概要
今日のデータ主導の世界では、さまざまな業界の組織が、大量のデータ、複雑なパイプライン、効率的なデータ処理のニーズに対処しています。 Apache Airflow などの従来のデータ エンジニアリング ソリューションは、これらの困難に対処するためにデータ操作を調整および制御する上で重要な役割を果たしてきました。 しかし、テクノロジーの急速な進化に伴い、世界の状況を再構築する新たな候補者、メイジが登場しました。 データ工学.
学習目標
- サードパーティのデータをシームレスに統合および同期するには
- 変換用に Python、SQL、R でリアルタイム パイプラインとバッチ パイプラインを構築するには
- 再利用可能で、データ検証によるテストが可能なモジュール式コード
- 就寝中に複数のパイプラインを実行、監視、調整するには
- 利用可能な共有ステージング環境を待たずに、クラウド上で共同作業し、Git でバージョン管理し、パイプラインをテストします。
- Terraform テンプレートを使用した、AWS、GCP、Azure などのクラウド プロバイダーへの迅速なデプロイメント
- 非常に大規模なデータセットをデータ ウェアハウス内で直接変換するか、Spark とのネイティブ統合を通じて変換します。
- 直感的な UI による組み込みの監視、アラート、可観測性
それは丸太から落ちるのと同じくらい簡単ではないでしょうか? それならぜひメイジを試してみてください!
この記事では、Mage の特徴と機能について、私がこれまでに学んだことと、Mage を使用して構築した最初のパイプラインに焦点を当てて説明します。
この記事は、の一部として公開されました データサイエンスブログ。
目次
メイジとは?
Mage は、次の機能を備えた最新のデータ オーケストレーション ツールです。 AI に基づいて構築されています 機械学習 をモデル化し、これまでにないほどデータ エンジニアリング プロセスを合理化し、最適化することを目指しています。 これは、データ変換と統合のための簡単かつ効果的なオープンソース データ パイプライン ツールであり、Airflow のような確立されたツールの魅力的な代替手段となります。 Mage は自動化とインテリジェンスのパワーを組み合わせることで、データ処理ワークフローに革命をもたらし、データの処理方法を変革します。 Mage は、比類のない機能とユーザーフレンドリーなインターフェイスを備えたこれまでの製品とは異なり、データ エンジニアリング プロセスの簡素化と最適化に努めています。
ステップ 1: クイックインストール
Mage は、Docker、pip、conda コマンドを使用してインストールすることも、仮想マシンとしてクラウド サービスでホストすることもできます。
ドッカーを使用する
#Command line for installing Mage using Docker
>docker run -it -p 6789:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name] #Command line for installing Mage locally at on a different port
>docker run -it -p 6790:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name]ピップの使用
#installing using pip command
>pip install mage-ai
>mage start [project_name] #installing using conda
>conda install -c conda-forge mage-ai
Spark、Postgres などを使用して Mage をインストールするための追加パッケージもあります。 この例では、Google Cloud Compute Engine を使用して SSH 経由で Mage (VM として) にアクセスしました。 必要な Python パッケージをインストールした後、次のコマンドを実行しました。
#Command for installing Mage
~$ mage sudo pip3 install mage-ai
#Command for starting the project
~$ mage start nyc_trides_project Checking port 6789...
