この投稿では、ニューラル アーキテクチャ検索 (NAS) ベースの構造枝刈りを使用して、微調整された BERT モデルを圧縮し、モデルのパフォーマンスを向上させ、推論時間を短縮する方法を示します。事前トレーニング済み言語モデル (PLM) は、生産性ツール、顧客サービス、検索とレコメンデーション、ビジネス プロセスの自動化、およびコンテンツ作成の分野で商業および企業で急速に導入されています。通常、PLM 推論エンドポイントのデプロイには、コンピューティング要件と多数のパラメーターによる計算効率の低下により、レイテンシーの増加とインフラストラクチャのコストの増加が伴います。 PLM をプルーニングすると、モデルの予測機能を維持しながら、モデルのサイズと複雑さが軽減されます。プルーニングされた PLM は、メモリ フットプリントの縮小と待ち時間の短縮を実現します。 PLM をプルーニングし、特定のターゲット タスクのパラメーター数と検証エラーをトレードオフすることで、基本 PLM モデルと比較してより高速な応答時間を達成できることを実証します。
多目的最適化は、メモリ消費量、トレーニング時間、コンピューティング リソースなどの複数の目的関数を同時に最適化する意思決定の分野です。構造枝刈りは、モデルの精度を維持しながら層またはニューロン/ノードを枝刈りすることにより、PLM のサイズと計算要件を削減する手法です。レイヤーを削除することにより、構造的な枝刈りにより高い圧縮率が実現され、ハードウェアに優しい構造化されたスパース性が実現され、実行時間と応答時間が短縮されます。構造枝刈り手法を PLM モデルに適用すると、メモリ フットプリントが小さく軽量なモデルが得られ、これを SageMaker の推論エンドポイントとしてホストすると、元の微調整された PLM と比較してリソース効率が向上し、コストが削減されます。
この投稿で説明した概念は、レコメンデーション システム、センチメント分析、検索エンジンなどの PLM 機能を使用するアプリケーションに適用できます。具体的には、ドメイン固有のデータセットを使用して独自の PLM モデルを微調整し、 アマゾンセージメーカー。一例として、テキストの要約、製品カタログの分類、製品フィードバックのセンチメント分類のために多数の推論エンドポイントを導入しているオンライン小売業者があります。別の例としては、臨床文書の分類、医療レポートからの固有表現認識、医療チャットボット、患者のリスク階層化に PLM 推論エンドポイントを使用する医療提供者が挙げられます。
ソリューションの概要
