
著者による画像
Python と Python データ分析スイート、および pandas や scikit-learn などの機械学習ライブラリを使用すると、データ サイエンス アプリケーションを簡単に開発できます。 ただし、Python での依存関係の管理は困難です。 データ サイエンス プロジェクトに取り組むときは、さまざまなライブラリをインストールし、特に使用しているライブラリのバージョンを追跡するのにかなりの時間を費やす必要があります。
他の開発者があなたのコードを実行してプロジェクトに貢献したい場合はどうすればよいでしょうか? そうですね、あなたのデータ サイエンス アプリケーションを複製したい他の開発者は、まず次のことを行う必要があります。 セットアップする コードを実行する前に、自分のマシン上にプロジェクト環境を構築します。 ライブラリのバージョンが異なるなどの小さな違いでも、コードに重大な変更が生じる可能性があります。 デッカー 救助へ。 Docker は開発プロセスを簡素化し、シームレスなコラボレーションを促進します。
このガイドでは、Docker の基本を紹介し、Docker を使用してデータ サイエンス アプリケーションをコンテナ化する方法を説明します。

著者による画像
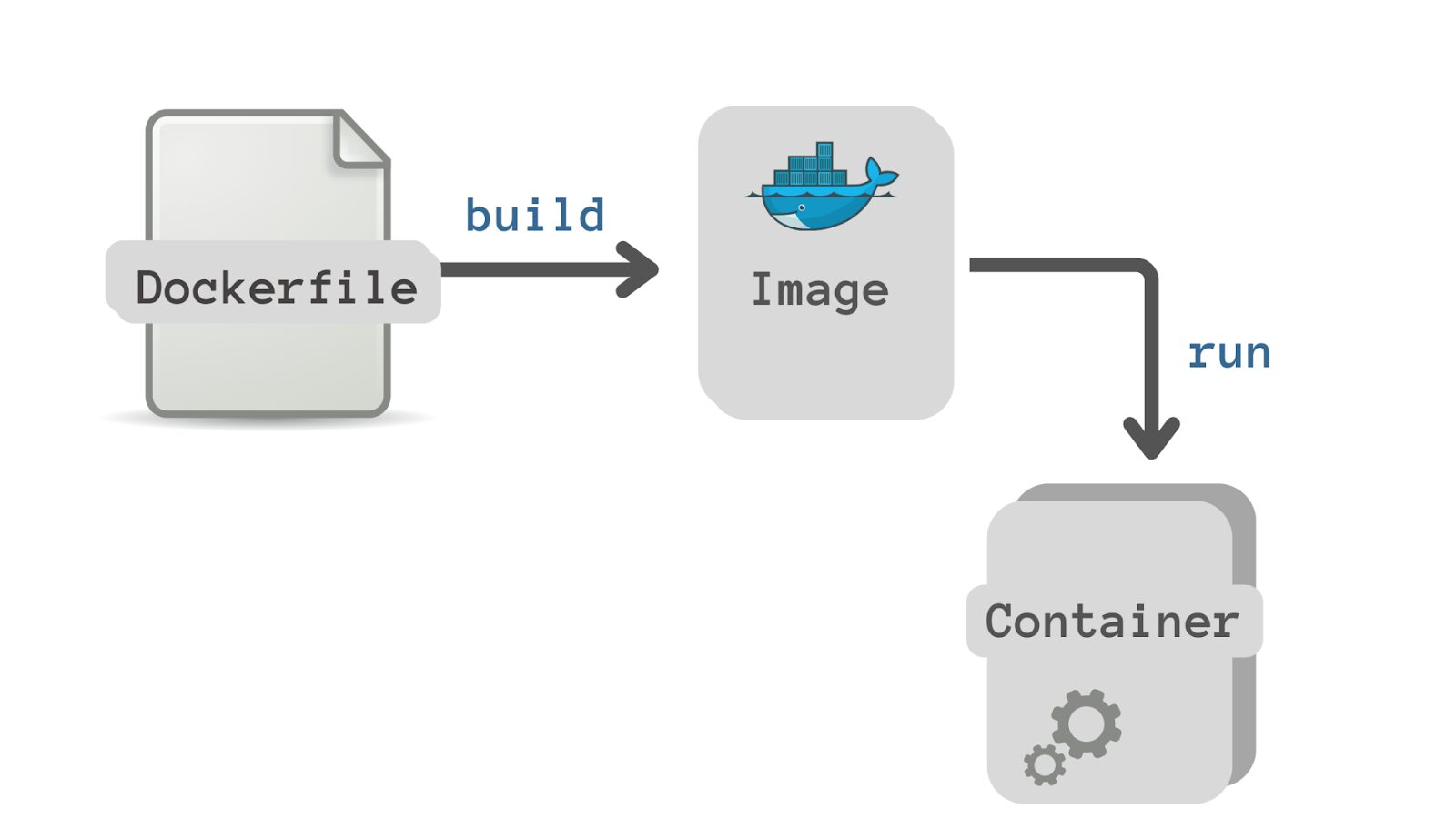
デッカー と呼ばれるポータブルなアーティファクトとしてアプリケーションを構築および共有できるコンテナ化ツールです。 画像.
