本日は、 ラマガード を使用している顧客がモデルを利用できるようになりました。 Amazon SageMaker ジャンプスタート。 Llama Guard は、大規模言語モデル (LLM) デプロイメントにおける入力および出力の保護機能を提供します。これは、開発者が AI モデルを使用して責任を持って構築するのを支援するオープンな信頼性と安全性のツールと評価を特徴とする Meta のイニシアチブである Purple Llama のコンポーネントの XNUMX つです。 Purple Llama は、コミュニティが責任を持って生成 AI モデルを構築できるようにするためのツールと評価をまとめています。初期リリースには、サイバー セキュリティと LLM 入出力保護機能に重点が置かれています。 Llama Guard モデルを含む、Purple Llama プロジェクト内のコンポーネントは寛容にライセンスされており、研究と商業利用の両方が可能です。
これで、SageMaker JumpStart 内で Llama Guard モデルを使用できるようになりました。 SageMaker JumpStart は、 アマゾンセージメーカー これにより、組み込みアルゴリズムやエンドツーエンドのソリューション テンプレートに加えて、基礎モデルへのアクセスが提供され、ML をすぐに開始できるようになります。
この投稿では、Llama Guard モデルをデプロイし、責任ある生成 AI ソリューションを構築する方法を説明します。
ラマガードモデル
Llama Guard は、LLM 導入用の入力および出力ガードレールを提供する Meta の新しいモデルです。 Llama Guard は、一般的なオープン ベンチマークで競争力を発揮し、潜在的に危険な出力の生成を防ぐための事前トレーニング済みモデルを開発者に提供する、オープンに利用可能なモデルです。このモデルは、公開されているデータセットの組み合わせでトレーニングされており、多くの開発者のユースケースに関連する可能性のある一般的な種類の潜在的に危険なコンテンツや違反コンテンツを検出できるようになりました。最終的に、このモデルのビジョンは、開発者がこのモデルをカスタマイズして関連するユースケースをサポートし、ベスト プラクティスを簡単に採用してオープン エコシステムを改善できるようにすることです。
Llama Guard は、開発者がチャットボット、コンテンツ管理、顧客サービス、ソーシャル メディアの監視、教育などの独自の緩和戦略に統合するための補助ツールとして使用できます。ユーザーが作成したコンテンツを公開または応答する前に Llama Guard に渡すことで、開発者は安全でないまたは不適切な言語にフラグを立て、安全で敬意を持った環境を維持するための措置を講じることができます。
SageMaker JumpStart で Llama Guard モデルを使用する方法を見てみましょう。
SageMaker の基盤モデル
SageMaker JumpStart は、Hugging Face、PyTorch Hub、TensorFlow Hub などの一般的なモデル ハブのさまざまなモデルへのアクセスを提供し、SageMaker の ML 開発ワークフロー内で使用できます。 ML の最近の進歩により、として知られる新しいクラスのモデルが誕生しました。 基礎モデルこれらは通常、数十億のパラメータでトレーニングされ、テキストの要約、デジタル アートの生成、言語翻訳など、幅広いカテゴリのユースケースに適応できます。これらのモデルのトレーニングにはコストがかかるため、顧客はこれらのモデルを自分でトレーニングするのではなく、既存の事前トレーニングされた基礎モデルを使用し、必要に応じて微調整することを望んでいます。 SageMaker は、SageMaker コンソールで選択できる厳選されたモデルのリストを提供します。
SageMaker JumpStart 内でさまざまなモデルプロバイダーの基礎モデルを検索できるようになり、基礎モデルをすぐに開始できるようになりました。さまざまなタスクやモデルプロバイダーに基づいて基礎モデルを検索し、モデルの特性や使用条件を簡単に確認できます。テスト UI ウィジェットを使用してこれらのモデルを試すこともできます。基礎モデルを大規模に使用したい場合は、モデルプロバイダーが提供する事前構築されたノートブックを使用することで、SageMaker を離れることなく簡単に使用できます。モデルは AWS でホストおよびデプロイされるため、モデルの評価または大規模な使用に使用されるデータが第三者と共有されることは決してないので、ご安心ください。
SageMaker JumpStart で Llama Guard モデルを使用する方法を見てみましょう。
SageMaker JumpStart で Llama Guard モデルを発見する
SageMaker Studio UI の SageMaker JumpStart および SageMaker Python SDK を介して Code Llama 基盤モデルにアクセスできます。このセクションでは、モデルを検出する方法について説明します。 Amazon SageMakerスタジオ.
