概要
理解した 決定木アルゴリズムの完全なフロー. これで、ランダムフォレストについて学ぶ必要がある理由を理解できます。 決定木アルゴリズムが既にある場合。 なぜランダムフォレストが必要なのですか? それは一体何なのか?決定木に。 ランダム フォレストは、教師あり機械学習アルゴリズムでもあります。 分類と回帰で広く使用されています。 しかし、決定木には過剰適合の問題があります。
オーバーフィッティングとは何か疑問に思っていますか? オーバーフィッティングは、モデルが複雑すぎてデータに適合しすぎた場合に発生します。 これは、モデルが目に見えないデータに対して正確な予測を行うことができないことを意味します。 の ランダムフォレストアルゴリズム 複数のディシジョン ツリーを作成し、それらの予測を組み合わせて、より正確な予測を作成することで、この問題に対処できます。
学習目標
- アンサンブル学習の基礎を理解する。
- ランダムフォレストの基本。
- 完全なランダム フォレストを構築する際に必要な各ステップの重要性を理解する。
- Python を使用したランダム フォレストの実用的な実装。
- オーバーフィッティングの問題がどのように解決されるかを理解する。
- また、堅牢性を向上させる方法についても理解します。
この記事は、の一部として公開されました データサイエンスブログソン.
目次
- アンサンブル テクニック: その内容と仕組み
- XNUMX つの簡単な手順に従うだけで、ランダム フォレストがどのように機能するかを理解できますか?
-
ステップ 1: 完全なトレーニング データセットを使用して複数のツリーを構築する方法
-
ステップ 2: 次のステップで複数の決定木を構築できます
-
ステップ 3: マルチツリー モデルを使用して結果を予測する場合、結果を期待するプロセスは何ですか?
-
ステップ 4: モデルが回帰または分類の結果を確定するとき、このステップを何と呼びますか?
-
まとめ
アンサンブル テクニック: それらは何であり、どのように機能するのか?
決定木では、質問に答える木は XNUMX つしかありません。 電話を買いたいとしましょう。 次のディシジョン ツリーを使用して、iPhone と Android フォンのどちらを購入するかを決定できます。
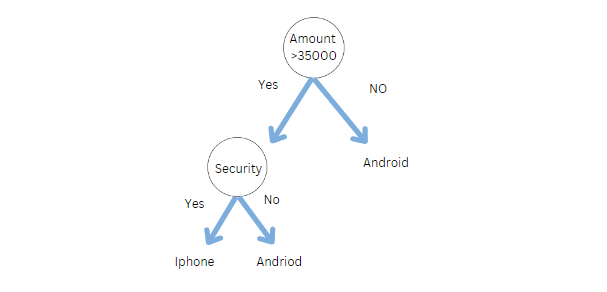
しかし、実生活でも同じことをしますか? XNUMX 人の人に電話を購入するように依頼しますか? 絶対 いいえ。家族、友人、専門家、販売員など、複数の人に尋ねます。
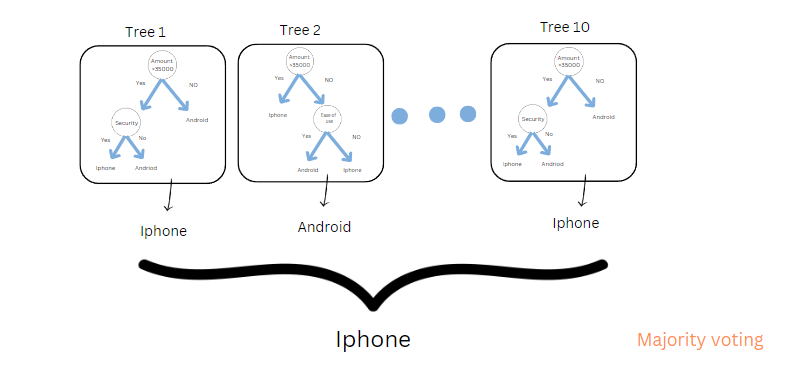
各木は各人に似ていると仮定します。 ということで、10人に聞いてみると(8人がiPhone、2人がAndroidと答えた。ランダムフォレスト分類では、最終的なアウトプットは多数決に基づく。私たちはiPhoneを買うだろう。