ソース コードとは別に、アプリケーションには一連の依存関係、必要な構成、システム ツールなどが含まれます。 たとえば、データ サイエンス プロジェクトでは、必要なライブラリをすべて開発環境 (できれば仮想環境内) にインストールします。 また、ライブラリがサポートする Python の更新バージョンを使用していることも確認します。
ただし、アプリケーションを別のマシンで実行しようとすると、依然として問題が発生する可能性があります。 これらの問題は、開発環境において XNUMX 台のマシン間で構成とライブラリのバージョンが一致しないことが原因で発生することがよくあります。
Docker を使用すると、アプリケーションを依存関係や構成とともにパッケージ化できます。 そのため、さまざまなホスト マシンにわたって、アプリケーションに対して分離され、再現可能で、一貫した環境を定義できます。
いくつかの概念/用語を見てみましょう。
Dockerイメージ
Docker イメージは、アプリケーションの移植可能な成果物です。
Dockerコンテナ
イメージを実行すると、基本的にアプリケーションがコンテナ環境内で実行されることになります。 したがって、イメージの実行中のインスタンスはコンテナーです。
Dockerレジストリ
Docker レジストリは、 保存 & 配布する ドッカーイメージ。 アプリケーションを Docker イメージにコンテナ化した後、開発者コミュニティをイメージ レジストリにプッシュすることで、開発者コミュニティが利用できるようにすることができます。 DockerHub は最大のパブリック レジストリであり、デフォルトではすべてのイメージが DockerHub からプルされます。
コンテナーはアプリケーションに分離された環境を提供するため、他の開発者は自分のマシンに Docker をセットアップするだけで済みます。 また、複雑なインストールを気にすることなく、単一のコマンドを使用して Docker イメージを取得し、コンテナを開始できます。
アプリケーションを開発する場合、同じアプリケーションの複数のバージョンを構築してテストすることも一般的です。 Docker を使用すると、同じアプリの複数のバージョンを異なるコンテナー内で実行できます。無し 同じ環境内での競合。
Docker は開発を簡素化するだけでなく、デプロイメントも簡素化し、開発チームと運用チームが効果的に連携するのに役立ちます。 サーバー側では、運用チームは複雑なバージョンや依存関係の競合の解決に時間を費やす必要がありません。 Docker ランタイムをセットアップするだけで済みます
このチュートリアルでほとんど使用する基本的な Docker コマンドをいくつか簡単に説明します。 より詳細な概要については、以下をお読みください。 すべてのデータ サイエンティストが知っておくべき 12 の Docker コマンド.
| Command | 演算 |
docker ps |
実行中のすべてのコンテナをリストします。 |
docker pull image-name |
デフォルトで DockerHub から image-name を取得します |
docker images |
利用可能なすべての画像をリストします |
docker run image-name |
イメージからコンテナを起動します |
docker start container-id |
停止したコンテナを再起動します |
docker stop container-id |
実行中のコンテナを停止します |
docker build path |
Dockerfile の指示を使用して、パスにイメージを構築します。 |
Note: プレフィックスを付けてすべてのコマンドを実行します sudo を作成していない場合は、 ドッカー ユーザーとのグループ。
Docker の基本を学習しました。学んだことを応用してみましょう。 このセクションでは、Docker を使用して単純なデータ サイエンス アプリケーションをコンテナ化します。
住宅価格予測モデル
入力特徴に基づいて目標値、つまり住宅価格の中央値を予測する次の線形回帰モデルを考えてみましょう。 モデルは以下を使用して構築されます。 カリフォルニア州の住宅データセット:
# house_price_prediction.py
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score # Load the California Housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target # Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Standardize features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) # Train the model
model = LinearRegression()
model.fit(X_train, y_train) # Make predictions on the test set
y_pred = model.predict(X_test) # Evaluate the model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred) print(f"Mean Squared Error: {mse:.2f}")
print(f"R-squared Score: {r2:.2f}")
scikit-learn が必須の依存関係であることはわかっています。 コードを実行すると、次のように設定されます as_frame データセットをロードするときは True に等しくなります。 したがって、パンダも必要です。 そしてその requirements.txt ファイルは次のようになります。
pandas==2.0
scikit-learn==1.2.2
著者による画像
Dockerfileを作成する
これまでのところ、ソースコードファイルは完成しています house_price_prediction.py と requirements.txt ファイル。 ここで定義する必要があります の アプリケーションからイメージを構築します。 の ドッカーファイル は、アプリケーションのソース コード ファイルからイメージを構築するこの定義を作成するために使用されます。
では、Dockerfile とは何でしょうか? これは、Docker イメージを構築するための段階的な手順が記載されたテキスト ドキュメントです。