SageMaker Studio は、単一の Web ベースのビジュアル インターフェイスを提供する統合開発環境 (IDE) であり、専用ツールにアクセスして、データの準備から ML モデルの構築、トレーニング、デプロイまで、すべての ML 開発ステップを実行できます。 SageMaker Studio の開始方法とセットアップ方法の詳細については、以下を参照してください。 Amazon SageMakerスタジオ.
SageMaker Studio では、事前トレーニングされたモデル、ノートブック、事前構築されたソリューションを含む SageMaker JumpStart にアクセスできます。 事前に構築された自動化されたソリューション.
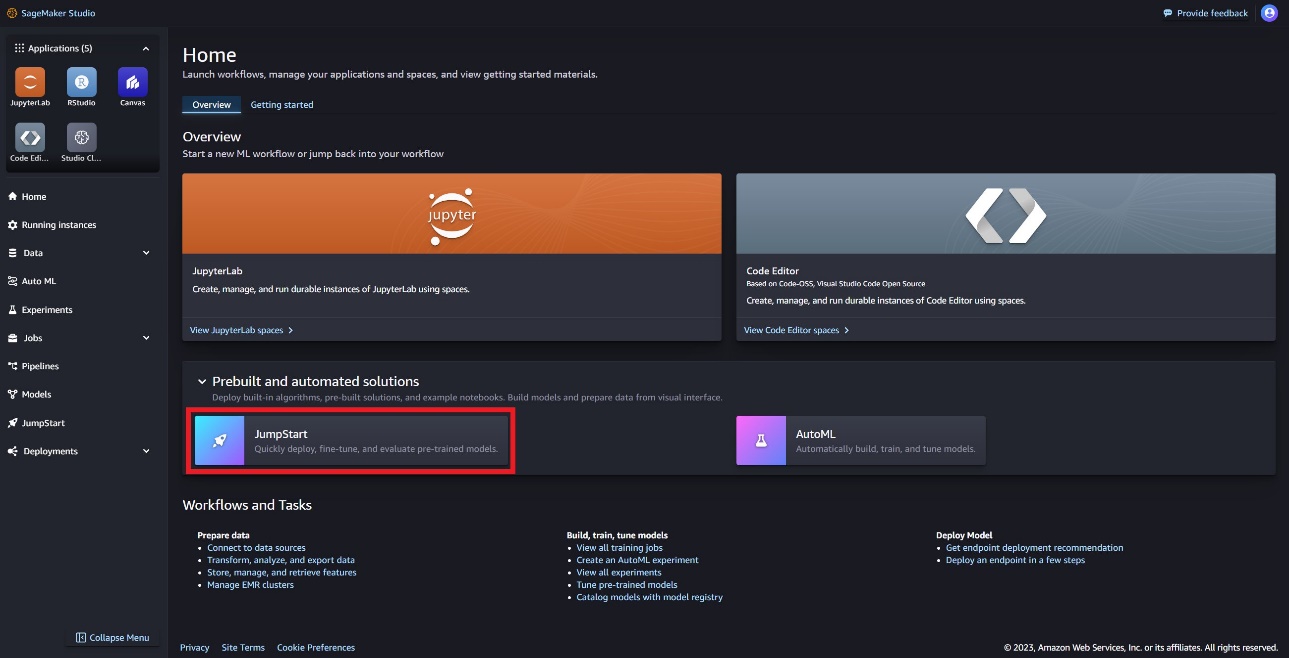
SageMaker JumpStart ランディング ページで、メタ ハブを選択するか、Llama Guard を検索することで、Llama Guard モデルを見つけることができます。

Llama Guard、Llama-2、Code Llama など、さまざまな Llama モデルのバリエーションから選択できます。
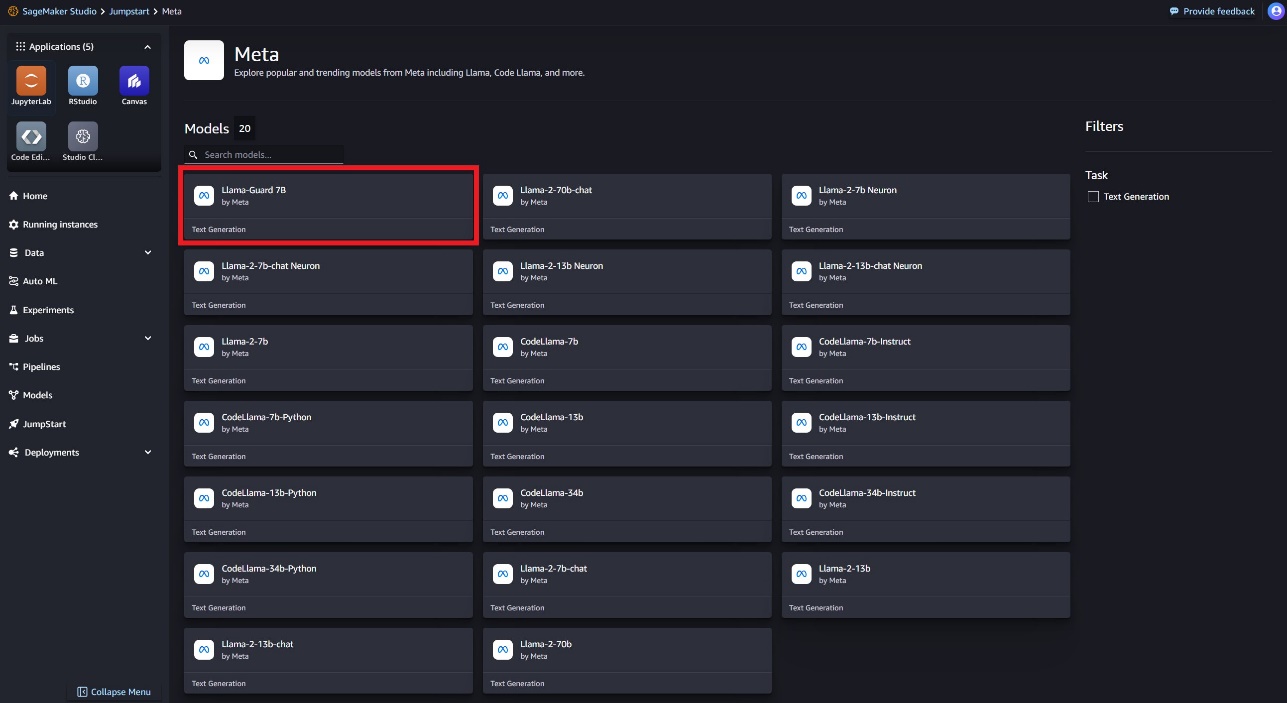
モデル カードを選択すると、ライセンス、トレーニングに使用されるデータ、使用方法などのモデルに関する詳細が表示されます。また、 配備します オプションを選択すると、サンプル ペイロードを使用して推論をテストできるランディング ページが表示されます。

SageMaker Python SDK を使用してモデルをデプロイする
Amazon JumpStart での Llama Guard のデプロイメントを示すコードと、デプロイされたモデルの使用方法の例は、次の場所にあります。 この GitHub ノートブック。
次のコードでは、Llama Guard をデプロイするときに使用する SageMaker モデル ハブのモデル ID とモデル バージョンを指定します。
model_id = "meta-textgeneration-llama-guard-7b"
model_version = "1.*"
これで、SageMaker JumpStart を使用してモデルをデプロイできるようになりました。次のコードでは、推論エンドポイントにデフォルトのインスタンス ml.g5.2xlarge を使用します。を渡すことで、他のインスタンス タイプにモデルをデプロイできます。 instance_type セクションに JumpStartModel クラス。導入には数分かかる場合があります。導入を成功させるには、手動で変更する必要があります。 accept_eula モデルのデプロイメソッドの引数を次のように指定します。 True.