注: 回帰モデルを構築している場合はどうなるでしょうか? 平均または平均を使用します。
いくつかの決定木モデルを組み合わせるプロセスをランダム フォレストと呼びます。 しかし、問題は、ロジスティック、ナイーブ ベイズ、KNN などの複数のモデルを組み合わせることができるかということです。そうであれば、それを何と呼ぶのでしょうか? これをバギングとブースティングと呼びます。 これらは、機械学習で使用される XNUMX つのアンサンブル手法であり、複数のモデルの予測を組み合わせて単一のモデルのパフォーマンスを向上させます。
バギング: バギングは、複数のモデルを結合する方法です。 上で説明したように、knn、単純ベイズ、ロジスティックなど、どのモデルでもかまいません。ただし、データ入力はすべてのモデルで同じになるため、結果は同じになります。 これを処理するために、ブートストラップ アグリゲーターを使用します。
- たとえば、10 個のモデルがある場合、各モデルはトレーニング データの異なるサブセットでトレーニングします。
- 通常、最終的な予測は、すべてのモデルからの予測の平均または多数決です。
それに加えて、上記の XNUMX つの点により、バギングは分散も減らします。
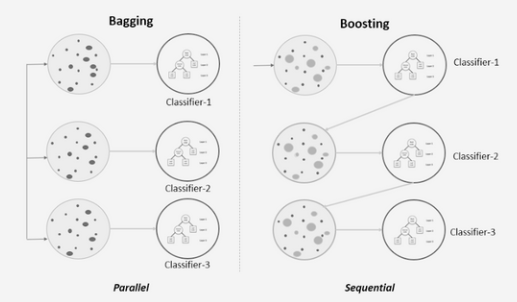
後押し: 逆に、BOOSTING は弱い学習者を組み合わせて強い学習者を生成します。. 上の画像では、シーケンシャル トレーニングに従っていることがわかります。
ブースティング アルゴリズムの種類
1.アダブースト
2.勾配ブースティング
3.XGブースト
今後の記事では、これらすべてのトピックについて説明します
ランダム フォレストの仕組みを理解するための段階的な手順
はい、4 つの簡単なステップでランダム フォレストの動作を理解することができます。 しかし、その前に、ランダム フォレストに関する XNUMX つの質問を理解する必要があります。
アンサンブル学習ランダム フォレストはどのタイプに属しますか?
これは、ランダム フォレストと呼ばれる複数の決定木を構築するバギングに属します。
ランダム フォレストを理解するには、段階的なアプローチが必要です。 これがステップバイステップのガイドです。

ステップ 1: ete トレーニング データセットを使用して複数のツリーを構築しますか?
トレーニング データセットがある場合。 モデルは、置換を使用してブートストラップ サンプルを作成します。
ブートストラップとは何ですか?
実際のトレーニング データセットから複数のサブセットを作成します。
複数のサブセットを作成する方法 行 & コラム セクションに トレーニング データセット? そして何 is 交換で?