Mage is running at http://localhost:6789 and serving project /home/srinikitha_sri789/nyc_trides_proj
INFO:mage_ai.server.scheduler_manager:Scheduler status: running.ステップ 2: ビルド
Mage は、プロジェクトの要件に応じてカスタマイズできるテスト ケースを含むコードが組み込まれたブロックをいくつか提供します。

Data Loader、Data Transformer、Data Exporter ブロック (ETL) を使用して API からデータをロードし、データを変換して、さらなる分析のために Google Big Query にエクスポートしました。
各ブロックがどのように機能するかを学びましょう。
I) データローダー
「データ ローダー」ブロックは、データ ソースとパイプライン内のデータ処理の後続ステージの間のブリッジとして機能します。 データ ローダーはソースからデータを取り込み、それを適切な形式に変換して、さらなる処理に使用できるようにします。
主な機能
- データソースの接続性: データ ローダー ブロックにより、幅広いデータベース、API、クラウド ストレージ システム (Azure Blob Storage、GBQ、GCS、MySQL、S3、Redshift、Snowflake、Delta Lake など)、およびその他のストリーミング プラットフォームへの接続が可能になります。
- データ品質チェックとエラー処理: データの読み込みプロセス中に、データ品質チェックを実行して、データが正確で、一貫性があり、確立された検証基準に準拠していることを確認します。 提供されたデータ パイプライン ロジックを使用して、検出されたエラーや異常をログに記録したり、フラグを立てたり、対処したりできます。
- メタデータ管理: 取り込まれたデータに関連するメタデータは、データ ローダー ブロックによって管理およびキャプチャされます。 データ ソース、抽出タイムスタンプ、データ スキーマ、およびその他の事実はすべて、このメタデータに含まれます。 効果的なメタデータ管理により、パイプライン全体のデータリネージ、監査、およびデータ変換の追跡が容易になります。
以下のスクリーンショットは、データ ローダーを使用して API から Mage に生データをロードする様子を示しています。 データ ローダー コードを実行し、テスト ケースに正常に合格すると、出力がターミナル内のツリー構造で表示されます。
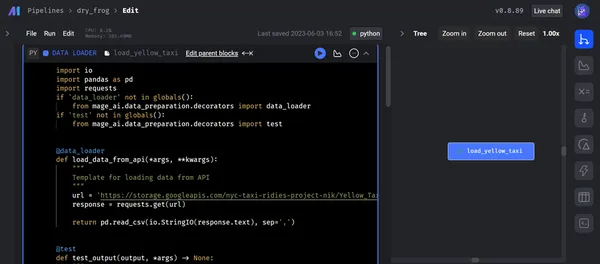
II) データ変換
「データ変換」ブロックは、受信データに対して操作を実行し、有意義な洞察を導き出し、それを下流プロセスに向けて準備します。 これには、汎用コード オプションと、データ探索、再スケーリング、および必要な列アクション、SQl、および R のための Python テンプレートでのデータ検証を使用して再利用およびテスト可能なモジュラー コードを含むスタンドアロン ファイルがあります。
主な機能
- データの結合: データ トランスフォーマー ブロックを使用すると、さまざまなソースまたはさまざまなデータセットからのデータを簡単に組み合わせてマージできます。 データ エンジニアは、内部結合、外部結合、クロス結合などのさまざまな結合が可能になるため、同様の主要な品質に基づいてデータを結合できます。 データの強化を行う場合、または複数のソースからのデータを結合する場合、この機能は非常に役立ちます。
- カスタム関数: カスタマイズされた関数と式を定義して適用して、データを操作できます。 組み込み関数を利用したり、ユーザー定義関数を作成して高度なデータ変換を行うことができます。
データをロードした後、変換コードは必要なすべての操作 (この例では、フラット ファイルをファクト テーブルとディメンション テーブルに変換) を実行し、コードをデータ エクスポーターに変換します。 データ変換ブロックを実行した後のツリー図は次のようになります。
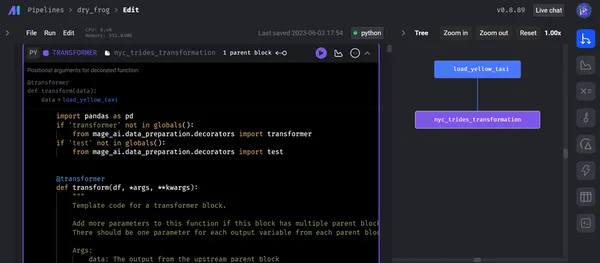
III) データエクスポーター
「データ エクスポーター」ブロックは、処理されたデータをエクスポートしてさまざまな宛先またはシステムに配信し、さらに使用、分析、または保存します。 シームレスなデータ転送と外部システムとの統合が保証されます。 Python (API、Azure Blob Storage、GBQ、GCS、MySQL、S3、Redshift、Snowflake、Delta Lake など)、SQL、R 用に提供されている既定のテンプレートを使用して、データを任意のストレージにエクスポートできます。