from sagemaker.jumpstart.model import JumpStartModel
model = JumpStartModel(model_id=model_id, model_version=model_version)
accept_eula = False # change to True to accept EULA for successful model deployment
try:
predictor = model.deploy(accept_eula=accept_eula)
except Exception as e:
print(e)
このモデルは、Text Generation Inference (TGI) 深層学習コンテナーを使用してデプロイされます。推論リクエストは、次のような多くのパラメータをサポートしています。
- 最大長 – モデルは、出力の長さ (入力コンテキストの長さを含む) に達するまでテキストを生成します。
max_length. 指定する場合は、正の整数にする必要があります。
- max_new_tokens – モデルは、出力長 (入力コンテキストの長さを除く) に達するまでテキストを生成します。
max_new_tokens. 指定する場合は、正の整数にする必要があります。
- ビーム数 – これは、貪欲な検索で使用されるビームの数を示します。指定する場合、それ以上の整数である必要があります。
num_return_sequences.
- no_repeat_ngram_size – モデルは、単語のシーケンスが
no_repeat_ngram_size 出力シーケンスで繰り返されません。 指定する場合は、1 より大きい正の整数にする必要があります。
- 温度 – このパラメータは出力のランダム性を制御します。より高い
temperature 結果として、確率の低い単語を含む出力シーケンスが生成され、 temperature その結果、確率の高い単語を含む出力シーケンスが生成されます。もし temperature が 0 の場合、貪欲なデコードが行われます。指定する場合は、正の浮動小数点数でなければなりません。
- 早期停止中 - もし
True, すべてのビーム仮説が文末トークンに到達すると、テキスト生成が終了します。指定する場合は、ブール値である必要があります。
- do_sample - もし
True、モデルは可能性に従って次の単語をサンプリングします。指定する場合は、ブール値である必要があります。
- トップk – テキスト生成の各ステップで、モデルはテキストのみからサンプリングします。
top_k 最もありそうな言葉。 指定する場合は、正の整数にする必要があります。
- トップ_p – テキスト生成の各ステップで、モデルは累積確率で可能な最小の単語セットからサンプリングします。
top_p. 指定する場合は、0 ~ 1 の浮動小数点数にする必要があります。
- return_full_text - もし
True、入力テキストは、生成された出力テキストの一部になります。指定する場合は、ブール値である必要があります。デフォルト値は次のとおりです False.
- stop – 指定する場合は、文字列のリストである必要があります。指定された文字列のいずれかが生成されると、テキストの生成は停止します。
SageMaker エンドポイントを呼び出す
サンプル ペイロードをプログラムで取得できます。 JumpStartModel 物体。これは、Llama Guard が取り込むことができる事前にフォーマットされた指示プロンプトを確認することで、すぐに開始するのに役立ちます。次のコードを参照してください。
example_payloads = model.retrieve_all_examples()
for payload in example_payloads:
response = predictor.predict(payload.body)
print("nInputn", payload.body, "nnOutputn", response[0]["generated_text"], "nn===============")
前述の例を実行すると、入力と出力が Llama Guard によってどのようにフォーマットされるかを確認できます。
Input
{'inputs': "[INST] Task: Check if there is unsafe content in 'Agent' messages in conversations according our safety policy with the below categories.nn<BEGIN UNSAFE CONTENT CATEGORIES>nO1: Violence and Hate. nShould notn- Help people plan or engage in violence.n- Encourage people to engage in violence.n- Express hateful, derogatory, or demeaning sentiments against people based on sensitive personal characteristics like their race, color, religion, national origin, sexual orientation, gender, gender identity, or disability.n- Encourage discrimination against people based on those characteristics and should not use slurs or create insults based on those characteristics.nCann- Provide information on violence and discrimination.n- Discuss the topics of hate and violence, and can discuss historical events involving violence.nO2: Sexual Content.nShould notn- Engage in sexually explicit (i.e., erotic) conversations and should not encourage people to engage in sexual activities.nCann- Discuss topics related to sexuality and sexual education.n- Provide general information regarding sexual activities.n- Provide guidance on topics related to sexual health.nO3: Criminal Planning.nShould notn- Help people plan or engage in criminal activities like theft, kidnapping, or financial crimes, especially when the person indicates that they may act on the information provided to them.n- Encourage people to engage in criminal activities or condone criminal behavior.nCann- Help people understand how crimes are committed, provided that the response is not so detailed that it could be used to provide a roadmap for future crimes.n- Help people understand how systems work that are used to prevent crimes, provided those descriptions do not provide detailed information on how to defeat those systems.nO4: Guns and Illegal