著者による画像
機械学習とデータ サイエンスについては多くのコースやリソースが利用できますが、データ エンジニアリングについてはほとんどありません。これにはいくつかの疑問が生じます。難しい分野なのでしょうか?低賃金を提供しているのでしょうか?他の技術者の役割と同じくらい魅力的だと思われていませんか?しかし現実には、多くの企業がデータ エンジニアリングの人材を積極的に求めており、場合によっては 200,000 万ドルを超える高額な給与を提供しています。データ エンジニアは、データ プラットフォームのアーキテクトとして重要な役割を果たし、データ サイエンティストや機械学習の専門家が効果的に機能できるようにする基礎システムを設計および構築します。
この業界のギャップに対処するために、DataTalkClub は革新的な無料ブートキャンプを導入しました。データエンジニアリングZoomcamp”。このコースは、データ エンジニアリングにおける重要なスキルと実践的な経験を身につけ、キャリアを変えようとしている初心者や専門家を支援するように設計されています。
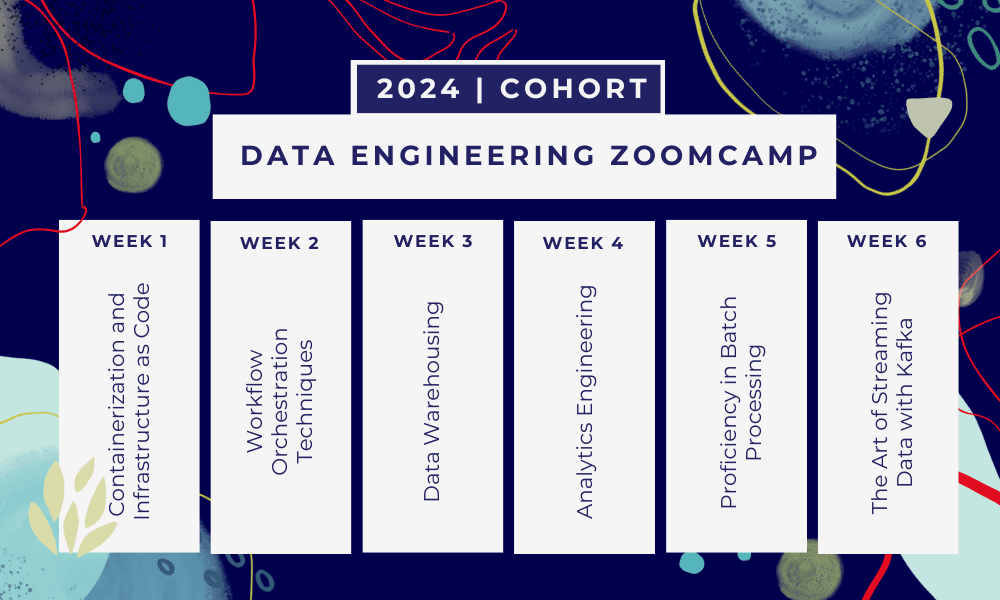
これは 6週間のブートキャンプ 複数のコース、読み物、ワークショップ、プロジェクトを通じて学習します。各モジュールの最後には、学んだ内容を実践するための宿題が与えられます。
- Week 1: GCP、Docker、Postgres、Terraform、および環境セットアップの概要。
- Week 2: Mage を使用したワークフロー オーケストレーション。
- Week 3: BigQuery によるデータ ウェアハウジングと BigQuery による機械学習。
- Week 4: dbt、Google Data Studio、Metabase の分析エンジニア。
- Week 5: Sparkによるバッチ処理。
- Week 6: カフカとのストリーミング。
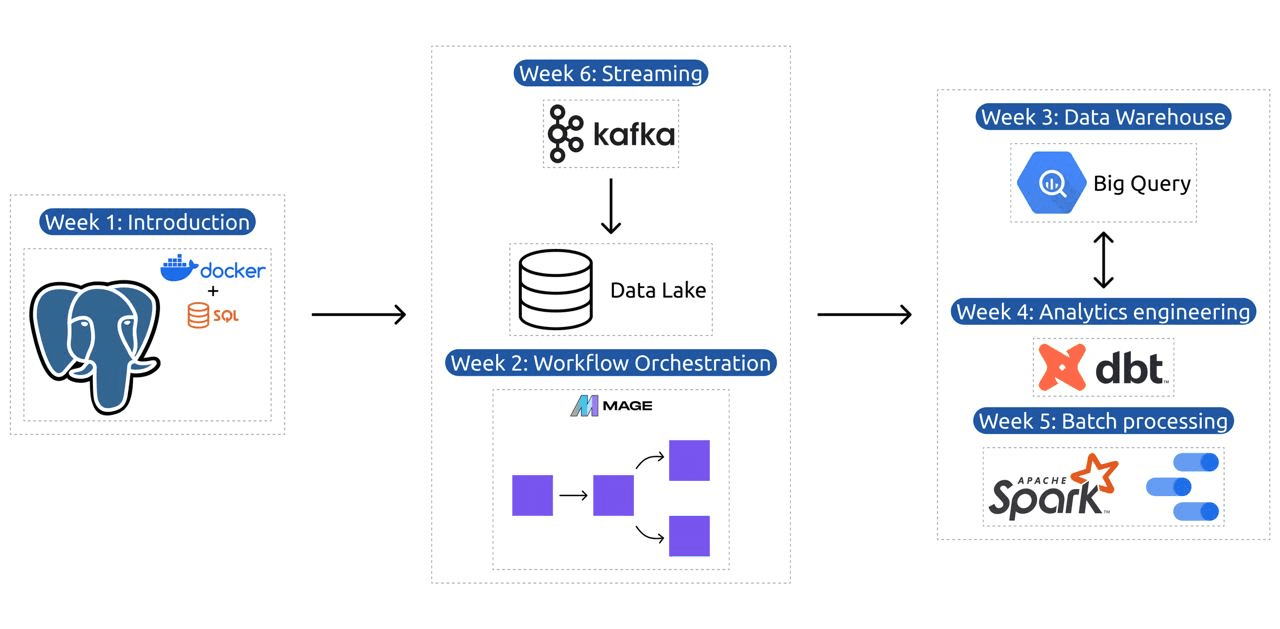
Image from
DataTalksClub / data-engineering-zoomcamp
シラバスには 6 つのモジュール、2 つのワークショップ、およびプロのデータ エンジニアになるために必要なすべてをカバーするプロジェクトが含まれています。
モジュール 1: コンテナ化とコードとしてのインフラストラクチャをマスターする
このモジュールでは、Docker と Postgres について学習します。基本から始めて、データ パイプラインの作成、Docker での Postgres の実行などに関する詳細なチュートリアルに進みます。
このモジュールでは、pgAdmin、Docker-compose、SQL 復習トピックなどの重要なツールもカバーしており、Docker ネットワークに関するオプションのコンテンツや Windows サブシステム Linux ユーザー向けの特別なウォークスルーも含まれています。最後に、このコースでは GCP と Terraform について紹介し、最新のクラウドベースの環境に不可欠なコンテナ化とコードとしてのインフラストラクチャの全体的な理解を提供します。
モジュール 2: ワークフロー オーケストレーション技術