主な機能
- スキーマの適応: これにより、エンジニアはエクスポートされたデータの形式とスキーマを宛先システムの要件に合わせて調整できます。
- バッチ処理とストリーミング: Data Exporter ブロックはバッチ モードとストリーミング モードの両方で動作します。 事前定義された間隔で、または特定のトリガーに基づいてデータをエクスポートすることで、バッチ処理を容易にします。 さらに、データのリアルタイム ストリーミングをサポートし、ダウンストリーム システムへの継続的かつほぼ瞬時のデータ転送を可能にします。
- コンプライアンス: データのエクスポート中に機密情報を保護するための暗号化、アクセス制御、データマスキングなどの機能があります。
データ変換後、高度な分析のためにデータ エクスポーターを使用して、変換/処理されたデータを Google BigQuery にエクスポートします。 データ エクスポータ ブロックが実行されると、以下のツリー図はその後のステップを示します。
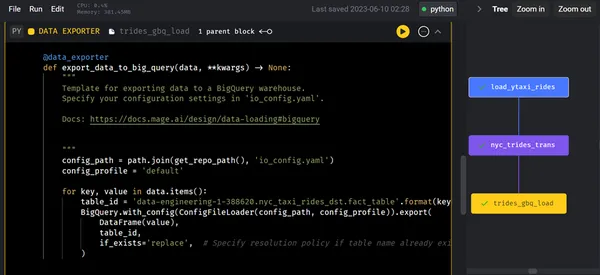

ステップ 3: プレビュー/分析
「プレビュー」フェーズでは、データ エンジニアがパイプラインの特定の時点で処理されたデータまたは中間データを検査およびプレビューできるようになります。 これは、データ変換の精度を確認し、データの品質を判断し、データについてさらに学ぶ有益な機会を提供します。
このフェーズでは、コードを実行するたびに、チャート、表、グラフの形式でフィードバックを受け取ります。 このフィードバックにより、貴重な洞察と情報を収集することができます。 インタラクティブなノートブック UI を使用して、コードの出力から結果をすぐに確認できます。 パイプラインでは、コードの各ブロックがデータを生成し、将来の利用に備えてバージョン管理、パーティション化、カタログ化が可能です。
主な機能
- Data Visualization
- データサンプリング
- データ品質評価
- 中間結果の検証
- 反復開発
- デバッグとトラブルシューティング
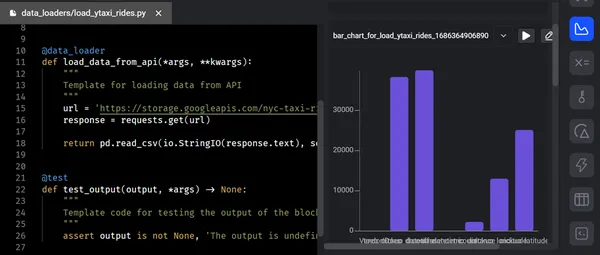

ステップ4:起動
データ パイプラインの「起動」フェーズは、処理されたデータを運用システムまたは下流システムに展開してさらなる分析を行う最終ステップを表します。 このフェーズでは、データが適切な宛先に送信され、意図した使用例でアクセスできるようになります。
主な機能
- データの展開
- 自動化とスケジューリング
- 監視とアラート
- バージョン管理とロールバック
- 化する強力なツール群
- エラー処理
維持された Terraform テンプレートを使用して、たった 2 つのコマンドで Mage を AWS、GCP、または Azure にデプロイでき、非常に大規模なデータセットをデータ ウェアハウス内で直接変換するか、Spark とのネイティブ統合を通じて変換し、組み込みの監視、アラート、およびパイプラインを運用可能にすることができます。観察性。
以下のスクリーンショットは、パイプラインの合計実行とそのステータス (成功または失敗など)、各ブロックのログ、およびそのレベルを示しています。
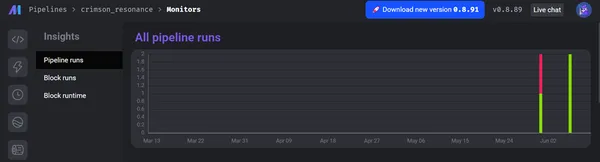
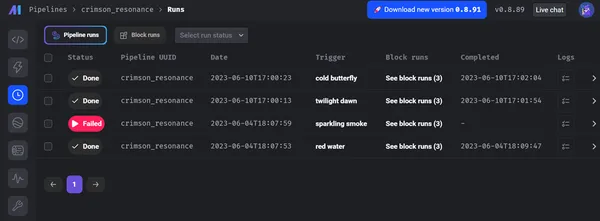
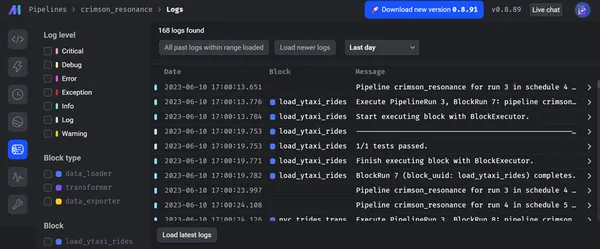
さらに、Mage はデータ ガバナンスとセキュリティを優先します。 データ エンジニアリング操作のための安全な環境を提供します。 エンドツーエンドの暗号化、アクセス制限、監査機能などの高度な組み込みセキュリティ メカニズムのおかげで。 Mage のアーキテクチャは、厳格なデータ保護ルールとベスト プラクティスに基づいており、データの整合性と機密性を保護します。 さらに、金融、電子商取引、ヘルスケアなどのさまざまな業界での Mage の可能性を強調する実際の使用例や成功事例を適用できます。
その他の相違点
| メイジ | その他のソフトウェア |
| Mage は、データを移動および変換できるデータ パイプラインを実行するためのエンジンです。 そのデータはどこにでも (S3 など) 保存でき、Sagemaker でモデルをトレーニングするために使用できます。 | セージメーカー: Sagemaker は、機械学習モデルのトレーニングに使用されるフルマネージド ML サービスです。 |