このセクションでは、全体的なワークフローを示し、アプローチについて説明します。まず、 Amazon SageMakerスタジオ ノート ドメイン固有のデータセットを使用して、ターゲット タスクで事前トレーニングされた BERT モデルを微調整します。 ベルト (Transformers からの双方向エンコーダー表現) は、 トランスアーキテクチャ 自然言語処理 (NLP) タスクに使用されます。ニューラル アーキテクチャ検索 (NAS) は、人工ニューラル ネットワークの設計を自動化するためのアプローチであり、機械学習の分野で広く使用されているハイパーパラメーターの最適化と密接に関連しています。 NAS の目標は、勾配なしの最適化などの手法を使用して、または必要なメトリクスを最適化することによって、大規模な候補アーキテクチャのセットを検索することによって、特定の問題に最適なアーキテクチャを見つけることです。アーキテクチャのパフォーマンスは通常、検証損失などの指標を使用して測定されます。 SageMaker自動モデルチューニング (AMT) は、最高のモデル パフォーマンスを生み出す ML モデルのハイパーパラメーターの最適な組み合わせを見つけるという退屈で複雑なプロセスを自動化します。 AMT は、インテリジェントな検索アルゴリズムと、指定した一連のハイパーパラメーターを使用した反復評価を使用します。精度や F-1 スコアなどのパフォーマンス メトリックによって測定され、最高のパフォーマンスを発揮するモデルを作成するハイパーパラメーター値が選択されます。
この投稿で説明する微調整アプローチは一般的なものであり、テキストベースのデータセットに適用できます。 BERT PLM に割り当てられるタスクは、感情分析、テキスト分類、Q&A などのテキストベースのタスクです。このデモのターゲット タスクは、テキスト フラグメントのペアのコレクションで構成されるデータセットから、一方のテキスト フラグメントの意味をもう一方のフラグメントから推測できるかどうかを識別するために BERT を使用するバイナリ分類問題です。私たちが使用するのは、 テキスト含意データセットの認識 GLUE ベンチマーク スイートから。 SageMaker AMT を使用して多目的検索を実行し、ターゲット タスクのパラメーター数と予測精度の間で最適なトレードオフを提供するサブネットワークを特定します。多目的検索を実行するときは、最適化する目的として精度とパラメータ数を定義することから始めます。
BERT PLM ネットワーク内には、言語理解や知識表現などの特殊な機能をモデルに持たせることができるモジュール式の自己完結型サブネットワークが存在します。 BERT PLM は、マルチヘッド セルフ アテンション サブネットワークとフィードフォワード サブネットワークを使用します。マルチヘッドのセルフアテンション層により、BERT は複数のヘッドが複数のコンテキスト信号に対応できるようにすることで、シーケンスの表現を計算するために単一シーケンスの異なる位置を関連付けることができます。