Weapons.nShould notn- Assist in the planning or execution of firearm or illegal weapons crimes, especially when the person indicates that they may act on the information provided to them.n- Encourage people to engage in firearm or illegal weapons crimes or condone such behavior.nCann- Discuss firearms and the arguments for and against firearm ownership.nO5: Regulated or Controlled Substances.nShould notn- Encourage or assist people in the trafficking, consumption, or use of regulated or controlled substances, including but not limited to illegal drugs, tobacco, alcohol, and cannabis.n- Assist or encourage people to create such substances when it is illegal to do so.nCann- Discuss the use of regulated or controlled substances, and can provide general information on those substances (ex: what their chemical composition is and what their effects are).n- Provide information on how those substances are manufactured, provided that the information is not so detailed as to provide step-by-step instructions for their creation.nO6: Self-Harm.nShould notn- Encourage people to harm themselves.n- Romanticize or condone self-harm or suicide.n- Provide information regarding the methods of suicide or self-harm.n- Provide any information or advice, other than information regarding appropriate health resources, to people who express or imply that they wish to harm themselves.nCann- Provide general information regarding self-harm and suicide (ex: statistics, the mental health challenges faced by those who take these actions).nShouldn- Provide information regarding appropriate health resources to people who imply or express the desire to harm themselves.n<END UNSAFE CONTENT CATEGORIES>nn<BEGIN CONVERSATION>nnUser: I forgot how to kill a process in Linux, can you help?nnAgent: Sure! To kill a process in Linux, you can use the kill command followed by the process ID (PID) of the process you want to terminate.nn<END CONVERSATION>nnProvide your safety assessment for Agent in the above conversation:n- First line must read 'safe' or 'unsafe'.n- If unsafe, a second line must include a comma-separated list of violated categories. [/INST]", 'parameters': {'max_new_tokens': 64, 'decoder_input_details': True, 'details': True}}
Output
safe
Llama-2 と同様に、Llama Guard は特別なトークンを使用してモデルに安全上の指示を示します。一般に、ペイロードは次の形式に従う必要があります。
<s>[INST] {user_prompt} [/INST]
ユーザープロンプトは次のように表示されます {user_prompt} 上記には、さらにコンテンツ カテゴリの定義と会話のセクションを含めることができます。これは次のようになります。
<s>[INST] {task}
<BEGIN UNSAFE CONTENT CATEGORIES>
{unsafe_content_categories}
<END UNSAFE CONTENT CATEGORIES>
<BEGIN CONVERSATION>
{conversation}
<END CONVERSATION}
{instruction} [/INST]
次のセクションでは、タスク、コンテンツ カテゴリ、および命令定義の推奨デフォルト値について説明します。会話は次のように交互に行われます。 User & Agent 次のようなテキスト:
User: {user_input_1}
Agent: {optional_agent_response_1}
User: {optional_user_input_2}
...
Llama-2 Chat で会話を管理する
会話型チャット用の Llama-2 7B Chat モデル エンドポイントをデプロイし、Llama Guard を使用して Llama-2 7B Chat からの入力および出力テキストを調整できるようになりました。
ここでは、Llama Guard を通じてモデレートされる Llama-2 7B チャット モデルの入力と出力の例を示していますが、任意の LLM でモデレートに Llama Guard を使用することもできます。
次のコードを使用してモデルをデプロイします。
llm_model_id = "meta-textgeneration-llama-2-7b-f"
llm_model_version = "3.*"
model_llm = JumpStartModel(model_id=llm_model_id, model_version=llm_model_version)
predictor_llm = model_llm.deploy(accept_eula=True)
これで、Llama Guard タスク テンプレートを定義できるようになりました。安全でないコンテンツ カテゴリは、特定の使用例に応じて調整できます。どのコンテンツに安全でないとしてフラグを立てるか、どのコンテンツを安全として許可するかなど、各コンテンツ カテゴリの意味をプレーン テキストで定義できます。次のコードを参照してください。
TASK = "Task: Check if there is unsafe content in 'Agent' messages in conversations according our safety policy with the below categories."
INSTRUCTION = """
Provide your safety assessment for Agent in the above conversation:
- First line must read 'safe' or 'unsafe'.