| Mage は、データの統合と変換 (ETL) のためのオープンソース データ パイプライン ツールです。 | ファイブトラン: Fivetran は、マネージド ETL サービスを提供するクローズドソースの Saas (software-as-a-service) 企業です。 |
| Mage は、データの統合と変換のためのオープンソース データ パイプライン ツールです。 Mage は、簡単な開発者エクスペリエンスを提供することに重点を置いています。 | エアバイト: AirByte は、API、アプリケーション、データベースからデータ レイク、データ ウェアハウス、その他の宛先にデータをレプリケートする、オープンソースの主要な ELT プラットフォームの XNUMX つです。 |
まとめ
結論として、データ エンジニアと分析専門家は、Mage ツールの各フェーズの機能と、データを管理および処理するための効率的なフレームワークを利用することで、データを効率的にロード、変換、エクスポート、プレビュー、展開できます。 この機能により、データ主導の意思決定の促進、貴重な洞察の抽出が可能になり、本番システムまたは下流システムへの対応が確実になります。 最先端の機能、スケーラビリティ、およびデータ ガバナンスへの重点的な取り組みが広く知られており、データ エンジニアリングの変革をもたらします。
主要な取り組み
- Mage は次のパイプラインを提供します 総合的なデータエンジニアリングこれには、データの取り込み、変換、プレビュー、展開が含まれます。 このエンドツーエンドのプラットフォームにより、迅速なデータ処理、効果的なデータ配布、シームレスな接続が保証されます。
- Mage のデータ エンジニアは、データ変換フェーズ中にさまざまな操作を適用して、データを確実にクレンジング、強化し、その後の処理に備えることができます。 プレビュー段階では、処理されたデータの検証と品質評価が可能になり、その正確性と信頼性が保証されます。
- データ エンジニアリング パイプライン全体を通じて、Mage は以下のことを提供します。 効率 & スケーラビリティ 最優先。 パフォーマンスを向上させるために、並列処理、データのパーティショニング、キャッシュなどの最適化手法が利用されます。
- メイジの起動ステージにより、 処理されたデータを簡単に転送 ダウンストリームまたは実稼働システムに送信します。 自動化、バージョン管理、エラー解決、パフォーマンスの最適化のためのツールが備わっており、信頼性の高いタイムリーなデータ送信を提供します。
よくある質問
A. Mage を際立たせる機能 (他のいくつかは最終的にこれらの機能を備えている可能性があります):
1. 簡単なUI/IDE データ パイプラインの構築と管理に使用されます。 データ パイプラインを構築すると、開発環境でも運用環境でもまったく同じように実行されます。 Airflow とは異なり、ツールのデプロイと運用環境でのインフラストラクチャの管理は非常に簡単かつシンプルです。
2. 拡張可能: 私たちは開発者を念頭に置いてツールを設計および構築し、ソース コードまたはプラグインを通じて新しい機能を簡単に追加できるようにしました。
3. モジュラー: 書き込むすべてのブロック/セルは、相互運用可能なスタンドアロン ファイルです。 つまり、他のパイプラインや他のコードベースでも使用できます。
A.Mage は現在、Python、SQL、R、PySpark、および Spark SQL (将来) をサポートしています。
A. Databricks は、Spark を実行するためのインフラストラクチャを提供します。 また、Spark でコードを実行できるノートブックも提供します。 魔術師は、AWS、GCP、さらには Databricks によって管理される Spark クラスター内でコードを実行できます。
A. はい、Mage は設計の一部として既存のデータ インフラストラクチャおよびツールとシームレスに統合します。 さまざまなデータ ストレージ プラットフォーム、データベース、API をサポートしており、好みのシステムとのスムーズな統合が可能です。
A. はい、メイジなら対応できます。 スケーラビリティとパフォーマンスの最適化機能により、変動するデータ量と処理ニーズに対応できるため、さまざまな規模やデータ処理の複雑さレベルの組織に適しています。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/06/modern-data-engineering-with-mage-empowering-efficient-data-processing/