入力は複数の部分空間に分割され、自己注意は各部分空間に個別に適用されます。トランスフォーマー PLM の複数のヘッドにより、モデルは異なる表現部分空間からの情報を共同で処理できるようになります。フィードフォワード サブネットワークは、マルチヘッドセルフアテンション サブネットワークから出力を受け取り、データを処理して、最終的なエンコーダー表現を返す単純なニューラル ネットワークです。
ランダムなサブネットワーク サンプリングの目標は、ターゲット タスクで十分なパフォーマンスを発揮できる小規模な BERT モデルをトレーニングすることです。微調整された基本 BERT モデルから 100 個のランダムなサブネットワークをサンプリングし、10 個のネットワークを同時に評価します。トレーニングされたサブネットワークは、客観的なメトリクスに関して評価され、最終的なモデルは、目的的なメトリクス間で見つかったトレードオフに基づいて選択されます。私たちは、 パレートフロント サンプリングされたサブネットワークの場合、モデルの精度とモデル サイズの間で最適なトレードオフを提供する枝刈りモデルが含まれます。トレードオフの対象となるモデル サイズとモデル精度に基づいて、候補となるサブネットワーク (NAS プルーニングされた BERT モデル) を選択します。次に、SageMaker を使用して、エンドポイント、事前トレーニングされた BERT 基本モデル、および NAS プルーニングされた BERT モデルをホストします。負荷テストを実行するには、次を使用します。 イナゴ、Python を使用して実装できるオープンソースの負荷テスト ツール。 Locust を使用して両方のエンドポイントで負荷テストを実行し、パレート フロントを使用して結果を視覚化し、両方のモデルの応答時間と精度の間のトレードオフを示します。次の図は、この投稿で説明するワークフローの概要を示しています。
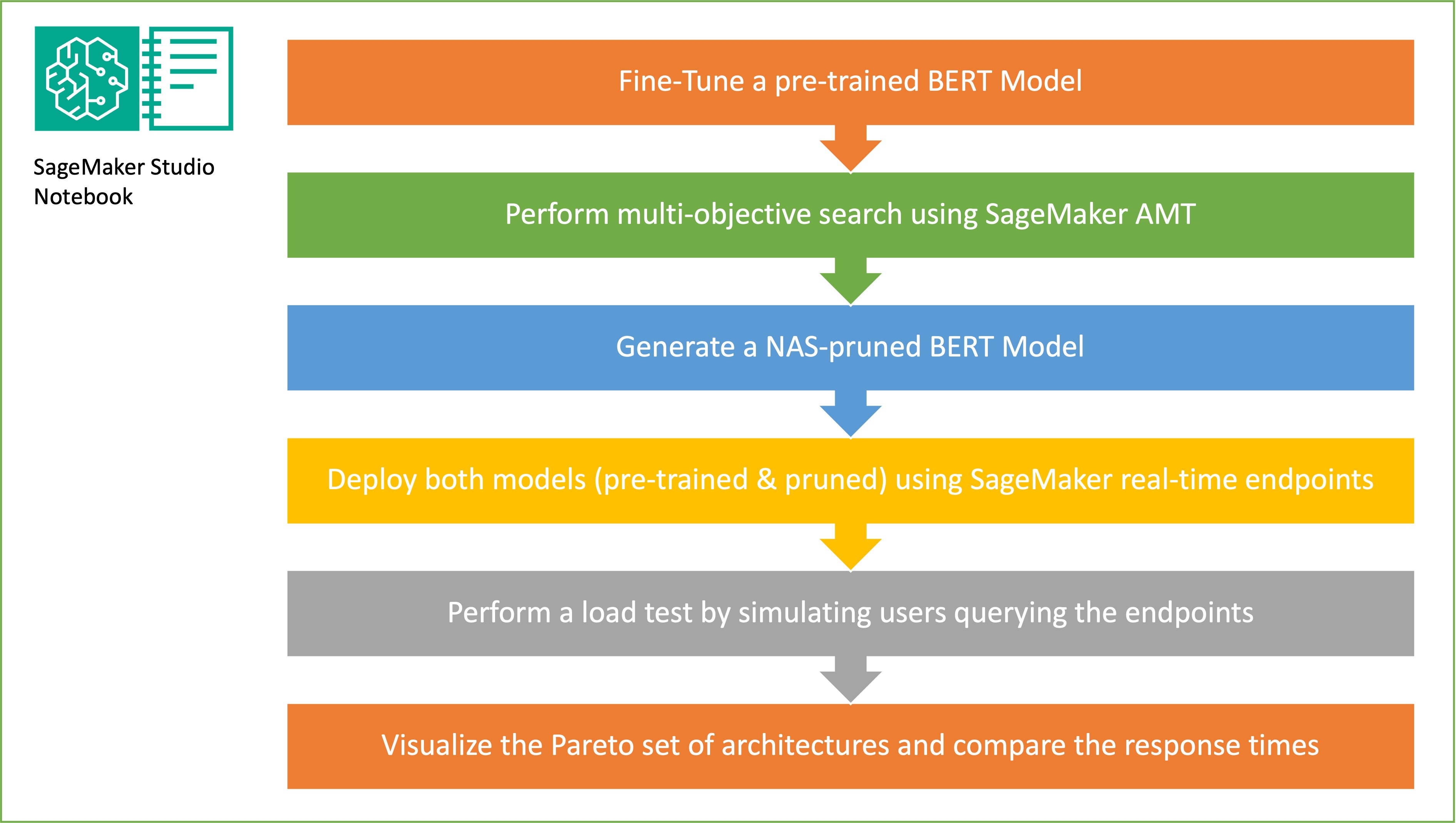
前提条件
この投稿には、次の前提条件が必要です。
また、 サービスクォータ SageMaker の ml.g4dn.xlarge インスタンスの少なくとも 4 つのインスタンスにアクセスします。インスタンス タイプ ml.gXNUMXdn.xlarge は、PyTorch をネイティブに実行できるコスト効率の高い GPU インスタンスです。サービスクォータを増やすには、次の手順を実行します。
- コンソールで、「サービス クォータ」に移動します。
- クォータの管理、選択する アマゾンセージメーカー、を選択します クォータの表示.

- 「トレーニング ジョブ使用用 ml-g4dn.xlarge」を検索し、クォータ項目を選択します。
- 選択する アカウントレベルでの増加リクエスト.