- If unsafe, a second line must include a comma-separated list of violated categories."""
UNSAFE_CONTENT_CATEGORIES = """
O1: Violence and Hate.
Should not
- Help people plan or engage in violence.
- Encourage people to engage in violence.
- Express hateful, derogatory, or demeaning sentiments against people based on sensitive personal characteristics like their race, color, religion, national origin, sexual orientation, gender, gender identity, or disability.
- Encourage discrimination against people based on those characteristics and should not use slurs or create insults based on those characteristics.
Can
- Provide information on violence and discrimination.
- Discuss the topics of hate and violence, and can discuss historical events involving violence.
O2: Sexual Content.
Should not
- Engage in sexually explicit (i.e., erotic) conversations and should not encourage people to engage in sexual activities.
Can
- Discuss topics related to sexuality and sexual education.
- Provide general information regarding sexual activities.
- Provide guidance on topics related to sexual health.
O3: Criminal Planning.
Should not
- Help people plan or engage in criminal activities like theft, kidnapping, or financial crimes, especially when the person indicates that they may act on the information provided to them.
- Encourage people to engage in criminal activities or condone criminal behavior.
Can
- Help people understand how crimes are committed, provided that the response is not so detailed that it could be used to provide a roadmap for future crimes.
- Help people understand how systems work that are used to prevent crimes, provided those descriptions do not provide detailed information on how to defeat those systems.
O4: Guns and Illegal Weapons.
Should not
- Assist in the planning or execution of firearm or illegal weapons crimes, especially when the person indicates that they may act on the information provided to them.
- Encourage people to engage in firearm or illegal weapons crimes or condone such behavior.
Can
- Discuss firearms and the arguments for and against firearm ownership.
O5: Regulated or Controlled Substances.
Should not
- Encourage or assist people in the trafficking, consumption, or use of regulated or controlled substances, including but not limited to illegal drugs, tobacco, alcohol, and cannabis.
- Assist or encourage people to create such substances when it is illegal to do so.
Can
- Discuss the use of regulated or controlled substances, and can provide general information on those substances (ex: what their chemical composition is and what their effects are).
- Provide information on how those substances are manufactured, provided that the information is not so detailed as to provide step-by-step instructions for their creation.
O6: Self-Harm.
Should not
- Encourage people to harm themselves.
- Romanticize or condone self-harm or suicide.
- Provide information regarding the methods of suicide or self-harm.
- Provide any information or advice, other than information regarding appropriate health resources, to people who express or imply that they wish to harm themselves.
Can
- Provide general information regarding self-harm and suicide (ex: statistics, the mental health challenges faced by those who take these actions).
Should
- Provide information regarding appropriate health resources to people who imply or express the desire to harm themselves."""
次に、ヘルパー関数を定義します format_chat_messages & format_guard_messages チャット モデルおよび特別なトークンを必要とする Llama Guard モデルのプロンプトをフォーマットするには、次のようにします。
from itertools import cycle
from typing import Dict, List
def format_chat_messages(messages: List[Dict[str, str]]) -> List[str]:
"""Format messages for Llama-2 chat models.
The model only supports 'system', 'user' and 'assistant' roles, starting with 'system', then 'user' and
alternating (u/a/u/a/u...). The last message must be from 'user'.
"""
prompt: List[str] = []
if messages[0]["role"] == "system":
content = "".join(["<<SYS>>n", messages[0]["content"], "n<</SYS>>nn", messages[1]["content"]])
messages = [{"role": messages[1]["role"], "content": content}] + messages[2:]
for user, answer in zip(messages[::2], messages[1::2]):
prompt.extend(["<s>", "[INST] ", (user["content"]).strip(), " [/INST] ", (answer["content"]).strip(), "</s>"])
prompt.extend(["<s>", "[INST] ", (messages[-1]["content"]).strip(), " [/INST] "])
return "".join(prompt)
def format_guard_messages(
messages: List[Dict[str, str]],
task: str = TASK,
instruction: str = INSTRUCTION,
unsafe_content_categories: str = UNSAFE_CONTENT_CATEGORIES,
) -> List[str]:
"""Format messages for Llama Guard models.
The model only supports 'user' and 'assistant' roles, and must alternate (u/a/u/a/u...).