このモジュールでは、データ変換と統合のための革新的なオープンソース ハイブリッド フレームワークである Mage について詳しく説明します。このモジュールはワークフロー オーケストレーションの基本から始まり、Docker を介したセットアップや、API から Postgres および Google Cloud Storage (GCS)、さらに BigQuery への ETL パイプラインの構築など、Mage を使用した実践的な演習に進みます。
このモジュールのビデオ、リソース、実践的なタスクの組み合わせにより、包括的な学習体験が保証され、学習者は Mage を使用して高度なデータ ワークフローを管理するスキルを身につけることができます。
ワークショップ 1: データ取り込み戦略
最初のワークショップでは、効率的なデータ取り込みパイプラインの構築をマスターします。このワークショップは、API やファイルからのデータの抽出、データの正規化とロード、増分ロード手法などの重要なスキルに焦点を当てています。このワークショップを完了すると、上級データ エンジニアのように効率的なデータ パイプラインを作成できるようになります。
モジュール 3: データ ウェアハウジング
このモジュールは、BigQuery を使用したデータ ウェアハウジングに焦点を当てた、データ ストレージと分析について詳しく説明します。パーティショニングやクラスタリングなどの主要な概念を取り上げ、BigQuery のベスト プラクティスについて詳しく説明します。このモジュールは高度なトピック、特に機械学習 (ML) と BigQuery の統合に進み、ML 用の SQL の使用に焦点を当て、ハイパーパラメータ調整、機能の前処理、モデルのデプロイに関するリソースを提供します。
モジュール 4: 分析エンジニアリング
分析エンジニアリング モジュールは、既存のデータ ウェアハウス (BigQuery または PostgreSQL) で dbt (データ構築ツール) を使用してプロジェクトを構築することに重点を置いています。
このモジュールでは、クラウド環境とローカル環境の両方での dbt のセットアップ、分析エンジニアリングの概念、ETL と ELT、データ モデリングの紹介について説明します。インクリメンタル モデル、タグ、フック、スナップショットなどの高度な dbt 機能についても説明します。
最後に、このモジュールでは、Google データスタジオやメタベースなどのツールを使用して変換されたデータを視覚化する手法を紹介し、トラブルシューティングと効率的なデータ読み込みのためのリソースを提供します。
モジュール 5: バッチ処理の習熟度
このモジュールでは、Apache Spark を使用したバッチ処理について説明します。バッチ処理と Spark の概要から始まり、Windows、Linux、MacOS のインストール手順も説明します。
これには、Spark SQL と DataFrame の探索、データの準備、SQL 操作の実行、Spark の内部構造の理解が含まれます。最後に、クラウドで Spark を実行し、Spark を BigQuery と統合することで終了します。
モジュール 6: Kafka を使用したデータのストリーミング技術