行:
我々はと言うとき 置換(理解を深めるために下の画像を参照してください)、サブセットでは、同じ行を複数回持つことができます。 あなたが見ることができるように サブセット 2、 2行目は2回繰り返され、 サブセット3 1 行目は 2 回繰り返されます。
コラム:
1. 分類の場合は、フィーチャの総数の平方根です
例: サブセットごとに合計 4 つの機能があるとします。
4 = 2 の平方根。これは、各ツリーの 2 つの特徴です。
2. 回帰: 特徴の総数を 3 で割った値
手順 2: 次の手順で複数の決定木を構築できます
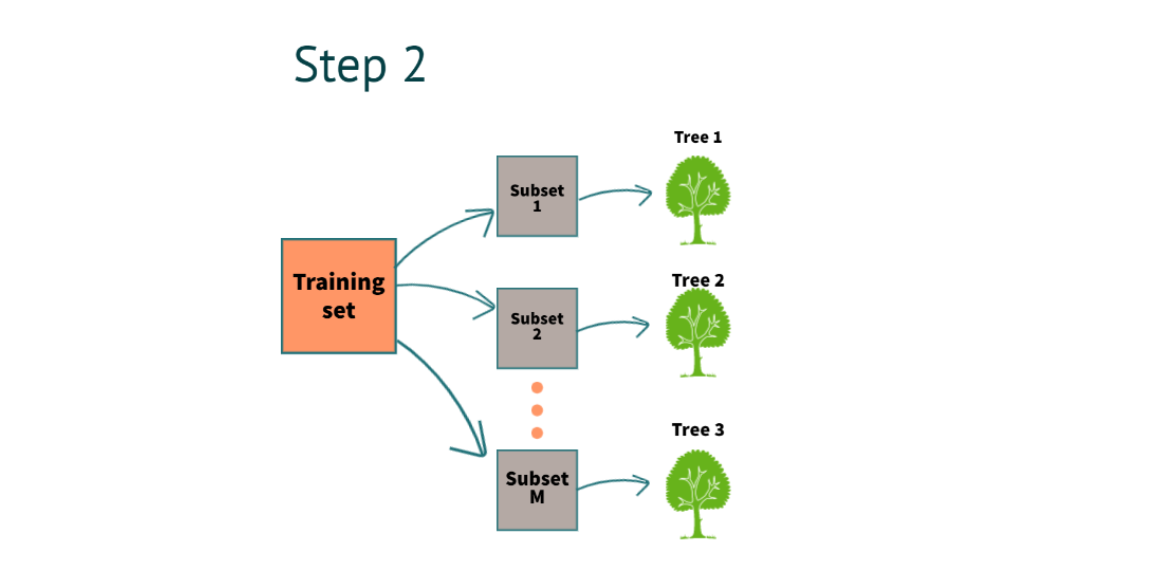
ステップ 1 が完了したら、各サブセットの決定木を作成します。 上記の例では、3 つの決定木があります。
どのようにして決定木を構築できたのか
決定木を構築するには、XNUMX つの方法を使用する必要があります。
1.ジニ
2. エントロピーと情報利得
数学の詳細な理解については、私の ディシジョン ツリーの記事 アナリティクス Vidhya で。
ステップ 3: マルチツリー モデルを使用して結果を予測する、結果を予測するプロセスとは?
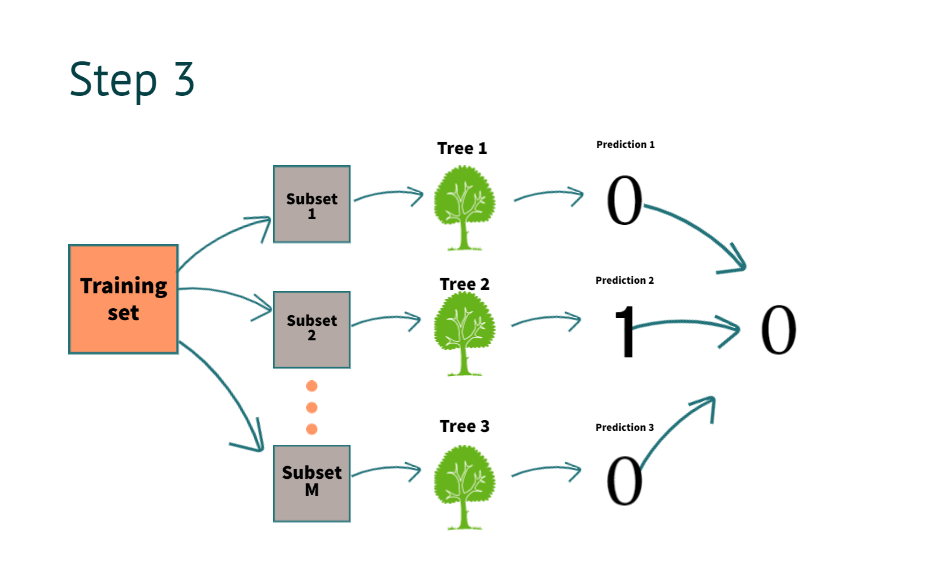
ここで決定木を作成したら、結果を取得します。 予測のための新しい情報があるとします
| 給与 | 財産 | ローン承認 |
| 10k | いいえ | ? |
モデルはそれを「0」と予測します。 画像でわかるように、上記の決定木予測をすべて組み合わせると、
すべてのツリーの予測を組み合わせるとはどういう意味ですか?
それを理解するために、ステップ XNUMX に進みます。
ステップ 4: モデルが回帰または分類の結果を確定するとき、それは何と呼ばれますか?

ステップ 4 では、集約と呼ばれる複数のツリーの予測を組み合わせるプロセスを明確に理解できます。
- 分類には、多数決を使用します
- 回帰には、平均化を使用します
これにより、ブートストラップ集約が正確に何であるかを理解できます。
さて、それがどのように役立つかを理解する必要があります。
偏差を減らします。 これは、目に見えないデータでもうまく機能する堅牢なモデルを構築するのに役立ちます。
Pythonの実装
# 必要なライブラリのインポート import pandas as pd import numpy as np from sklearn.datasets import load_iris data = load_iris()
sklearn ライブラリからアイリス データセットをロードする
# アイリス データを列名として機能名を持つ Pandas データ フレームに変換します df = pd.DataFrame(data.data, columns=data.feature_names)
# ターゲット名とターゲット コードを使用して、新しい列 'target' をデータフレームに追加します df['target'] = pd.Categorical.from_codes(data.target, data.target_names) # データフレームの最初の 5 行を出力します print(df.頭())
データをデータ フレームに変換した後、最初の 5 行を出力しています。
# データ X と y を分割 X = df.drop('target',axis=1) y = df['target']
# sklearn から train_test_split 関数をインポート from sklearn.model_selection import train_test_split
X_train、X_test、y_train、y_test = train_test_split(X、y、test_size=0.3、random_state=0)
# sklearn から RandomForestClassifier をインポートします from sklearn.ensemble import RandomForestClassifier
classifier_rf = RandomForestClassifier (random_state=42、n_jobs=-1、n_estimators=20)
Hyper パラメーターを使用したランダム フォレスト分類器を使用しています。
- Random_state (モデルを実行するたびに同じ結果を生成するのに役立ちます)
- n_jobs (すべてのプロセッサを使用します)
- n_estimators( ランダム フォレストで 20 個の決定木を使用しています。必要に応じて調整できます。
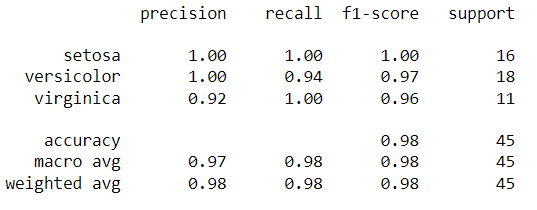
# トレーニング データを適合させる classifier_rf.fit(X_train, y_train) # テスト データを予測する y_pred = classifier_rf.predict(X_test) from sklearn.metrics import conflict_matrix, classification_report, accuracy_score print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test) 、y_pred))
予測は y_pred 変数に保存されています。 以下のレポートを使用して、実際と予測を比較できます。
まとめ
この記事では、最も一般的なアルゴリズムについて説明しました。 要約すると、ランダム フォレストについて詳しく学習しました。 重要なポイントを見てみましょう。
主な要点
- ランダム フォレストでは、情報が複数のツリーに渡されるため、単一の決定ツリーよりも精度が高くなります。
- リアルタイムでは、バランスの取れたデータセットを取得できません。そのため、ほとんどの機械学習モデルは特定の XNUMX つのクラスに偏ります。 それでも、ランダム フォレストは、データをランダム化することで、不均衡なデータセットを処理できます。
- 複数の決定木を使用して、欠落している情報を平均化します。 したがって、ランダム フォレストを使用すると、欠損値も処理できます。
- 最後に、分散を減らすことで、堅牢なモデルをリアルタイムで構築するのに役立ちます。
私の記事を楽しんでくれましたか? 以下にコメントしてください。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/02/how-does-random-forest-work/