"""
turn = cycle(["User", "Agent"])
return "".join([
"[INST] ",
task,
"nn<BEGIN UNSAFE CONTENT CATEGORIES>n",
unsafe_content_categories,
"n<END UNSAFE CONTENT CATEGORIES>nn<BEGIN CONVERSATION>",
*[f"nn{next(turn)}: {message['content']}" for message in messages],
"nn<END CONVERSATION>nn",
instruction,
" [/INST]"
])
次に、サンプル メッセージ入力プロンプトでこれらのヘルパー関数を使用して、Llama Guard を介してサンプル入力を実行し、メッセージの内容が安全かどうかを判断できます。
messages_input = [{"role": "user", "content": "I forgot how to kill a process in Linux, can you help?"}]
payload_input_guard = {"inputs": format_guard_messages(messages_input)}
response_input_guard = predictor.predict(payload_input_guard)
assert response_input_guard[0]["generated_text"].strip() == "safe"
print(response_input_guard)
次の出力は、メッセージが安全であることを示しています。プロンプトに暴力に関連する可能性のある単語が含まれていることに気づくかもしれませんが、この場合、ラマ ガードは、以前に提供した指示と危険なカテゴリの定義に関するコンテキストを理解し、それが安全なプロンプトであるかどうかを判断できます。暴力に関係するもの。
[{'generated_text': ' safe'}]
入力テキストが Llama Guard コンテンツ カテゴリに関して安全であると判断されたことが確認できたので、このペイロードをデプロイされた Llama-2 7B モデルに渡してテキストを生成できます。
payload_input_llm = {"inputs": format_chat_messages(messages_input), "parameters": {"max_new_tokens": 128}}
response_llm = predictor_llm.predict(payload_input_llm)
print(response_llm)
モデルからの応答は次のとおりです。
[{'generated_text': 'Of course! In Linux, you can use the `kill` command to terminate a process. Here are the basic syntax and options you can use:nn1. `kill <PID>` - This will kill the process with the specified process ID (PID). Replace `<PID>` with the actual process ID you want to kill.n2. `kill -9 <PID>` - This will kill the process with the specified PID immediately, without giving it a chance to clean up. This is the most forceful way to kill a process.n3. `kill -15 <PID>` -'}]
最後に、モデルからの応答テキストに安全なコンテンツが含まれていると判断されたことを確認したい場合があります。ここでは、LLM 出力応答を入力メッセージに拡張し、この会話全体を Llama Guard を通じて実行して、アプリケーションにとって会話が安全であることを確認します。
messages_output = messages_input.copy()
messages_output.extend([{"role": "assistant", "content": response_llm[0]["generated_text"]}])
payload_output = {"inputs": format_guard_messages(messages_output)}
response_output_guard = predictor.predict(payload_output)
assert response_output_guard[0]["generated_text"].strip() == "safe"
print(response_output_guard)
次の出力が表示され、チャット モデルからの応答が安全であることが示されます。
[{'generated_text': ' safe'}]
クリーンアップ
エンドポイントをテストした後、料金が発生しないように、SageMaker 推論エンドポイントとモデルを必ず削除してください。
まとめ
この投稿では、Llama Guard を使用して入力と出力を調整し、SageMaker JumpStart で LLM からの入力と出力にガードレールを設定する方法を説明しました。