著者による画像
この例の Dockerfile は次のとおりです。
# Use the official Python image as the base image
FROM python:3.9-slim # Set the working directory in the container
WORKDIR /app # Copy the requirements.txt file to the container
COPY requirements.txt . # Install the dependencies
RUN pip install --no-cache-dir -r requirements.txt # Copy the script file to the container
COPY house_price_prediction.py . # Set the command to run your Python script
CMD ["python", "house_price_prediction.py"]
Dockerfile の内容を分析してみましょう。
- すべての Dockerfile は、
FROMベースイメージを指定する命令。 ベースイメージは、イメージの基礎となるイメージです。 ここでは、Python 3.9 で利用可能なイメージを使用します。 のFROMこの命令は、指定されたベース イメージから現在のイメージを構築するように Docker に指示します。 -
SETコマンドは、以下のすべてのコマンドの作業ディレクトリを設定するために使用されます (アプリ この例では)。 - 次に、
requirements.txtファイルをコンテナのファイル システムにコピーします。 -
RUN命令は、コンテナ内のシェルで指定されたコマンドを実行します。 ここでは、次を使用して必要な依存関係をすべてインストールします。pip. - 次に、ソース コード ファイル (Python スクリプト) をコピーします。
house_price_prediction.py-コンテナのファイルシステムへ。 - 最後に
CMDコンテナの起動時に実行される命令を指します。 ここで実行する必要があるのは、house_price_prediction.py脚本。 Dockerfile には XNUMX つだけ含める必要がありますCMD命令。
イメージを構築する
Dockerfile を定義したので、次を実行して Docker イメージを構築できます。 docker build:
docker build -t ml-app .
オプション -t で画像の名前とタグを指定できます。 名札 フォーマット。 デフォルトのタグは 最新の.
ビルド プロセスには数分かかります。
Sending build context to Docker daemon 4.608kB
Step 1/6 : FROM python:3.9-slim
3.9-slim: Pulling from library/python
5b5fe70539cd: Pull complete f4b0e4004dc0: Pull complete ec1650096fae: Pull complete 2ee3c5a347ae: Pull complete d854e82593a7: Pull complete Digest: sha256:0074c6241f2ff175532c72fb0fb37264e8a1ac68f9790f9ee6da7e9fdfb67a0e
Status: Downloaded newer image for python:3.9-slim ---> 326a3a036ed2
Step 2/6 : WORKDIR /app
...
...
...
Step 6/6 : CMD ["python", "house_price_prediction.py"] ---> Running in 7fcef6a2ab2c
Removing intermediate container 7fcef6a2ab2c ---> 2607aa43c61a
Successfully built 2607aa43c61a
Successfully tagged ml-app:latest
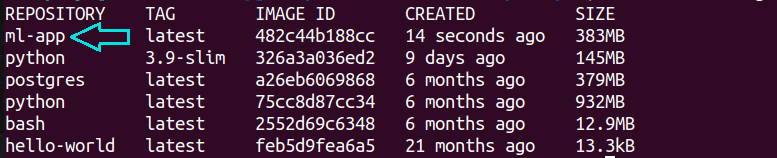
Docker イメージが構築されたら、次のコマンドを実行します。 docker images 指図。 をご覧ください。ml-app 画像も掲載されています。
docker images
Dockerイメージを実行できます ml-app docker run コマンド:
docker run ml-app

おめでとう! 初めてのデータ サイエンス アプリケーションを Docker 化しました。 DockerHub アカウントを作成すると、そのアカウント (または組織内のプライベート リポジトリ) にイメージをプッシュできます。
この Docker 入門チュートリアルがお役に立てば幸いです。 このチュートリアルで使用されているコードは次の場所にあります。 このGitHubリポジトリ。 次のステップとして、マシン上に Docker をセットアップし、この例を試してください。 または、選択したアプリケーションを Dockerize します。
マシンに Docker をインストールする最も簡単な方法は、 Dockerデスクトップ: Docker CLI クライアントと GUI の両方を入手して、コンテナーを簡単に管理できます。 Docker をセットアップして、すぐにコーディングを開始してください。
バラ プリヤ C インド出身の開発者兼テクニカル ライターです。 彼女は、数学、プログラミング、データ サイエンス、コンテンツ作成が交わる場所で働くのが好きです。 彼女の興味と専門分野には、DevOps、データ サイエンス、自然言語処理が含まれます。 彼女は読書、執筆、コーディング、コーヒーが好きです。 現在、彼女はチュートリアル、ハウツー ガイド、意見記事などを作成して、学習し、開発者コミュニティと知識を共有することに取り組んでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/07/docker-tutorial-data-scientists.html?utm_source=rss&utm_medium=rss&utm_campaign=docker-tutorial-for-data-scientists