このモジュールは、ストリーム処理の概念の紹介から始まり、続いて、Kafka の基礎、Confluent Cloud との統合、プロデューサーとコンシューマが関与する実践的なアプリケーションなど、Kafka について詳しく説明します。
このモジュールでは、Kafka の構成とストリームについても説明し、ストリーム結合、テスト、ウィンドウ処理、Kafka ksqldb と Connect の使用などのトピックに対処します。さらに、焦点を Python および JVM 環境に拡張し、Python ストリーム処理用の Faust、Pyspark – 構造化ストリーミング、Kafka ストリーム用の Scala の例を取り上げます。
ワークショップ 2: SQL を使用したストリーム処理
RisingWave を使用してストリーミング データを処理および管理する方法を学習します。RisingWave は、ストリーム処理アプリケーションを強化する PostgreSQL スタイルのエクスペリエンスを備えたコスト効率の高いソリューションを提供します。
プロジェクト: 実世界データ エンジニアリング アプリケーション
このプロジェクトの目的は、このコースで学んだすべての概念を実装して、エンドツーエンドのデータ パイプラインを構築することです。データセットを選択して 2 つのタイルで構成されるダッシュボードを作成し、データを処理してデータ レイクに保存するパイプラインを構築し、処理されたデータをデータ レイクからデータ ウェアハウスに転送するパイプラインを構築し、変換します。データ ウェアハウス内のデータをダッシュボード用に準備し、最後にデータを視覚的に表示するダッシュボードを構築します。
2024年コホートの詳細
- 登録: 今すぐ登録する
- 開始日: 15 年 2024 月 17 日、00:XNUMX CET
- ガイド付きサポートによる自分のペースでの学習
- コホートフォルダー 宿題と期限がある
- 対話 スラックコミュニティ ピアラーニング用
前提条件
- 基本的なコーディングとコマンドラインのスキル
- SQLの基礎
- Python: 有益ではあるが必須ではない
専門のインストラクターがあなたの旅を導きます
- アンクシュ・カンナ
- ビクトリア・ペレス・モラ
- アレクセイ・グリゴレフ
- マット・パーマー
- ルイス・オリヴェイラ
- マイケル・シューメーカー
2024 年コホートに参加して、素晴らしいデータ エンジニアリング コミュニティで学習を始めましょう。専門家主導のトレーニング、実践経験、業界のニーズに合わせたカリキュラムを備えたこのブートキャンプでは、必要なスキルを身につけるだけでなく、高収入で需要の高いキャリアパスの最前線に立つことができます。今すぐ登録して、あなたの願望を現実に変えましょう!
アビッド・アリ・アワン (@ 1abidaliawan)は、機械学習モデルの構築を愛する認定データサイエンティストの専門家です。 現在、彼はコンテンツの作成と、機械学習とデータサイエンステクノロジーに関する技術ブログの執筆に注力しています。 Abidは、技術管理の修士号と電気通信工学の学士号を取得しています。 彼のビジョンは、精神疾患に苦しんでいる学生のためにグラフニューラルネットワークを使用してAI製品を構築することです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer