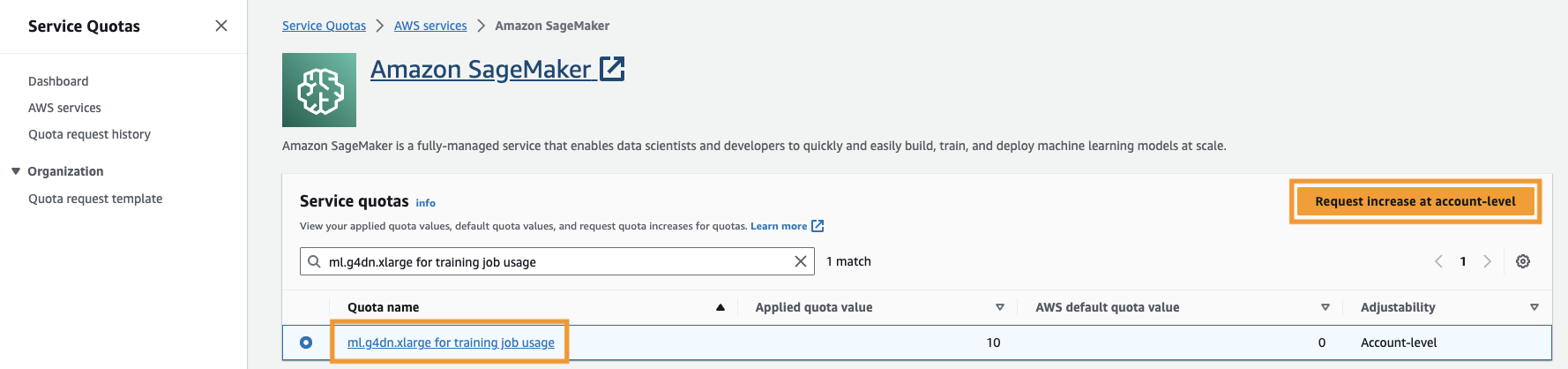
- クォータ値を増やす、5 以上の値を入力します。
- 選択する リクエスト.
アカウントの権限によっては、要求されたクォータの承認が完了するまでに時間がかかる場合があります。
- SageMaker コンソールから SageMaker Studio を開きます。

- 選択する システム端末 下 ユーティリティとファイル.
- 次のコマンドを実行して、 GitHubレポ SageMaker Studio インスタンスに:
- MFAデバイスに移動する
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - ファイルをオープンする
nas_for_llm_with_amt.ipynb. - 環境をセットアップします。
ml.g4dn.xlargeインスタンスと選択 選択.
事前トレーニングされた BERT モデルをセットアップする
このセクションでは、テキスト含意の認識データセットをデータセット ライブラリからインポートし、データセットをトレーニング セットと検証セットに分割します。このデータセットは文のペアで構成されます。 BERT PLM のタスクは、2 つのテキスト フラグメントが与えられた場合、一方のテキスト フラグメントの意味をもう一方のテキスト フラグメントから推測できるかどうかを認識することです。次の例では、2 番目のフレーズから最初のフレーズの意味を推測できます。
テキスト認識含意データセットを GLUE ベンチマーク スイート経由 データセットライブラリ トレーニング スクリプト内の Hugging Face より (./training.py)。 GLUE からの元のトレーニング データセットをトレーニング セットと検証セットに分割しました。私たちのアプローチでは、トレーニング データセットを使用してベース BERT モデルを微調整し、次に多目的検索を実行して、目的のメトリクス間の最適なバランスをとるサブネットワークのセットを特定します。 BERT モデルの微調整専用にトレーニング データセットを使用します。ただし、ホールドアウト検証データセットの精度を測定することで、多目的検索に検証データを使用します。
ドメイン固有のデータセットを使用して BERT PLM を微調整する
生の BERT モデルの一般的な使用例には、次の文の予測やマスクされた言語モデリングが含まれます。テキスト認識含意などの下流タスクに基本 BERT モデルを使用するには、ドメイン固有のデータセットを使用してモデルをさらに微調整する必要があります。微調整された BERT モデルは、シーケンス分類、質問応答、トークン分類などのタスクに使用できます。ただし、このデモでは、バイナリ分類に微調整されたモデルを使用します。次のハイパーパラメータを使用して、事前に準備したトレーニング データセットを使用して事前トレーニングされた BERT モデルを微調整します。
モデルトレーニングのチェックポイントを Amazon シンプル ストレージ サービス (Amazon S3) バケットに追加され、NAS ベースの多目的検索中にモデルをロードできるようになります。モデルをトレーニングする前に、エポック、トレーニング損失、パラメーターの数、検証エラーなどのメトリクスを定義します。
微調整プロセスが開始されてから、トレーニング ジョブが完了するまでに約 15 分かかります。
多目的検索を実行してサブネットワークを選択し、結果を視覚化します
次のステップでは、SageMaker AMT を使用してランダムなサブネットワークをサンプリングすることにより、微調整された基本 BERT モデルに対して多目的検索を実行します。スーパーネットワーク内のサブネットワーク (微調整された BERT モデル) にアクセスするには、サブネットワークの一部ではない PLM のすべてのコンポーネントをマスクアウトします。 PLM でスーパーネットワークをマスクしてサブネットワークを見つけることは、モデルの動作パターンを分離して識別するために使用される手法です。 Hugging Face トランスフォーマーでは、隠れたサイズがヘッドの数の倍数である必要があることに注意してください。 Transformer PLM の隠れたサイズは、隠れた状態ベクトル空間のサイズを制御します。これは、データ内の複雑な表現とパターンを学習するモデルの能力に影響します。 BERT PLM では、隠れ状態ベクトルは固定サイズ (768) です。非表示のサイズは変更できないため、頭の数は [1、3、6、12] でなければなりません。
単一目的の最適化とは対照的に、複数目的の設定では、通常、すべての目的を同時に最適化する単一のソリューションはありません。代わりに、少なくとも 1 つの目的 (検証エラーなど) において他のすべてのソリューションを支配する一連のソリューションを収集することを目的としています。これで、削減したいメトリクス (検証エラーとパラメータの数) を設定して、AMT を介して多目的検索を開始できるようになりました。ランダムなサブネットワークはパラメータによって定義されます。 max_jobs 同時ジョブの数はパラメータによって定義されます。 max_parallel_jobs。モデルのチェックポイントをロードしてサブネットワークを評価するコードは、次の場所にあります。 evaluate_subnetwork.py スクリプト。
AMT チューニング ジョブの実行には約 2 時間 20 分かかります。 AMT チューニング ジョブが正常に実行された後、ジョブの履歴を解析し、ヘッド数、レイヤー数、ユニット数などのサブネットワークの構成と、検証エラーやパラメーター数などの対応するメトリックを収集します。次のスクリーンショットは、成功した AMT チューナー ジョブの概要を示しています。
次に、パレート セット (パレート フロンティアまたはパレート最適セットとも呼ばれます) を使用して結果を視覚化します。これは、目的のメトリック (検証誤差) において他のすべてのサブネットワークを支配するサブネットワークの最適なセットを特定するのに役立ちます。
まず、AMT チューニング ジョブからデータを収集します。次に、次を使用してパレート集合をプロットします。 matplotlob.pyplot x 軸にパラメータの数、y 軸に検証誤差をとります。これは、パレート セットのあるサブネットワークから別のサブネットワークに移動する場合、パフォーマンスまたはモデル サイズのいずれかを犠牲にして、もう一方を改善する必要があることを意味します。最終的に、パレート セットにより、好みに最も適したサブネットワークを選択できる柔軟性が得られます。ネットワークのサイズをどの程度削減するか、どの程度のパフォーマンスを犠牲にするかを決定できます。

SageMaker を使用して、微調整された BERT モデルと NAS に最適化されたサブネットワーク モデルをデプロイします。
次に、パフォーマンスの低下を最小限に抑えるパレート セット内の最大のモデルをデプロイします。 SageMakerエンドポイント。最良のモデルは、検証エラーとユースケースのパラメーター数の間で最適なトレードオフを提供するモデルです。
モデル比較
私たちは、事前トレーニング済みの基本 BERT モデルを取得し、ドメイン固有のデータセットを使用して微調整し、NAS 検索を実行して客観的なメトリクスに基づいて支配的なサブネットワークを特定し、プルーニングされたモデルを SageMaker エンドポイントにデプロイしました。さらに、事前トレーニングされた基本 BERT モデルを取得し、その基本モデルを 2 番目の SageMaker エンドポイントにデプロイしました。次に、私たちは走りました 負荷テスト 両方の推論エンドポイントで Locust を使用し、応答時間の観点からパフォーマンスを評価しました。
まず、必要な Locust ライブラリと Boto3 ライブラリをインポートします。次に、リクエストのメタデータを構築し、負荷テストに使用する開始時間を記録します。次に、ペイロードは BotoClient 経由で SageMaker エンドポイント呼び出し API に渡され、実際のユーザーリクエストをシミュレートします。 Locust を使用して複数の仮想ユーザーを生成し、リクエストを並行して送信し、負荷がかかった状態でのエンドポイントのパフォーマンスを測定します。テストは、XNUMX つのエンドポイントそれぞれのユーザー数を増やすことによって実行されます。テストが完了すると、Locust はデプロイされたモデルごとにリクエスト統計 CSV ファイルを出力します。
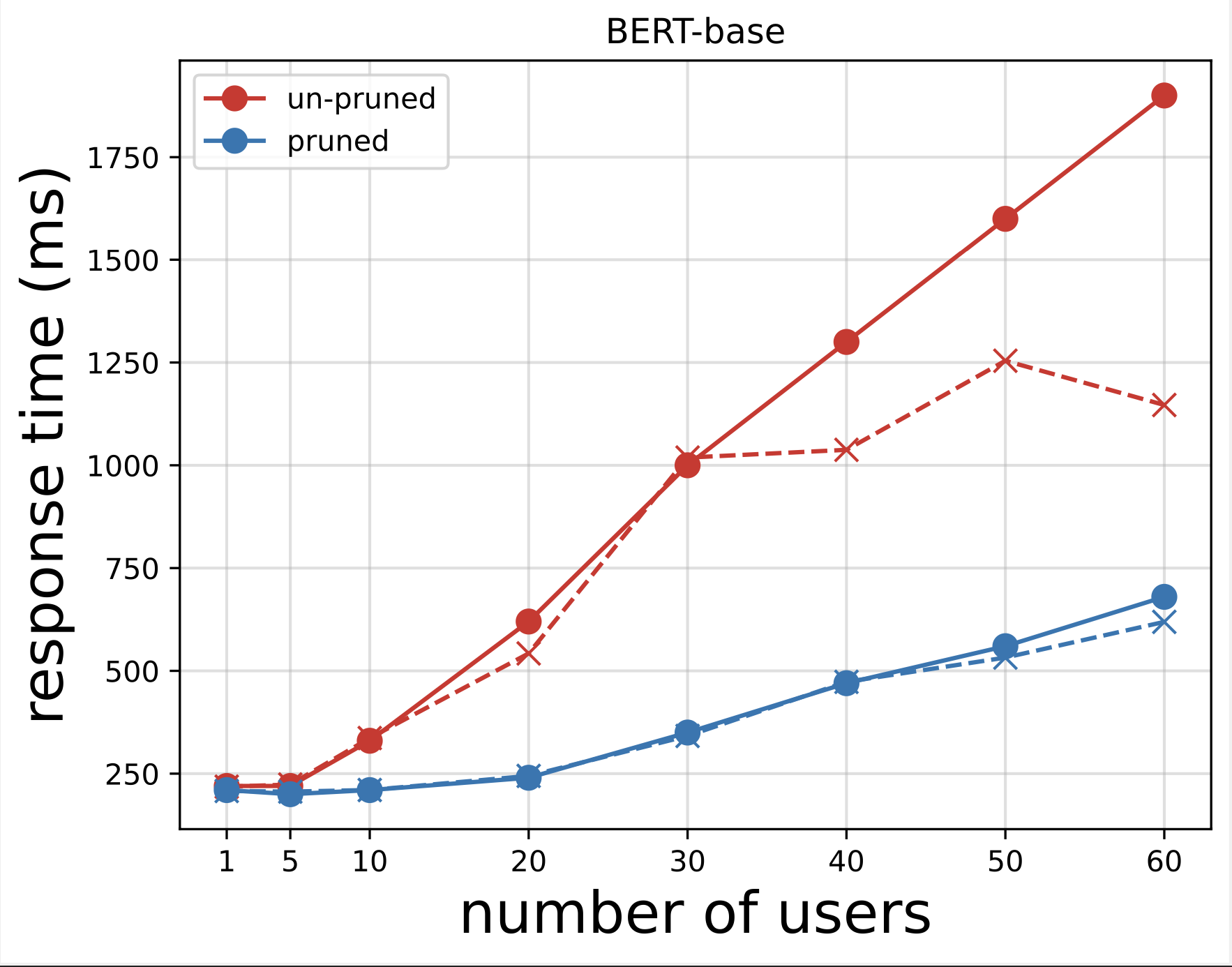
次に、Locust でテストを実行した後にダウンロードした CSV ファイルから応答時間のプロットを生成します。応答時間とユーザー数をプロットする目的は、モデル エンドポイントの応答時間の影響を視覚化することで負荷テストの結果を分析することです。次のグラフでは、NAS プルーニング モデル エンドポイントが、基本 BERT モデル エンドポイントと比較して短い応答時間を実現していることがわかります。
最初のグラフの拡張である 70 番目のグラフでは、約 90 ユーザーを超えると、SageMaker がベース BERT モデル エンドポイントのスロットルを開始し、例外をスローすることがわかります。ただし、NAS プルーニング モデルのエンドポイントの場合、スロットルは 100 ~ XNUMX ユーザーの間で発生し、応答時間は短くなります。

2 つのグラフから、プルーニングされていないモデルと比較して、プルーニングされたモデルの方が応答時間が速く、スケーリングが優れていることがわかります。 PLM アプリケーションに多数の推論エンドポイントをデプロイするユーザーの場合と同様に、推論エンドポイントの数をスケールすると、コスト上の利点とパフォーマンスの向上がかなり大きくなり始めます。
クリーンアップ
微調整された基本 BERT モデルおよび NAS プルーニングされたモデルの SageMaker エンドポイントを削除するには、次の手順を実行します。
- SageMakerコンソールで、 推論 & エンドポイント ナビゲーションペインに表示されます。
- エンドポイントを選択して削除します。
あるいは、SageMaker Studio ノートブックから、エンドポイント名を指定して次のコマンドを実行します。
まとめ
この投稿では、NAS を使用して微調整された BERT モデルをプルーニングする方法について説明しました。まず、ドメイン固有のデータを使用して基本 BERT モデルをトレーニングし、それを SageMaker エンドポイントにデプロイしました。ターゲットタスクに対して SageMaker AMT を使用して、微調整された基本 BERT モデルに対して多目的検索を実行しました。パレート フロントを視覚化し、パレート最適な NAS プルーニングされた BERT モデルを選択し、そのモデルを 2 番目の SageMaker エンドポイントにデプロイしました。 Locust を使用して負荷テストを実行し、両方のエンドポイントにクエリを実行するユーザーをシミュレートし、応答時間を測定して CSV ファイルに記録しました。両方のモデルの応答時間とユーザー数をプロットしました。
プルーニングされた BERT モデルの方が、応答時間とインスタンスのスロットルしきい値の両方で大幅にパフォーマンスが向上していることがわかりました。 NAS プルーニング モデルは、ベース BERT モデルと比較して、より多くのユーザーがシステムに負荷をかけても、より低い応答時間を維持し、エンドポイントの負荷増加に対する耐性が高いと結論付けました。この投稿で説明した NAS テクニックを任意の大規模言語モデルに適用すると、大幅に短い応答時間でターゲット タスクを実行できるプルーニングされたモデルを見つけることができます。検証損失に加えてレイテンシーをパラメータとして使用することで、アプローチをさらに最適化できます。
この記事では NAS を使用しますが、量子化は PLM モデルの最適化と圧縮に使用されるもう 32 つの一般的なアプローチです。量子化により、トレーニングされたネットワーク内の重みとアクティベーションの精度が 8 ビット浮動小数点から 16 ビットまたは XNUMX ビット整数などのより低いビット幅に低下し、その結果、より高速な推論を生成する圧縮モデルが生成されます。量子化によってパラメータの数は減りません。代わりに、既存のパラメータの精度を下げて、圧縮されたモデルを取得します。 NAS プルーニングは、PLM 内の冗長なネットワークを削除し、パラメーターの少ない疎なモデルを作成します。通常、NAS プルーニングと量子化は一緒に使用され、大規模な PLM を圧縮してモデルの精度を維持し、パフォーマンスを向上させながら検証損失を削減し、モデル サイズを縮小します。 PLM のサイズを削減するために一般的に使用されるその他の手法には次のものがあります。 知識蒸留, 行列分解, 蒸留カスケード.
ブログ投稿で提案されているアプローチは、SageMaker を使用してドメイン固有のデータを使用してモデルをトレーニングおよび微調整し、エンドポイントをデプロイして推論を生成するチームに適しています。生成 AI アプリケーションの構築に必要な高性能の基盤モデルの選択肢を提供するフルマネージド サービスをお探しの場合は、次の使用を検討してください。 アマゾンの岩盤。幅広いビジネス ユース ケースに対応する事前トレーニング済みのオープン ソース モデルを探しており、ソリューション テンプレートとサンプル ノートブックにアクセスしたい場合は、次の使用を検討してください。 Amazon SageMaker ジャンプスタート。この投稿で使用した Hugging Face BERT ベース ケース モデルの事前トレーニング済みバージョンも、SageMaker JumpStart から入手できます。
著者について
 アパラジータン・ヴァイディヤナータン AWS のプリンシパル エンタープライズ ソリューション アーキテクトです。彼は、エンタープライズ、大規模、分散ソフトウェア システムの設計と開発に 24 年以上の経験を持つクラウド アーキテクトです。彼は生成 AI と機械学習データ エンジニアリングを専門としています。彼はマラソンランナーを目指しており、趣味はハイキング、自転車に乗り、妻と XNUMX 人の男の子と一緒に時間を過ごすことです。
アパラジータン・ヴァイディヤナータン AWS のプリンシパル エンタープライズ ソリューション アーキテクトです。彼は、エンタープライズ、大規模、分散ソフトウェア システムの設計と開発に 24 年以上の経験を持つクラウド アーキテクトです。彼は生成 AI と機械学習データ エンジニアリングを専門としています。彼はマラソンランナーを目指しており、趣味はハイキング、自転車に乗り、妻と XNUMX 人の男の子と一緒に時間を過ごすことです。
 アーロン・クライン は、AWS の上級応用科学者であり、ディープ ニューラル ネットワークの自動機械学習手法に取り組んでいます。
アーロン・クライン は、AWS の上級応用科学者であり、ディープ ニューラル ネットワークの自動機械学習手法に取り組んでいます。
 ヤチェク・ゴレビオフスキ AWSのSrAppliedScientistです。
ヤチェク・ゴレビオフスキ AWSのSrAppliedScientistです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/