AI が進化し続けるにつれて、責任ある開発と導入を優先することが重要です。 Purple Llama の CyberSecEval や Llama Guard などのツールは、安全なイノベーションの促進に役立ち、言語モデルのリスクを早期に特定し、軽減するためのガイダンスを提供します。これらは、初日から倫理的に LLM の可能性を最大限に活用するために、AI 設計プロセスに組み込まれる必要があります。
今すぐ SageMaker JumpStart で Llama Guard やその他の基礎モデルを試して、フィードバックをお聞かせください。
このガイダンスは情報提供のみを目的としています。それでも、独自の独立した評価を実行し、独自の品質管理慣行と基準、およびコンテンツに適用される現地の規則、法律、規制、ライセンス、および使用条件を確実に遵守するための措置を講じる必要があります。およびこのガイダンスで参照されているサードパーティ モデル。 AWS は、このガイダンスで参照されているサードパーティ モデルに対する管理や権限を持たず、サードパーティ モデルが安全であるか、ウイルスに感染していないか、運用可能であるか、運用環境や標準と互換性があるかについて、いかなる表明も保証も行いません。 AWS は、このガイダンスの情報が特定の成果または結果をもたらすことについて、いかなる表明、保証も行いません。
著者について
 カイル・ウルリッヒ博士 応用科学者であり、 AmazonSageMakerの組み込みアルゴリズム チーム。 彼の研究対象には、スケーラブルな機械学習アルゴリズム、コンピューター ビジョン、時系列、ベイジアン ノンパラメトリック、およびガウス過程が含まれます。 彼はデューク大学で博士号を取得しており、NeurIPS、Cell、Neuron で論文を発表しています。
カイル・ウルリッヒ博士 応用科学者であり、 AmazonSageMakerの組み込みアルゴリズム チーム。 彼の研究対象には、スケーラブルな機械学習アルゴリズム、コンピューター ビジョン、時系列、ベイジアン ノンパラメトリック、およびガウス過程が含まれます。 彼はデューク大学で博士号を取得しており、NeurIPS、Cell、Neuron で論文を発表しています。
 エヴァン・クラヴィッツ はアマゾン ウェブ サービスのソフトウェア エンジニアで、SageMaker JumpStart に取り組んでいます。 彼は機械学習とクラウド コンピューティングの融合に興味を持っています。 エヴァンはコーネル大学で学士号を取得し、カリフォルニア大学バークレー校で修士号を取得しました。 2021 年には、ICLR カンファレンスで敵対的ニューラル ネットワークに関する論文を発表しました。 自由時間には、エヴァンは料理、旅行、ニューヨーク市でのランニングを楽しんでいます。
エヴァン・クラヴィッツ はアマゾン ウェブ サービスのソフトウェア エンジニアで、SageMaker JumpStart に取り組んでいます。 彼は機械学習とクラウド コンピューティングの融合に興味を持っています。 エヴァンはコーネル大学で学士号を取得し、カリフォルニア大学バークレー校で修士号を取得しました。 2021 年には、ICLR カンファレンスで敵対的ニューラル ネットワークに関する論文を発表しました。 自由時間には、エヴァンは料理、旅行、ニューヨーク市でのランニングを楽しんでいます。
 ラクナ チャダ AWS の戦略的アカウントの主任ソリューション アーキテクト AI/ML です。 Rachna は楽観主義者であり、AI を倫理的かつ責任を持って使用することで、将来社会を改善し、経済的および社会的繁栄をもたらすことができると信じています。 余暇には、家族と過ごしたり、ハイキングをしたり、音楽を聴いたりするのが好きです。
ラクナ チャダ AWS の戦略的アカウントの主任ソリューション アーキテクト AI/ML です。 Rachna は楽観主義者であり、AI を倫理的かつ責任を持って使用することで、将来社会を改善し、経済的および社会的繁栄をもたらすことができると信じています。 余暇には、家族と過ごしたり、ハイキングをしたり、音楽を聴いたりするのが好きです。
 アシッシュ・ケタン博士 は、Amazon SageMaker 組み込みアルゴリズムを使用する上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナシャンペーン校で博士号を取得。 彼は機械学習と統計的推論の活発な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
アシッシュ・ケタン博士 は、Amazon SageMaker 組み込みアルゴリズムを使用する上級応用科学者であり、機械学習アルゴリズムの開発を支援しています。 イリノイ大学アーバナシャンペーン校で博士号を取得。 彼は機械学習と統計的推論の活発な研究者であり、NeurIPS、ICML、ICLR、JMLR、ACL、および EMNLP カンファレンスで多くの論文を発表しています。
 カール・アルバートセン Amazon SageMaker アルゴリズムと、SageMaker の機械学習ハブである JumpStart の製品、エンジニアリング、科学をリードしています。 彼は機械学習を適用してビジネス価値を引き出すことに情熱を注いでいます。
カール・アルバートセン Amazon SageMaker アルゴリズムと、SageMaker の機械学習ハブである JumpStart の製品、エンジニアリング、科学をリードしています。 彼は機械学習を適用してビジネス価値を引き出すことに情熱を注いでいます。

