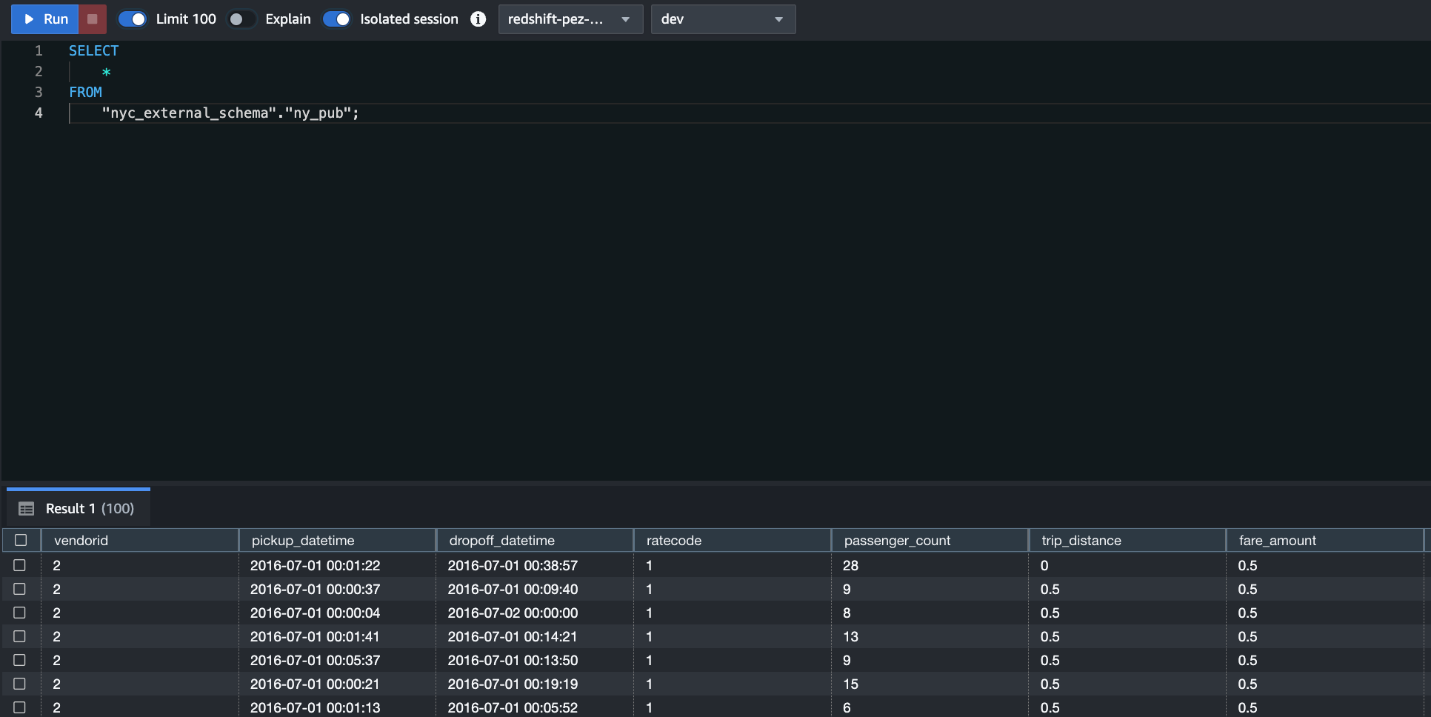
ユースケース 2: Lake Formation との Redshift データ共有
この使用例では、IAM Identity Center と Amazon Redshift の統合が設定されており、前のセクションで説明した手順に従って Lake Formation の伝播が有効になっていることが前提となっています。
オブジェクトとのデータ共有を作成し、それをデータ カタログと共有します
データ共有を作成するには、次の手順を実行します。
- 管理者ロールを使用して Amazon Redshift コンソールにサインインします。
- クエリ エディター v2 に移動します。
- Redshift ソースクラスターの横にあるオプションメニュー (3 つのドット) を選択し、 接続を作成する.
- [データベース ユーザー名を使用した一時的な資格情報] オプションを使用して管理者ユーザーとして接続し、次の SQL コマンドを実行してデータ共有を作成します。
- を選択してデータ共有を承認します。 データ共有 ナビゲーション ページでデータ共有を選択する
salesdb. - データ共有を選択し、 承認する.
これで、データ共有を Lake Formation に AWS Glue データベースとして登録できるようになりました。
- データ レイク管理者の IAM ユーザーまたはロールとして Lake Formation コンソールにサインインします。
- データカタログ ナビゲーション ペインで、 データ共有 Redshift データ共有の招待状を表示します。 タブには何も表示されないことに注意してください。
- データ共有の販売を選択し、 招待状の確認.
- 詳細を確認したら、選択してください 同意.
- AWS Glue データベースの名前 (例: salesds) を入力し、選択します。 レビューと作成にスキップ.
AWS Glue データベースが Redshift データ共有上に作成されると、以下で表示できます。 共有データベース.
IAM Identity Center ユーザーグループに AWS Glue データベースとテーブルに対するアクセス許可を付与します。
IAM Identity Center グループにデータベース権限を付与するには、次の手順を実行します。
- レイクフォーメーションコンソールの データカタログ ナビゲーション ペインで、 データベース.
- データベース salesds を選択し、 メニュー、選択 グラント.
- 選択する 助成金データベース.
- [プリンシパル] で、次を選択します。 IAM アイデンティティ センター 選択して Add.
- ポップアップ ウィンドウの検索バーに IAM Identity Center グループ awssso と入力し、awssso-sales グループを選択します。
- 選択する 割り当てます.
- LF-タグまたはカタログリソース、salesds はすでに選択されています データベース.
- 選択 説明する for データベースのアクセス許可.
- 選択する グラント 権限を適用します。
次に、IAM Identity Center グループにテーブル権限を付与します。
- データカタログ ナビゲーション ペインで、 データベース.
- データベース salesds を選択し、 メニュー、選択 グラント.
- プリンシパル選択 IAM アイデンティティ センター 選択して Add.
- ポップアップ ウィンドウの検索バーに IAM Identity Center グループ awssso と入力し、awssso-sales グループを選択します。
- 選択する 割り当てます.
- LF-タグまたはカタログリソース、salesds はすでに選択されています データベース.
- テーブル類、 sales_schema.store_sales を選択します。
- 選択 説明する & 選択 for テーブルのアクセス許可.
- 選択する グラント 権限を適用します。
ターゲット Redshift クラスターに外部スキーマをマウントし、IAM Identity Center ユーザーのアクセスを有効にします。
次の手順を完了します。
- 管理者ロールを使用して Amazon Redshift コンソールにサインインします。
- クエリ エディター v2 に移動します。
- 管理者ユーザーとして接続し、次の SQL コマンドを実行して、AWS Glue データベースの顧客を外部スキーマとしてマウントし、販売グループへのアクセスを有効にします。
IAM Identity Center ユーザーとして Redshift データ共有にアクセスする
データ共有にアクセスするには、次の手順を実行します。
- Amazon Redshift コンソールで、Query Editor v2 に移動します。
- クラスターの横にあるオプション メニュー (3 つのドット) を選択し、 接続を作成する.
- IAM Identity Center に接続し、ブラウザーのログインに IAM Identity Center のユーザーとパスワードを入力します。
- 次の SQL コマンドを実行して、データ レイク テーブルをクエリします。
Transitive Identity Propagation を使用すると、Lake Formation ダッシュボードからデータセットへのユーザー アクセスと、データセットへのアクセスに使用されるサービスを監査できるようになり、完全な追跡可能性が提供されます。アイデンティティ センター ユーザー ID が「459e10f6-a3d0-47ae-bc8d-a66f8b054014」であるフェデレーション ユーザー Ethan の場合、以下のイベント ログが表示されます。

クリーンアップ
リソースをクリーンアップするには、次の手順を実行します。
- S3 バケットからデータを削除します。
- Lake Formation アプリケーションと、テスト用に作成した Redshift プロビジョニングされたクラスターを削除します。
- CloudFormation スタックの作成に使用した IAM 管理者として CloudFormation コンソールにサインインし、作成したスタックを削除します。
まとめ
この投稿では、IAM Identity Center を使用して Amazon Redshift と Lake Formation 全体にユーザー ID を伝播することで、分析のためのアクセス管理を簡素化する方法について説明しました。 Amazon Redshift と Lake Formation に接続して、信頼できる ID の伝播を開始する方法を学びました。また、信頼できる ID の伝播をサポートするために Redshift Spectrum とデータ共有を構成する方法も学びました。
IAM Identity Center について詳しくは、こちらをご覧ください。 Amazonレッドシフト & AWSレイクフォーメーション。ご質問やフィードバックをコメント欄に残してください。
著者について
 ハルシダ・パテル は、AWS の分析スペシャリスト プリンシパル ソリューション アーキテクトです。
ハルシダ・パテル は、AWS の分析スペシャリスト プリンシパル ソリューション アーキテクトです。
 シュリヴィディヤ・パルタサラティ AWS Lake Formation チームのシニア ビッグデータ アーキテクトです。 彼女は、データ メッシュ ソリューションを構築し、それをコミュニティと共有することを楽しんでいます。
シュリヴィディヤ・パルタサラティ AWS Lake Formation チームのシニア ビッグデータ アーキテクトです。 彼女は、データ メッシュ ソリューションを構築し、それをコミュニティと共有することを楽しんでいます。
 マニーシュシャルマ AWSのシニアデータベースエンジニアであり、大規模なデータウェアハウスおよび分析ソリューションの設計と実装にXNUMX年以上の経験があります。 彼はさまざまなAmazonRedshiftパートナーや顧客と協力して、より良い統合を推進しています。
マニーシュシャルマ AWSのシニアデータベースエンジニアであり、大規模なデータウェアハウスおよび分析ソリューションの設計と実装にXNUMX年以上の経験があります。 彼はさまざまなAmazonRedshiftパートナーや顧客と協力して、より良い統合を推進しています。
 プーロミ・ダスグプタ AWS のシニア分析ソリューション アーキテクトです。 彼女は、顧客がクラウドベースの分析ソリューションを構築してビジネス上の問題を解決できるよう支援することに情熱を注いでいます。 仕事以外では、旅行や家族と過ごすことが好きです。
プーロミ・ダスグプタ AWS のシニア分析ソリューション アーキテクトです。 彼女は、顧客がクラウドベースの分析ソリューションを構築してビジネス上の問題を解決できるよう支援することに情熱を注いでいます。 仕事以外では、旅行や家族と過ごすことが好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/simplify-access-management-with-amazon-redshift-and-aws-lake-formation-for-users-in-an-external-identity-provider/

